 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Autonomous Robotic Mapping of Fragile Geologic Features
May 04, 2021

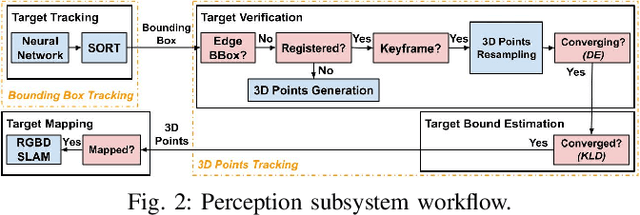
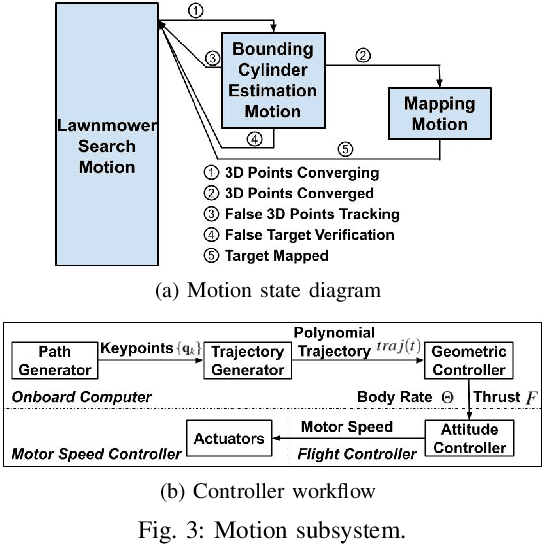
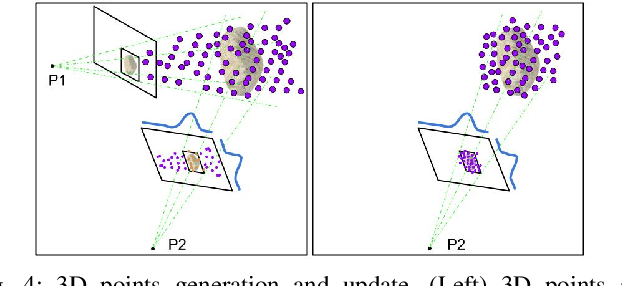
Robotic mapping is useful in scientific applications that involve surveying unstructured environments. This paper presents a target-oriented mapping system for sparsely distributed geologic surface features, such as precariously balanced rocks (PBRs), whose geometric fragility parameters can provide valuable information on earthquake shaking history and landscape development for a region. With this geomorphology problem as the test domain, we demonstrate a pipeline for detecting, localizing, and precisely mapping fragile geologic features distributed on a landscape. To do so, we first carry out a lawn-mower search pattern in the survey region from a high elevation using an Unpiloted Aerial Vehicle (UAV). Once a potential PBR target is detected by a deep neural network, we track the bounding box in the image frames using a real-time tracking algorithm. The location and occupancy of the target in world coordinates are estimated using a sampling-based filtering algorithm, where a set of 3D points are re-sampled after weighting by the tracked bounding boxes from different camera perspectives. The converged 3D points provide a prior on 3D bounding shape of a target, which is used for UAV path planning to closely and completely map the target with Simultaneous Localization and Mapping (SLAM). After target mapping, the UAV resumes the lawn-mower search pattern to find the next target. We introduce techniques to make the target mapping robust to false positive and missing detection from the neural network. Our target-oriented mapping system has the advantages of reducing map storage and emphasizing complete visible surface features on specified targets.
