 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Superpixels and Graph Convolutional Neural Networks for Efficient Detection of Nutrient Deficiency Stress from Aerial Imagery
Apr 22, 2021
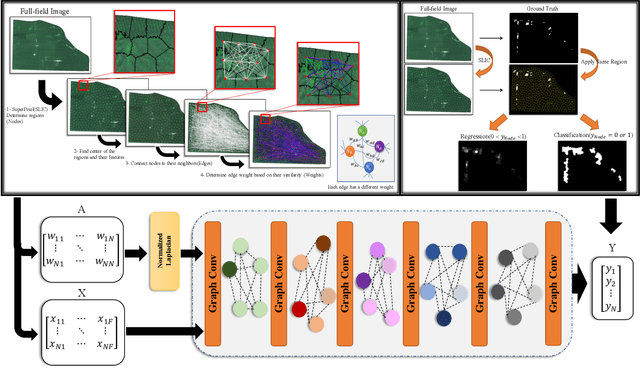



Advances in remote sensing technology have led to the capture of massive amounts of data. Increased image resolution, more frequent revisit times, and additional spectral channels have created an explosion in the amount of data that is available to provide analyses and intelligence across domains, including agriculture. However, the processing of this data comes with a cost in terms of computation time and money, both of which must be considered when the goal of an algorithm is to provide real-time intelligence to improve efficiencies. Specifically, we seek to identify nutrient deficient areas from remotely sensed data to alert farmers to regions that require attention; detection of nutrient deficient areas is a key task in precision agriculture as farmers must quickly respond to struggling areas to protect their harvests. Past methods have focused on pixel-level classification (i.e. semantic segmentation) of the field to achieve these tasks, often using deep learning models with tens-of-millions of parameters. In contrast, we propose a much lighter graph-based method to perform node-based classification. We first use Simple Linear Iterative Cluster (SLIC) to produce superpixels across the field. Then, to perform segmentation across the non-Euclidean domain of superpixels, we leverage a Graph Convolutional Neural Network (GCN). This model has 4-orders-of-magnitude fewer parameters than a CNN model and trains in a matter of minutes.
Astronomical image reconstruction with convolutional neural networks
Jun 07, 2017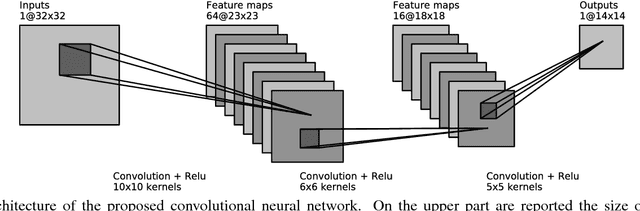
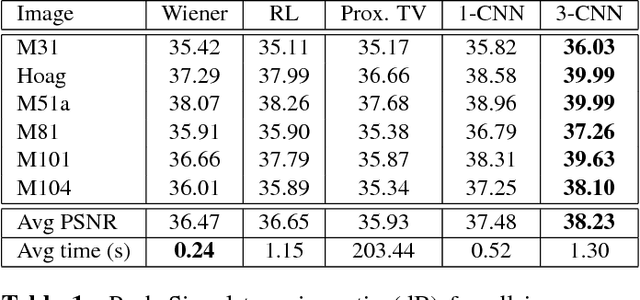


State of the art methods in astronomical image reconstruction rely on the resolution of a regularized or constrained optimization problem. Solving this problem can be computationally intensive and usually leads to a quadratic or at least superlinear complexity w.r.t. the number of pixels in the image. We investigate in this work the use of convolutional neural networks for image reconstruction in astronomy. With neural networks, the computationally intensive tasks is the training step, but the prediction step has a fixed complexity per pixel, i.e. a linear complexity. Numerical experiments show that our approach is both computationally efficient and competitive with other state of the art methods in addition to being interpretable.
