 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-linguistic differences and similarities in image descriptions
Aug 13, 2017
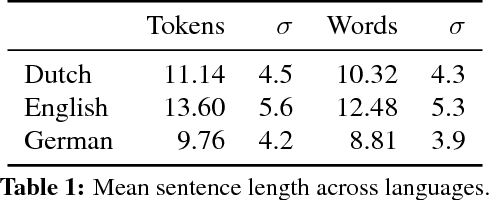
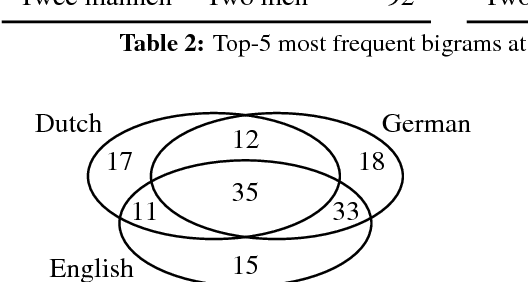


Automatic image description systems are commonly trained and evaluated on large image description datasets. Recently, researchers have started to collect such datasets for languages other than English. An unexplored question is how different these datasets are from English and, if there are any differences, what causes them to differ. This paper provides a cross-linguistic comparison of Dutch, English, and German image descriptions. We find that these descriptions are similar in many respects, but the familiarity of crowd workers with the subjects of the images has a noticeable influence on description specificity.
FrameNet: Learning Local Canonical Frames of 3D Surfaces from a Single RGB Image
Mar 29, 2019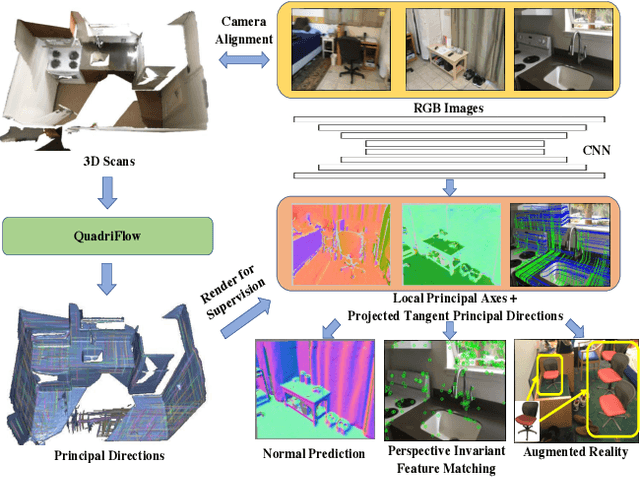
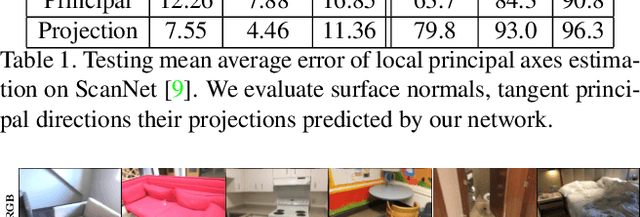

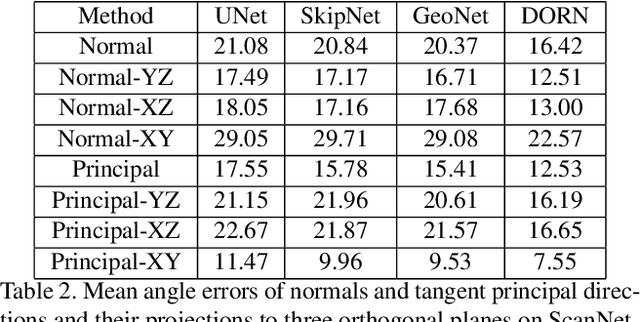
In this work, we introduce the novel problem of identifying dense canonical 3D coordinate frames from a single RGB image. We observe that each pixel in an image corresponds to a surface in the underlying 3D geometry, where a canonical frame can be identified as represented by three orthogonal axes, one along its normal direction and two in its tangent plane. We propose an algorithm to predict these axes from RGB. Our first insight is that canonical frames computed automatically with recently introduced direction field synthesis methods can provide training data for the task. Our second insight is that networks designed for surface normal prediction provide better results when trained jointly to predict canonical frames, and even better when trained to also predict 2D projections of canonical frames. We conjecture this is because projections of canonical tangent directions often align with local gradients in images, and because those directions are tightly linked to 3D canonical frames through projective geometry and orthogonality constraints. In our experiments, we find that our method predicts 3D canonical frames that can be used in applications ranging from surface normal estimation, feature matching, and augmented reality.
