 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D coherent x-ray imaging via deep convolutional neural networks
Feb 26, 2021
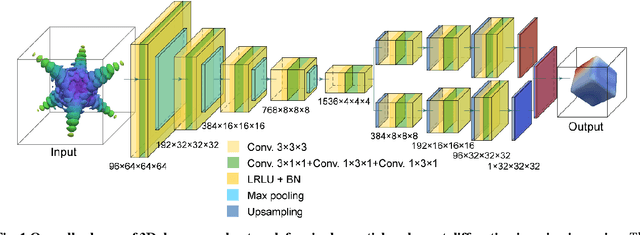
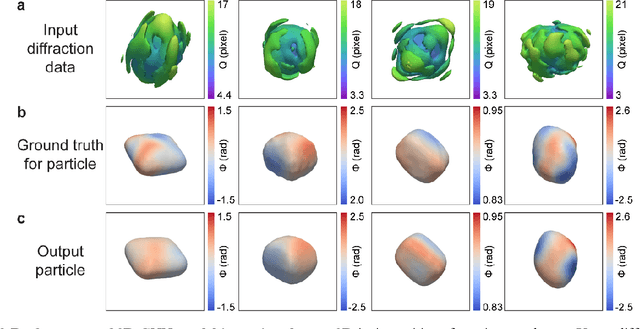
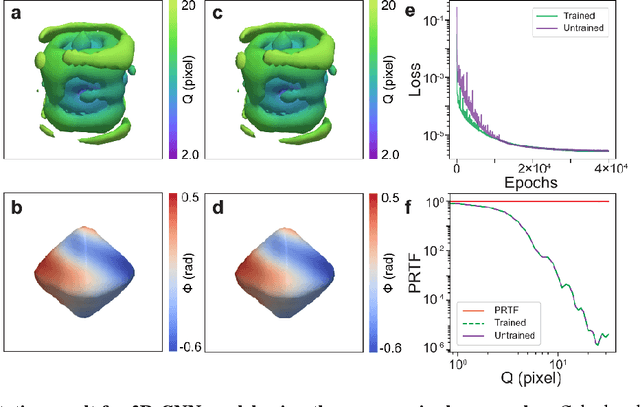
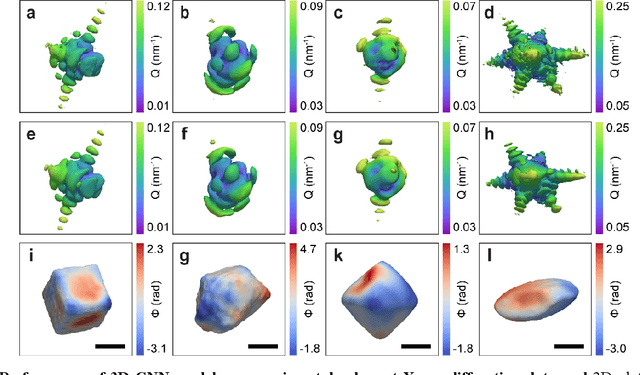
As a critical component of coherent X-ray diffraction imaging (CDI), phase retrieval has been extensively applied in X-ray structural science to recover the 3D morphological information inside measured particles. Despite meeting all the oversampling requirements of Sayre and Shannon, current phase retrieval approaches still have trouble achieving a unique inversion of experimental data in the presence of noise. Here, we propose to overcome this limitation by incorporating a 3D Machine Learning (ML) model combining (optional) supervised training with unsupervised refinement. The trained ML model can rapidly provide an immediate result with high accuracy, which will benefit real-time experiments. More significantly, the Neural Network model can be used without any prior training to learn the missing phases of an image based on minimization of an appropriate loss function alone. We demonstrate significantly improved performance with experimental Bragg CDI data over traditional iterative phase retrieval algorithms.