Artist, Style And Year Classification Using Face Recognition And Clustering With Convolutional Neural Networks
Dec 02, 2020
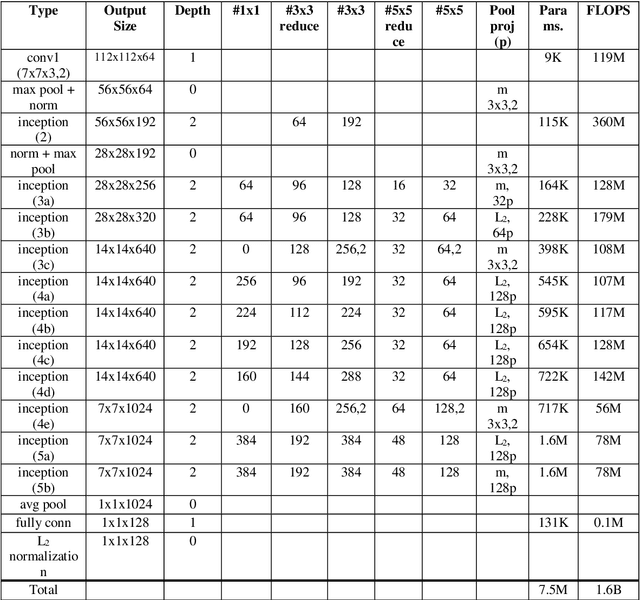

Artist, year and style classification of fine-art paintings are generally achieved using standard image classification methods, image segmentation, or more recently, convolutional neural networks (CNNs). This works aims to use newly developed face recognition methods such as FaceNet that use CNNs to cluster fine-art paintings using the extracted faces in the paintings, which are found abundantly. A dataset consisting of over 80,000 paintings from over 1000 artists is chosen, and three separate face recognition and clustering tasks are performed. The produced clusters are analyzed by the file names of the paintings and the clusters are named by their majority artist, year range, and style. The clusters are further analyzed and their performance metrics are calculated. The study shows promising results as the artist, year, and styles are clustered with an accuracy of 58.8, 63.7, and 81.3 percent, while the clusters have an average purity of 63.1, 72.4, and 85.9 percent.
Fast digital refocusing and depth of field extended Fourier ptychography microscopy
May 06, 2021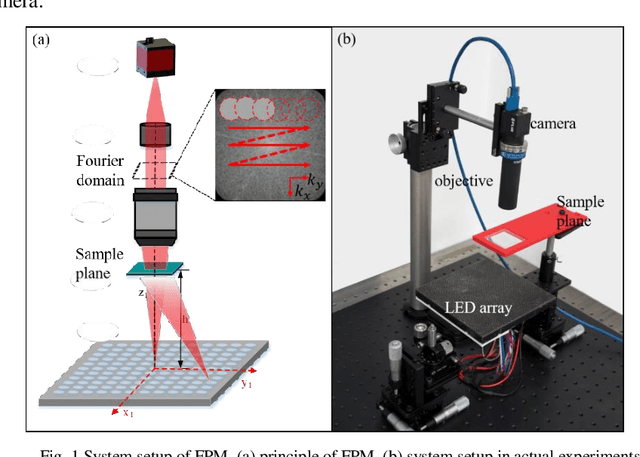
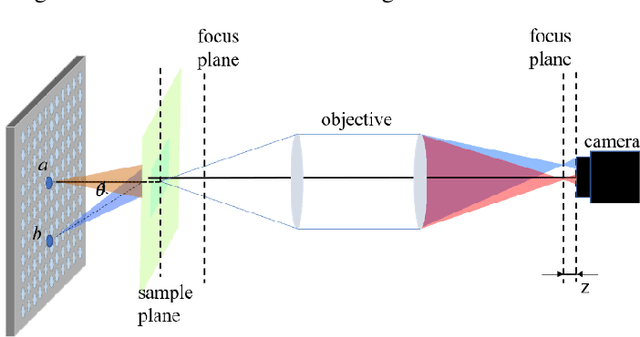
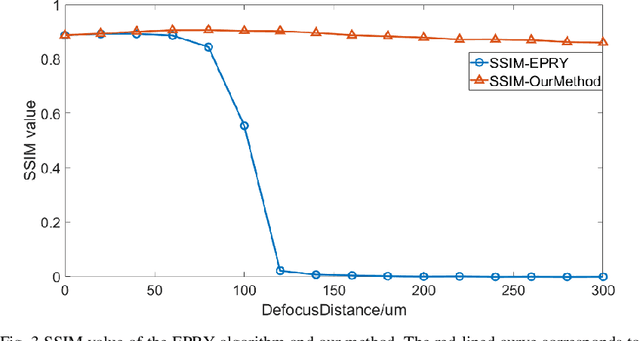

Fourier ptychography microscopy (FPM), sharing its roots with synthetic aperture technique and phase retrieval method, is a recently developed computational microscopic super-resolution technique. By turning on the light-emitting diode (LED) elements sequentially and acquiring the corresponding images that contain different spatial