 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transfer learning based few-shot classification using optimal transport mapping from preprocessed latent space of backbone neural network
Feb 11, 2021
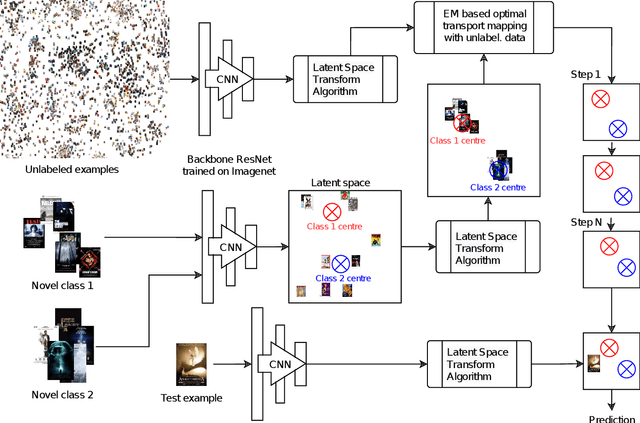
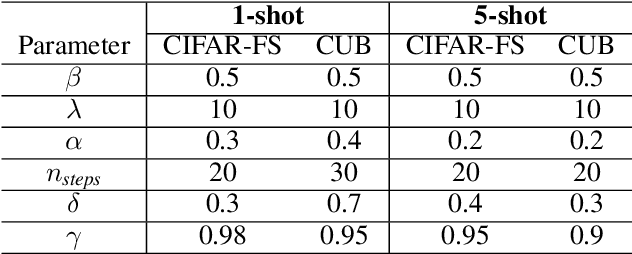
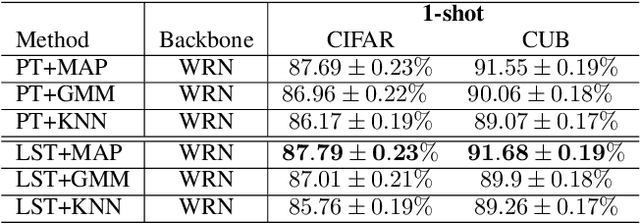
MetaDL Challenge 2020 focused on image classification tasks in few-shot settings. This paper describes second best submission in the competition. Our meta learning approach modifies the distribution of classes in a latent space produced by a backbone network for each class in order to better follow the Gaussian distribution. After this operation which we call Latent Space Transform algorithm, centers of classes are further aligned in an iterative fashion of the Expectation Maximisation algorithm to utilize information in unlabeled data that are often provided on top of few labelled instances. For this task, we utilize optimal transport mapping using the Sinkhorn algorithm. Our experiments show that this approach outperforms previous works as well as other variants of the algorithm, using K-Nearest Neighbour algorithm, Gaussian Mixture Models, etc.
Sparse Oblique Decision Trees: A Tool to Understand and Manipulate Neural Net Features
Apr 07, 2021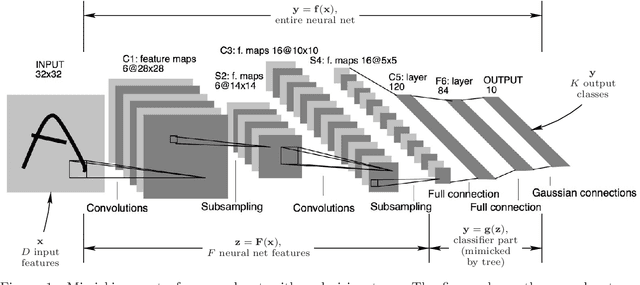

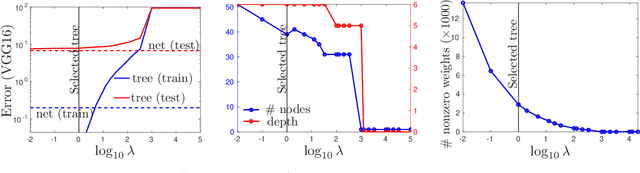

The widespread deployment of deep nets in practical applications has lead to a growing desire to understand how and why such black-box methods perform prediction. Much work has focused on understanding what part of the input pattern (an image, say) is responsible for a particular class being predicted, and how the input may be manipulated to predict a different class. We focus instead on understanding which of the internal features computed by the neural net are responsible for a particular class. We achieve this by mimicking part of the neural net with an oblique decision tree having sparse weight vectors at the decision nodes. Using the recently proposed Tree Alternating Optimization (TAO) algorithm, we are able to learn trees that are both highly accurate and interpretable. Such trees can faithfully mimic the part of the neural net they replaced, and hence they can provide insights into the deep net black box. Further, we show we can easily manipulate the neural net features in order to make the net predict, or not predict, a given class, thus showing that it is possible to carry out adversarial attacks at the level of the features. These insights and manipulations apply globally to the entire training and test set, not just at a local (single-instance) level. We demonstrate this robustly in the MNIST and ImageNet datasets with LeNet5 and VGG networks.
