 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Augmentation for Meta-Learning
Oct 14, 2020
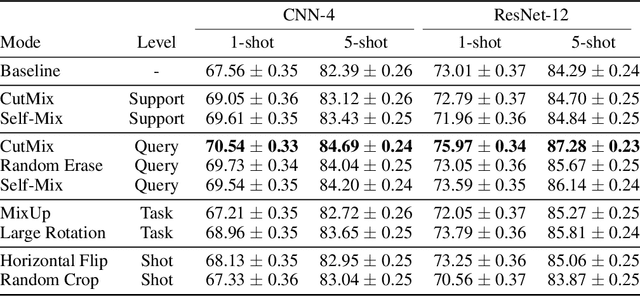
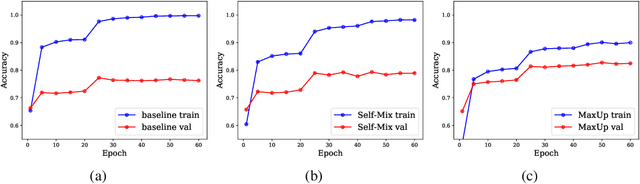
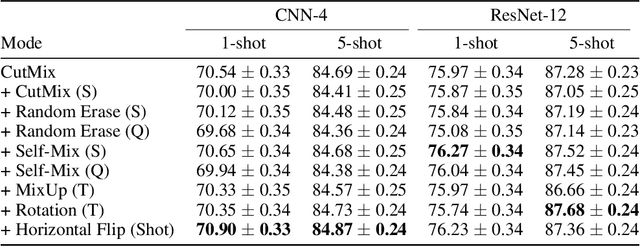
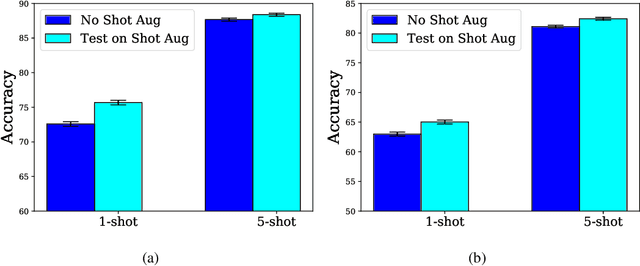
Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, sophisticated data augmentation schemes are used to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample not only images, but classes as well. We investigate how data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.
Fully Automated Left Atrium Segmentation from Anatomical Cine Long-axis MRI Sequences using Deep Convolutional Neural Network with Unscented Kalman Filter
Sep 28, 2020
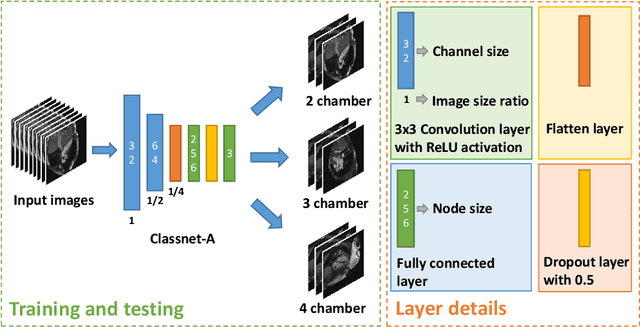
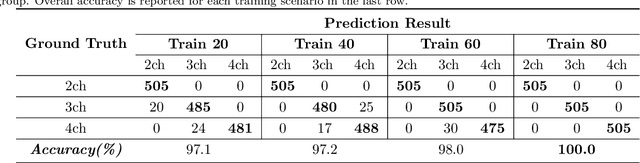
This study proposes a fully automated approach for the left atrial segmentation from routine cine long-axis cardiac magnetic resonance image sequences using deep convolutional neural networks and Bayesian filtering. The proposed approach consists of a classification network that automatically detects the type of long-axis sequence and three different convolutional neural network models followed by unscented Kalman filtering (UKF) that delineates the left atrium. Instead of training and predicting all long-axis sequence types together, the proposed approach first identifies the image sequence type as to 2, 3 and 4 chamber views, and then performs prediction based on neural nets trained for that particular sequence type. The datasets were acquired retrospectively and ground truth manual segmentation was provided by an expert radiologist. In addition to neural net based classification and segmentation, another neural net is trained and utilized to select image sequences for further processing using UKF to impose temporal consistency over cardiac cycle. A cyclic dynamic model with time-varying angular frequency is introduced in UKF to characterize the variations in cardiac motion during image scanning. The proposed approach was trained and evaluated separately with varying amount of training data with images acquired from 20, 40, 60 and 80 patients. Evaluations over 1515 images with equal number of images from each chamber group acquired from an additional 20 patients demonstrated that the proposed model outperformed state-of-the-art and yielded a mean Dice coefficient value of 94.1%, 93.7% and 90.1% for 2, 3 and 4-chamber sequences, respectively, when trained with datasets from 80 patients.
