 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ZM-Net: Real-time Zero-shot Image Manipulation Network
Mar 22, 2017

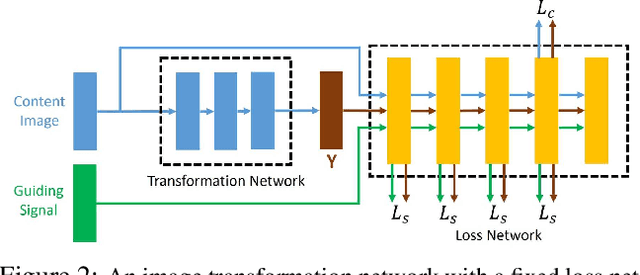


Many problems in image processing and computer vision (e.g. colorization, style transfer) can be posed as 'manipulating' an input image into a corresponding output image given a user-specified guiding signal. A holy-grail solution towards generic image manipulation should be able to efficiently alter an input image with any personalized signals (even signals unseen during training), such as diverse paintings and arbitrary descriptive attributes. However, existing methods are either inefficient to simultaneously process multiple signals (let alone generalize to unseen signals), or unable to handle signals from other modalities. In this paper, we make the first attempt to address the zero-shot image manipulation task. We cast this problem as manipulating an input image according to a parametric model whose key parameters can be conditionally generated from any guiding signal (even unseen ones). To this end, we propose the Zero-shot Manipulation Net (ZM-Net), a fully-differentiable architecture that jointly optimizes an image-transformation network (TNet) and a parameter network (PNet). The PNet learns to generate key transformation parameters for the TNet given any guiding signal while the TNet performs fast zero-shot image manipulation according to both signal-dependent parameters from the PNet and signal-invariant parameters from the TNet itself. Extensive experiments show that our ZM-Net can perform high-quality image manipulation conditioned on different forms of guiding signals (e.g. style images and attributes) in real-time (tens of milliseconds per image) even for unseen signals. Moreover, a large-scale style dataset with over 20,000 style images is also constructed to promote further research.