Classification by Attention: Scene Graph Classification with Prior Knowledge
Nov 19, 2020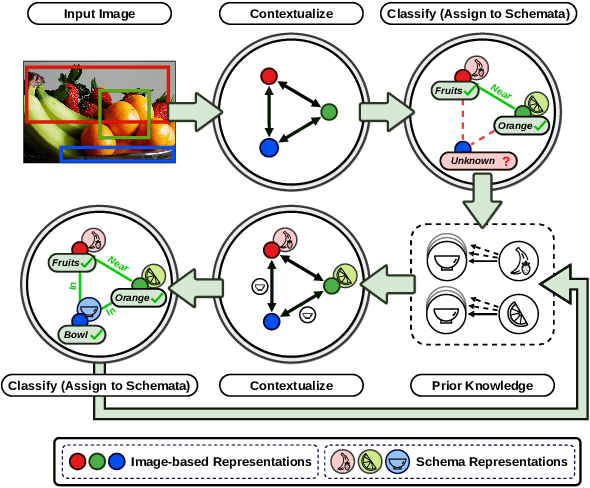
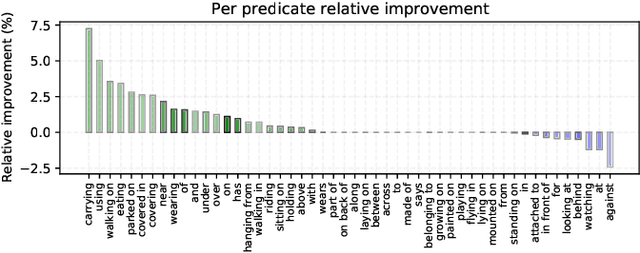
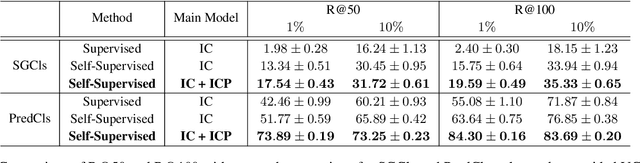

A main challenge in scene graph classification is that the appearance of objects and relations can be significantly different from one image to another. Previous works have addressed this by relational reasoning over all objects in an image, or incorporating prior knowledge into classification. Unlike previous works, we do not consider separate models for the perception and prior knowledge. Instead, we take a multi-task learning approach, where the classification is implemented as an attention layer. This allows for the prior knowledge to emerge and propagate within the perception model. By enforcing the model to also represent the prior, we achieve a strong inductive bias. We show that our model can accurately generate commonsense knowledge and that the iterative injection of this knowledge to scene representations leads to a significantly higher classification performance. Additionally, our model can be fine-tuned on external knowledge given as triples. When combined with self-supervised learning, this leads to accurate predictions with 1% of annotated images only.
Evaluation of CNN-based Single-Image Depth Estimation Methods
May 03, 2018
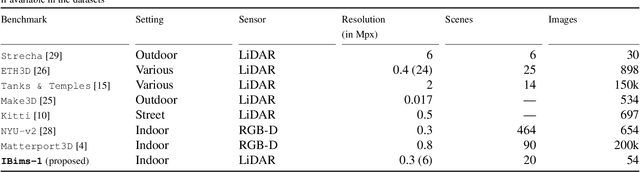
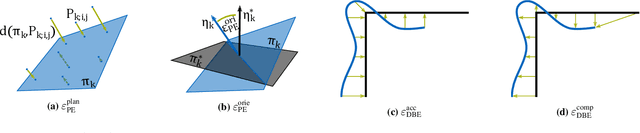
While an increasing interest in deep models for single-image depth estimation methods can be observed, established schemes for their evaluation are still limited. We propose a set of novel quality criteria, allowing for a more detailed analysis by focusing on specific characteristics of depth maps. In particular, we address the preservation of edges and planar regions, depth consistency, and absolute distance accuracy. In order to employ these metrics to evaluate and compare state-of-the-art single-image depth estimation approaches, we provide a new high-quality RGB-D dataset. We used a DSLR camera together with a laser scanner to acquire high-resolution images and highly accurate depth maps. Experimental results show the validity of our proposed evaluation protocol.