SemStyle: Learning to Generate Stylised Image Captions using Unaligned Text
May 18, 2018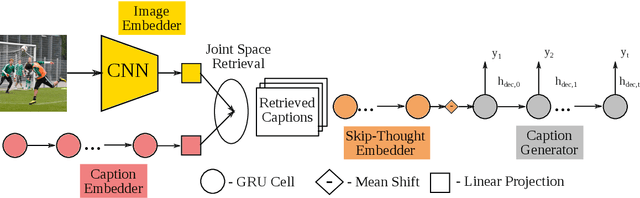

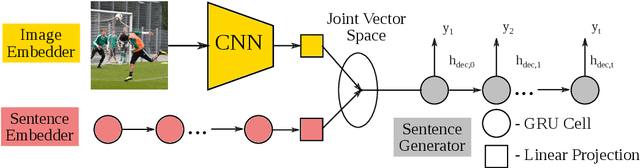
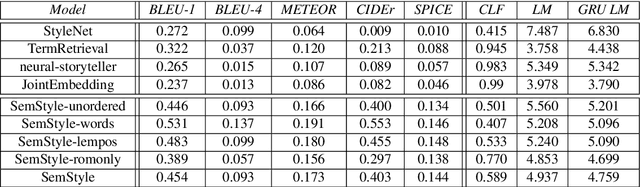
Linguistic style is an essential part of written communication, with the power to affect both clarity and attractiveness. With recent advances in vision and language, we can start to tackle the problem of generating image captions that are both visually grounded and appropriately styled. Existing approaches either require styled training captions aligned to images or generate captions with low relevance. We develop a model that learns to generate visually relevant styled captions from a large corpus of styled text without aligned images. The core idea of this model, called SemStyle, is to separate semantics and style. One key component is a novel and concise semantic term representation generated using natural language processing techniques and frame semantics. In addition, we develop a unified language model that decodes sentences with diverse word choices and syntax for different styles. Evaluations, both automatic and manual, show captions from SemStyle preserve image semantics, are descriptive, and are style shifted. More broadly, this work provides possibilities to learn richer image descriptions from the plethora of linguistic data available on the web.
Explainability in CNN Models By Means of Z-Scores
Feb 11, 2021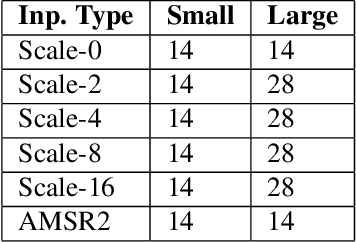
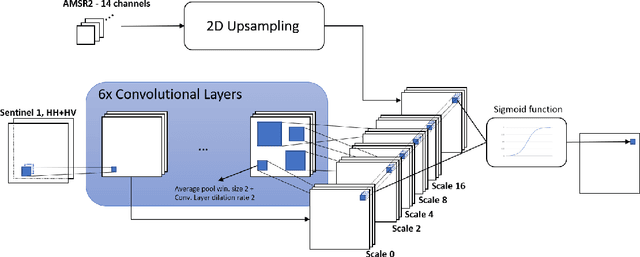
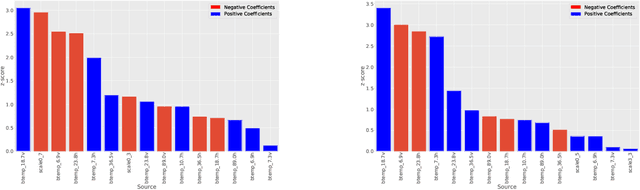
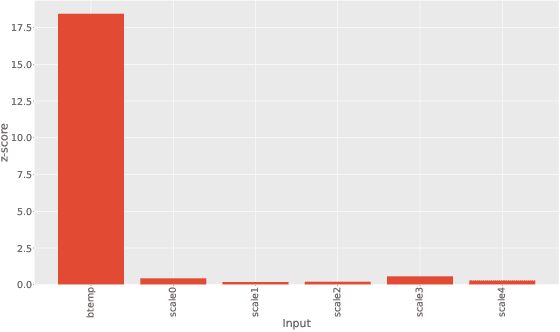
This paper explores the similarities of output layers in Neural Networks (NNs) with logistic regression to explain importance of inputs by Z-scores. The network analyzed, a network for fusion of Synthetic Aperture Radar (SAR) and Microwave Radiometry (MWR) data, is applied to prediction of arctic sea ice. With the analysis the importance of MWR relative to SAR is found to favor MWR components. Further, as the model represents image features at different scales, the relative importance of these are as well analyzed. The suggested methodology offers a simple and easy framework for analyzing output layer components and can reduce the number of components for further analysis with e.g. common NN visualization methods.
