 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Overcoming Catastrophic Forgetting with Gaussian Mixture Replay
Apr 19, 2021
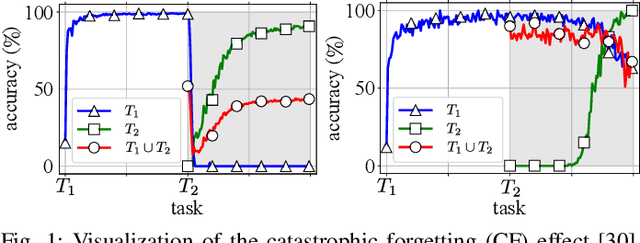

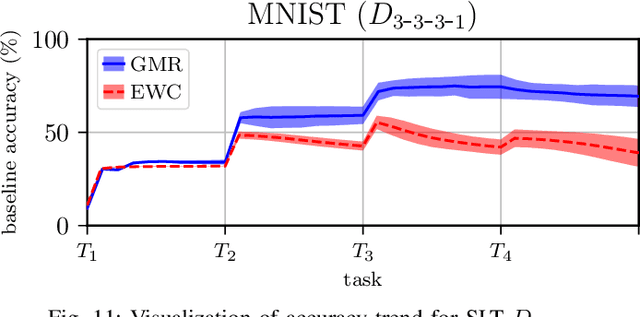
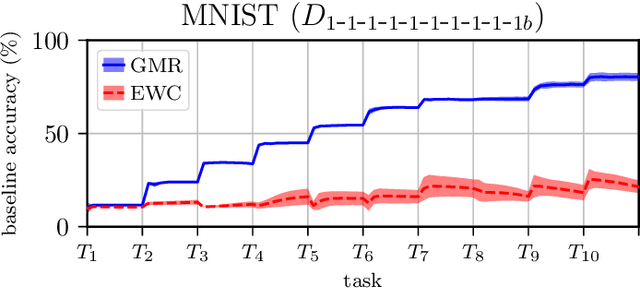
We present Gaussian Mixture Replay (GMR), a rehearsal-based approach for continual learning (CL) based on Gaussian Mixture Models (GMM). CL approaches are intended to tackle the problem of catastrophic forgetting (CF), which occurs for Deep Neural Networks (DNNs) when sequentially training them on successive sub-tasks. GMR mitigates CF by generating samples from previous tasks and merging them with current training data. GMMs serve several purposes here: sample generation, density estimation (e.g., for detecting outliers or recognizing task boundaries) and providing a high-level feature representation for classification. GMR has several conceptual advantages over existing replay-based CL approaches. First of all, GMR achieves sample generation, classification and density estimation in a single network structure with strongly reduced memory requirements. Secondly, it can be trained at constant time complexity w.r.t. the number of sub-tasks, making it particularly suitable for life-long learning. Furthermore, GMR minimizes a differentiable loss function and seems to avoid mode collapse. In addition, task boundaries can be detected by applying GMM density estimation. Lastly, GMR does not require access to sub-tasks lying in the future for hyper-parameter tuning, allowing CL under real-world constraints. We evaluate GMR on multiple image datasets, which are divided into class-disjoint sub-tasks.
