 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving reproducibility in synchrotron tomography using implementation-adapted filters
Mar 15, 2021
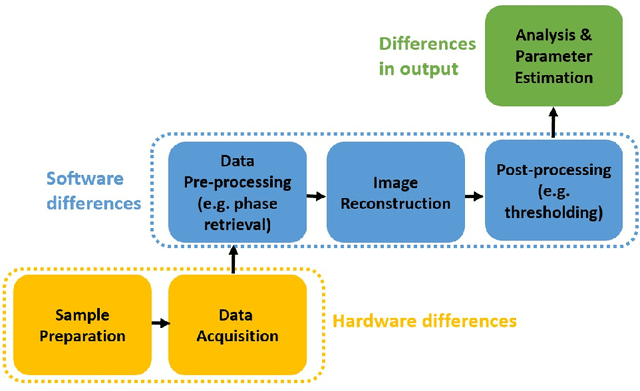
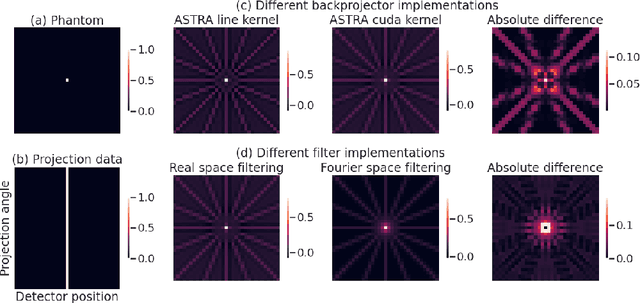
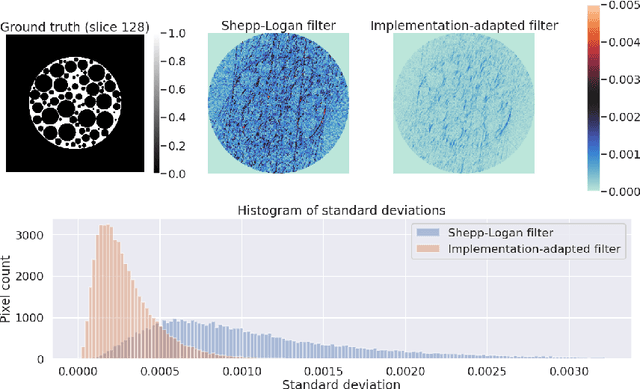
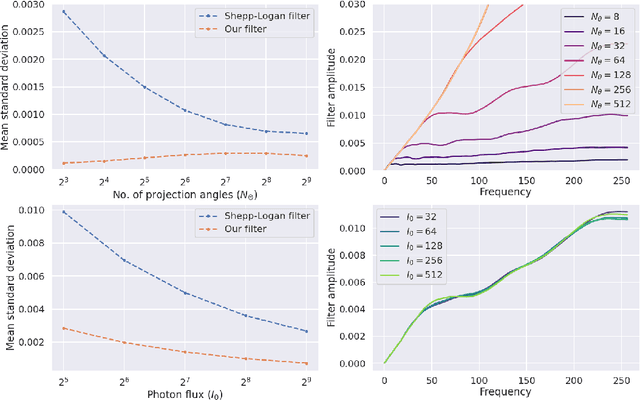
For reconstructing large tomographic datasets fast, filtered backprojection-type or Fourier-based algorithms are still the method of choice, as they have been for decades. These robust and computationally efficient algorithms have been integrated in a broad range of software packages. Despite the fact that the underlying mathematical formulas used for image reconstruction are unambiguous, variations in discretisation and interpolation result in quantitative differences between reconstructed images obtained from different software. This hinders reproducibility of experimental results. In this paper, we propose a way to reduce such differences by optimising the filter used in analytical algorithms. These filters can be computed using a wrapper routine around a black-box implementation of a reconstruction algorithm, and lead to quantitatively similar reconstructions. We demonstrate use cases for our approach by computing implementation-adapted filters for several open-source implementations and applying it to simulated phantoms and real-world data acquired at the synchrotron. Our contribution to a reproducible reconstruction step forms a building block towards a fully reproducible synchrotron tomography data processing pipeline.
