 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ordinal Neural Network Transformation Models: Deep and interpretable regression models for ordinal outcomes
Oct 26, 2020
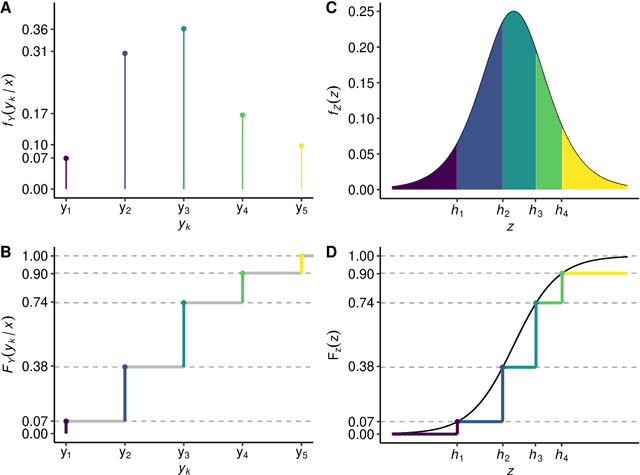
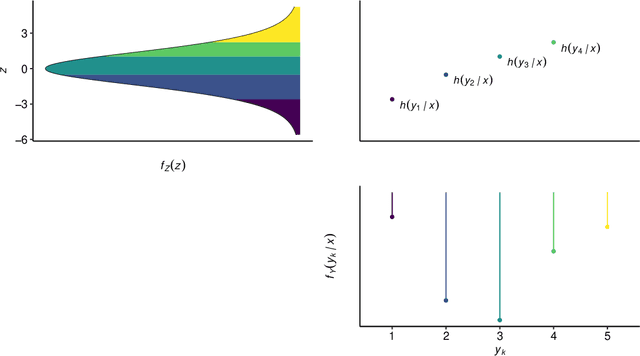
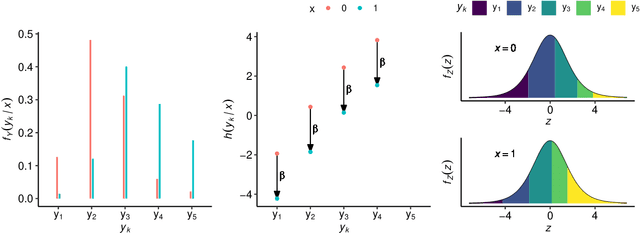
Outcomes with a natural order commonly occur in prediction tasks and oftentimes the available input data are a mixture of complex data, like images, and tabular predictors. Although deep Learning (DL) methods have shown outstanding performance on image classification, most models treat ordered outcomes as unordered and lack interpretability. In contrast, classical ordinal regression models yield interpretable predictor effects but are limited to tabular input data. Here, we present the highly modular class of ordinal neural network transformation models (ONTRAMs). Transformation models use a parametric transformation function and a simple distribution to trade off flexibility and interpretability of individual model components. In ONTRAMs, this trade-off is achieved by additively decomposing the transformation function into terms for the tabular and image data using a set of jointly trained neural networks. We show that the most flexible ONTRAMs achieve on-par performance with DL classifiers while outperforming them in training speed. We discuss how to interpret components of ONTRAMs in general and in the case of correlated tabular and image data. Taken together, ONTRAMs join benefits of DL and distributional regression to create interpretable prediction models for ordinal outcomes.
