 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hopper: Multi-hop Transformer for Spatiotemporal Reasoning
Mar 22, 2021
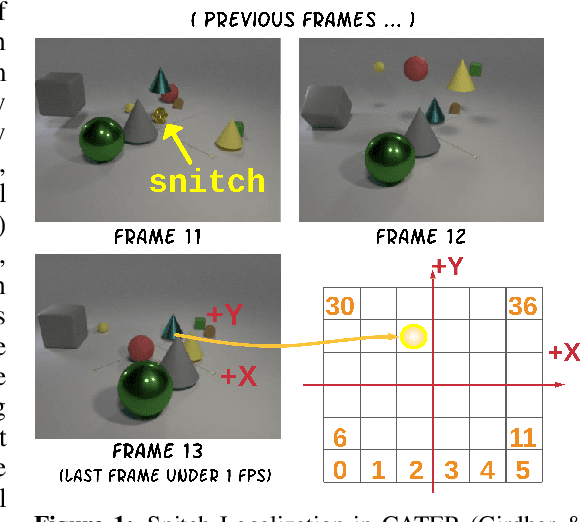
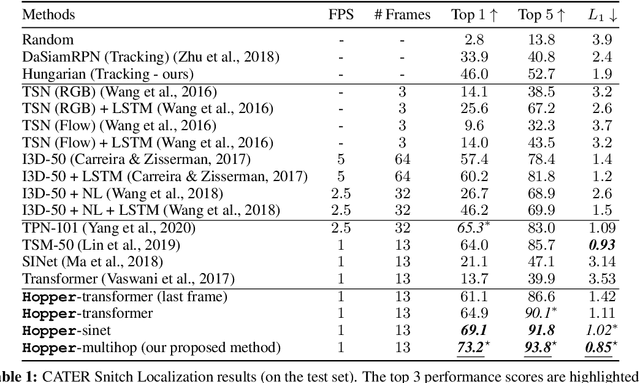
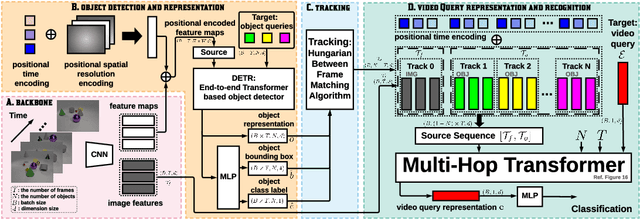
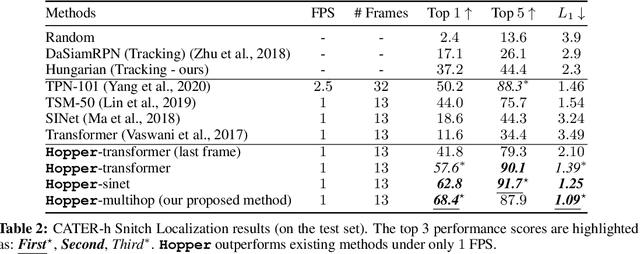
This paper considers the problem of spatiotemporal object-centric reasoning in videos. Central to our approach is the notion of object permanence, i.e., the ability to reason about the location of objects as they move through the video while being occluded, contained or carried by other objects. Existing deep learning based approaches often suffer from spatiotemporal biases when applied to video reasoning problems. We propose Hopper, which uses a Multi-hop Transformer for reasoning object permanence in videos. Given a video and a localization query, Hopper reasons over image and object tracks to automatically hop over critical frames in an iterative fashion to predict the final position of the object of interest. We demonstrate the effectiveness of using a contrastive loss to reduce spatiotemporal biases. We evaluate over CATER dataset and find that Hopper achieves 73.2% Top-1 accuracy using just 1 FPS by hopping through just a few critical frames. We also demonstrate Hopper can perform long-term reasoning by building a CATER-h dataset that requires multi-step reasoning to localize objects of interest correctly.