Evaluation of Multi-Slice Inputs to Convolutional Neural Networks for Medical Image Segmentation
Dec 22, 2019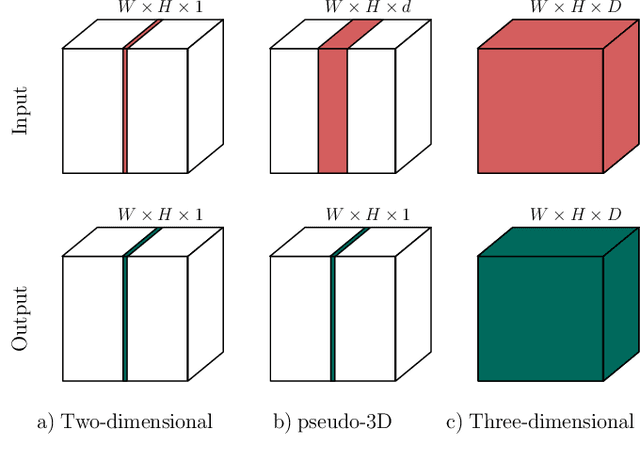
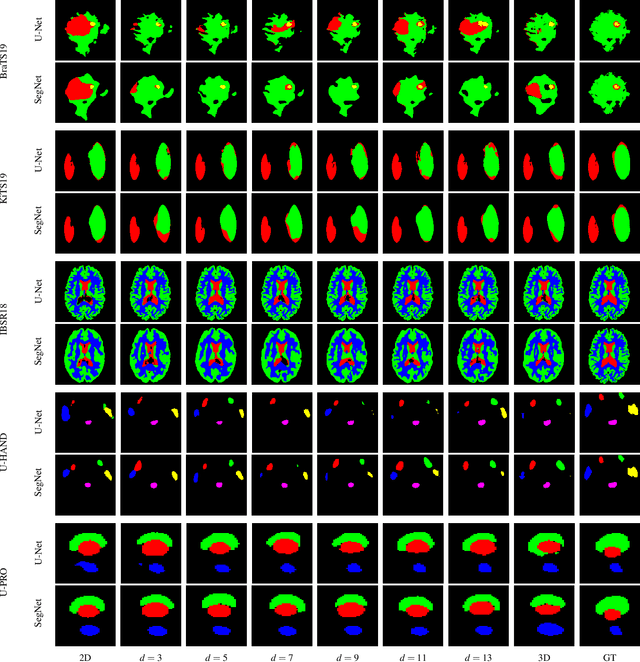
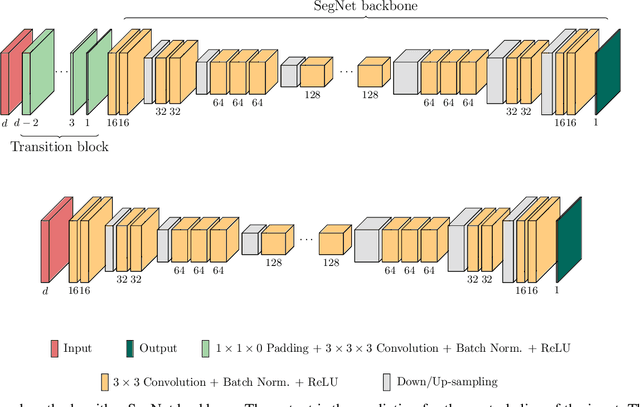
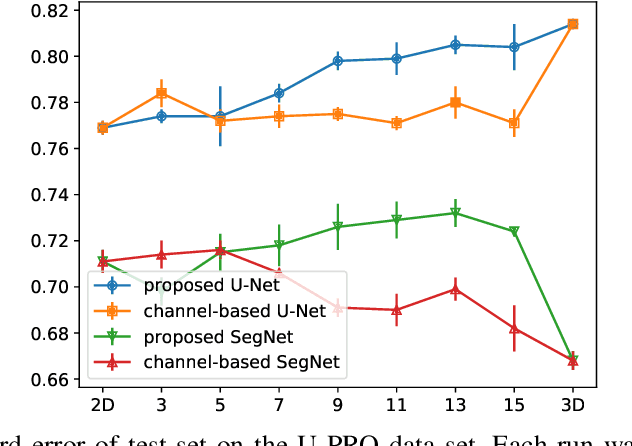
When using Convolutional Neural Networks (CNNs) for segmentation of organs and lesions in medical images, the conventional approach is to work with inputs and outputs either as single slice (2D) or whole volumes (3D). One common alternative, in this study denoted as pseudo-3D, is to use a stack of adjacent slices as input and produce a prediction for at least the central slice. This approach gives the network the possibility to capture 3D spatial information, with only a minor additional computational cost. In this study, we systematically evaluate the segmentation performance and computational costs of this pseudo-3D approach as a function of the number of input slices, and compare the results to conventional end-to-end 2D and 3D CNNs. The standard pseudo-3D method regards the neighboring slices as multiple input image channels. We additionally evaluate a simple approach where the input stack is a volumetric input that is repeatably convolved in 3D to obtain a 2D feature map. This 2D map is in turn fed into a standard 2D network. We conducted experiments using two different CNN backbone architectures and on five diverse data sets covering different anatomical regions, imaging modalities, and segmentation tasks. We found that while both pseudo-3D methods can process a large number of slices at once and still be computationally much more efficient than fully 3D CNNs, a significant improvement over a regular 2D CNN was only observed for one of the five data sets. An analysis of the structural properties of the segmentation masks revealed no relations to the segmentation performance with respect to the number of input slices. The conclusion is therefore that in the general case, multi-slice inputs appear to not significantly improve segmentation results over using 2D or 3D CNNs.
