 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SOLD2: Self-supervised Occlusion-aware Line Description and Detection
Apr 09, 2021
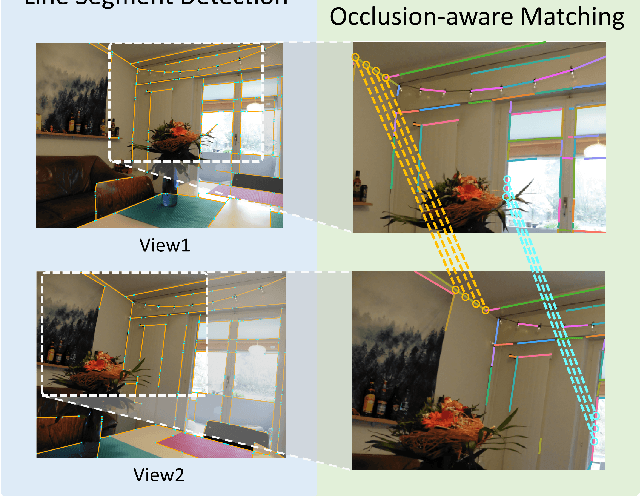
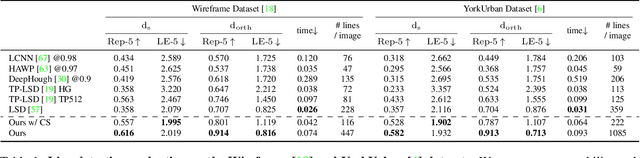
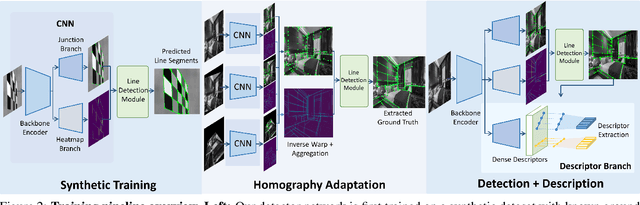
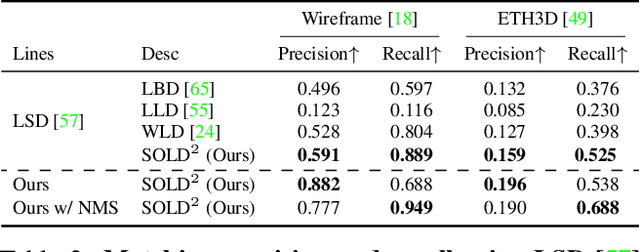
Compared to feature point detection and description, detecting and matching line segments offer additional challenges. Yet, line features represent a promising complement to points for multi-view tasks. Lines are indeed well-defined by the image gradient, frequently appear even in poorly textured areas and offer robust structural cues. We thus hereby introduce the first joint detection and description of line segments in a single deep network. Thanks to a self-supervised training, our method does not require any annotated line labels and can therefore generalize to any dataset. Our detector offers repeatable and accurate localization of line segments in images, departing from the wireframe parsing approach. Leveraging the recent progresses in descriptor learning, our proposed line descriptor is highly discriminative, while remaining robust to viewpoint changes and occlusions. We evaluate our approach against previous line detection and description methods on several multi-view datasets created with homographic warps as well as real-world viewpoint changes. Our full pipeline yields higher repeatability, localization accuracy and matching metrics, and thus represents a first step to bridge the gap with learned feature points methods. Code and trained weights are available at https://github.com/cvg/SOLD2.
