 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pruning the Index Contents for Memory Efficient Open-Domain QA
Feb 21, 2021
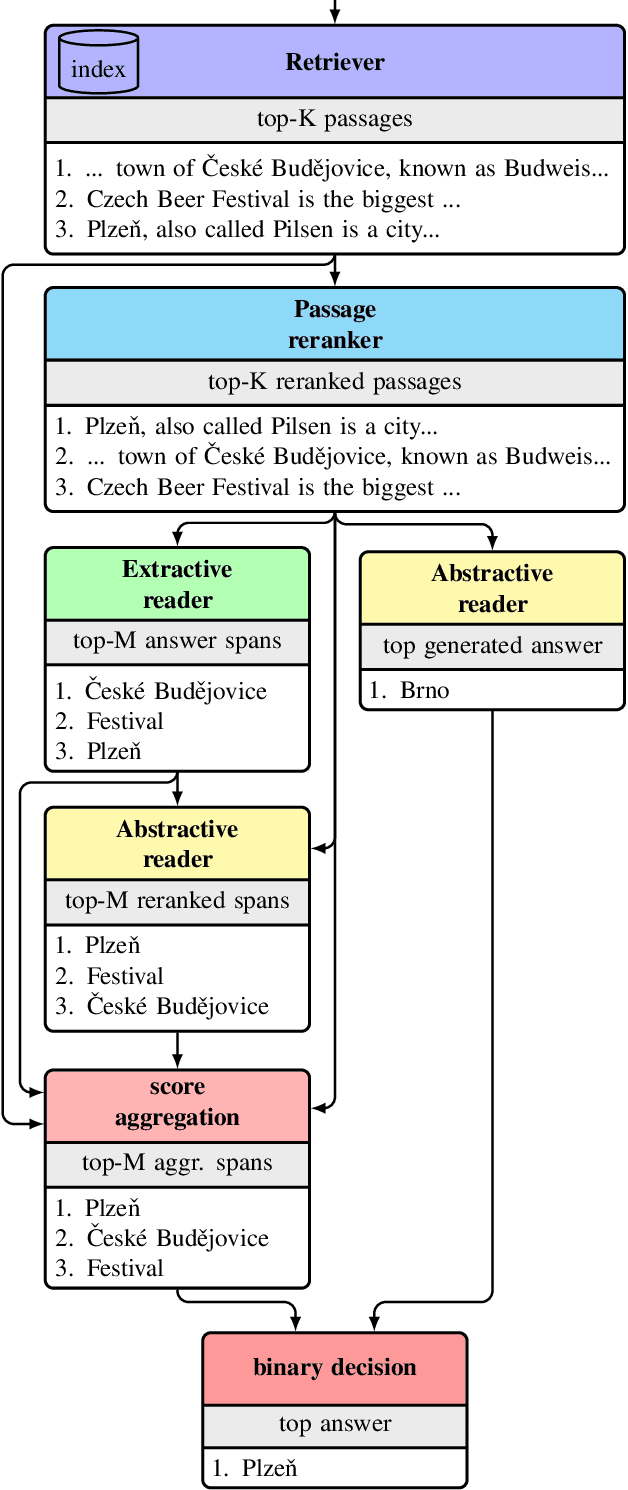
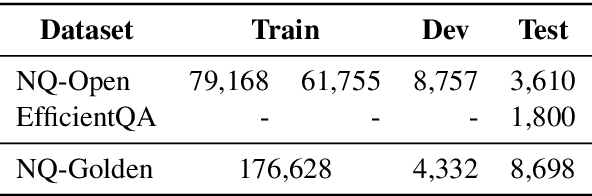
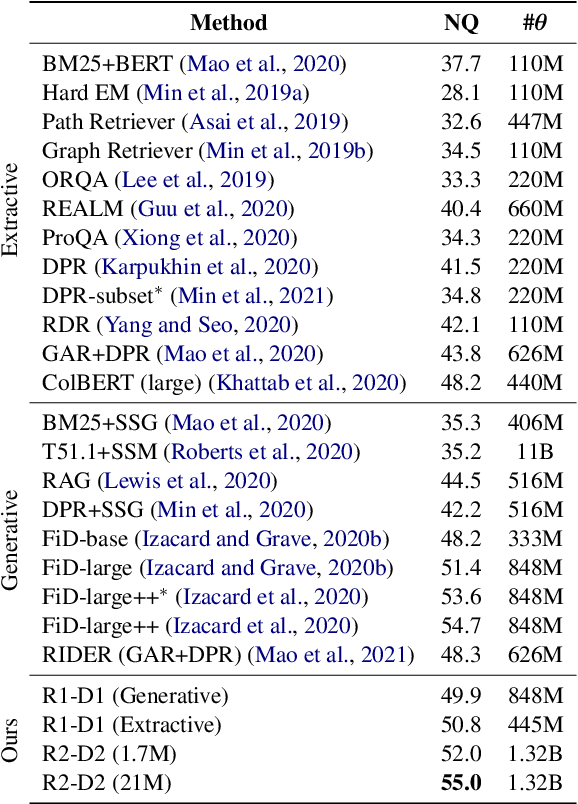
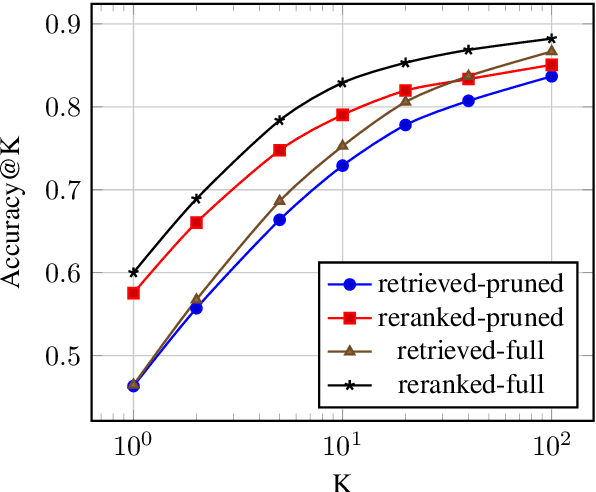
This work presents a novel pipeline that demonstrates what is achievable with a combined effort of state-of-the-art approaches, surpassing the 50% exact match on NaturalQuestions and EfficentQA datasets. Specifically, it proposes the novel R2-D2 (Rank twice, reaD twice) pipeline composed of retriever, reranker, extractive reader, generative reader and a simple way to combine them. Furthermore, previous work often comes with a massive index of external documents that scales in the order of tens of GiB. This work presents a simple approach for pruning the contents of a massive index such that the open-domain QA system altogether with index, OS, and library components fits into 6GiB docker image while retaining only 8% of original index contents and losing only 3% EM accuracy.
Spectral MVIR: Joint Reconstruction of 3D Shape and Spectral Reflectance
Apr 15, 2021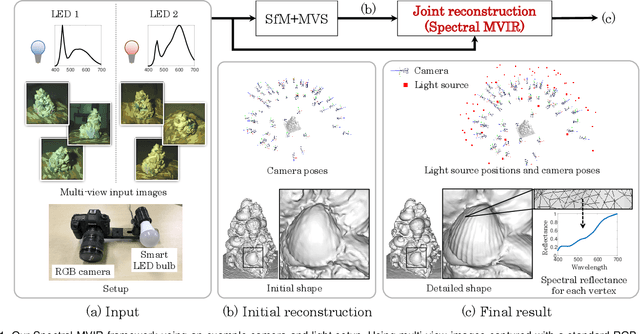



Reconstructing an object's high-quality 3D shape with inherent spectral reflectance property, beyond typical device-dependent RGB albedos, opens the door to applications requiring a high-fidelity 3D model in terms of both geometry and photometry. In this paper, we propose a novel Multi-View Inverse Rendering (MVIR) method called Spectral MVIR for jointly reconstructing the 3D shape and the spectral reflectance for each point of object surfaces from multi-view images captured using a standard RGB camera and low-cost lighting equipment such as an LED bulb or an LED projector. Our main contributions are twofold: (i) We present a rendering model that considers both geometric and photometric principles in the image formation by explicitly considering camera spectral sensitivity, light's spectral power distribution, and light source positions. (ii) Based on the derived model, we build a cost-optimization MVIR framework for the joint reconstruction of the 3D shape and the per-vertex spectral reflectance while estimating the light source positions and the shadows. Different from most existing spectral-3D acquisition methods, our method does not require expensive special equipment and cumbersome geometric calibration. Experimental results using both synthetic and real-world data demonstrate that our Spectral MVIR can acquire a high-quality 3D model with accurate spectral reflectance property.
