 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Discriminative Multilevel Structured Dictionaries for Supervised Image Classification
Feb 28, 2018
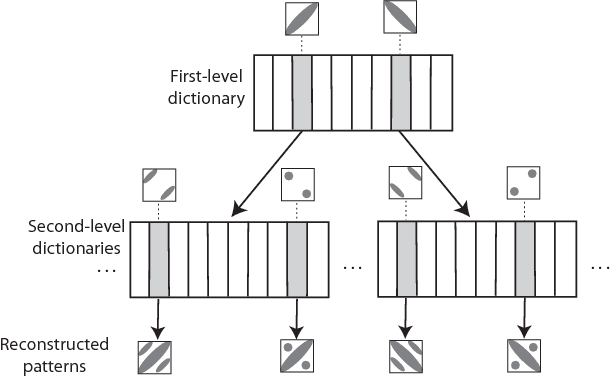


Sparse representations using overcomplete dictionaries have proved to be a powerful tool in many signal processing applications such as denoising, super-resolution, inpainting, compression or classification. The sparsity of the representation very much depends on how well the dictionary is adapted to the data at hand. In this paper, we propose a method for learning structured multilevel dictionaries with discriminative constraints to make them well suited for the supervised pixelwise classification of images. A multilevel tree-structured discriminative dictionary is learnt for each class, with a learning objective concerning the reconstruction errors of the image patches around the pixels over each class-representative dictionary. After the initial assignment of the class labels to image pixels based on their sparse representations over the learnt dictionaries, the final classification is achieved by smoothing the label image with a graph cut method and an erosion method. Applied to a common set of texture images, our supervised classification method shows competitive results with the state of the art.
Improvement of Multiparametric MR Image Segmentation by Augmenting the Data with Generative Adversarial Networks for Glioma Patients
Oct 01, 2019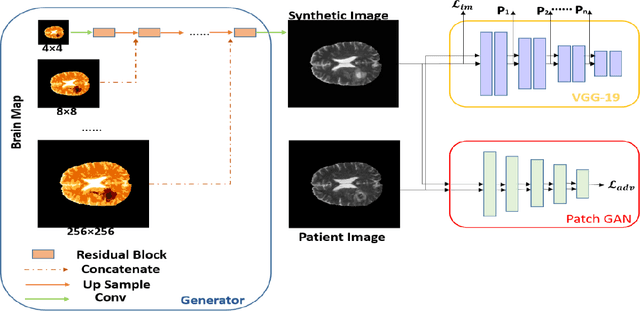
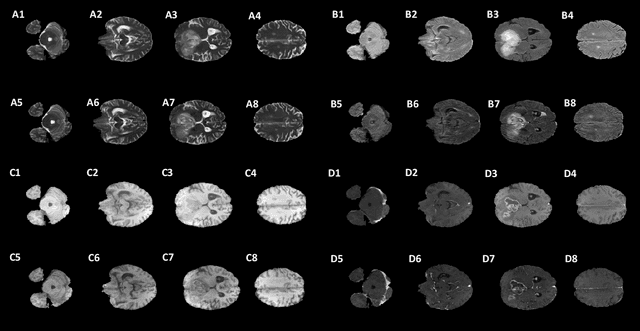
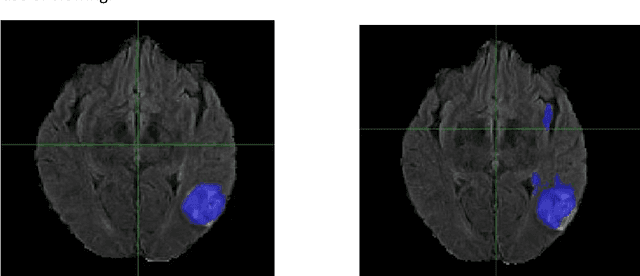
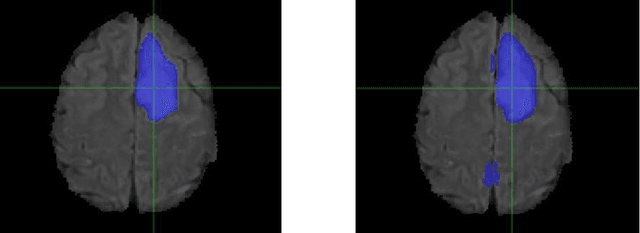
Every year thousands of patients are diagnosed with a glioma, a type of malignant brain tumor. Physicians use MR images as a key tool in the diagnosis and treatment of these patients. Neural networks show great potential to aid physicians in the medical image analysis. This study investigates the use of varying amounts of synthetic brain T1-weighted (T1), post-contrast T1-weighted (T1Gd), T2-weighted (T2), and T2 Fluid Attenuated Inversion Recovery (FLAIR) MR images created by a generative adversarial network to overcome the lack of annotated medical image data in training separate 2D U-Nets to segment enhancing tumor, peritumoral edema, and