 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021

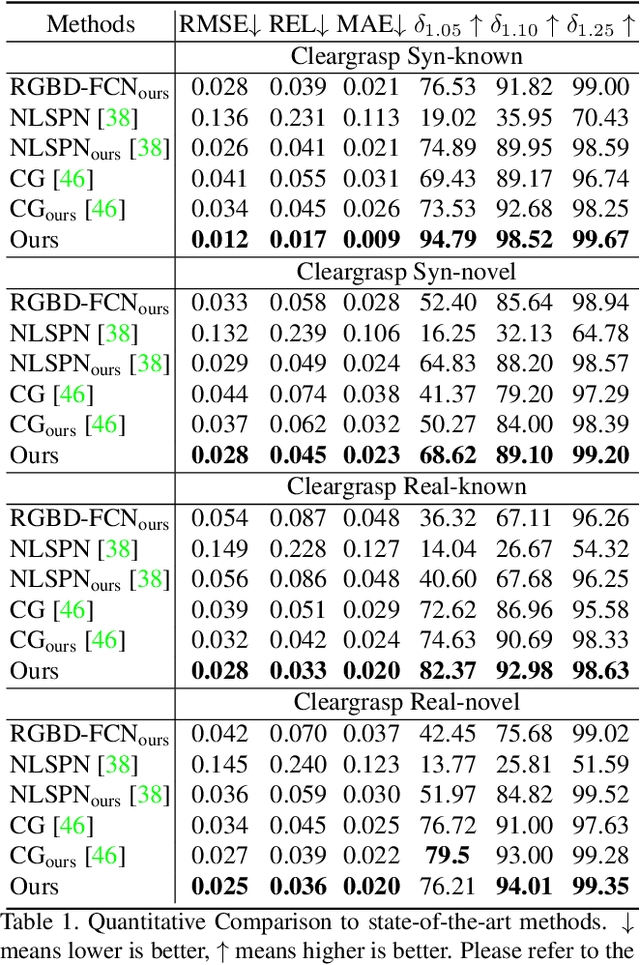


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Scientific image rendering for space scenes with the SurRender software
Oct 02, 2018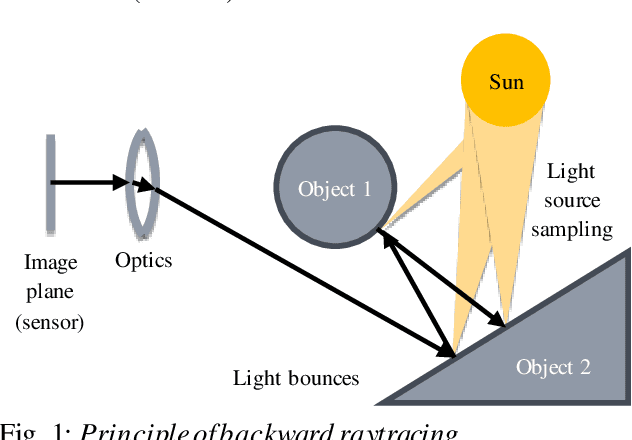



Spacecraft autonomy can be enhanced by vision-based navigation (VBN) techniques. Applications range from manoeuvers around Solar System objects and landing on planetary surfaces, to in-orbit servicing or space debris removal. The development and validation of VBN algorithms relies on the availability of physically accurate relevant images. Yet archival data from past missions can rarely serve this purpose and acquiring new data is often costly. The SurRender software is an image simulator that addresses the challenges of realistic image rendering, with high representativeness for space scenes. Images are rendered by raytracing, which implements the physical principles of geometrical light propagation, in physical units. A macroscopic instrument model and scene objects reflectance functions are used. SurRender is specially optimized for space scenes, with huge distances between objects and scenes up to Solar System size. Raytracing conveniently tackles some important effects for VBN algorithms: image quality, eclipses, secondary illumination, subpixel limb imaging, etc. A simulation is easily setup (in MATLAB, Python, and more) by specifying the position of the bodies (camera, Sun, planets, satellites) over time, 3D shapes and material surface properties. SurRender comes with its own modelling tool enabling to go beyond existing models for shapes, materials and sensors (projection, temporal sampling, electronics, etc.). It is natively designed to simulate different kinds of sensors (visible, LIDAR, etc.). Tools are available for manipulating huge datasets to store albedo maps and digital elevation models, or for procedural (fractal) texturing that generates high-quality images for a large range of observing distances (from millions of km to touchdown). We illustrate SurRender performances with a selection of case studies, placing particular emphasis on a 900-km Moon flyby simulation.