Matthews Correlation Coefficient Loss for Deep Convolutional Networks: Application to Skin Lesion Segmentation
Oct 26, 2020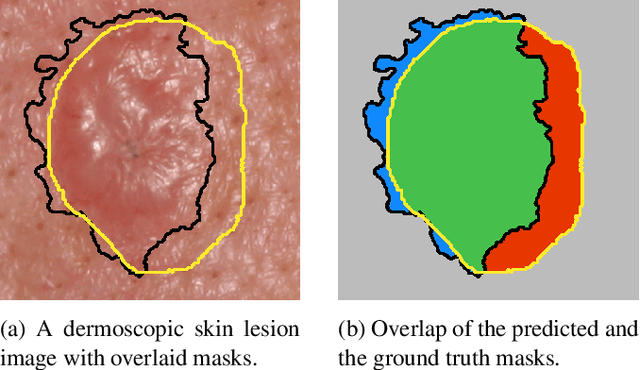
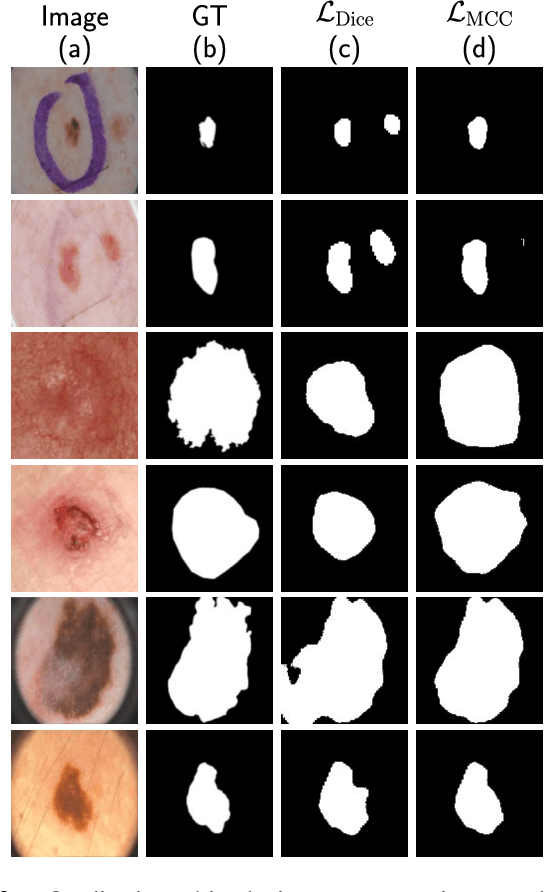
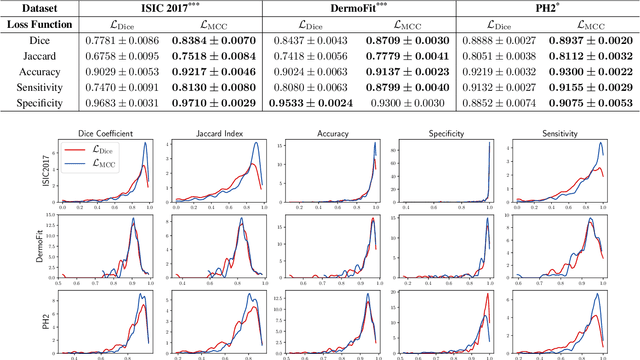
The segmentation of skin lesions is a crucial task in clinical decision support systems for the computer aided diagnosis of skin lesions. Although deep learning based approaches have improved segmentation performance, these models are often susceptible to class imbalance in the data, particularly, the fraction of the image occupied by the background healthy skin. Despite variations of the popular Dice loss function being proposed to tackle the class imbalance problem, the Dice loss formulation does not penalize misclassifications of the background pixels. We propose a novel metric-based loss function using the Matthews correlation coefficient, a metric that has been shown to be efficient in scenarios with skewed class distributions, and use it to optimize deep segmentation models. Evaluations on three dermoscopic image datasets: the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset, the DermoFit Image Library, and the PH2 dataset show that models trained using the proposed loss function outperform those trained using Dice loss by 11.25%, 4.87%, and 0.76% respectively in the mean Jaccard index. We plan to release the code on GitHub at https://github.com/kakumarabhishek/MCC-Loss upon publication of this paper.
