 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Model-Driven Synthetic Training Image Generation: An Approach to Cognition in Rail Defect Detection
Dec 31, 2023
Recent advancements in cognitive computing, with the integration of deep learning techniques, have facilitated the development of intelligent cognitive systems (ICS). This is particularly beneficial in the context of rail defect detection, where the ICS would emulate human-like analysis of image data for defect patterns. Despite the success of Convolutional Neural Networks (CNN) in visual defect classification, the scarcity of large datasets for rail defect detection remains a challenge due to infrequent accident events that would result in defective parts and images. Contemporary researchers have addressed this data scarcity challenge by exploring rule-based and generative data augmentation models. Among these, Variational Autoencoder (VAE) models can generate realistic data without extensive baseline datasets for noise modeling. This study proposes a VAE-based synthetic image generation technique for rail defects, incorporating weight decay regularization and image reconstruction loss to prevent overfitting. The proposed method is applied to create a synthetic dataset for the Canadian Pacific Railway (CPR) with just 50 real samples across five classes. Remarkably, 500 synthetic samples are generated with a minimal reconstruction loss of 0.021. A Visual Transformer (ViT) model underwent fine-tuning using this synthetic CPR dataset, achieving high accuracy rates (98%-99%) in classifying the five defect classes. This research offers a promising solution to the data scarcity challenge in rail defect detection, showcasing the potential for robust ICS development in this domain.
Segment Anything Model Meets Image Harmonization
Dec 20, 2023Image harmonization is a crucial technique in image composition that aims to seamlessly match the background by adjusting the foreground of composite images. Current methods adopt either global-level or pixel-level feature matching. Global-level feature matching ignores the proximity prior, treating foreground and background as separate entities. On the other hand, pixel-level feature matching loses contextual information. Therefore, it is necessary to use the information from semantic maps that describe different objects to guide harmonization. In this paper, we propose Semantic-guided Region-aware Instance Normalization (SRIN) that can utilize the semantic segmentation maps output by a pre-trained Segment Anything Model (SAM) to guide the visual consistency learning of foreground and background features. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods.
Segment Any Cell: A SAM-based Auto-prompting Fine-tuning Framework for Nuclei Segmentation
Jan 24, 2024In the rapidly evolving field of AI research, foundational models like BERT and GPT have significantly advanced language and vision tasks. The advent of pretrain-prompting models such as ChatGPT and Segmentation Anything Model (SAM) has further revolutionized image segmentation. However, their applications in specialized areas, particularly in nuclei segmentation within medical imaging, reveal a key challenge: the generation of high-quality, informative prompts is as crucial as applying state-of-the-art (SOTA) fine-tuning techniques on foundation models. To address this, we introduce Segment Any Cell (SAC), an innovative framework that enhances SAM specifically for nuclei segmentation. SAC integrates a Low-Rank Adaptation (LoRA) within the attention layer of the Transformer to improve the fine-tuning process, outperforming existing SOTA methods. It also introduces an innovative auto-prompt generator that produces effective prompts to guide segmentation, a critical factor in handling the complexities of nuclei segmentation in biomedical imaging. Our extensive experiments demonstrate the superiority of SAC in nuclei segmentation tasks, proving its effectiveness as a tool for pathologists and researchers. Our contributions include a novel prompt generation strategy, automated adaptability for diverse segmentation tasks, the innovative application of Low-Rank Attention Adaptation in SAM, and a versatile framework for semantic segmentation challenges.