SANTIS: Sampling-Augmented Neural neTwork with Incoherent Structure for MR image reconstruction
Dec 08, 2018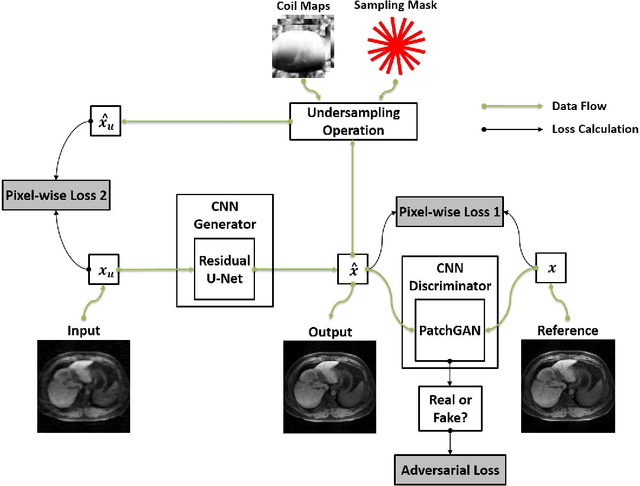
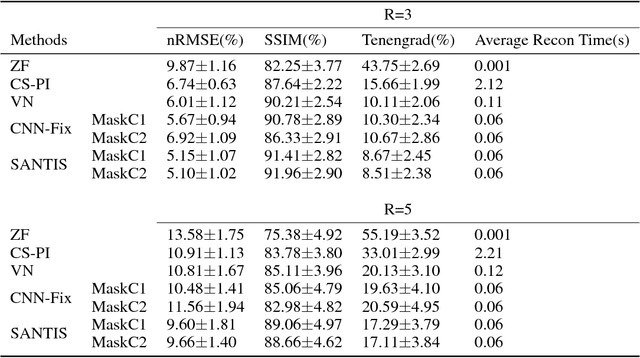
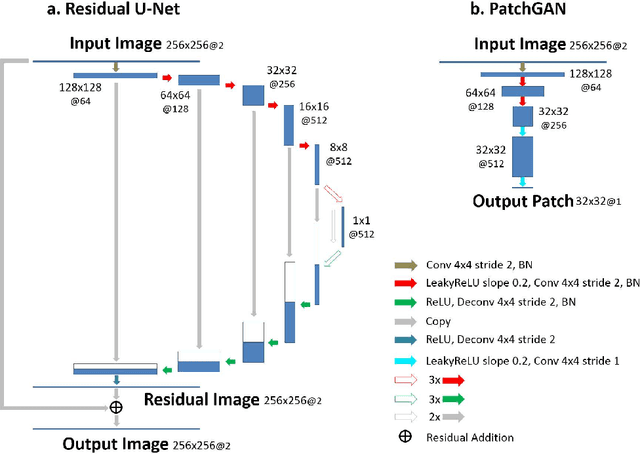
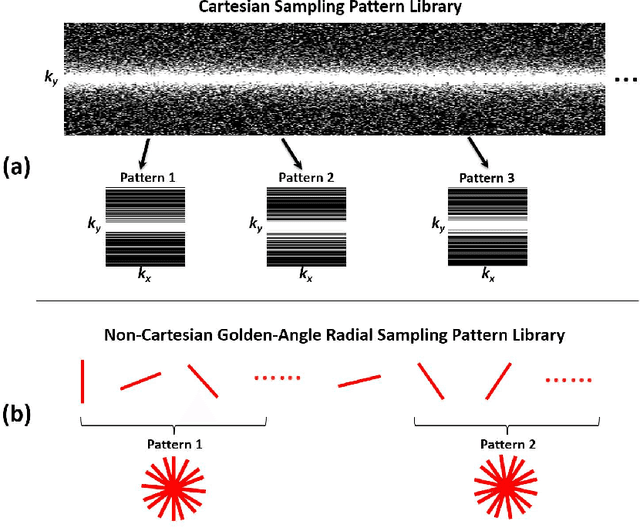
Deep learning holds great promise in the reconstruction of undersampled Magnetic Resonance Imaging (MRI) data, providing new opportunities to escalate the performance of rapid MRI. In existing deep learning-based reconstruction methods, supervised training is performed using artifact-free reference images and their corresponding undersampled pairs. The undersampled images are generated by a fixed undersampling pattern in the training, and the trained network is then applied to reconstruct new images acquired with the same pattern in the inference. While such a training strategy can maintain a favorable reconstruction for a pre-selected undersampling pattern, the robustness of the trained network against any discrepancy of undersampling schemes is typically poor. We developed a novel deep learning-based reconstruction framework called SANTIS for efficient MR image reconstruction with improved robustness against sampling pattern discrepancy. SANTIS uses a data cycle-consistent adversarial network combining efficient end-to-end convolutional neural network mapping, data fidelity enforcement and adversarial training for reconstructing accelerated MR images more faithfully. A training strategy employing sampling augmentation with extensive variation of undersampling patterns was further introduced to promote the robustness of the trained network. Compared to conventional reconstruction and standard deep learning methods, SANTIS achieved consistent better reconstruction performance, with lower errors, greater image sharpness and higher similarity with respect to the reference regardless of the undersampling patterns during inference. This novel concept behind SANTIS can particularly be useful towards improving the robustness of deep learning-based image reconstruction against discrepancy between training and evaluation, which is currently an important but less studied open question.