Decorrelating Adversarial Nets for Clustering Mobile Network Data
Mar 11, 2021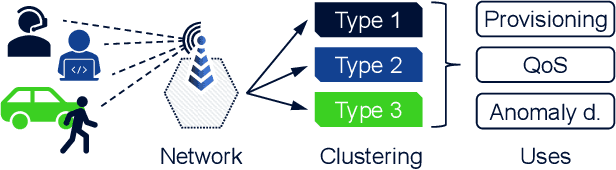
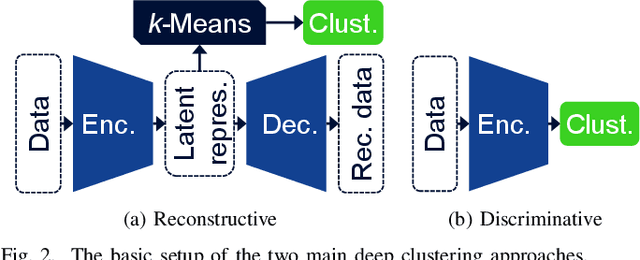
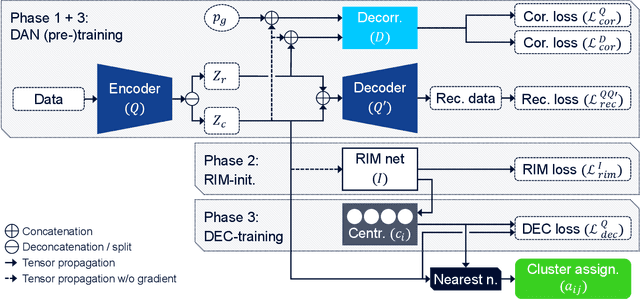
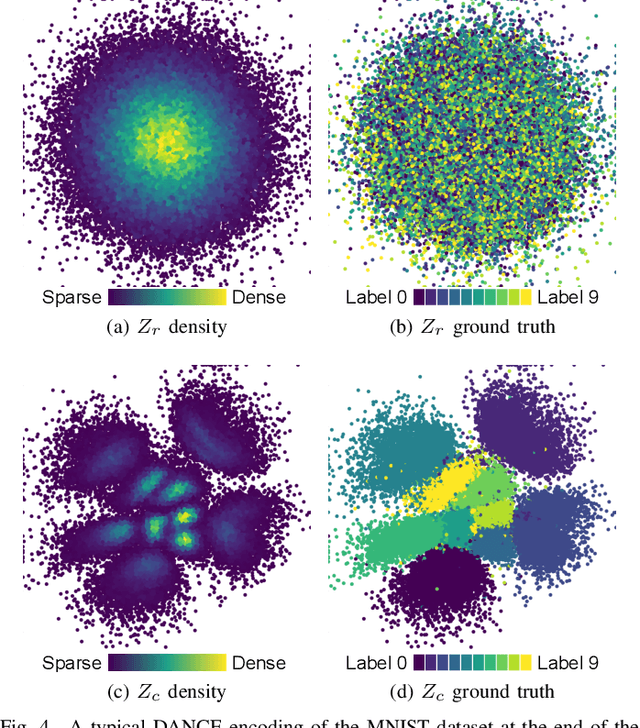
Deep learning will play a crucial role in enabling cognitive automation for the mobile networks of the future. Deep clustering, a subset of deep learning, could be a valuable tool for many network automation use-cases. Unfortunately, most state-of-the-art clustering algorithms target image datasets, which makes them hard to apply to mobile network data due to their highly tuned nature and related assumptions about the data. In this paper, we propose a new algorithm, DANCE (Decorrelating Adversarial Nets for Clustering-friendly Encoding), intended to be a reliable deep clustering method which also performs well when applied to network automation use-cases. DANCE uses a reconstructive clustering approach, separating clustering-relevant from clustering-irrelevant features in a latent representation. This separation removes unnecessary information from the clustering, increasing consistency and peak performance. We comprehensively evaluate DANCE and other select state-of-the-art deep clustering algorithms, and show that DANCE outperforms these algorithms by a significant margin on a mobile network dataset.