GANs for Biological Image Synthesis
Sep 12, 2017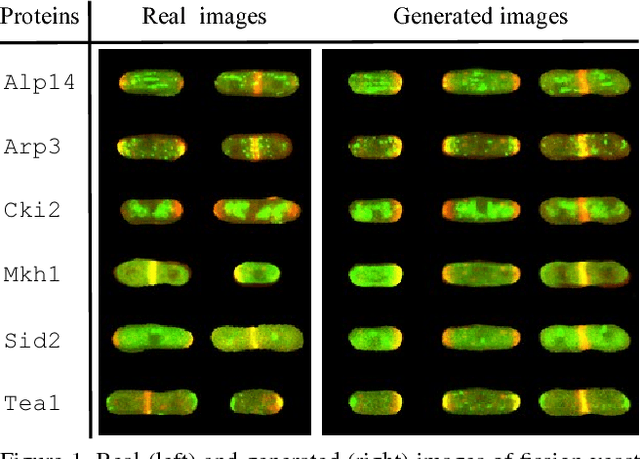
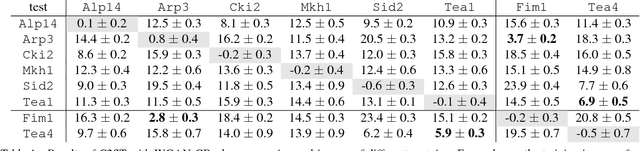
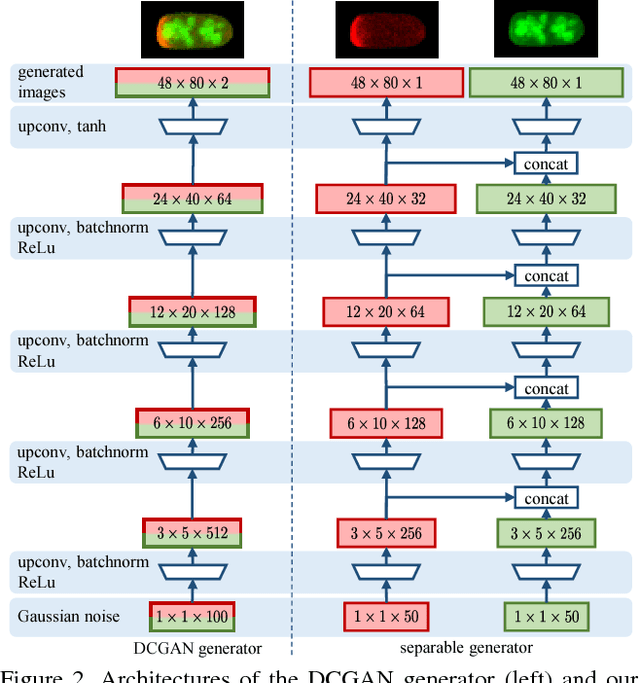
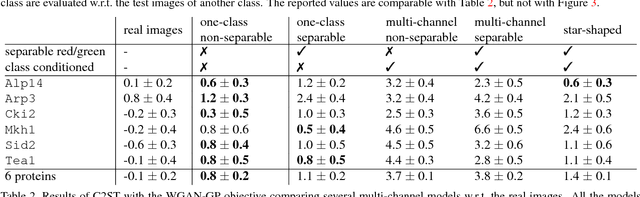
In this paper, we propose a novel application of Generative Adversarial Networks (GAN) to the synthesis of cells imaged by fluorescence microscopy. Compared to natural images, cells tend to have a simpler and more geometric global structure that facilitates image generation. However, the correlation between the spatial pattern of different fluorescent proteins reflects important biological functions, and synthesized images have to capture these relationships to be relevant for biological applications. We adapt GANs to the task at hand and propose new models with casual dependencies between image channels that can generate multi-channel images, which would be impossible to obtain experimentally. We evaluate our approach using two independent techniques and compare it against sensible baselines. Finally, we demonstrate that by interpolating across the latent space we can mimic the known changes in protein localization that occur through time during the cell cycle, allowing us to predict temporal evolution from static images.
