 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Noise-Equipped Convolutional Neural Networks
Dec 09, 2020

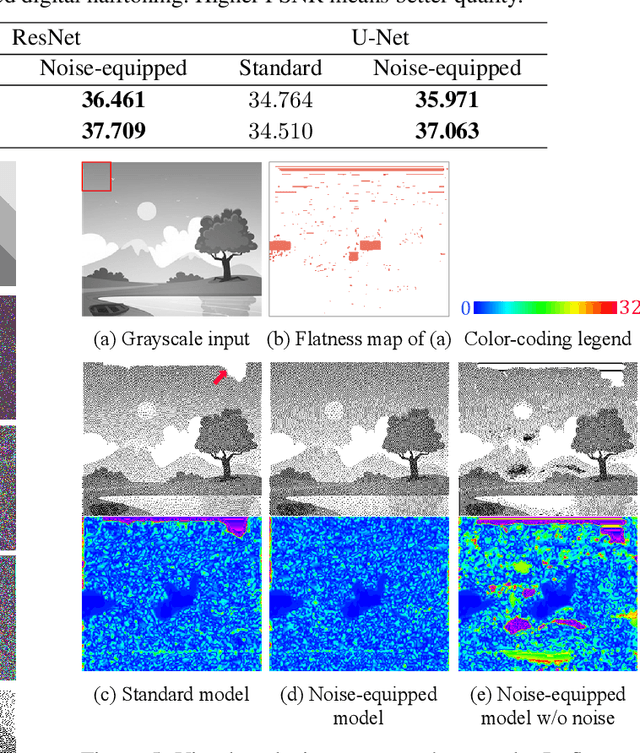
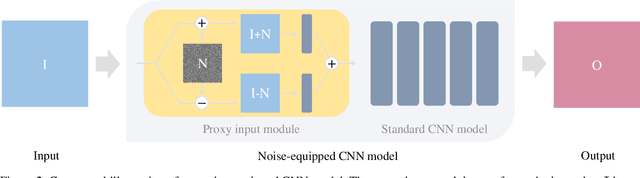

As a generic modeling tool, Convolutional Neural Network (CNN) has been widely employed in image synthesis and translation tasks. However, when a CNN model is fed with a flat input, the transformation degrades into a scaling operation due to the spatial sharing nature of convolution kernels. This inherent problem has been barely studied nor raised as an application restriction. In this paper, we point out that such convolution degradation actually hinders some specific image generation tasks that expect value-variant output from a flat input. We study the cause behind it and propose a generic solution to tackle it. Our key idea is to break the flat input condition through a proxy input module that perturbs the input data symmetrically with a noise map and reassembles them in feature domain. We call it noise-equipped CNN model and study its behavior through multiple analysis. Our experiments show that our model is free of degradation and hence serves as a superior alternative to standard CNN models. We further demonstrate improved performances of applying our model to existing applications, e.g. semantic photo synthesis and color-encoded grayscale generation.