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation
Jul 03, 2020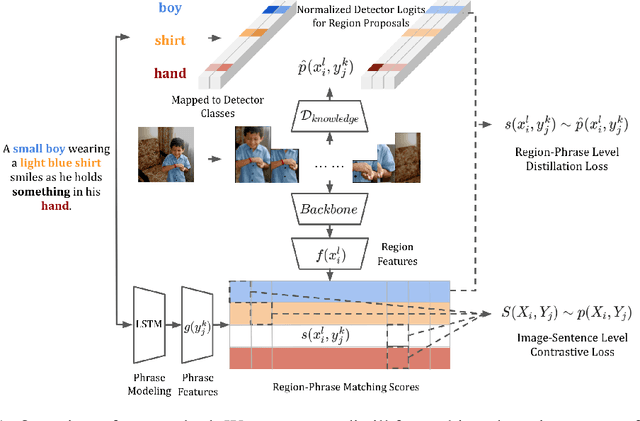
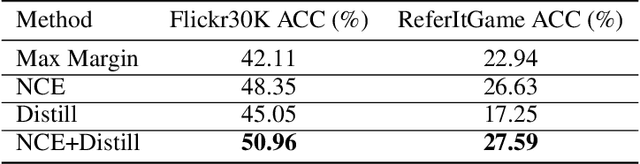

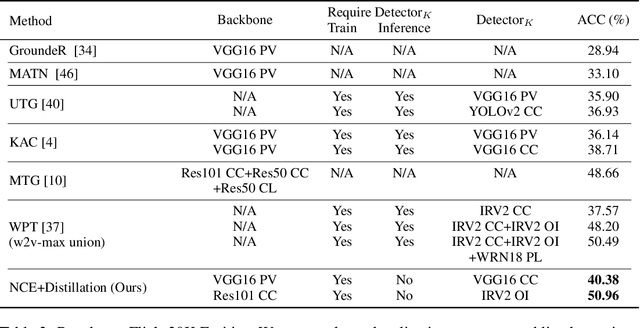
Weakly supervised phrase grounding aims at learning region-phrase correspondences using only image-sentence pairs. A major challenge thus lies in the missing links between image regions and sentence phrases during training. To address this challenge, we leverage a generic object detector at training time, and propose a contrastive learning framework that accounts for both region-phrase and image-sentence matching. Our core innovation is the learning of a region-phrase score function, based on which an image-sentence score function is further constructed. Importantly, our region-phrase score function is learned by distilling from soft matching scores between the detected object class names and candidate phrases within an image-sentence pair, while the image-sentence score function is supervised by ground-truth image-sentence pairs. The design of such score functions removes the need of object detection at test time, thereby significantly reducing the inference cost. Without bells and whistles, our approach achieves state-of-the-art results on the task of visual phrase grounding, surpassing previous methods that require expensive object detectors at test time.
Processing of incomplete images by (graph) convolutional neural networks
Oct 26, 2020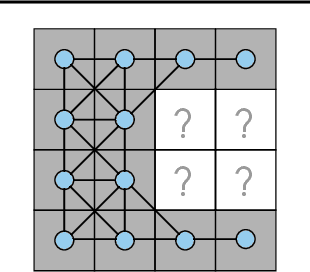

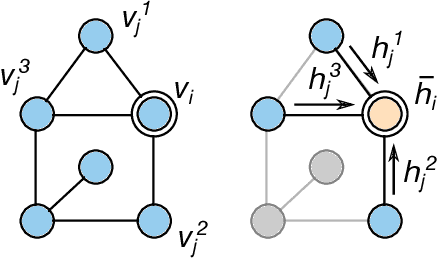
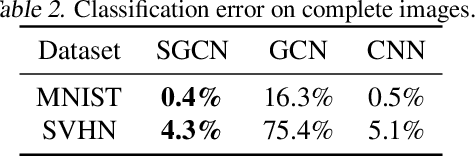
We investigate the problem of training neural networks from incomplete images without replacing missing values. For this purpose, we first represent an image as a graph, in which missing pixels are entirely ignored. The graph image representation is processed using a spatial graph convolutional network (SGCN) -- a type of graph convolutional networks, which is a proper generalization of classical CNNs operating on images. On one hand, our approach avoids the problem of missing data imputation while, on the other hand, there is a natural correspondence between CNNs and SGCN. Experiments confirm that our approach performs better than analogical CNNs with the imputation of missing values on typical classification and reconstruction tasks.