Towards Unsupervised Learning for Instrument Segmentation in Robotic Surgery with Cycle-Consistent Adversarial Networks
Jul 09, 2020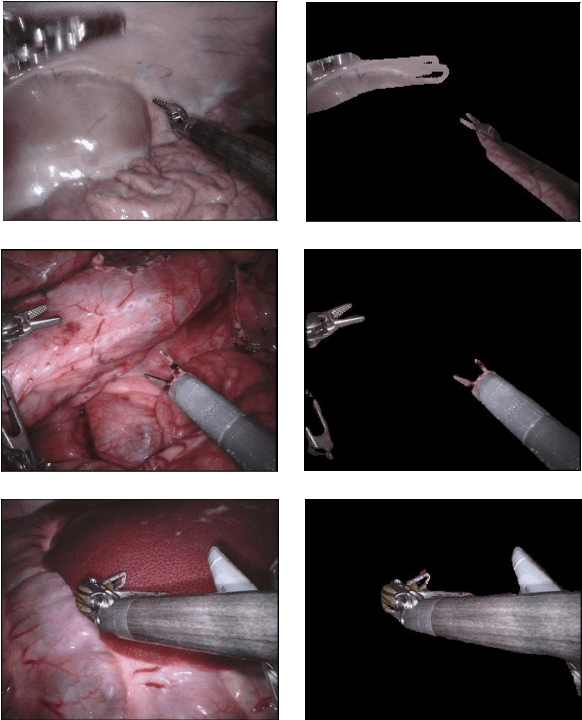
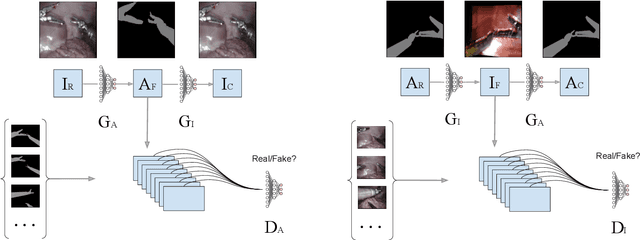
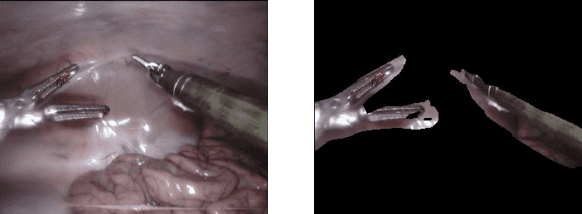
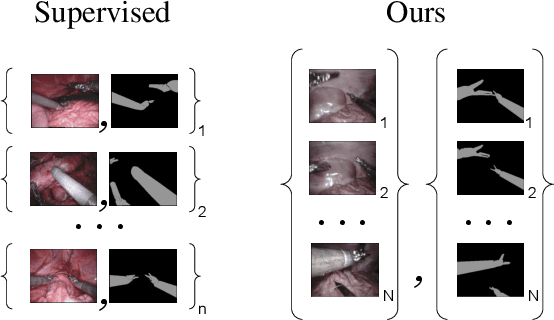
Surgical tool segmentation in endoscopic images is an important problem: it is a crucial step towards full instrument pose estimation and it is used for integration of pre- and intra-operative images into the endoscopic view. While many recent approaches based on convolutional neural networks have shown great results, a key barrier to progress lies in the acquisition of a large number of manually-annotated images which is necessary for an algorithm to generalize and work well in diverse surgical scenarios. Unlike the surgical image data itself, annotations are difficult to acquire and may be of variable quality. On the other hand, synthetic annotations can be automatically generated by using forward kinematic model of the robot and CAD models of tools by projecting them onto an image plane. Unfortunately, this model is very inaccurate and cannot be used for supervised learning of image segmentation models. Since generated annotations will not directly correspond to endoscopic images due to errors, we formulate the problem as an unpaired image-to-image translation where the goal is to learn the mapping between an input endoscopic image and a corresponding annotation using an adversarial model. Our approach allows to train image segmentation models without the need to acquire expensive annotations and can potentially exploit large unlabeled endoscopic image collection outside the annotated distributions of image/annotation data. We test our proposed method on Endovis 2017 challenge dataset and show that it is competitive with supervised segmentation methods.