Impact of ultrasound image reconstruction method on breast lesion classification with neural transfer learning
Apr 06, 2018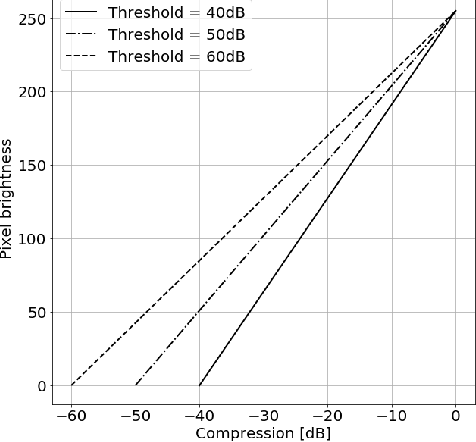
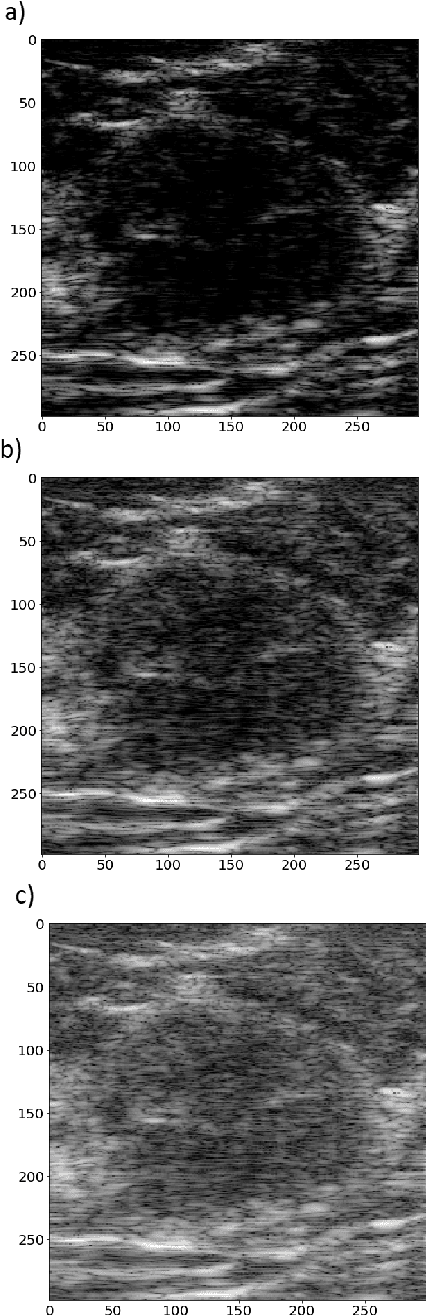
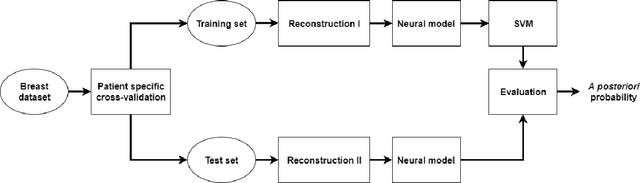
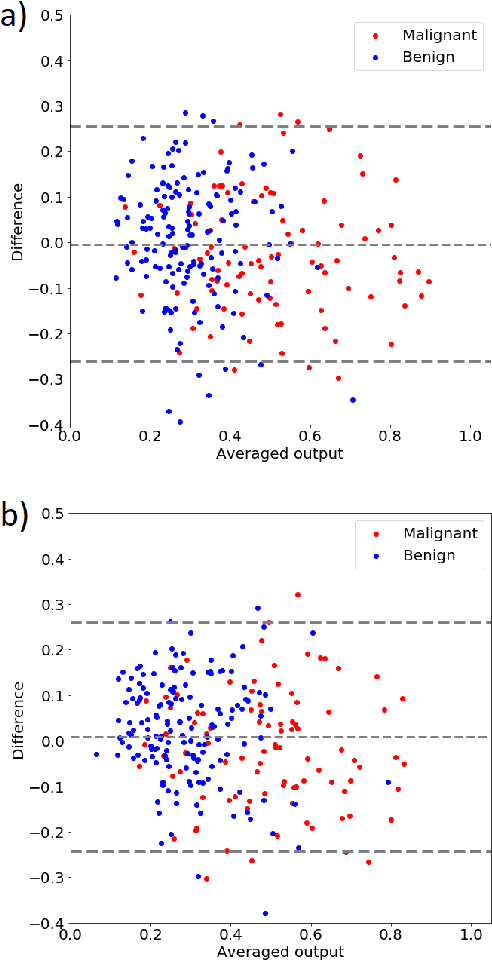
Deep learning algorithms, especially convolutional neural networks, have become a methodology of choice in medical image analysis. However, recent studies in computer vision show that even a small modification of input image intensities may cause a deep learning model to classify the image differently. In medical imaging, the distribution of image intensities is related to applied image reconstruction algorithm. In this paper we investigate the impact of ultrasound image reconstruction method on breast lesion classification with neural transfer learning. Due to high dynamic range raw ultrasonic signals are commonly compressed in order to reconstruct B-mode images. Based on raw data acquired from breast lesions, we reconstruct B-mode images using different compression levels. Next, transfer learning is applied for classification. Differently reconstructed images are employed for training and evaluation. We show that the modification of the reconstruction algorithm leads to decrease of classification performance. As a remedy, we propose a method of data augmentation. We show that the augmentation of the training set with differently reconstructed B-mode images leads to a more robust and efficient classification. Our study suggests that it is important to take into account image reconstruction algorithms implemented in medical scanners during development of computer aided diagnosis systems.
