 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Shadowy Lives of Emojis: An Analysis of a Hacktivist Collective's Use of Emojis on Twitter
May 07, 2021

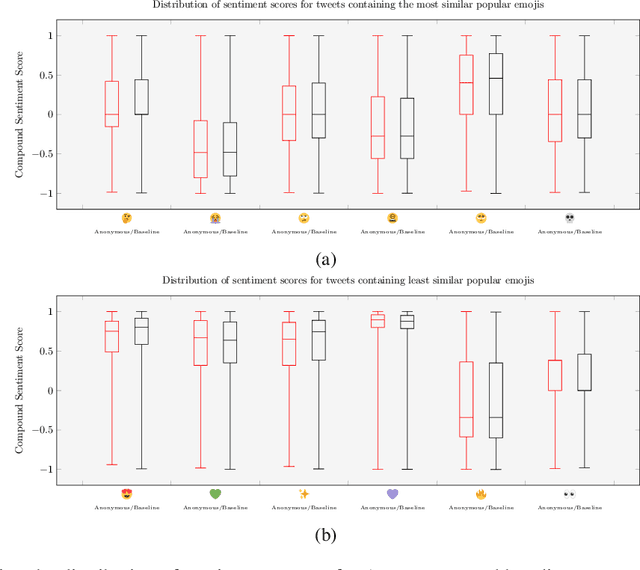
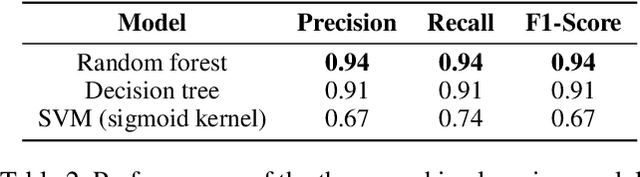

Emojis have established themselves as a popular means of communication in online messaging. Despite the apparent ubiquity in these image-based tokens, however, interpretation and ambiguity may allow for unique uses of emojis to appear. In this paper, we present the first examination of emoji usage by hacktivist groups via a study of the Anonymous collective on Twitter. This research aims to identify whether Anonymous affiliates have evolved their own approach to using emojis. To do this, we compare a large dataset of Anonymous tweets to a baseline tweet dataset from randomly sampled Twitter users using computational and qualitative analysis to compare their emoji usage. We utilise Word2Vec language models to examine the semantic relationships between emojis, identifying clear distinctions in the emoji-emoji relationships of Anonymous users. We then explore how emojis are used as a means of conveying emotions, finding that despite little commonality in emoji-emoji semantic ties, Anonymous emoji usage displays similar patterns of emotional purpose to the emojis of baseline Twitter users. Finally, we explore the textual context in which these emojis occur, finding that although similarities exist between the emoji usage of our Anonymous and baseline Twitter datasets, Anonymous users appear to have adopted more specific interpretations of certain emojis. This includes the use of emojis as a means of expressing adoration and infatuation towards notable Anonymous affiliates. These findings indicate that emojis appear to retain a considerable degree of similarity within Anonymous accounts as compared to more typical Twitter users. However, their are signs that emoji usage in Anonymous accounts has evolved somewhat, gaining additional group-specific associations that reveal new insights into the behaviours of this unusual collective.