Trumpets: Injective Flows for Inference and Inverse Problems
Feb 20, 2021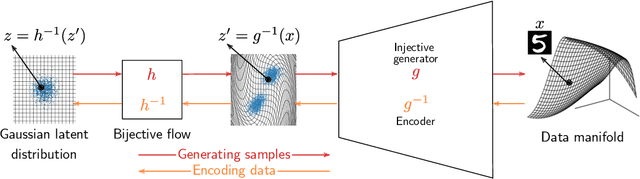

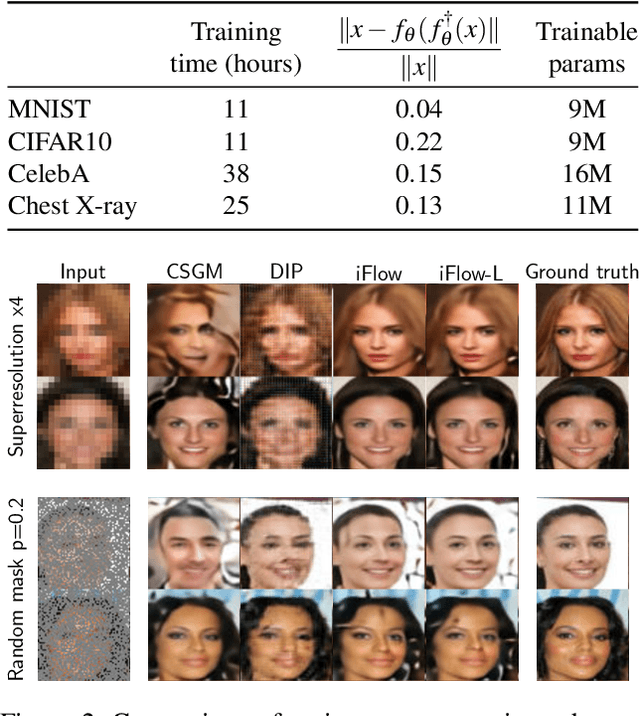
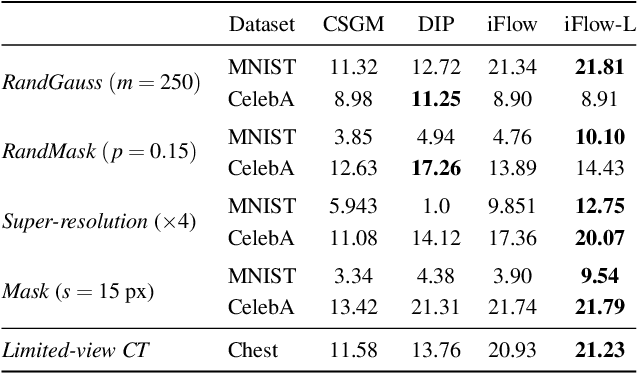
We propose injective generative models called Trumpets that generalize invertible normalizing flows. The proposed generators progressively increase dimension from a low-dimensional latent space. We demonstrate that Trumpets can be trained orders of magnitudes faster than standard flows while yielding samples of comparable or better quality. They retain many of the advantages of the standard flows such as training based on maximum likelihood and a fast, exact inverse of the generator. Since Trumpets are injective and have fast inverses, they can be effectively used for downstream Bayesian inference. To wit, we use Trumpet priors for maximum a posteriori estimation in the context of image reconstruction from compressive measurements, outperforming competitive baselines in terms of reconstruction quality and speed. We then propose an efficient method for posterior characterization and uncertainty quantification with Trumpets by taking advantage of the low-dimensional latent space.