Deep Learning Generalization and the Convex Hull of Training Sets
Jan 25, 2021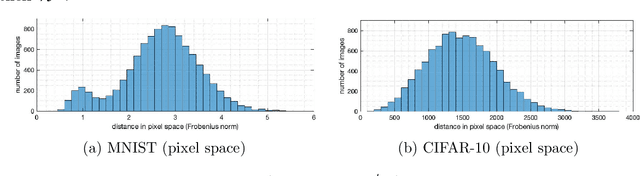


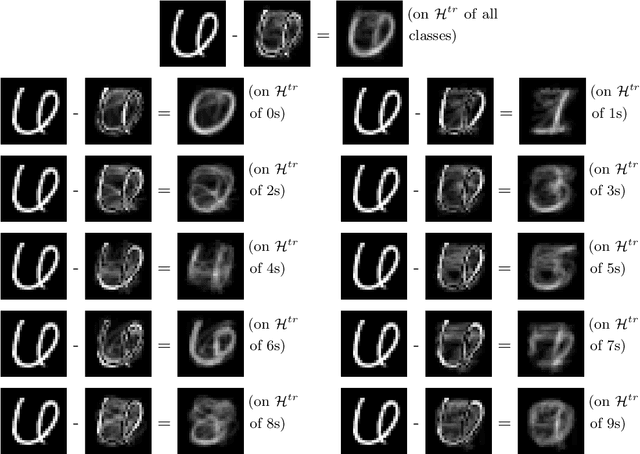
We study the generalization of deep learning models in relation to the convex hull of their training sets. A trained image classifier basically partitions its domain via decision boundaries and assigns a class to each of those partitions. The location of decision boundaries inside the convex hull of training set can be investigated in relation to the training samples. However, our analysis shows that in standard image classification datasets, all testing images are considerably outside that convex hull, in the pixel space, in the wavelet space, and in the internal representations learned by deep networks. Therefore, the performance of a trained model partially depends on how its decision boundaries are extended outside the convex hull of its training data. From this perspective which is not studied before, over-parameterization of deep learning models may be considered a necessity for shaping the extension of decision boundaries. At the same time, over-parameterization should be accompanied by a specific training regime, in order to yield a model that not only fits the training set, but also its decision boundaries extend desirably outside the convex hull. To illustrate this, we investigate the decision boundaries of a neural network, with various degrees of parameters, inside and outside the convex hull of its training set. Moreover, we use a polynomial decision boundary to study the necessity of over-parameterization and the influence of training regime in shaping its extensions outside the convex hull of training set.
not-so-BigGAN: Generating High-Fidelity Images on a Small Compute Budget
Sep 09, 2020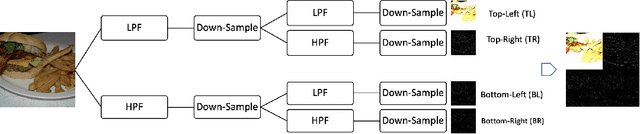
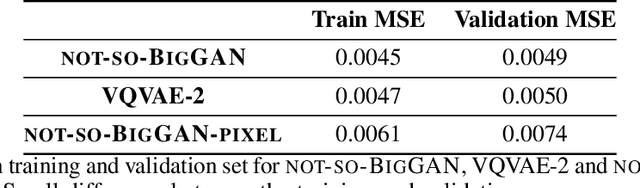
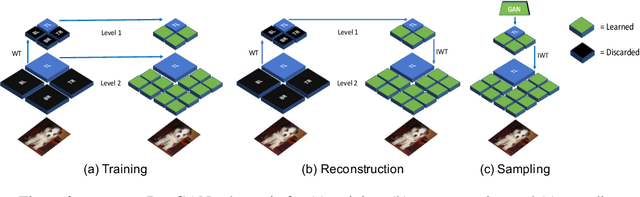
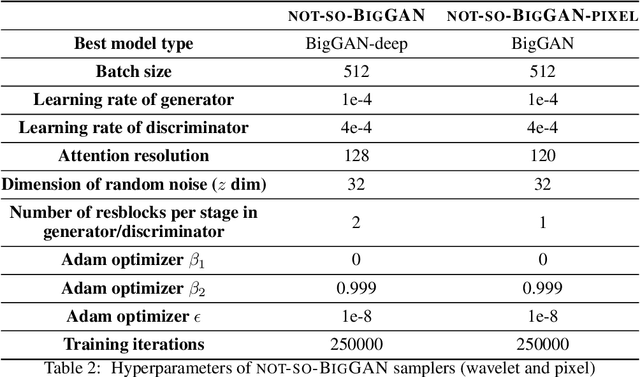
BigGAN is the state-of-the-art in high-resolution image generation, successfully leveraging advancements in scalable computing and theoretical understanding of generative adversarial methods to set new records in conditional image generation. A major part of BigGAN's success is due to its use of large mini-batch sizes during training in high dimensions. While effective, this technique requires an incredible amount of compute resources and/or time (256 TPU-v3 Cores), putting the model out of reach for the larger research community. In this paper, we present not-so-BigGAN, a simple and scalable framework for training deep generative models on high-dimensional natural images. Instead of modelling the image in pixel space like in BigGAN, not-so-BigGAN uses wavelet transformations to bypass the curse of dimensionality, reducing the overall compute requirement significantly. Through extensive empirical evaluation, we demonstrate that for a fixed compute budget, not-so-BigGAN converges several times faster than BigGAN, reaching competitive image quality with an order of magnitude lower compute budget (4 Telsa-V100 GPUs).