GANs for Biological Image Synthesis
Sep 12, 2017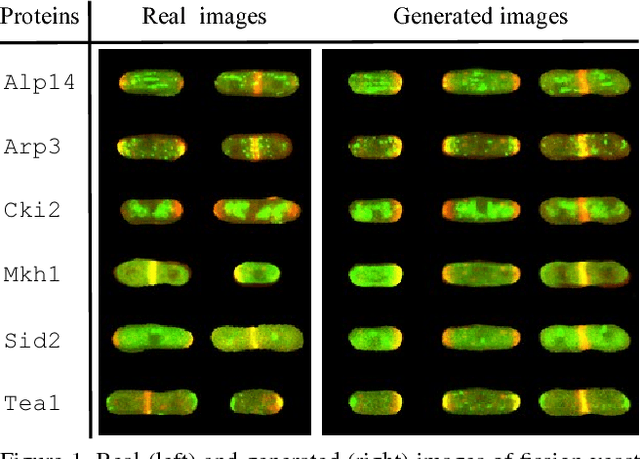
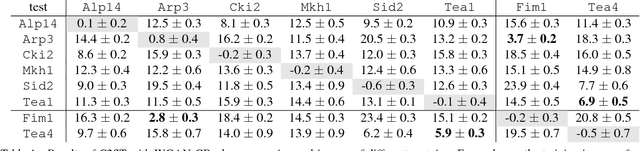
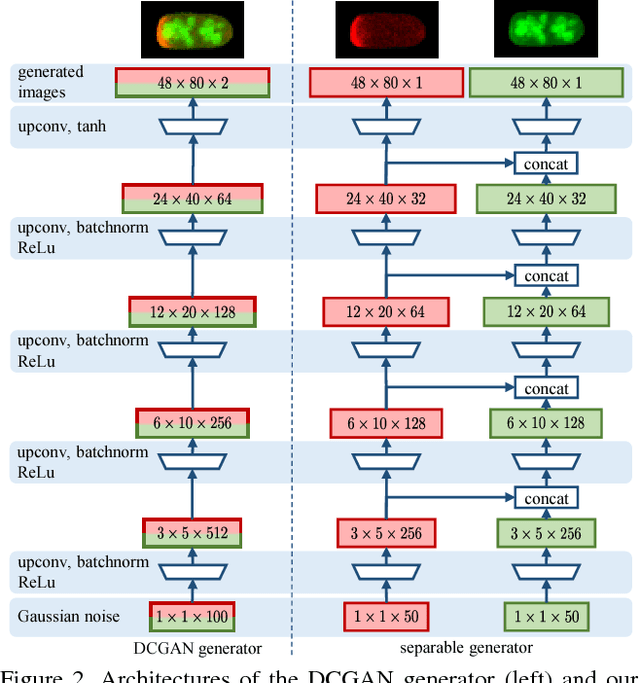
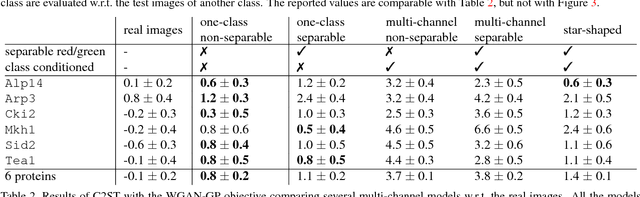
In this paper, we propose a novel application of Generative Adversarial Networks (GAN) to the synthesis of cells imaged by fluorescence microscopy. Compared to natural images, cells tend to have a simpler and more geometric global structure that facilitates image generation. However, the correlation between the spatial pattern of different fluorescent proteins reflects important biological functions, and synthesized images have to capture these relationships to be relevant for biological applications. We adapt GANs to the task at hand and propose new models with casual dependencies between image channels that can generate multi-channel images, which would be impossible to obtain experimentally. We evaluate our approach using two independent techniques and compare it against sensible baselines. Finally, we demonstrate that by interpolating across the latent space we can mimic the known changes in protein localization that occur through time during the cell cycle, allowing us to predict temporal evolution from static images.
