 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Robust Illumination-Invariant Camera System for Agricultural Applications
Jan 06, 2021
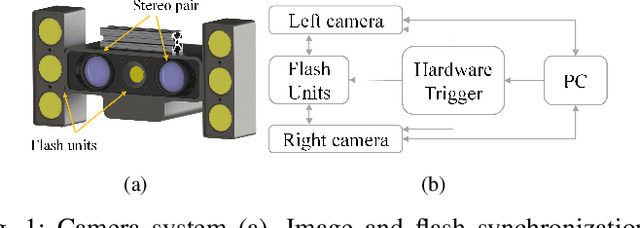

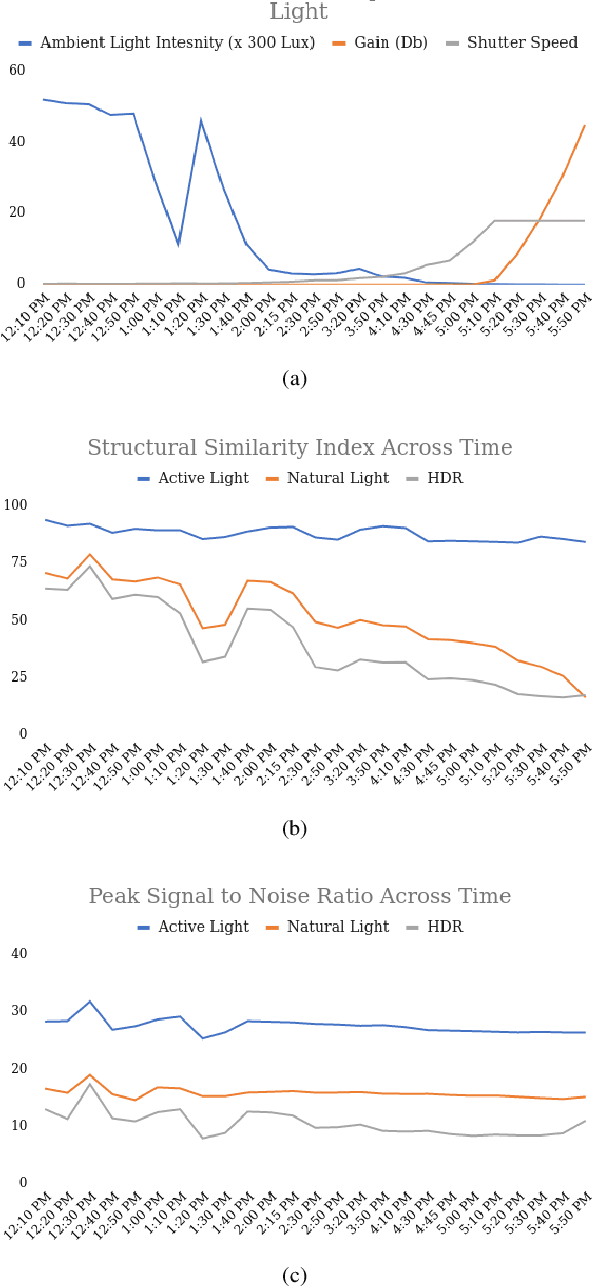
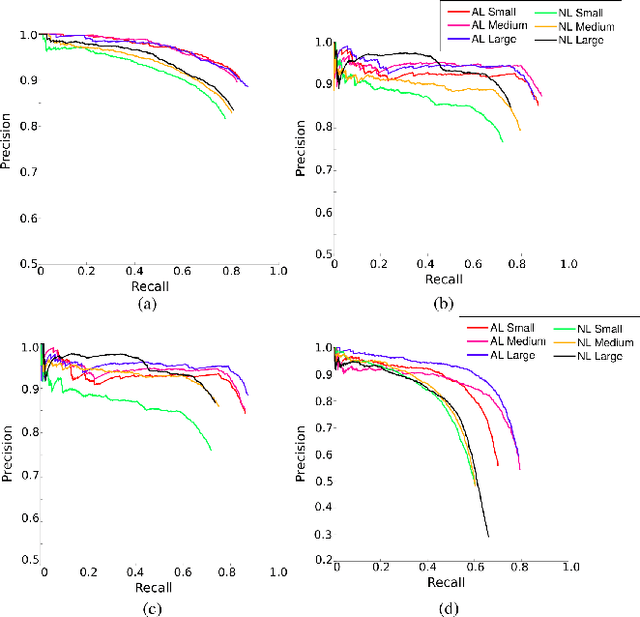
Object detection and semantic segmentation are two of the most widely adopted deep learning algorithms in agricultural applications. One of the major sources of variability in image quality acquired in the outdoors for such tasks is changing lighting condition that can alter the appearance of the objects or the contents of the entire image. While transfer learning and data augmentation to some extent reduce the need for large amount of data to train deep neural networks, the large variety of cultivars and the lack of shared datasets in agriculture makes wide-scale field deployments difficult. In this paper, we present a high throughput robust active lighting-based camera system that generates consistent images in all lighting conditions. We detail experiments that show the consistency in images quality leading to relatively fewer images to train deep neural networks for the task of object detection. We further present results from field experiment under extreme lighting conditions where images without active lighting significantly lack to provide consistent results. The experimental results show that on average, deep nets for object detection trained on consistent data required nearly four times less data to achieve similar level of accuracy. This proposed work could potentially provide pragmatic solutions to computer vision needs in agriculture.