Discriminative Pattern Mining for Breast Cancer Histopathology Image Classification via Fully Convolutional Autoencoder
Feb 27, 2019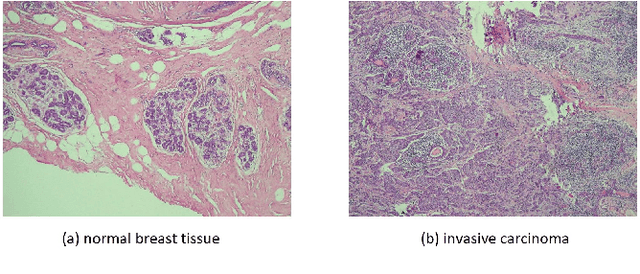

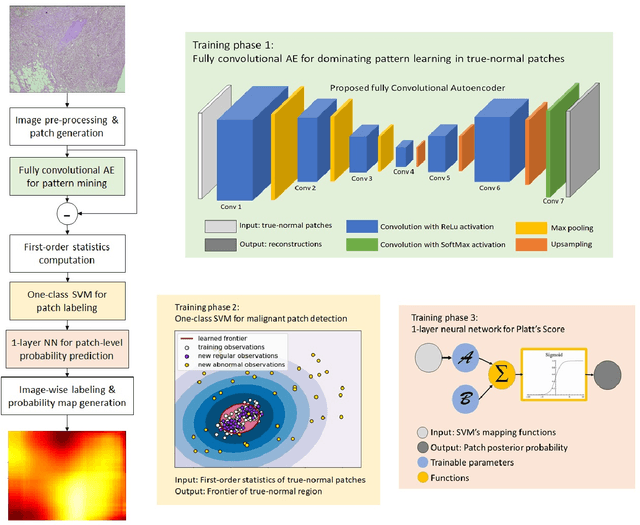
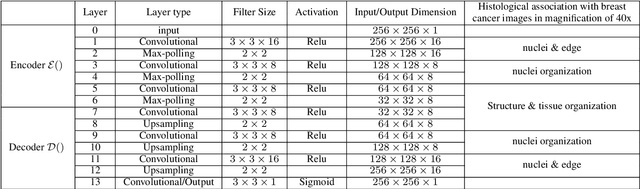
Accurate diagnosis of breast cancer in histopathology images is challenging due to the heterogeneity of cancer cell growth as well as of a variety of benign breast tissue proliferative lesions. In this paper, we propose a practical and self-interpretable invasive cancer diagnosis solution. With minimum annotation information, the proposed method mines contrast patterns between normal and malignant images in unsupervised manner and generates a probability map of abnormalities to verify its reasoning. Particularly, a fully convolutional autoencoder is used to learn the dominant structural patterns among normal image patches. Patches that do not share the characteristics of this normal population are detected and analyzed by one-class support vector machine and 1-layer neural network. We apply the proposed method to a public breast cancer image set. Our results, in consultation with a senior pathologist, demonstrate that the proposed method outperforms existing methods. The obtained probability map could benefit the pathology practice by providing visualized verification data and potentially leads to a better understanding of data-driven diagnosis solutions.