Learning Deep Context-Network Architectures for Image Annotation
Mar 23, 2018

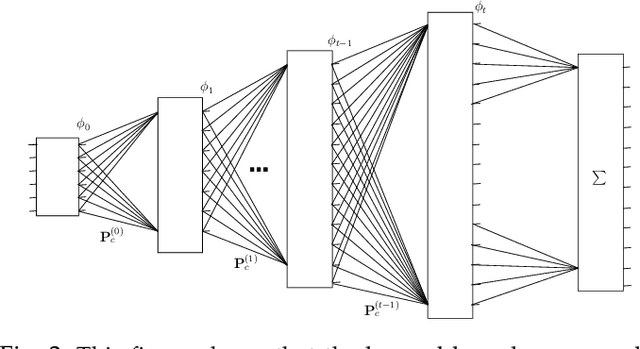

Context plays an important role in visual pattern recognition as it provides complementary clues for different learning tasks including image classification and annotation. In the particular scenario of kernel learning, the general recipe of context-based kernel design consists in learning positive semi-definite similarity functions that return high values not only when data share similar content but also similar context. However, in spite of having a positive impact on performance, the use of context in these kernel design methods has not been fully explored; indeed, context has been handcrafted instead of being learned. In this paper, we introduce a novel context-aware kernel design framework based on deep learning. Our method discriminatively learns spatial geometric context as the weights of a deep network (DN). The architecture of this network is fully determined by the solution of an objective function that mixes content, context and regularization, while the parameters of this network determine the most relevant (discriminant) parts of the learned context. We apply this context and kernel learning framework to image classification using the challenging ImageCLEF Photo Annotation benchmark; the latter shows that our deep context learning provides highly effective kernels for image classification as corroborated through extensive experiments.
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
Jan 11, 2019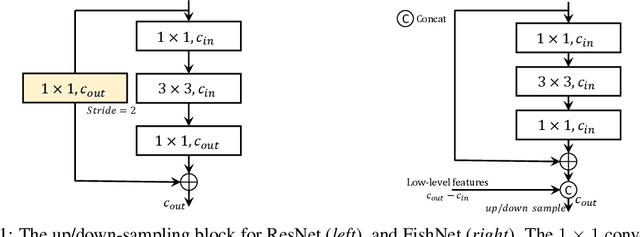
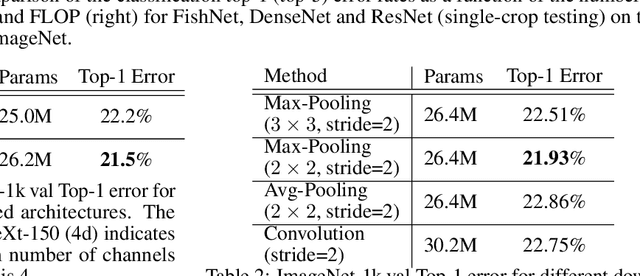
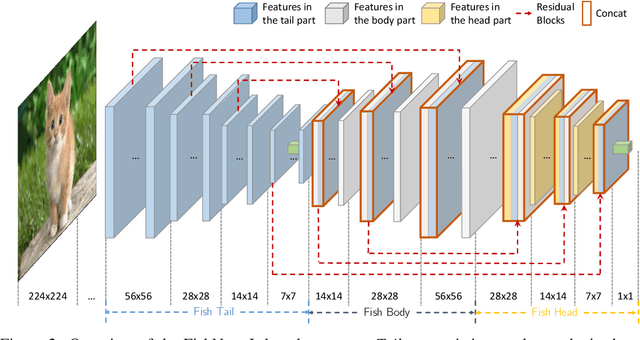
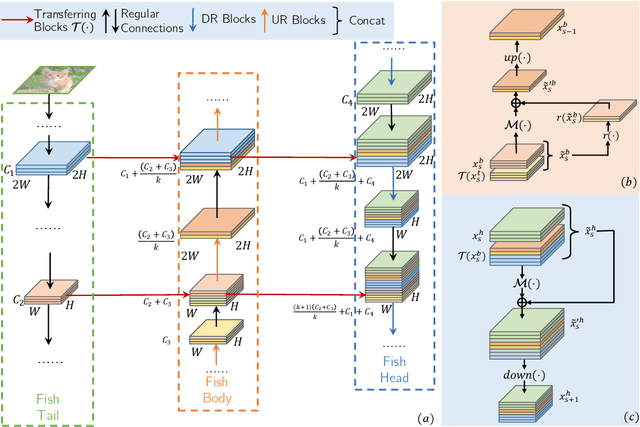
The basic principles in designing convolutional neural network (CNN) structures for predicting objects on different levels, e.g., image-level, region-level, and pixel-level are diverging. Generally, network structures designed specifically for image classification are directly used as default backbone structure for other tasks including detection and segmentation, but there is seldom backbone structure designed under the consideration of unifying