Differentiable Drawing and Sketching
Mar 30, 2021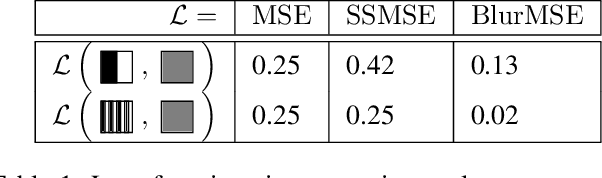

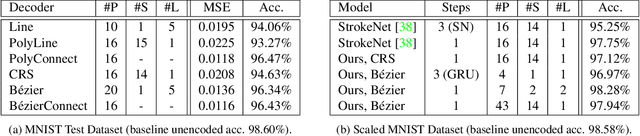

We present a bottom-up differentiable relaxation of the process of drawing points, lines and curves into a pixel raster. Our approach arises from the observation that rasterising a pixel in an image given parameters of a primitive can be reformulated in terms of the primitive's distance transform, and then relaxed to allow the primitive's parameters to be learned. This relaxation allows end-to-end differentiable programs and deep networks to be learned and optimised and provides several building blocks that allow control over how a compositional drawing process is modelled. We emphasise the bottom-up nature of our proposed approach, which allows for drawing operations to be composed in ways that can mimic the physical reality of drawing rather than being tied to, for example, approaches in modern computer graphics. With the proposed approach we demonstrate how sketches can be generated by directly optimising against photographs and how auto-encoders can be built to transform rasterised handwritten digits into vectors without supervision. Extensive experimental results highlight the power of this approach under different modelling assumptions for drawing tasks.