A Hybrid Quantum enabled RBM Advantage: Convolutional Autoencoders For Quantum Image Compression and Generative Learning
Jan 31, 2020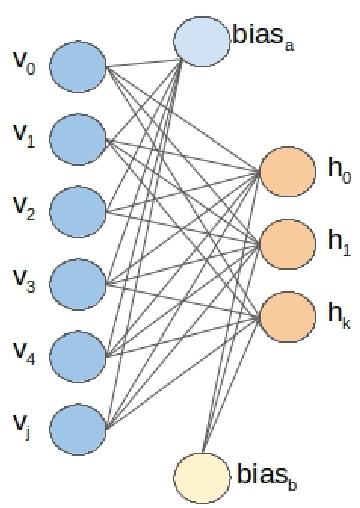

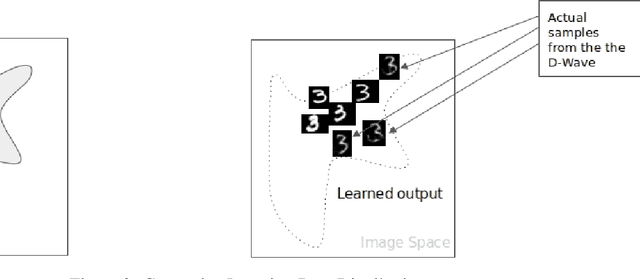

Understanding how the D-Wave quantum computer could be used for machine learning problems is of growing interest. Our work evaluates the feasibility of using the D-Wave as a sampler for machine learning. We describe a hybrid system that combines a classical deep neural network autoencoder with a quantum annealing Restricted Boltzmann Machine (RBM) using the D-Wave. We evaluate our hybrid autoencoder algorithm using two datasets, the MNIST dataset and MNIST Fashion dataset. We evaluate the quality of this method by using a downstream classification method where the training is based on quantum RBM-generated samples. Our method overcomes two key limitations in the current 2000-qubit D-Wave processor, namely the limited number of qubits available to accommodate typical problem sizes for fully connected quantum objective functions and samples that are binary pixel representations. As a consequence of these limitations we are able to show how we achieved nearly a 22-fold compression factor of grayscale 28 x 28 sized images to binary 6 x 6 sized images with a lossy recovery of the original 28 x 28 grayscale images. We further show how generating samples from the D-Wave after training the RBM, resulted in 28 x 28 images that were variations of the original input data distribution, as opposed to recreating the training samples. We formulated an MNIST classification problem using a deep convolutional neural network that used samples from a quantum RBM to train the MNIST classifier and compared the results with an MNIST classifier trained with the original MNIST training data set, as well as an MNIST classifier trained using classical RBM samples. Our hybrid autoencoder approach indicates advantage for RBM results relative to the use of a current RBM classical computer implementation for image-based machine learning and even more promising results for the next generation D-Wave quantum system.