the advantages of networks designed for pixel-level or region-level predicting tasks, which may require very deep features with high resolution. Towards this goal, we design a fish-like network, called FishNet. In FishNet, the information of all resolutions is preserved and refined for the final task. Besides, we observe that existing works still cannot \emph{directly} propagate the gradient information from deep layers to shallow layers. Our design can better handle this problem. Extensive experiments have been conducted to demonstrate the remarkable performance of the FishNet. In particular, on ImageNet-1k, the accuracy of FishNet is able to surpass the performance of DenseNet and ResNet with fewer parameters. FishNet was applied as one of the modules in the winning entry of the COCO Detection 2018 challenge. The code is available at https://github.com/kevin-ssy/FishNet.
DeepFacePencil: Creating Face Images from Freehand Sketches
Aug 31, 2020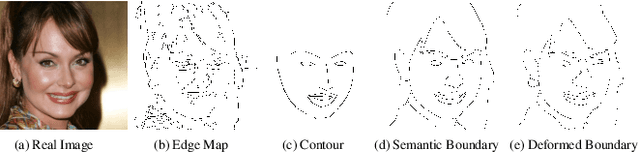

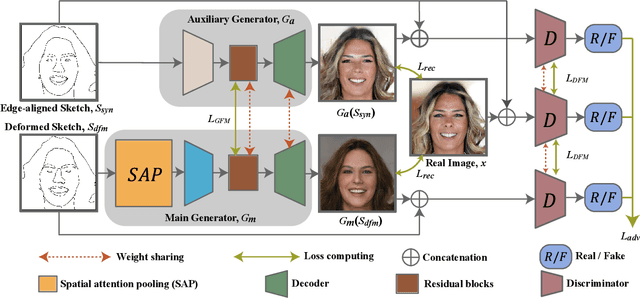
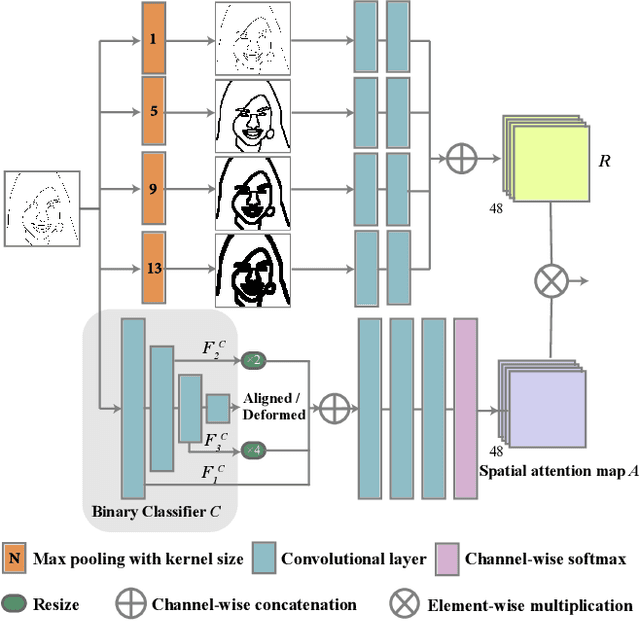
In this paper, we explore the task of generating photo-realistic face images from hand-drawn sketches. Existing image-to-image translation methods require a large-scale dataset of paired sketches and images for supervision. They typically utilize synthesized edge maps of face images as training data. However, these synthesized edge maps strictly align with the edges of the corresponding face images, which limit their generalization ability to real hand-drawn sketches with vast stroke diversity. To address this problem, we propose DeepFacePencil, an effective tool that is able to generate photo-realistic face images from hand-drawn sketches, based on a novel dual generator image translation network during training. A novel spatial attention pooling (SAP) is designed to adaptively handle stroke distortions which are spatially varying to support various stroke styles and different levels of details. We conduct extensive experiments and the results demonstrate the superiority of our model over existing methods on both image quality and model generalization to hand-drawn sketches.