BIRNet: Brain Image Registration Using Dual-Supervised Fully Convolutional Networks
Feb 13, 2018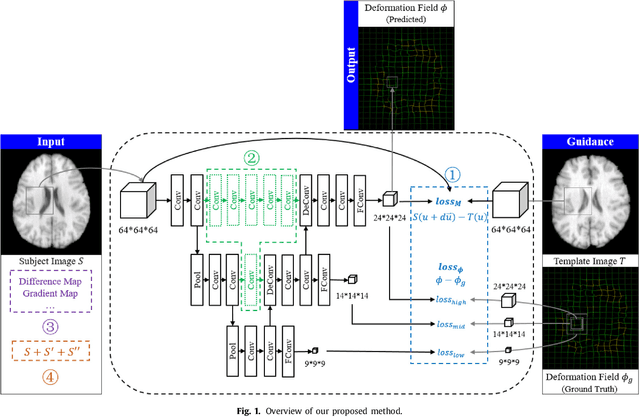

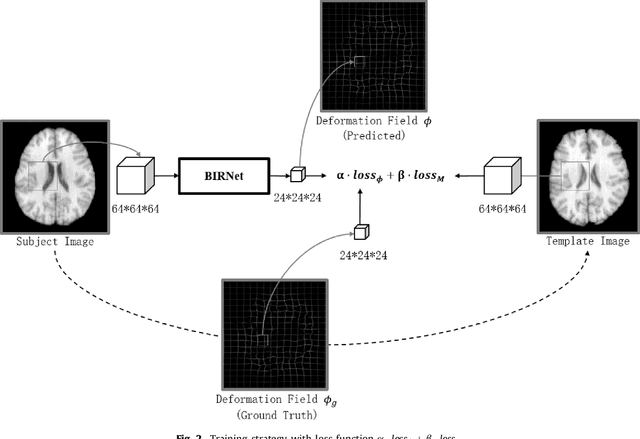
In this paper, we propose a deep learning approach for image registration by predicting deformation from image appearance. Since obtaining ground-truth deformation fields for training can be challenging, we design a fully convolutional network that is subject to dual-guidance: (1) Coarse guidance using deformation fields obtained by an existing registration method; and (2) Fine guidance using image similarity. The latter guidance helps avoid overly relying on the supervision from the training deformation fields, which could be inaccurate. For effective training, we further improve the deep convolutional network with gap filling, hierarchical loss, and multi-source strategies. Experiments on a variety of datasets show promising registration accuracy and efficiency compared with state-of-the-art methods.
ISTA-Net++: Flexible Deep Unfolding Network for Compressive Sensing
Mar 22, 2021
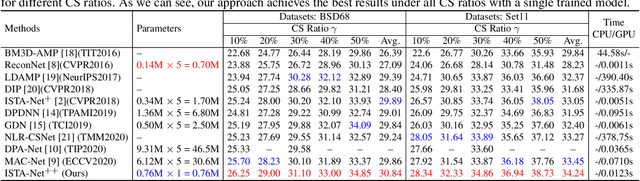

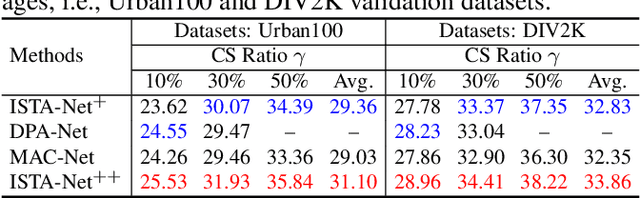
While deep neural networks have achieved impressive success in image compressive sensing (CS), most of them lack flexibility when dealing with multi-ratio tasks and multi-scene images in practical applications. To tackle these challenges, we propose a novel end-to-end flexible ISTA-unfolding deep network, dubbed ISTA-Net++, with superior performance and strong flexibility. Specifically, by developing a dynamic unfolding strategy, our model enjoys the adaptability of handling CS problems with different ratios, i.e., multi-ratio tasks, through a single model. A cross-block strategy is further utilized to reduce blocking artifacts and enhance the CS recovery quality. Furthermore, we adopt a balanced dataset for training, which brings more robustness when reconstructing images of multiple scenes. Extensive experiments on four datasets show that ISTA-Net++ achieves state-of-the-art results in terms of both quantitative metrics and visual quality. Considering its flexibility, effectiveness and practicability, our model is expected to serve as a suitable baseline in future CS research. The source code is available on https://github.com/jianzhangcs/ISTA-Netpp.