A Teacher-Student Framework for Semi-supervised Medical Image Segmentation From Mixed Supervision
Oct 23, 2020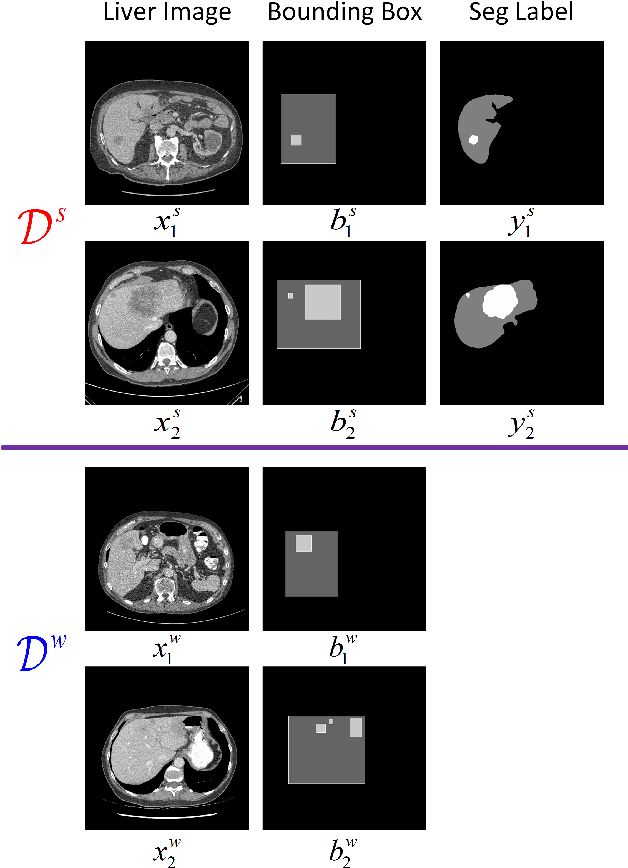
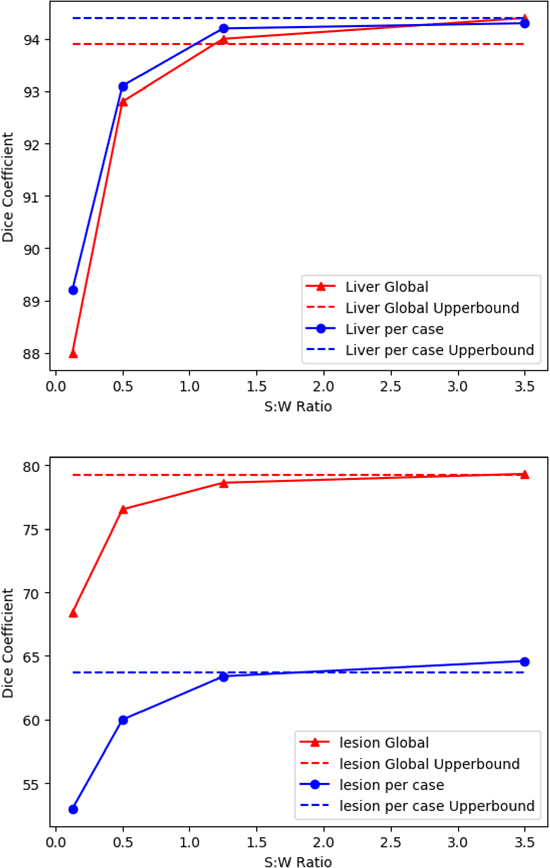
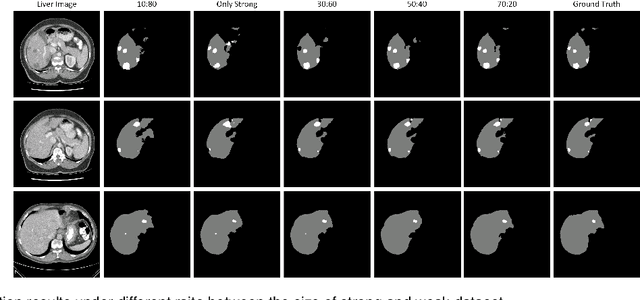
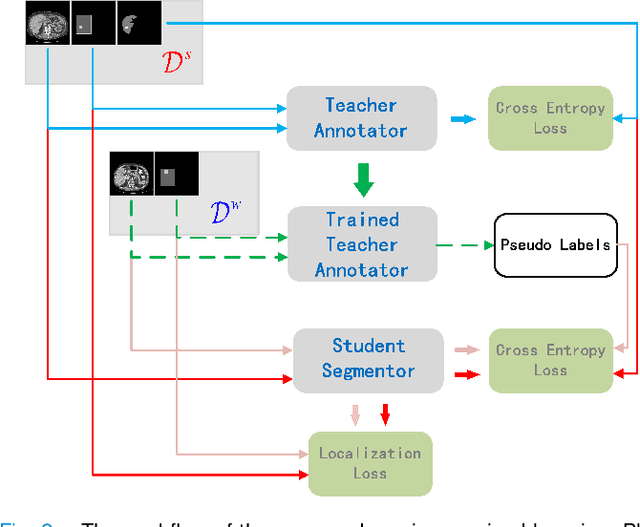
Standard segmentation of medical images based on full-supervised convolutional networks demands accurate dense annotations. Such learning framework is built on laborious manual annotation with restrict demands for expertise, leading to insufficient high-quality labels. To overcome such limitation and exploit massive weakly labeled data, we relaxed the rigid labeling requirement and developed a semi-supervised learning framework based on a teacher-student fashion for organ and lesion segmentation with partial dense-labeled supervision and supplementary loose bounding-box supervision which are easier to acquire. Observing the geometrical relation of an organ and its inner lesions in most cases, we propose a hierarchical organ-to-lesion (O2L) attention module in a teacher segmentor to produce pseudo-labels. Then a student segmentor is trained with combinations of manual-labeled and pseudo-labeled annotations. We further proposed a localization branch realized via an aggregation of high-level features in a deep decoder to predict locations of organ and lesion, which enriches student segmentor with precise localization information. We validated each design in our model on LiTS challenge datasets by ablation study and showed its state-of-the-art performance compared with recent methods. We show our model is robust to the quality of bounding box and achieves comparable performance compared with full-supervised learning methods.