Classification of Urban Morphology with Deep Learning: Application on Urban Vitality
May 07, 2021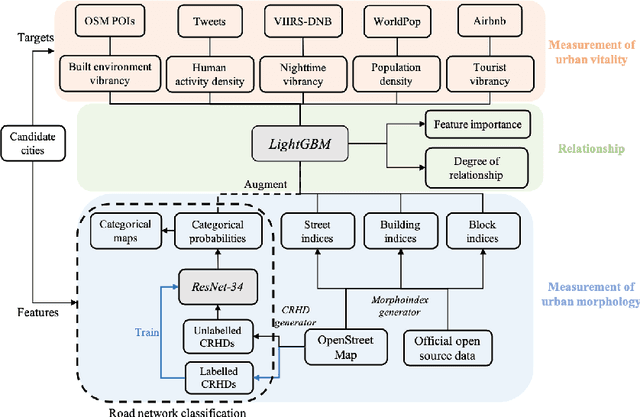
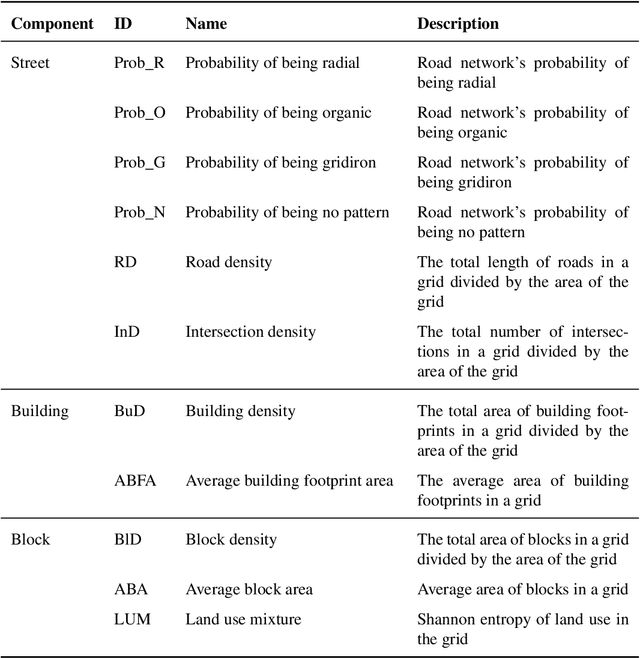
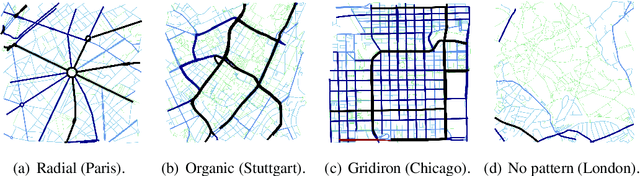
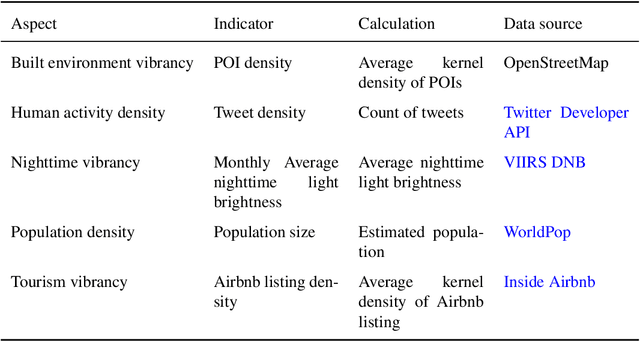
There is a prevailing trend to study urban morphology quantitatively thanks to the growing accessibility to various forms of spatial big data, increasing computing power, and use cases benefiting from such information. The methods developed up to now measure urban morphology with numerical indices describing density, proportion, and mixture, but they do not directly represent morphological features from human's visual and intuitive perspective. We take the first step to bridge the gap by proposing a deep learning-based technique to automatically classify road networks into four classes on a visual basis. The method is implemented by generating an image of the street network (Colored Road Hierarchy Diagram), which we introduce in this paper, and classifying it using a deep convolutional neural network (ResNet-34). The model achieves an overall classification accuracy of 0.875. Nine cities around the world are selected as the study areas and their road networks are acquired from OpenStreetMap. Latent subgroups among the cities are uncovered through a clustering on the percentage of each road network category. In the subsequent part of the paper, we focus on the usability of such classification: the effectiveness of our human perception augmentation is examined by a case study of urban vitality prediction. An advanced tree-based regression model is for the first time designated to establish the relationship between morphological indices and vitality indicators. A positive effect of human perception augmentation is detected in the comparative experiment of baseline model and augmented model. This work expands the toolkit of quantitative urban morphology study with new techniques, supporting further studies in the future.
