 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Novel Evaluation Metrics for Seam Carving based Image Retargeting
Sep 22, 2017
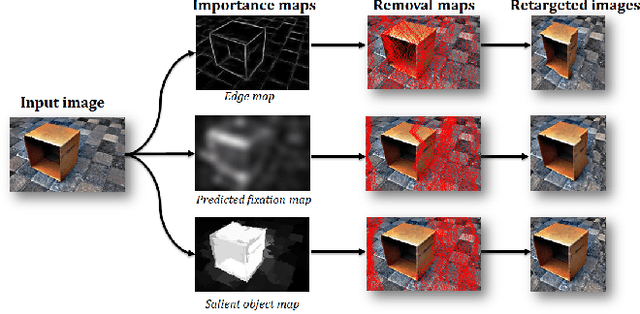
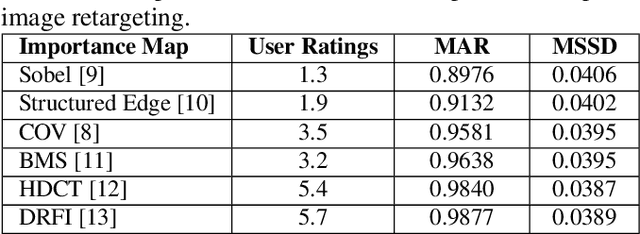
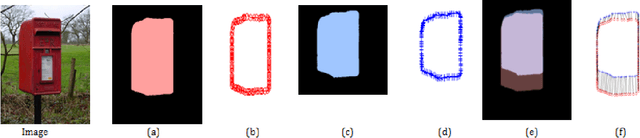
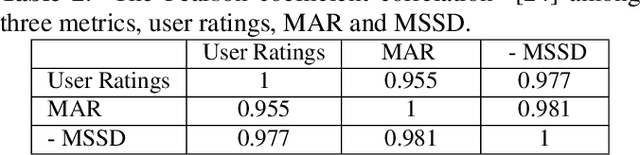
Image retargeting effectively resizes images by preserving the recognizability of important image regions. Most of retargeting methods rely on good importance maps as a cue to retain or remove certain regions in the input image. In addition, the traditional evaluation exhaustively depends on user ratings. There is a legitimate need for a methodological approach for evaluating retargeted results. Therefore, in this paper, we conduct a study and analysis on the prominent method in image retargeting, Seam Carving. First, we introduce two novel evaluation metrics which can be considered as the proxy of user ratings. Second, we exploit salient object dataset as a benchmark for this task. We then investigate different types of importance maps for this particular problem. The experiments show that humans in general agree with the evaluation metrics on the retargeted results and some importance map methods are consistently more favorable than others.
Self-supervised Pretraining of Visual Features in the Wild
Mar 02, 2021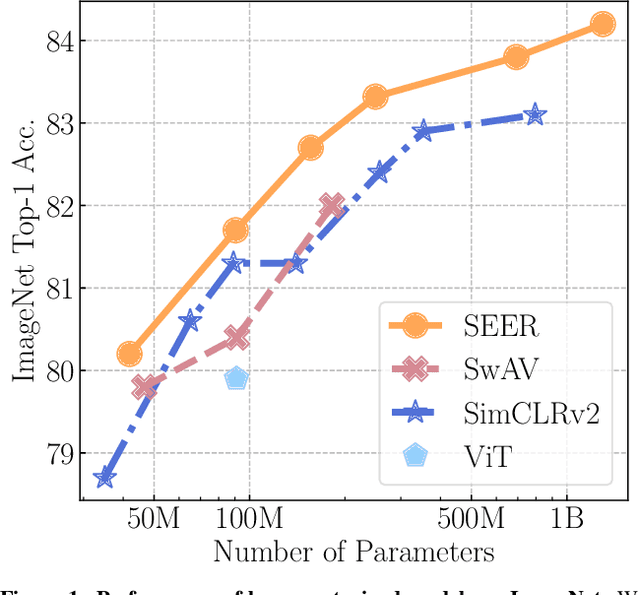
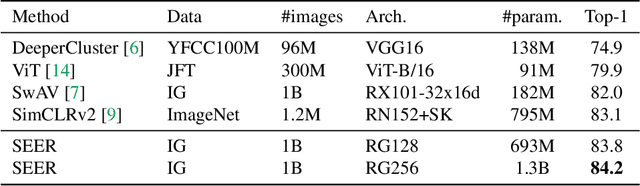
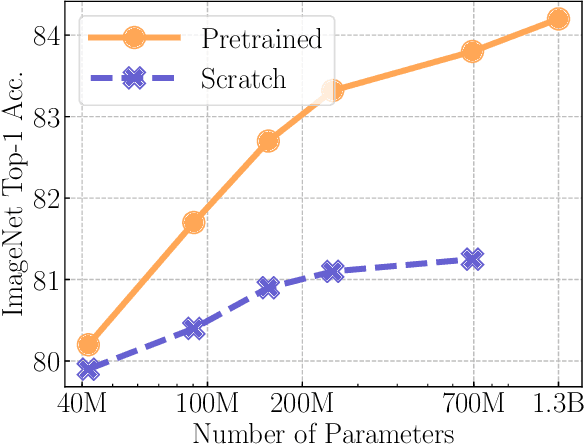
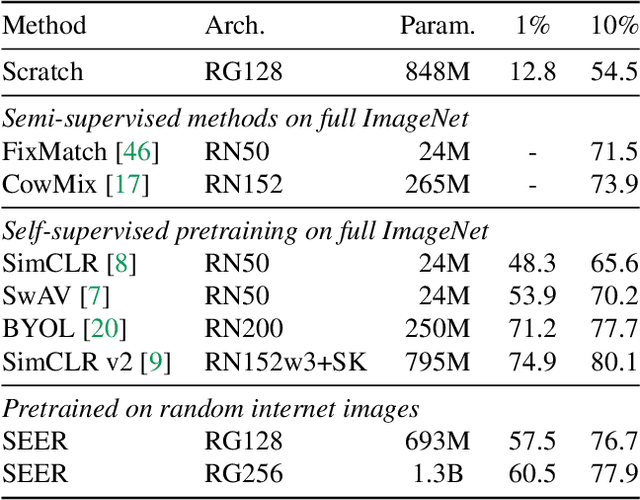
Recently, self-supervised learning methods like MoCo, SimCLR, BYOL and SwAV have reduced the gap with supervised methods. These results have been achieved in a control environment, that is the highly curated ImageNet dataset. However, the premise of self-supervised learning is that it can learn from any random image and from any unbounded dataset. In this work, we explore if self-supervision lives to its