 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predictive 3D Sonar Mapping of Underwater Environments via Object-specific Bayesian Inference
Apr 07, 2021
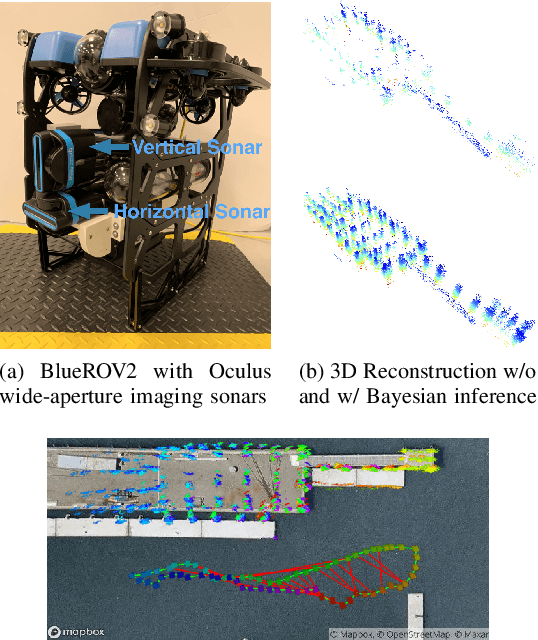

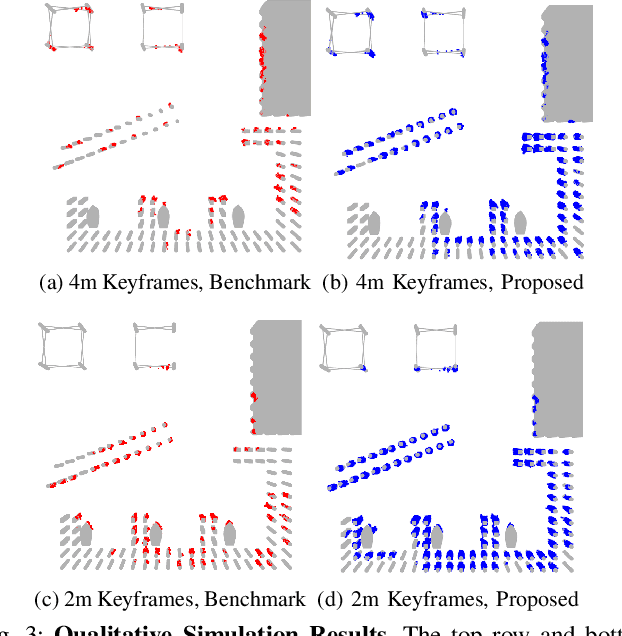
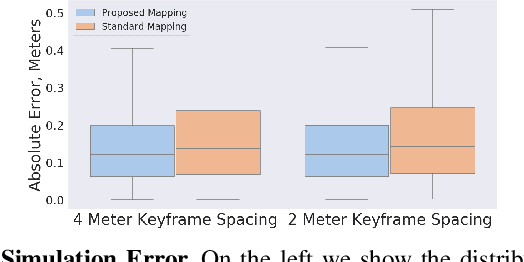
Recent work has achieved dense 3D reconstruction with wide-aperture imaging sonar using a stereo pair of orthogonally oriented sonars. This allows each sonar to observe a spatial dimension that the other is missing, without requiring any prior assumptions about scene geometry. However, this is achieved only in a small region with overlapping fields-of-view, leaving large regions of sonar image observations with an unknown elevation angle. Our work aims to achieve large-scale 3D reconstruction more efficiently using this sensor arrangement. We propose dividing the world into semantic classes to exploit the presence of repeating structures in the subsea environment. We use a Bayesian inference framework to build an understanding of each object class's geometry when 3D information is available from the orthogonal sonar fusion system, and when the elevation angle of our returns is unknown, our framework is used to infer unknown 3D structure. We quantitatively validate our method in a simulation and use data collected from a real outdoor littoral environment to demonstrate the efficacy of our framework in the field. Video attachment: https://www.youtube.com/watch?v=WouCrY9eK4o&t=75s
DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images
Mar 29, 2021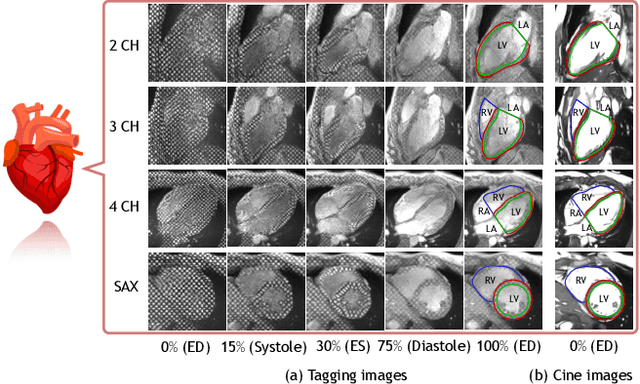
Cardiac tagging magnetic resonance imaging (t-MRI) is the gold standard for regional myocardium deformation and cardiac strain estimation. However, this technique has not been widely used in clinical diagnosis, as a result of the difficulty of motion tracking encountered with t-MRI images. In this paper, we propose a novel deep learning-based fully unsupervised method for in vivo motion tracking on t-MRI images. We