An Attention-Based Approach for Single Image Super Resolution
Jul 18, 2018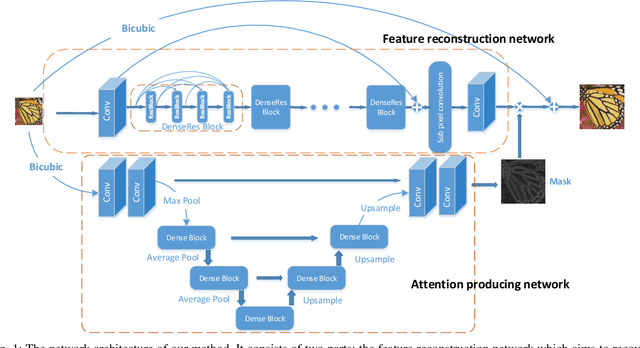
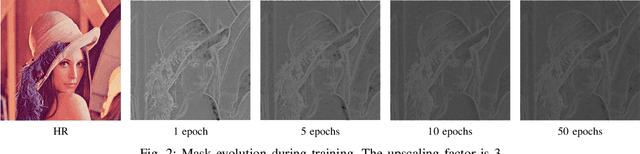

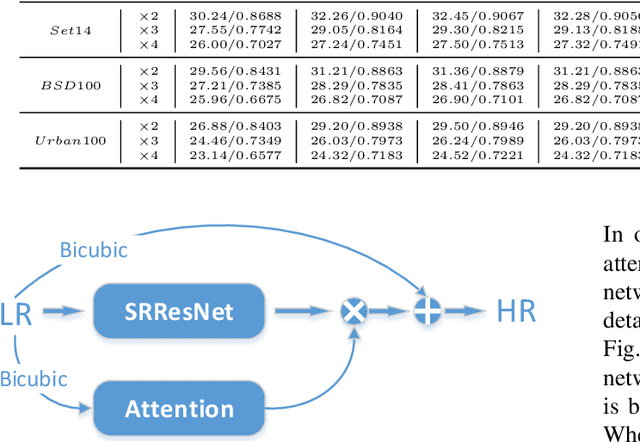
The main challenge of single image super resolution (SISR) is the recovery of high frequency details such as tiny textures. However, most of the state-of-the-art methods lack specific modules to identify high frequency areas, causing the output image to be blurred. We propose an attention-based approach to give a discrimination between texture areas and smooth areas. After the positions of high frequency details are located, high frequency compensation is carried out. This approach can incorporate with previously proposed SISR networks. By providing high frequency enhancement, better performance and visual effect are achieved. We also propose our own SISR network composed of DenseRes blocks. The block provides an effective way to combine the low level features and high level features. Extensive benchmark evaluation shows that our proposed method achieves significant improvement over the state-of-the-art works in SISR.
Conditional Variational Capsule Network for Open Set Recognition
Apr 19, 2021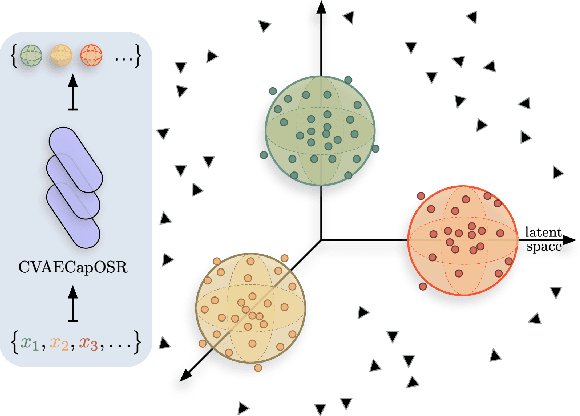
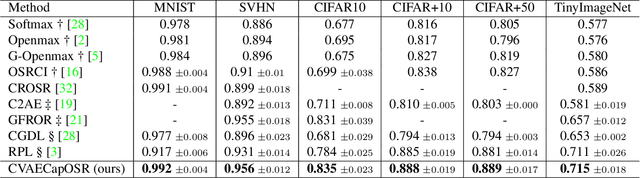
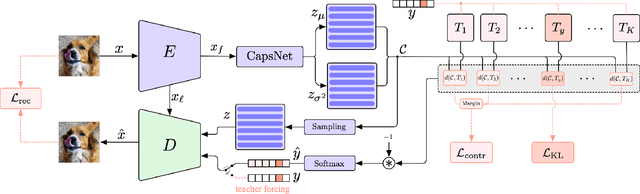

In open set recognition, a classifier has to detect unknown classes that are not known at training time. In order to recognize new classes, the classifier has to project the input samples of known classes in very compact and separated regions of the features space in order to discriminate outlier samples of unknown classes. Recently proposed Capsule Networks have shown to outperform alternatives in many fields, particularly in image recognition, however they have not been fully applied yet to open-set recognition. In capsule networks, scalar neurons are replaced by capsule vectors or matrices, whose entries represent different properties of objects. In our proposal, during training, capsules features of the same known class are encouraged to match a pre-defined gaussian, one for each class. To this end, we use the variational autoencoder framework, with a set of gaussian prior as the approximation for the posterior distribution. In this way, we are able to control the compactness of the features of the same class around the center of the gaussians, thus controlling the ability of the classifier in detecting samples from unknown classes. We conducted several experiments and ablation of our model, obtaining state of the art results on different datasets in the open set recognition and unknown detection tasks.