Context Modeling in 3D Human Pose Estimation: A Unified Perspective
Mar 30, 2021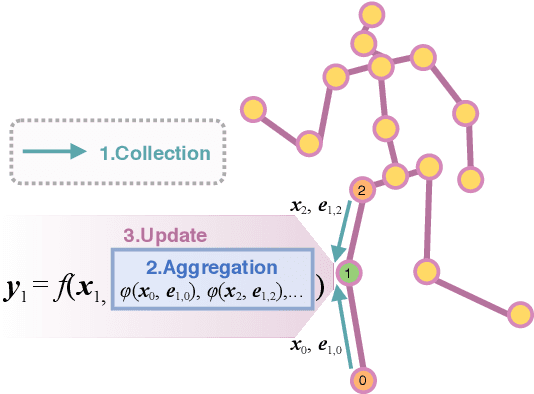
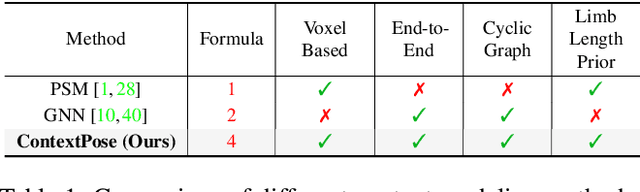
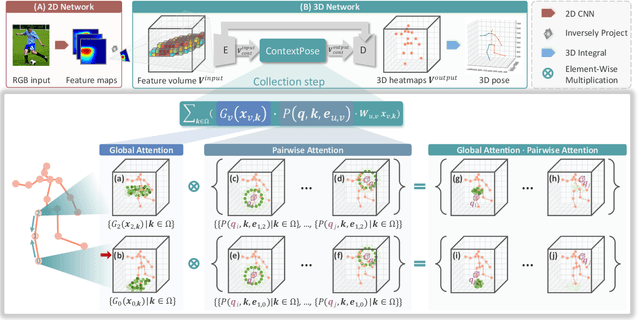
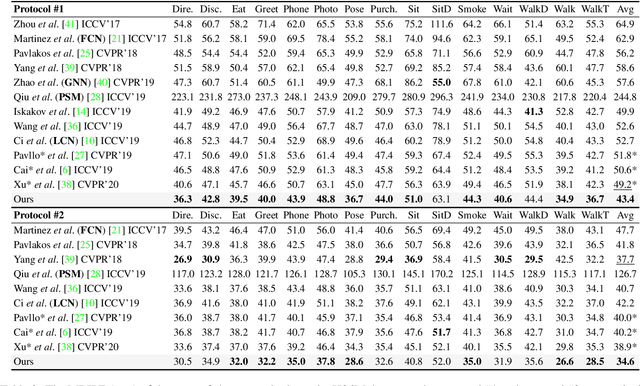
Estimating 3D human pose from a single image suffers from severe ambiguity since multiple 3D joint configurations may have the same 2D projection. The state-of-the-art methods often rely on context modeling methods such as pictorial structure model (PSM) or graph neural network (GNN) to reduce ambiguity. However, there is no study that rigorously compares them side by side. So we first present a general formula for context modeling in which both PSM and GNN are its special cases. By comparing the two methods, we found that the end-to-end training scheme in GNN and the limb length constraints in PSM are two complementary factors to improve results. To combine their advantages, we propose ContextPose based on attention mechanism that allows enforcing soft limb length constraints in a deep network. The approach effectively reduces the chance of getting absurd 3D pose estimates with incorrect limb lengths and achieves state-of-the-art results on two benchmark datasets. More importantly, the introduction of limb length constraints into deep networks enables the approach to achieve much better generalization performance.
DAF-NET: a saliency based weakly supervised method of dual attention fusion for fine-grained image classification
Jan 04, 2020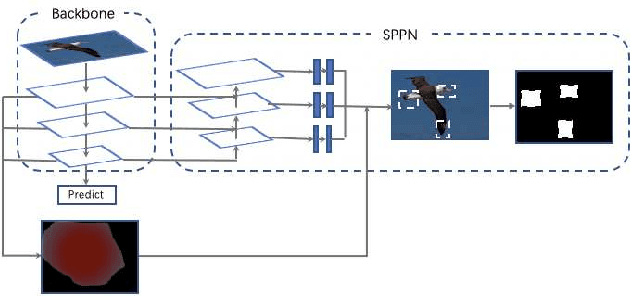
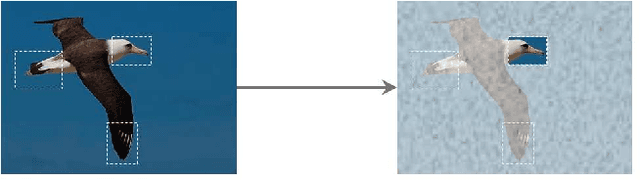
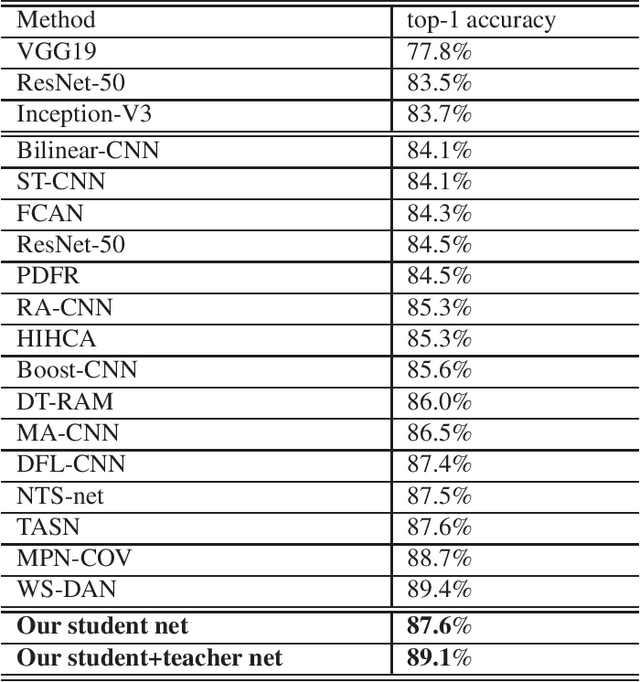
Fine-grained image classification is a challenging problem, since the difficulty of finding discriminative features. To handle this circumstance, basically, there are two ways to go. One is use attention based method to focus on informative areas, while the other one aims to find high order between features. Further, for attention based method there are two directions, activation based and detection based, which are proved