Identifying the Origin of Finger Vein Samples Using Texture Descriptors
Feb 08, 2021
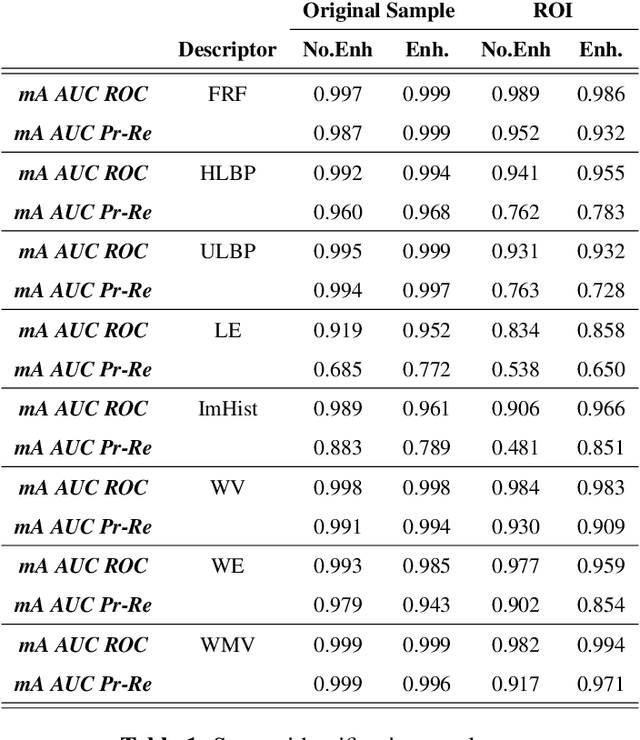


Identifying the origin of a sample image in biometric systems can be beneficial for data authentication in case of attacks against the system and for initiating sensor-specific processing pipelines in sensor-heterogeneous environments. Motivated by shortcomings of the photo response non-uniformity (PRNU) based method in the biometric context, we use a texture classification approach to detect the origin of finger vein sample images. Based on eight publicly available finger vein datasets and applying eight classical yet simple texture descriptors and SVM classification, we demonstrate excellent sensor model identification results for raw finger vein samples as well as for the more challenging region of interest data. The observed results establish texture descriptors as effective competitors to PRNU in finger vein sensor model identification.