Deep J-Sense: Accelerated MRI Reconstruction via Unrolled Alternating Optimization
Mar 02, 2021
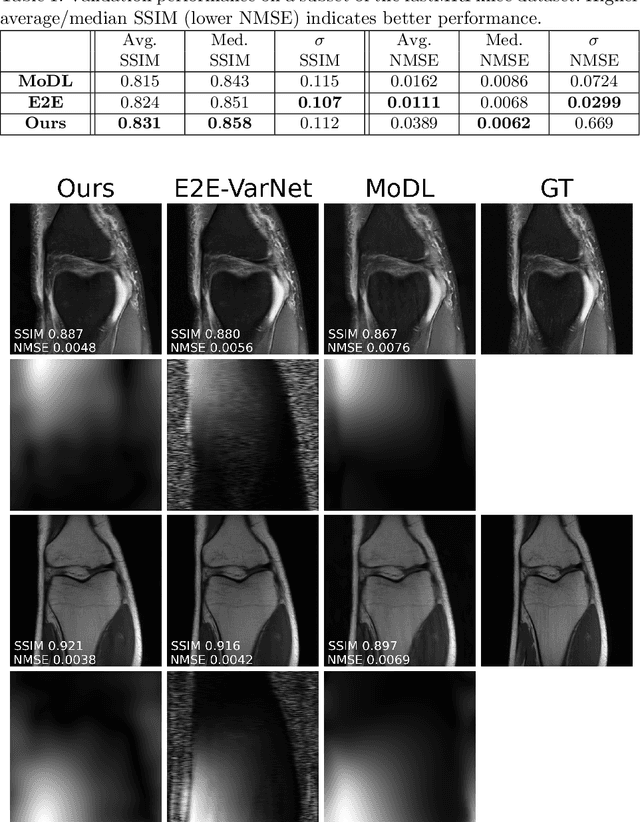
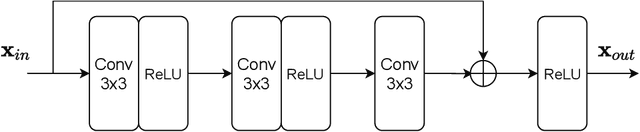
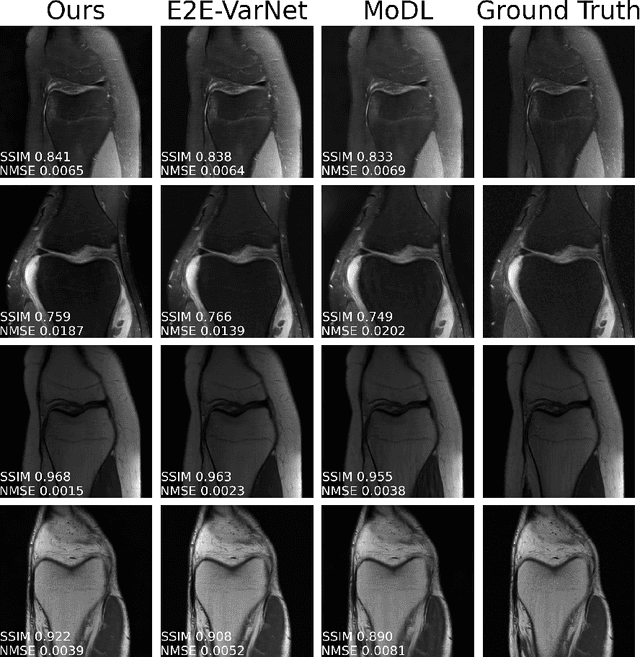
Accelerated multi-coil magnetic resonance imaging reconstruction has seen a substantial recent improvement combining compressed sensing with deep learning. However, most of these methods rely on estimates of the coil sensitivity profiles, or on calibration data for estimating model parameters. Prior work has shown that these methods degrade in performance when the quality of these estimators are poor or when the scan parameters differ from the training conditions. Here we introduce Deep J-Sense as a deep learning approach that builds on unrolled alternating