necrosis (non-enhancing tumor core) regions on gliomas. These synthetic MR images were assessed quantitively (SSIM=0.79) and qualitatively by a physician who found that the synthetic images seem stronger for delineation of structural boundaries but struggle more when gradient is significant, (e.g. edema signal in T2 modalities). Multiple 2D U-Nets were trained with original BraTS data and differing subsets of a quarter, half, three-quarters, and all synthetic MR images. There was not an obvious correlation between the improvement of values of the metrics in separate validation dataset for each structure and amount of synthetic data added, there is a strong correlation between the amount of synthetic data added and the number of best overall validation metrics. In summary, this study showed ability to generate high quality synthetic Flair, T2, T1, and T1CE MR images using the GAN. Using the synthetic MR images showed encouraging results to improve the U-Net segmentation performance which has the potential to address the scarcity of readily available medical images.
Classification of Urban Morphology with Deep Learning: Application on Urban Vitality
May 07, 2021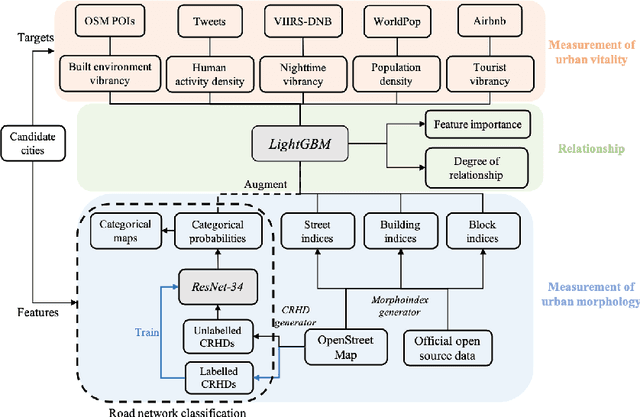
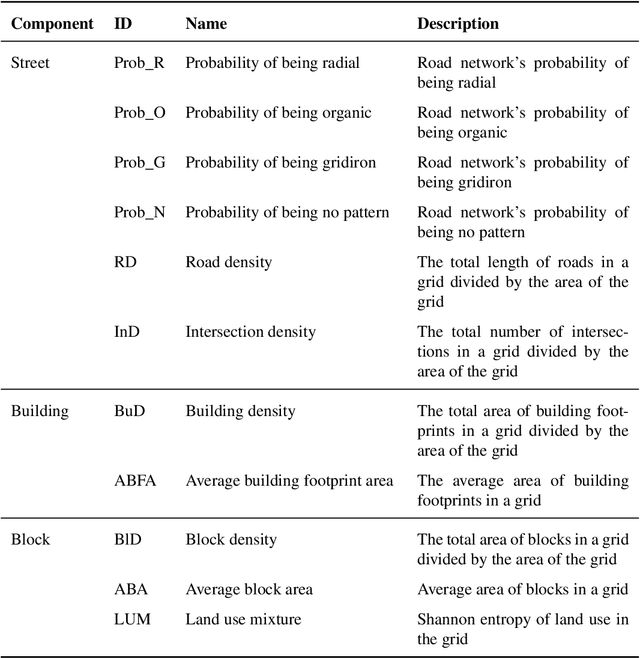
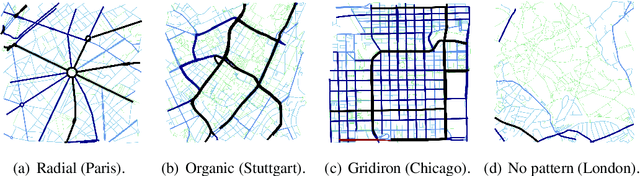
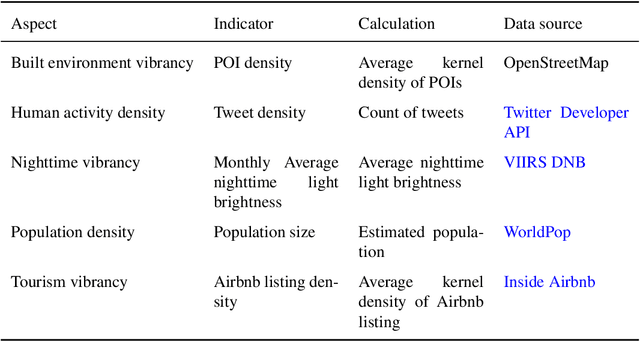
There is a prevailing trend to study urban morphology quantitatively thanks to the growing accessibility to various forms of spatial big data, increasing computing power, and use cases benefiting from such information. The methods developed up to now measure urban morphology with numerical indices describing density, proportion, and mixture, but they do not directly represent morphological features from human's visual and intuitive perspective. We take the first step to bridge the gap by proposing a deep learning-based technique to automatically classify road networks into four classes on a visual basis. The method is implemented by generating an image of the street network (Colored Road Hierarchy Diagram), which we introduce in this paper, and classifying it using a deep convolutional neural network (ResNet-34). The model achieves an overall classification accuracy of 0.875. Nine cities around the world are selected as