Distributed Deep Learning Using Volunteer Computing-Like Paradigm
Apr 02, 2021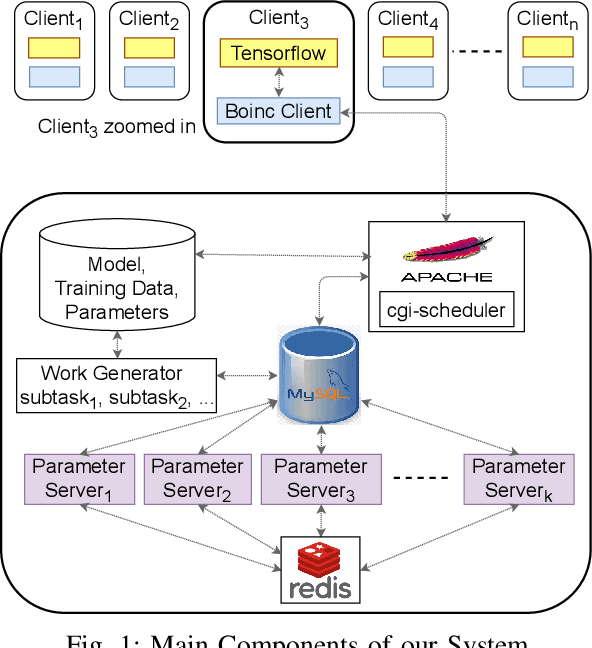
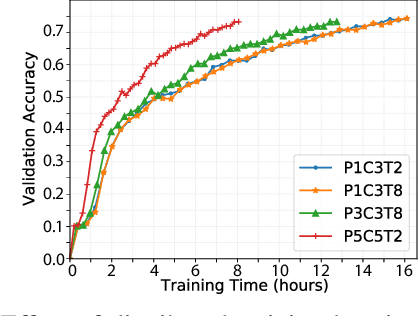
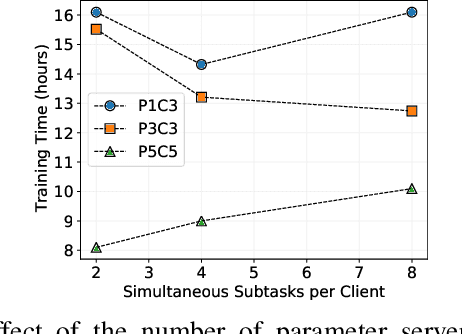
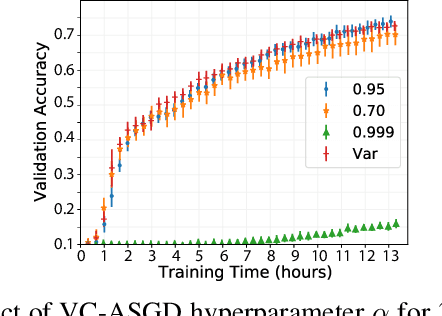
Use of Deep Learning (DL) in commercial applications such as image classification, sentiment analysis and speech recognition is increasing. When training DL models with large number of parameters and/or large datasets, cost and speed of training can become prohibitive. Distributed DL training solutions that split a training job into subtasks and execute them over multiple nodes can decrease training time. However, the cost of current solutions, built predominantly for cluster computing systems, can still be an issue. In contrast to cluster computing systems, Volunteer Computing (VC) systems can lower the cost of computing, but applications running on VC systems have to handle fault tolerance, variable network latency and heterogeneity of compute nodes, and the current solutions are not designed to do so. We design a distributed solution that can run DL training on a VC system by using a data parallel approach. We implement a novel asynchronous SGD scheme called VC-ASGD suited for VC systems. In contrast to traditional VC systems that lower cost by using untrustworthy volunteer devices, we lower cost by leveraging preemptible computing instances on commercial cloud platforms. By using preemptible instances that require applications to be fault tolerant, we lower cost by 70-90% and improve data security.