first estimate the motion field (INF) between any two consecutive t-MRI frames by a bi-directional generative diffeomorphic registration neural network. Using this result, we then estimate the Lagrangian motion field between the reference frame and any other frame through a differentiable composition layer. By utilizing temporal information to perform reasonable estimations on spatio-temporal motion fields, this novel method provides a useful solution for motion tracking and image registration in dynamic medical imaging. Our method has been validated on a representative clinical t-MRI dataset; the experimental results show that our method is superior to conventional motion tracking methods in terms of landmark tracking accuracy and inference efficiency.
Monocular 3D Vehicle Detection Using Uncalibrated Traffic Cameras through Homography
Mar 29, 2021


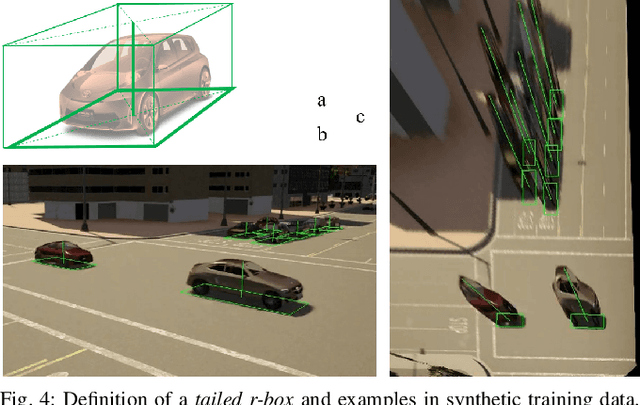
This paper proposes a method to extract the position and pose of vehicles in the 3D world from a single traffic camera. Most previous monocular 3D vehicle detection algorithms focused on cameras on vehicles from the perspective of a driver, and assumed known intrinsic and extrinsic calibration. On the contrary, this paper focuses on the same task using uncalibrated monocular traffic cameras. We observe that the homography between the road plane and the image plane is essential to 3D vehicle detection and the data synthesis for this task, and the homography can be estimated without the camera intrinsics and extrinsics. We conduct 3D vehicle detection by estimating the rotated bounding boxes (r-boxes) in the bird's eye view (BEV) images generated from inverse perspective mapping. We propose a new regression target called \textit{tailed~r-box} and a \textit{dual-view} network architecture which boosts the detection accuracy on warped BEV images. Experiments show that the proposed method can generalize to new camera and environment setups despite not seeing imaged from them during training.