expectation by training large models on random, uncurated images with no supervision. Our final SElf-supERvised (SEER) model, a RegNetY with 1.3B parameters trained on 1B random images with 512 GPUs achieves 84.2% top-1 accuracy, surpassing the best self-supervised pretrained model by 1% and confirming that self-supervised learning works in a real world setting. Interestingly, we also observe that self-supervised models are good few-shot learners achieving 77.9% top-1 with access to only 10% of ImageNet. Code: https://github.com/facebookresearch/vissl
Medical Imaging and Machine Learning
Mar 02, 2021

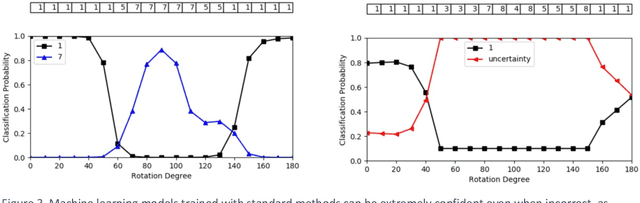
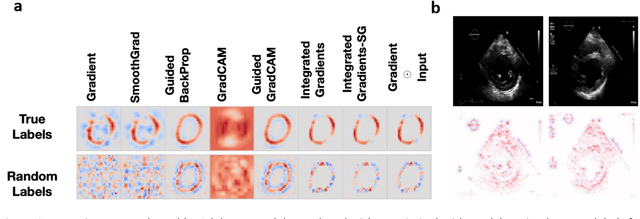
Advances in computing power, deep learning architectures, and expert labelled datasets have spurred the development of medical imaging artificial intelligence systems that rival clinical experts in a variety of scenarios. The National Institutes of Health in 2018 identified key focus areas for the future of artificial intelligence in medical imaging, creating a foundational roadmap for research in image acquisition, algorithms, data standardization, and translatable clinical decision support systems. Among the key issues raised in the report: data availability, need for novel computing architectures and explainable AI algorithms, are still relevant despite the tremendous progress made over the past few years alone. Furthermore, translational goals of data sharing, validation of performance for regulatory approval, generalizability and mitigation of unintended bias must be accounted for early in the development process. In this perspective paper we explore challenges unique to high dimensional clinical imaging data, in addition to highlighting some of the technical and ethical considerations in developing high-dimensional, multi-modality, machine learning systems for clinical decision support.
