 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast digital refocusing and depth of field extended Fourier ptychography microscopy
May 06, 2021
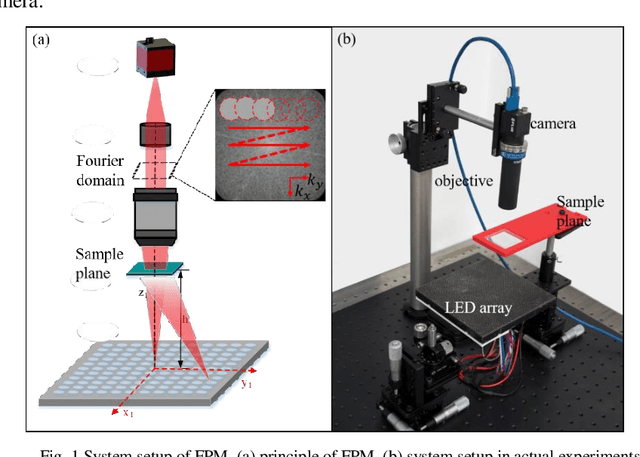
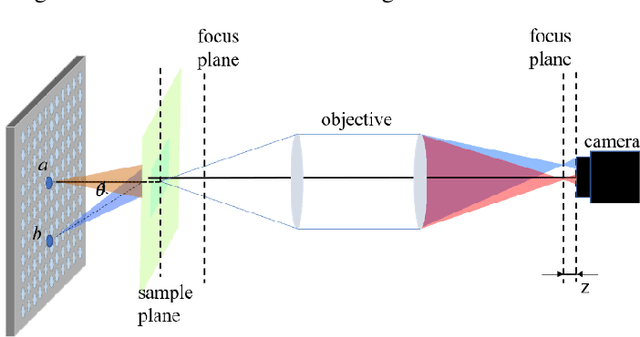
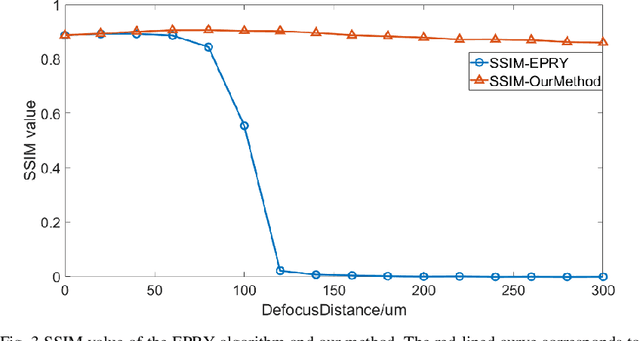

Fourier ptychography microscopy (FPM), sharing its roots with synthetic aperture technique and phase retrieval method, is a recently developed computational microscopic super-resolution technique. By turning on the light-emitting diode (LED) elements sequentially and acquiring the corresponding images that contain different spatial frequencies, FPM can achieve a wide field-of-view (FOV), high-spatial-resolution imaging, and phase recovery simultaneously. Conventional FPM assumes that the sample is sufficiently thin and strictly in focus. Nevertheless, even for a relatively thin sample, the non-planar distribution characteristics and the non-ideal position/posture of the sample will cause all or part of FOV to be defocused. In this paper, we proposed a fast digital refocusing and depth-of-field (DOF) extended FPM strategy by taking the advantages of image lateral shift caused by sample defocusing and varied-angle illuminations. The lateral shift amount is proportional to the defocus distance and the tangent of the illumination angle. Instead of searching the optimal defocus distance in optimization strategy, which is time-consuming, the defocus distance of each subregion of the sample can be precisely and quickly obtained by calculating the relative lateral shift amounts corresponding to different oblique illuminations. And then, the digital refocusing strategy rooting in the Fresnel propagator is integrated into the FPM framework to achieve the high-resolution and phase information reconstruction for each part of the sample, which means the DOF the FPM is effectively extended. The feasibility of the proposed method in fast digital refocusing and FOV extending is verified in the actual experiments with the USAF chart and biological samples.