3D AffordanceNet: A Benchmark for Visual Object Affordance Understanding
Mar 31, 2021

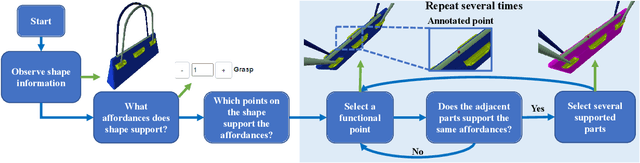
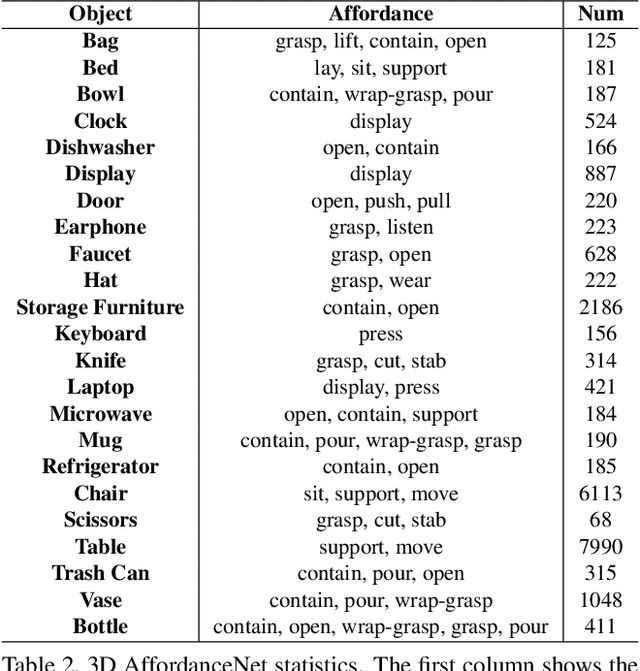
The ability to understand the ways to interact with objects from visual cues, a.k.a. visual affordance, is essential to vision-guided robotic research. This involves categorizing, segmenting and reasoning of visual affordance. Relevant studies in 2D and 2.5D image domains have been made previously, however, a truly functional understanding of object affordance requires learning and prediction in the 3D physical domain, which is still absent in the community. In this work, we present a 3D AffordanceNet dataset, a benchmark of 23k shapes from 23 semantic object categories, annotated with 18 visual affordance categories. Based on this dataset, we provide three benchmarking tasks for evaluating visual affordance understanding, including full-shape, partial-view and rotation-invariant affordance estimations. Three state-of-the-art point cloud deep learning networks are evaluated on all tasks. In addition we also investigate a semi-supervised learning setup to explore the possibility to benefit from unlabeled data. Comprehensive results on our contributed dataset show the promise of visual affordance understanding as a valuable yet challenging benchmark.