Uncertainty-guided Model Generalization to Unseen Domains
Mar 12, 2021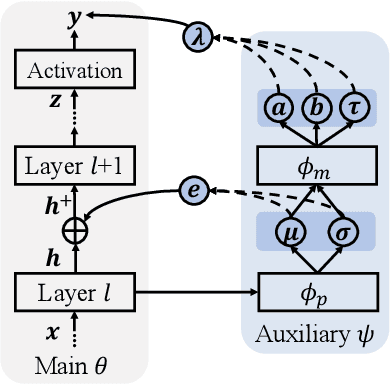
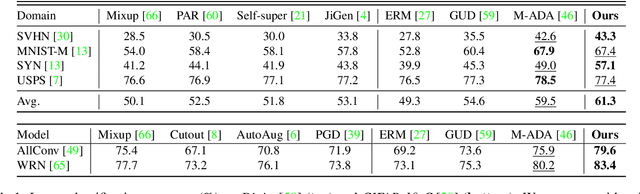
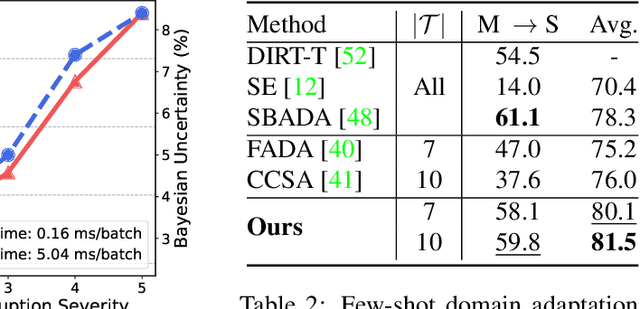
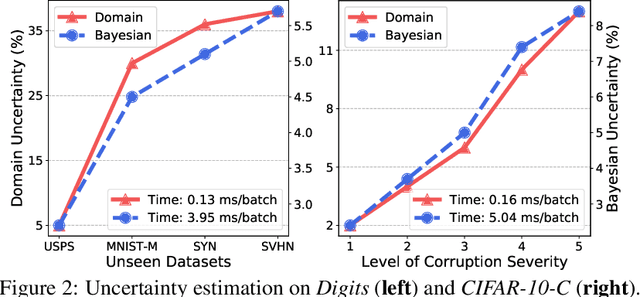
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations. In this paper, we propose a new solution. The key idea is to augment the source capacity in both input and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) access the generalization uncertainty from a single source and (2) leverage it to guide both input and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
A Front-End for Dense Monocular SLAM using a Learned Outlier Mask Prior
Apr 01, 2021


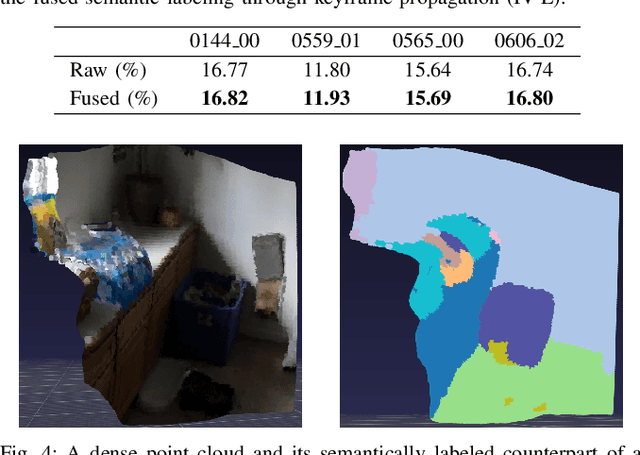
Recent achievements in depth prediction from a single RGB image have powered the new research area of combining convolutional neural networks (CNNs) with classical simultaneous localization and mapping (SLAM) algorithms. The depth prediction from a CNN provides a reasonable initial point in the optimization process in the traditional SLAM algorithms, while the SLAM algorithms further improve the CNN prediction online. However, most of the current CNN-SLAM approaches have only taken advantage of the depth prediction but not yet other products from a CNN. In this work, we explore the use of the outlier mask, a by-product from unsupervised learning of depth from video, as a prior in a classical probability model for depth estimate fusion to step up the outlier-resistant tracking performance of a SLAM front-end. On the other hand, some of the previous CNN-SLAM work builds on feature-based sparse SLAM methods, wasting the per-pixel dense prediction from a CNN. In contrast to these sparse methods, we devise a dense CNN-assisted SLAM front-end that is implementable with TensorFlow and evaluate it on both indoor and outdoor datasets.