Noisy Labels Can Induce Good Representations
Dec 23, 2020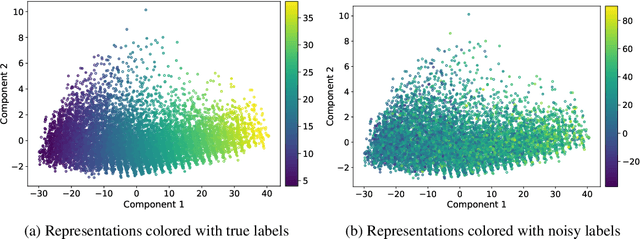

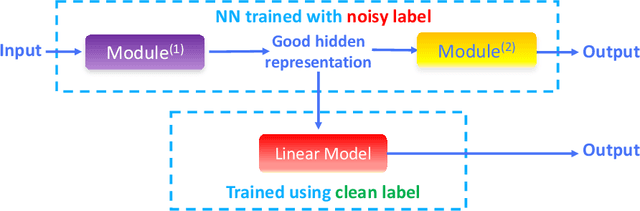
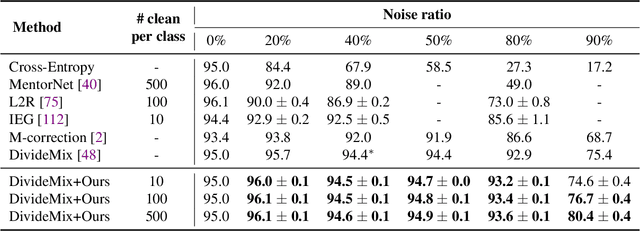
The current success of deep learning depends on large-scale labeled datasets. In practice, high-quality annotations are expensive to collect, but noisy annotations are more affordable. Previous works report mixed empirical results when training with noisy labels: neural networks can easily memorize random labels, but they can also generalize from noisy labels. To explain this puzzle, we study how architecture affects learning with noisy labels. We observe that if an architecture "suits" the task, training with noisy labels can induce useful hidden representations, even when the model generalizes poorly; i.e., the last few layers of the model are more negatively affected by noisy labels. This finding leads to a simple method to improve models trained on noisy labels: replacing the final dense layers with a linear model, whose weights are learned from a small set of clean data. We empirically validate our findings across three architectures (Convolutional Neural Networks, Graph Neural Networks, and Multi-Layer Perceptrons) and two domains (graph algorithmic tasks and image classification). Furthermore, we achieve state-of-the-art results on image classification benchmarks by combining our method with existing approaches on noisy label training.