Stylized Neural Painting
Nov 16, 2020
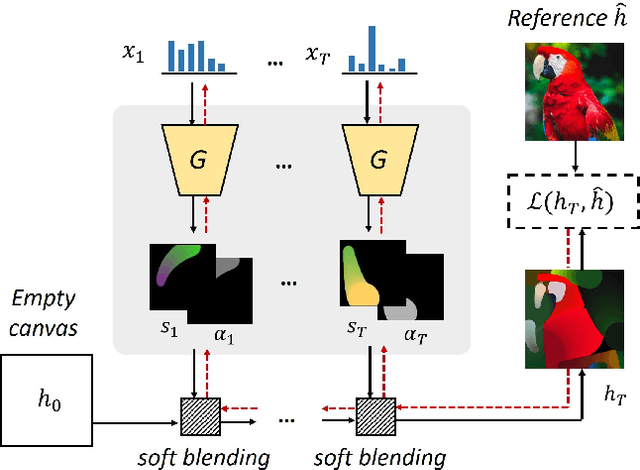
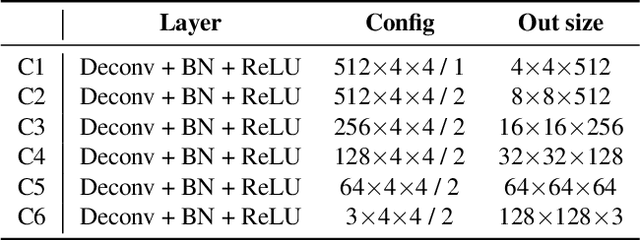
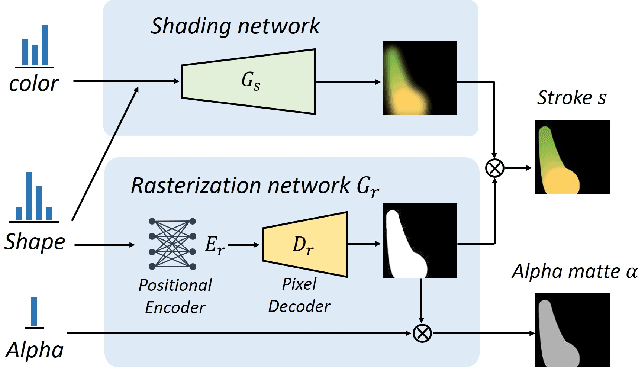
This paper proposes an image-to-painting translation method that generates vivid and realistic painting artworks with controllable styles. Different from previous image-to-image translation methods that formulate the translation as pixel-wise prediction, we deal with such an artistic creation process in a vectorized environment and produce a sequence of physically meaningful stroke parameters that can be further used for rendering. Since a typical vector render is not differentiable, we design a novel neural renderer which imitates the behavior of the vector renderer and then frame the stroke prediction as a parameter searching process that maximizes the similarity between the input and the rendering output. We explored the zero-gradient problem on parameter searching and propose to solve this problem from an optimal transportation perspective. We also show that previous neural renderers have a parameter coupling problem and we re-design the rendering network with a rasterization network and a shading network that better handles the disentanglement of shape and color. Experiments show that the paintings generated by our method have a high degree of fidelity in both global appearance and local textures. Our method can be also jointly optimized with neural style transfer that further transfers visual style from other images. Our code and animated results are available at \url{https://jiupinjia.github.io/neuralpainter/}.
Learning Deep Context-Network Architectures for Image Annotation
Mar 23, 2018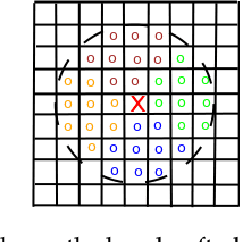

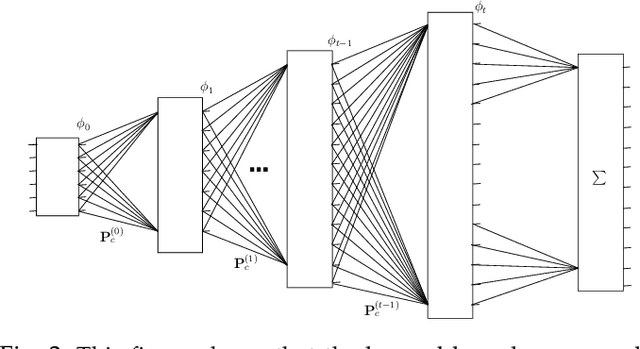

Context plays an important role in visual pattern recognition as it provides complementary clues for different learning tasks including image classification and annotation. In the particular scenario of kernel learning, the general recipe of context-based kernel design consists in learning positive semi-definite similarity functions that return high values not only when data share similar content but also similar context. However, in spite of having a positive impact on performance, the use of context in these kernel design methods has not been fully explored; indeed, context has been handcrafted instead of being learned. In this paper, we introduce a novel context-aware kernel design framework based on deep learning. Our method discriminatively learns spatial geometric context as the weights of a deep network (DN). The architecture of this network is fully determined by the solution of an objective function that mixes content, context and regularization, while the parameters of this network determine the most relevant (discriminant) parts of the learned context. We apply this context and kernel learning framework to image classification using the challenging ImageCLEF Photo Annotation benchmark; the latter shows that our deep context learning provides highly effective kernels for image classification as corroborated through extensive experiments.