Towards creativity characterization of generative models via group-based subset scanning
Apr 01, 2021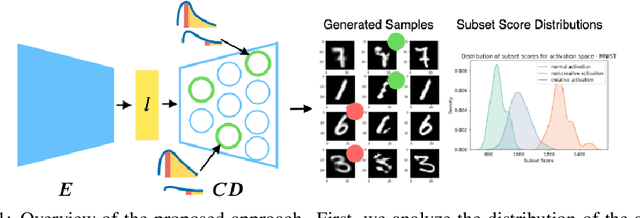
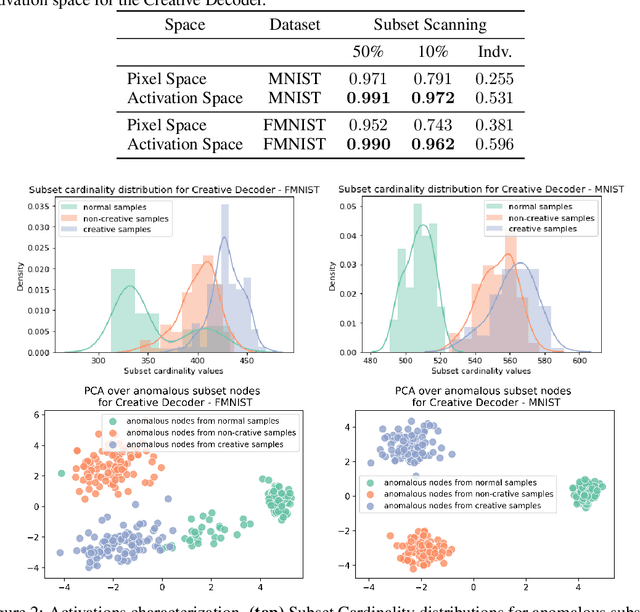
Deep generative models, such as Variational Autoencoders (VAEs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed to creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to quantify, detect, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of generative models. Our experiments on original, typically decoded, and "creatively decoded" (Das et al 2020) image datasets reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for normal sample generation.
RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving
Dec 30, 2020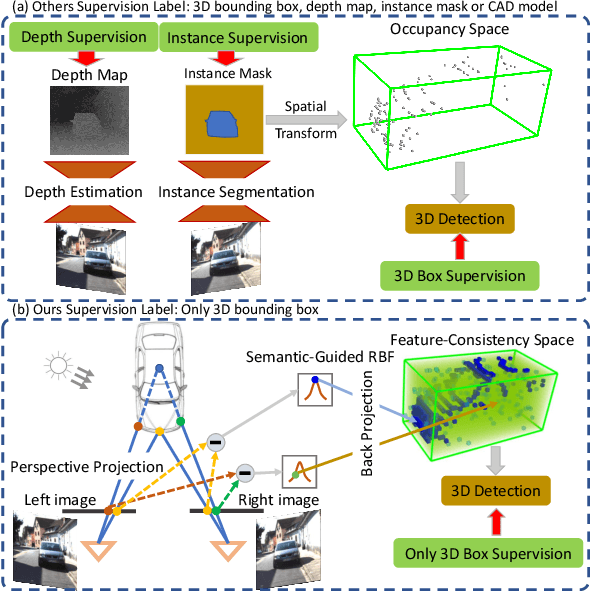

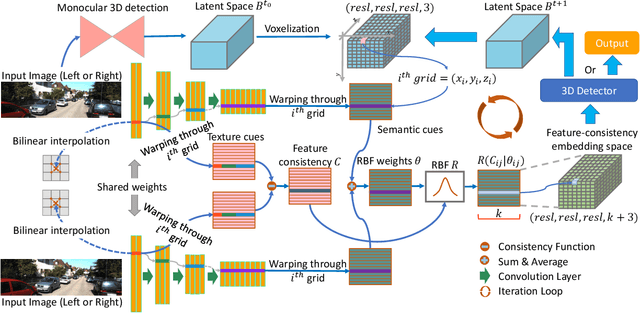
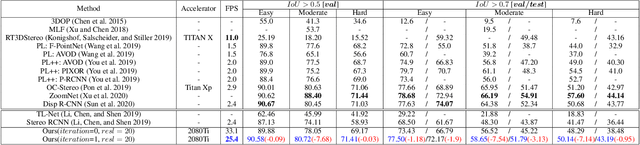
Although the recent image-based 3D object detection methods using Pseudo-LiDAR representation have shown great capabilities, a notable gap in efficiency and accuracy still exist compared with LiDAR-based methods. Besides, over-reliance on the stand-alone depth estimator, requiring a large number of pixel-wise annotations in the training stage and more computation in the inferencing stage, limits the scaling application in the real world. In this paper, we propose an efficient and accurate 3D object detection method from stereo images, named RTS3D. Different from the 3D occupancy space in the Pseudo-LiDAR similar methods, we design a novel 4D feature-consistent embedding (FCE) space as the intermediate representation of the 3D scene without depth supervision. The FCE space encodes the object's structural and semantic information by exploring the multi-scale feature consistency warped from stereo pair. Furthermore, a semantic-guided RBF (Radial Basis Function) and a structure-aware attention module are devised to reduce the influence of FCE space noise without instance mask supervision. Experiments on the KITTI benchmark show that RTS3D is the first true real-time system (FPS$>$24) for stereo image 3D detection meanwhile achieves $10\%$ improvement in average precision comparing with the previous state-of-the-art method. The code will be available at https://github.com/Banconxuan/RTS3D
Unsupervised Learning of Monocular Depth and Ego-Motion Using Multiple Masks
Apr 01, 2021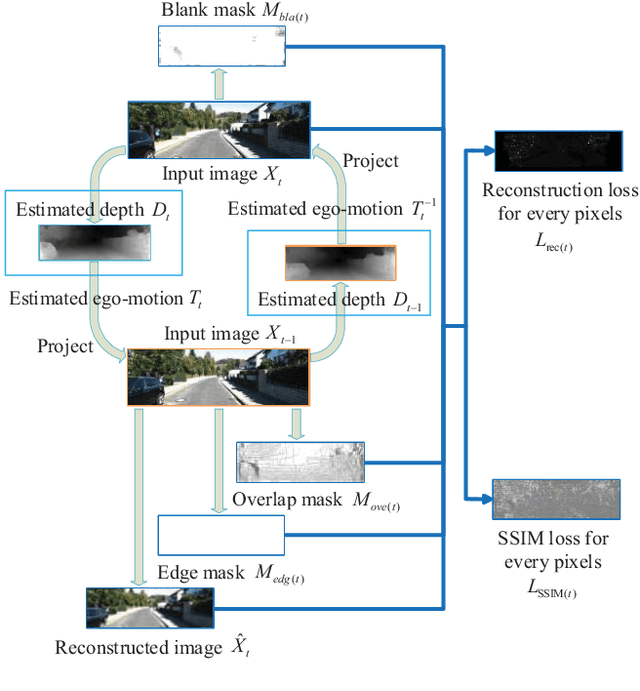