Fast Adaptation with Linearized Neural Networks
Mar 02, 2021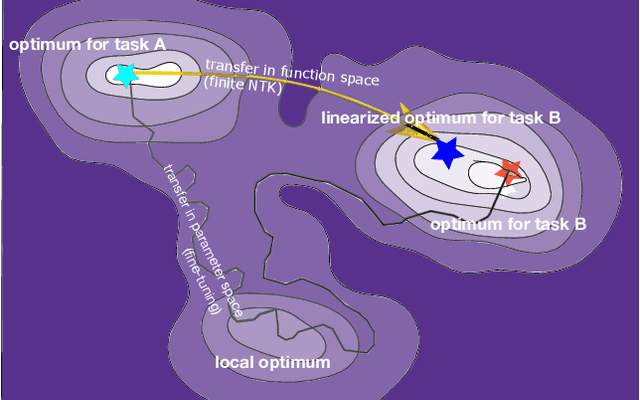

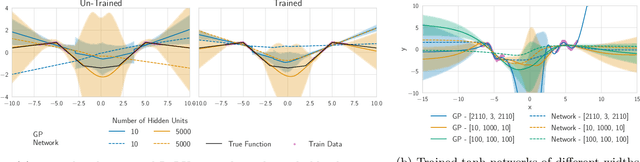
The inductive biases of trained neural networks are difficult to understand and, consequently, to adapt to new settings. We study the inductive biases of linearizations of neural networks, which we show to be surprisingly good summaries of the full network functions. Inspired by this finding, we propose a technique for embedding these inductive biases into Gaussian processes through a kernel designed from the Jacobian of the network. In this setting, domain adaptation takes the form of interpretable posterior inference, with accompanying uncertainty estimation. This inference is analytic and free of local optima issues found in standard techniques such as fine-tuning neural network weights to a new task. We develop significant computational speed-ups based on matrix multiplies, including a novel implementation for scalable Fisher vector products. Our experiments on both image classification and regression demonstrate the promise and convenience of this framework for transfer learning, compared to neural network fine-tuning. Code is available at https://github.com/amzn/xfer/tree/master/finite_ntk.
