 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Anomalies: a Review and Synthesis of Detection Methods
Aug 07, 2018

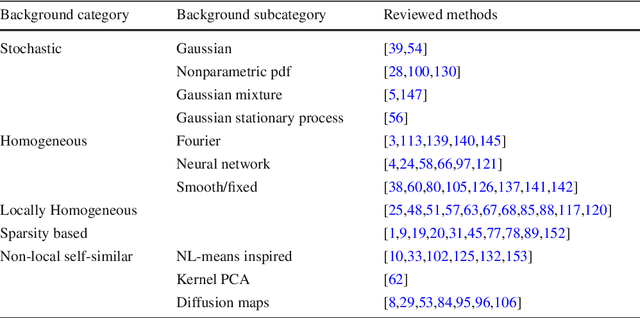

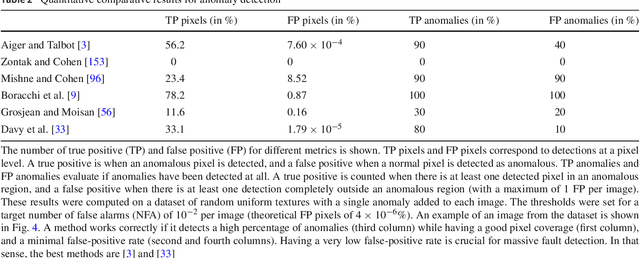
We review the broad variety of methods that have been proposed for anomaly detection in images. Most methods found in the literature have in mind a particular application. Yet we show that the methods can be classified mainly by the structural assumption they make on the "normal" image. Five different structural assumptions emerge. Our analysis leads us to reformulate the best representative algorithms by attaching to them an a contrario detection that controls the number of false positives and thus derive universal detection thresholds. By combining the most general structural assumptions expressing the background's normality with the best proposed statistical detection tools, we end up proposing generic algorithms that seem to generalize or reconcile most methods. We compare the six best representatives of our proposed classes of algorithms on anomalous images taken from classic papers on the subject, and on a synthetic database. Our conclusion is that it is possible to perform automatic anomaly detection on a single image.
Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data
Jul 23, 2018
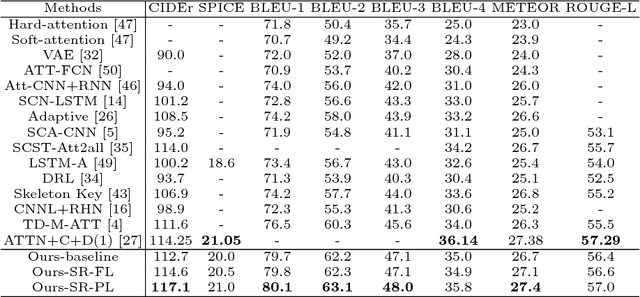
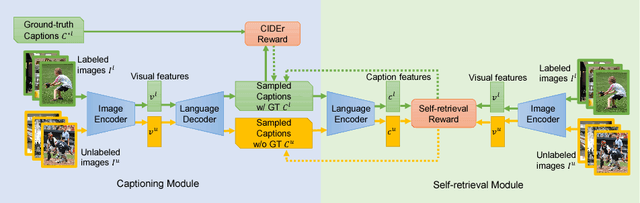
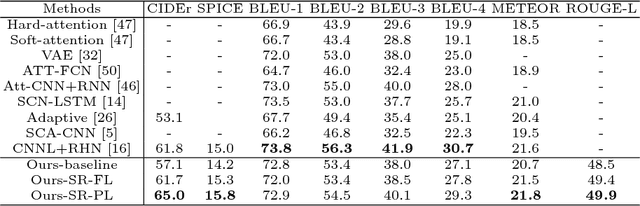
The aim of image captioning is to generate captions by machine to describe image contents. Despite many efforts, generating discriminative captions for images remains non-trivial. Most traditional approaches imitate the language structure patterns, thus tend to fall into a stereotype of replicating frequent phrases or sentences and neglect unique aspects of each image. In this work, we propose an image captioning framework with a self-retrieval module as training guidance, which encourages generating discriminative captions. It brings unique advantages: (1) the self-retrieval guidance can act as a metric and an evaluator of caption discriminativeness to assure the quality of generated captions. (2) The correspondence between generated captions and images are naturally incorporated in the generation process without human annotations, and hence our approach could utilize a large amount of unlabeled images to boost captioning performance with no additional laborious annotations. We demonstrate the effectiveness of the proposed retrieval-guided method on COCO and Flickr30k captioning datasets, and show its superior captioning performance with more discriminative captions.