Automatically Designing CNN Architectures for Medical Image Segmentation
Jul 19, 2018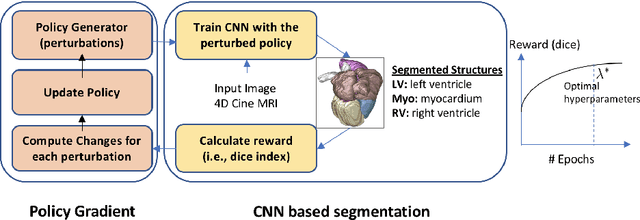
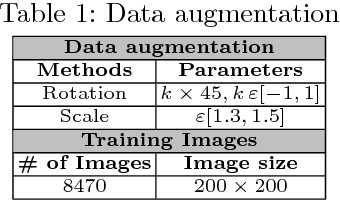
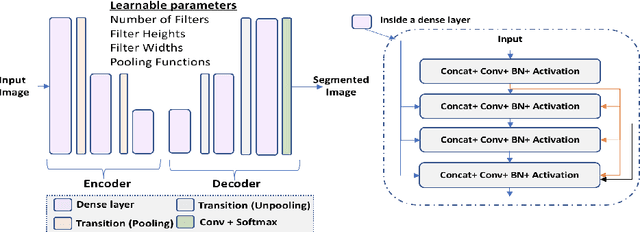
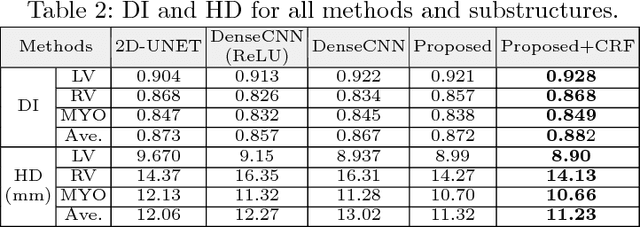
Deep neural network architectures have traditionally been designed and explored with human expertise in a long-lasting trial-and-error process. This process requires huge amount of time, expertise, and resources. To address this tedious problem, we propose a novel algorithm to optimally find hyperparameters of a deep network architecture automatically. We specifically focus on designing neural architectures for medical image segmentation task. Our proposed method is based on a policy gradient reinforcement learning for which the reward function is assigned a segmentation evaluation utility (i.e., dice index). We show the efficacy of the proposed method with its low computational cost in comparison with the state-of-the-art medical image segmentation networks. We also present a new architecture design, a densely connected encoder-decoder CNN, as a strong baseline architecture to apply the proposed hyperparameter search algorithm. We apply the proposed algorithm to each layer of the baseline architectures. As an application, we train the proposed system on cine cardiac MR images from Automated Cardiac Diagnosis Challenge (ACDC) MICCAI 2017. Starting from a baseline segmentation architecture, the resulting network architecture obtains the state-of-the-art results in accuracy without performing any trial-and-error based architecture design approaches or close supervision of the hyperparameters changes.
AMPA-Net: Optimization-Inspired Attention Neural Network for Deep Compressed Sensing
Oct 15, 2020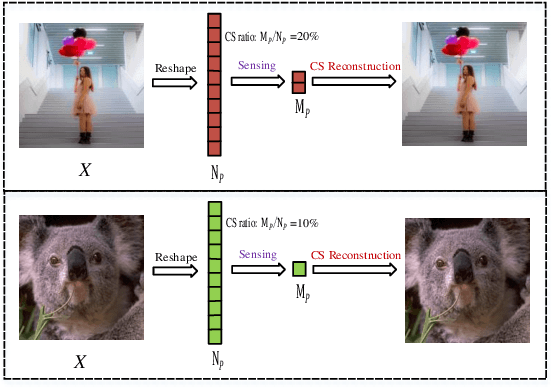
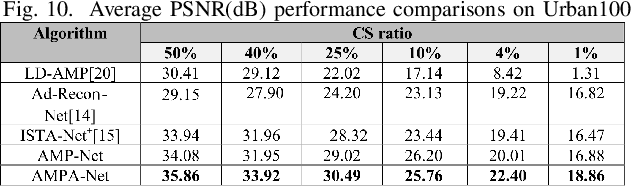
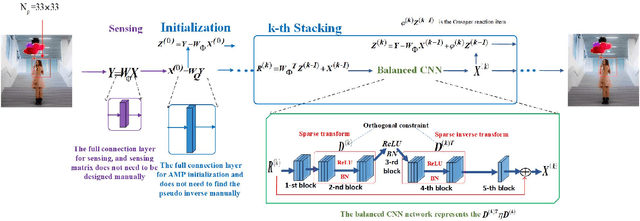
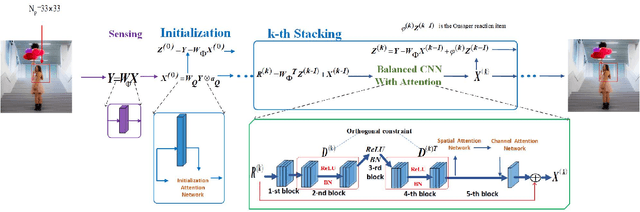