Efficient and Differentiable Shadow Computation for Inverse Problems
Apr 01, 2021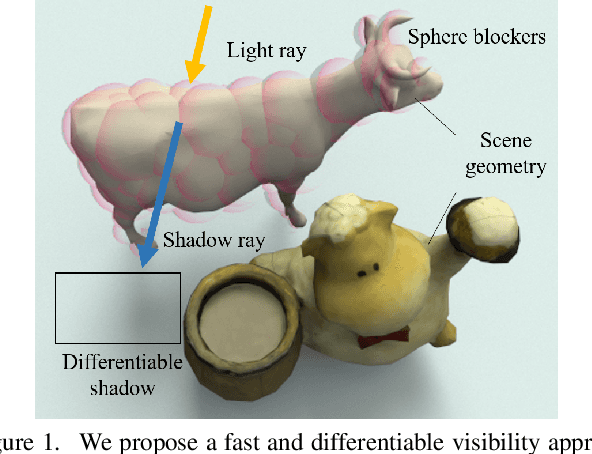
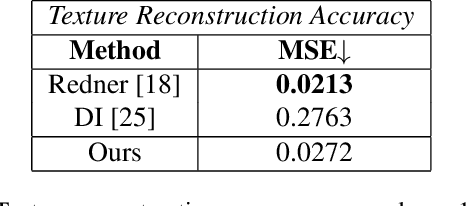
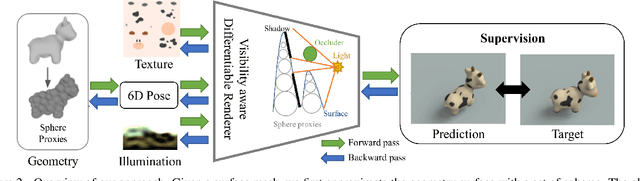
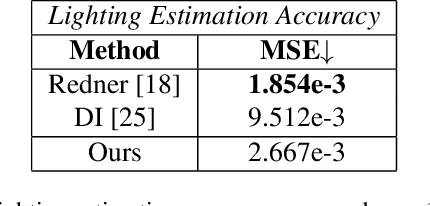
Differentiable rendering has received increasing interest for image-based inverse problems. It can benefit traditional optimization-based solutions to inverse problems, but also allows for self-supervision of learning-based approaches for which training data with ground truth annotation is hard to obtain. However, existing differentiable renderers either do not model visibility of the light sources from the different points in the scene, responsible for shadows in the images, or are too slow for being used to train deep architectures over thousands of iterations. To this end, we propose an accurate yet efficient approach for differentiable visibility and soft shadow computation. Our approach is based on the spherical harmonics approximations of the scene illumination and visibility, where the occluding surface is approximated with spheres. This allows for a significantly more efficient shadow computation compared to methods based on ray tracing. As our formulation is differentiable, it can be used to solve inverse problems such as texture, illumination, rigid pose, and geometric deformation recovery from images using analysis-by-synthesis optimization.
Adversarial Robust Training in MRI Reconstruction
Oct 30, 2020
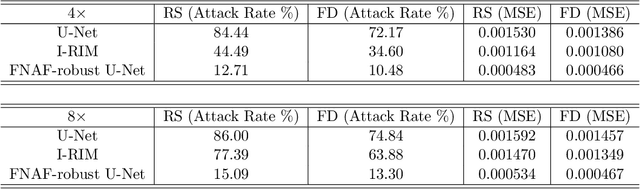

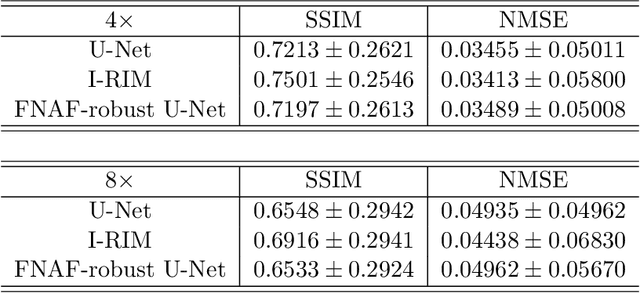
Deep Learning has shown potential in accelerating Magnetic Resonance Image acquisition and reconstruction. Nevertheless, there is a dearth of tailored methods to guarantee that the reconstruction of small features is achieved with high fidelity. In this work, we employ adversarial attacks to generate small synthetic perturbations that when added to the input MRI, they are not reconstructed by a trained DL reconstruction network. Then, we use robust training to increase the network's sensitivity to small features and encourage their reconstruction. Next, we investigate the generalization of said approach to real world features. For this, a musculoskeletal radiologist annotated a set of cartilage and meniscal lesions from the knee Fast-MRI dataset, and a classification network was devised to assess the features reconstruction. Experimental results show that by introducing robust training to a reconstruction network, the rate (4.8\%) of false negative features in image reconstruction can be reduced. The results are encouraging and highlight the necessity for attention on this problem by the image reconstruction community, as a milestone for the introduction of DL reconstruction in clinical practice. To support further research, we make our annotation publicly available at https://github.com/fcaliva/fastMRI_BB_abnormalities_annotation.