Matched sample selection with GANs for mitigating attribute confounding
Mar 24, 2021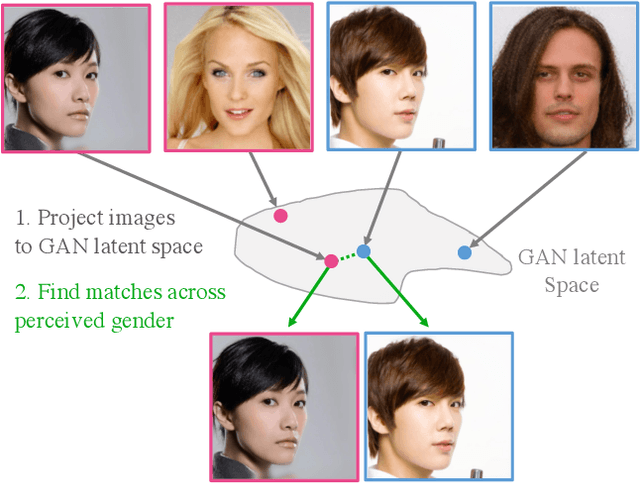
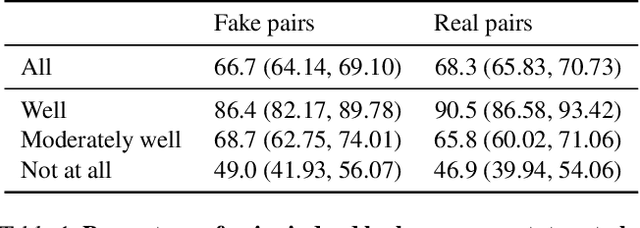
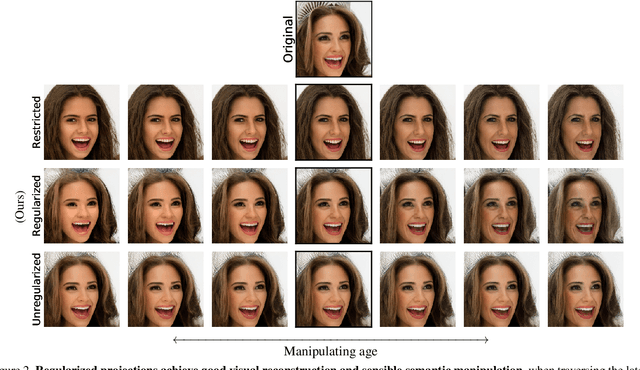

Measuring biases of vision systems with respect to protected attributes like gender and age is critical as these systems gain widespread use in society. However, significant correlations between attributes in benchmark datasets make it difficult to separate algorithmic bias from dataset bias. To mitigate such attribute confounding during bias analysis, we propose a matching approach that selects a subset of images from the full dataset with balanced attribute distributions across protected attributes. Our matching approach first projects real images onto a generative adversarial network (GAN)'s latent space in a manner that preserves semantic attributes. It then finds image matches in this latent space across a chosen protected attribute, yielding a dataset where semantic and perceptual attributes are balanced across the protected attribute. We validate projection and matching strategies with qualitative, quantitative, and human annotation experiments. We demonstrate our work in the context of gender bias in multiple open-source facial-recognition classifiers and find that bias persists after removing key confounders via matching. Code and documentation to reproduce the results here and apply the methods to new data is available at https://github.com/csinva/matching-with-gans .