Efficient embedding network for 3D brain tumor segmentation
Nov 22, 2020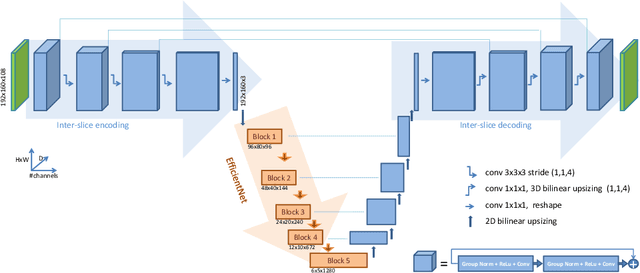
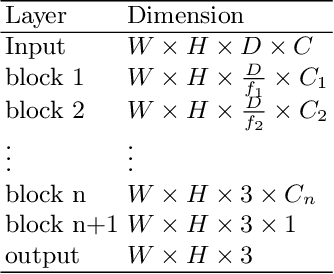
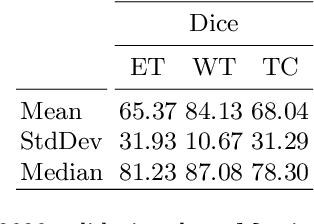
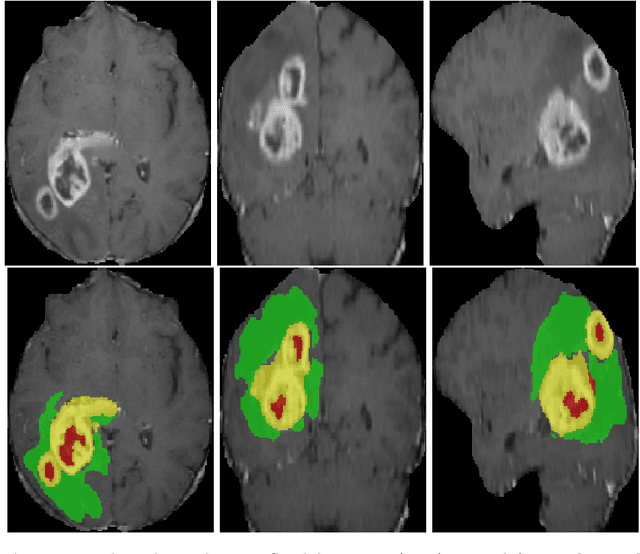
3D medical image processing with deep learning greatly suffers from a lack of data. Thus, studies carried out in this field are limited compared to works related to 2D natural image analysis, where very large datasets exist. As a result, powerful and efficient 2D convolutional neural networks have been developed and trained. In this paper, we investigate a way to transfer the performance of a two-dimensional classiffication network for the purpose of three-dimensional semantic segmentation of brain tumors. We propose an asymmetric U-Net network by incorporating the EfficientNet model as part of the encoding branch. As the input data is in 3D, the first layers of the encoder are devoted to the reduction of the third dimension in order to fit the input of the EfficientNet network. Experimental results on validation and test data from the BraTS 2020 challenge demonstrate that the proposed method achieve promising performance.
* Multimodal Brain Tumor Segmentation Challenge 2020
I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
Jun 03, 2017
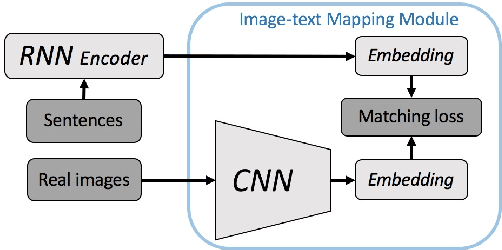
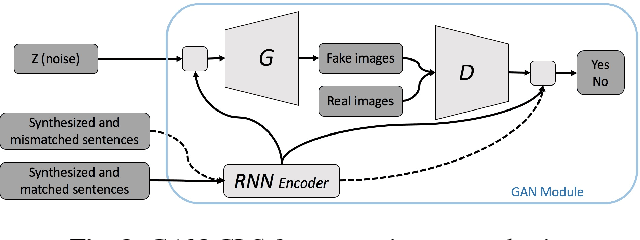
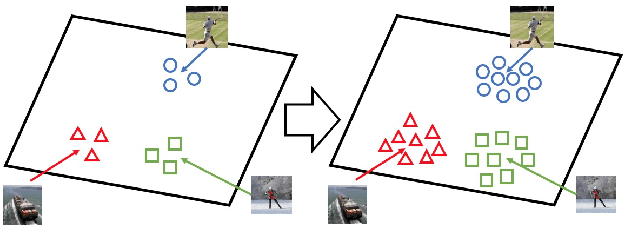
Translating information between text and image is a fundamental problem in artificial intelligence that connects natural language processing and computer vision. In the past few years, performance in image caption generation has seen significant improvement through the adoption of recurrent neural networks (RNN). Meanwhile, text-to-image generation begun to generate plausible images using datasets of specific categories like birds and flowers. We've even seen image generation from multi-category datasets such as the Microsoft Common Objects in Context (MSCOCO) through the use of generative adversarial networks (GANs). Synthesizing objects with a complex shape, however, is still challenging. For example, animals and