Neural Networks for Semantic Gaze Analysis in XR Settings
Mar 18, 2021
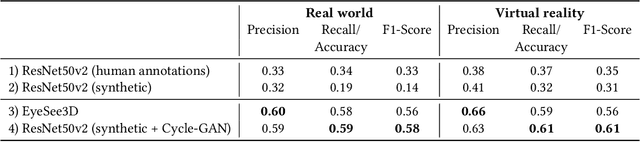
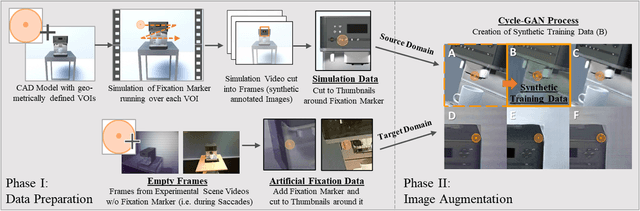
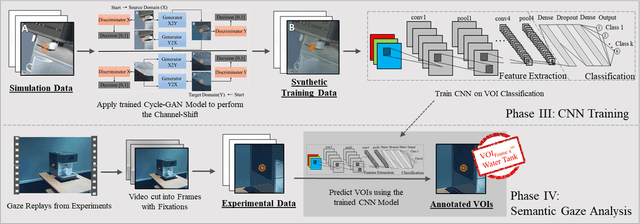
Virtual-reality (VR) and augmented-reality (AR) technology is increasingly combined with eye-tracking. This combination broadens both fields and opens up new areas of application, in which visual perception and related cognitive processes can be studied in interactive but still well controlled settings. However, performing a semantic gaze analysis of eye-tracking data from interactive three-dimensional scenes is a resource-intense task, which so far has been an obstacle to economic use. In this paper we present a novel approach which minimizes time and information necessary to annotate volumes of interest (VOIs) by using techniques from object recognition. To do so, we train convolutional neural networks (CNNs) on synthetic data sets derived from virtual models using image augmentation techniques. We evaluate our method in real and virtual environments, showing that the method can compete with state-of-the-art approaches, while not relying on additional markers or preexisting databases but instead offering cross-platform use.
FastNeRF: High-Fidelity Neural Rendering at 200FPS
Mar 18, 2021
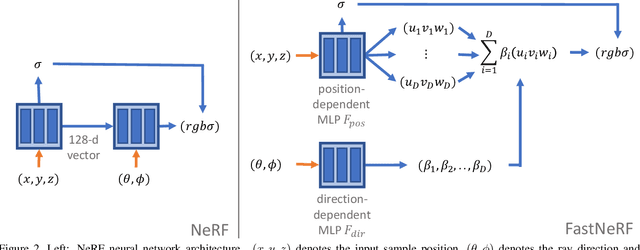
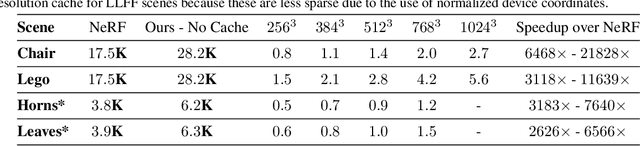
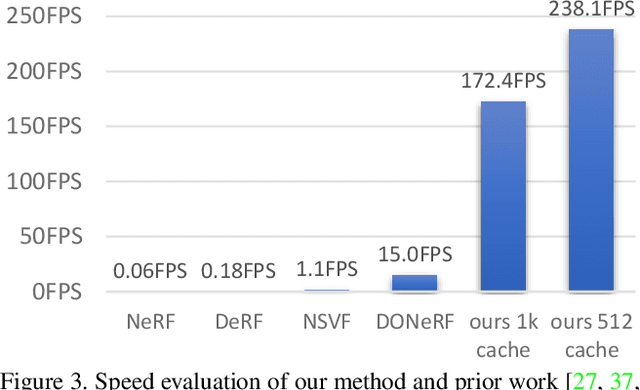
Recent work on Neural Radiance Fields (NeRF) showed how neural networks can be used to encode complex 3D environments that can be rendered photorealistically from novel viewpoints. Rendering these images is very computationally demanding and recent improvements are still a long way from enabling interactive rates, even on high-end hardware. Motivated by scenarios on mobile and mixed reality devices, we propose FastNeRF, the first NeRF-based system capable of rendering high fidelity photorealistic images at 200Hz on a high-end consumer GPU. The core of our method is a graphics-inspired factorization that allows for (i) compactly caching a deep radiance map at each position in space, (ii) efficiently querying that map using ray directions to estimate the pixel values in the rendered image. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF algorithm and at least an order of magnitude faster than existing work on accelerating NeRF, while maintaining visual quality and extensibility.