minimization and increases robustness: our algorithm refines both the magnetization (image) kernel and the coil sensitivity maps. Experimental results on a subset of the knee fastMRI dataset show that this increases reconstruction performance and provides a significant degree of robustness to varying acceleration factors and calibration region sizes.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021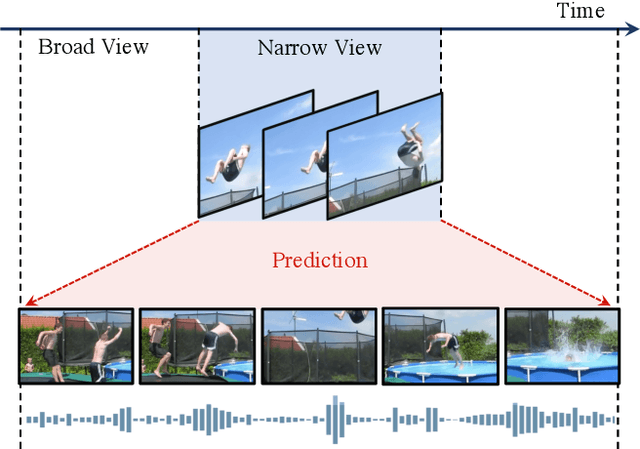
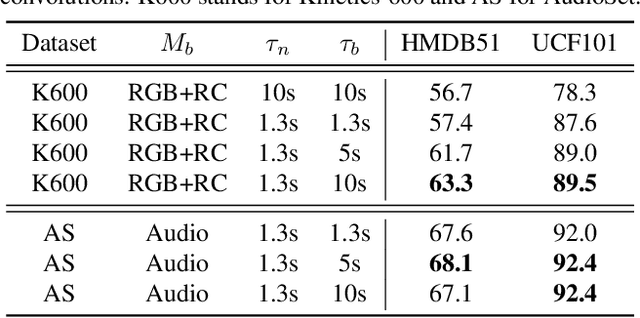
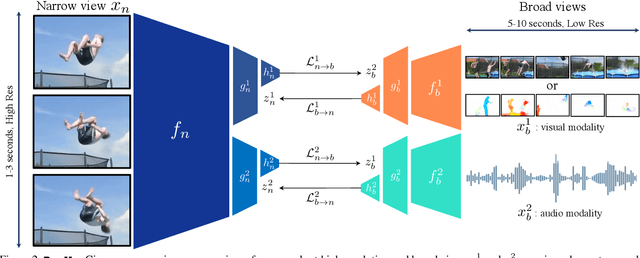
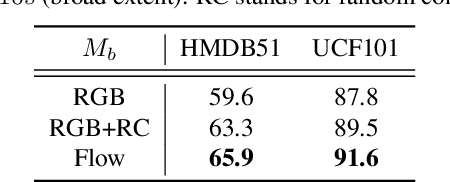
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Geospatial Transformations for Ground-Based Sky Imaging Systems
Mar 02, 2021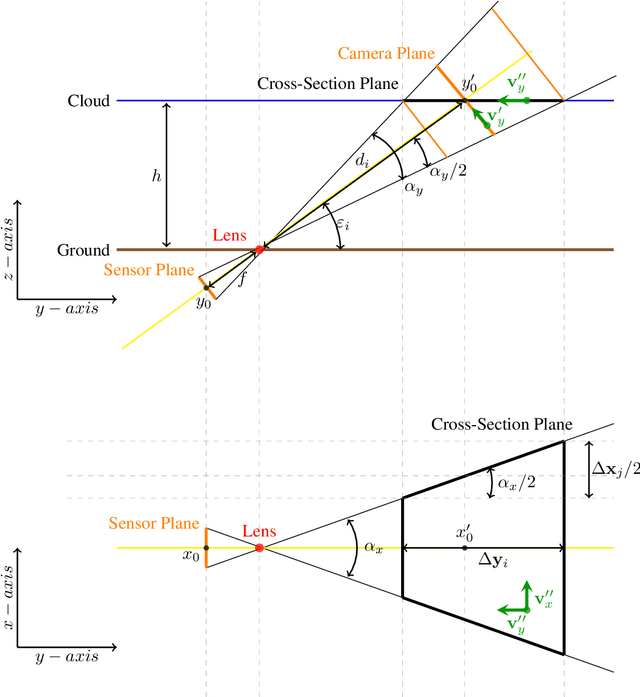
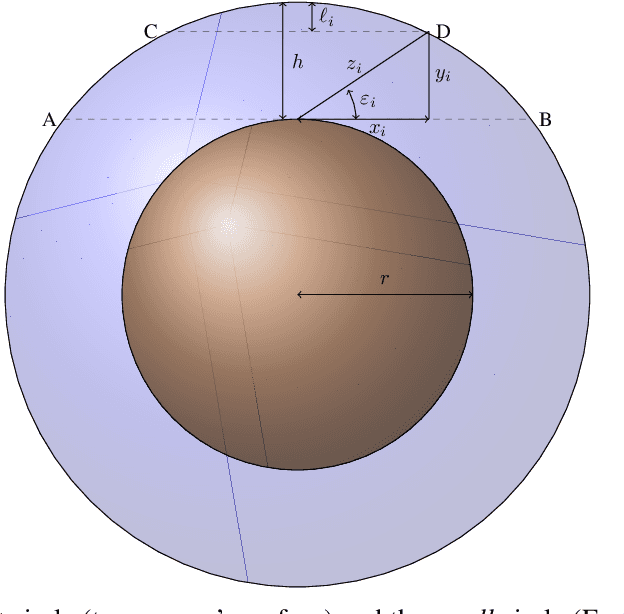