Improved Reinforcement Learning through Imitation Learning Pretraining Towards Image-based Autonomous Driving
Jul 16, 2019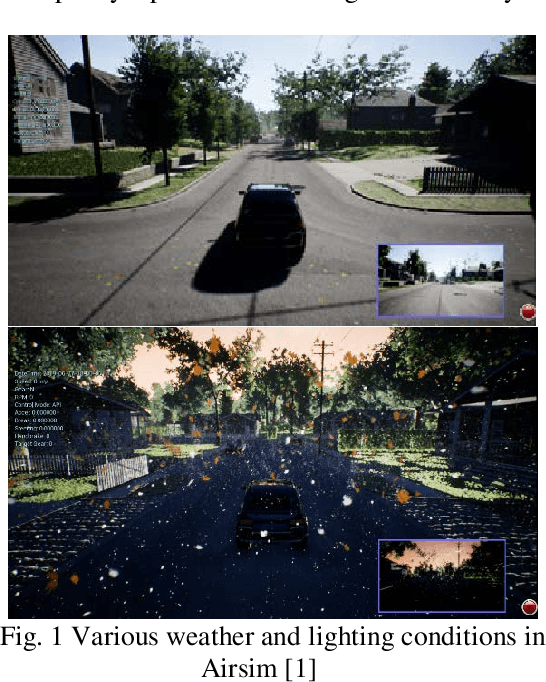
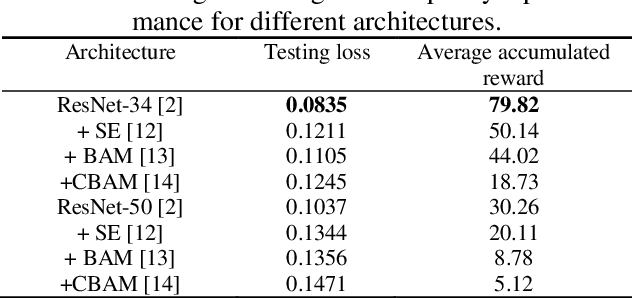
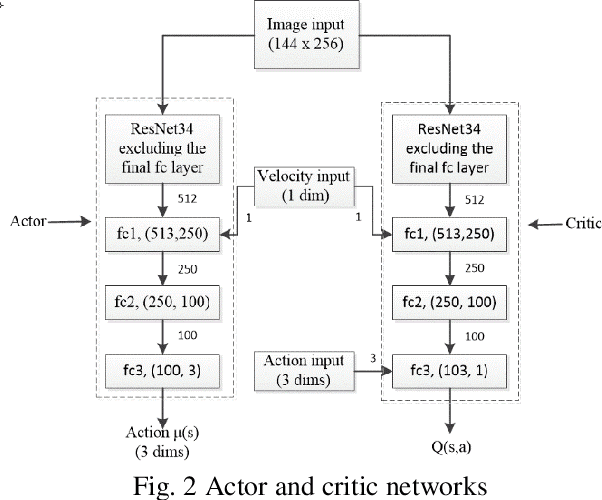

We present a training pipeline for the autonomous driving task given the current camera image and vehicle speed as the input to produce the throttle, brake, and steering control output. The simulator Airsim's convenient weather and lighting API provides a sufficient diversity during training which can be very helpful to increase the trained policy's robustness. In order to not limit the possible policy's performance, we use a continuous and deterministic control policy setting. We utilize ResNet-34 as our actor and critic networks with some slight changes in the fully connected layers. Considering human's mastery of this task and the high-complexity nature of this task, we first use imitation learning to mimic the given human policy and leverage the trained policy and its weights to the reinforcement learning phase for which we use DDPG. This combination shows a considerable performance boost comparing to both pure imitation learning and pure DDPG for the autonomous driving task.
Scalable Visual Attribute Extraction through Hidden Layers of a Residual ConvNet
Mar 31, 2021
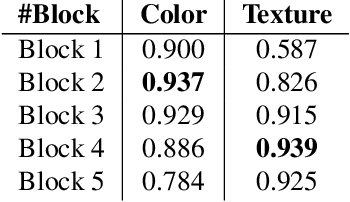

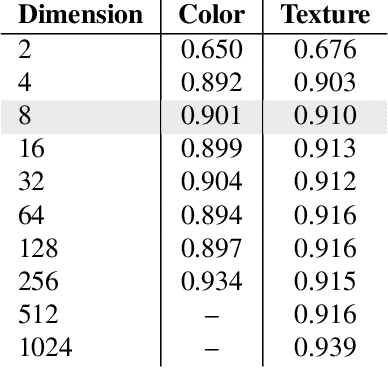
Visual attributes play an essential role in real applications based on image retrieval. For instance, the extraction of attributes from images allows an eCommerce search engine to produce retrieval results with higher precision. The traditional manner to build an attribute extractor is by training a convnet-based classifier with a fixed number of classes. However, this approach does not scale for real applications where the number of attributes changes frequently. Therefore in this work, we propose an approach for extracting visual attributes from images, leveraging the learned capability of the hidden layers of a general convolutional network to discriminate among different visual features. We run experiments with a resnet-50 trained on Imagenet, on which we evaluate the output of its different blocks to discriminate between colors and textures. Our results show that the second block of the resnet is appropriate for discriminating colors, while the fourth block can be used for textures. In both cases, the achieved accuracy of attribute classification is superior to 93%. We also show that the proposed embeddings form local structures in the underlying feature space, which makes it possible to apply reduction techniques like UMAP, maintaining high accuracy and widely reducing the size of the feature space.