Selective Output Smoothing Regularization: Regularize Neural Networks by Softening Output Distributions
Mar 29, 2021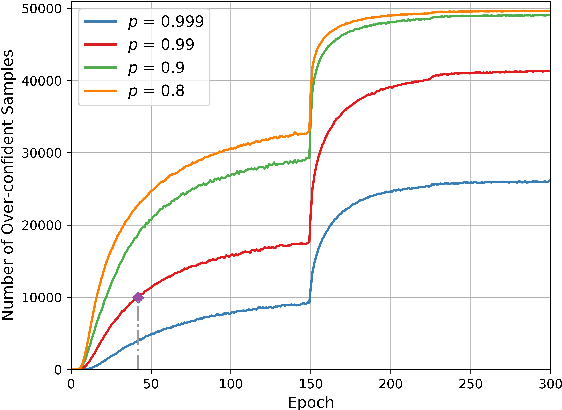
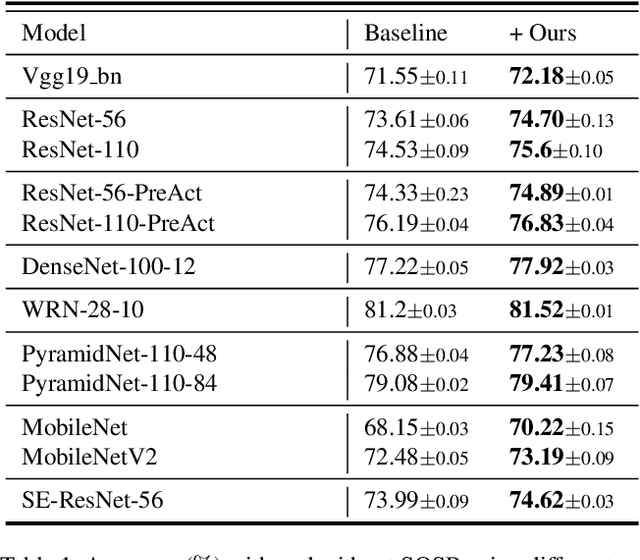
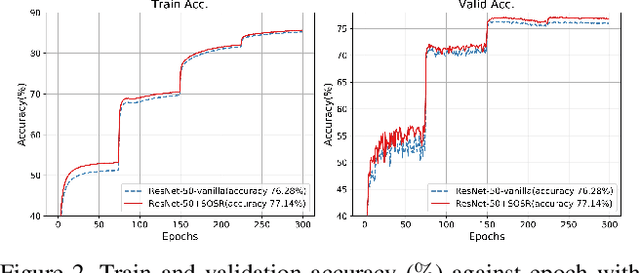

In this paper, we propose Selective Output Smoothing Regularization, a novel regularization method for training the Convolutional Neural Networks (CNNs). Inspired by the diverse effects on training from different samples, Selective Output Smoothing Regularization improves the performance by encouraging the model to produce equal logits on incorrect classes when dealing with samples that the model classifies correctly and over-confidently. This plug-and-play regularization method can be conveniently incorporated into almost any CNN-based project without extra hassle. Extensive experiments have shown that Selective Output Smoothing Regularization consistently achieves significant improvement in image classification benchmarks, such as CIFAR-100, Tiny ImageNet, ImageNet, and CUB-200-2011. Particularly, our method obtains 77.30$\%$ accuracy on ImageNet with ResNet-50, which gains 1.1$\%$ than baseline (76.2$\%$). We also empirically demonstrate the ability of our method to make further improvements when combining with other widely used regularization techniques. On Pascal detection, using the SOSR-trained ImageNet classifier as the pretrained model leads to better detection performances. Moreover, we demonstrate the effectiveness of our method in small sample size problem and imbalanced dataset problem.