Confidence-aware Non-repetitive Multimodal Transformers for TextCaps
Dec 08, 2020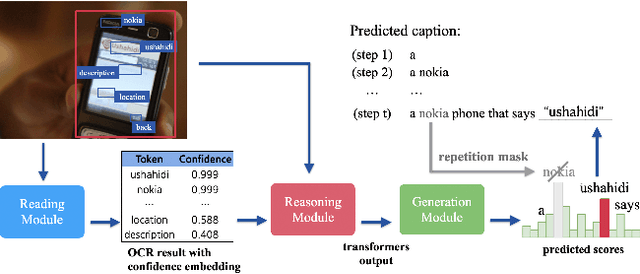
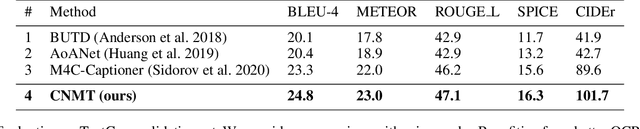
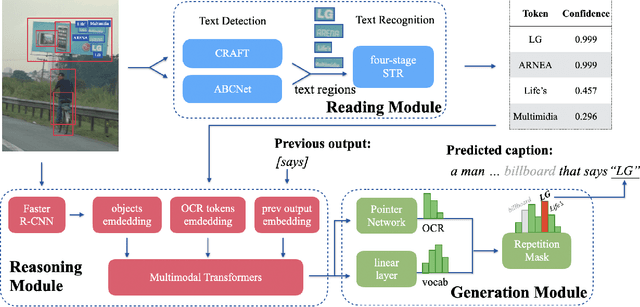
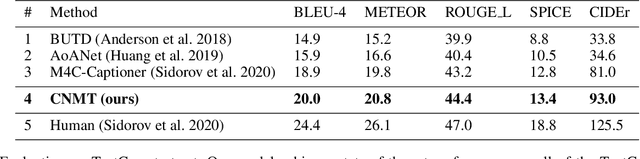
When describing an image, reading text in the visual scene is crucial to understand the key information. Recent work explores the TextCaps task, i.e. image captioning with reading Optical Character Recognition (OCR) tokens, which requires models to read text and cover them in generated captions. Existing approaches fail to generate accurate descriptions because of their (1) poor reading ability; (2) inability to choose the crucial words among all extracted OCR tokens; (3) repetition of words in predicted captions. To this end, we propose a Confidence-aware Non-repetitive Multimodal Transformers (CNMT) to tackle the above challenges. Our CNMT consists of a reading, a reasoning and a generation modules, in which Reading Module employs better OCR systems to enhance text reading ability and a confidence embedding to select the most noteworthy tokens. To address the issue of word redundancy in captions, our Generation Module includes a repetition mask to avoid predicting repeated word in captions. Our model outperforms state-of-the-art models on TextCaps dataset, improving from 81.0 to 93.0 in CIDEr. Our source code is publicly available.