humans have many degrees of freedom, which means that they can take on many complex shapes. We propose a new training method called Image-Text-Image (I2T2I) which integrates text-to-image and image-to-text (image captioning) synthesis to improve the performance of text-to-image synthesis. We demonstrate that %the capability of our method to understand the sentence descriptions, so as to I2T2I can generate better multi-categories images using MSCOCO than the state-of-the-art. We also demonstrate that I2T2I can achieve transfer learning by using a pre-trained image captioning module to generate human images on the MPII Human Pose
Layout-Guided Novel View Synthesis from a Single Indoor Panorama
Mar 31, 2021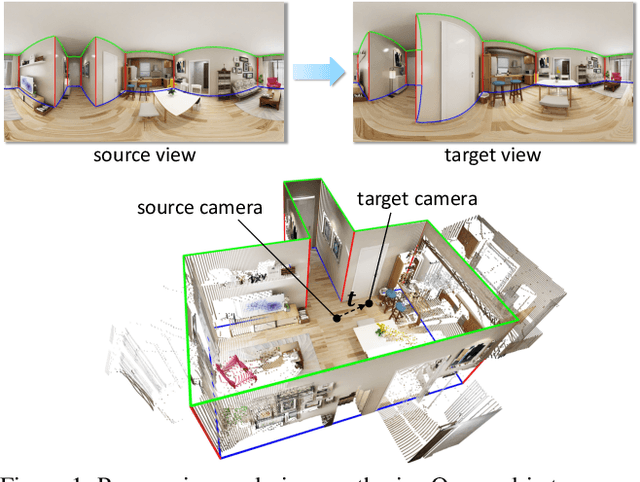
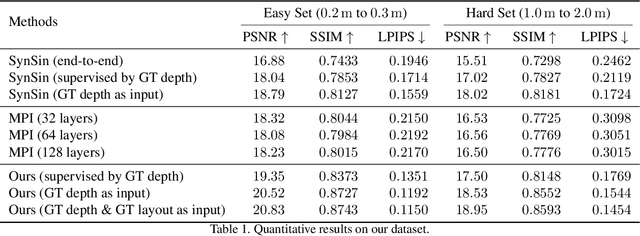
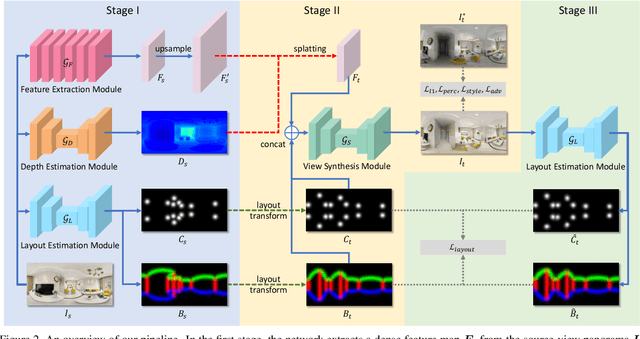
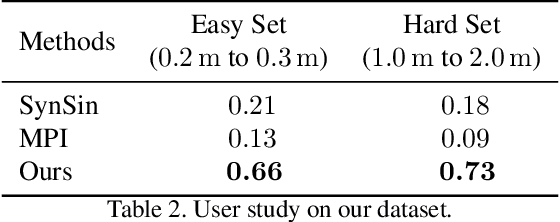
Existing view synthesis methods mainly focus on the perspective images and have shown promising results. However, due to the limited field-of-view of the pinhole camera, the performance quickly degrades when large camera movements are adopted. In this paper, we make the first attempt to generate novel views from a single indoor panorama and take the large camera translations into consideration. To tackle this challenging problem, we first use Convolutional Neural Networks (CNNs) to extract the deep features and estimate the depth map from the source-view image. Then, we leverage the room layout prior, a strong structural constraint of the indoor scene, to guide the generation of target views. More concretely, we estimate the room layout in the source view and transform it into the target viewpoint as guidance. Meanwhile, we also constrain the room layout of the generated target-view images to enforce geometric consistency. To validate the effectiveness of our method, we further build a large-scale photo-realistic dataset containing both small and large camera translations. The experimental results on our challenging dataset demonstrate that our method achieves state-of-the-art performance. The project page is at https://github.com/bluestyle97/PNVS.