frequencies, FPM can achieve a wide field-of-view (FOV), high-spatial-resolution imaging, and phase recovery simultaneously. Conventional FPM assumes that the sample is sufficiently thin and strictly in focus. Nevertheless, even for a relatively thin sample, the non-planar distribution characteristics and the non-ideal position/posture of the sample will cause all or part of FOV to be defocused. In this paper, we proposed a fast digital refocusing and depth-of-field (DOF) extended FPM strategy by taking the advantages of image lateral shift caused by sample defocusing and varied-angle illuminations. The lateral shift amount is proportional to the defocus distance and the tangent of the illumination angle. Instead of searching the optimal defocus distance in optimization strategy, which is time-consuming, the defocus distance of each subregion of the sample can be precisely and quickly obtained by calculating the relative lateral shift amounts corresponding to different oblique illuminations. And then, the digital refocusing strategy rooting in the Fresnel propagator is integrated into the FPM framework to achieve the high-resolution and phase information reconstruction for each part of the sample, which means the DOF the FPM is effectively extended. The feasibility of the proposed method in fast digital refocusing and FOV extending is verified in the actual experiments with the USAF chart and biological samples.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018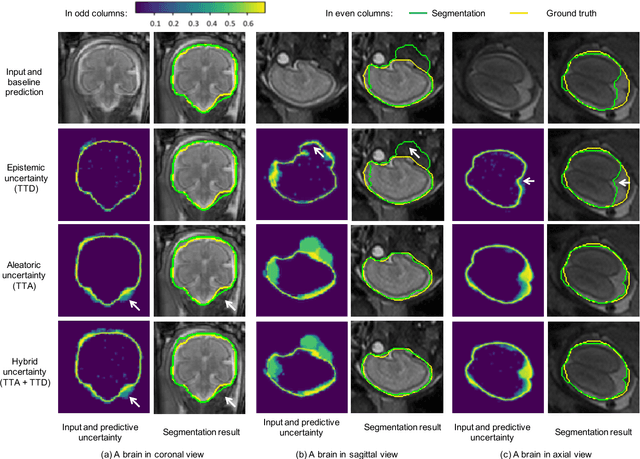
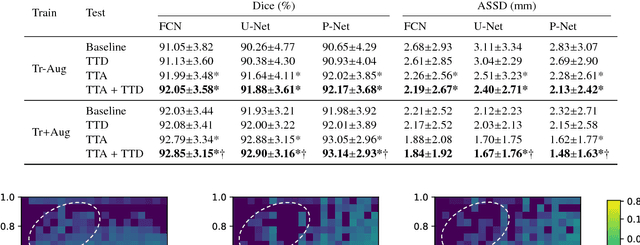
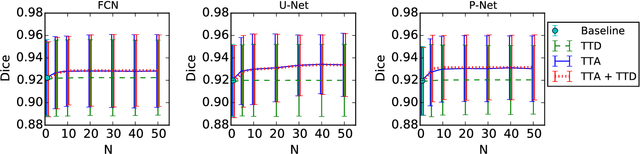
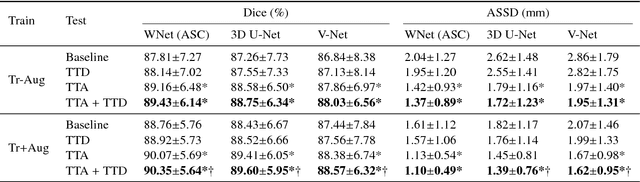
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.