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Oct 30, 2020



With the increasing popularity of augmented and virtual reality, retailers are now focusing more towards customer satisfaction to increase the amount of sales. Although augmented reality is not a new concept but it has gained much needed attention over the past few years. Our present work is targeted towards this direction which may be used to enhance user experience in various virtual and augmented reality based applications. We propose a model to change skin tone of a person. Given any input image of a person or a group of persons with some value indicating the desired change of skin color towards fairness or darkness, this method can change the skin tone of the persons in the image. This is an unsupervised method and also unconstrained in terms of pose, illumination, number of persons in the image etc. The goal of this work is to reduce the time and effort which is generally required for changing the skin tone using existing applications (e.g., Photoshop) by professionals or novice. To establish the efficacy of this method we have compared our result with that of some popular photo editor and also with the result of some existing benchmark method related to human attribute manipulation. Rigorous experiments on different datasets show the effectiveness of this method in terms of synthesizing perceptually convincing outputs.
A Framework for 3D Tracking of Frontal Dynamic Objects in Autonomous Cars
Mar 24, 2021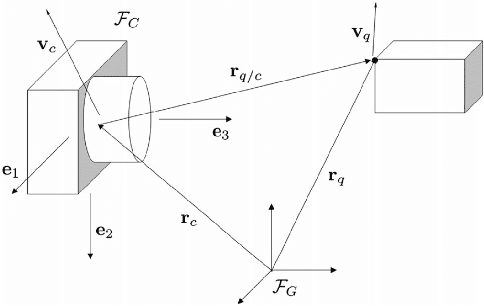

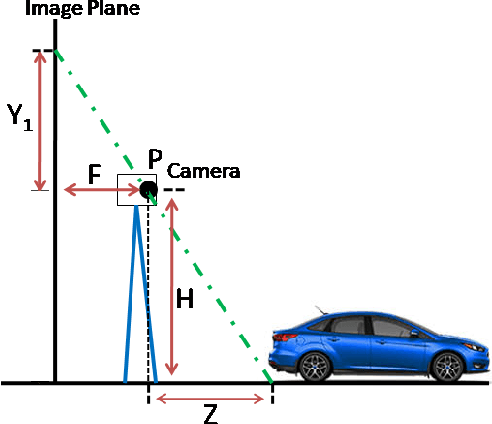
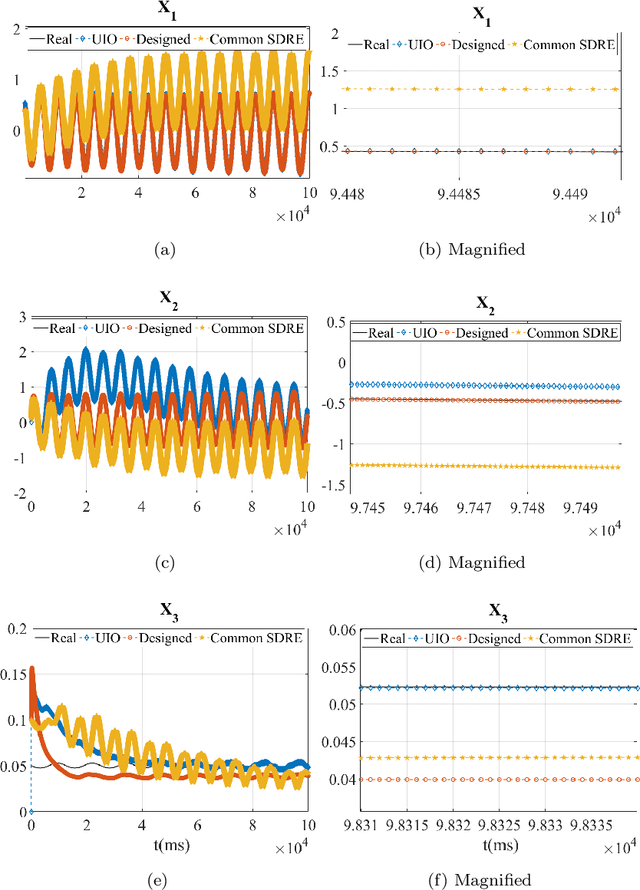
Both recognition and 3D tracking of frontal dynamic objects are crucial problems in an autonomous vehicle, while depth estimation as an essential issue becomes a challenging problem using a monocular camera. Since both camera and objects are moving, the issue can be formed as a structure from motion (SFM) problem. In this paper, to elicit features from an image, the YOLOv3 approach is utilized beside an OpenCV tracker. Subsequently, to obtain the lateral and longitudinal distances, a nonlinear SFM model is considered alongside a state-dependent Riccati equation (SDRE) filter and a newly developed observation model. Additionally, a switching method in the form of switching estimation error covariance is proposed to enhance the robust performance of the SDRE filter. The stability analysis of the presented filter is conducted on a class of discrete nonlinear systems. Furthermore, the ultimate bound of estimation error caused by model uncertainties is analytically obtained to investigate the switching significance. Simulations are reported to validate the performance of the switched SDRE filter. Finally, real-time experiments are performed through a multi-thread framework implemented on a Jetson TX2 board, while radar data is used for the evaluation.