Playing Lottery Tickets with Vision and Language
Apr 23, 2021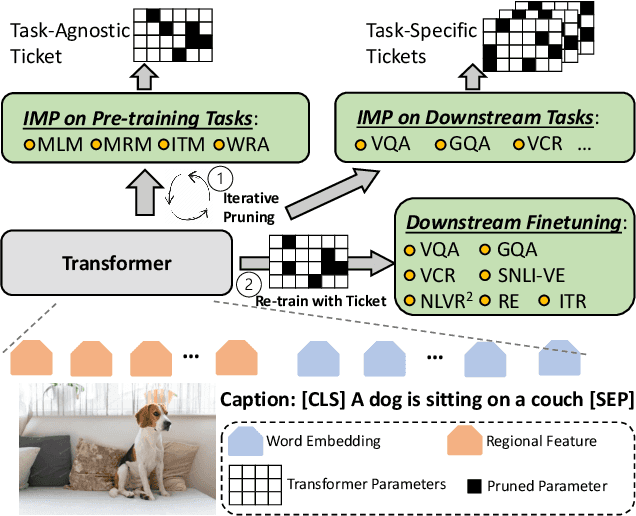
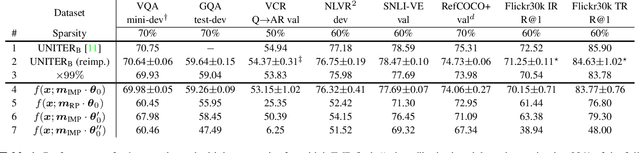
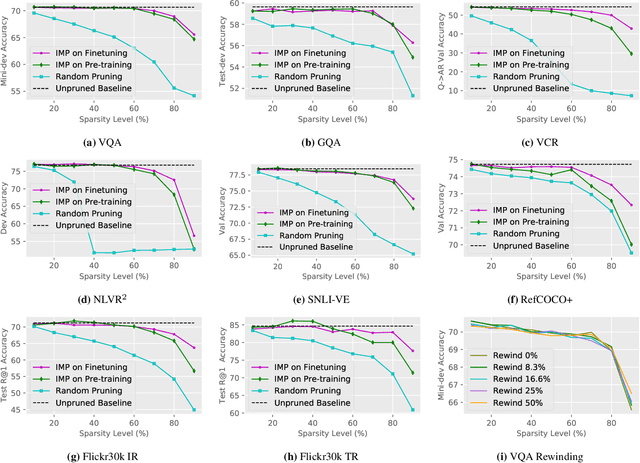
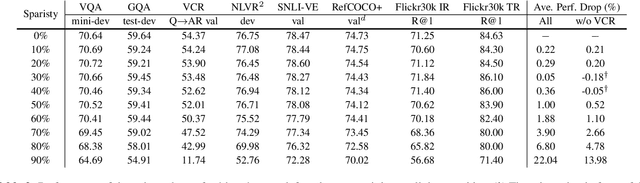
Large-scale transformer-based pre-training has recently revolutionized vision-and-language (V+L) research. Models such as LXMERT, ViLBERT and UNITER have significantly lifted the state of the art over a wide range of V+L tasks. However, the large number of parameters in such models hinders their application in practice. In parallel, work on the lottery ticket hypothesis has shown that deep neural networks contain small matching subnetworks that can achieve on par or even better performance than the dense networks when trained in isolation. In this work, we perform the first empirical study to assess whether such trainable subnetworks also exist in pre-trained V+L models. We use UNITER, one of the best-performing V+L models, as the testbed, and consolidate 7 representative V+L tasks for experiments, including visual question answering, visual commonsense reasoning, visual entailment, referring expression comprehension, image-text retrieval, GQA, and NLVR$^2$. Through comprehensive analysis, we summarize our main findings as follows. ($i$) It is difficult to find subnetworks (i.e., the tickets) that strictly match the performance of the full UNITER model. However, it is encouraging to confirm that we can find "relaxed" winning tickets at 50%-70% sparsity that maintain 99% of the full accuracy. ($ii$) Subnetworks found by task-specific pruning transfer reasonably well to the other tasks, while those found on the pre-training tasks at 60%/70% sparsity transfer universally, matching 98%/96% of the full accuracy on average over all the tasks. ($iii$) Adversarial training can be further used to enhance the performance of the found lottery tickets.
DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images
Mar 13, 2021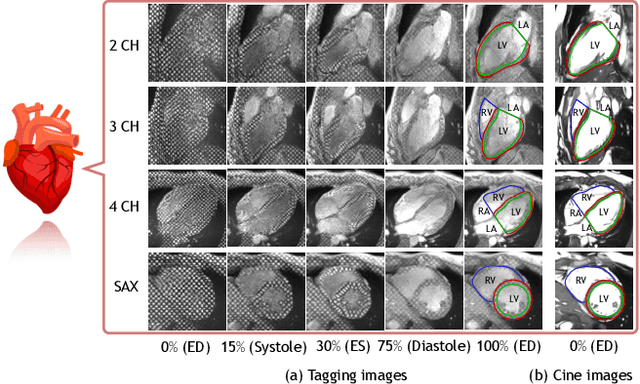
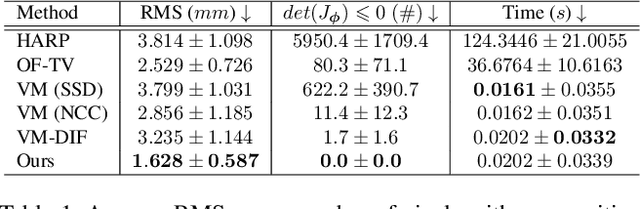
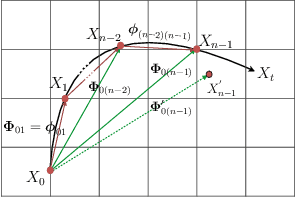
Cardiac tagging magnetic resonance imaging (t-MRI) is the gold standard for regional myocardium deformation and cardiac strain estimation. However, this technique has not been widely used in clinical diagnosis, as a result of the difficulty of motion tracking encountered with t-MRI images. In this paper, we propose a novel deep learning-based fully unsupervised method for in vivo motion tracking on t-MRI images. We first estimate the motion field (INF) between any two consecutive t-MRI frames by a bi-directional generative diffeomorphic registration neural network. Using this result, we then estimate the Lagrangian motion field between the reference frame and any other frame through a differentiable composition layer. By utilizing temporal information to perform reasonable estimations on spatio-temporal motion fields, this novel method provides a useful solution for motion tracking and image registration in dynamic medical imaging. Our method has been validated on a representative clinical t-MRI dataset; the experimental results show that our method is superior to conventional motion tracking methods in terms of landmark tracking accuracy and inference efficiency.
ORStereo: Occlusion-Aware Recurrent Stereo Matching for 4K-Resolution Images
Mar 13, 2021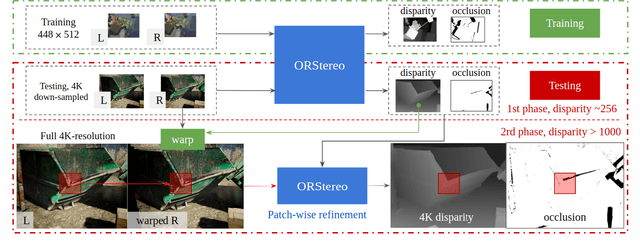

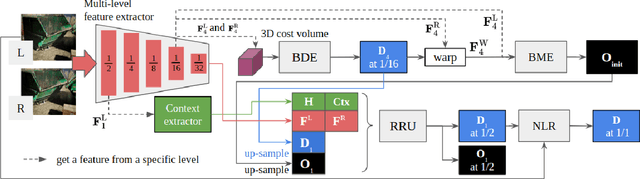
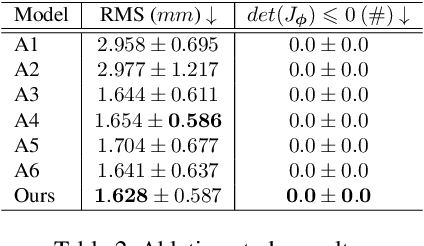
Stereo reconstruction models trained on small images do not generalize well to high-resolution data. Training a model on high-resolution image size faces difficulties of data availability and is often infeasible due to limited computing resources. In this work, we present the Occlusion-aware Recurrent binocular Stereo matching (ORStereo), which deals with these issues by only training on available low disparity range stereo images. ORStereo generalizes to unseen high-resolution images with large disparity ranges by formulating the task as residual updates and refinements of an initial prediction. ORStereo is trained on images with disparity ranges limited to 256 pixels, yet it can operate 4K-resolution input with over 1000 disparities using limited GPU memory. We test the model's capability on both synthetic and real-world high-resolution images. Experimental results demonstrate that ORStereo achieves comparable performance on 4K-resolution images compared to state-of-the-art methods trained on large disparity ranges. Compared to other methods that are only trained on low-resolution images, our method is 70% more accurate on 4K-resolution images.