The Cube++ Illumination Estimation Dataset
Nov 19, 2020
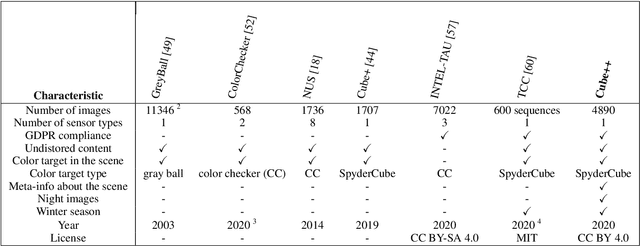

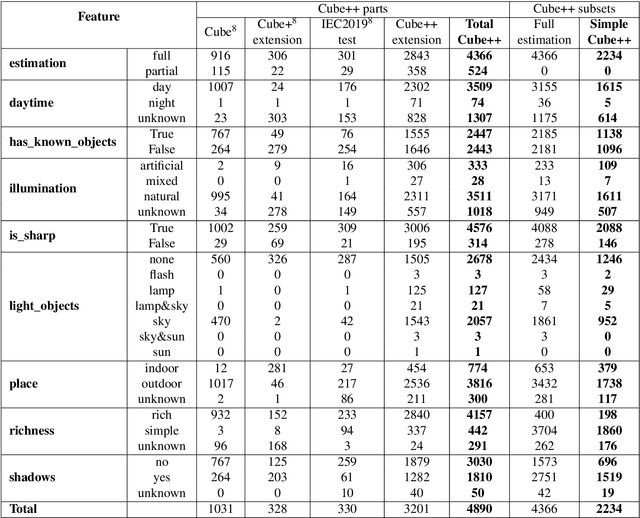
Computational color constancy has the important task of reducing the influence of the scene illumination on the object colors. As such, it is an essential part of the image processing pipelines of most digital cameras. One of the important parts of the computational color constancy is illumination estimation, i.e. estimating the illumination color. When an illumination estimation method is proposed, its accuracy is usually reported by providing the values of error metrics obtained on the images of publicly available datasets. However, over time it has been shown that many of these datasets have problems such as too few images, inappropriate image quality, lack of scene diversity, absence of version tracking, violation of various assumptions, GDPR regulation violation, lack of additional shooting procedure info, etc. In this paper, a new illumination estimation dataset is proposed that aims to alleviate many of the mentioned problems and to help the illumination estimation research. It consists of 4890 images with known illumination colors as well as with additional semantic data that can further make the learning process more accurate. Due to the usage of the SpyderCube color target, for every image there are two ground-truth illumination records covering different directions. Because of that, the dataset can be used for training and testing of methods that perform single or two-illuminant estimation. This makes it superior to many similar existing datasets. The datasets, it's smaller version SimpleCube++, and the accompanying code are available at https://github.com/Visillect/CubePlusPlus/.