Recurrent neural network-based volumetric fluorescence microscopy
Oct 21, 2020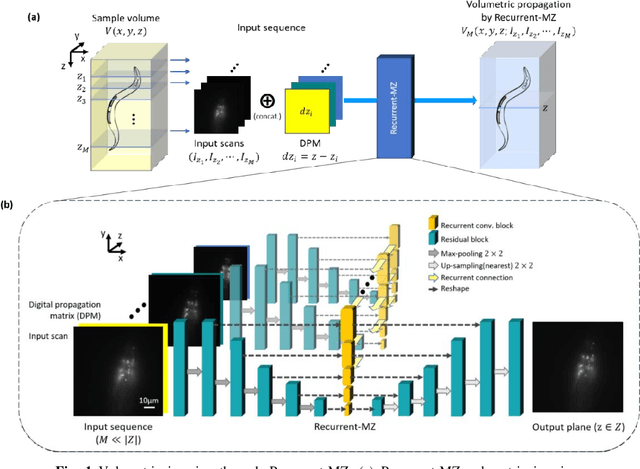
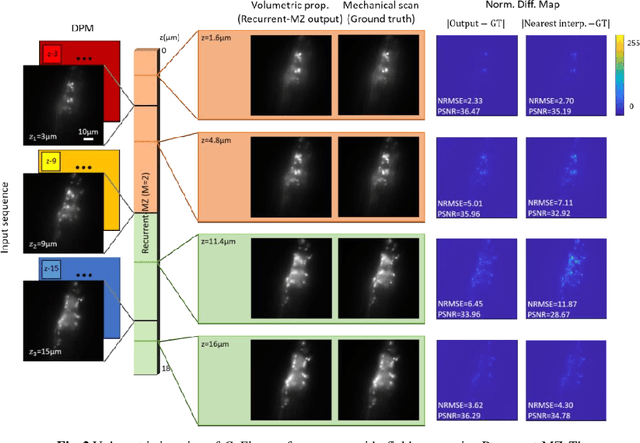
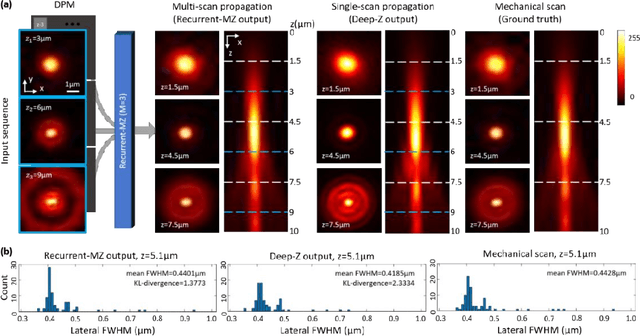
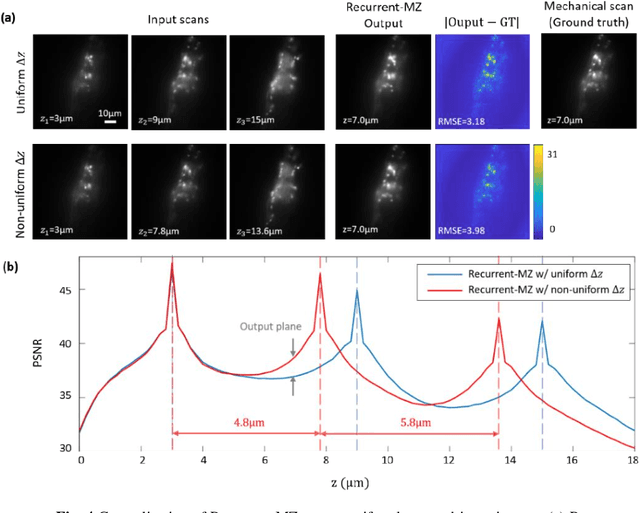
Volumetric imaging of samples using fluorescence microscopy plays an important role in various fields including physical, medical and life sciences. Here we report a deep learning-based volumetric image inference framework that uses 2D images that are sparsely captured by a standard wide-field fluorescence microscope at arbitrary axial positions within the sample volume. Through a recurrent convolutional neural network, which we term as Recurrent-MZ, 2D fluorescence information from a few axial planes within the sample is explicitly incorporated to digitally reconstruct the sample volume over an extended depth-of-field. Using experiments on C. Elegans and nanobead samples, Recurrent-MZ is demonstrated to increase the depth-of-field of a 63x/1.4NA objective lens by approximately 50-fold, also providing a 30-fold reduction in the number of axial scans required to image the same sample volume. We further illustrated the generalization of this recurrent network for 3D imaging by showing its resilience to varying imaging conditions, including e.g., different sequences of input images, covering various axial permutations and unknown axial positioning errors. Recurrent-MZ demonstrates the first application of recurrent neural networks in microscopic image reconstruction and provides a flexible and rapid volumetric imaging framework, overcoming the limitations of current 3D scanning microscopy tools.