Identifying Melanoma Images using EfficientNet Ensemble: Winning Solution to the SIIM-ISIC Melanoma Classification Challenge
Oct 11, 2020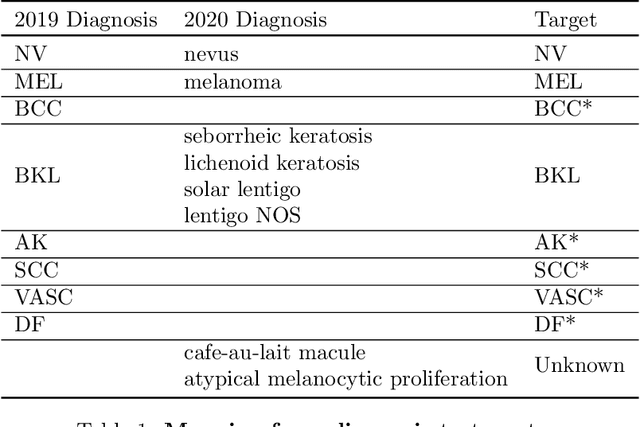
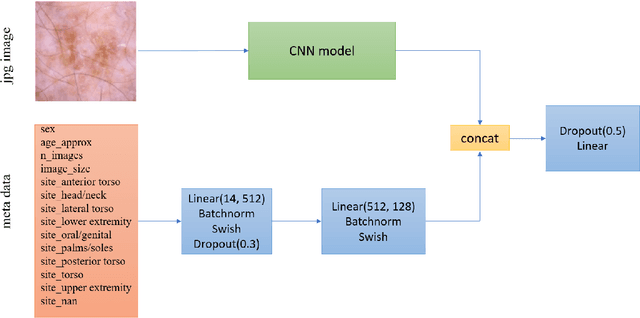
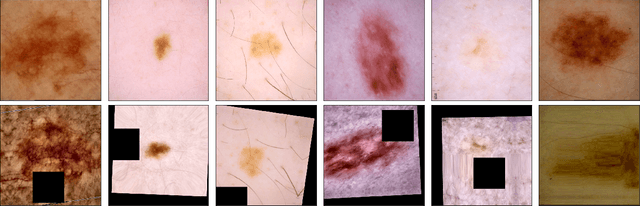
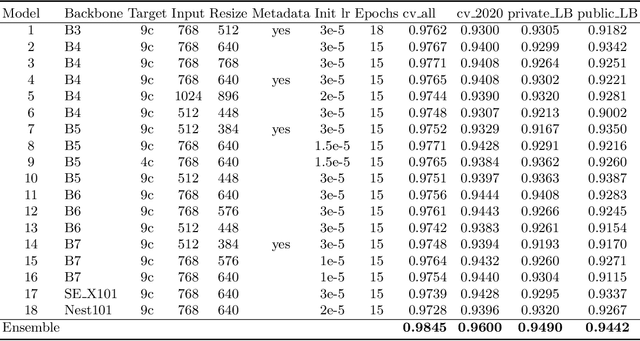
We present our winning solution to the SIIM-ISIC Melanoma Classification Challenge. It is an ensemble of convolutions neural network (CNN) models with different backbones and input sizes, most of which are image-only models while a few of them used image-level and patient-level metadata. The keys to our winning are: (1) stable validation scheme (2) good choice of model target (3) carefully tuned pipeline and (4) ensembling with very diverse models. The winning submission scored 0.9600 AUC on cross validation and 0.9490 AUC on private leaderboard.