MUSE: Illustrating Textual Attributes by Portrait Generation
Nov 09, 2020
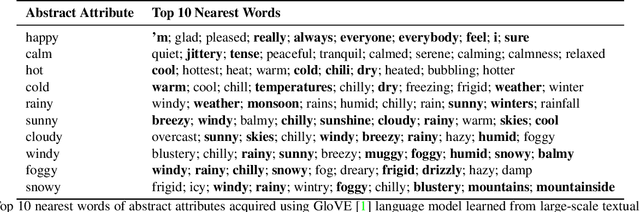

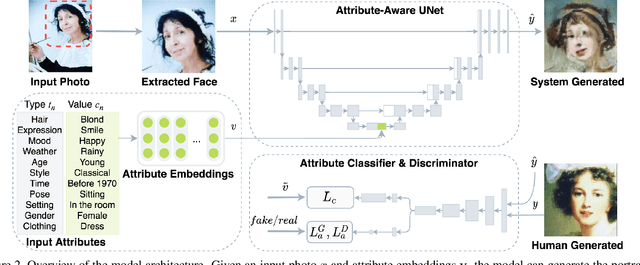
We propose a novel approach, MUSE, to illustrate textual attributes visually via portrait generation. MUSE takes a set of attributes written in text, in addition to facial features extracted from a photo of the subject as input. We propose 11 attribute types to represent inspirations from a subject's profile, emotion, story, and environment. We propose a novel stacked neural network architecture by extending an image-to-image generative model to accept textual attributes. Experiments show that our approach significantly outperforms several state-of-the-art methods without using textual attributes, with Inception Score score increased by 6% and Fr\'echet Inception Distance (FID) score decreased by 11%, respectively. We also propose a new attribute reconstruction metric to evaluate whether the generated portraits preserve the subject's attributes. Experiments show that our approach can accurately illustrate 78% textual attributes, which also help MUSE capture the subject in a more creative and expressive way.
Benchmarking Deep Learning Classifiers: Beyond Accuracy