Autonomous Flight through Cluttered Outdoor Environments Using a Memoryless Planner
Mar 22, 2021
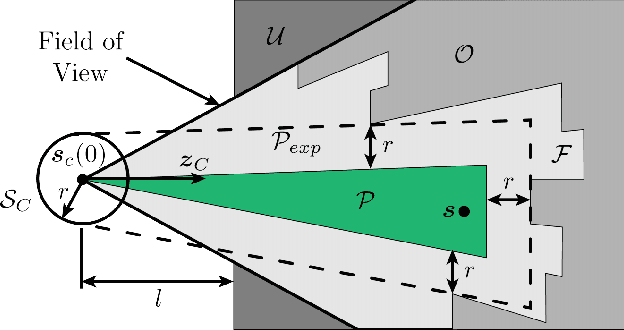
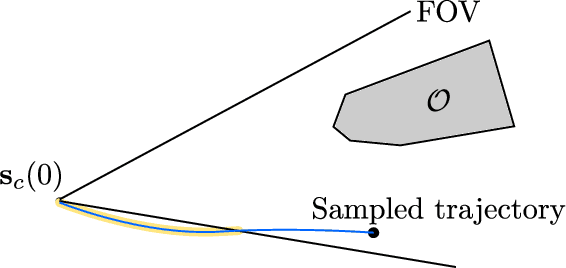
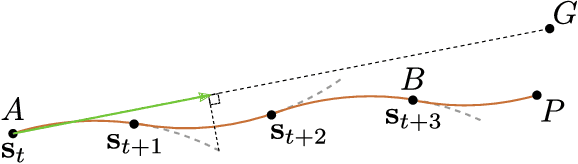
This paper introduces a collision avoidance system for navigating a multicopter in cluttered outdoor environments based on the recent memory-less motion planner, rectangular pyramid partitioning using integrated depth sensors (RAPPIDS). The RAPPIDS motion planner generates collision-free flight trajectories at high speed with low computational cost using only the latest depth image. In this work we extend it to improve the performance of the planner by taking the following issues into account. (a) Changes in the dynamic characteristics of the multicopter that occur during flight, such as changes in motor input/output characteristics due to battery voltage drop. (b) The noise of the flight sensor, which can cause unwanted control input components. (c) Planner utility function which may not be suitable for the cluttered environment. Therefore, in this paper we introduce solutions to each of the above problems and propose a system for the successful operation of the RAPPIDS planner in an outdoor cluttered flight environment. At the end of the paper, we validate the proposed method's effectiveness by presenting the flight experiment results in a forest environment. A video can be found at www.youtube.com/channel/UCK-gErmvZlBODN5gQpNcpsg
iCurb: Imitation Learning-based Detection of Road Curbs using Aerial Images for Autonomous Driving
Mar 31, 2021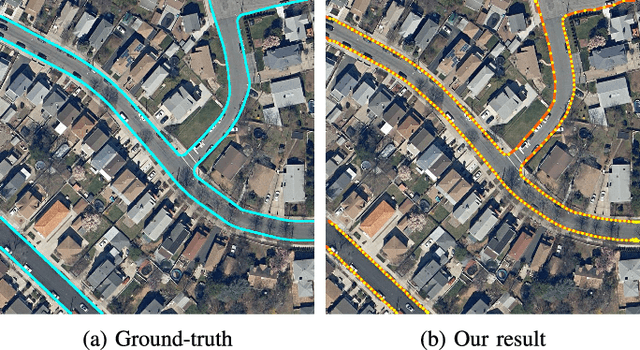
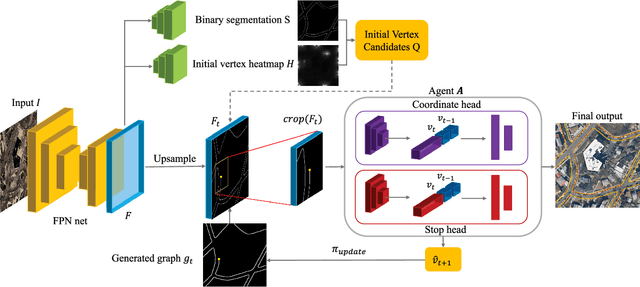
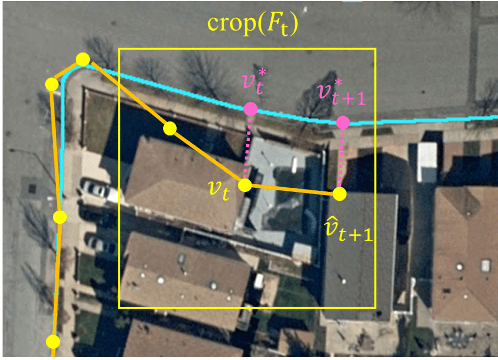
Detection of road curbs is an essential capability for autonomous driving. It can be used for autonomous vehicles to determine drivable areas on roads. Usually, road curbs are detected on-line using vehicle-mounted sensors, such as video cameras and 3-D Lidars. However, on-line detection using video cameras may suffer from challenging illumination conditions, and Lidar-based approaches may be difficult to detect far-away road curbs due to the sparsity issue of point clouds. In recent years, aerial images are becoming more and more worldwide available. We find that the visual appearances between road areas and off-road areas are usually different in aerial images, so we propose a novel solution to detect road curbs off-line using aerial images. The input to our method is an aerial image, and the output is directly a graph (i.e., vertices and edges) representing road curbs. To this end, we formulate the problem as an imitation learning problem, and design a novel network and an innovative training strategy to train an agent to iteratively find the road-curb graph. The experimental results on a public dataset confirm the effectiveness and superiority of our method. This work is accompanied with a demonstration video and a supplementary document at https://tonyxuqaq.github.io/iCurb/.