Anti-Adversarially Manipulated Attributions for Weakly and Semi-Supervised Semantic Segmentation
Mar 16, 2021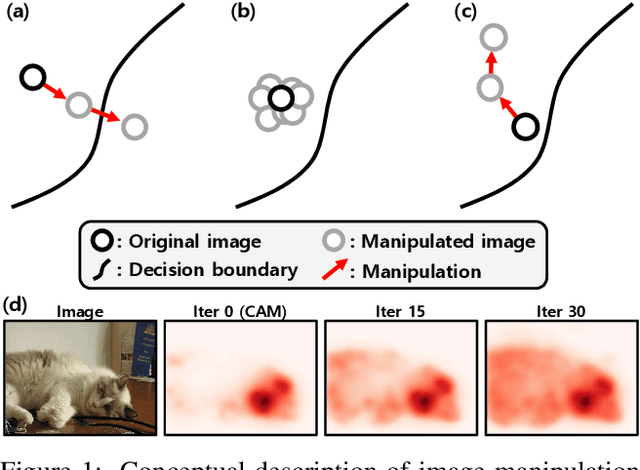
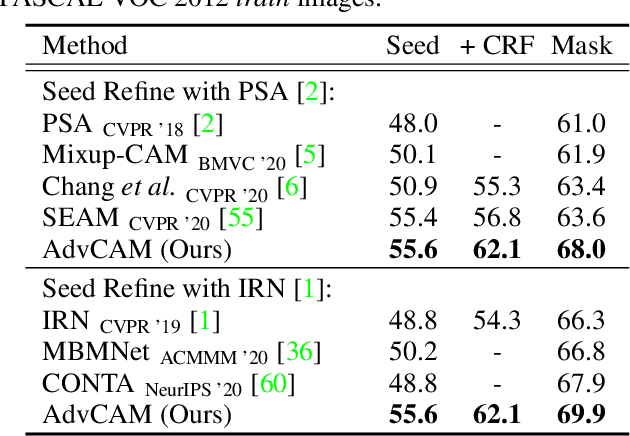
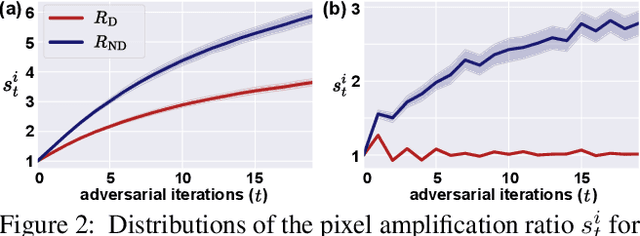
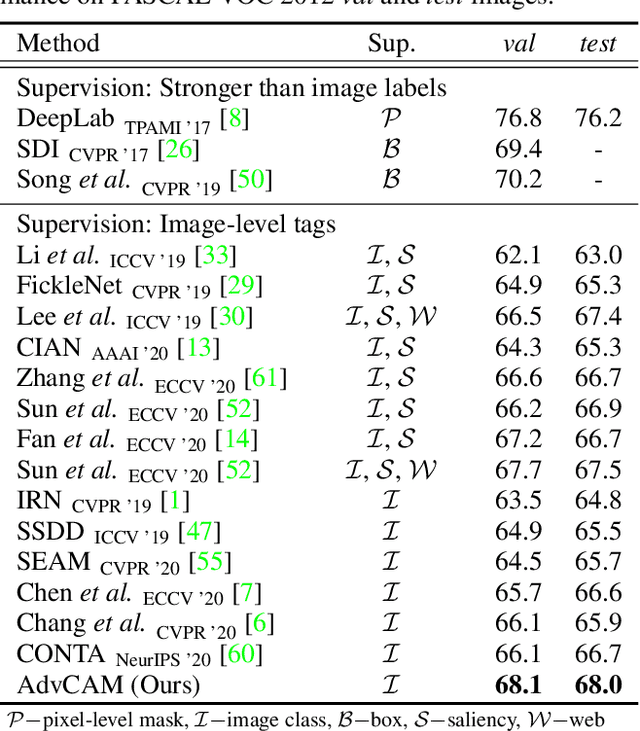
Weakly supervised semantic segmentation produces a pixel-level localization from a classifier, but it is likely to restrict its focus to a small discriminative region of the target object. AdvCAM is an attribution map of an image that is manipulated to increase the classification score. This manipulation is realized in an anti-adversarial manner, which perturbs the images along pixel gradients in the opposite direction from those used in an adversarial attack. It forces regions initially considered not to be discriminative to become involved in subsequent classifications, and produces attribution maps that successively identify more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and limits the attributions of the regions that already have high scores. On PASCAL VOC 2012 test images, we achieve mIoUs of 68.0 and 76.9 for weakly and semi-supervised semantic segmentation respectively, which represent a new state-of-the-art.