Automated Building Image Extraction from 360-degree Panoramas for Post-Disaster Evaluation
May 04, 2019

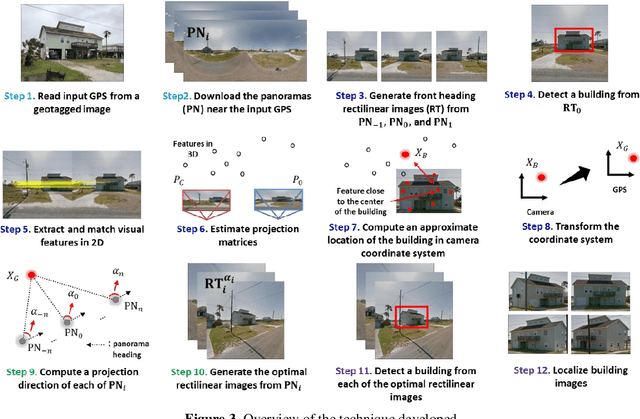
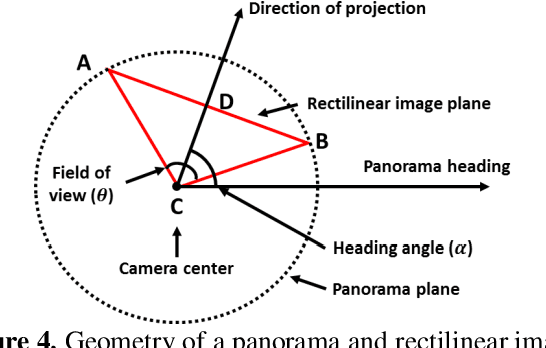
After a disaster, teams of structural engineers collect vast amounts of images from damaged buildings to obtain new knowledge and extract lessons from the event. However, in many cases, the images collected are captured without sufficient spatial context. When damage is severe, it may be quite difficult to even recognize the building. Accessing images of the pre-disaster condition of those buildings is required to accurately identify the cause of the failure or the actual loss in the building. Here, to address this issue, we develop a method to automatically extract pre-event building images from 360o panorama images (panoramas). By providing a geotagged image collected near the target building as the input, panoramas close to the input image location are automatically downloaded through street view services (e.g., Google or Bing in the United States). By computing the geometric relationship between the panoramas and the target building, the most suitable projection direction for each panorama is identified to generate high-quality 2D images of the building. Region-based convolutional neural networks are exploited to recognize the building within those 2D images. Several panoramas are used so that the detected building images provide various viewpoints of the building. To demonstrate the capability of the technique, we consider residential buildings