effective by scholars. However ,rare work focus on fusing two types of attention with high order feature. In this paper, we propose a novel DAF method which fuse two types of attention and use them to as PAF(part attention filter) in deep bilinear transformation module to mine the relationship between separate parts of an object. Briefly, our network constructed by a student net who attempt to output two attention maps and a teacher net uses these two maps as empirical information to refine the result. The experiment result shows that only student net could get 87.6% accuracy in CUB dataset while cooperating with teacher net could achieve 89.1% accuracy.
Classification by Attention: Scene Graph Classification with Prior Knowledge
Dec 17, 2020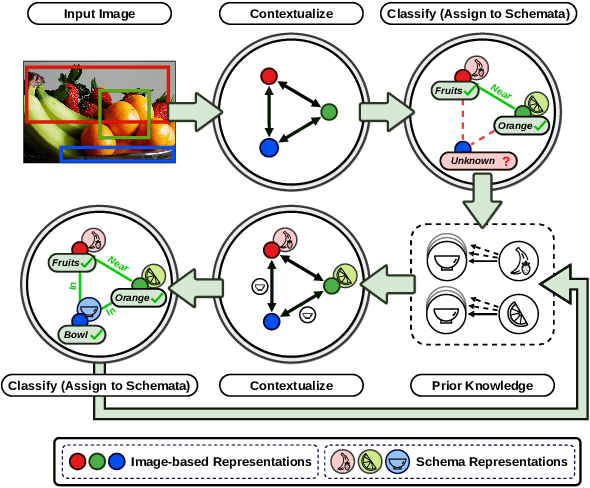
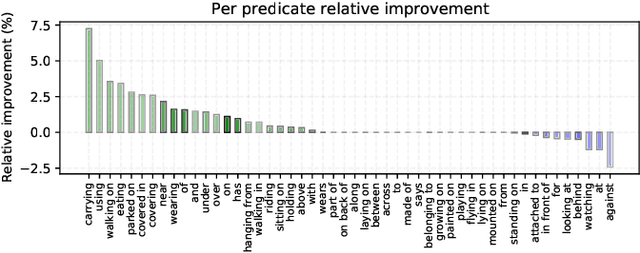
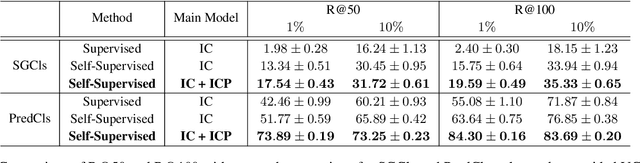

A major challenge in scene graph classification is that the appearance of objects and relations can be significantly different from one image to another. Previous works have addressed this by relational reasoning over all objects in an image or incorporating prior knowledge into classification. Unlike previous works, we do not consider separate models for perception and prior knowledge. Instead, we take a multi-task learning approach, where we implement the classification as an attention layer. This allows for the prior knowledge to emerge and propagate within the perception model. By enforcing the model also to represent the prior, we achieve a strong inductive bias. We show that our model can accurately generate commonsense knowledge and that the iterative injection of this knowledge to scene representations leads to significantly higher classification performance. Additionally, our model can be fine-tuned on external knowledge given as triples. When combined with self-supervised learning and with 1% of annotated images only, this gives more than 3% improvement in object classification, 26% in scene graph classification, and 36% in predicate prediction accuracy.