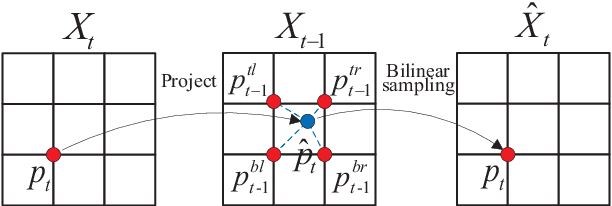
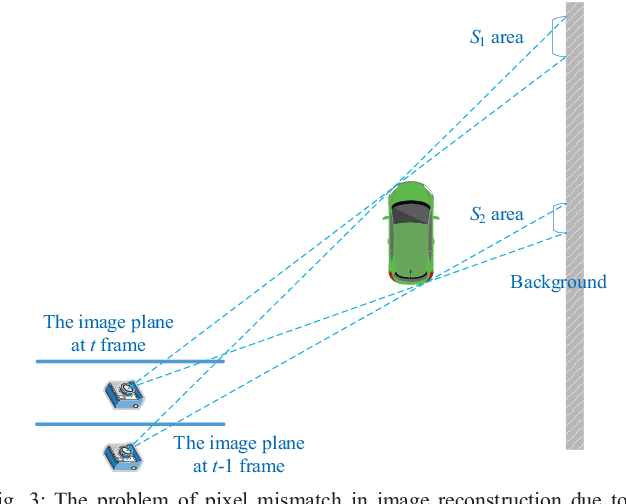
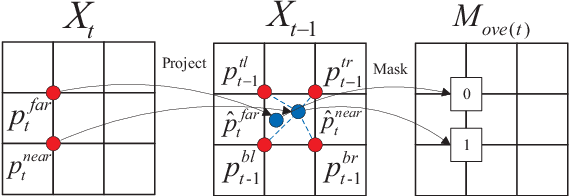
A new unsupervised learning method of depth and ego-motion using multiple masks from monocular video is proposed in this paper. The depth estimation network and the ego-motion estimation network are trained according to the constraints of depth and ego-motion without truth values. The main contribution of our method is to carefully consider the occlusion of the pixels generated when the adjacent frames are projected to each other, and the blank problem generated in the projection target imaging plane. Two fine masks are designed to solve most of the image pixel mismatch caused by the movement of the camera. In addition, some relatively rare circumstances are considered, and repeated masking is proposed. To some extent, the method is to use a geometric relationship to filter the mismatched pixels for training, making unsupervised learning more efficient and accurate. The experiments on KITTI dataset show our method achieves good performance in terms of depth and ego-motion. The generalization capability of our method is demonstrated by training on the low-quality uncalibrated bike video dataset and evaluating on KITTI dataset, and the results are still good.
* Accepted to ICRA 2019
OR-Net: Pointwise Relational Inference for Data Completion under Partial Observation
May 02, 2021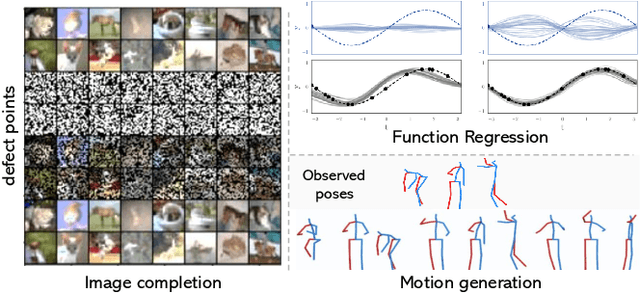
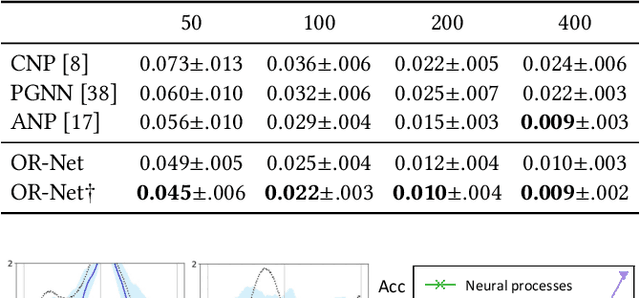
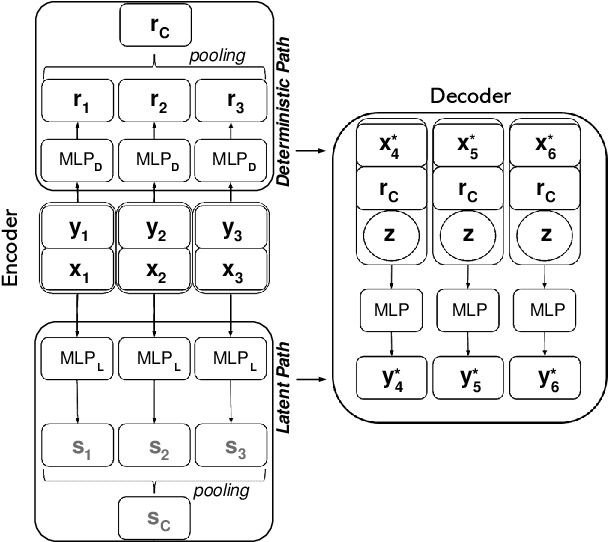
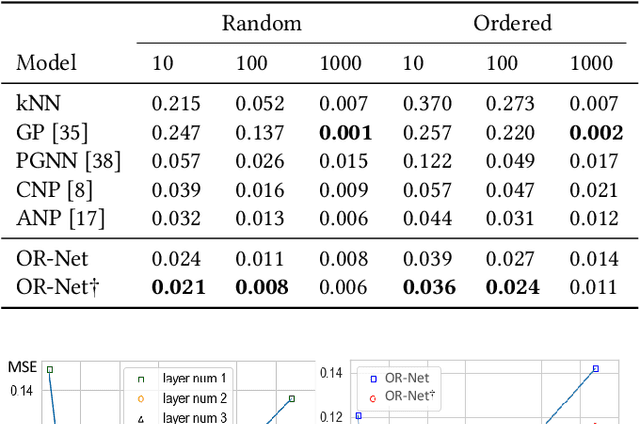