Bridging the Distribution Gap of Visible-Infrared Person Re-identification with Modality Batch Normalization
Mar 08, 2021
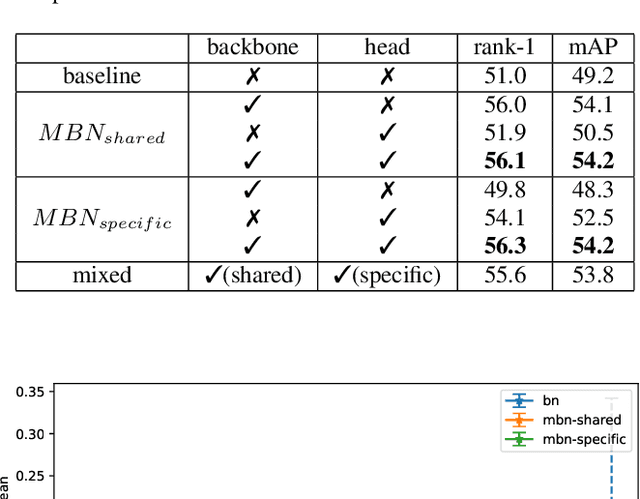
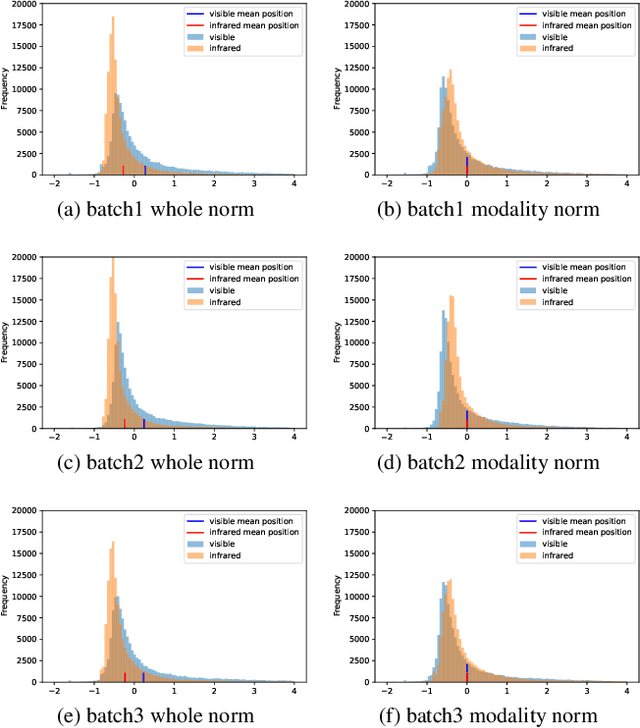
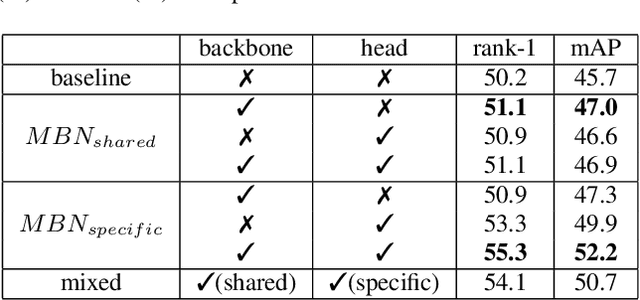
Visible-infrared cross-modality person re-identification (VI-ReID), whose aim is to match person images between visible and infrared modality, is a challenging cross-modality image retrieval task. Most existing works integrate batch normalization layers into their neural network, but we found out that batch normalization layers would lead to two types of distribution gap: 1) inter-mini-batch distribution gap -- the distribution gap of the same modality between each mini-batch; 2) intra-mini-batch modality distribution gap -- the distribution gap of different modality within the same mini-batch. To address these problems, we propose a new batch normalization layer called Modality Batch Normalization (MBN), which normalizes each modality sub-mini-batch respectively instead of the whole mini-batch, and can reduce these distribution gap significantly. Extensive experiments show that our MBN is able to boost the performance of VI-ReID models, even with different datasets, backbones and losses.
PureGaze: Purifying Gaze Feature for Generalizable Gaze Estimation
Mar 24, 2021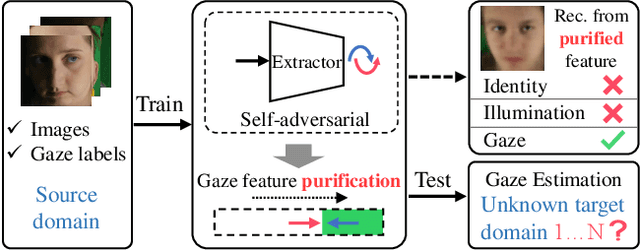
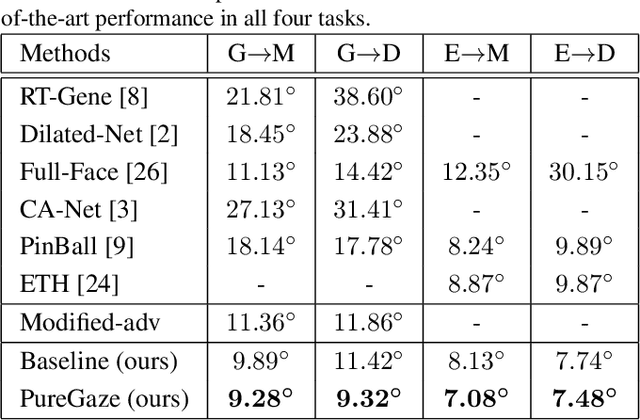
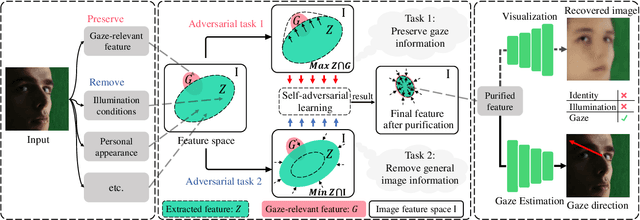
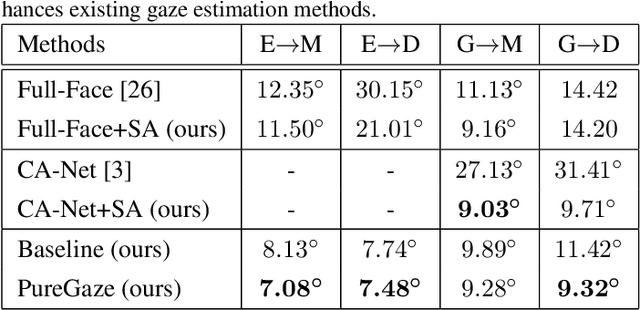