Optimal Threshold Design for Quanta Image Sensor
Oct 30, 2017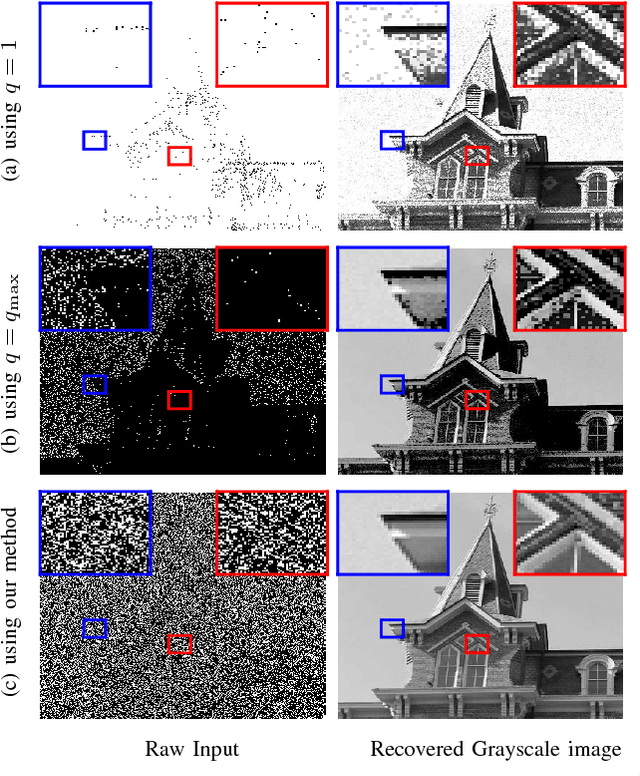
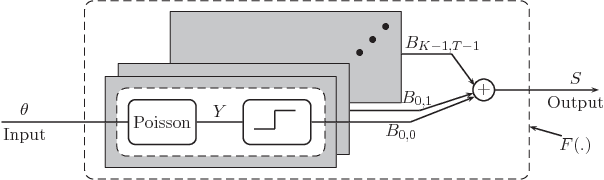


Quanta Image Sensor (QIS) is a binary imaging device envisioned to be the next generation image sensor after CCD and CMOS. Equipped with a massive number of single photon detectors, the sensor has a threshold $q$ above which the number of arriving photons will trigger a binary response "1", or "0" otherwise. Existing methods in the device literature typically assume that $q=1$ uniformly. We argue that a spatially varying threshold can significantly improve the signal-to-noise ratio of the reconstructed image. In this paper, we present an optimal threshold design framework. We make two contributions. First, we derive a set of oracle results to theoretically inform the maximally achievable performance. We show that the oracle threshold should match exactly with the underlying pixel intensity. Second, we show that around the oracle threshold there exists a set of thresholds that give asymptotically unbiased reconstructions. The asymptotic unbiasedness has a phase transition behavior which allows us to develop a practical threshold update scheme using a bisection method. Experimentally, the new threshold design method achieves better rate of convergence than existing methods.
Channel-wise and Spatial Feature Modulation Network for Single Image Super-Resolution
Sep 28, 2018



The performance of single image super-resolution has achieved significant improvement by utilizing deep convolutional neural networks (CNNs). The features in deep CNN contain different types of information which make different contributions to image reconstruction. However, most CNN-based models lack discriminative ability for different types of information and deal with them equally, which results in the representational capacity of the models being limited. On the other hand, as the depth of neural networks grows, the long-term information coming from preceding layers is easy to be weaken or lost in late layers, which is adverse to super-resolving image. To capture more informative features and maintain long-term information for image super-resolution, we propose a channel-wise and spatial feature modulation (CSFM) network in which a sequence of feature-modulation memory (FMM) modules is cascaded with a densely connected structure to transform low-resolution features to high informative features. In each FMM module, we construct a set of channel-wise and spatial attention residual (CSAR) blocks and stack them in a chain structure to dynamically modulate multi-level features in a global-and-local manner. This feature modulation strategy enables the high contribution information to be enhanced and the redundant information to be suppressed. Meanwhile, for long-term information persistence, a gated fusion (GF) node is attached at the end of the FMM module to adaptively fuse hierarchical features and distill more effective information via the dense skip connections and the gating mechanism. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over the state-of-the-art methods.