Mar 02, 2021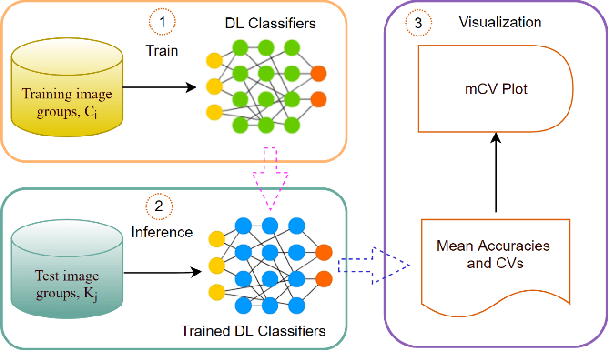
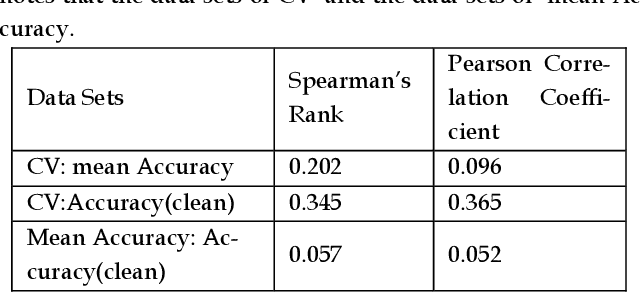
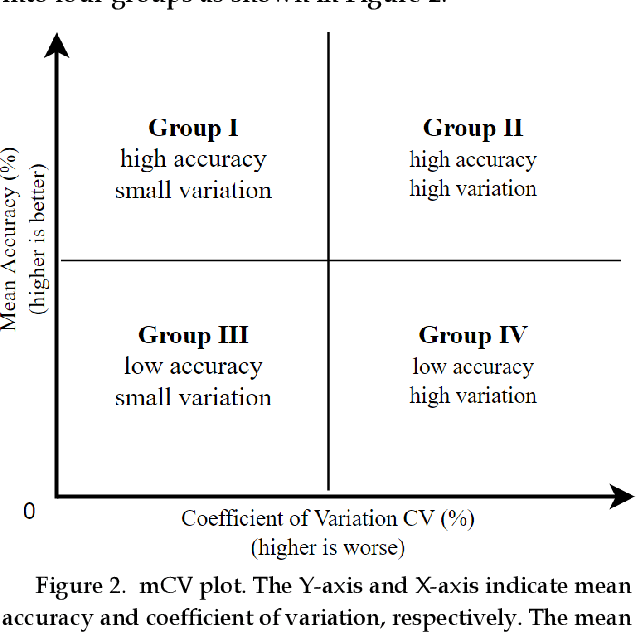
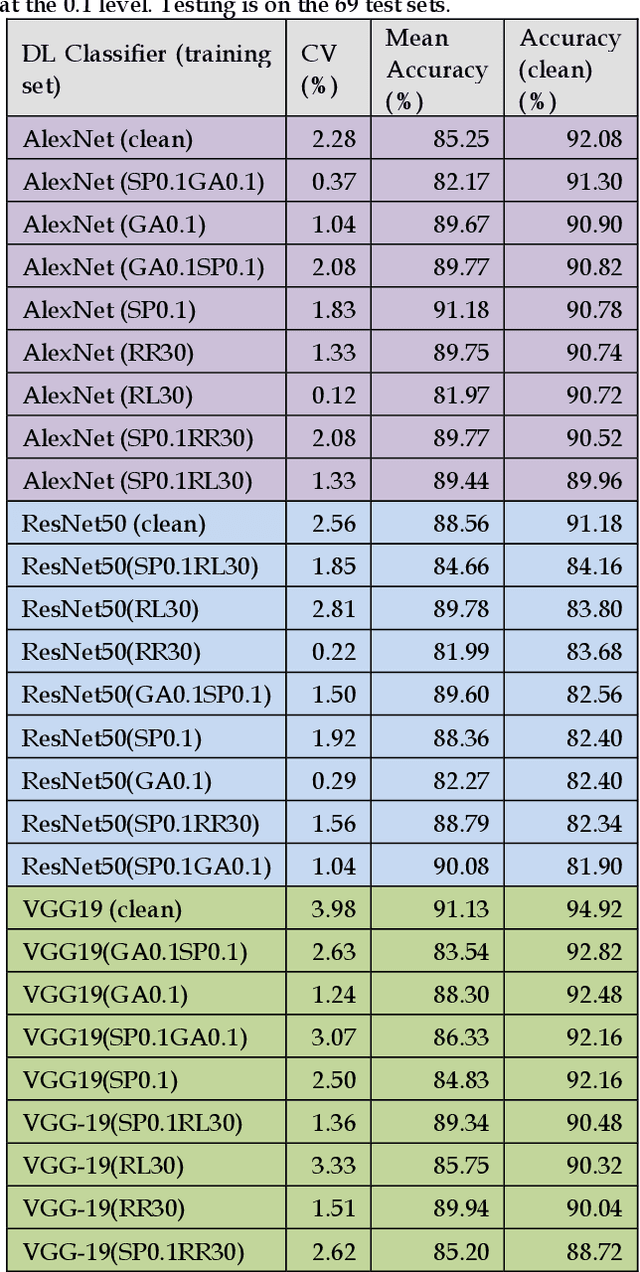
Previous research evaluating deep learning (DL) classifiers has often used top-1/top-5 accuracy. However, the accuracy of DL classifiers is unstable in that it often changes significantly when retested on imperfect or adversarial images. This paper adds to the small but fundamental body of work on benchmarking the robustness of DL classifiers on imperfect images by proposing a two-dimensional metric, consisting of mean accuracy and coefficient of variation, to measure the robustness of DL classifiers. Spearman's rank correlation coefficient and Pearson's correlation coefficient are used and their independence evaluated. A statistical plot we call mCV is presented which aims to help visualize the robustness of the performance of DL classifiers across varying amounts of imperfection in tested images. Finally, we demonstrate that defective images corrupted by two-factor corruption could be used to improve the robustness of DL classifiers. All source codes and related image sets are shared on a website (http://www.animpala.com) to support future research projects.