Brain Tumor Classification Using Medial Residual Encoder Layers
Nov 01, 2020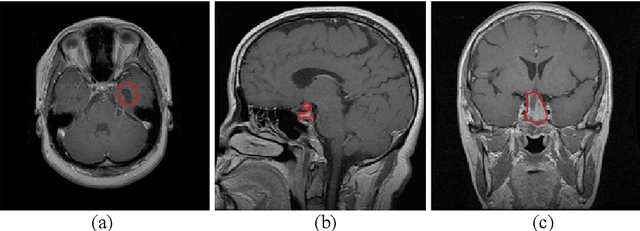

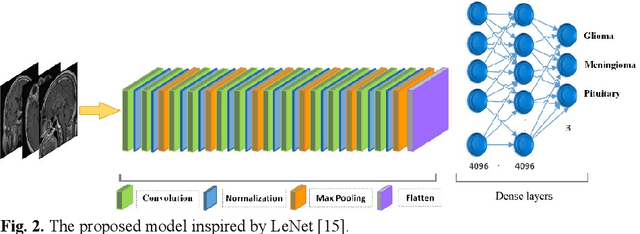
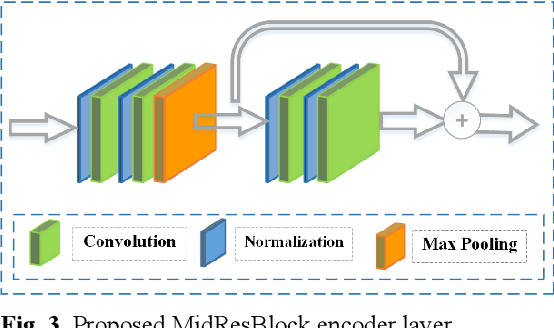
According to the World Health Organization, cancer is the second leading cause of death worldwide, responsible for over 9.5 million deaths in 2018 alone. Brain tumors count for one out of every four cancer deaths. Accurate and timely diagnosis of brain tumors will lead to more effective treatments. To date, several image classification approaches have been proposed to aid diagnosis and treatment. We propose an encoder layer that uses post-max-pooling features for residual learning. Our approach shows promising results by improving the tumor classification accuracy in MR images using a limited medical image dataset. Experimental evaluations of this model on a dataset consisting of 3064 MR images show 95-98% accuracy, which is better than previous studies on this database.
On the stability of deep convolutional neural networks under irregular or random deformations
Apr 24, 2021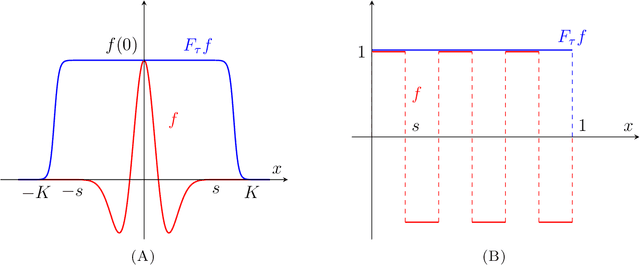
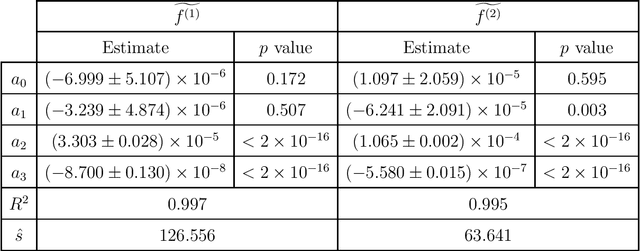

The problem of robustness under location deformations for deep convolutional neural networks (DCNNs) is of great theoretical and practical interest. This issue has been studied in pioneering works, especially for scattering-type architectures, for deformation vector fields $\tau(x)$ with some regularity - at least $C^1$. Here we address this issue for any field $\tau\in L^\infty(\mathbb{R}^d;\mathbb{R}^d)$, without any additional regularity assumption, hence including the case of wild irregular deformations such as a noise on the pixel location of an image. We prove that for signals in multiresolution approximation spaces $U_s$ at scale $s$, whenever the network is Lipschitz continuous (regardless of its architecture), stability in $L^2$ holds in the regime $\|\tau\|_{L^\infty}/s\ll 1$, essentially as a consequence of the uncertainty principle. When $\|\tau\|_{L^\infty}/s\gg 1$ instability can occur even for well-structured DCNNs such as the wavelet scattering networks, and we provide a sharp upper bound for the asymptotic growth rate. The stability results are then extended to signals in the Besov space $B^{d/2}_{2,1}$ tailored to the given multiresolution approximation. We also consider the case of more general time-frequency deformations. Finally, we provide stochastic versions of the aforementioned results, namely we study the issue of stability in mean when $\tau(x)$ is modeled as a random field (not bounded, in general) with with identically distributed variables $|\tau(x)|$, $x\in\mathbb{R}^d$.