Compressed sensing (CS) is a challenging problem in image processing due to reconstructing an almost complete image from a limited measurement. To achieve fast and accurate CS reconstruction, we synthesize the advantages of two well-known methods (neural network and optimization algorithm) to propose a novel optimization inspired neural network which dubbed AMP-Net. AMP-Net realizes the fusion of the Approximate Message Passing (AMP) algorithm and neural network. All of its parameters are learned automatically. Furthermore, we propose an AMPA-Net which uses three attention networks to improve the representation ability of AMP-Net. Finally, We demonstrate the effectiveness of AMP-Net and AMPA-Net on four CS reconstruction benchmark data sets.
* 7 pages,7 figures
An optical neural network using less than 1 photon per multiplication
Apr 27, 2021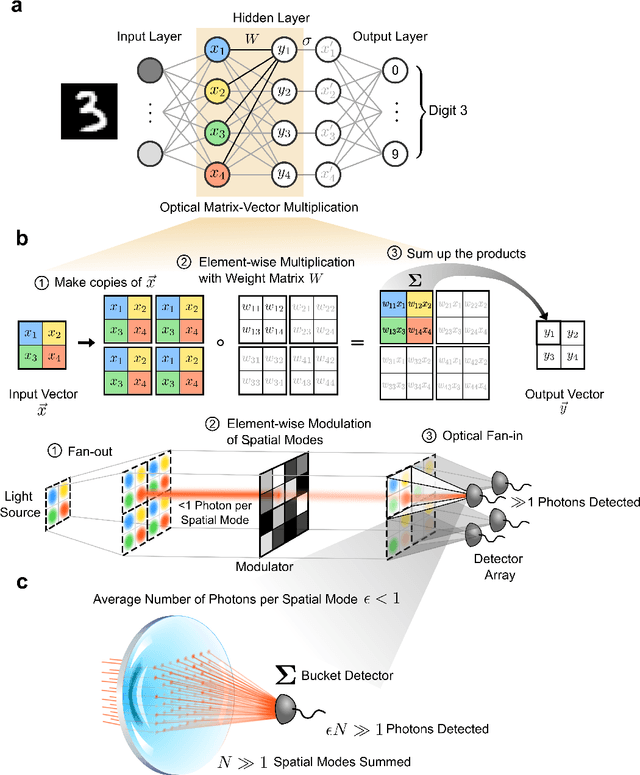
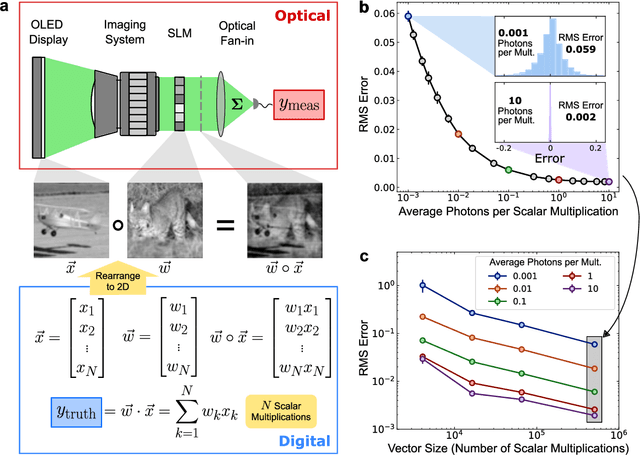
Deep learning has rapidly become a widespread tool in both scientific and commercial endeavors. Milestones of deep learning exceeding human performance have been achieved for a growing number of tasks over the past several years, across areas as diverse as game-playing, natural-language translation, and medical-image analysis. However, continued progress is increasingly hampered by the high energy costs associated with training and running deep neural networks on electronic processors. Optical neural networks have attracted attention as an alternative physical platform for deep learning, as it has been theoretically predicted that they can fundamentally achieve higher energy efficiency than neural networks deployed on conventional digital computers. Here, we experimentally demonstrate an optical neural network achieving 99% accuracy on handwritten-digit classification using ~3.2 detected photons per weight multiplication and ~90% accuracy using ~0.64 photons (~$2.4 \times 10^{-19}$ J of optical energy) per weight multiplication. This performance was achieved using a custom free-space optical processor that executes matrix-vector multiplications in a massively parallel fashion, with up to ~0.5 million scalar (weight) multiplications performed at the same time. Using commercially available optical components and standard neural-network training methods, we demonstrated that optical neural networks can operate near the standard quantum limit with extremely low optical powers and still achieve high accuracy. Our results provide a proof-of-principle for low-optical-power operation, and with careful system design including the surrounding electronics used for data storage and control, open up a path to realizing optical processors that require only $10^{-16}$ J total energy per scalar multiplication -- which is orders of magnitude more efficient than current digital processors.