Machine Learning for Shipwreck Segmentation from Side Scan Sonar Imagery: Dataset and Benchmark
Jan 25, 2024Open-source benchmark datasets have been a critical component for advancing machine learning for robot perception in terrestrial applications. Benchmark datasets enable the widespread development of state-of-the-art machine learning methods, which require large datasets for training, validation, and thorough comparison to competing approaches. Underwater environments impose several operational challenges that hinder efforts to collect large benchmark datasets for marine robot perception. Furthermore, a low abundance of targets of interest relative to the size of the search space leads to increased time and cost required to collect useful datasets for a specific task. As a result, there is limited availability of labeled benchmark datasets for underwater applications. We present the AI4Shipwrecks dataset, which consists of 24 distinct shipwreck sites totaling 286 high-resolution labeled side scan sonar images to advance the state-of-the-art in autonomous sonar image understanding. We leverage the unique abundance of targets in Thunder Bay National Marine Sanctuary in Lake Huron, MI, to collect and compile a sonar imagery benchmark dataset through surveys with an autonomous underwater vehicle (AUV). We consulted with expert marine archaeologists for the labeling of robotically gathered data. We then leverage this dataset to perform benchmark experiments for comparison of state-of-the-art supervised segmentation methods, and we present insights on opportunities and open challenges for the field. The dataset and benchmarking tools will be released as an open-source benchmark dataset to spur innovation in machine learning for Great Lakes and ocean exploration. The dataset and accompanying software are available at https://umfieldrobotics.github.io/ai4shipwrecks/.
Diffusion-based Data Augmentation for Object Counting Problems
Jan 25, 2024Crowd counting is an important problem in computer vision due to its wide range of applications in image understanding. Currently, this problem is typically addressed using deep learning approaches, such as Convolutional Neural Networks (CNNs) and Transformers. However, deep networks are data-driven and are prone to overfitting, especially when the available labeled crowd dataset is limited. To overcome this limitation, we have designed a pipeline that utilizes a diffusion model to generate extensive training data. We are the first to generate images conditioned on a location dot map (a binary dot map that specifies the location of human heads) with a diffusion model. We are also the first to use these diverse synthetic data to augment the crowd counting models. Our proposed smoothed density map input for ControlNet significantly improves ControlNet's performance in generating crowds in the correct locations. Also, Our proposed counting loss for the diffusion model effectively minimizes the discrepancies between the location dot map and the crowd images generated. Additionally, our innovative guidance sampling further directs the diffusion process toward regions where the generated crowd images align most accurately with the location dot map. Collectively, we have enhanced ControlNet's ability to generate specified objects from a location dot map, which can be used for data augmentation in various counting problems. Moreover, our framework is versatile and can be easily adapted to all kinds of counting problems. Extensive experiments demonstrate that our framework improves the counting performance on the ShanghaiTech, NWPU-Crowd, UCF-QNRF, and TRANCOS datasets, showcasing its effectiveness.
Cross-Level Multi-Instance Distillation for Self-Supervised Fine-Grained Visual Categorization
Jan 16, 2024High-quality annotation of fine-grained visual categories demands great expert knowledge, which is taxing and time consuming. Alternatively, learning fine-grained visual representation from enormous unlabeled images (e.g., species, brands) by self-supervised learning becomes a feasible solution. However, recent researches find that existing self-supervised learning methods are less qualified to represent fine-grained categories. The bottleneck lies in that the pre-text representation is built from every patch-wise embedding, while fine-grained categories are only determined by several key patches of an image. In this paper, we propose a Cross-level Multi-instance Distillation (CMD) framework to tackle the challenge. Our key idea is to consider the importance of each image patch in determining the fine-grained pre-text representation by multiple instance learning. To comprehensively learn the relation between informative patches and fine-grained semantics, the multi-instance knowledge distillation is implemented on both the region/image crop pairs from the teacher and student net, and the region-image crops inside the teacher / student net, which we term as intra-level multi-instance distillation and inter-level multi-instance distillation. Extensive experiments on CUB-200-2011, Stanford Cars and FGVC Aircraft show that the proposed method outperforms the contemporary method by upto 10.14% and existing state-of-the-art self-supervised learning approaches by upto 19.78% on both top-1 accuracy and Rank-1 retrieval metric.