A Partially Reversible U-Net for Memory-Efficient Volumetric Image Segmentation
Jun 20, 2019
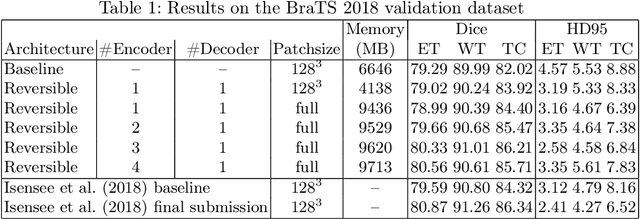

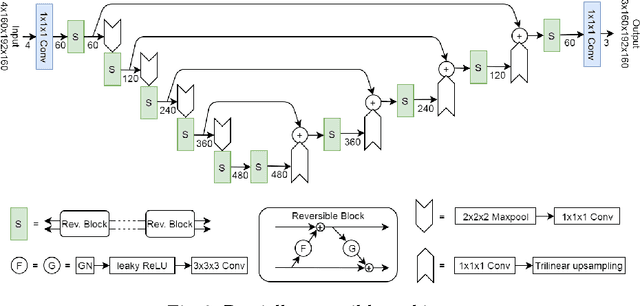
One of the key drawbacks of 3D convolutional neural networks for segmentation is their memory footprint, which necessitates compromises in the network architecture in order to fit into a given memory budget. Motivated by the RevNet for image classification, we propose a partially reversible U-Net architecture that reduces memory consumption substantially. The reversible architecture allows us to exactly recover each layer's outputs from the subsequent layer's ones, eliminating the need to store activations for backpropagation. This alleviates the biggest memory bottleneck and enables very deep (theoretically infinitely deep) 3D architectures. On the BraTS challenge dataset, we demonstrate substantial memory savings. We further show that the freed memory can be used for processing the whole field-of-view (FOV) instead of patches. Increasing network depth led to higher segmentation accuracy while growing the memory footprint only by a very small fraction, thanks to the partially reversible architecture.
A Conglomerate of Multiple OCR Table Detection and Extraction
Oct 16, 2020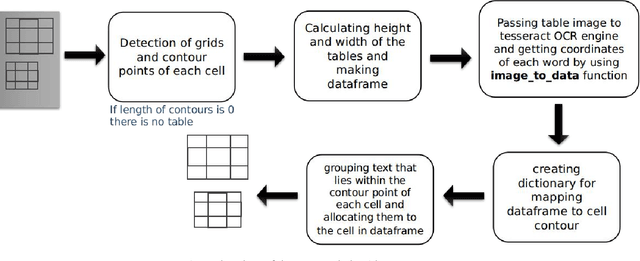
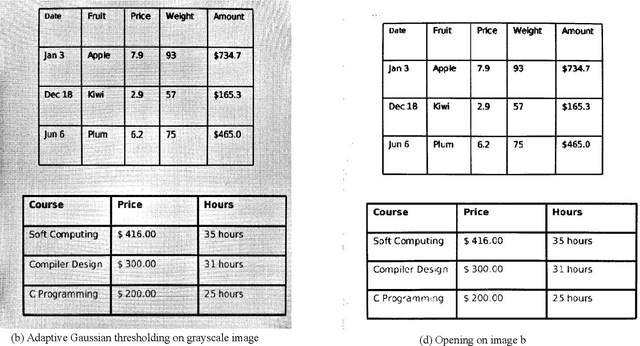
Information representation as tables are compact and concise method that eases searching, indexing, and storage requirements. Extracting and cloning tables from parsable documents is easier and widely used, however industry still faces challenge in detecting and extracting tables from OCR documents or images. This paper proposes an algorithm that detects and extracts multiple tables from OCR document. The algorithm uses a combination of image processing techniques, text recognition and procedural coding to identify distinct tables in same image and map the text to appropriate corresponding cell in dataframe which can be stored as Comma-separated values, Database, Excel and multiple other usable formats.