Importance of Self-Consistency in Active Learning for Semantic Segmentation
Aug 04, 2020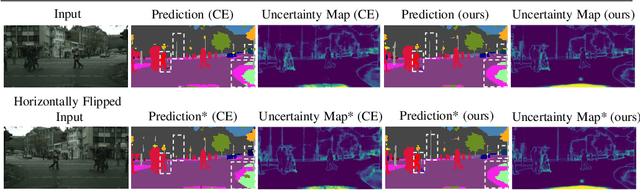
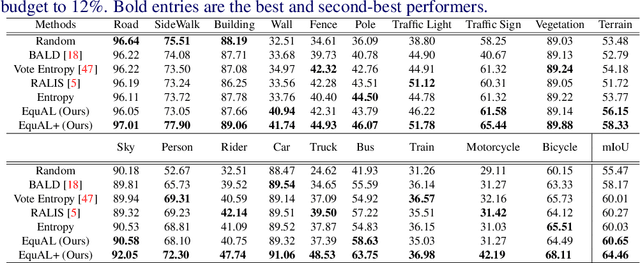
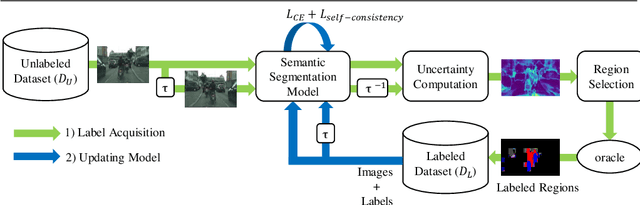
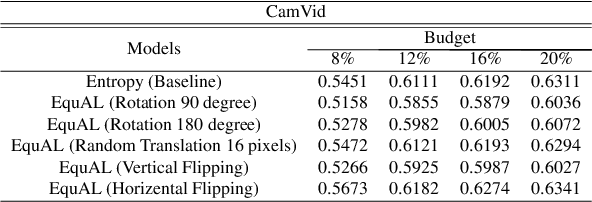
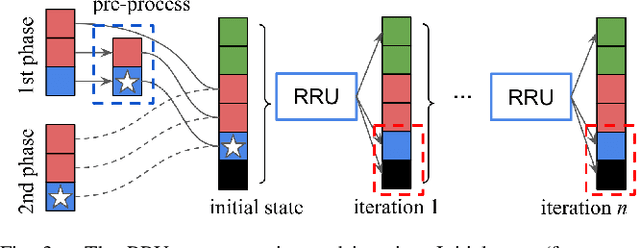
We address the task of active learning in the context of semantic segmentation and show that self-consistency can be a powerful source of self-supervision to greatly improve the performance of a data-driven model with access to only a small amount of labeled data. Self-consistency uses the simple observation that the results of semantic segmentation for a specific image should not change under transformations like horizontal flipping (i.e., the results should only be flipped). In other words, the output of a model should be consistent under equivariant transformations. The self-supervisory signal of self-consistency is particularly helpful during active learning since the model is prone to overfitting when there is only a small amount of labeled training data. In our proposed active learning framework, we iteratively extract small image patches that need to be labeled, by selecting image patches that have high uncertainty (high entropy) under equivariant transformations. We enforce pixel-wise self-consistency between the outputs of segmentation network for each image and its transformation (horizontally flipped) to utilize the rich self-supervisory information and reduce the uncertainty of the network. In this way, we are able to find the image patches over which the current model struggles the most to classify. By iteratively training over these difficult image patches, our experiments show that our active learning approach reaches $\sim96\%$ of the top performance of a model trained on all data, by using only $12\%$ of the total data on benchmark semantic segmentation datasets (e.g., CamVid and Cityscapes).