Learning from Large-scale Noisy Web Data with Ubiquitous Reweighting for Image Classification
Nov 02, 2018
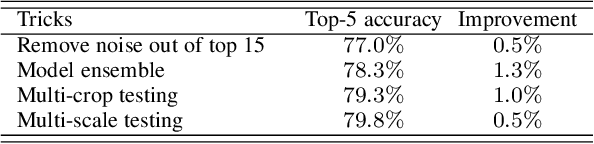


Many advances of deep learning techniques originate from the efforts of addressing the image classification task on large-scale datasets. However, the construction of such clean datasets is costly and time-consuming since the Internet is overwhelmed by noisy images with inadequate and inaccurate tags. In this paper, we propose a Ubiquitous Reweighting Network (URNet) that learns an image classification model from large-scale noisy data. By observing the web data, we find that there are five key challenges, \ie, imbalanced class sizes, high intra-classes diversity and inter-class similarity, imprecise instances, insufficient representative instances, and ambiguous class labels. To alleviate these challenges, we assume that every training instance has the potential to contribute positively by alleviating the data bias and noise via reweighting the influence of each instance according to different class sizes, large instance clusters, its confidence, small instance bags and the labels. In this manner, the influence of bias and noise in the web data can be gradually alleviated, leading to the steadily improving performance of URNet. Experimental results in the WebVision 2018 challenge with 16 million noisy training images from 5000 classes show that our approach outperforms state-of-the-art models and ranks the first place in the image classification task.
SuctionNet-1Billion: A Large-Scale Benchmark for Suction Grasping
Mar 23, 2021



Suction is an important solution for the longstanding robotic grasping problem. Compared with other kinds of grasping, suction grasping is easier to represent and often more reliable in practice. Though preferred in many scenarios, it is not fully investigated and lacks sufficient training data and evaluation benchmarks. To address that, firstly, we propose a new physical model to analytically evaluate seal formation and wrench resistance of a suction grasping, which are two key aspects of grasp success. Secondly, a two-step methodology is adopted to generate annotations on a large-scale dataset collected in real-world cluttered scenarios. Thirdly, a standard online evaluation system is proposed to evaluate suction poses in continuous operation space, which can benchmark different algorithms fairly without the need of exhaustive labeling. Real-robot experiments are conducted to show that our annotations align well with real world. Meanwhile, we propose a method to predict numerous suction poses from an RGB-D image of a cluttered scene and demonstrate our superiority against several previous methods. Result analyses are further provided to help readers better understand the challenges in this area. Data and source code are publicly available at www.graspnet.net.