Understanding Image Virality
May 26, 2015
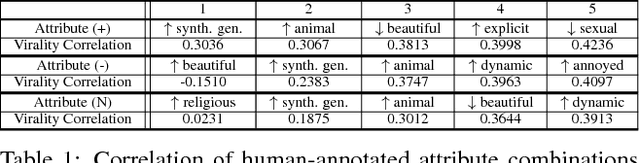
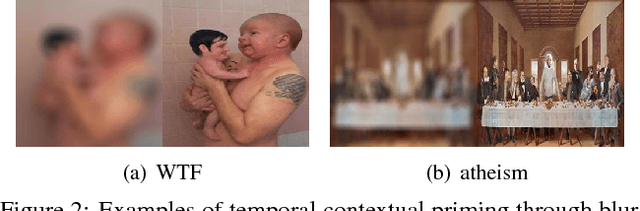
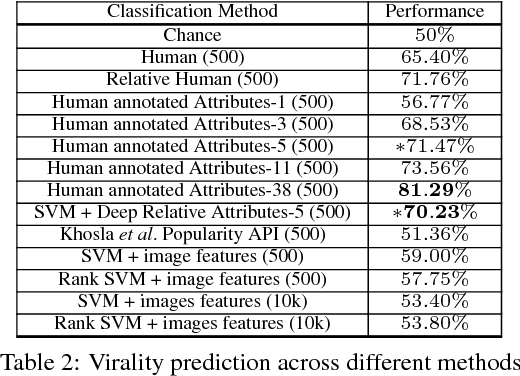
Virality of online content on social networking websites is an important but esoteric phenomenon often studied in fields like marketing, psychology and data mining. In this paper we study viral images from a computer vision perspective. We introduce three new image datasets from Reddit, and define a virality score using Reddit metadata. We train classifiers with state-of-the-art image features to predict virality of individual images, relative virality in pairs of images, and the dominant topic of a viral image. We also compare machine performance to human performance on these tasks. We find that computers perform poorly with low level features, and high level information is critical for predicting virality. We encode semantic information through relative attributes. We identify the 5 key visual attributes that correlate with virality. We create an attribute-based characterization of images that can predict relative virality with 68.10% accuracy (SVM+Deep Relative Attributes) -- better than humans at 60.12%. Finally, we study how human prediction of image virality varies with different `contexts' in which the images are viewed, such as the influence of neighbouring images, images recently viewed, as well as the image title or caption. This work is a first step in understanding the complex but important phenomenon of image virality. Our datasets and annotations will be made publicly available.