Automated Seizure Detection and Seizure Type Classification From Electroencephalography With a Graph Neural Network and Self-Supervised Pre-Training
Apr 16, 2021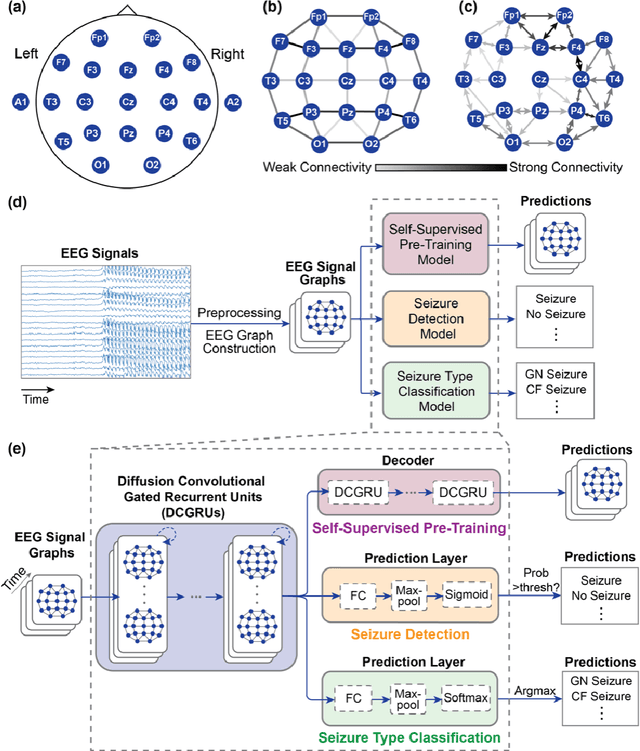
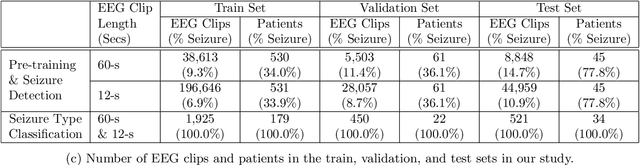
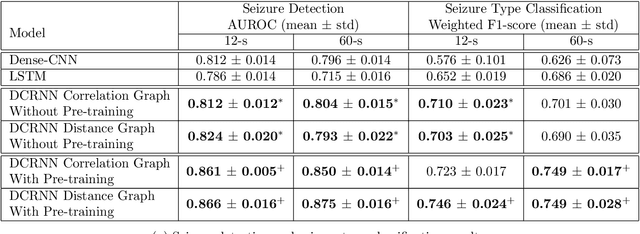
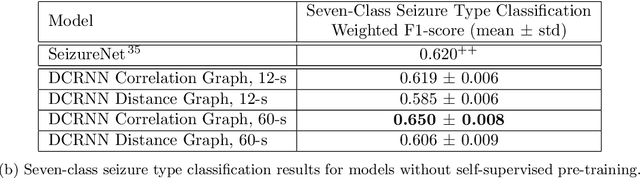
Automated seizure detection and classification from electroencephalography (EEG) can greatly improve the diagnosis and treatment of seizures. While prior studies mainly used convolutional neural networks (CNNs) that assume image-like structure in EEG signals or spectrograms, this modeling choice does not reflect the natural geometry of or connectivity between EEG electrodes. In this study, we propose modeling EEGs as graphs and present a graph neural network for automated seizure detection and classification. In addition, we leverage unlabeled EEG data using a self-supervised pre-training strategy. Our graph model with self-supervised pre-training significantly outperforms previous state-of-the-art CNN and Long Short-Term Memory (LSTM) models by 6.3 points (7.8%) in Area Under the Receiver Operating Characteristic curve (AUROC) for seizure detection and 6.3 points (9.2%) in weighted F1-score for seizure type classification. Ablation studies show that our graph-based modeling approach significantly outperforms existing CNN or LSTM models, and that self-supervision helps further improve the model performance. Moreover, we find that self-supervised pre-training substantially improves model performance on combined tonic seizures, a low-prevalence seizure type. Furthermore, our model interpretability analysis suggests that our model is better at identifying seizure regions compared to an existing CNN. In summary, our graph-based modeling approach integrates domain knowledge about EEG, sets a new state-of-the-art for seizure detection and classification on a large public dataset (5,499 EEG files), and provides better ability to identify seizure regions.