Importance of Self-Consistency in Active Learning for Semantic Segmentation
Aug 04, 2020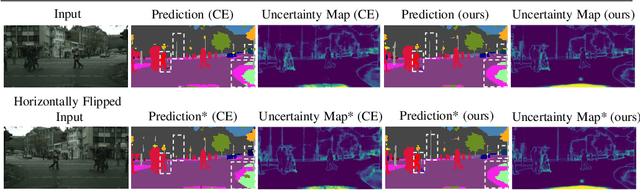
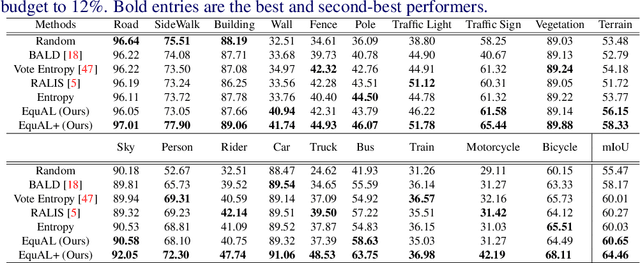
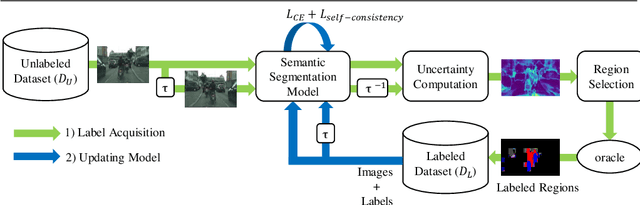
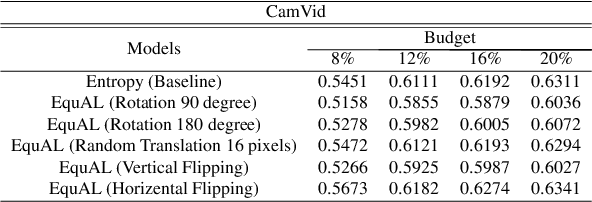
We address the task of active learning in the context of semantic segmentation and show that self-consistency can be a powerful source of self-supervision to greatly improve the performance of a data-driven model with access to only a small amount of labeled data. Self-consistency uses the simple observation that the results of semantic segmentation for a specific image should not change under transformations like horizontal flipping (i.e., the results should only be flipped). In other words, the output of a model should be consistent under equivariant transformations. The self-supervisory signal of self-consistency is particularly helpful during active learning since the model is prone to overfitting when there is only a small amount of labeled training data. In our proposed active learning framework, we iteratively extract small image patches that need to be labeled, by selecting image patches that have high uncertainty (high entropy) under equivariant transformations. We enforce pixel-wise self-consistency between the outputs of segmentation network for each image and its transformation (horizontally flipped) to utilize the rich self-supervisory information and reduce the uncertainty of the network. In this way, we are able to find the image patches over which the current model struggles the most to classify. By iteratively training over these difficult image patches, our experiments show that our active learning approach reaches $\sim96\%$ of the top performance of a model trained on all data, by using only $12\%$ of the total data on benchmark semantic segmentation datasets (e.g., CamVid and Cityscapes).
NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
Mar 01, 2021
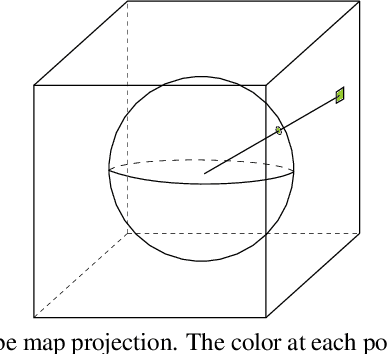
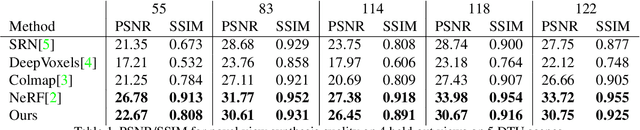
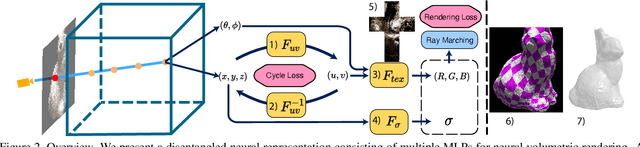
Recent work has demonstrated that volumetric scene representations combined with differentiable volume rendering can enable photo-realistic rendering for challenging scenes that mesh reconstruction fails on. However, these methods entangle geometry and appearance in a "black-box" volume that cannot be edited. Instead, we present an approach that explicitly disentangles geometry--represented as a continuous 3D volume--from appearance--represented as a continuous 2D texture map. We achieve this by introducing a 3D-to-2D texture mapping (or surface parameterization) network into volumetric representations. We constrain this texture mapping network using an additional 2D-to-3D inverse mapping network and a novel cycle consistency loss to make 3D surface points map to 2D texture points that map back to the original 3D points. We demonstrate that this representation can be reconstructed using only multi-view image supervision and generates high-quality rendering results. More importantly, by separating geometry and texture, we allow users to edit appearance by simply editing 2D texture maps.
A Learned Compact and Editable Light Field Representation
Mar 21, 2021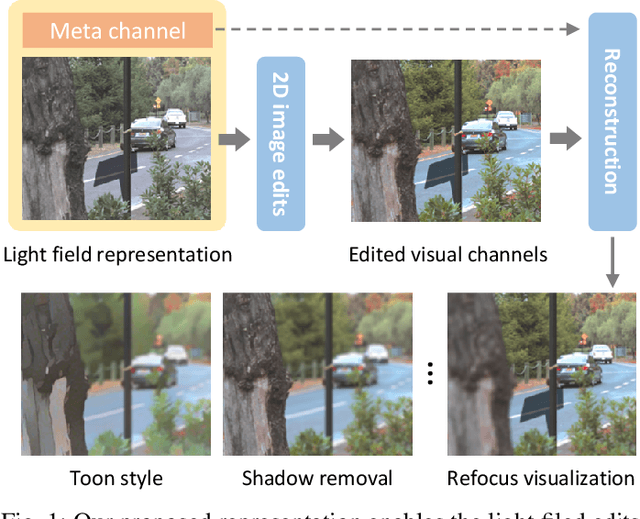



Light fields are 4D scene representation typically structured as arrays of views, or several directional samples per pixel in a single view. This highly correlated structure is not very efficient to transmit and manipulate (especially for editing), though. To tackle these problems, we present a novel compact and editable light field representation, consisting of a set of visual channels (i.e. the central RGB view) and a complementary meta channel that encodes the residual geometric and appearance information. The visual channels in this representation can be edited using existing 2D image editing tools, before accurately reconstructing the whole edited light field back. We propose to learn this representation via an autoencoder framework, consisting of an encoder for learning the representation, and a decoder for reconstructing the light field. To handle the challenging occlusions and propagation of edits, we specifically designed an editing-aware decoding network and its associated training strategy, so that the edits to the visual channels can be consistently propagated to the whole light field upon reconstruction.Experimental results show that our proposed method outperforms related existing methods in reconstruction accuracy, and achieves visually pleasant performance in editing propagation.