the study areas and their road networks are acquired from OpenStreetMap. Latent subgroups among the cities are uncovered through a clustering on the percentage of each road network category. In the subsequent part of the paper, we focus on the usability of such classification: the effectiveness of our human perception augmentation is examined by a case study of urban vitality prediction. An advanced tree-based regression model is for the first time designated to establish the relationship between morphological indices and vitality indicators. A positive effect of human perception augmentation is detected in the comparative experiment of baseline model and augmented model. This work expands the toolkit of quantitative urban morphology study with new techniques, supporting further studies in the future.
Learning Deep Similarity Models with Focus Ranking for Fabric Image Retrieval
Dec 29, 2017

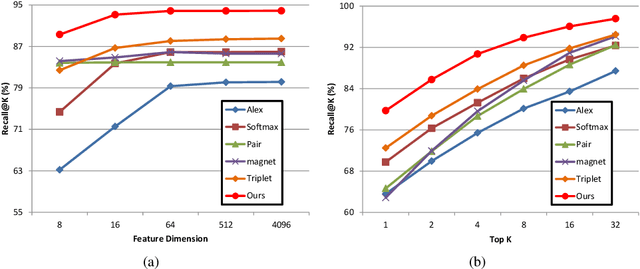
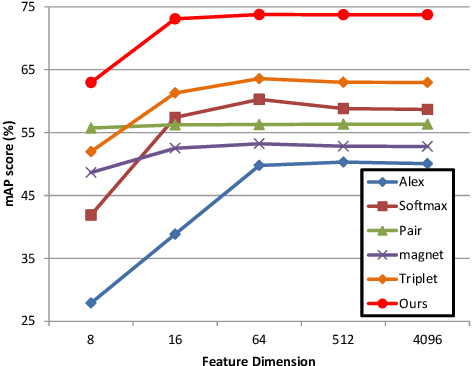
Fabric image retrieval is beneficial to many applications including clothing searching, online shopping and cloth modeling. Learning pairwise image similarity is of great importance to an image retrieval task. With the resurgence of Convolutional Neural Networks (CNNs), recent works have achieved significant progresses via deep representation learning with metric embedding, which drives similar examples close to each other in a feature space, and dissimilar ones apart from each other. In this paper, we propose a novel embedding method termed focus ranking that can be easily unified into a CNN for jointly learning image representations and metrics in the context of fine-grained fabric image retrieval. Focus ranking aims to rank similar examples higher than all dissimilar ones by penalizing ranking disorders via the minimization of the overall cost attributed to similar samples being ranked below dissimilar ones. At the training stage, training samples are organized into focus ranking units for efficient optimization. We build a large-scale fabric image retrieval dataset (FIRD) with about 25,000 images of 4,300 fabrics, and test the proposed model on the FIRD dataset. Experimental results show the superiority of the proposed model over existing metric embedding models.