Cross-convolutional-layer Pooling for Image Recognition
Dec 22, 2016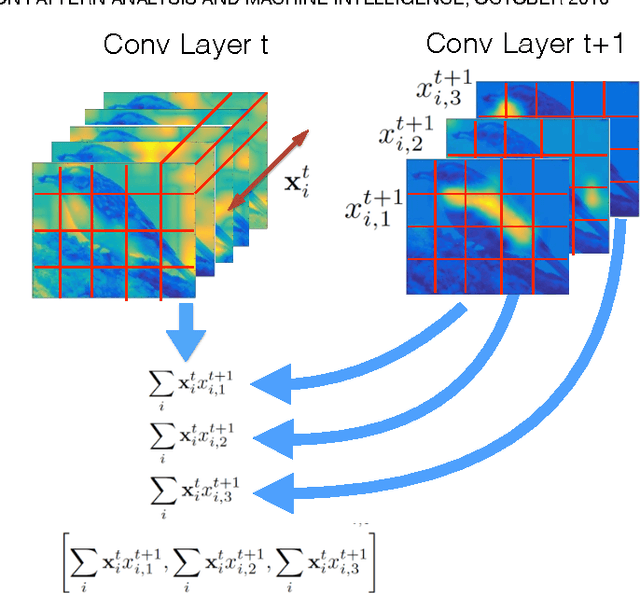
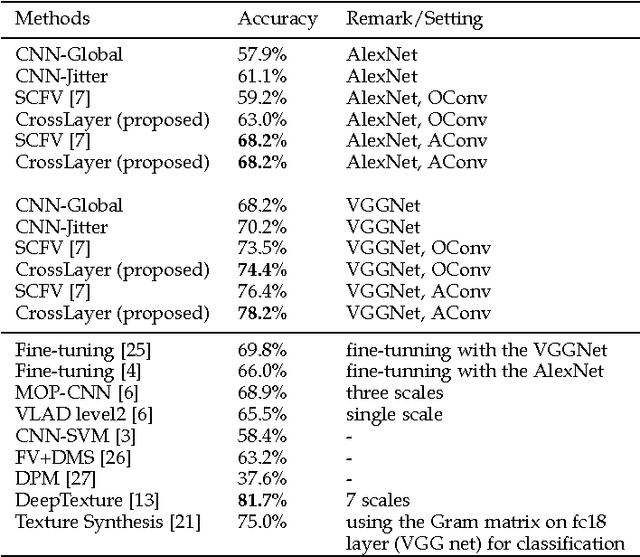

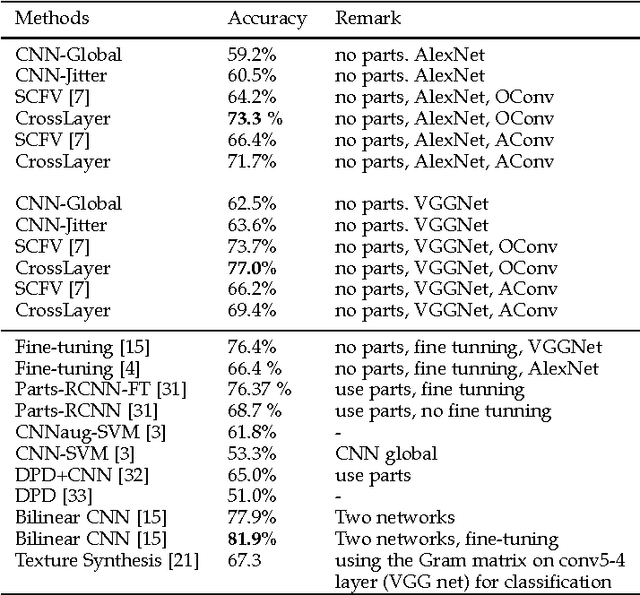
Recent studies have shown that a Deep Convolutional Neural Network (DCNN) pretrained on a large image dataset can be used as a universal image descriptor, and that doing so leads to impressive performance for a variety of image classification tasks. Most of these studies adopt activations from a single DCNN layer, usually the fully-connected layer, as the image representation. In this paper, we proposed a novel way to extract image representations from two consecutive convolutional layers: one layer is utilized for local feature extraction and the other serves as guidance to pool the extracted features. By taking different viewpoints of convolutional layers, we further develop two schemes to realize this idea. The first one directly uses convolutional layers from a DCNN. The second one applies the pretrained CNN on densely sampled image regions and treats the fully-connected activations of each image region as convolutional feature activations. We then train another convolutional layer on top of that as the pooling-guidance convolutional layer. By applying our method to three popular visual classification tasks, we find our first scheme tends to perform better on the applications which need strong discrimination on subtle object patterns within small regions while the latter excels in the cases that require discrimination on category-level patterns. Overall, the proposed method achieves superior performance over existing ways of extracting image representations from a DCNN.