From Shadow Generation to Shadow Removal
Mar 24, 2021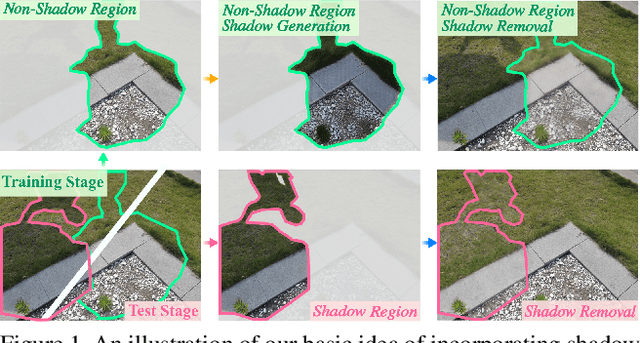
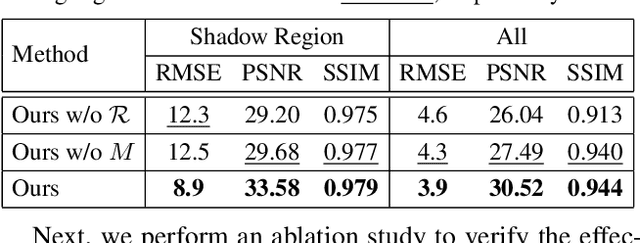
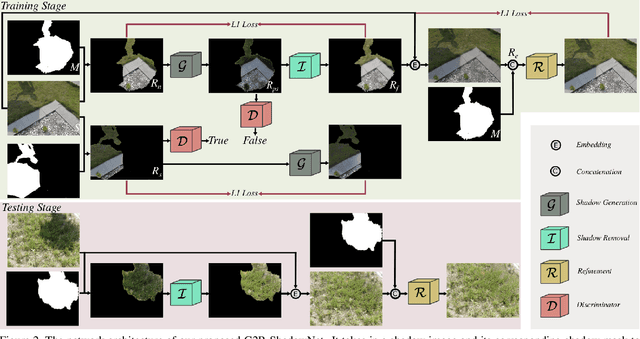
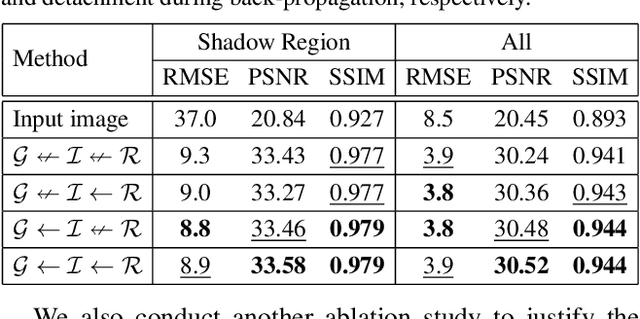
Shadow removal is a computer-vision task that aims to restore the image content in shadow regions. While almost all recent shadow-removal methods require shadow-free images for training, in ECCV 2020 Le and Samaras introduces an innovative approach without this requirement by cropping patches with and without shadows from shadow images as training samples. However, it is still laborious and time-consuming to construct a large amount of such unpaired patches. In this paper, we propose a new G2R-ShadowNet which leverages shadow generation for weakly-supervised shadow removal by only using a set of shadow images and their corresponding shadow masks for training. The proposed G2R-ShadowNet consists of three sub-networks for shadow generation, shadow removal and refinement, respectively and they are jointly trained in an end-to-end fashion. In particular, the shadow generation sub-net stylises non-shadow regions to be shadow ones, leading to paired data for training the shadow-removal sub-net. Extensive experiments on the ISTD dataset and the Video Shadow Removal dataset show that the proposed G2R-ShadowNet achieves competitive performances against the current state of the arts and outperforms Le and Samaras' patch-based shadow-removal method.
Carrying out CNN Channel Pruning in a White Box
Apr 24, 2021
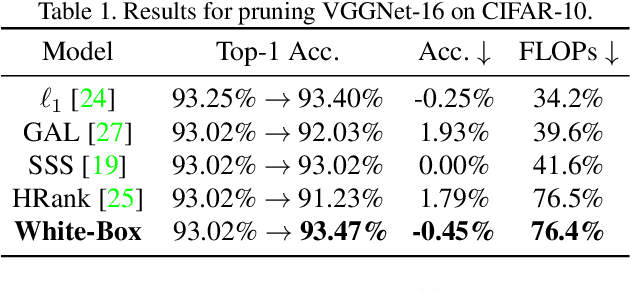
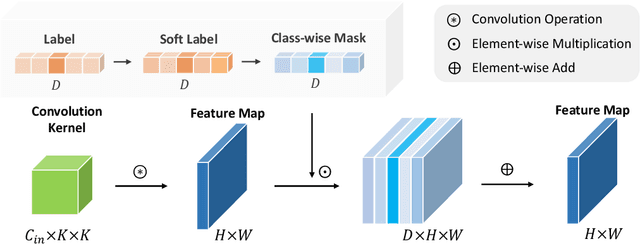
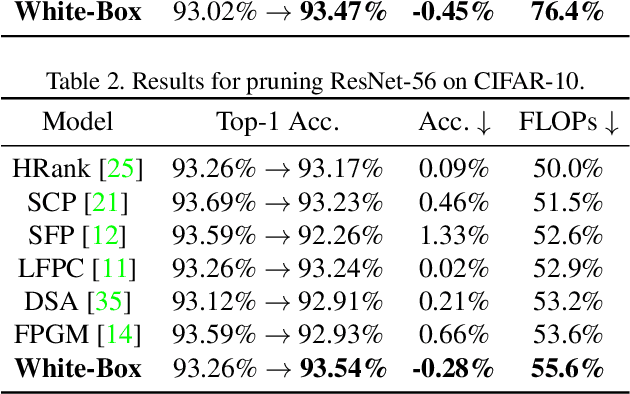
Channel Pruning has been long adopted for compressing CNNs, which significantly reduces the overall computation. Prior works implement channel pruning in an unexplainable manner, which tends to reduce the final classification errors while failing to consider the internal influence of each channel. In this paper, we conduct channel pruning in a white box. Through deep visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we choose to preserve channels contributing to most categories. Specifically, to model the contribution of each channel to differentiating categories, we develop a class-wise mask for each channel, implemented in a dynamic training manner w.r.t. the input