Robust Rational Polynomial Camera Modelling for SAR and Pushbroom Imaging
Feb 26, 2021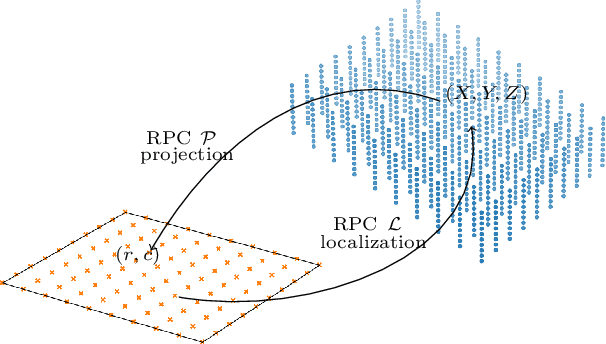
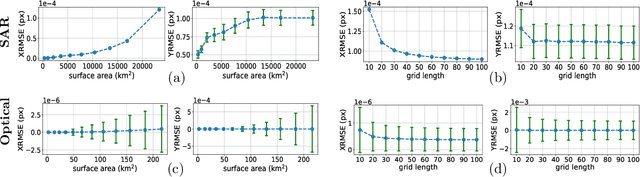
The Rational Polynomial Camera (RPC) model can be used to describe a variety of image acquisition systems in remote sensing, notably optical and Synthetic Aperture Radar (SAR) sensors. RPC functions relate 3D to 2D coordinates and vice versa, regardless of physical sensor specificities, which has made them an essential tool to harness satellite images in a generic way. This article describes a terrain-independent algorithm to accurately derive a RPC model from a set of 3D-2D point correspondences based on a regularized least squares fit. The performance of the method is assessed by varying the point correspondences and the size of the area that they cover. We test the algorithm on SAR and optical data, to derive RPCs from physical sensor models or from other RPC models after composition with corrective functions.
A Closer Look at Self-training for Zero-Label Semantic Segmentation
Apr 21, 2021
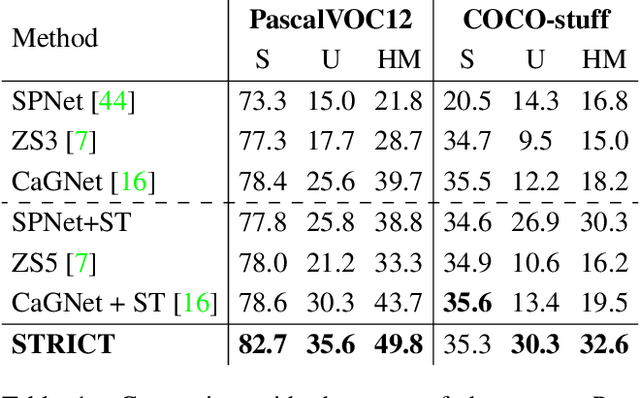
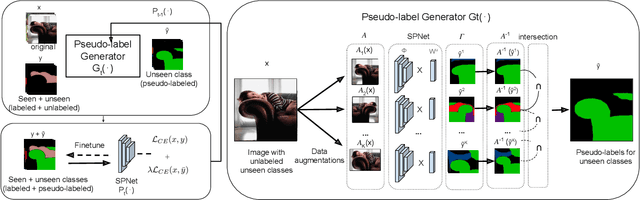
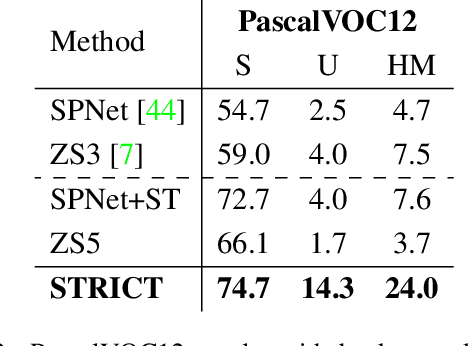
Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.