Anti-Adversarially Manipulated Attributions for Weakly and Semi-Supervised Semantic Segmentation
Mar 16, 2021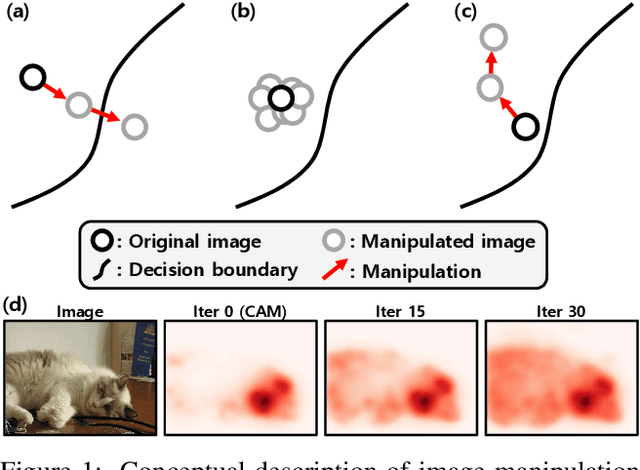
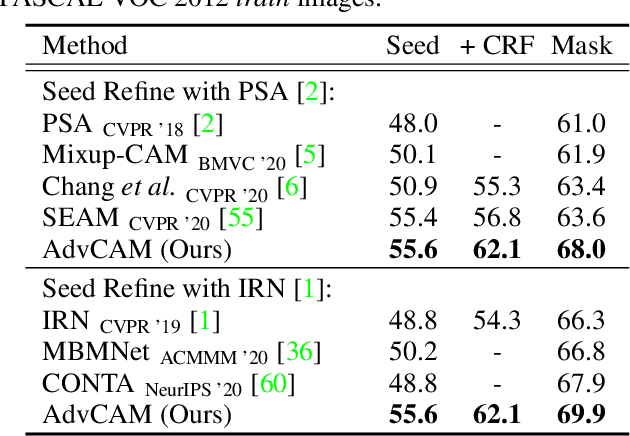
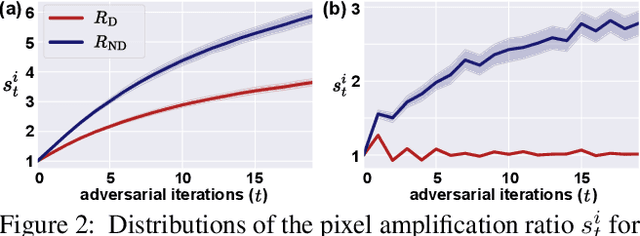
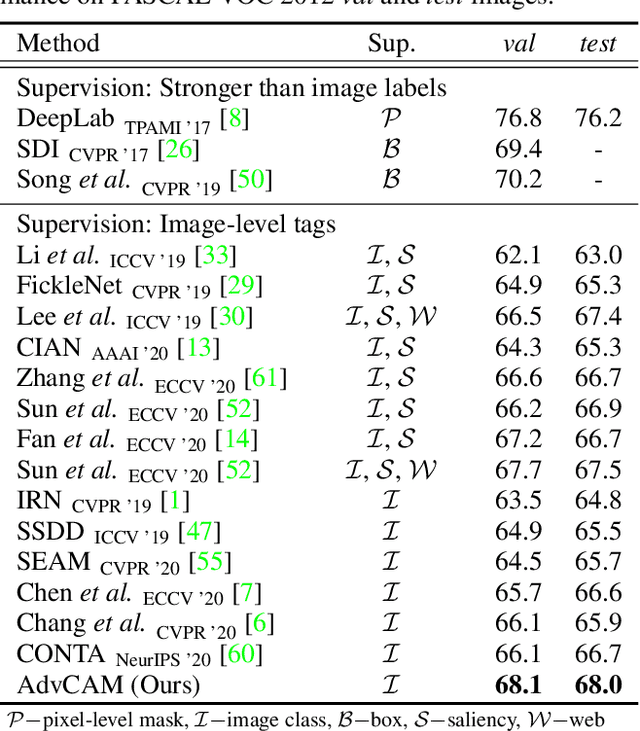
Weakly supervised semantic segmentation produces a pixel-level localization from a classifier, but it is likely to restrict its focus to a small discriminative region of the target object. AdvCAM is an attribution map of an image that is manipulated to increase the classification score. This manipulation is realized in an anti-adversarial manner, which perturbs the images along pixel gradients in the opposite direction from those used in an adversarial attack. It forces regions initially considered not to be discriminative to become involved in subsequent classifications, and produces attribution maps that successively identify more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and limits the attributions of the regions that already have high scores. On PASCAL VOC 2012 test images, we achieve mIoUs of 68.0 and 76.9 for weakly and semi-supervised semantic segmentation respectively, which represent a new state-of-the-art.