Contemporary data-driven methods are typically fed with full supervision on large-scale datasets which limits their applicability. However, in the actual systems with limitations such as measurement error and data acquisition problems, people usually obtain incomplete data. Although data completion has attracted wide attention, the underlying data pattern and relativity are still under-developed. Currently, the family of latent variable models allows learning deep latent variables over observed variables by fitting the marginal distribution. As far as we know, current methods fail to perceive the data relativity under partial observation. Aiming at modeling incomplete data, this work uses relational inference to fill in the incomplete data. Specifically, we expect to approximate the real joint distribution over the partial observation and latent variables, thus infer the unseen targets respectively. To this end, we propose Omni-Relational Network (OR-Net) to model the pointwise relativity in two aspects: (i) On one hand, the inner relationship is built among the context points in the partial observation; (ii) On the other hand, the unseen targets are inferred by learning the cross-relationship with the observed data points. It is further discovered that the proposed method can be generalized to different scenarios regardless of whether the physical structure can be observed or not. It is demonstrated that the proposed OR-Net can be well generalized for data completion tasks of various modalities, including function regression, image completion on MNIST and CelebA datasets, and also sequential motion generation conditioned on the observed poses.
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021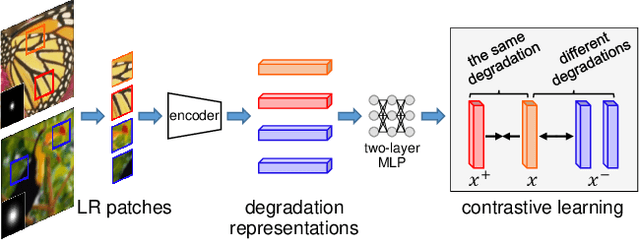

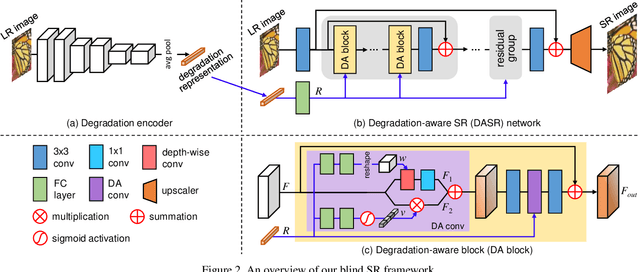
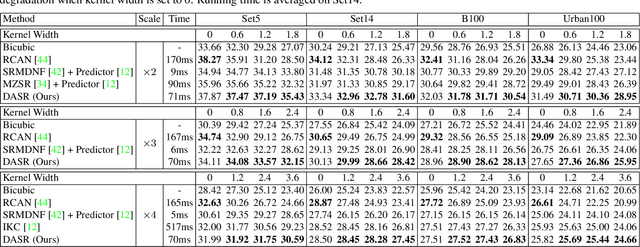
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.