Weather and Light Level Classification for Autonomous Driving: Dataset, Baseline and Active Learning
Apr 28, 2021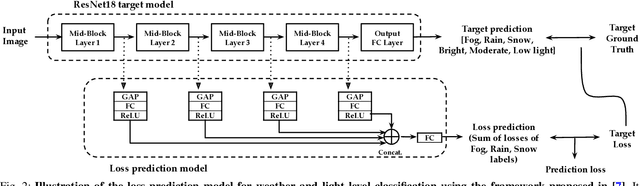
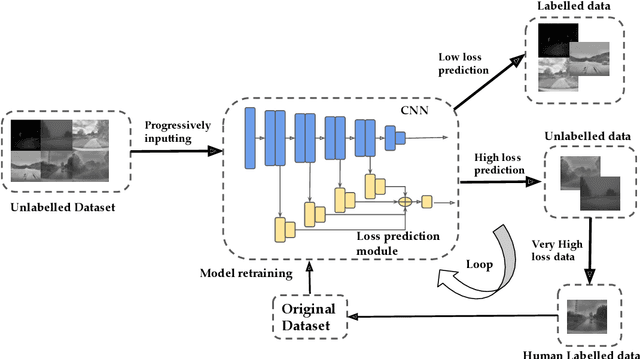
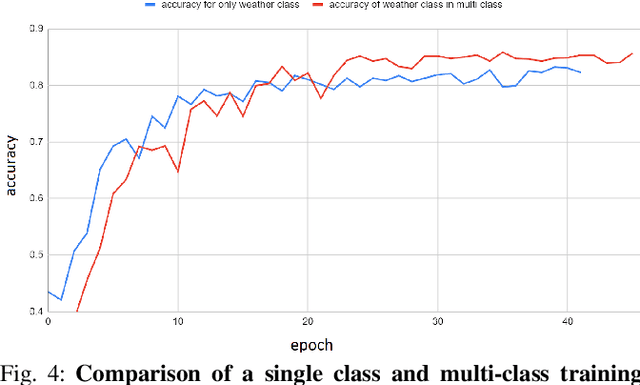
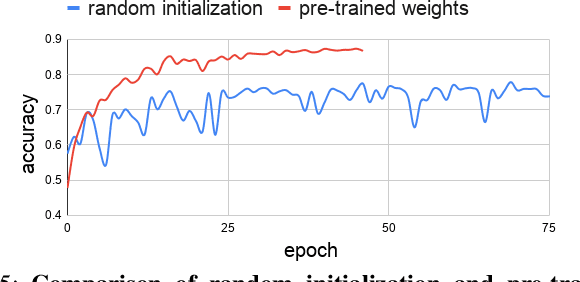
Autonomous driving is rapidly advancing, and Level 2 functions are becoming a standard feature. One of the foremost outstanding hurdles is to obtain robust visual perception in harsh weather and low light conditions where accuracy degradation is severe. It is critical to have a weather classification model to decrease visual perception confidence during these scenarios. Thus, we have built a new dataset for weather (fog, rain, and snow) classification and light level (bright, moderate, and low) classification. Furthermore, we provide street type (asphalt, grass, and cobblestone) classification, leading to 9 labels. Each image has three labels corresponding to weather, light level, and street type. We recorded the data utilizing an industrial front camera of RCCC (red/clear) format with a resolution of $1024\times1084$. We collected 15k video sequences and sampled 60k images. We implement an active learning framework to reduce the dataset's redundancy and find the optimal set of frames for training a model. We distilled the 60k images further to 1.1k images, which will be shared publicly after privacy anonymization. There is no public dataset for weather and light level classification focused on autonomous driving to the best of our knowledge. The baseline ResNet18 network used for weather classification achieves state-of-the-art results in two non-automotive weather classification public datasets but significantly lower accuracy on our proposed dataset, demonstrating it is not saturated and needs further research.