UnrealROX+: An Improved Tool for Acquiring Synthetic Data from Virtual 3D Environments
Apr 23, 2021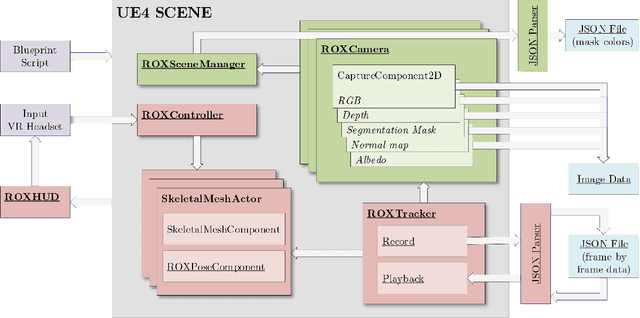



Synthetic data generation has become essential in last years for feeding data-driven algorithms, which surpassed traditional techniques performance in almost every computer vision problem. Gathering and labelling the amount of data needed for these data-hungry models in the real world may become unfeasible and error-prone, while synthetic data give us the possibility of generating huge amounts of data with pixel-perfect annotations. However, most synthetic datasets lack from enough realism in their rendered images. In that context UnrealROX generation tool was presented in 2019, allowing to generate highly realistic data, at high resolutions and framerates, with an efficient pipeline based on Unreal Engine, a cutting-edge videogame engine. UnrealROX enabled robotic vision researchers to generate realistic and visually plausible data with full ground truth for a wide variety of problems such as class and instance semantic segmentation, object detection, depth estimation, visual grasping, and navigation. Nevertheless, its workflow was very tied to generate image sequences from a robotic on-board camera, making hard to generate data for other purposes. In this work, we present UnrealROX+, an improved version of UnrealROX where its decoupled and easy-to-use data acquisition system allows to quickly design and generate data in a much more flexible and customizable way. Moreover, it is packaged as an Unreal plug-in, which makes it more comfortable to use with already existing Unreal projects, and it also includes new features such as generating albedo or a Python API for interacting with the virtual environment from Deep Learning frameworks.
Unsupervised Learning of Dense Visual Representations
Nov 11, 2020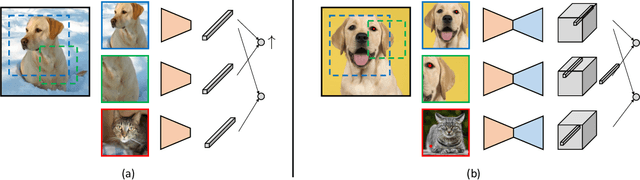


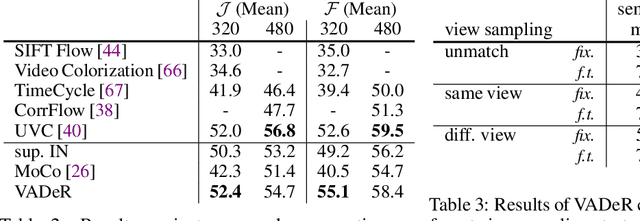
Contrastive self-supervised learning has emerged as a promising approach to unsupervised visual representation learning. In general, these methods learn global (image-level) representations that are invariant to different views (i.e., compositions of data augmentation) of the same image. However, many visual understanding tasks require dense (pixel-level) representations. In this paper, we propose View-Agnostic Dense Representation (VADeR) for unsupervised learning of dense representations. VADeR learns pixelwise representations by forcing local features to remain constant over different viewing conditions. Specifically, this is achieved through pixel-level contrastive learning: matching features (that is, features that describes the same location of the scene on different views) should be close in an embedding space, while non-matching features should be apart. VADeR provides a natural representation for dense prediction tasks and transfers well to downstream tasks. Our method outperforms ImageNet supervised pretraining (and strong unsupervised baselines) in multiple dense prediction tasks.