Deep Networks for Compressed Image Sensing
Jul 22, 2017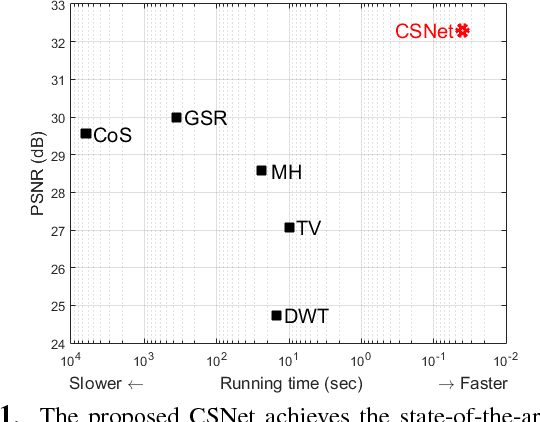
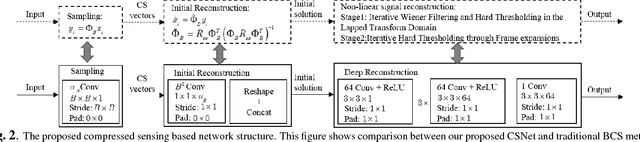
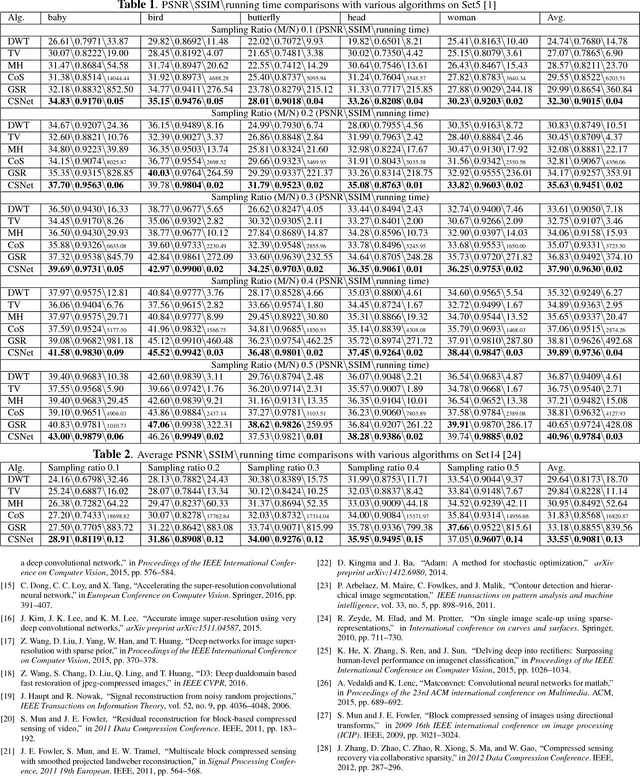
The compressed sensing (CS) theory has been successfully applied to image compression in the past few years as most image signals are sparse in a certain domain. Several CS reconstruction models have been recently proposed and obtained superior performance. However, there still exist two important challenges within the CS theory. The first one is how to design a sampling mechanism to achieve an optimal sampling efficiency, and the second one is how to perform the reconstruction to get the highest quality to achieve an optimal signal recovery. In this paper, we try to deal with these two problems with a deep network. First of all, we train a sampling matrix via the network training instead of using a traditional manually designed one, which is much appropriate for our deep network based reconstruct process. Then, we propose a deep network to recover the image, which imitates traditional compressed sensing reconstruction processes. Experimental results demonstrate that our deep networks based CS reconstruction method offers a very significant quality improvement compared against state of the art ones.