Iteratively reweighted penalty alternating minimization methods with continuation for image deblurring
Feb 09, 2019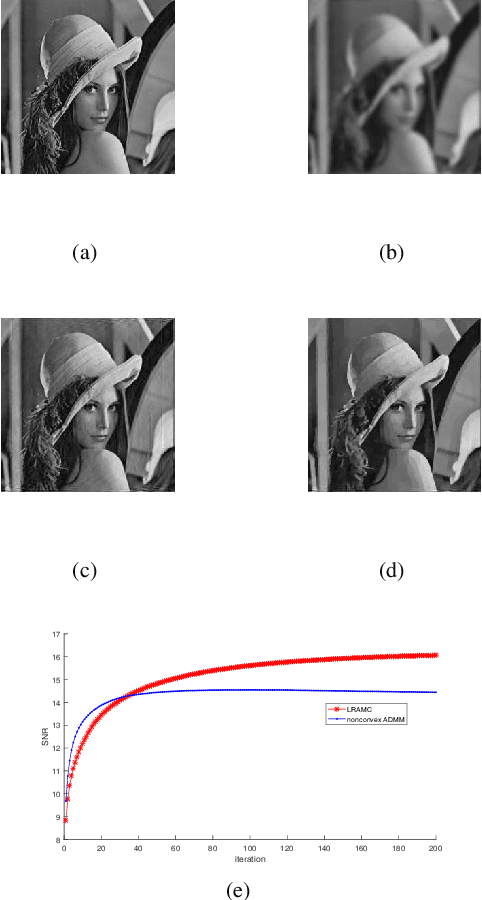
In this paper, we consider a class of nonconvex problems with linear constraints appearing frequently in the area of image processing. We solve this problem by the penalty method and propose the iteratively reweighted alternating minimization algorithm. To speed up the algorithm, we also apply the continuation strategy to the penalty parameter. A convergence result is proved for the algorithm. Compared with the nonconvex ADMM, the proposed algorithm enjoys both theoretical and computational advantages like weaker convergence requirements and faster speed. Numerical results demonstrate the efficiency of the proposed algorithm.
Test Automation with Grad-CAM Heatmaps -- A Future Pipe Segment in MLOps for Vision AI?
Mar 02, 2021



Machine Learning (ML) is a fundamental part of modern perception systems. In the last decade, the performance of computer vision using trained deep neural networks has outperformed previous approaches based on careful feature engineering. However, the opaqueness of large ML models is a substantial impediment for critical applications such as in the automotive context. As a remedy, Gradient-weighted Class Activation Mapping (Grad-CAM) has been proposed to provide visual explanations of model internals. In this paper, we demonstrate how Grad-CAM heatmaps can be used to increase the explainability of an image recognition model trained for a pedestrian underpass. We argue how the heatmaps support compliance to the EU's seven key requirements for Trustworthy AI. Finally, we propose adding automated heatmap analysis as a pipe segment in an MLOps pipeline. We believe that such a building block can be used to automatically detect if a trained ML-model is activated based on invalid pixels in test images, suggesting biased models.
Automatic Breast Ultrasound Image Segmentation: A Survey
Jan 09, 2018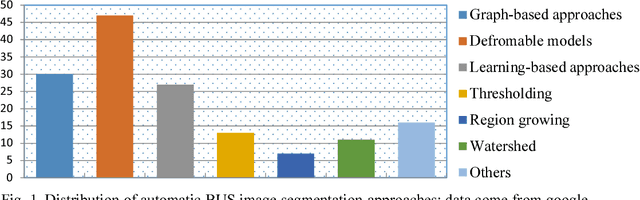
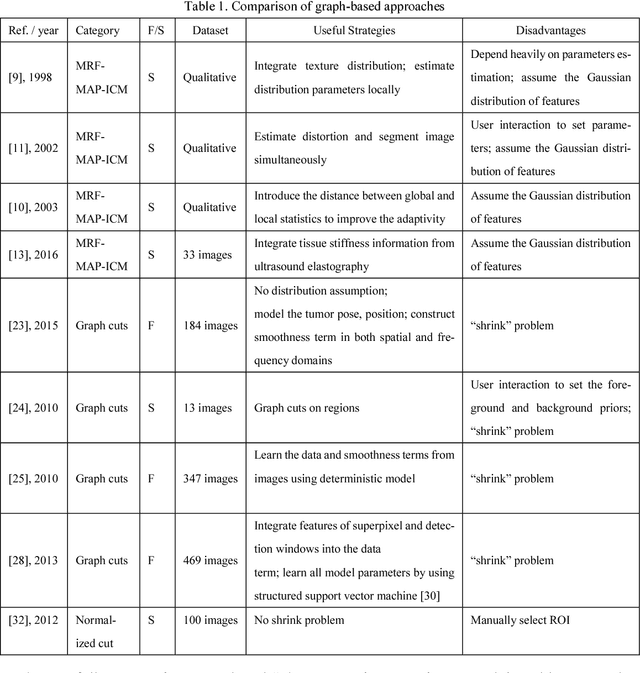
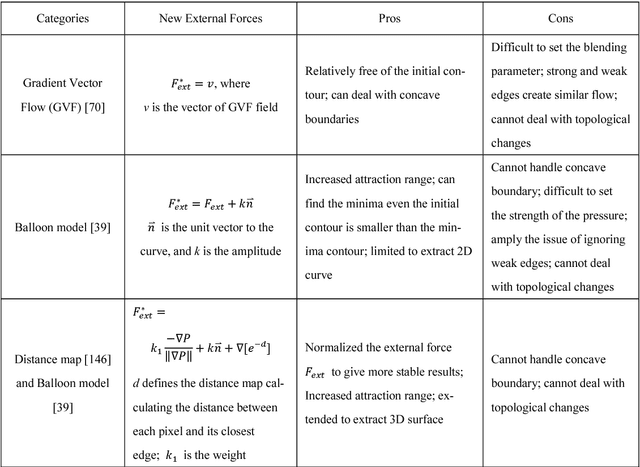
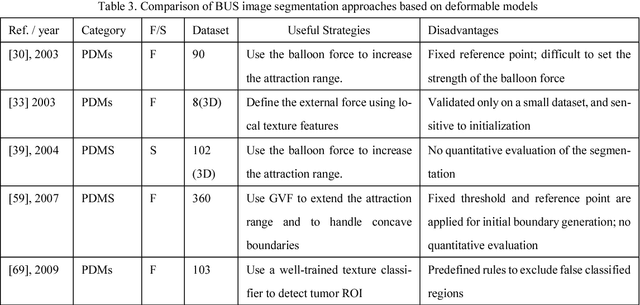