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis
Apr 15, 2021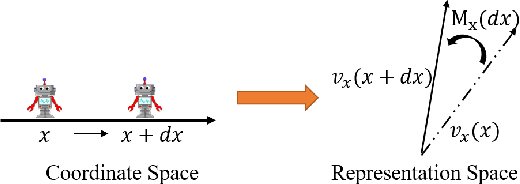
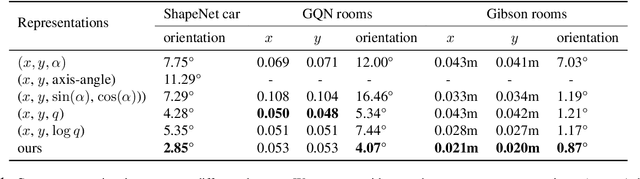
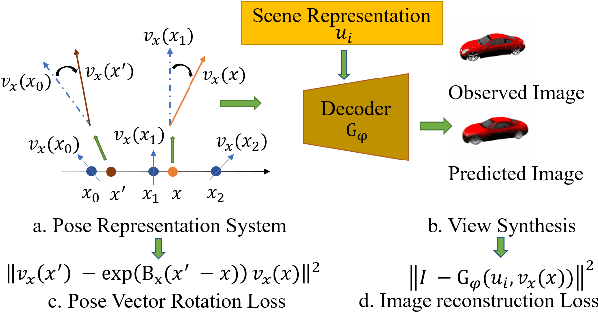
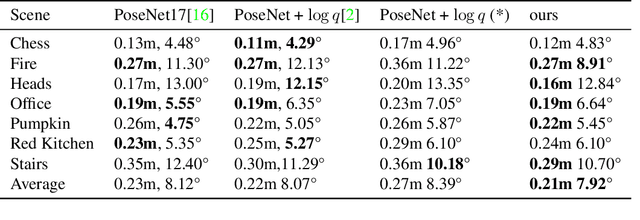
How to effectively represent camera pose is an essential problem in 3D computer vision, especially in tasks such as camera pose regression and novel view synthesis. Traditionally, 3D position of the camera is represented by Cartesian coordinate and the orientation is represented by Euler angle or quaternions. These representations are manually designed, which may not be the most effective representation for downstream tasks. In this work, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements. Specifically, the camera pose and 3D scene are represented as vectors and the local camera movement is represented as a matrix operating on the vector of the camera pose. We demonstrate that the camera movement can further be parametrized by a matrix Lie algebra that underlies a rotation system in the neural space. The vector representations are then concatenated and generate the posed 2D image through a decoder network. The model is learned from only posed 2D images and corresponding camera poses, without access to depths or shapes. We conduct extensive experiments on synthetic and real datasets. The results show that compared with other camera pose representations, our learned representation is more robust to noise in novel view synthesis and more effective in camera pose regression.