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
Jan 11, 2019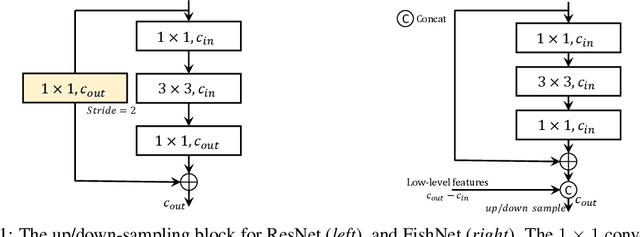
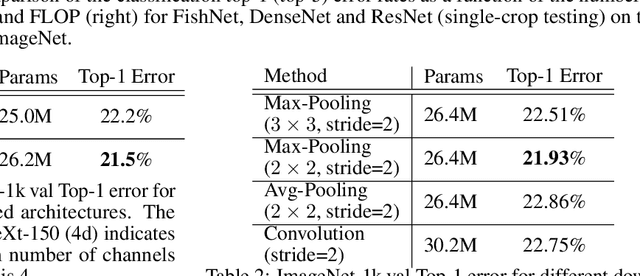
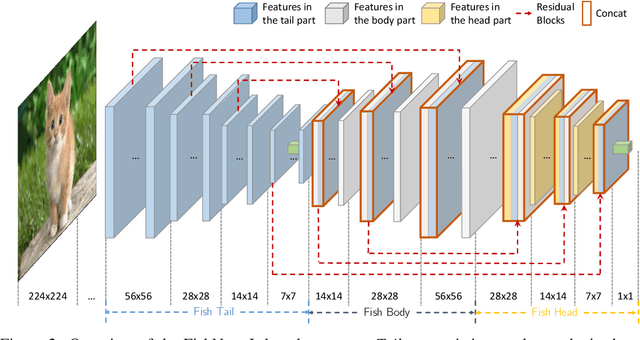
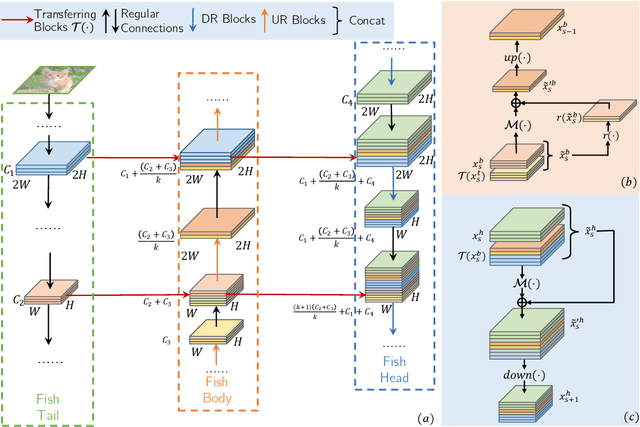
The basic principles in designing convolutional neural network (CNN) structures for predicting objects on different levels, e.g., image-level, region-level, and pixel-level are diverging. Generally, network structures designed specifically for image classification are directly used as default backbone structure for other tasks including detection and segmentation, but there is seldom backbone structure designed under the consideration of unifying the advantages of networks designed for pixel-level or region-level predicting tasks, which may require very deep features with high resolution. Towards this goal, we design a fish-like network, called FishNet. In FishNet, the information of all resolutions is preserved and refined for the final task. Besides, we observe that existing works still cannot \emph{directly} propagate the gradient information from deep layers to shallow layers. Our design can better handle this problem. Extensive experiments have been conducted to demonstrate the remarkable performance of the FishNet. In particular, on ImageNet-1k, the accuracy of FishNet is able to surpass the performance of DenseNet and ResNet with fewer parameters. FishNet was applied as one of the modules in the winning entry of the COCO Detection 2018 challenge. The code is available at https://github.com/kevin-ssy/FishNet.