Benefiting Deep Latent Variable Models via Learning the Prior and Removing Latent Regularization
Jul 16, 2020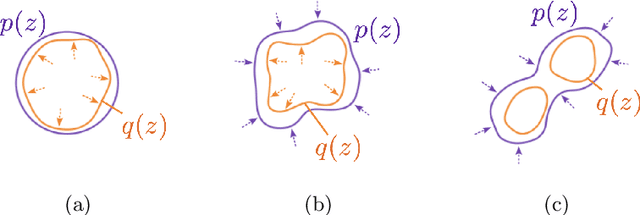
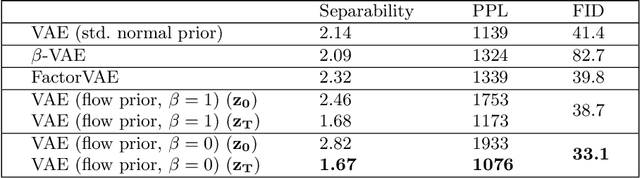
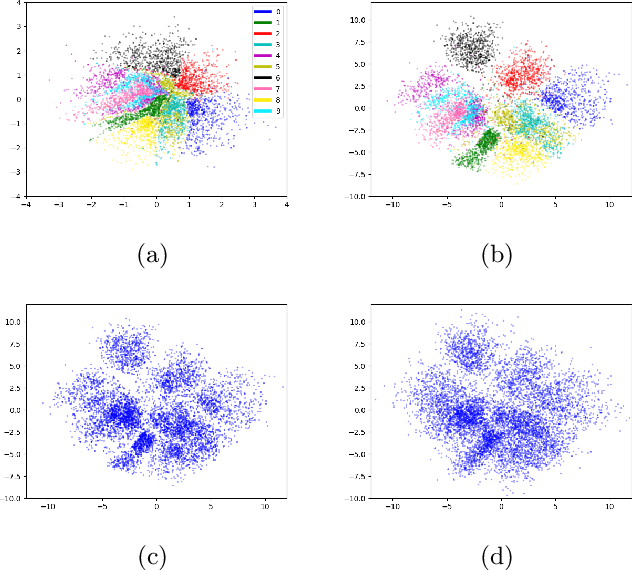

There exist many forms of deep latent variable models, such as the variational autoencoder and adversarial autoencoder. Regardless of the specific class of model, there exists an implicit consensus that the latent distribution should be regularized towards the prior, even in the case where the prior distribution is learned. Upon investigating the effect of latent regularization on image generation our results indicate that in the case where a sufficiently expressive prior is learned, latent regularization is not necessary and may in fact be harmful insofar as image quality is concerned. We additionally investigate the benefit of learned priors on two common problems in computer vision: latent variable disentanglement, and diversity in image-to-image translation.
C2CL: Contact to Contactless Fingerprint Matching
Apr 08, 2021
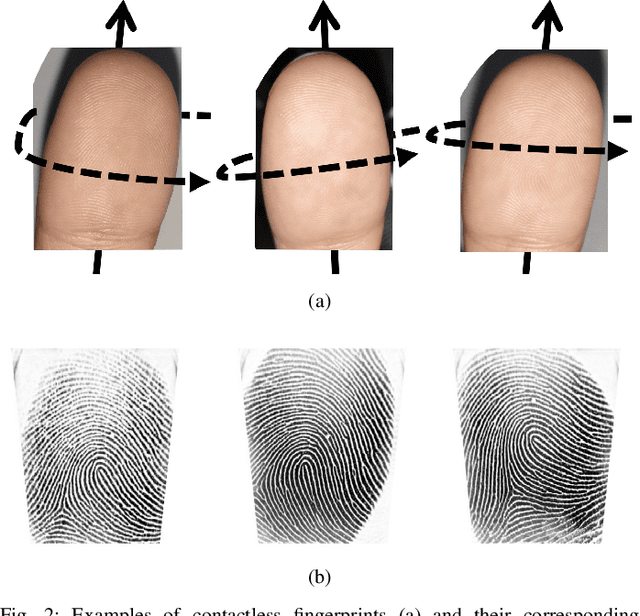
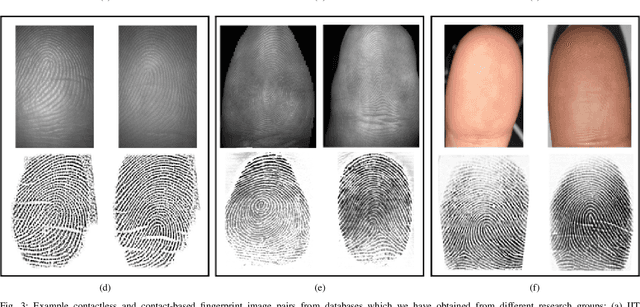
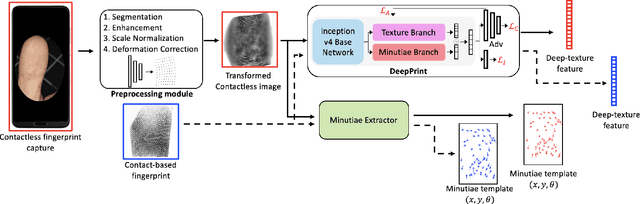
Matching contactless fingerprints or finger photos to contact-based fingerprint impressions has received increased attention in the wake of COVID-19 due to the superior hygiene of the contactless acquisition and the widespread availability of low cost mobile phones capable of capturing photos of fingerprints with sufficient resolution for verification purposes. This paper presents an end-to-end automated system, called C2CL, comprised of a mobile finger photo capture app, preprocessing, and matching algorithms to handle the challenges inhibiting previous cross-matching methods; namely i) low ridge-valley contrast of contactless fingerprints, ii) varying roll, pitch, yaw, and distance of the finger to the camera, iii) non-linear distortion of contact-based fingerprints, and vi) different image qualities of smartphone cameras. Our preprocessing algorithm segments, enhances, scales, and unwarps contactless fingerprints, while our matching algorithm extracts both minutiae and texture representations. A sequestered dataset of 9,888 contactless 2D fingerprints and corresponding contact-based fingerprints from 206 subjects (2 thumbs and 2 index fingers for each subject) acquired using our mobile capture app is used to evaluate the cross-database performance of our proposed algorithm. Furthermore, additional experimental results on 3 publicly available datasets demonstrate, for the first time, contact to contactless fingerprint matching accuracy that is comparable to existing contact to contact fingerprint matching systems (TAR in the range of 96.67% to 98.15% at FAR=0.01%).