Teacher-Student Adversarial Depth Hallucination to Improve Face Recognition
Apr 06, 2021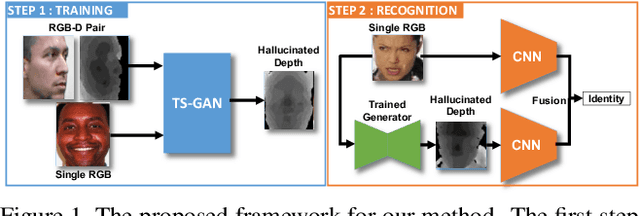
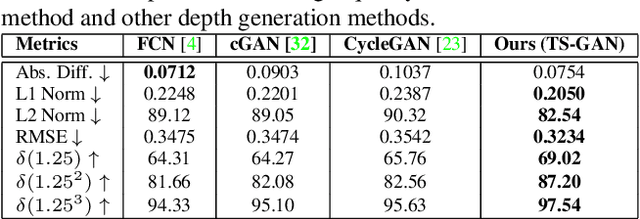
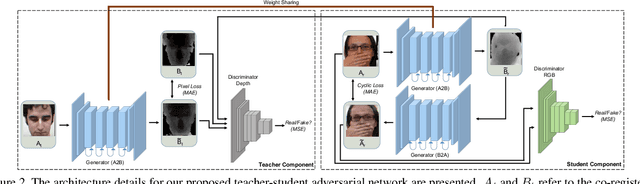
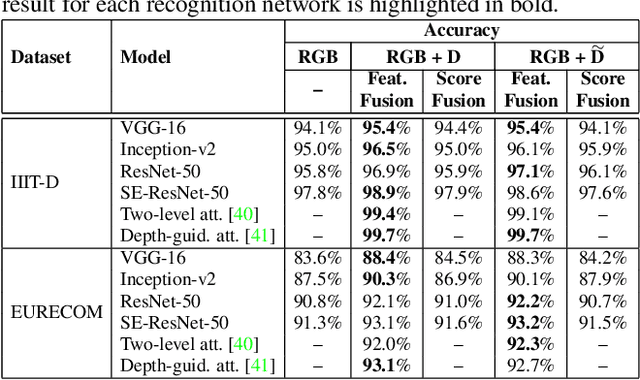
We present the Teacher-Student Generative Adversarial Network (TS-GAN) to generate depth images from a single RGB image in order to boost the recognition accuracy of face recognition (FR) systems. For our method to generalize well across unseen datasets, we design two components in the architecture, a teacher and a student. The teacher, which itself consists of a generator and a discriminator, learns a latent mapping between input RGB and paired depth images in a supervised fashion. The student, which consists of two generators (one shared with the teacher) and a discriminator, learns from new RGB data with no available paired depth information, for improved generalization. The fully trained shared generator can then be used in runtime to hallucinate depth from RGB for downstream applications such as face recognition. We perform rigorous experiments to show the superiority of TS-GAN over other methods in generating synthetic depth images. Moreover, face recognition experiments demonstrate that our hallucinated depth along with the input RGB images boosts performance across various architectures when compared to a single RGB modality by average values of +1.2%, +2.6%, and +2.6% for IIIT-D, EURECOM, and LFW datasets respectively.
HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
Oct 15, 2020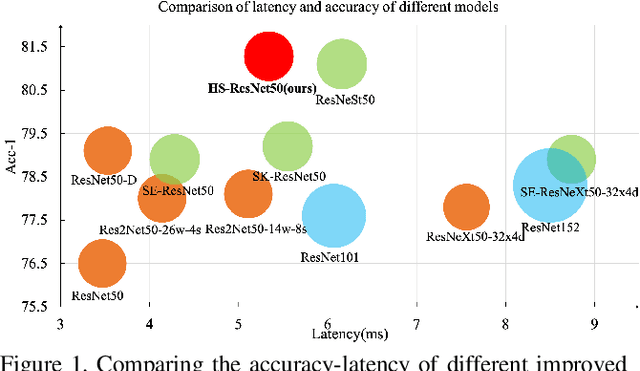
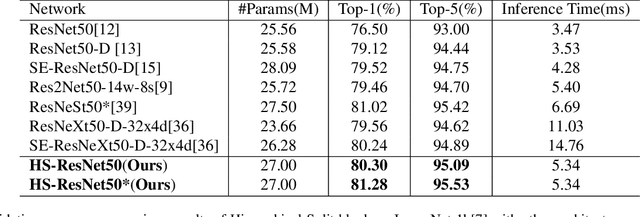
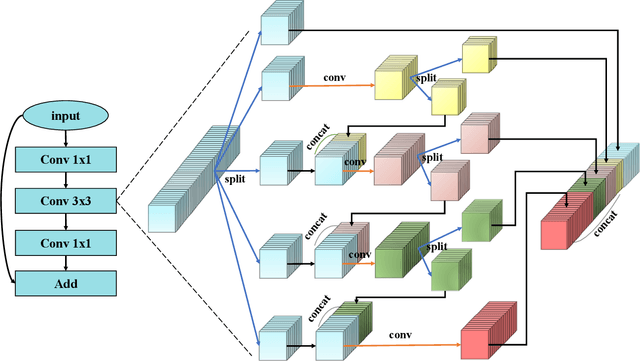

This paper addresses representational block named Hierarchical-Split Block, which can be taken as a plug-and-play block to upgrade existing convolutional neural networks, improves model performance significantly in a network. Hierarchical-Split Block contains many hierarchical split and concatenate connections within one single residual block. We find