Gaze estimation methods learn eye gaze from facial features. However, among rich information in the facial image, real gaze-relevant features only correspond to subtle changes in eye region, while other gaze-irrelevant features like illumination, personal appearance and even facial expression may affect the learning in an unexpected way. This is a major reason why existing methods show significant performance degradation in cross-domain/dataset evaluation. In this paper, we tackle the domain generalization problem in cross-domain gaze estimation for unknown target domains. To be specific, we realize the domain generalization by gaze feature purification. We eliminate gaze-irrelevant factors such as illumination and identity to improve the cross-dataset performance without knowing the target dataset. We design a plug-and-play self-adversarial framework for the gaze feature purification. The framework enhances not only our baseline but also existing gaze estimation methods directly and significantly. Our method achieves the state-of-the-art performance in different benchmarks. Meanwhile, the purification is easily explainable via visualization.
Combining Deep Transfer Learning with Signal-image Encoding for Multi-Modal Mental Wellbeing Classification
Nov 20, 2020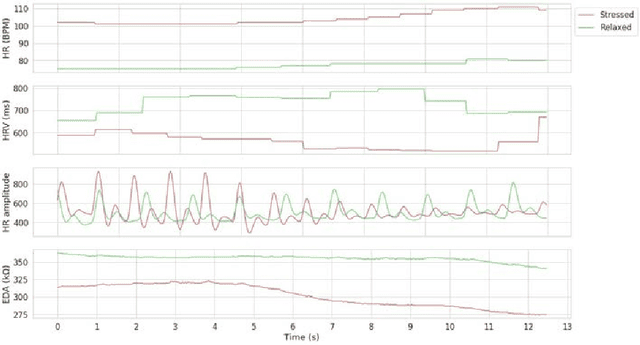
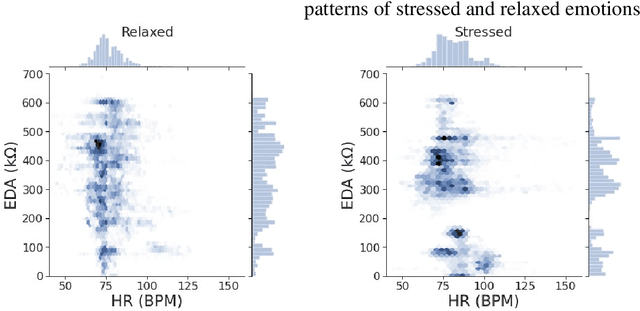
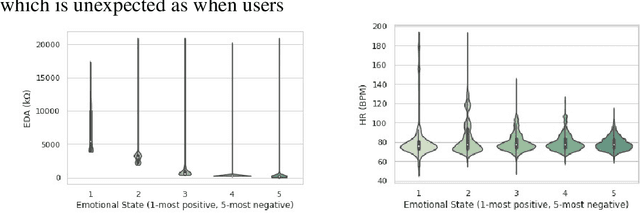
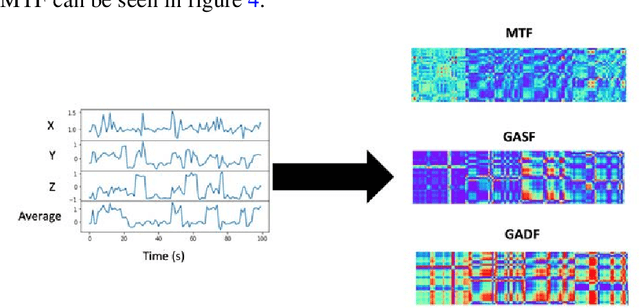
The quantification of emotional states is an important step to understanding wellbeing. Time series data from multiple modalities such as physiological and motion sensor data have proven to be integral for measuring and quantifying emotions. Monitoring emotional trajectories over long periods of time inherits some critical limitations in relation to the size of the training data. This shortcoming may hinder the development of reliable and accurate machine learning models. To address this problem, this paper proposes a framework to tackle the limitation in performing emotional state recognition on multiple multimodal datasets: 1) encoding multivariate time series data into coloured images; 2) leveraging pre-trained object recognition