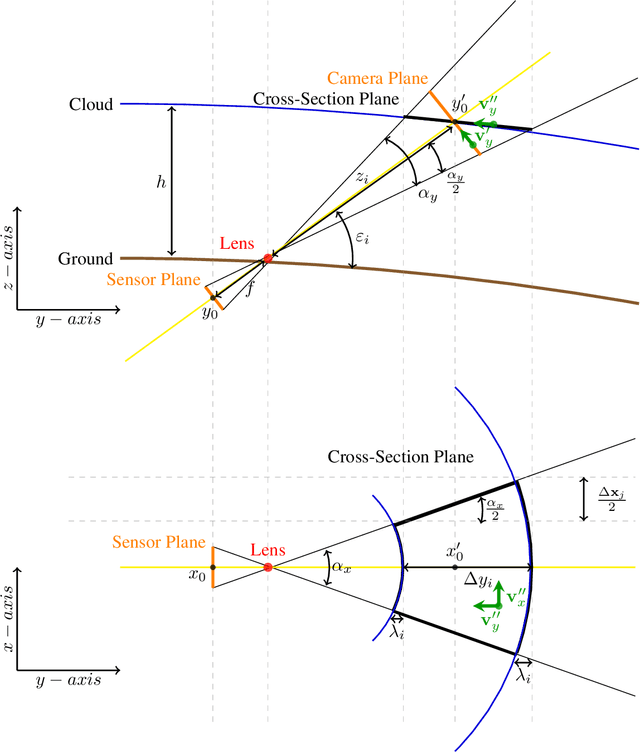

Sky imaging systems use lenses to acquire images concentrating light beams in an imager. The light beams received by the imager have an elevation angle with respect to the normal of the device. This produces that the pixels in an image contain information from different areas of the sky within imaging system Field Of View (FOV). The area of the field of view contained in the pixels increases as the elevation angle of the incident light beams decreases. When the sky imaging system are mounted on a solar tracker the angle of incidence of the light beams varies along time. This investigation introduces a transformation that projects the original euclidean frame of the plane of the imager to the geospatial frame of the sky imaging system field of view.