multi-scale features is of great importance for numerous vision tasks. Moreover, Hierarchical-Split block is very flexible and efficient, which provides a large space of potential network architectures for different applications. In this work, we present a common backbone based on Hierarchical-Split block for tasks: image classification, object detection, instance segmentation and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baseline. As shown in Figure1, for image classification, our 50-layers network(HS-ResNet50) achieves 81.28% top-1 accuracy with competitive latency on ImageNet-1k dataset. It also outperforms most state-of-the-art models. The source code and models will be available on: https://github.com/PaddlePaddle/PaddleClas
MVPNet: Multi-View Point Regression Networks for 3D Object Reconstruction from A Single Image
Nov 23, 2018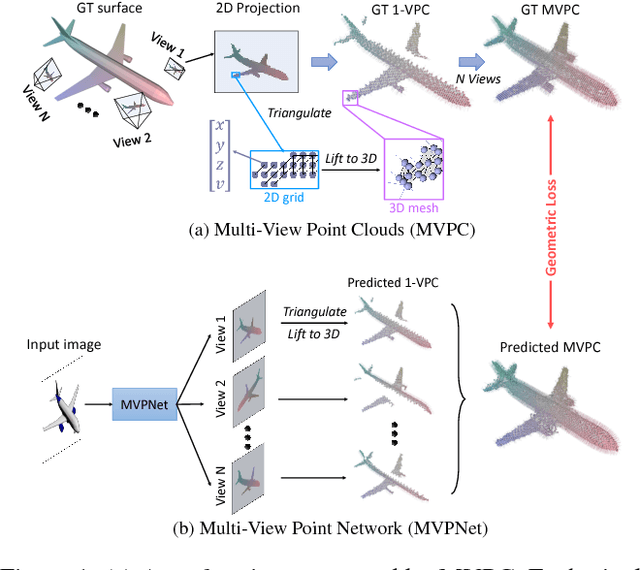
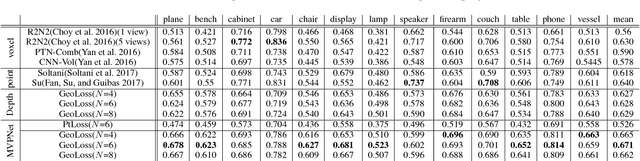
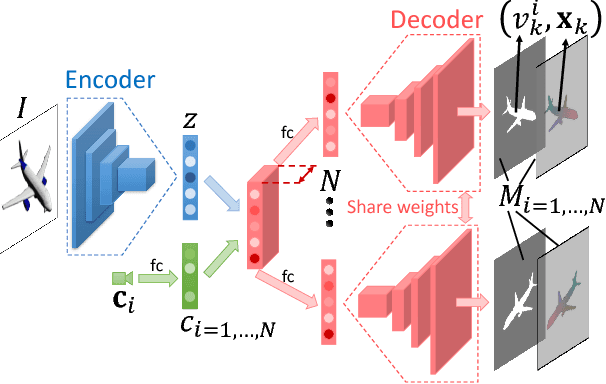

In this paper, we address the problem of reconstructing an object's surface from a single image using generative networks. First, we represent a 3D surface with an aggregation of dense point clouds from multiple views. Each point cloud is embedded in a regular 2D grid aligned on an image plane of a viewpoint, making the point cloud convolution-favored and ordered so as to fit into deep network architectures. The point clouds can be easily triangulated by exploiting connectivities of the 2D grids to form mesh-based surfaces. Second, we propose an encoder-decoder network that generates such kind of multiple view-dependent point clouds from a single image by regressing their 3D coordinates and visibilities. We also introduce a novel geometric loss that is able to interpret discrepancy over 3D surfaces as opposed to 2D projective planes, resorting to the surface discretization on the constructed meshes. We demonstrate that the multi-view point regression network outperforms state-of-the-art methods with a significant improvement on challenging datasets.