Video Action Understanding: A Tutorial
Oct 13, 2020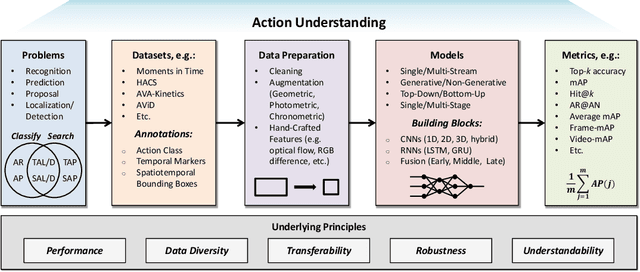
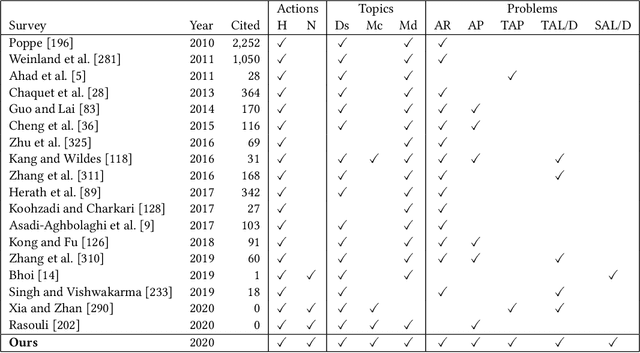
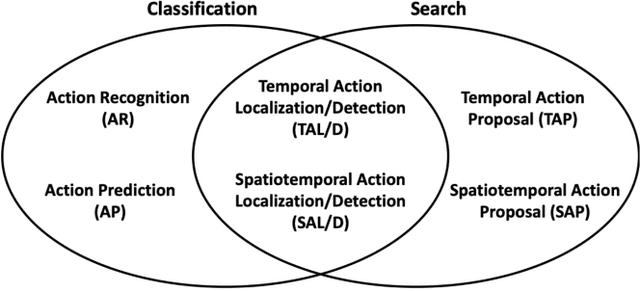
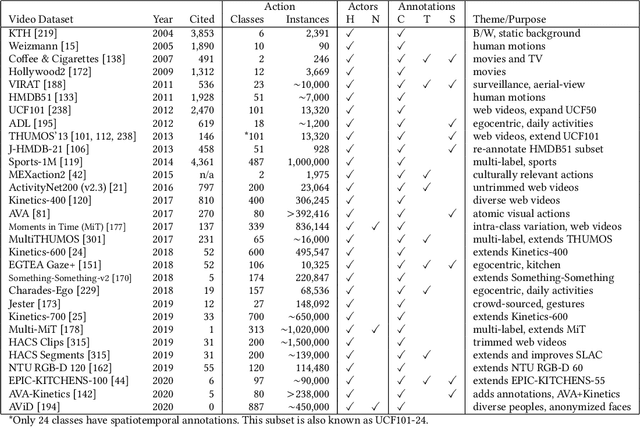
Many believe that the successes of deep learning on image understanding problems can be replicated in the realm of video understanding. However, the span of video action problems and the set of proposed deep learning solutions is arguably wider and more diverse than those of their 2D image siblings. Finding, identifying, and predicting actions are a few of the most salient tasks in video action understanding. This tutorial clarifies a taxonomy of video action problems, highlights datasets and metrics used to baseline each problem, describes common data preparation methods, and presents the building blocks of state-of-the-art deep learning model architectures.