in Holiday Beach, Texas, the United States which experienced significant devastation in Hurricane Harvey in 2017. Using geotagged images gathered during actual post-disaster building reconnaissance missions, we verify the method by successfully extracting residential building images from Google Street View images, which were captured before the event.
Targeted aspect based multimodal sentiment analysis:an attention capsule extraction and multi-head fusion network
Mar 13, 2021
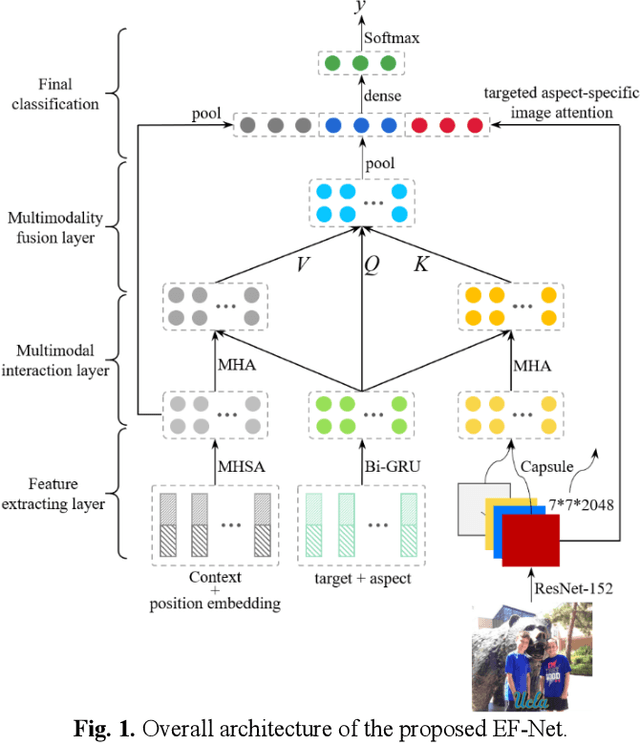
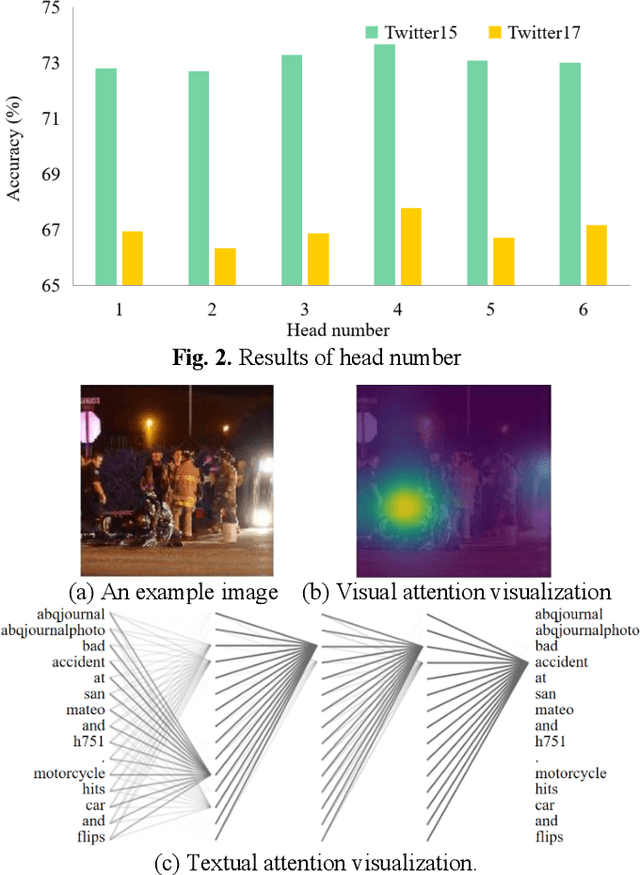
Multimodal sentiment analysis has currently identified its significance in a variety of domains. For the purpose of sentiment analysis, different aspects of distinguishing modalities, which correspond to one target, are processed and analyzed. In this work, we propose the targeted aspect-based multimodal sentiment analysis (TABMSA) for the first time. Furthermore, an attention capsule extraction and multi-head fusion network (EF-Net) on the task of TABMSA is devised. The multi-head attention (MHA) based network and the ResNet-152 are employed to deal with texts and images, respectively. The integration of MHA and capsule network aims to capture the interaction among the multimodal inputs. In addition to the targeted aspect, the information from the context and the image is also incorporated for sentiment delivered. We evaluate the proposed model on two manually annotated datasets. the experimental results demonstrate the effectiveness of our proposed model for this new task.