LARNet: Lie Algebra Residual Network for Profile Face Recognition
Mar 15, 2021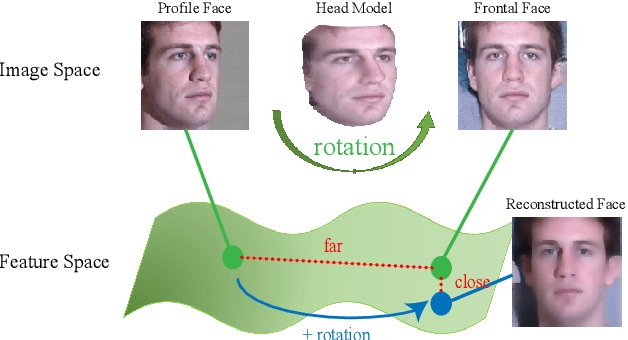
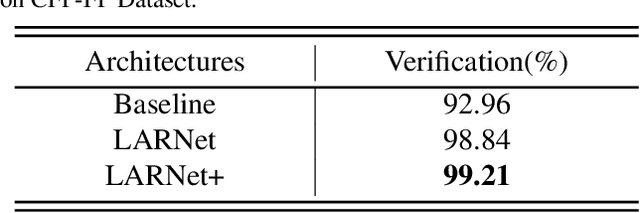
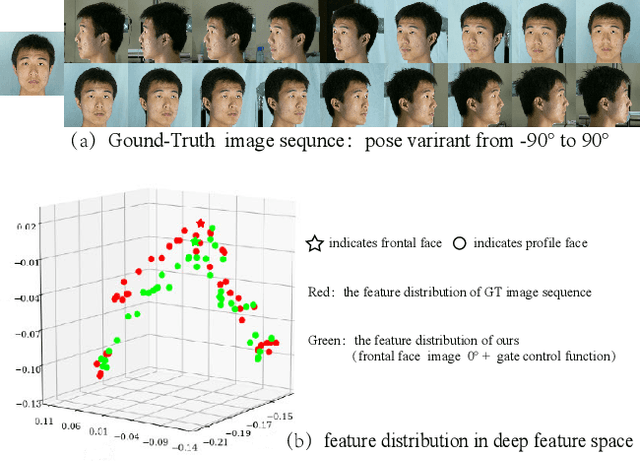

Due to large variations between profile and frontal faces, profile-based face recognition remains as a tremendous challenge in many practical vision scenarios. Traditional techniques address this challenge either by synthesizing frontal faces or by pose-invariants learning. In this paper, we propose a novel method with Lie algebra theory to explore how face rotation in the 3D space affects the deep feature generation process of convolutional neural networks (CNNs). We prove that face rotation in the image space is equivalent to an additive residual component in the feature space of CNNs, which is determined solely by the rotation. Based on this theoretical finding, we further design a Lie algebraic residual network (LARNet) for tackling profile-based face recognition. Our LARNet consists of a residual subnet for decoding rotation information from input face images, and a gating subnet to learn rotation magnitude for controlling the number of residual components contributing to the feature learning process. Comprehensive experimental evaluations on frontal-profile face datasets and general face recognition datasets demonstrate that our method consistently outperforms the state-of-the-arts.