Evolving Deep Convolutional Neural Networks for Hyperspectral Image Denoising
Aug 15, 2020Hyperspectral images (HSIs) are susceptible to various noise factors leading to the loss of information, and the noise restricts the subsequent HSIs object detection and classification tasks. In recent years, learning-based methods have demonstrated their superior strengths in denoising the HSIs. Unfortunately, most of the methods are manually designed based on the extensive expertise that is not necessarily available to the users interested. In this paper, we propose a novel algorithm to automatically build an optimal Convolutional Neural Network (CNN) to effectively denoise HSIs. Particularly, the proposed algorithm focuses on the architectures and the initialization of the connection weights of the CNN. The experiments of the proposed algorithm have been well-designed and compared against the state-of-the-art peer competitors, and the experimental results demonstrate the competitive performance of the proposed algorithm in terms of the different evaluation metrics, visual assessments, and the computational complexity.
Impact of Facial Tattoos and Paintings on Face Recognition Systems
Mar 27, 2021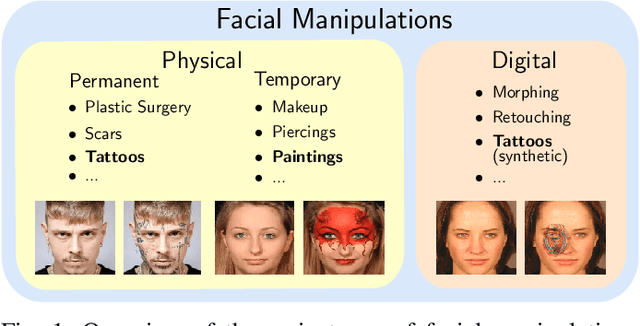
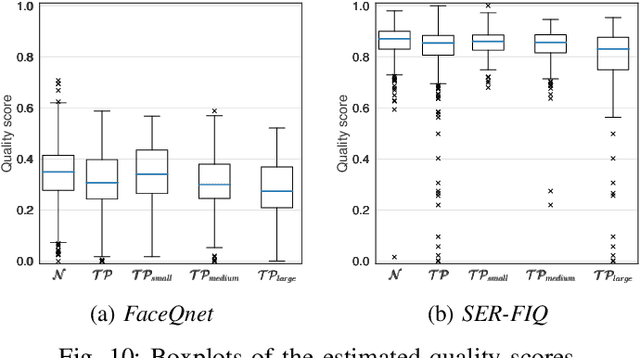
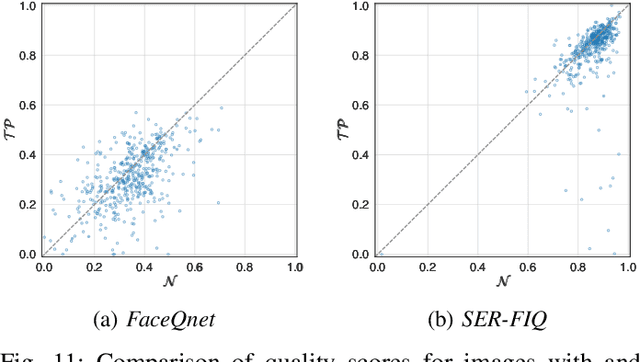

In the past years, face recognition technologies have shown impressive recognition performance, mainly due to recent developments in deep convolutional neural networks. Notwithstanding those improvements, several challenges which affect the performance of face recognition systems remain. In this work, we investigate the impact that facial tattoos and paintings have on current face recognition systems. To this end, we first collected an appropriate database containing image-pairs of individuals with and without facial tattoos or paintings. The assembled database was used to evaluate how facial tattoos and paintings affect the detection, quality estimation, as well as the feature extraction and comparison modules of a face recognition system. The impact on these modules was evaluated using state-of-the-art open-source and commercial systems. The obtained results show that facial tattoos and paintings affect all the tested modules, especially for images where a large area of the face is covered with tattoos or paintings. Our work is an initial case-study and indicates a need to design algorithms which are robust to the visual changes caused by facial tattoos and paintings.