Unsupervised image segmentation via maximum a posteriori estimation of continuous max-flow
Nov 01, 2018



Recent thrust in imaging capabilities in medical as well as emerging areas of manufacturing systems creates unique opportunities and challenges for on-the-fly, unsupervised estimation of anomalies and other regions of interest. With the ever-growing image database, it is remarkably costly to create annotations and atlases associated with different combinations of imaging capabilities and regions of interest. To address this issue, we present an unsupervised learning approach to a continuous max-flow problem. We show that the maximum a posteriori estimation of the image labels can be formulated as a capacitated max-flow problem over a continuous domain with unknown flow capacities. The flow capacities are then iteratively obtained by considering a Markov random field prior over the neighborhood structure in the image. We also present results to establish the consistency of the proposed approach. We establish the performance of our approach on two real-world datasets including, brain tumor segmentation and defect identification in additively manufactured surfaces as gathered from electron microscopic images. We also present an exhaustive comparison with other state-of-the-art supervised as well as unsupervised algorithms. Results suggest that the method is able to perform almost comparable to other supervised approaches, but more 90% improvement in terms of Dice score as compared to other unsupervised methods.
Poisoning MorphNet for Clean-Label Backdoor Attack to Point Clouds
May 11, 2021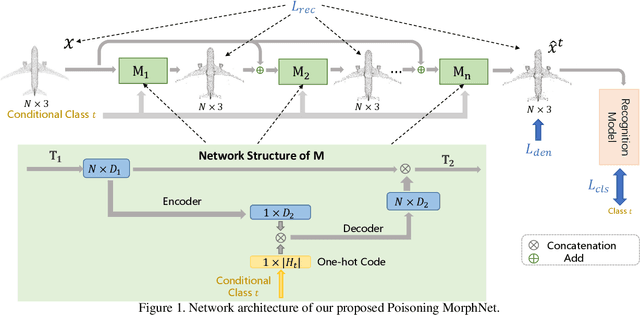

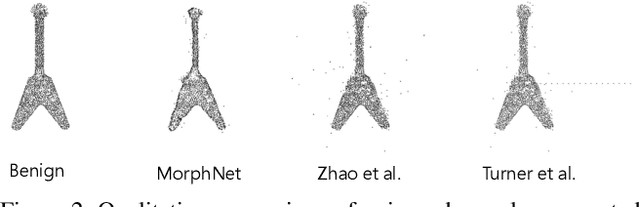

This paper presents Poisoning MorphNet, the first backdoor attack method on point clouds. Conventional adversarial attack takes place in the inference stage, often fooling a model by perturbing samples. In contrast, backdoor attack aims to implant triggers into a model during the training stage, such that the victim model acts normally on the clean data unless a trigger is present in a sample. This work follows a typical setting of clean-label backdoor attack, where a few poisoned samples (with their content tampered yet labels unchanged) are injected into the training set. The unique contributions of MorphNet are two-fold. First, it is key to ensure the implanted triggers both visually imperceptible to humans and lead to high attack success rate on the point clouds. To this end, MorphNet jointly optimizes two objectives for sample-adaptive poisoning: a reconstruction loss that preserves the visual similarity between benign / poisoned point clouds, and a classification loss that enforces a modern recognition model of point clouds tends to mis-classify the poisoned sample to a pre-specified target category. This implicitly conducts spectral separation over point clouds, hiding sample-adaptive triggers in fine-grained high-frequency details. Secondly, existing backdoor attack methods are mainly designed for image data, easily defended by some point cloud specific operations (such as denoising). We propose a third loss in MorphNet for suppressing isolated points, leading to improved resistance to denoising-based defense. Comprehensive evaluations are conducted on ModelNet40 and ShapeNetcorev2. Our proposed Poisoning MorphNet outstrips all previous methods with clear margins.