Scientific image rendering for space scenes with the SurRender software
Oct 02, 2018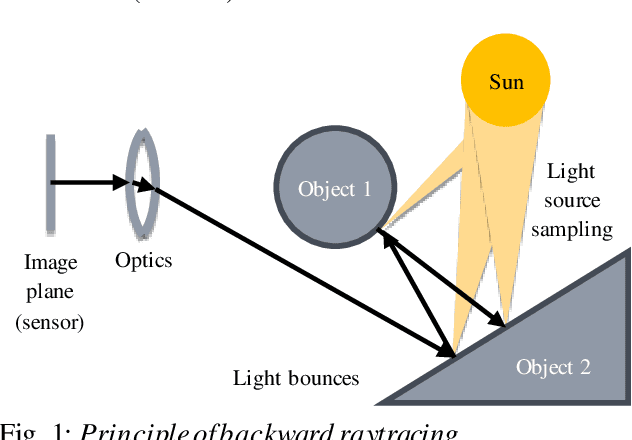



Spacecraft autonomy can be enhanced by vision-based navigation (VBN) techniques. Applications range from manoeuvers around Solar System objects and landing on planetary surfaces, to in-orbit servicing or space debris removal. The development and validation of VBN algorithms relies on the availability of physically accurate relevant images. Yet archival data from past missions can rarely serve this purpose and acquiring new data is often costly. The SurRender software is an image simulator that addresses the challenges of realistic image rendering, with high representativeness for space scenes. Images are rendered by raytracing, which implements the physical principles of geometrical light propagation, in physical units. A macroscopic instrument model and scene objects reflectance functions are used. SurRender is specially optimized for space scenes, with huge distances between objects and scenes up to Solar System size. Raytracing conveniently tackles some important effects for VBN algorithms: image quality, eclipses, secondary illumination, subpixel limb imaging, etc. A simulation is easily setup (in MATLAB, Python, and more) by specifying the position of the bodies (camera, Sun, planets, satellites) over time, 3D shapes and material surface properties. SurRender comes with its own modelling tool enabling to go beyond existing models for shapes, materials and sensors (projection, temporal sampling, electronics, etc.). It is natively designed to simulate different kinds of sensors (visible, LIDAR, etc.). Tools are available for manipulating huge datasets to store albedo maps and digital elevation models, or for procedural (fractal) texturing that generates high-quality images for a large range of observing distances (from millions of km to touchdown). We illustrate SurRender performances with a selection of case studies, placing particular emphasis on a 900-km Moon flyby simulation.
Image2song: Song Retrieval via Bridging Image Content and Lyric Words
Aug 19, 2017

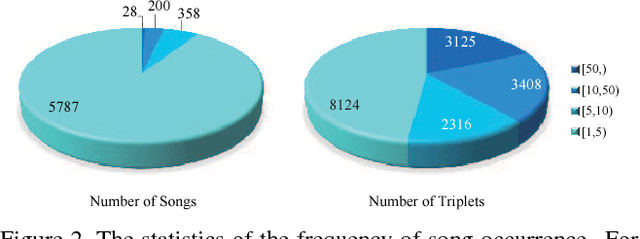
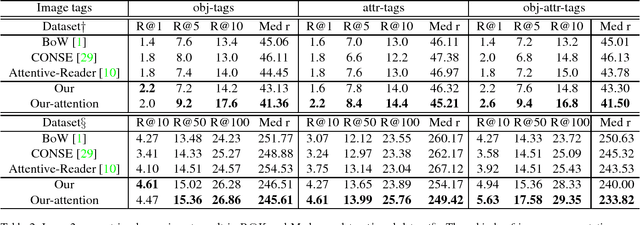
Image is usually taken for expressing some kinds of emotions or purposes, such as love, celebrating Christmas. There is another better way that combines the image and relevant song to amplify the expression, which has drawn much attention in the social network recently. Hence, the automatic selection of songs should be expected. In this paper, we propose to retrieve semantic relevant songs just by an image query, which is named as the image2song problem. Motivated by the requirements of establishing correlation in semantic/content, we build a semantic-based song retrieval framework, which learns the correlation between image content and lyric words. This model uses a convolutional neural network to generate rich tags from image regions, a recurrent neural network to model lyric, and then establishes correlation via a multi-layer perceptron. To reduce the content gap between image and lyric, we propose to make the lyric modeling focus on the main image content via a tag attention. We collect a dataset from the social-sharing multimodal data to study the proposed problem, which consists of (image, music clip, lyric) triplets. We demonstrate that our proposed model shows noticeable results in the image2song retrieval task and provides suitable songs. Besides, the song2image task is also performed.