Fine-tuning Handwriting Recognition systems with Temporal Dropout
Jan 31, 2021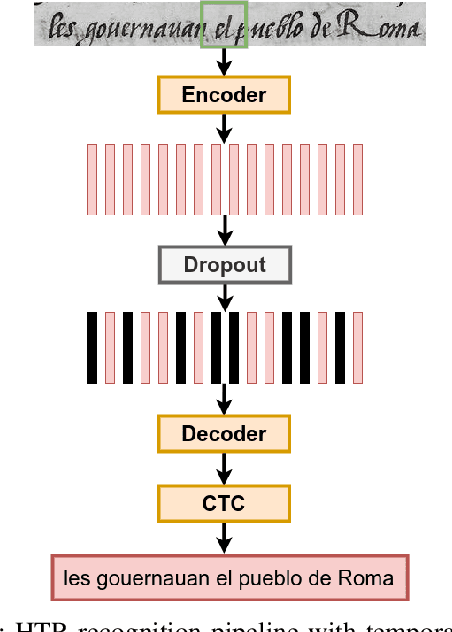
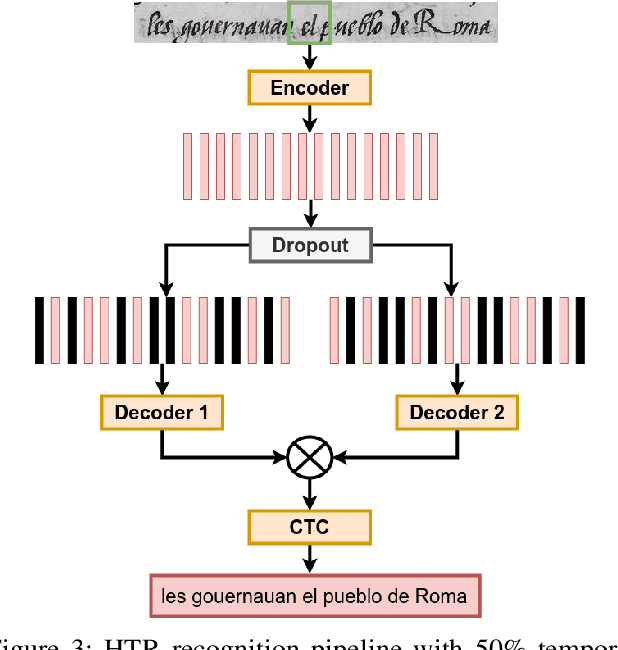
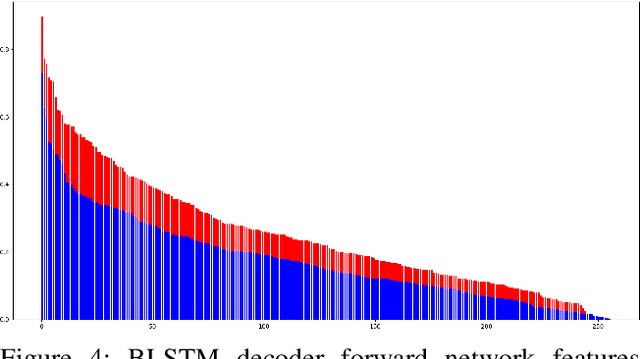
This paper introduces a novel method to fine-tune handwriting recognition systems based on Recurrent Neural Networks (RNN). Long Short-Term Memory (LSTM) networks are good at modeling long sequences but they tend to overfit over time. To improve the system's ability to model sequences, we propose to drop information at random positions in the sequence. We call our approach Temporal Dropout (TD). We apply TD at the image level as well to internal network representation. We show that TD improves the results on two different datasets. Our method outperforms previous state-of-the-art on Rodrigo dataset.