image's category. On the basis of the learned class-wise mask, we perform a global voting mechanism to remove channels with less category discrimination. Lastly, a fine-tuning process is conducted to recover the performance of the pruned model. To our best knowledge, it is the first time that CNN interpretability theory is considered to guide channel pruning. Extensive experiments demonstrate the superiority of our White-Box over many state-of-the-arts. For instance, on CIFAR-10, it reduces 65.23% FLOPs with even 0.62% accuracy improvement for ResNet-110. On ILSVRC-2012, White-Box achieves a 45.6% FLOPs reduction with only a small loss of 0.83% in the top-1 accuracy for ResNet-50. Code, training logs and pruned models are anonymously at https://github.com/zyxxmu/White-Box.
Relation-aware Instance Refinement for Weakly Supervised Visual Grounding
Mar 24, 2021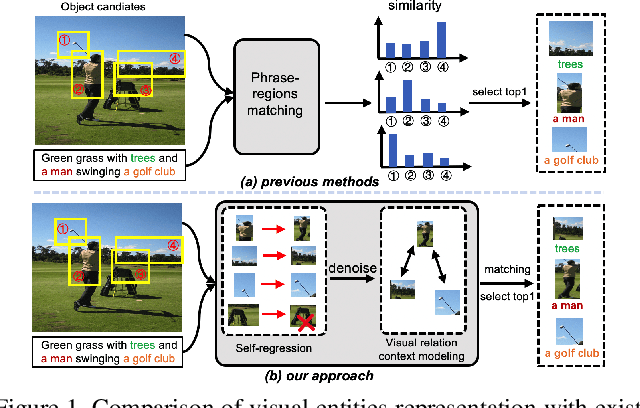
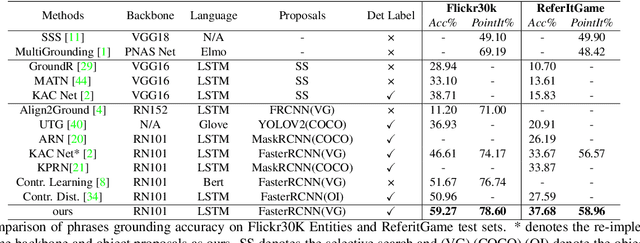
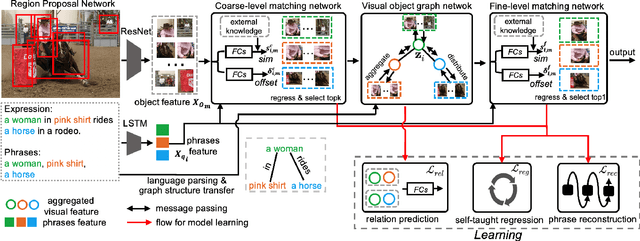

Visual grounding, which aims to build a correspondence between visual objects and their language entities, plays a key role in cross-modal scene understanding. One promising and scalable strategy for learning visual grounding is to utilize weak supervision from only image-caption pairs. Previous methods typically rely on matching query phrases directly to a precomputed, fixed object candidate pool, which leads to inaccurate localization and ambiguous matching due to lack of semantic relation constraints. In our paper, we propose a novel context-aware weakly-supervised learning method that incorporates coarse-to-fine object refinement and entity relation modeling into a two-stage deep network, capable of producing more accurate object representation and matching. To effectively train our network, we introduce a self-taught regression loss for the proposal locations and a classification loss based on parsed entity relations. Extensive experiments on two public benchmarks Flickr30K Entities and ReferItGame demonstrate the efficacy of our weakly grounding framework. The results show that we outperform the previous methods by a considerable margin, achieving 59.27\% top-1 accuracy in Flickr30K Entities and 37.68\% in the ReferItGame dataset respectively (Code is available at https://github.com/youngfly11/ReIR-WeaklyGrounding.pytorch.git).