Incremental Training and Group Convolution Pruning for Runtime DNN Performance Scaling on Heterogeneous Embedded Platforms
May 08, 2021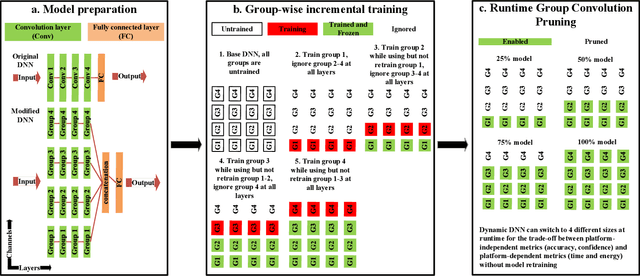
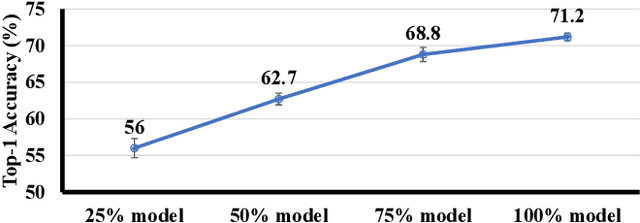
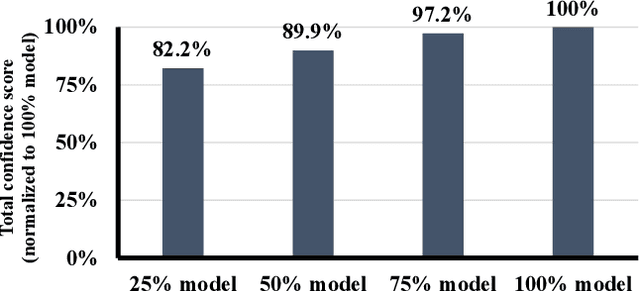
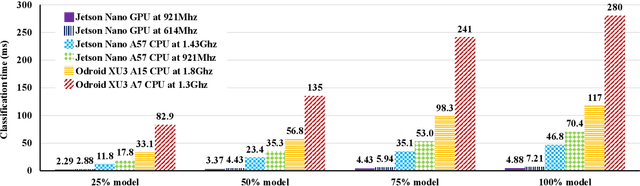
Inference for Deep Neural Networks is increasingly being executed locally on mobile and embedded platforms due to its advantages in latency, privacy and connectivity. Since modern System on Chips typically execute a combination of different and dynamic workloads concurrently, it is challenging to consistently meet inference time/energy budget at runtime because of the local computing resources available to the DNNs vary considerably. To address this challenge, a variety of dynamic DNNs were proposed. However, these works have significant memory overhead, limited runtime recoverable compression rate and narrow dynamic ranges of performance scaling. In this paper, we present a dynamic DNN using incremental training and group convolution pruning. The channels of the DNN convolution layer are divided into groups, which are then trained incrementally. At runtime, following groups can be pruned for inference time/energy reduction or added back for accuracy recovery without model retraining. In addition, we combine task mapping and Dynamic Voltage Frequency Scaling (DVFS) with our dynamic DNN to deliver finer trade-off between accuracy and time/power/energy over a wider dynamic range. We illustrate the approach by modifying AlexNet for the CIFAR10 image dataset and evaluate our work on two heterogeneous hardware platforms: Odroid XU3 (ARM big.LITTLE CPUs) and Nvidia Jetson Nano (CPU and GPU). Compared to the existing works, our approach can provide up to 2.36x (energy) and 2.73x (time) wider dynamic range with a 2.4x smaller memory footprint at the same compression rate. It achieved 10.6x (energy) and 41.6x (time) wider dynamic range by combining with task mapping and DVFS.