models to apply a Transfer Learning (TL) approach using the images from step 1; 3) utilising a 1D Convolutional Neural Network (CNN) to perform emotion classification from physiological data; 4) concatenating the pre-trained TL model with the 1D CNN. Furthermore, the possibility of performing TL to infer stress from physiological data is explored by initially training a 1D CNN using a large physical activity dataset and then applying the learned knowledge to the target dataset. We demonstrate that model performance when inferring real-world wellbeing rated on a 5-point Likert scale can be enhanced using our framework, resulting in up to 98.5% accuracy, outperforming a conventional CNN by 4.5%. Subject-independent models using the same approach resulted in an average of 72.3% accuracy (SD 0.038). The proposed CNN-TL-based methodology may overcome problems with small training datasets, thus improving on the performance of conventional deep learning methods.
Unsupervised semantic discovery through visual patterns detection
Feb 24, 2021
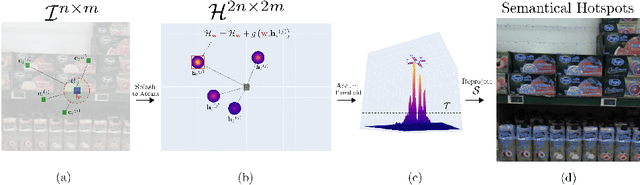
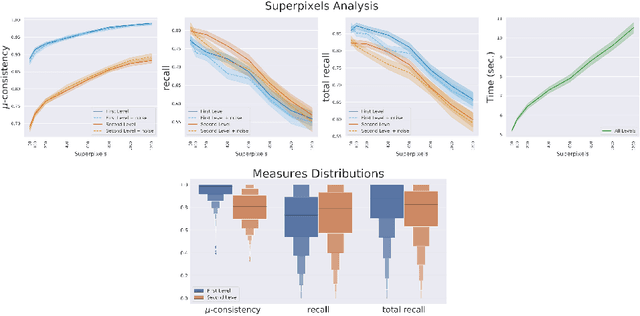

We propose a new fast fully unsupervised method to discover semantic patterns. Our algorithm is able to hierarchically find visual categories and produce a segmentation mask where previous methods fail. Through the modeling of what is a visual pattern in an image, we introduce the notion of "semantic levels" and devise a conceptual framework along with measures and a dedicated benchmark dataset for future comparisons. Our algorithm is composed by two phases. A filtering phase, which selects semantical hotsposts by means of an accumulator space, then a clustering phase which propagates the semantic properties of the hotspots on a superpixels basis. We provide both qualitative and quantitative experimental validation, achieving optimal results in terms of robustness to noise and semantic consistency. We also made code and dataset publicly available.