Layout-Guided Novel View Synthesis from a Single Indoor Panorama
Mar 31, 2021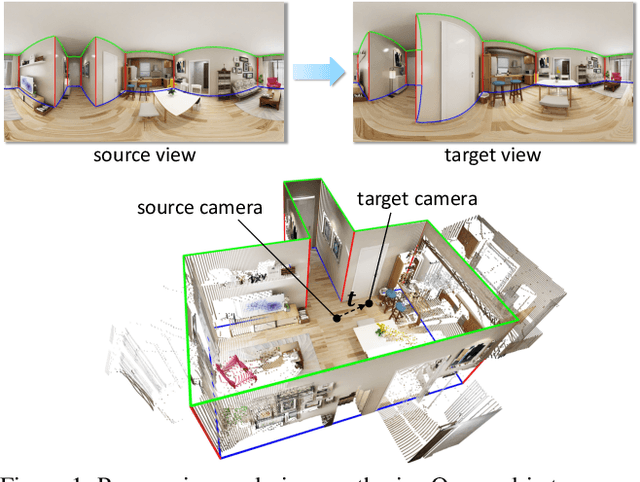
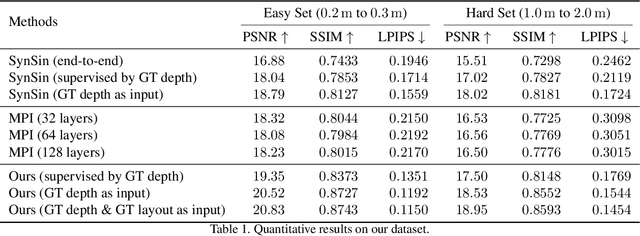
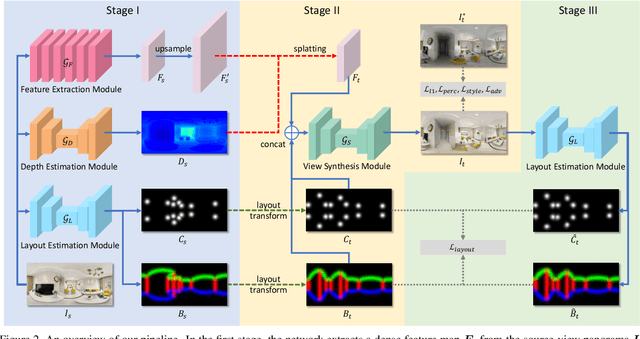
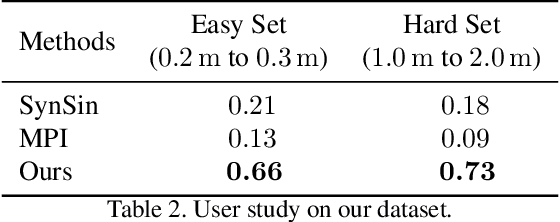
Existing view synthesis methods mainly focus on the perspective images and have shown promising results. However, due to the limited field-of-view of the pinhole camera, the performance quickly degrades when large camera movements are adopted. In this paper, we make the first attempt to generate novel views from a single indoor panorama and take the large camera translations into consideration. To tackle this challenging problem, we first use Convolutional Neural Networks (CNNs) to extract the deep features and estimate the depth map from the source-view image. Then, we leverage the room layout prior, a strong structural constraint of the indoor scene, to guide the generation of target views. More concretely, we estimate the room layout in the source view and transform it into the target viewpoint as guidance. Meanwhile, we also constrain the room layout of the generated target-view images to enforce geometric consistency. To validate the effectiveness of our method, we further build a large-scale photo-realistic dataset containing both small and large camera translations. The experimental results on our challenging dataset demonstrate that our method achieves state-of-the-art performance. The project page is at https://github.com/bluestyle97/PNVS.