Analysis Towards Classification of Infection and Ischaemia of Diabetic Foot Ulcers
Apr 07, 2021
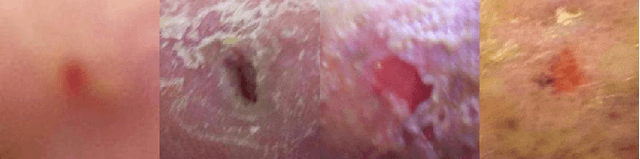
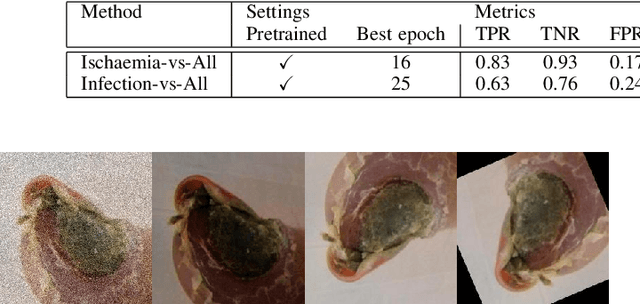
This paper introduces the Diabetic Foot Ulcers dataset (DFUC2021) for analysis of pathology, focusing on infection and ischaemia. We describe the data preparation of DFUC2021 for ground truth annotation, data curation and data analysis. The final release of DFUC2021 consists of 15,683 DFU patches, with 5,955 training, 5,734 for testing and 3,994 unlabeled DFU patches. The ground truth labels are four classes, i.e. control, infection, ischaemia and both conditions. We curate the dataset using image hashing techniques and analyse the separability using UMAP projection. We benchmark the performance of five key backbones of deep learning, i.e. VGG16, ResNet101, InceptionV3, DenseNet121 and EfficientNet on DFUC2021. We report the optimised results of these key backbones with different strategies. Based on our observations, we conclude that EfficientNetB0 with data augmentation and transfer learning provided the best results for multi-class (4-class) classification with macro-average Precision, Recall and F1-score of 0.57, 0.62 and 0.55, respectively. In ischaemia and infection recognition, when trained on one-versus-all, EfficientNetB0 achieved comparable results with the state of the art. Finally, we interpret the results with statistical analysis and Grad-CAM visualisation.
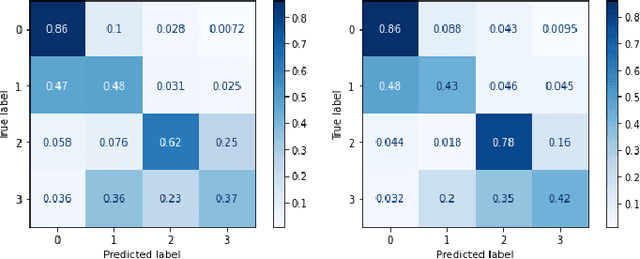
Where and What? Examining Interpretable Disentangled Representations
Apr 07, 2021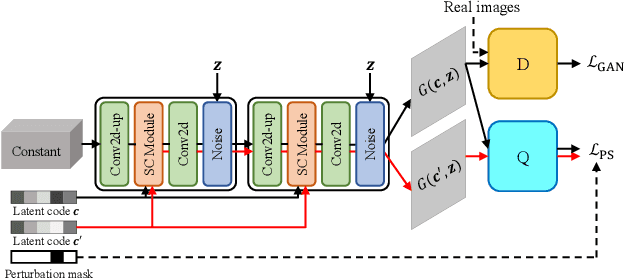
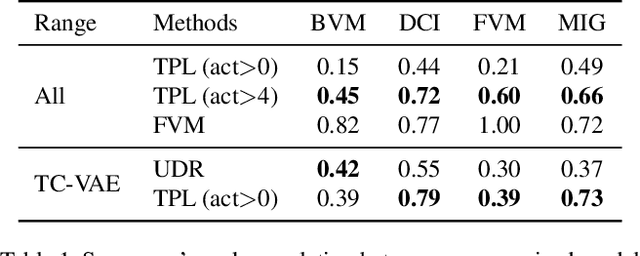
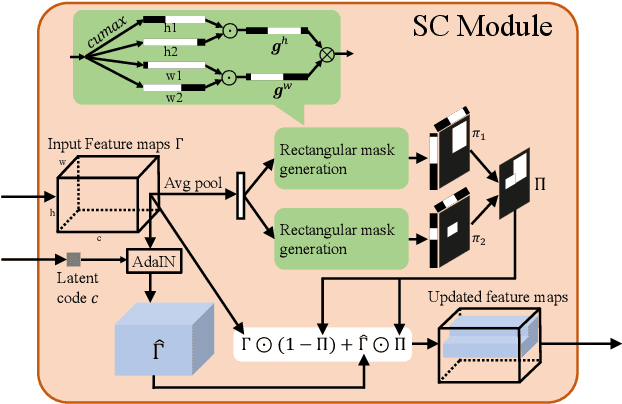
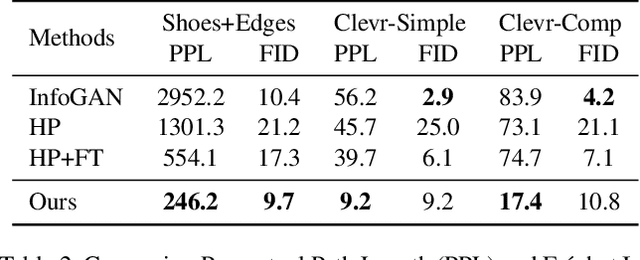
Capturing interpretable variations has long been one of the goals in disentanglement learning. However, unlike the independence assumption, interpretability has rarely been exploited to encourage disentanglement in the unsupervised setting. In this paper, we examine the interpretability of disentangled representations by investigating two questions: where to be interpreted and what to be interpreted? A latent code is easily to be interpreted if it would consistently impact a certain subarea of the resulting generated