Revisiting Light Field Rendering with Deep Anti-Aliasing Neural Network
Apr 14, 2021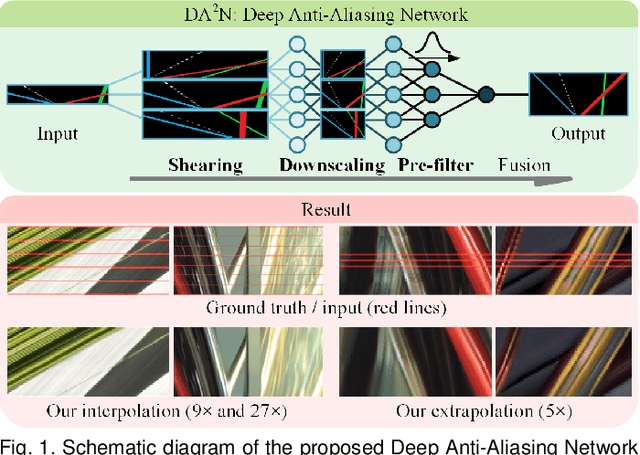

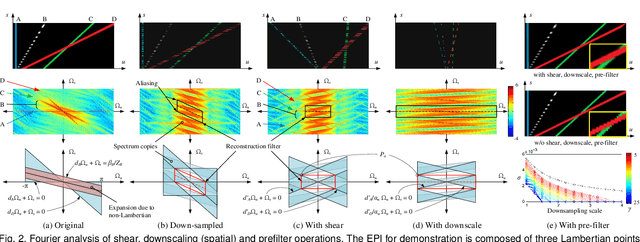
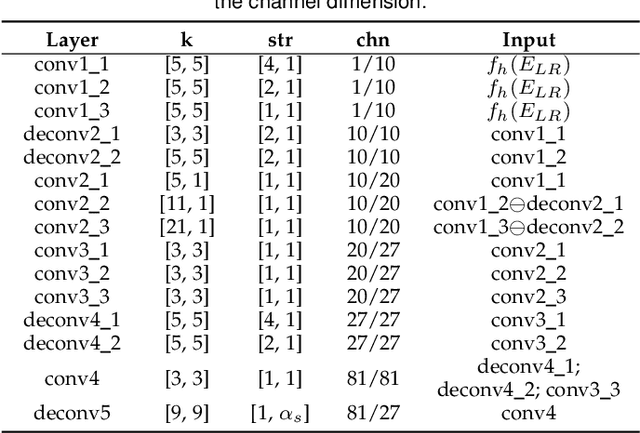
The light field (LF) reconstruction is mainly confronted with two challenges, large disparity and the non-Lambertian effect. Typical approaches either address the large disparity challenge using depth estimation followed by view synthesis or eschew explicit depth information to enable non-Lambertian rendering, but rarely solve both challenges in a unified framework. In this paper, we revisit the classic LF rendering framework to address both challenges by incorporating it with advanced deep learning techniques. First, we analytically show that the essential issue behind the large disparity and non-Lambertian challenges is the aliasing problem. Classic LF rendering approaches typically mitigate the aliasing with a reconstruction filter in the Fourier domain, which is, however, intractable to implement within a deep learning pipeline. Instead, we introduce an alternative framework to perform anti-aliasing reconstruction in the image domain and analytically show comparable efficacy on the aliasing issue. To explore the full potential, we then embed the anti-aliasing framework into a deep neural network through the design of an integrated architecture and trainable parameters. The network is trained through end-to-end optimization using a peculiar training set, including regular LFs and unstructured LFs. The proposed deep learning pipeline shows a substantial superiority in solving both the large disparity and the non-Lambertian challenges compared with other state-of-the-art approaches. In addition to the view interpolation for an LF, we also show that the proposed pipeline also benefits light field view extrapolation.
* 14 pages, 12 figures. Accepted by IEEE TPAMI