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020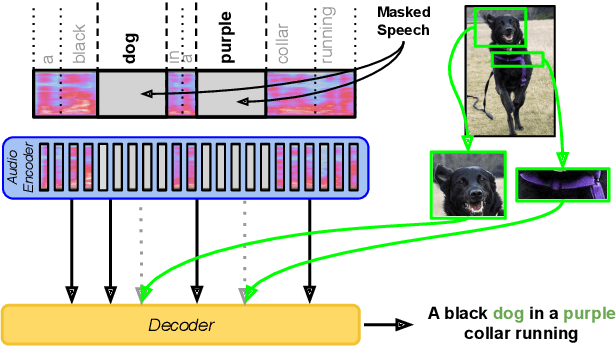
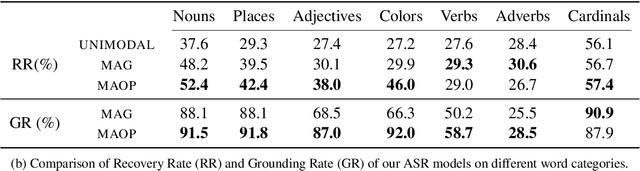
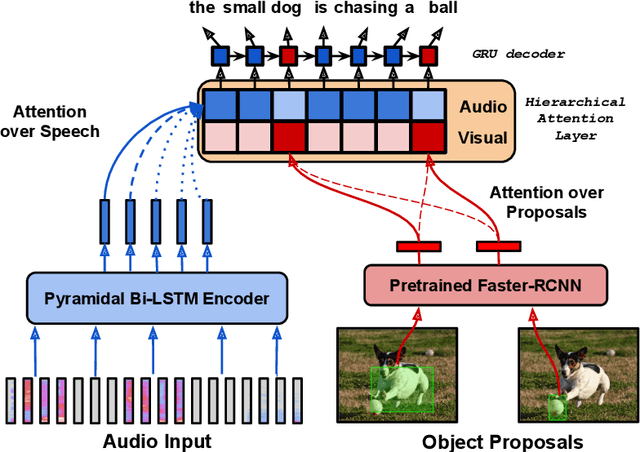
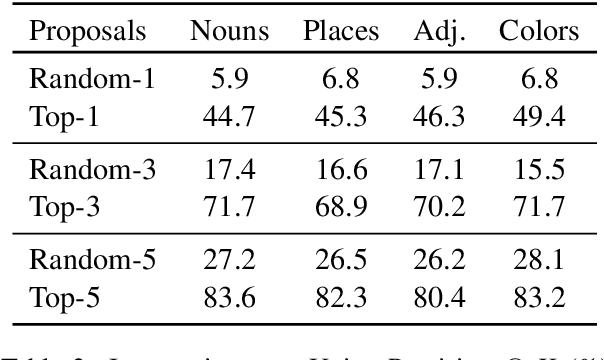
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
Self-Supervised Adaptation for Video Super-Resolution
Mar 18, 2021
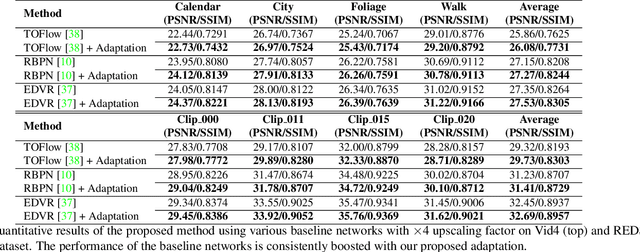
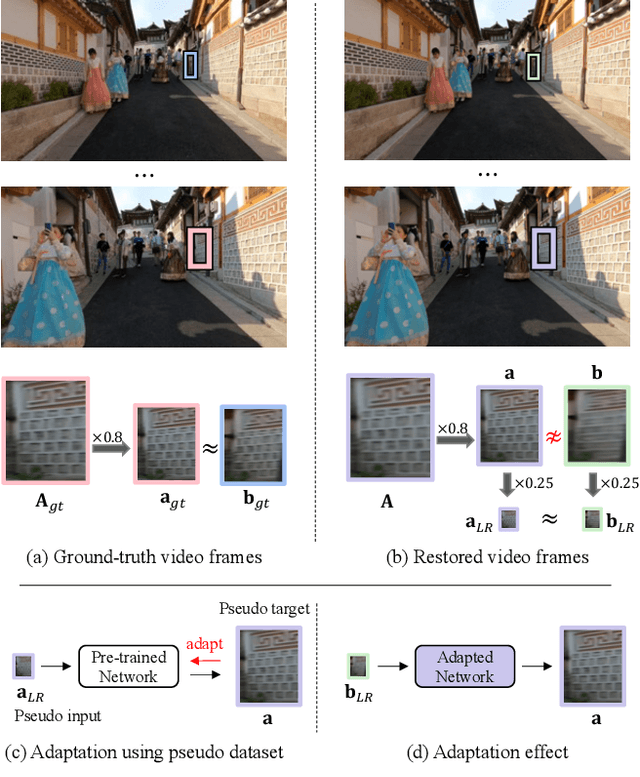
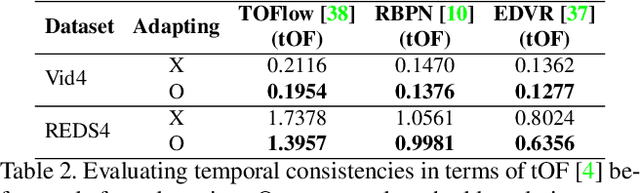
Recent single-image super-resolution (SISR) networks, which can adapt their network parameters to specific input images, have shown promising results by exploiting the information available within the input data as well as large external datasets. However, the extension of these self-supervised SISR approaches to video handling has yet to be studied. Thus, we present a new learning algorithm that allows conventional video super-resolution (VSR) networks to adapt their parameters to test video frames without using the ground-truth datasets. By utilizing many self-similar patches across space and time, we improve the performance of fully pre-trained VSR networks and produce temporally consistent video frames. Moreover, we present a test-time knowledge distillation technique that accelerates the adaptation speed with less hardware resources. In our experiments, we demonstrate that our novel learning algorithm can fine-tune state-of-the-art VSR networks and substantially elevate performance on numerous benchmark datasets.
A Review on Deep Learning in UAV Remote Sensing
Jan 22, 2021

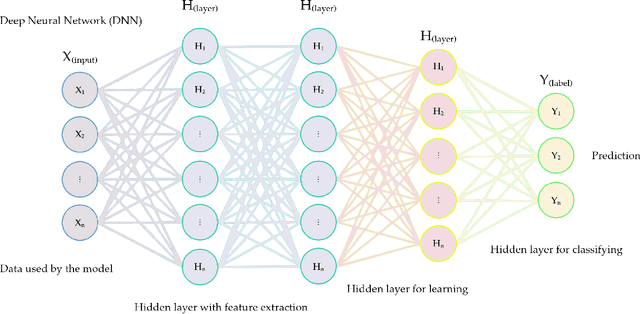
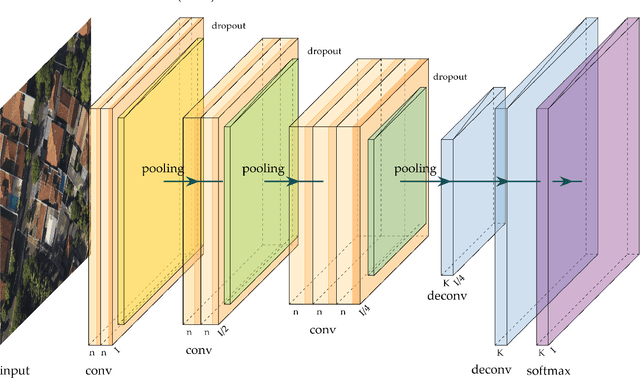
Deep Neural Networks (DNNs) learn representation from data with an impressive capability, and brought important breakthroughs for processing images, time-series, natural language, audio, video, and many others. In the remote sensing field, surveys and literature revisions specifically involving DNNs algorithms' applications have been conducted in an attempt to summarize the amount of information produced in its subfields. Recently, Unmanned Aerial Vehicles (UAV) based applications have dominated aerial sensing research. However, a literature revision that combines both "deep learning" and "UAV remote sensing" thematics has not yet been conducted. The motivation for our work was to present a comprehensive review of the fundamentals of Deep Learning (DL) applied in UAV-based imagery. We focused mainly on describing classification and regression techniques used in recent applications with UAV-acquired data. For that, a total of 232 papers published in international scientific journal databases was examined. We gathered the published material and evaluated their characteristics regarding application, sensor, and technique used. We relate how DL presents promising results and has the potential for processing tasks associated with UAV-based image data. Lastly, we project future perspectives, commentating on prominent DL paths to be explored in the UAV remote sensing field. Our revision consists of a friendly-approach to introduce, commentate, and summarize the state-of-the-art in UAV-based image applications with DNNs algorithms in diverse subfields of remote sensing, grouping it in the environmental, urban, and agricultural contexts.
Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment
Apr 15, 2021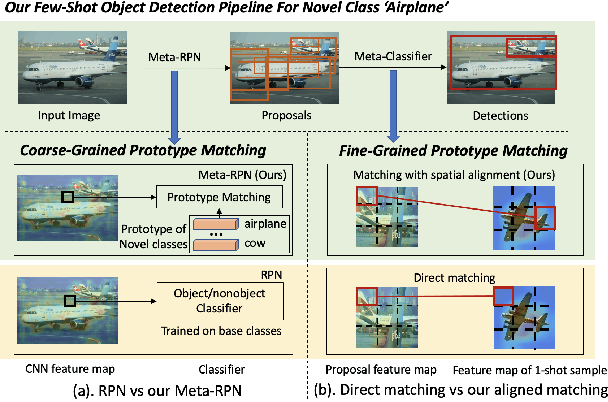
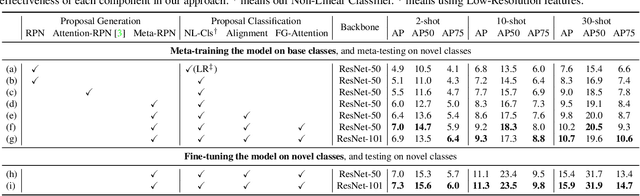
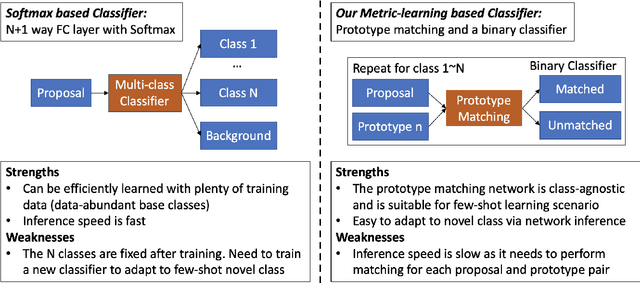
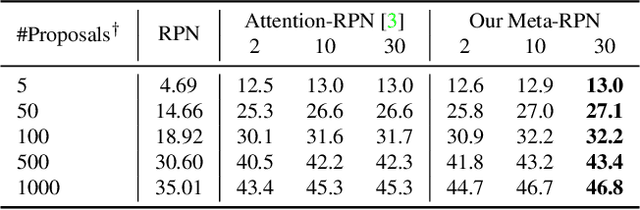
Few-shot object detection (FSOD) aims to detect objects using only few examples. It's critically needed for many practical applications but so far remains challenging. We propose a meta-learning based few-shot object detection method by transferring meta-knowledge learned from data-abundant base classes to data-scarce novel classes. Our method incorporates a coarse-to-fine approach into the proposal based object detection framework and integrates prototype based classifiers into both the proposal generation and classification stages. To improve proposal generation for few-shot novel classes, we propose to learn a lightweight matching network to measure the similarity between each spatial position in the query image feature map and spatially-pooled class features, instead of the traditional object/nonobject classifier, thus generating category-specific proposals and improving proposal recall for novel classes. To address the spatial misalignment between generated proposals and few-shot class examples, we propose a novel attentive feature alignment method, thus improving the performance of few-shot object detection. Meanwhile we jointly learn a Faster R-CNN detection head for base classes. Extensive experiments conducted on multiple FSOD benchmarks show our proposed approach achieves state of the art results under (incremental) few-shot learning settings.