image. We thus propose to learn a spatial mask to localize the effect of each individual latent dimension. On the other hand, interpretability usually comes from latent dimensions that capture simple and basic variations in data. We thus impose a perturbation on a certain dimension of the latent code, and expect to identify the perturbation along this dimension from the generated images so that the encoding of simple variations can be enforced. Additionally, we develop an unsupervised model selection method, which accumulates perceptual distance scores along axes in the latent space. On various datasets, our models can learn high-quality disentangled representations without supervision, showing the proposed modeling of interpretability is an effective proxy for achieving unsupervised disentanglement.
CONFIG: Controllable Neural Face Image Generation
May 12, 2020
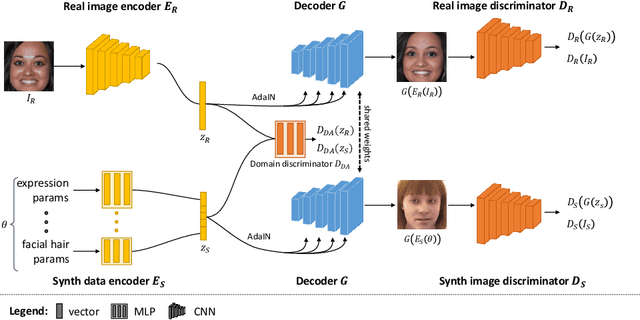


Our ability to sample realistic natural images, particularly faces, has advanced by leaps and bounds in recent years, yet our ability to exert fine-tuned control over the generative process has lagged behind. If this new technology is to find practical uses, we need to achieve a level of control over generative networks which, without sacrificing realism, is on par with that seen in computer graphics and character animation. To this end we propose ConfigNet, a neural face model that allows for controlling individual aspects of output images in semantically meaningful ways and that is a significant step on the path towards finely-controllable neural rendering. ConfigNet is trained on real face images as well as synthetic face renders. Our novel method uses synthetic data to factorize the latent space into elements that correspond to the inputs of a traditional rendering pipeline, separating aspects such as head pose, facial expression, hair style, illumination, and many others which are very hard to annotate in real data. The real images, which are presented to the network without labels, extend the variety of the generated images and encourage realism. Finally, we propose an evaluation criterion using an attribute detection network combined with a user study and demonstrate state-of-the-art individual control over attributes in the output images.