Patch-based Evaluation of Dense Image Matching Quality
Jul 25, 2018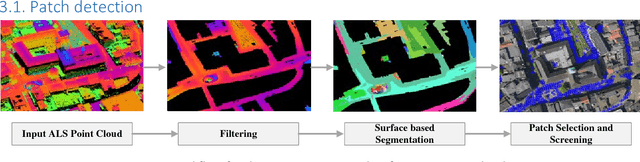

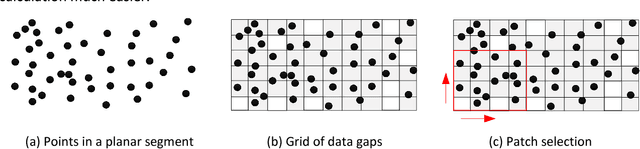

Airborne laser scanning and photogrammetry are two main techniques to obtain 3D data representing the object surface. Due to the high cost of laser scanning, we want to explore the potential of using point clouds derived by dense image matching (DIM), as effective alternatives to laser scanning data. We present a framework to evaluate point clouds from dense image matching and derived Digital Surface Models (DSM) based on automatically extracted sample patches. Dense matching error and noise level are evaluated quantitatively at both the local level and whole block level. Experiments show that the optimal vertical accuracy achieved by dense matching is as follows: the mean offset to the reference data is 0.1 Ground Sampling Distance (GSD); the maximum offset goes up to 1.0 GSD. When additional oblique images are used in dense matching, the mean deviation, the variation of mean deviation and the level of random noise all get improved. We also detect a bias between the point cloud and DSM from a single photogrammetric workflow. This framework also allows to reveal inhomogeneity in the distribution of the dense matching errors due to over-fitted BBA network. Meanwhile, suggestions are given on the photogrammetric quality control.
* 16 pages
Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
Apr 13, 2021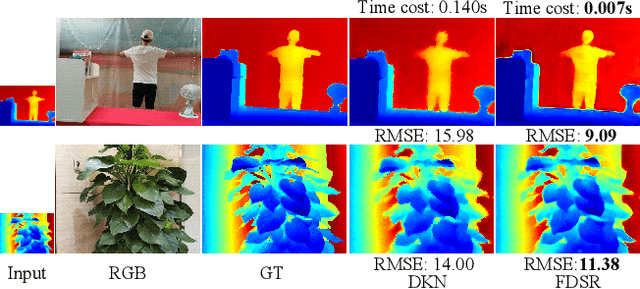


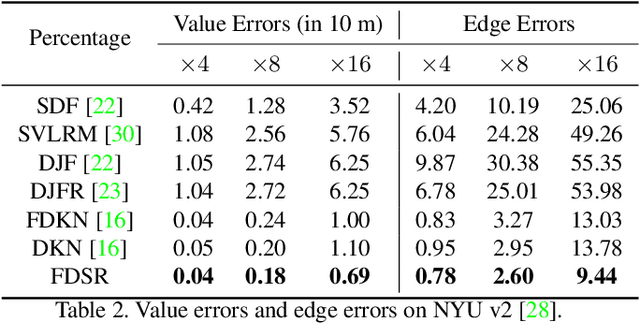
Depth maps obtained by commercial depth sensors are always in low-resolution, making it difficult to be used in various computer vision tasks. Thus, depth map super-resolution (SR) is a practical and valuable task, which upscales the depth map into high-resolution (HR) space. However, limited by the lack of real-world paired low-resolution (LR) and HR depth maps, most existing methods use downsampling to obtain paired training samples. To this end, we first construct a large-scale dataset named "RGB-D-D", which can greatly promote the study of depth map SR and even more depth-related real-world tasks. The "D-D" in our dataset represents the paired LR and HR depth maps captured from mobile phone and Lucid Helios respectively ranging from indoor scenes to challenging outdoor scenes. Besides, we provide a fast depth map super-resolution (FDSR) baseline, in which the high-frequency component adaptively decomposed from RGB image to guide the depth map SR. Extensive experiments on existing public datasets demonstrate the effectiveness and efficiency of our network compared with the state-of-the-art methods. Moreover, for the real-world LR depth maps, our algorithm can produce more accurate HR depth maps with clearer boundaries and to some extent correct the depth value errors.