Breast cancer is one of the leading causes of cancer death among women worldwide. In clinical routine, automatic breast ultrasound (BUS) image segmentation is very challenging and essential for cancer diagnosis and treatment planning. Many BUS segmentation approaches have been studied in the last two decades, and have been proved to be effective on private datasets. Currently, the advancement of BUS image segmentation seems to meet its bottleneck. The improvement of the performance is increasingly challenging, and only few new approaches were published in the last several years. It is the time to look at the field by reviewing previous approaches comprehensively and to investigate the future directions. In this paper, we study the basic ideas, theories, pros and cons of the approaches, group them into categories, and extensively review each category in depth by discussing the principles, application issues, and advantages/disadvantages.
A Hierarchical Approach for Generating Descriptive Image Paragraphs
Apr 10, 2017
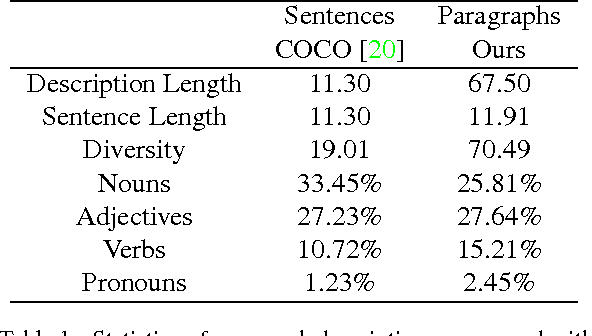
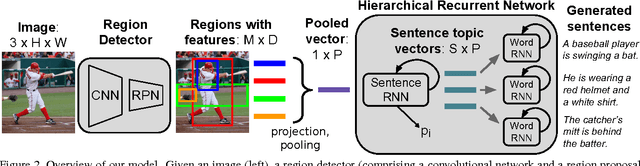
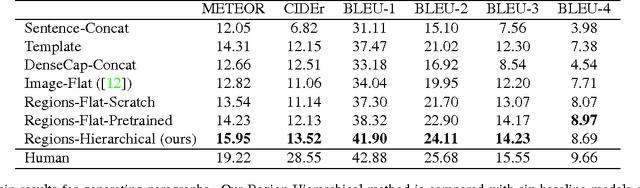
Recent progress on image captioning has made it possible to generate novel sentences describing images in natural language, but compressing an image into a single sentence can describe visual content in only coarse detail. While one new captioning approach, dense captioning, can potentially describe images in finer levels of detail by captioning many regions within an image, it in turn is unable to produce a coherent story for an image. In this paper we overcome these limitations by generating entire paragraphs for describing images, which can tell detailed, unified stories. We develop a model that decomposes both images and paragraphs into their constituent parts, detecting semantic regions in images and using a hierarchical recurrent neural network to reason about language. Linguistic analysis confirms the complexity of the paragraph generation task, and thorough experiments on a new dataset of image and paragraph pairs demonstrate the effectiveness of our approach.