Embedded Self-Distillation in Compact Multi-Branch Ensemble Network for Remote Sensing Scene Classification
Apr 01, 2021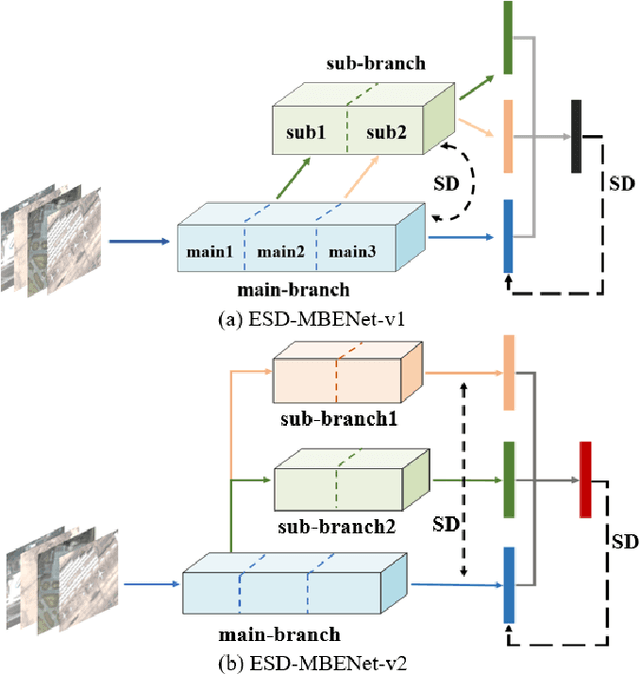
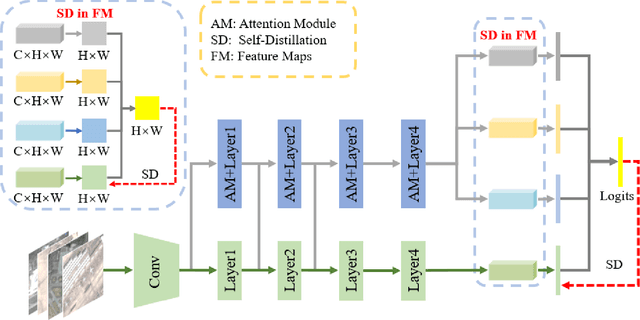
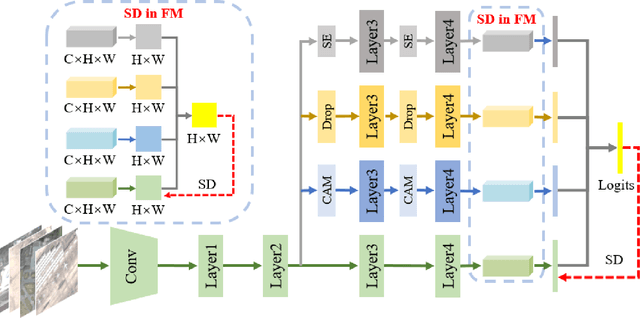
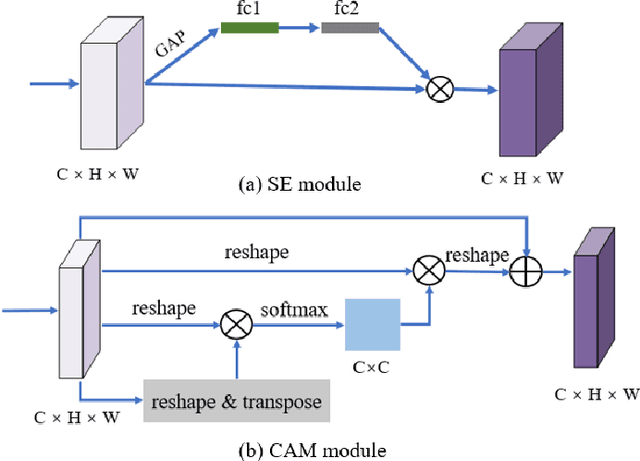
Remote sensing (RS) image scene classification task faces many challenges due to the interference from different characteristics of different geographical elements. To solve this problem, we propose a multi-branch ensemble network to enhance the feature representation ability by fusing features in final output logits and intermediate feature maps. However, simply adding branches will increase the complexity of models and decline the inference efficiency. On this issue, we embed self-distillation (SD) method to transfer knowledge from ensemble network to main-branch in it. Through optimizing with SD, main-branch will have close performance as ensemble network. During inference, we can cut other branches to simplify the whole model. In this paper, we first design compact multi-branch ensemble network, which can be trained in an end-to-end manner. Then, we insert SD method on output logits and feature maps. Compared to previous methods, our proposed architecture (ESD-MBENet) performs strongly on classification accuracy with compact design. Extensive experiments are applied on three benchmark RS datasets AID, NWPU-RESISC45 and UC-Merced with three classic baseline models, VGG16, ResNet50 and DenseNet121. Results prove that our proposed ESD-MBENet can achieve better accuracy than previous state-of-the-art (SOTA) complex models. Moreover, abundant visualization analysis make our method more convincing and interpretable.