Dual Structure-Preserving Image Filterings for Semi-supervised Medical Image Segmentation
Dec 12, 2023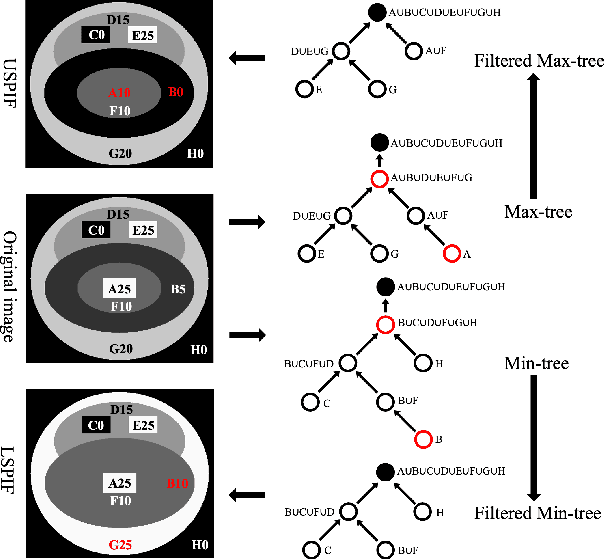
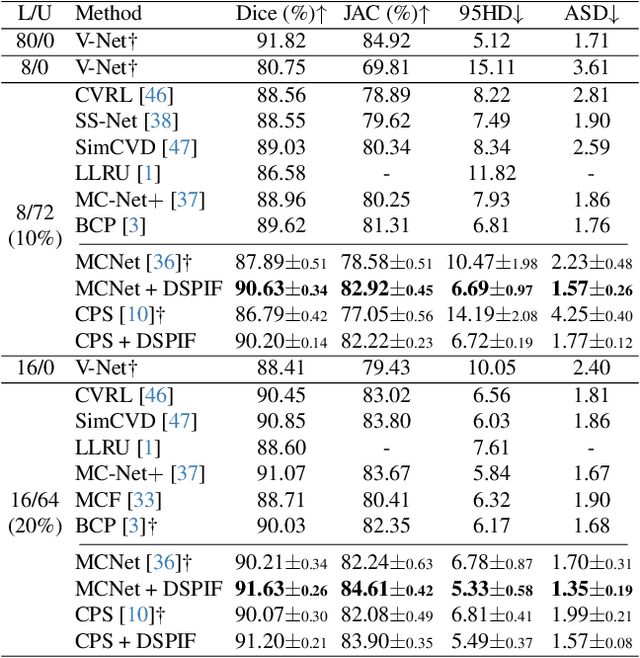
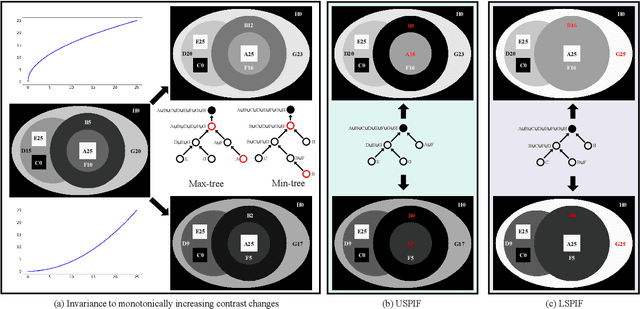
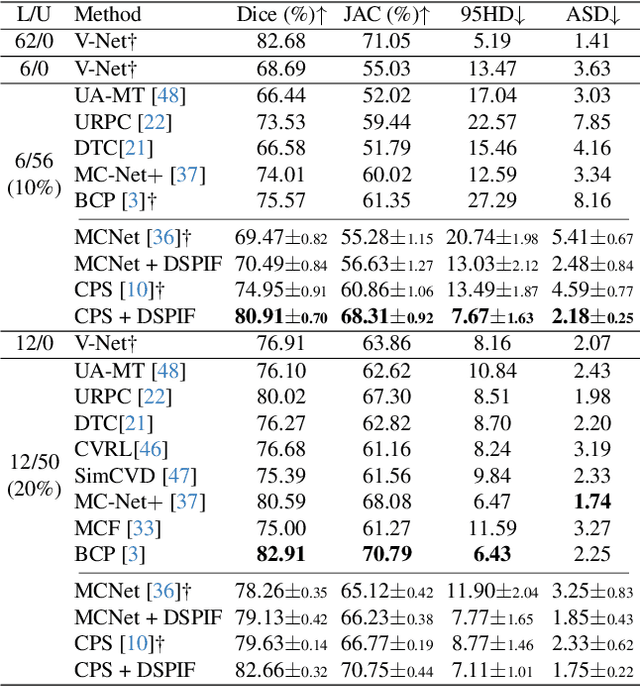
Semi-supervised image segmentation has attracted great attention recently. The key is how to leverage unlabeled images in the training process. Most methods maintain consistent predictions of the unlabeled images under variations (e.g., adding noise/perturbations, or creating alternative versions) in the image and/or model level. In most image-level variation, medical images often have prior structure information, which has not been well explored. In this paper, we propose novel dual structure-preserving image filterings (DSPIF) as the image-level variations for semi-supervised medical image segmentation. Motivated by connected filtering that simplifies image via filtering in structure-aware tree-based image representation, we resort to the dual contrast invariant Max-tree and Min-tree representation. Specifically, we propose a novel connected filtering that removes topologically equivalent nodes (i.e. connected components) having no siblings in the Max/Min-tree. This results in two filtered images preserving topologically critical structure. Applying such dual structure-preserving image filterings in mutual supervision is beneficial for semi-supervised medical image segmentation. Extensive experimental results on three benchmark datasets demonstrate that the proposed method significantly/consistently outperforms some state-of-the-art methods. The source codes will be publicly available.
MultiFusionNet: Multilayer Multimodal Fusion of Deep Neural Networks for Chest X-Ray Image Classification
Jan 01, 2024Chest X-ray imaging is a critical diagnostic tool for identifying pulmonary diseases. However, manual interpretation of these images is time-consuming and error-prone. Automated systems utilizing convolutional neural networks (CNNs) have shown promise in improving the accuracy and efficiency of chest X-ray image classification. While previous work has mainly focused on using feature maps from the final convolution layer, there is a need to explore the