Unsupervised Representation Learning by Predicting Image Rotations
Mar 21, 2018



Over the last years, deep convolutional neural networks (ConvNets) have transformed the field of computer vision thanks to their unparalleled capacity to learn high level semantic image features. However, in order to successfully learn those features, they usually require massive amounts of manually labeled data, which is both expensive and impractical to scale. Therefore, unsupervised semantic feature learning, i.e., learning without requiring manual annotation effort, is of crucial importance in order to successfully harvest the vast amount of visual data that are available today. In our work we propose to learn image features by training ConvNets to recognize the 2d rotation that is applied to the image that it gets as input. We demonstrate both qualitatively and quantitatively that this apparently simple task actually provides a very powerful supervisory signal for semantic feature learning. We exhaustively evaluate our method in various unsupervised feature learning benchmarks and we exhibit in all of them state-of-the-art performance. Specifically, our results on those benchmarks demonstrate dramatic improvements w.r.t. prior state-of-the-art approaches in unsupervised representation learning and thus significantly close the gap with supervised feature learning. For instance, in PASCAL VOC 2007 detection task our unsupervised pre-trained AlexNet model achieves the state-of-the-art (among unsupervised methods) mAP of 54.4% that is only 2.4 points lower from the supervised case. We get similarly striking results when we transfer our unsupervised learned features on various other tasks, such as ImageNet classification, PASCAL classification, PASCAL segmentation, and CIFAR-10 classification. The code and models of our paper will be published on: https://github.com/gidariss/FeatureLearningRotNet .