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis
Apr 15, 2021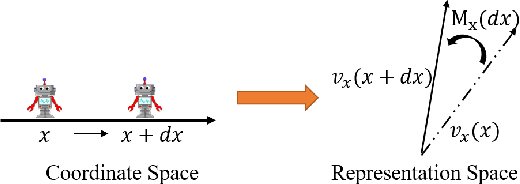
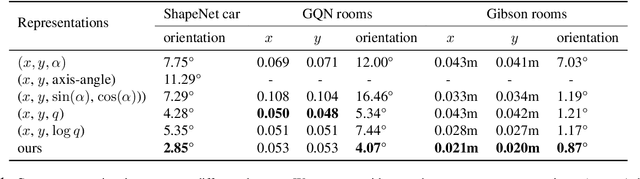
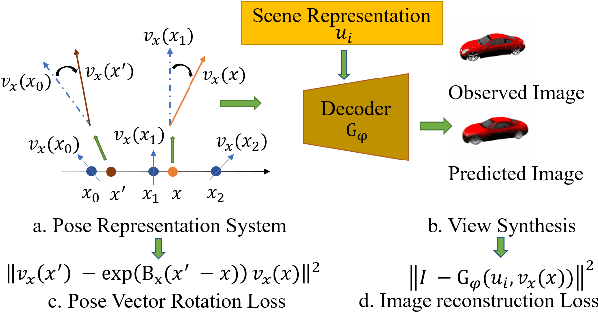
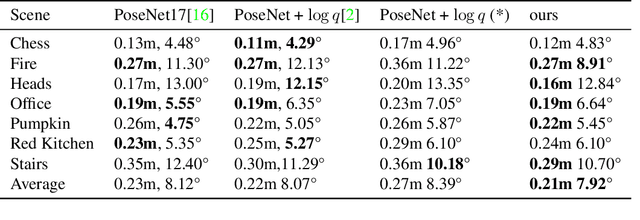
How to effectively represent camera pose is an essential problem in 3D computer vision, especially in tasks such as camera pose regression and novel view synthesis. Traditionally, 3D position of the camera is represented by Cartesian coordinate and the orientation is represented by Euler angle or quaternions. These representations are manually designed, which may not be the most effective representation for downstream tasks. In this work, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements. Specifically, the camera pose and 3D scene are represented as vectors and the local camera movement is represented as a matrix operating on the vector of the camera pose. We demonstrate that the camera movement can further be parametrized by a matrix Lie algebra that underlies a rotation system in the neural space. The vector representations are then concatenated and generate the posed 2D image through a decoder network. The model is learned from only posed 2D images and corresponding camera poses, without access to depths or shapes. We conduct extensive experiments on synthetic and real datasets. The results show that compared with other camera pose representations, our learned representation is more robust to noise in novel view synthesis and more effective in camera pose regression.
Deep image mining for diabetic retinopathy screening
Apr 28, 2017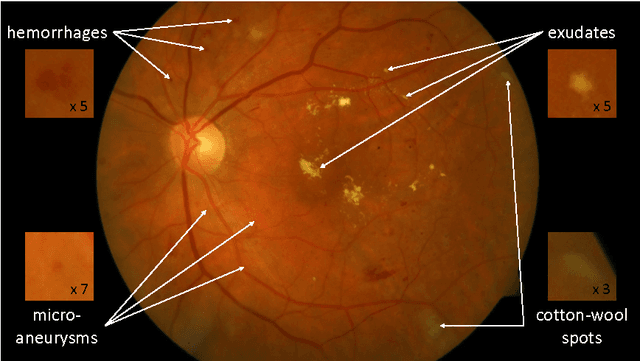
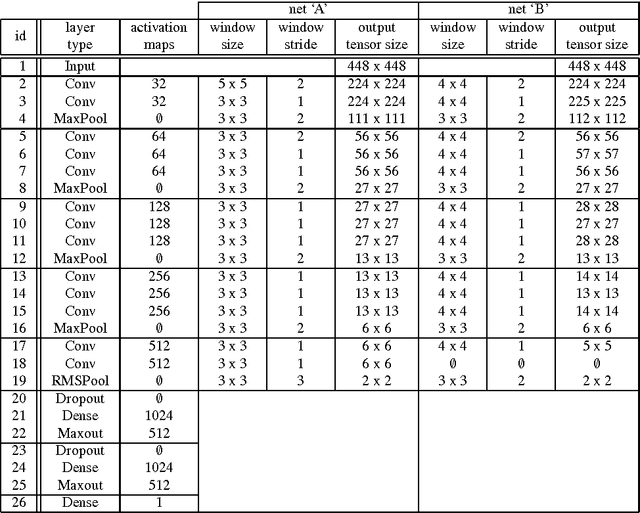
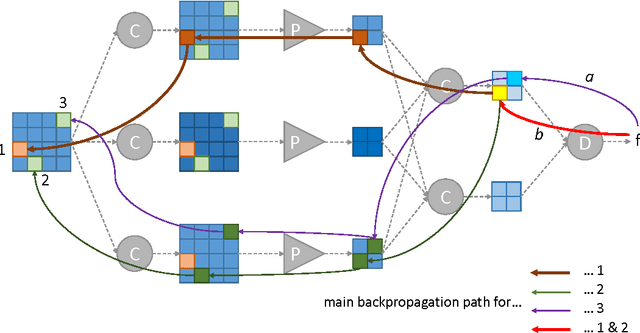
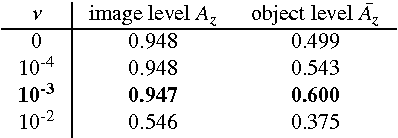
Deep learning is quickly becoming the leading methodology for medical image analysis. Given a large medical archive, where each image is associated with a diagnosis, efficient pathology detectors or classifiers can be trained with virtually no expert knowledge about the target pathologies. However, deep learning algorithms, including the popular ConvNets, are black boxes: little is known about the local patterns analyzed by ConvNets to make a decision at the image level. A solution is proposed in this paper to create heatmaps showing which pixels in images play a role in the image-level predictions. In other words, a ConvNet trained for image-level classification can be used to detect lesions as well. A generalization of the