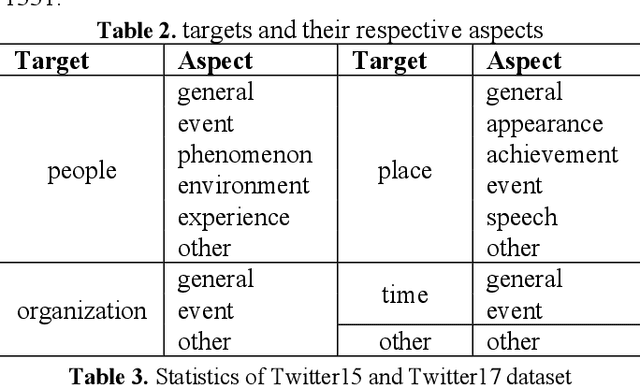
Pix2Prof: fast extraction of sequential information from galaxy imagery via deep learning
Oct 01, 2020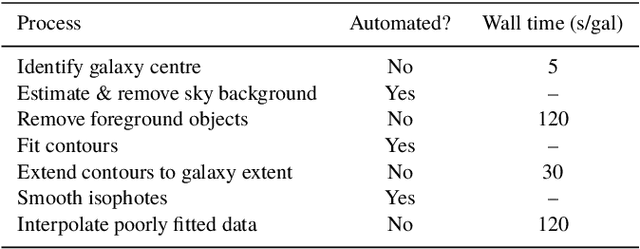
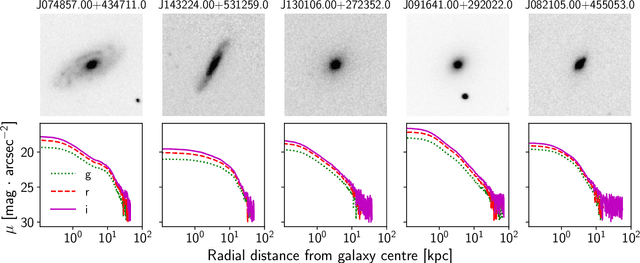
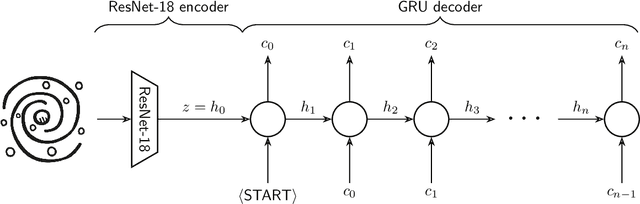
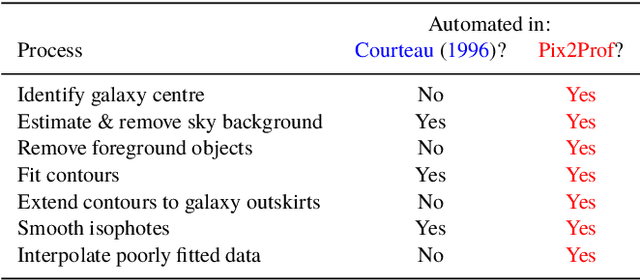
We present "Pix2Prof", a deep learning model that eliminates manual steps in the measurement of galaxy surface brightness (SB) profiles. We argue that a galaxy "profile" of any sort is conceptually similar to an image caption. This idea allows us to leverage image captioning methods from the field of natural language processing, and so we design Pix2Prof as a float sequence "captioning" model suitable for SB profile inferral. We demonstrate the technique by approximating the galaxy SB fitting method described by Courteau (1996), an algorithm with several manual steps. We use g, r, and i-band images from the Sloan Digital Sky Survey (SDSS) Data Release 10 (DR10) to train Pix2Prof on 5367 image--SB profile pairs. We test Pix2Prof on 300 SDSS DR10 galaxy image--SB profile pairs in each of the g, r, and i bands to calibrate the mean SB deviation between interactive manual measurements and automated extractions, and demonstrate the effectiveness of Pix2Prof in mirroring the manual method. Pix2Prof processes $\sim1$ image per second on an Intel Xeon E5-2650 v3 and $\sim2$ images per second on a NVIDIA TESLA V100, improving on the speed of the manual interactive method by more than two orders of magnitude. Crucially, Pix2Prof requires no manual interaction, and since galaxy profile estimation is an embarrassingly parallel problem, we can further increase the throughput by running many Pix2Prof instances simultaneously. In perspective, Pix2Prof would take under an hour to infer profiles for $10^5$ galaxies on a single NVIDIA DGX-2 system. A single human expert would take approximately two years to complete the same task. Automated methodology such as this will accelerate the analysis of the next generation of large area sky surveys expected to yield hundreds of millions of targets. In such instances, all manual approaches -- even those involving a large number of experts -- would be impractical.