Video Action Understanding: A Tutorial
Oct 13, 2020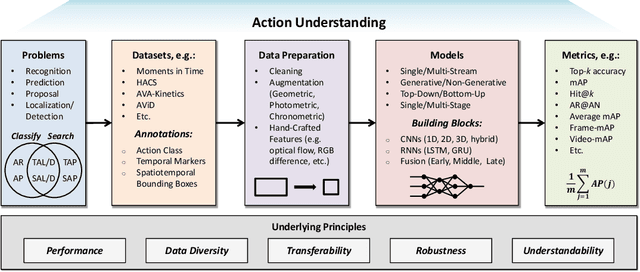
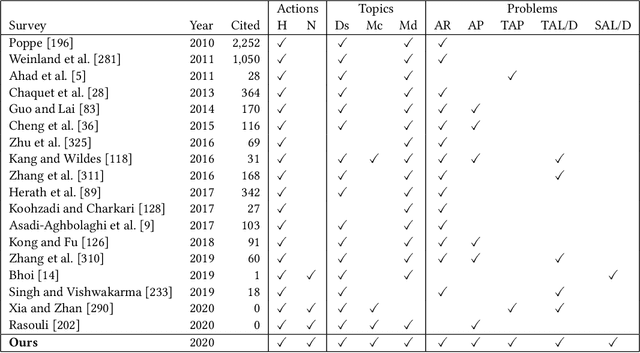
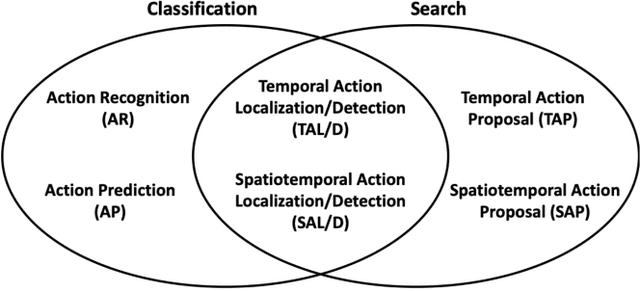
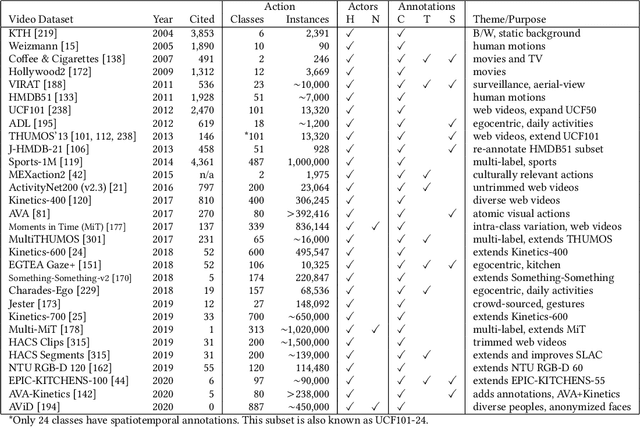
Many believe that the successes of deep learning on image understanding problems can be replicated in the realm of video understanding. However, the span of video action problems and the set of proposed deep learning solutions is arguably wider and more diverse than those of their 2D image siblings. Finding, identifying, and predicting actions are a few of the most salient tasks in video action understanding. This tutorial clarifies a taxonomy of video action problems, highlights datasets and metrics used to baseline each problem, describes common data preparation methods, and presents the building blocks of state-of-the-art deep learning model architectures.