FoodAI: Food Image Recognition via Deep Learning for Smart Food Logging
Sep 26, 2019



An important aspect of health monitoring is effective logging of food consumption. This can help management of diet-related diseases like obesity, diabetes, and even cardiovascular diseases. Moreover, food logging can help fitness enthusiasts, and people who wanting to achieve a target weight. However, food-logging is cumbersome, and requires not only taking additional effort to note down the food item consumed regularly, but also sufficient knowledge of the food item consumed (which is difficult due to the availability of a wide variety of cuisines). With increasing reliance on smart devices, we exploit the convenience offered through the use of smart phones and propose a smart-food logging system: FoodAI, which offers state-of-the-art deep-learning based image recognition capabilities. FoodAI has been developed in Singapore and is particularly focused on food items commonly consumed in Singapore. FoodAI models were trained on a corpus of 400,000 food images from 756 different classes. In this paper we present extensive analysis and insights into the development of this system. FoodAI has been deployed as an API service and is one of the components powering Healthy 365, a mobile app developed by Singapore's Heath Promotion Board. We have over 100 registered organizations (universities, companies, start-ups) subscribing to this service and actively receive several API requests a day. FoodAI has made food logging convenient, aiding smart consumption and a healthy lifestyle.
Robust Differentiable SVD
Apr 08, 2021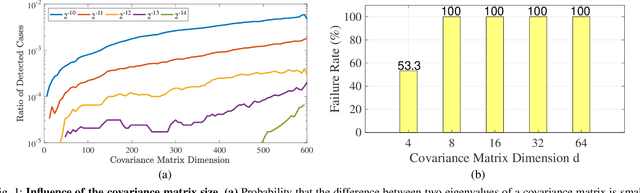



Eigendecomposition of symmetric matrices is at the heart of many computer vision algorithms. However, the derivatives of the eigenvectors tend to be numerically unstable, whether using the SVD to compute them analytically or using the Power Iteration (PI) method to approximate them. This instability arises in the presence of eigenvalues that are close to each other. This makes integrating eigendecomposition into deep networks difficult and often results in poor convergence, particularly when dealing with large matrices. While this can be mitigated by partitioning the data into small arbitrary groups, doing so has no theoretical basis and makes it impossible to exploit the full power of eigendecomposition. In previous work, we mitigated this using SVD during the forward pass and PI to compute the gradients during the backward pass. However, the iterative deflation procedure required to compute multiple eigenvectors using PI tends to accumulate errors and yield inaccurate gradients. Here, we show that the Taylor expansion of the SVD gradient is theoretically equivalent to the gradient obtained using PI without relying in practice on an iterative process and thus yields more accurate gradients. We demonstrate the benefits of this increased accuracy for image classification and style transfer.
* IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) PREPRINT 2021
Weakly-Supervised Multi-Face 3D Reconstruction
Jan 06, 2021


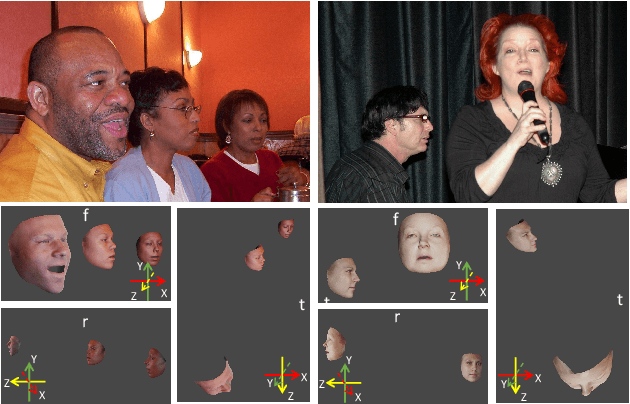
3D face reconstruction plays a very important role in many real-world multimedia applications, including digital entertainment, social media, affection analysis, and person identification. The de-facto pipeline for estimating the parametric face model from an image requires to firstly detect the facial regions with landmarks, and then crop each face to feed the deep learning-based regressor. Comparing to the conventional methods performing forward inference for each detected instance independently, we suggest an effective end-to-end framework for multi-face 3D reconstruction, which is able to predict the model parameters of multiple instances simultaneously using single network inference. Our proposed approach not only greatly reduces the computational redundancy in feature extraction but also makes the deployment procedure much easier using the single network model. More importantly, we employ the same global camera model for the reconstructed faces in each image, which makes it possible to recover the relative head positions and orientations in the 3D scene. We have conducted extensive experiments to evaluate our proposed approach on the sparse and dense face alignment tasks. The experimental results indicate that our proposed approach is very promising on face alignment tasks without fully-supervision and pre-processing like detection and crop. Our implementation is publicly available at \url{https://github.com/kalyo-zjl/WM3DR}.
Geometry-based Distance Decomposition for Monocular 3D Object Detection
Apr 08, 2021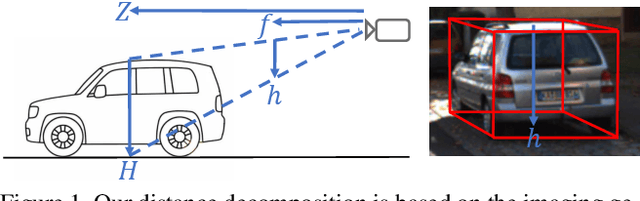
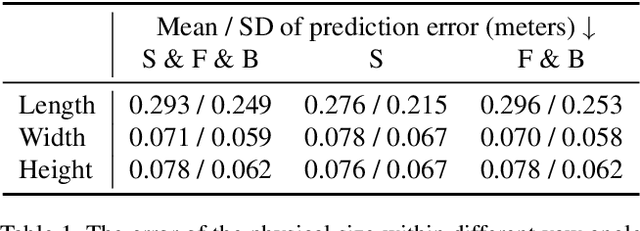

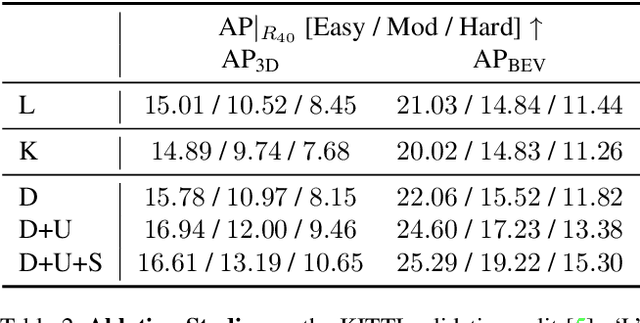
Monocular 3D object detection is of great significance for autonomous driving but remains challenging. The core challenge is to predict the distance of objects in the absence of explicit depth information. Unlike regressing the distance as a single variable in most existing methods, we propose a novel geometry-based distance decomposition to recover the distance by its factors. The decomposition factors the distance of objects into the most representative and stable variables, i.e. the physical height and the projected visual height in the image plane. Moreover, the decomposition maintains the self-consistency between the two heights, leading to the robust distance prediction when both predicted heights are inaccurate. The decomposition also enables us to trace the cause of the distance uncertainty for different scenarios. Such decomposition makes the distance prediction interpretable, accurate, and robust. Our method directly predicts 3D bounding boxes from RGB images with a compact architecture, making the training and inference simple and efficient. The experimental results show that our method achieves the state-of-the-art performance on the monocular 3D Object detection and Birds Eye View tasks on the KITTI dataset, and can generalize to images with different camera intrinsics.