A Facial Feature Discovery Framework for Race Classification Using Deep Learning
Mar 29, 2021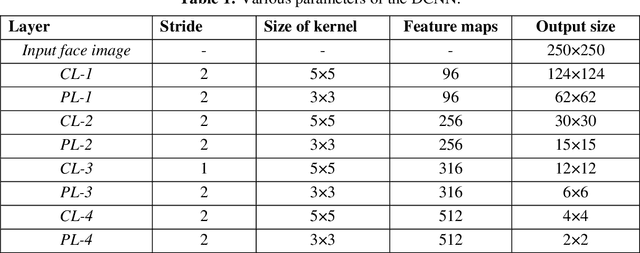
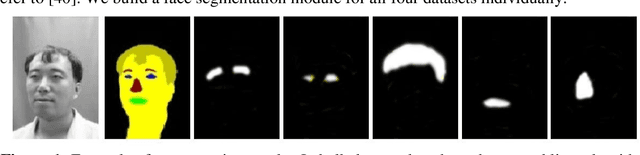
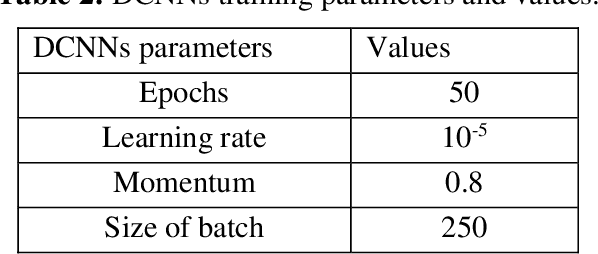

Race classification is a long-standing challenge in the field of face image analysis. The investigation of salient facial features is an important task to avoid processing all face parts. Face segmentation strongly benefits several face analysis tasks, including ethnicity and race classification. We propose a raceclassification algorithm using a prior face segmentation framework. A deep convolutional neural network (DCNN) was used to construct a face segmentation model. For training the DCNN, we label face images according to seven different classes, that is, nose, skin, hair, eyes, brows, back, and mouth. The DCNN model developed in the first phase was used to create segmentation results. The probabilistic classification method is used, and probability maps (PMs) are created for each semantic class. We investigated five salient facial features from among seven that help in race classification. Features are extracted from the PMs of five classes, and a new model is trained based on the DCNN. We assessed the performance of the proposed race classification method on four standard face datasets, reporting superior results compared with previous studies.
* Number of pages in the paper are 15
Revisiting 3D Context Modeling with Supervised Pre-training for Universal Lesion Detection in CT Slices
Dec 16, 2020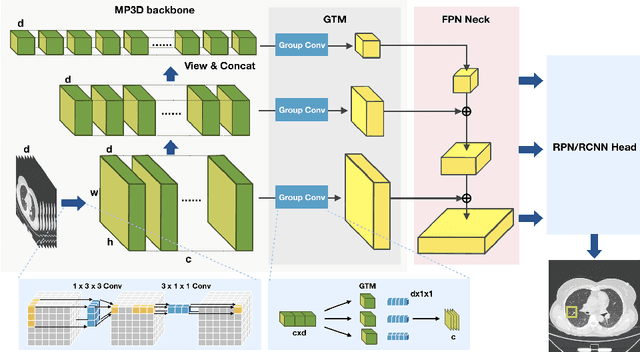
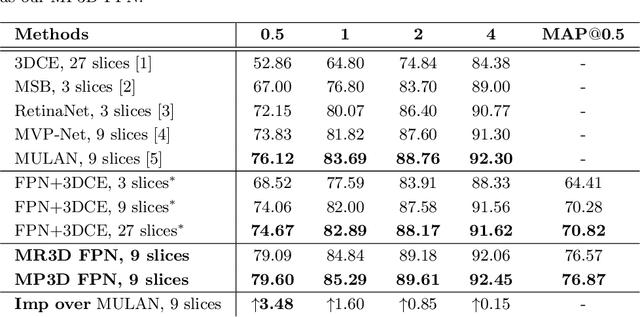
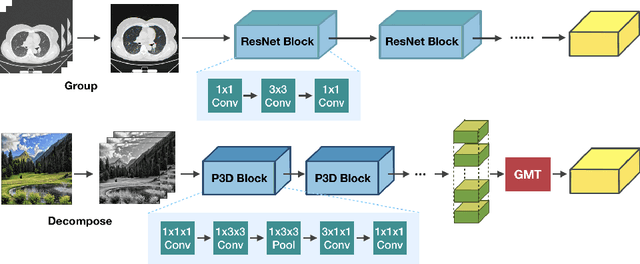

Universal lesion detection from computed tomography (CT) slices is important for comprehensive disease screening. Since each lesion can locate in multiple adjacent slices, 3D context modeling is of great significance for developing automated lesion detection algorithms. In this work, we propose a Modified Pseudo-3D Feature Pyramid Network (MP3D FPN) that leverages depthwise separable convolutional filters and a group transform module (GTM) to efficiently extract 3D context enhanced 2D features for universal lesion detection in CT slices. To facilitate faster convergence, a novel 3D network pre-training method is derived using solely large-scale 2D object detection dataset in the natural image domain. We demonstrate that with the novel pre-training method, the proposed MP3D FPN achieves state-of-the-art detection performance on the DeepLesion dataset (3.48% absolute improvement in the sensitivity of FPs@0.5), significantly surpassing the baseline method by up to 6.06% (in MAP@0.5) which adopts 2D convolution for 3D context modeling. Moreover, the proposed 3D pre-trained weights can potentially be used to boost the performance of other 3D medical image analysis tasks.