Image analysis for Alzheimer's disease prediction: Embracing pathological hallmarks for model architecture design
Nov 13, 2020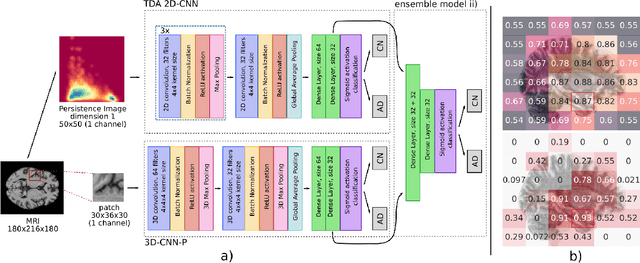
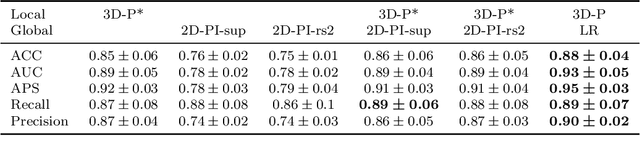
Alzheimer's disease (AD) is associated with local (e.g. brain tissue atrophy) and global brain changes (loss of cerebral connectivity), which can be detected by high-resolution structural magnetic resonance imaging. Conventionally, these changes and their relation to AD are investigated independently. Here, we introduce a novel, highly-scalable approach that simultaneously captures $\textit{local}$ and $\textit{global}$ changes in the diseased brain. It is based on a neural network architecture that combines patch-based, high-resolution 3D-CNNs with global topological features, evaluating multi-scale brain tissue connectivity. Our local-global approach reached competitive results with an average precision score of $0.95\pm0.03$ for the classification of cognitively normal subjects and AD patients (prevalence $\approx 55\%$).
DeepViT: Towards Deeper Vision Transformer
Apr 19, 2021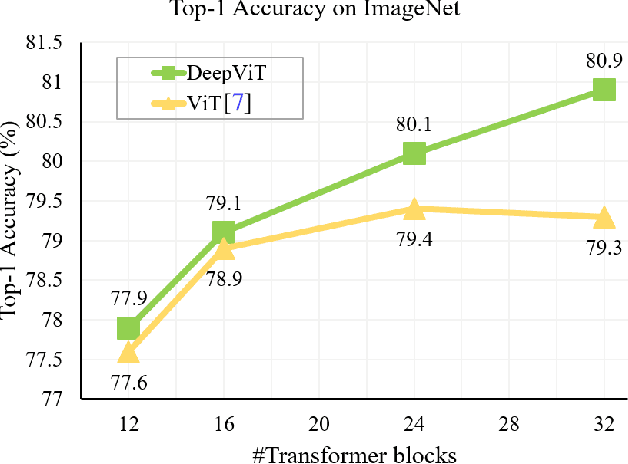
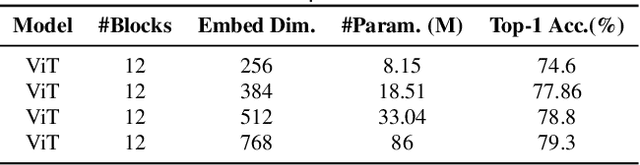
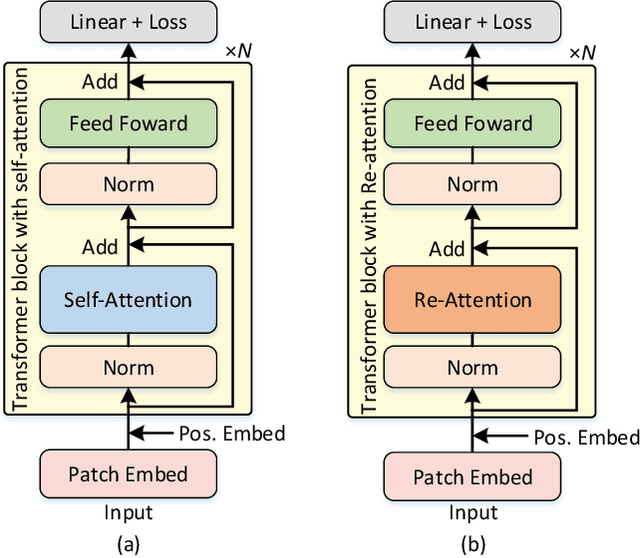

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.