Ordinal Distance Metric Learning with MDS for Image Ranking
Feb 27, 2019

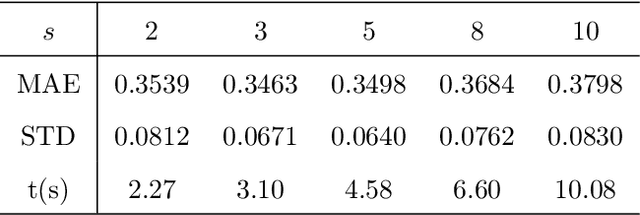
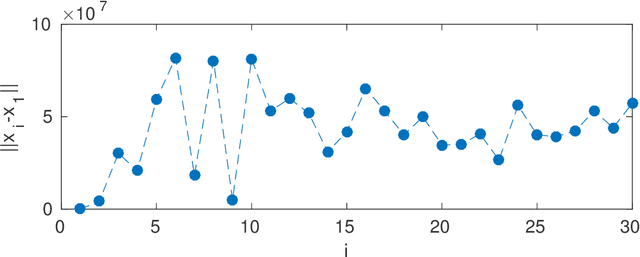
Image ranking is to rank images based on some known ranked images. In this paper, we propose an improved linear ordinal distance metric learning approach based on the linear distance metric learning model. By decomposing the distance metric $A$ as $L^TL$, the problem can be cast as looking for a linear map between two sets of points in different spaces, meanwhile maintaining some data structures. The ordinal relation of the labels can be maintained via classical multidimensional scaling, a popular tool for dimension reduction in statistics. A least squares fitting term is then introduced to the cost function, which can also maintain the local data structure. The resulting model is an unconstrained problem, and can better fit the data structure. Extensive numerical results demonstrate the improvement of the new approach over the linear distance metric learning model both in speed and ranking performance.
An End-to-End Computer Vision Methodology for Quantitative Metallography
Apr 22, 2021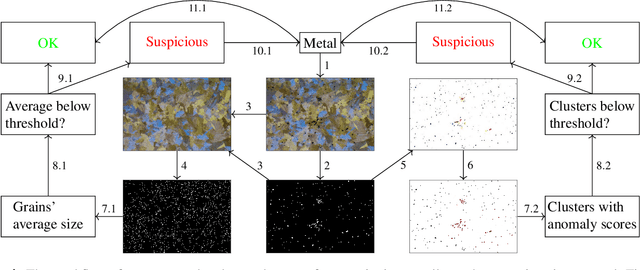

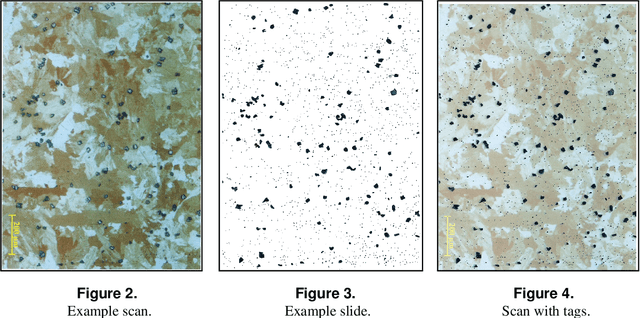

Metallography is crucial for a proper assessment of material's properties. It involves mainly the investigation of spatial distribution of grains and the occurrence and characteristics of inclusions or precipitates. This work presents an holistic artificial intelligence model for Anomaly Detection that automatically quantifies the degree of anomaly of impurities in alloys. We suggest the following examination process: (1) Deep semantic segmentation is performed on the inclusions (based on a suitable metallographic database of alloys and corresponding tags of inclusions), producing inclusions masks that are saved into a separated database. (2) Deep image inpainting is performed to fill the removed inclusions parts, resulting in 'clean' metallographic images, which contain the background of grains. (3) Grains' boundaries are marked using deep semantic segmentation (based on another metallographic database of alloys), producing boundaries that are ready for further inspection on the distribution of grains' size. (4) Deep anomaly detection and pattern recognition is performed on the inclusions masks to determine spatial, shape and area anomaly detection of the inclusions. Finally, the system recommends to an expert on areas of interests for further examination. The performance of the model is presented and analyzed based on few representative cases. Although the models presented here were developed for metallography analysis, most of them can be generalized to a wider set of problems in which anomaly detection of geometrical objects is desired. All models as well as the data-sets that were created for this work, are publicly available at https://github.com/Scientific-Computing-Lab-NRCN/MLography.