Learning from Subjective Ratings Using Auto-Decoded Deep Latent Embeddings
Apr 16, 2021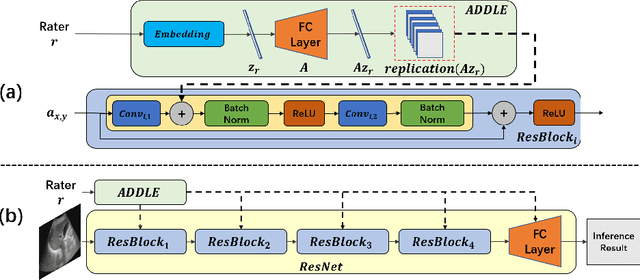
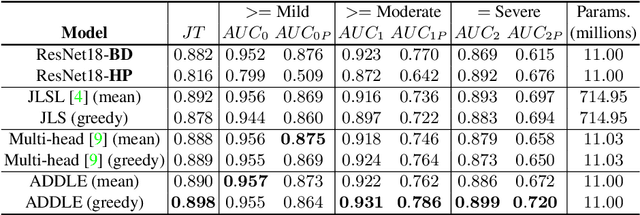
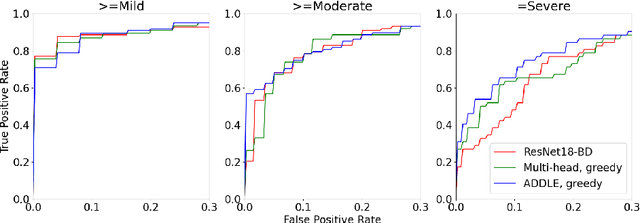
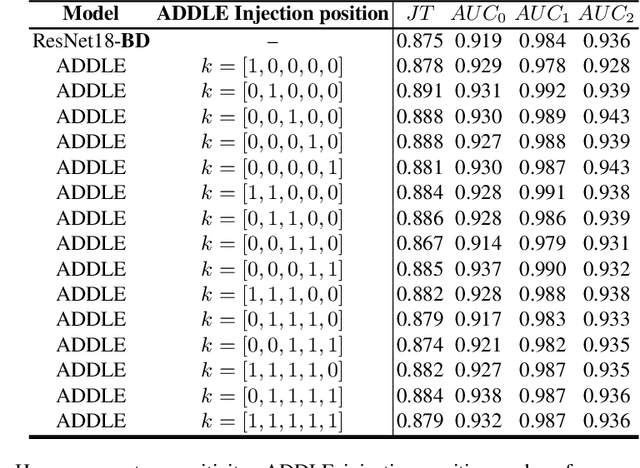
Depending on the application, radiological diagnoses can be associated with high inter- and intra-rater variabilities. Most computer-aided diagnosis (CAD) solutions treat such data as incontrovertible, exposing learning algorithms to considerable and possibly contradictory label noise and biases. Thus, managing subjectivity in labels is a fundamental problem in medical imaging analysis. To address this challenge, we introduce auto-decoded deep latent embeddings (ADDLE), which explicitly models the tendencies of each rater using an auto-decoder framework. After a simple linear transformation, the latent variables can be injected into any backbone at any and multiple points, allowing the model to account for rater-specific effects on the diagnosis. Importantly, ADDLE does not expect multiple raters per image in training, meaning it can readily learn from data mined from hospital archives. Moreover, the complexity of training ADDLE does not increase as more raters are added. During inference each rater can be simulated and a 'mean' or 'greedy' virtual rating can be produced. We test ADDLE on the problem of liver steatosis diagnosis from 2D ultrasound (US) by collecting 46 084 studies along with clinical US diagnoses originating from 65 different raters. We evaluated diagnostic performance using a separate dataset with gold-standard biopsy diagnoses. ADDLE can improve the partial areas under the curve (AUCs) for diagnosing severe steatosis by 10.5% over standard classifiers while outperforming other annotator-noise approaches, including those requiring 65 times the parameters.