Local Neighborhood Intensity Pattern: A new texture feature descriptor for image retrieval
Jul 02, 2018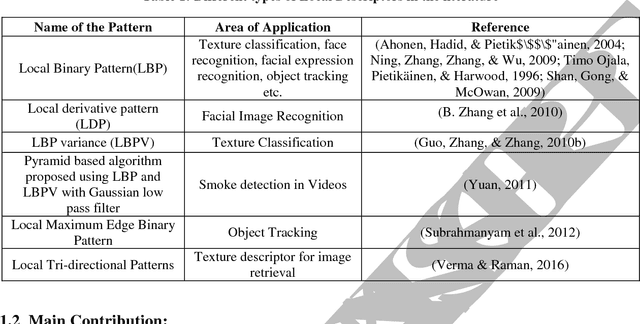
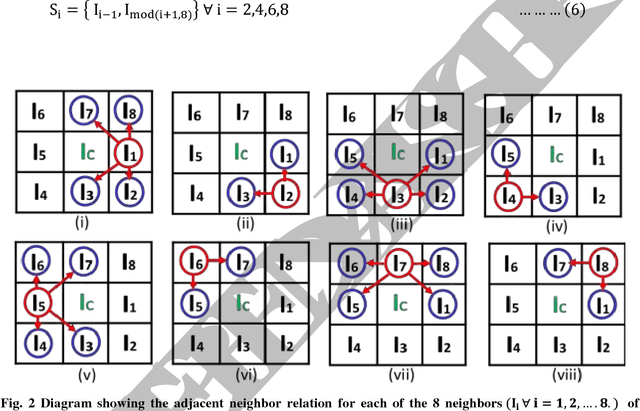
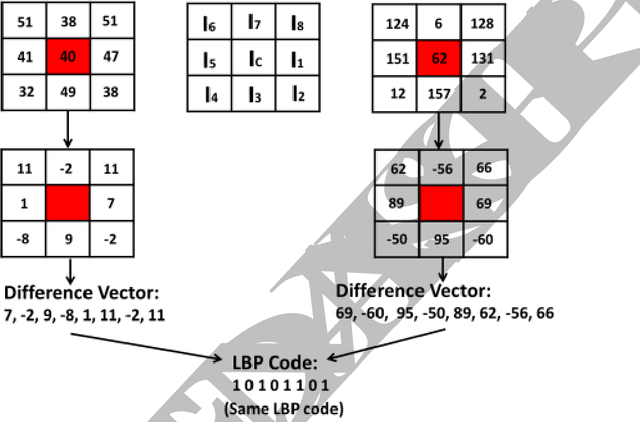
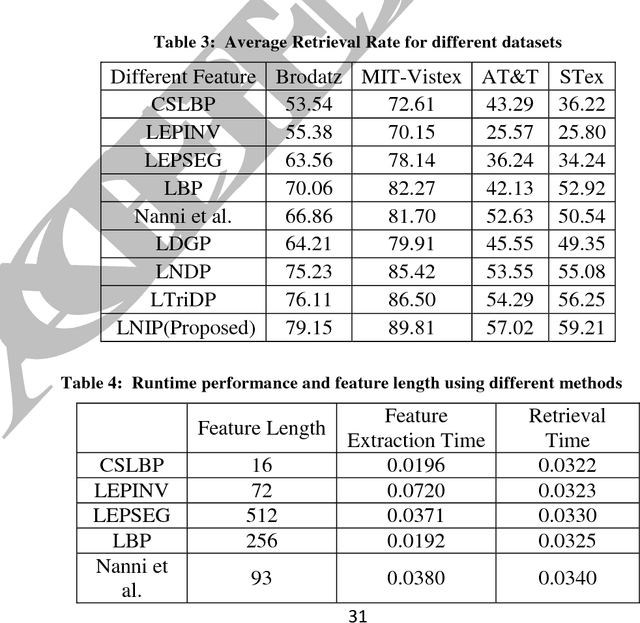
In this paper, a new texture descriptor based on the local neighborhood intensity difference is proposed for content based image retrieval (CBIR). For computation of texture features like Local Binary Pattern (LBP), the center pixel in a 3*3 window of an image is compared with all the remaining neighbors, one pixel at a time to generate a binary bit pattern. It ignores the effect of the adjacent neighbors of a particular pixel for its binary encoding and also for texture description. The proposed method is based on the concept that neighbors of a particular pixel hold a significant amount of texture information that can be considered for efficient texture representation for CBIR. Taking this into account, we develop a new texture descriptor, named as Local Neighborhood Intensity Pattern (LNIP) which considers the relative intensity difference between a particular pixel and the center pixel by considering its adjacent neighbors and generate a sign and a magnitude pattern. Since sign and magnitude patterns hold complementary information to each other, these two patterns are concatenated into a single feature descriptor to generate a more concrete and useful feature descriptor. The proposed descriptor has been tested for image retrieval on four databases, including three texture image databases - Brodatz texture image database, MIT VisTex database and Salzburg texture database and one face database AT&T face database. The precision and recall values observed on these databases are compared with some state-of-art local patterns. The proposed method showed a significant improvement over many other existing methods.