Motion Basis Learning for Unsupervised Deep Homography Estimation with Subspace Projection
Mar 29, 2021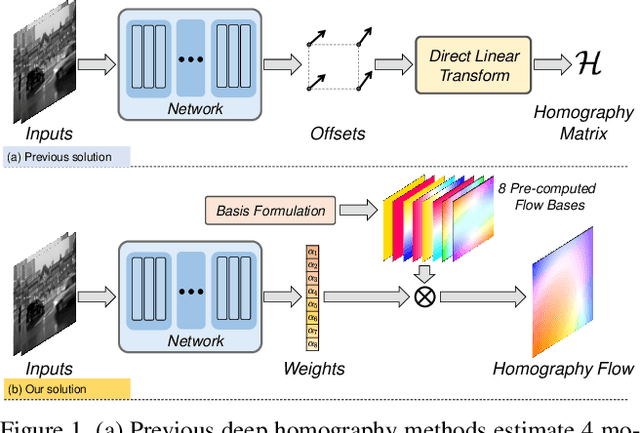
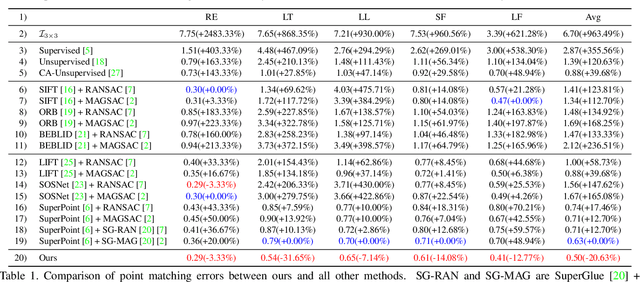
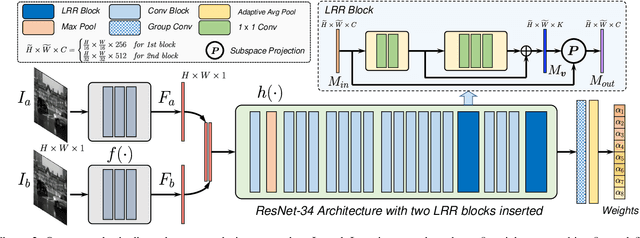

In this paper, we introduce a new framework for unsupervised deep homography estimation. Our contributions are 3 folds. First, unlike previous methods that regress 4 offsets for a homography, we propose a homography flow representation, which can be estimated by a weighted sum of 8 pre-defined homography flow bases. Second, considering a homography contains 8 Degree-of-Freedoms (DOFs) that is much less than the rank of the network features, we propose a Low Rank Representation (LRR) block that reduces the feature rank, so that features corresponding to the dominant motions are retained while others are rejected. Last, we propose a Feature Identity Loss (FIL) to enforce the learned image feature warp-equivariant, meaning that the result should be identical if the order of warp operation and feature extraction is swapped. With this constraint, the unsupervised optimization is achieved more effectively and more stable features are learned. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show our approach outperforms the state-of-the-art on the homography benchmark datasets both qualitatively and quantitatively.