Hopper: Multi-hop Transformer for Spatiotemporal Reasoning
Mar 22, 2021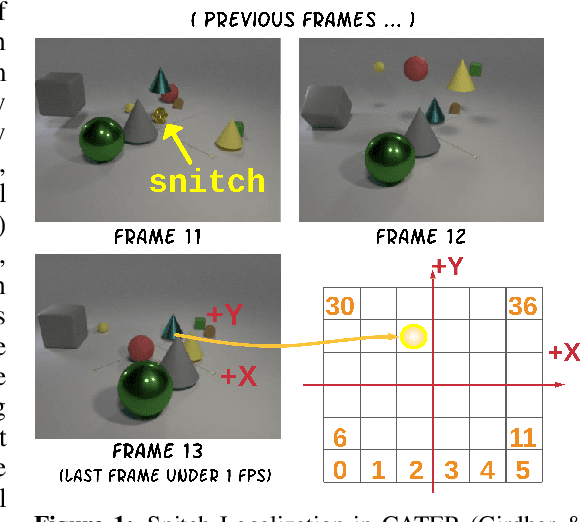
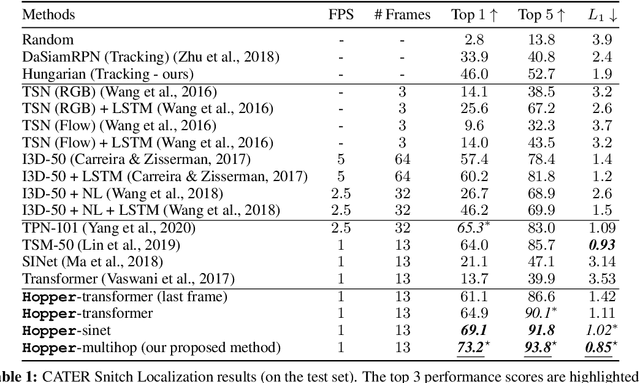
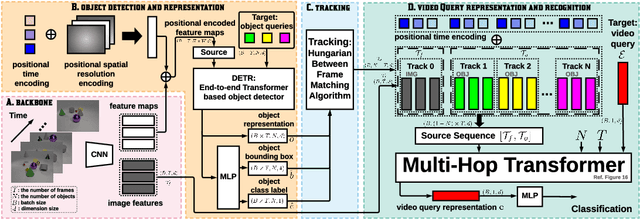
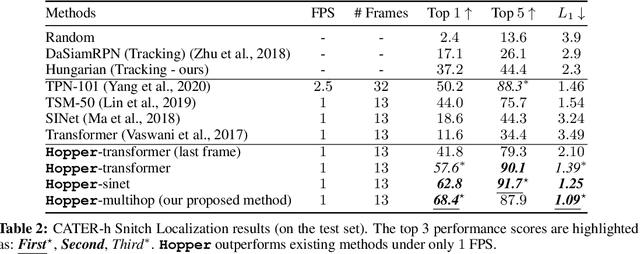
This paper considers the problem of spatiotemporal object-centric reasoning in videos. Central to our approach is the notion of object permanence, i.e., the ability to reason about the location of objects as they move through the video while being occluded, contained or carried by other objects. Existing deep learning based approaches often suffer from spatiotemporal biases when applied to video reasoning problems. We propose Hopper, which uses a Multi-hop Transformer for reasoning object permanence in videos. Given a video and a localization query, Hopper reasons over image and object tracks to automatically hop over critical frames in an iterative fashion to predict the final position of the object of interest. We demonstrate the effectiveness of using a contrastive loss to reduce spatiotemporal biases. We evaluate over CATER dataset and find that Hopper achieves 73.2% Top-1 accuracy using just 1 FPS by hopping through just a few critical frames. We also demonstrate Hopper can perform long-term reasoning by building a CATER-h dataset that requires multi-step reasoning to localize objects of interest correctly.
Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs
Nov 28, 2020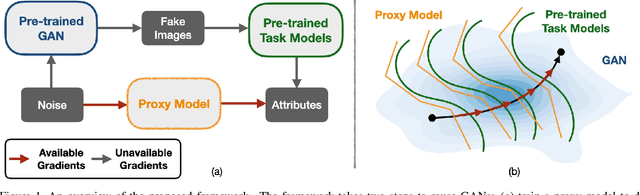
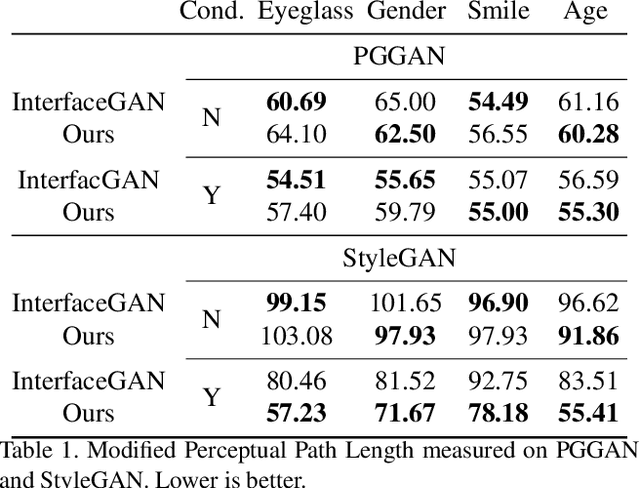

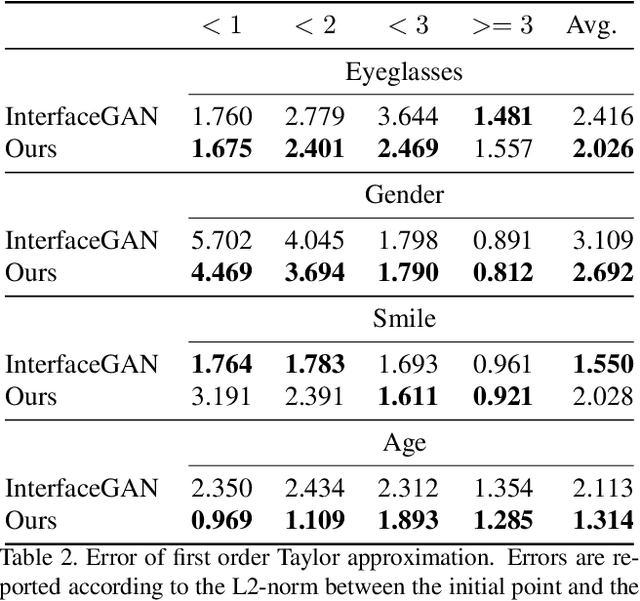
While Generative Adversarial Networks (GANs) show increasing performance and the level of realism is becoming indistinguishable from natural images, this also comes with high demands on data and computation. We show that state-of-the-art GAN models -- such as they are being publicly released by researchers and industry -- can be used for a range of applications beyond unconditional image generation. We achieve this by an iterative scheme that also allows gaining control over the image generation process despite the highly non-linear latent spaces of the latest GAN models. We demonstrate that this opens up the possibility to re-use state-of-the-art, difficult to train, pre-trained GANs with a high level of control even if only black-box access is granted. Our work also raises concerns and awareness that the use cases of a published GAN model may well reach beyond the creators' intention, which needs to be taken into account before a full public release.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018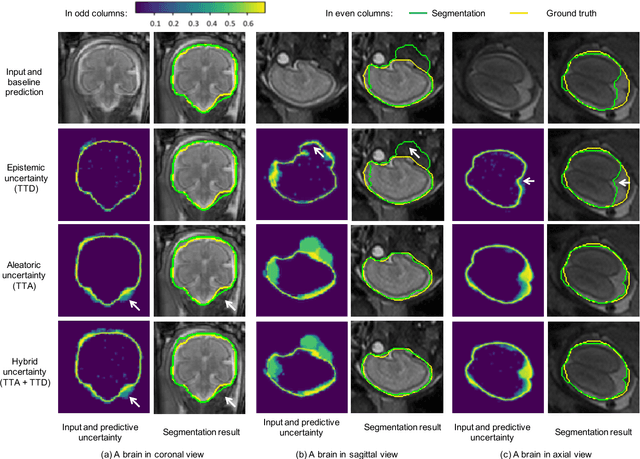
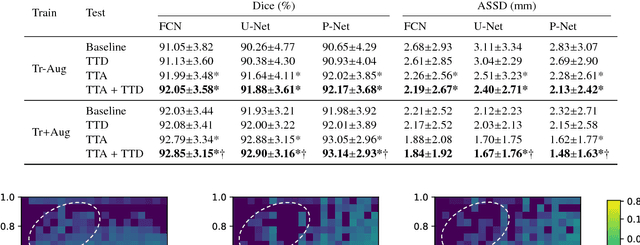
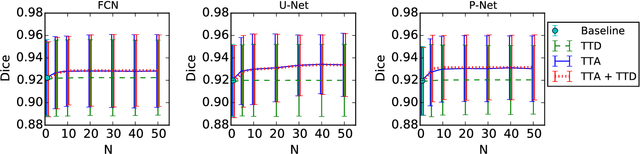
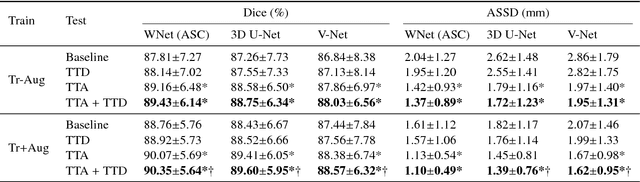
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.