Authoring image decompositions with generative models
Dec 05, 2016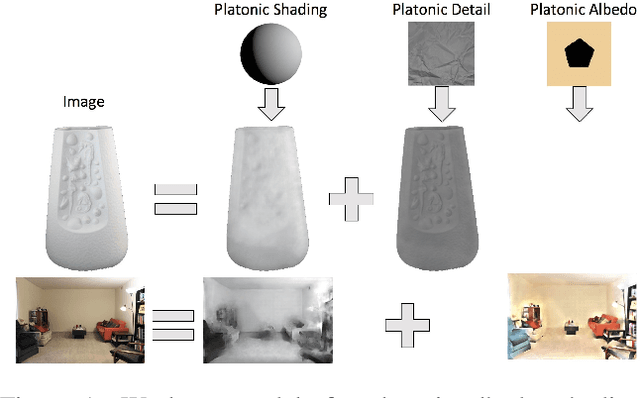
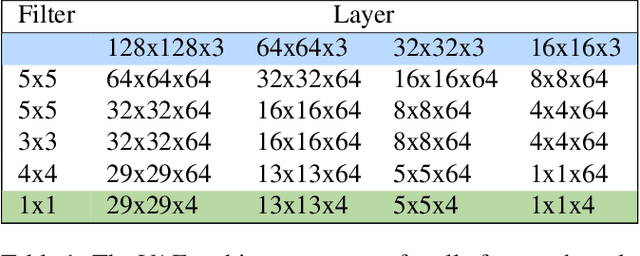
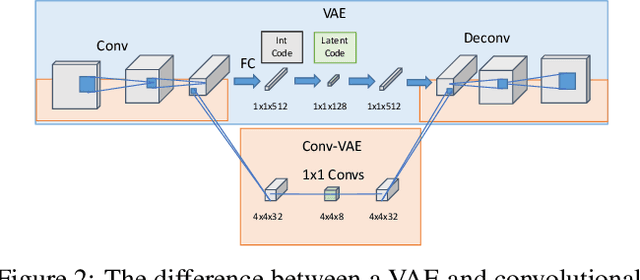
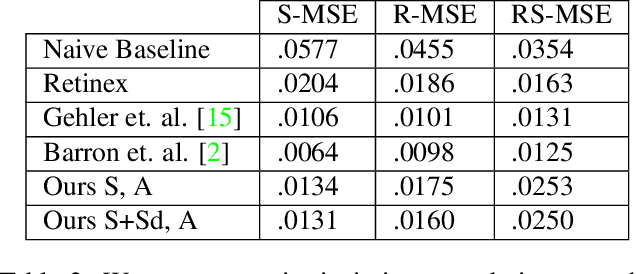
We show how to extend traditional intrinsic image decompositions to incorporate further layers above albedo and shading. It is hard to obtain data to learn a multi-layer decomposition. Instead, we can learn to decompose an image into layers that are "like this" by authoring generative models for each layer using proxy examples that capture the Platonic ideal (Mondrian images for albedo; rendered 3D primitives for shading; material swatches for shading detail). Our method then generates image layers, one from each model, that explain the image. Our approach rests on innovation in generative models for images. We introduce a Convolutional Variational Auto Encoder (conv-VAE), a novel VAE architecture that can reconstruct high fidelity images. The approach is general, and does not require that layers admit a physical interpretation.