An Automatic System to Monitor the Physical Distance and Face Mask Wearing of Construction Workers in COVID-19 Pandemic
Jan 30, 2021

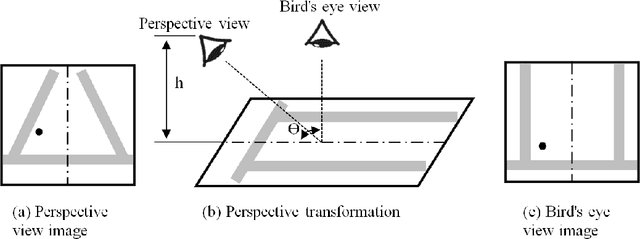
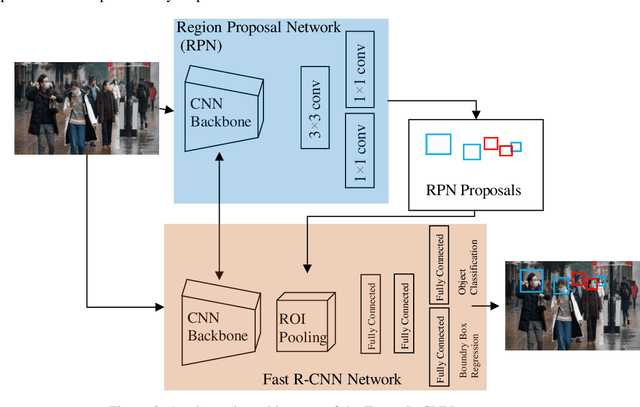
The COVID-19 pandemic has caused many shutdowns in different industries around the world. Sectors such as infrastructure construction and maintenance projects have not been suspended due to their significant effect on people's routine life. In such projects, workers work close together that makes a high risk of infection. The World Health Organization recommends wearing a face mask and practicing physical distancing to mitigate the virus's spread. This paper developed a computer vision system to automatically detect the violation of face mask wearing and physical distancing among construction workers to assure their safety on infrastructure projects during the pandemic. For the face mask detection, the paper collected and annotated 1,000 images, including different types of face mask wearing, and added them to a pre-existing face mask dataset to develop a dataset of 1,853 images. Then trained and tested multiple Tensorflow state-of-the-art object detection models on the face mask dataset and chose the Faster R-CNN Inception ResNet V2 network that yielded the accuracy of 99.8%. For physical distance detection, the paper employed the Faster R-CNN Inception V2 to detect people. A transformation matrix was used to eliminate the camera angle's effect on the object distances on the image. The Euclidian distance used the pixels of the transformed image to compute the actual distance between people. A threshold of six feet was considered to capture physical distance violation. The paper also used transfer learning for training the model. The final model was applied on four videos of road maintenance projects in Houston, TX, that effectively detected the face mask and physical distance. We recommend that construction owners use the proposed system to enhance construction workers' safety in the pandemic situation.