Surrogate Supervision for Medical Image Analysis: Effective Deep Learning From Limited Quantities of Labeled Data
Jan 25, 2019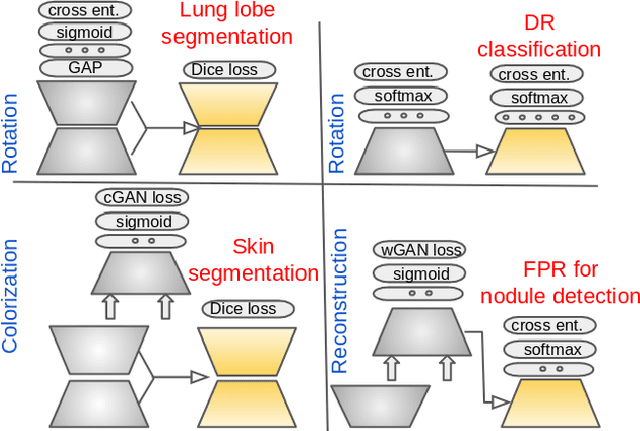

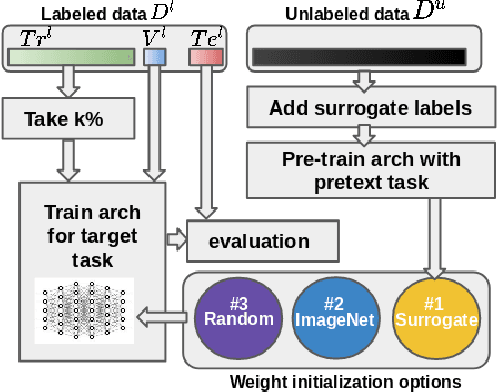
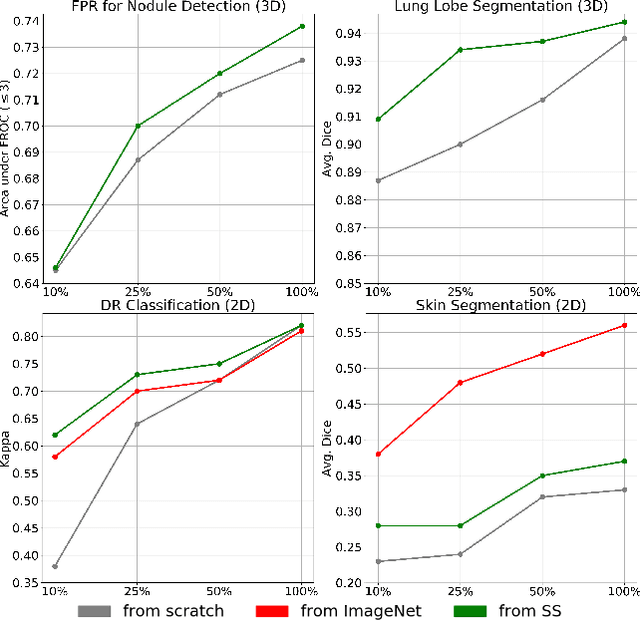
We investigate the effectiveness of a simple solution to the common problem of deep learning in medical image analysis with limited quantities of labeled training data. The underlying idea is to assign artificial labels to abundantly available unlabeled medical images and, through a process known as surrogate supervision, pre-train a deep neural network model for the target medical image analysis task lacking sufficient labeled training data. In particular, we employ 3 surrogate supervision schemes, namely rotation, reconstruction, and colorization, in 4 different medical imaging applications representing classification and segmentation for both 2D and 3D medical images. 3 key findings emerge from our research: 1) pre-training with surrogate supervision is effective for small training sets; 2) deep models trained from initial weights pre-trained through surrogate supervision outperform the same models when trained from scratch, suggesting that pre-training with surrogate supervision should be considered prior to training any deep 3D models; 3) pre-training models in the medical domain with surrogate supervision is more effective than transfer learning from an unrelated domain (e.g., natural images), indicating the practical value of abundant unlabeled medical image data.