Dual-Consistency Semi-Supervised Learning with Uncertainty Quantification for COVID-19 Lesion Segmentation from CT Images
Apr 07, 2021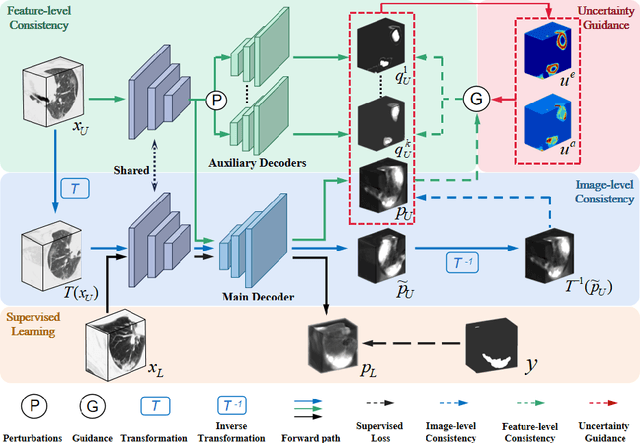
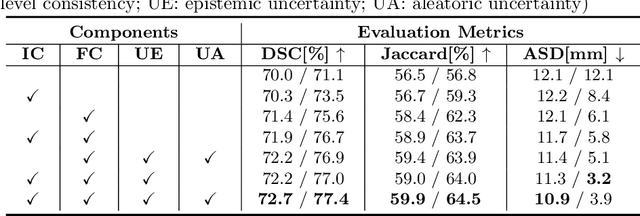
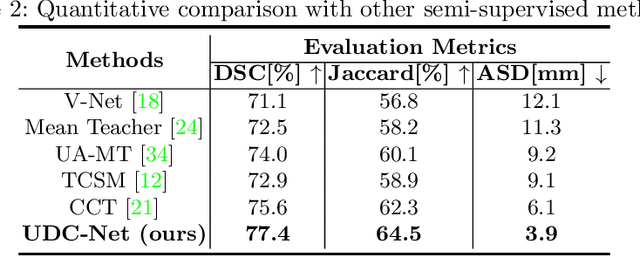
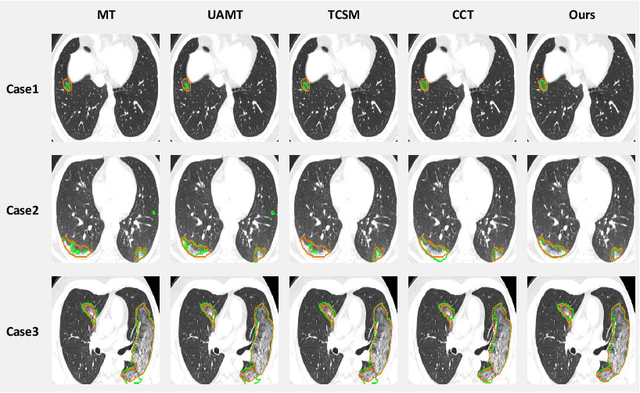
The novel coronavirus disease 2019 (COVID-19) characterized by atypical pneumonia has caused millions of deaths worldwide. Automatically segmenting lesions from chest Computed Tomography (CT) is a promising way to assist doctors in COVID-19 screening, treatment planning, and follow-up monitoring. However, voxel-wise annotations are extremely expert-demanding and scarce, especially when it comes to novel diseases, while an abundance of unlabeled data could be available. To tackle the challenge of limited annotations, in this paper, we propose an uncertainty-guided dual-consistency learning network (UDC-Net) for semi-supervised COVID-19 lesion segmentation from CT images. Specifically, we present a dual-consistency learning scheme that simultaneously imposes image transformation equivalence and feature perturbation invariance to effectively harness the knowledge from unlabeled data. We then quantify both the epistemic uncertainty and the aleatoric uncertainty and employ them together to guide the consistency regularization for more reliable unsupervised learning. Extensive experiments showed that our proposed UDC-Net improves the fully supervised method by 6.3% in Dice and outperforms other competitive semi-supervised approaches by significant margins, demonstrating high potential in real-world clinical practice.