IR2VI: Enhanced Night Environmental Perception by Unsupervised Thermal Image Translation
Jun 25, 2018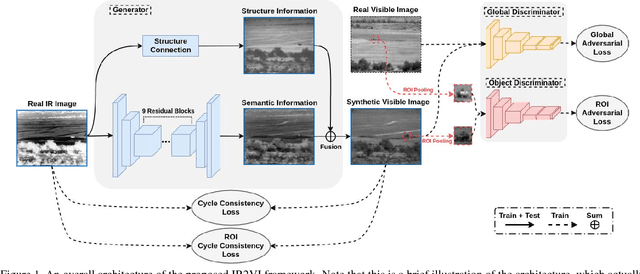



Context enhancement is critical for night vision (NV) applications, especially for the dark night situation without any artificial lights. In this paper, we present the infrared-to-visual (IR2VI) algorithm, a novel unsupervised thermal-to-visible image translation framework based on generative adversarial networks (GANs). IR2VI is able to learn the intrinsic characteristics from VI images and integrate them into IR images. Since the existing unsupervised GAN-based image translation approaches face several challenges, such as incorrect mapping and lack of fine details, we propose a structure connection module and a region-of-interest (ROI) focal loss method to address the current limitations. Experimental results show the superiority of the IR2VI algorithm over baseline methods.
Efficient Initial Pose-graph Generation for Global SfM
Nov 26, 2020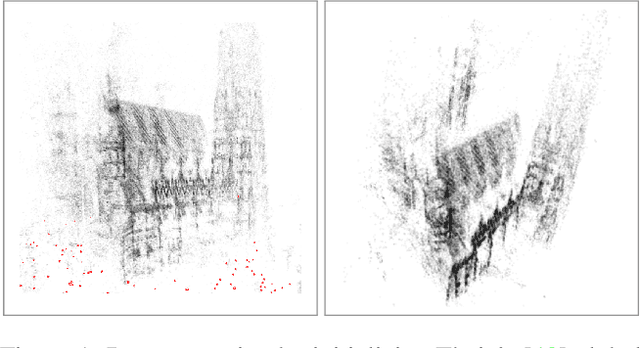
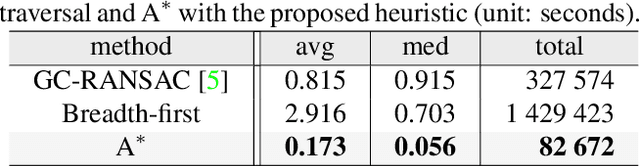
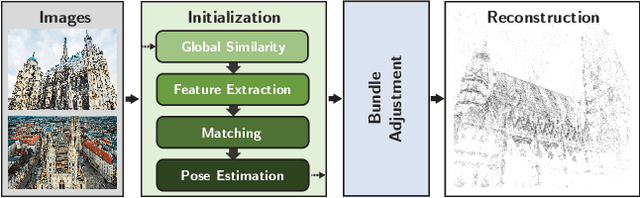
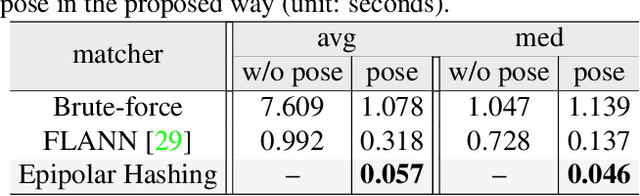
We propose ways to speed up the initial pose-graph generation for global Structure-from-Motion algorithms. To avoid forming tentative point correspondences by FLANN and geometric verification by RANSAC, which are the most time-consuming steps of the pose-graph creation, we propose two new methods - built on the fact that image pairs usually are matched consecutively. Thus, candidate relative poses can be recovered from paths in the partly-built pose-graph. We propose a heuristic for the A* traversal, considering global similarity of images and the quality of the pose-graph edges. Given a relative pose from a path, descriptor-based feature matching is made "light-weight" by exploiting the known epipolar