Learning Kernel for Conditional Moment-Matching Discrepancy-based Image Classification
Aug 24, 2020
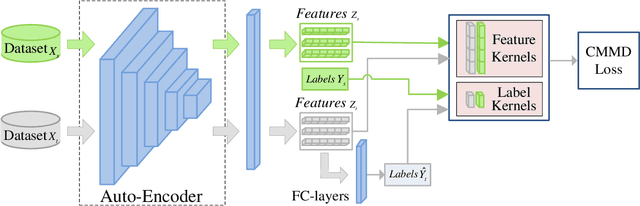
Conditional Maximum Mean Discrepancy (CMMD) can capture the discrepancy between conditional distributions by drawing support from nonlinear kernel functions, thus it has been successfully used for pattern classification. However, CMMD does not work well on complex distributions, especially when the kernel function fails to correctly characterize the difference between intra-class similarity and inter-class similarity. In this paper, a new kernel learning method is proposed to improve the discrimination performance of CMMD. It can be operated with deep network features iteratively and thus denoted as KLN for abbreviation. The CMMD loss and an auto-encoder (AE) are used to learn an injective function. By considering the compound kernel, i.e., the injective function with a characteristic kernel, the effectiveness of CMMD for data category description is enhanced. KLN can simultaneously learn a more expressive kernel and label prediction distribution, thus, it can be used to improve the classification performance in both supervised and semi-supervised learning scenarios. In particular, the kernel-based similarities are iteratively learned on the deep network features, and the algorithm can be implemented in an end-to-end manner. Extensive experiments are conducted on four benchmark datasets, including MNIST, SVHN, CIFAR-10 and CIFAR-100. The results indicate that KLN achieves state-of-the-art classification performance.
Discriminative Transfer Learning for General Image Restoration
Mar 27, 2017
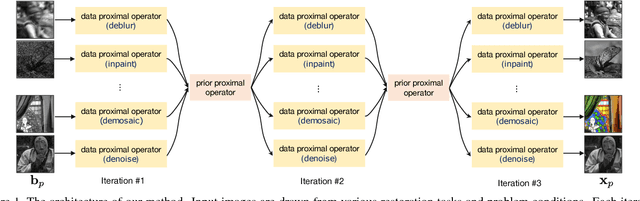

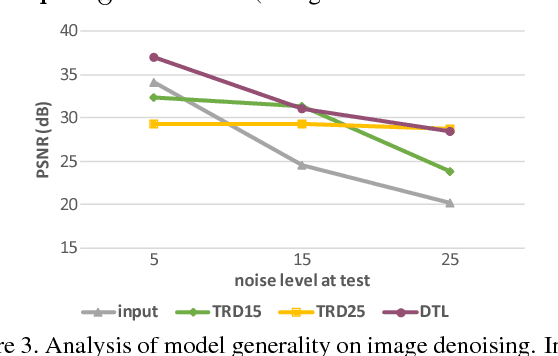
Recently, several discriminative learning approaches have been proposed for effective image restoration, achieving convincing trade-off between image quality and computational efficiency. However, these methods require separate training for each restoration task (e.g., denoising, deblurring, demosaicing) and problem condition (e.g., noise level of input images). This makes it time-consuming and difficult to encompass all tasks and conditions during training. In this paper, we propose a discriminative transfer learning method that incorporates formal proximal optimization and discriminative learning for general image restoration. The method requires a single-pass training and allows for reuse across various problems and conditions while achieving an efficiency comparable to previous discriminative approaches. Furthermore, after being trained, our model can be easily transferred to new likelihood terms to solve untrained tasks, or be combined with existing priors to further improve image restoration quality.