backpropagation method is proposed in order to train ConvNets that produce high-quality heatmaps. The proposed solution is applied to diabetic retinopathy (DR) screening in a dataset of almost 90,000 fundus photographs from the 2015 Kaggle Diabetic Retinopathy competition and a private dataset of almost 110,000 photographs (e-ophtha). For the task of detecting referable DR, very good detection performance was achieved: $A_z = 0.954$ in Kaggle's dataset and $A_z = 0.949$ in e-ophtha. Performance was also evaluated at the image level and at the lesion level in the DiaretDB1 dataset, where four types of lesions are manually segmented: microaneurysms, hemorrhages, exudates and cotton-wool spots. The proposed detector outperforms recent algorithms trained to detect those lesions specifically, as well as competing heatmap generation algorithms for ConvNets. This detector is part of the Messidor system for mobile eye pathology screening. Because it does not rely on expert knowledge or manual segmentation for detecting relevant patterns, the proposed solution is a promising image mining tool, which has the potential to discover new biomarkers in images.
* Accepted for publication in Medical Image Analysis
Design of optimal illumination patterns in single-pixel imaging using image dictionaries
Jun 04, 2018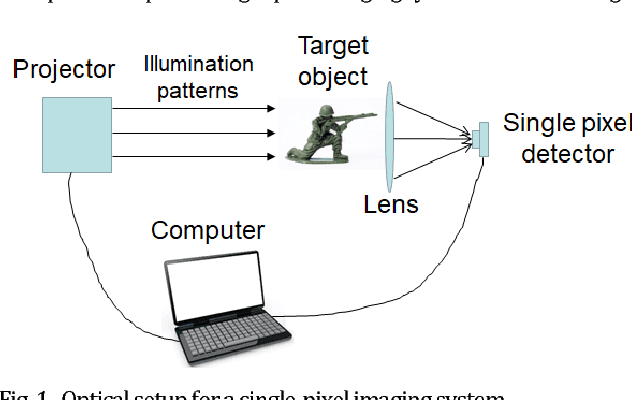


Single-pixel imaging (SPI) has a major drawback that the huge number of sequential illuminations for capturing one single image requires long acquisition time and high cost. Basis illumination patterns such as sinusoidal patterns in Fourier transform and Hadamard patterns are employed to enhance the imaging efficiency. The basis illumination patterns can achieve much better efficiency than random intensity illumination patterns but the performance is still sub-optimal since the basis patterns are fixed and non-adaptive for varying object images. In this work, we propose a novel scheme to design the illumination patterns adaptively when SPI is applied in a specific and pre-known imaging scenario. Exemplar training images belonging to the target specific category of object images are collected and an image dictionary is constructed in advance. Then the optimized illumination patterns are designed by extracting the common image features from the image dictionary using principal component analysis. Simulation results reveal that our proposed scheme outperforms conventional Fourier single-pixel imaging in terms of imaging efficiency.