Synthesis versus analysis in patch-based image priors
Feb 20, 2017In global models/priors (for example, using wavelet frames), there is a well known analysis vs synthesis dichotomy in the way signal/image priors are formulated. In patch-based image models/priors, this dichotomy is also present in the choice of how each patch is modeled. This paper shows that there is another analysis vs synthesis dichotomy, in terms of how the whole image is related to the patches, and that all existing patch-based formulations that provide a global image prior belong to the analysis category. We then propose a synthesis formulation, where the image is explicitly modeled as being synthesized by additively combining a collection of independent patches. We formally establish that these analysis and synthesis formulations are not equivalent in general and that both formulations are compatible with analysis and synthesis formulations at the patch level. Finally, we present an instance of the alternating direction method of multipliers (ADMM) that can be used to perform image denoising under the proposed synthesis formulation, showing its computational feasibility. Rather than showing the superiority of the synthesis or analysis formulations, the contributions of this paper is to establish the existence of both alternatives, thus closing the corresponding gap in the field of patch-based image processing.
Inspecting state of the art performance and NLP metrics in image-based medical report generation
Nov 21, 2020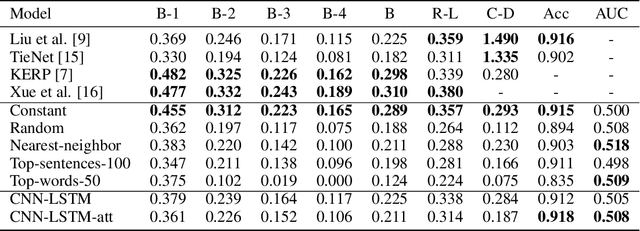
Several deep learning architectures have been proposed over the last years to deal with the problem of generating a written report given an imaging exam as input. Most works evaluate the generated reports using standard Natural Language Processing (NLP) metrics (e.g. BLEU, ROUGE), reporting significant progress. In this article, we contrast this progress by comparing state of the art (SOTA) models against weak baselines. We show that simple and even naive approaches yield near SOTA performance on most traditional NLP metrics. We conclude that evaluation methods in this task should be further studied towards correctly measuring clinical accuracy, ideally involving physicians to contribute to this end.
Human 3D keypoints via spatial uncertainty modeling
Dec 18, 2020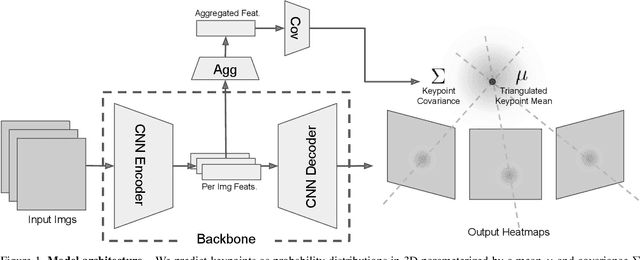
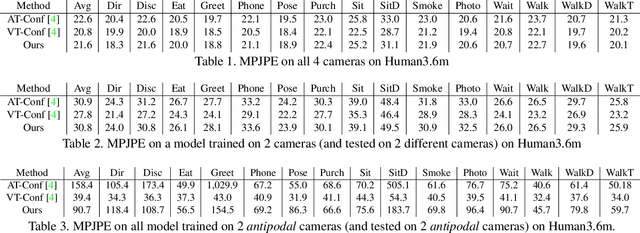

We introduce a technique for 3D human keypoint estimation that directly models the notion of spatial uncertainty of a keypoint. Our technique employs a principled approach to modelling spatial uncertainty inspired from techniques in robust statistics. Furthermore, our pipeline requires no 3D ground truth labels, relying instead on (possibly noisy) 2D image-level keypoints. Our method achieves near state-of-the-art performance on Human3.6m while being efficient to evaluate and straightforward to