benefits of leveraging additional layers for improved disease classification. Extracting robust features from limited medical image datasets remains a critical challenge. In this paper, we propose a novel deep learning-based multilayer multimodal fusion model that emphasizes extracting features from different layers and fusing them. Our disease detection model considers the discriminatory information captured by each layer. Furthermore, we propose the fusion of different-sized feature maps (FDSFM) module to effectively merge feature maps from diverse layers. The proposed model achieves a significantly higher accuracy of 97.21% and 99.60% for both three-class and two-class classifications, respectively. The proposed multilayer multimodal fusion model, along with the FDSFM module, holds promise for accurate disease classification and can also be extended to other disease classifications in chest X-ray images.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Jan 15, 2024The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
Statistical Test for Attention Map in Vision Transformer
Jan 16, 2024The Vision Transformer (ViT) demonstrates exceptional performance in various computer vision tasks. Attention is crucial for ViT to capture complex wide-ranging relationships among image patches, allowing the model to weigh the importance of image patches and aiding our understanding of the decision-making process. However, when utilizing the attention of ViT as evidence in high-stakes decision-making tasks such as medical diagnostics, a challenge arises due to the potential of attention mechanisms erroneously focusing on irrelevant regions. In this study, we propose a statistical test for ViT's attentions, enabling us to use the attentions as reliable quantitative evidence indicators for ViT's decision-making with a rigorously controlled error rate. Using the framework called selective inference, we quantify the statistical significance of attentions in the form of p-values, which enables the theoretically grounded quantification of the false positive detection probability of attentions. We demonstrate the validity and the effectiveness of the proposed method through numerical experiments and applications to brain image diagnoses.