Exploring Models and Data for Remote Sensing Image Caption Generation
Dec 21, 2017
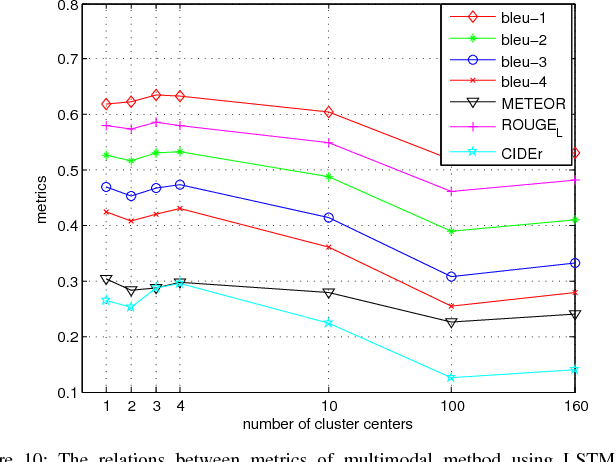
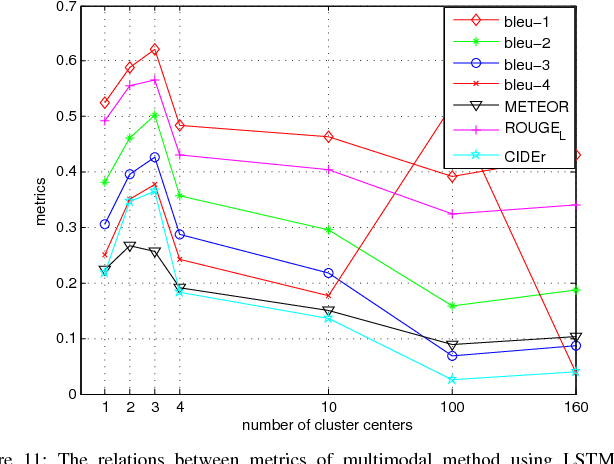
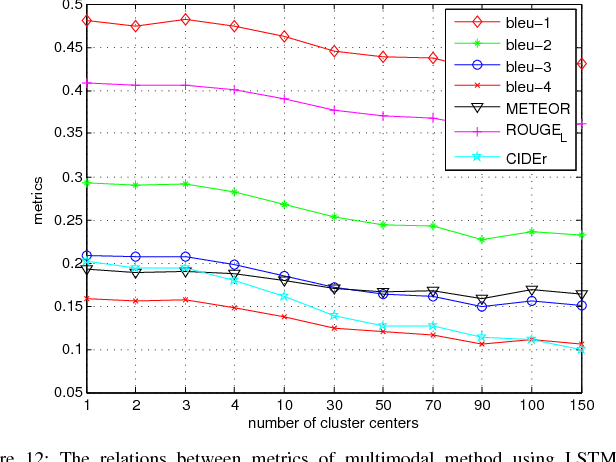
Inspired by recent development of artificial satellite, remote sensing images have attracted extensive attention. Recently, noticeable progress has been made in scene classification and target detection.However, it is still not clear how to describe the remote sensing image content with accurate and concise sentences. In this paper, we investigate to describe the remote sensing images with accurate and flexible sentences. First, some annotated instructions are presented to better describe the remote sensing images considering the special characteristics of remote sensing images. Second, in order to exhaustively exploit the contents of remote sensing images, a large-scale aerial image data set is constructed for remote sensing image caption. Finally, a comprehensive review is presented on the proposed data set to fully advance the task of remote sensing caption. Extensive experiments on the proposed data set demonstrate that the content of the remote sensing image can be completely described by generating language descriptions. The data set is available at https://github.com/201528014227051/RSICD_optimal