geometry. To speed up PROSAC-based sampling when RANSAC is applied, we propose a third method to order the correspondences by their inlier probabilities from previous estimations. The algorithms are tested on 402130 image pairs from the 1DSfM dataset and they speed up the feature matching 17 times and pose estimation 5 times.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020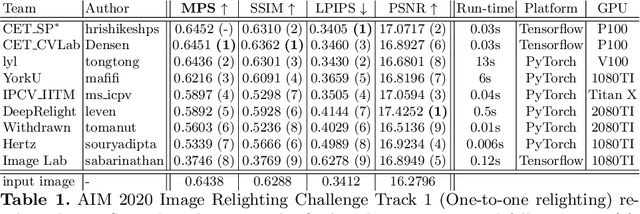

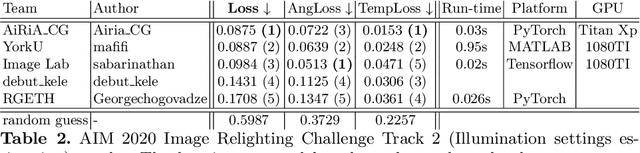

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
Attribute Prototype Network for Zero-Shot Learning
Aug 19, 2020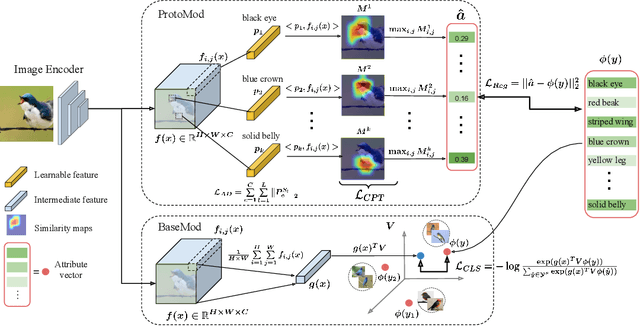
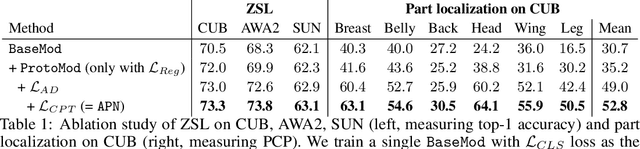
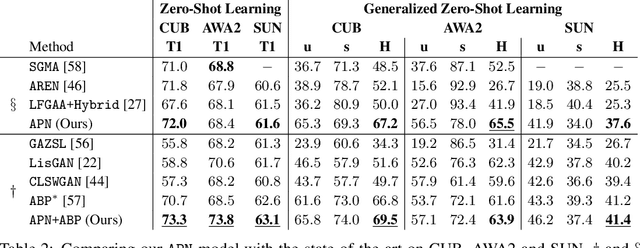
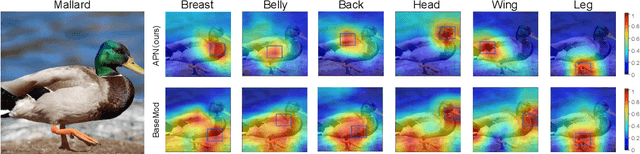
From the beginning of zero-shot learning research, visual attributes have been shown to play an important role. In order to better transfer attribute-based knowledge from known to unknown classes, we argue that an image representation with integrated attribute localization ability would be beneficial for zero-shot learning. To this end, we propose a novel zero-shot representation learning framework that jointly learns discriminative global and local features using only class-level attributes. While a visual-semantic embedding layer learns global features, local features are learned through an attribute prototype network that simultaneously regresses and decorrelates attributes from intermediate features. We show that our locality augmented image representations achieve a new state-of-the-art on three zero-shot learning benchmarks. As an additional benefit, our model points to the visual evidence of the attributes in an image, e.g. for the CUB dataset, confirming the improved attribute localization ability of our image representation. The code will be publicaly available at https://wenjiaxu.github.io/APN-ZSL/.