Dual Adversarial Network: Toward Real-world Noise Removal and Noise Generation
Jul 12, 2020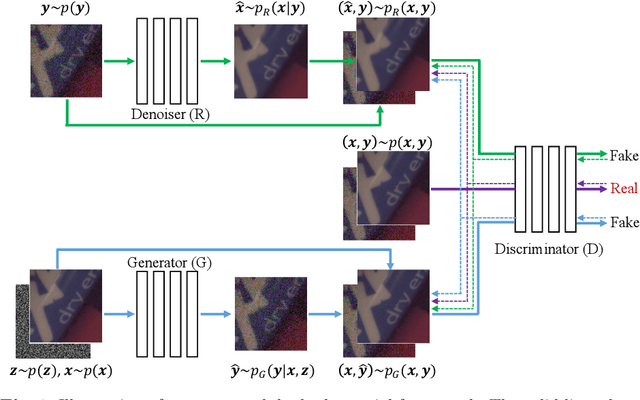
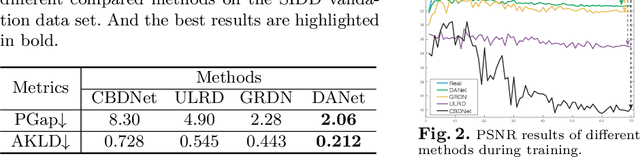
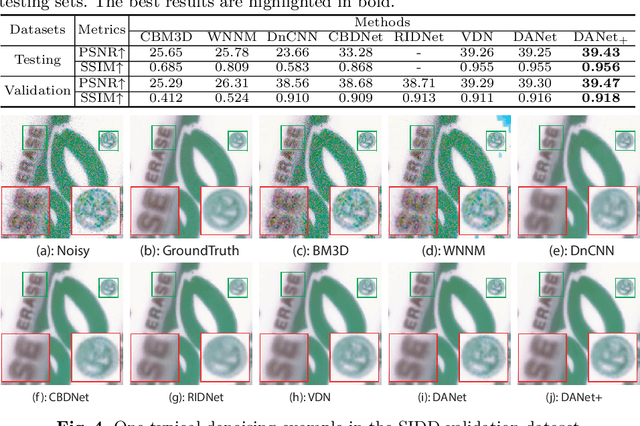

Real-world image noise removal is a long-standing yet very challenging task in computer vision. The success of deep neural network in denoising stimulates the research of noise generation, aiming at synthesizing more clean-noisy image pairs to facilitate the training of deep denoisers. In this work, we propose a novel unified framework to simultaneously deal with the noise removal and noise generation tasks. Instead of only inferring the posteriori distribution of the latent clean image conditioned on the observed noisy image in traditional MAP framework, our proposed method learns the joint distribution of the clean-noisy image pairs. Specifically, we approximate the joint distribution with two different factorized forms, which can be formulated as a denoiser mapping the noisy image to the clean one and a generator mapping the clean image to the noisy one. The learned joint distribution implicitly contains all the information between the noisy and clean images, avoiding the necessity of manually designing the image priors and noise assumptions as traditional. Besides, the performance of our denoiser can be further improved by augmenting the original training dataset with the learned generator. Moreover, we propose two metrics to assess the quality of the generated noisy image, for which, to the best of our knowledge, such metrics are firstly proposed along this research line. Extensive experiments have been conducted to demonstrate the superiority of our method over the state-of-the-arts both in the real noise removal and generation tasks. The training and testing code is available at https://github.com/zsyOAOA/DANet.
Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data
Nov 01, 2018Image translation is a computer vision task that involves translating one representation of the scene into another. Various approaches have been proposed and achieved highly desirable results. Nevertheless, its accomplishment requires abundant paired training data which are expensive to acquire. Therefore, models for translation are usually trained on a set of paired training data which are carefully and laboriously designed. Our work is focused on learning through automatically generated paired data. We propose a method to generate fake sketches from images using an adversarial network and then pair the images with corresponding fake sketches to form large-scale multi-class paired training data for training a sketch-to-image translation model. Our model is an encoder-decoder architecture where the encoder generates fake sketches from images and the decoder performs sketch-to-image translation. Qualitative results show that the encoder can be used for generating large-scale multi-class paired data under low supervision. Our current dataset now contains 61255 image and (fake) sketch pairs from 256 different categories. These figures can be greatly increased in the future thanks to our weak reliance on manually labeled data.