Masking Strategies for Image Manifolds
Jun 15, 2016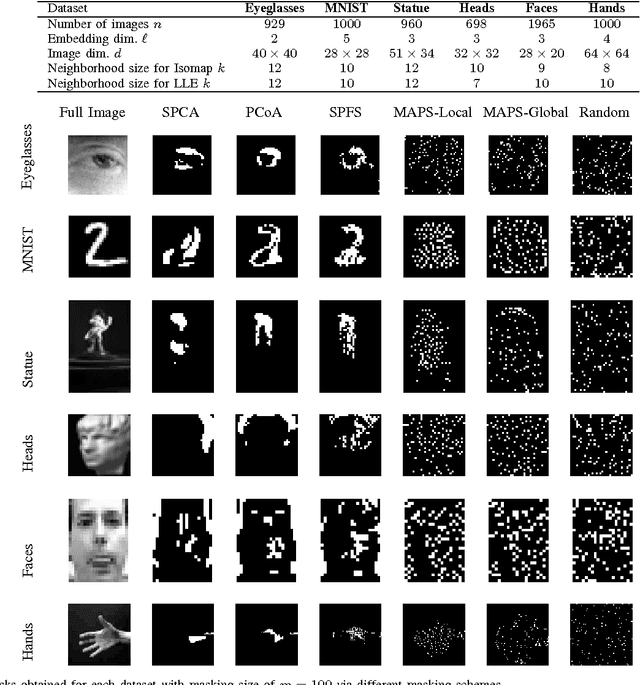
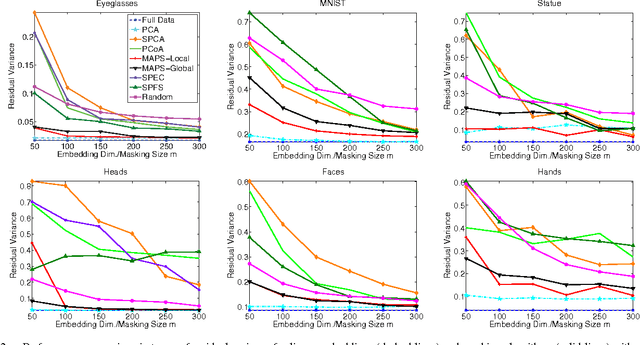
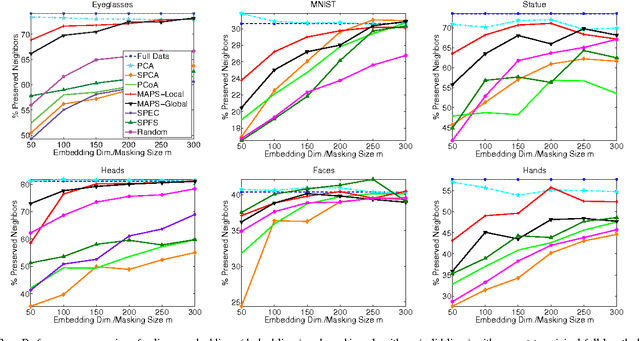
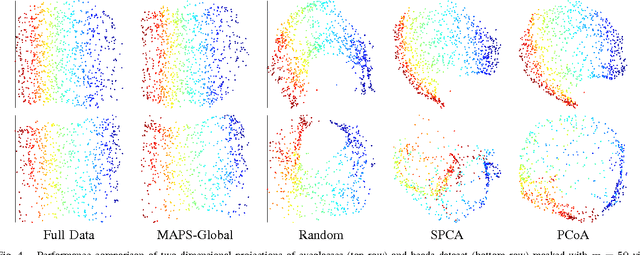
We consider the problem of selecting an optimal mask for an image manifold, i.e., choosing a subset of the pixels of the image that preserves the manifold's geometric structure present in the original data. Such masking implements a form of compressive sensing through emerging imaging sensor platforms for which the power expense grows with the number of pixels acquired. Our goal is for the manifold learned from masked images to resemble its full image counterpart as closely as possible. More precisely, we show that one can indeed accurately learn an image manifold without having to consider a large majority of the image pixels. In doing so, we consider two masking methods that preserve the local and global geometric structure of the manifold, respectively. In each case, the process of finding the optimal masking pattern can be cast as a binary integer program, which is computationally expensive but can be approximated by a fast greedy algorithm. Numerical experiments show that the relevant manifold structure is preserved through the data-dependent masking process, even for modest mask sizes.