Shape, Illumination, and Reflectance from Shading
Oct 07, 2020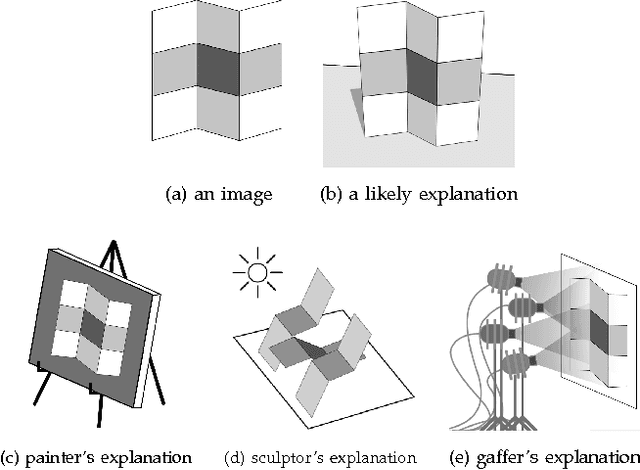
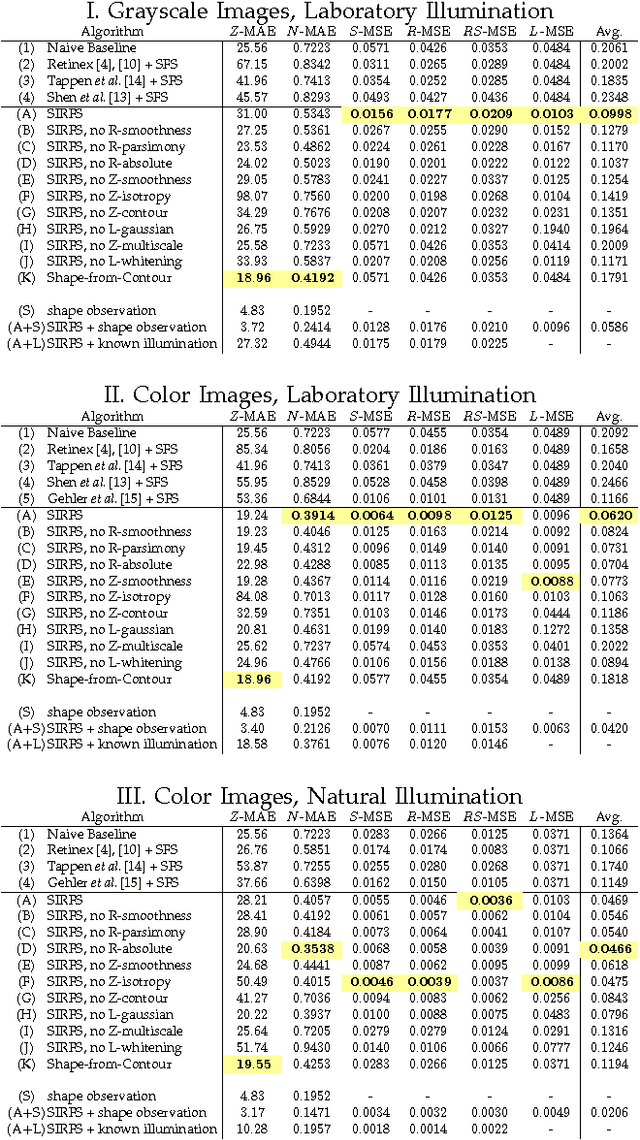
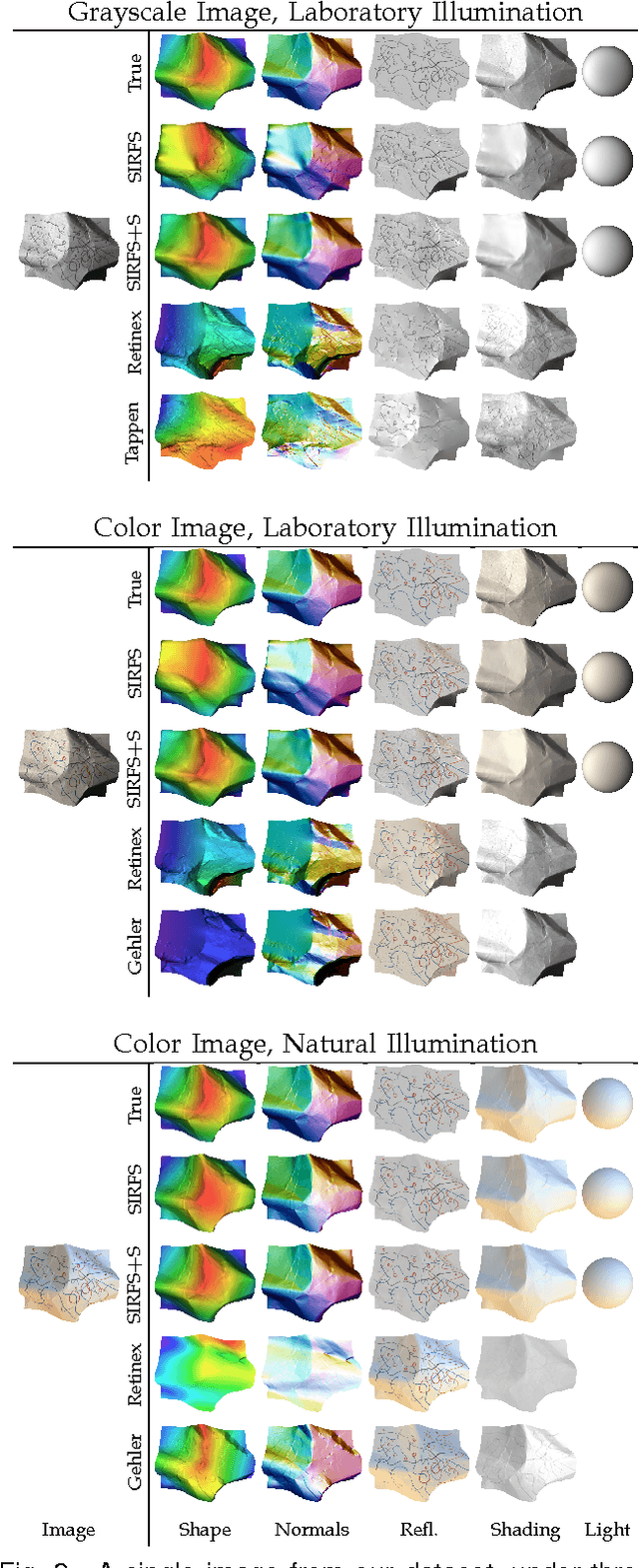
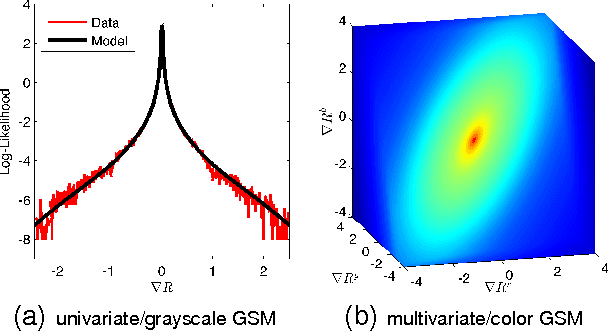
A fundamental problem in computer vision is that of inferring the intrinsic, 3D structure of the world from flat, 2D images of that world. Traditional methods for recovering scene properties such as shape, reflectance, or illumination rely on multiple observations of the same scene to overconstrain the problem. Recovering these same properties from a single image seems almost impossible in comparison -- there are an infinite number of shapes, paint, and lights that exactly reproduce a single image. However, certain explanations are more likely than others: surfaces tend to be smooth, paint tends to be uniform, and illumination tends to be natural. We therefore pose this problem as one of statistical inference, and define an optimization problem that searches for the *most likely* explanation of a single image. Our technique can be viewed as a superset of several classic computer vision problems (shape-from-shading, intrinsic images, color constancy, illumination estimation, etc) and outperforms all previous solutions to those constituent problems.