 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Partially Reversible U-Net for Memory-Efficient Volumetric Image Segmentation
Jun 20, 2019

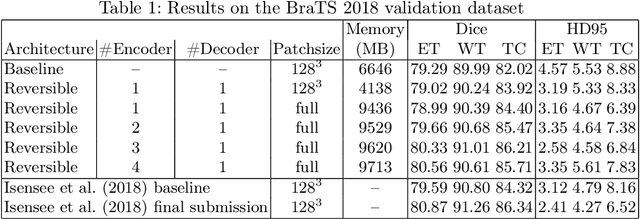

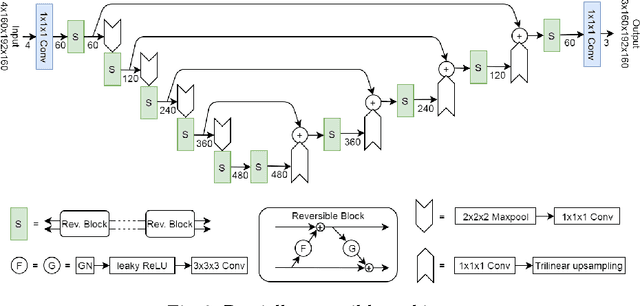
One of the key drawbacks of 3D convolutional neural networks for segmentation is their memory footprint, which necessitates compromises in the network architecture in order to fit into a given memory budget. Motivated by the RevNet for image classification, we propose a partially reversible U-Net architecture that reduces memory consumption substantially. The reversible architecture allows us to exactly recover each layer's outputs from the subsequent layer's ones, eliminating the need to store activations for backpropagation. This alleviates the biggest memory bottleneck and enables very deep (theoretically infinitely deep) 3D architectures. On the BraTS challenge dataset, we demonstrate substantial memory savings. We further show that the freed memory can be used for processing the whole field-of-view (FOV) instead of patches. Increasing network depth led to higher segmentation accuracy while growing the memory footprint only by a very small fraction, thanks to the partially reversible architecture.
OCID-Ref: A 3D Robotic Dataset with Embodied Language for Clutter Scene Grounding
Mar 13, 2021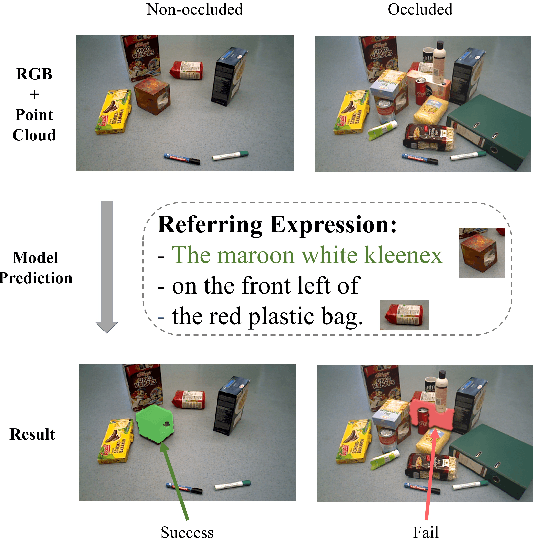

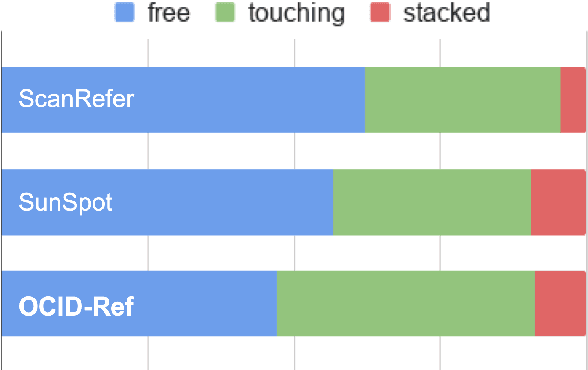

To effectively apply robots in working environments and assist humans, it is essential to develop and evaluate how visual grounding (VG) can affect machine performance on occluded objects. However, current VG works are limited in working environments, such as offices and warehouses, where objects are usually occluded due to space utilization issues. In our work, we propose a novel OCID-Ref dataset featuring a referring expression segmentation task with referring expressions of occluded objects. OCID-Ref consists of 305,694 referring expressions from 2,300 scenes with providing RGB image and point cloud inputs. To resolve challenging occlusion issues, we argue that it's crucial to take advantage of both 2D and 3D signals to resolve challenging occlusion issues. Our experimental results demonstrate the effectiveness of aggregating 2D and 3D signals but referring to occluded objects still remains challenging for the modern visual grounding systems. OCID-Ref is publicly available at https://github.com/lluma/OCID-Ref
CONFIG: Controllable Neural Face Image Generation
May 06, 2020
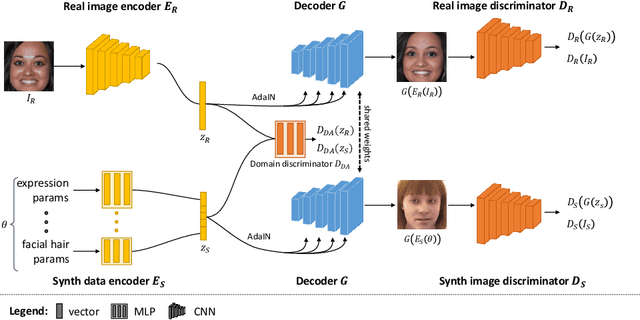


Our ability to sample realistic natural images, particularly faces, has advanced by leaps and bounds in recent years, yet our ability to exert fine-tuned control over the generative process has lagged behind. If this new technology is to find practical uses, we need to achieve a level of control over generative networks which, without sacrificing realism, is on par with that seen in computer graphics and character animation. To this end we propose ConfigNet, a neural face model that allows for controlling individual aspects of output images in semantically meaningful ways and that is a significant step on the path towards finely-controllable neural rendering. ConfigNet is trained on real face images as well as synthetic face renders. Our novel method uses synthetic data to factorize the latent space into elements that correspond to the inputs of a traditional rendering pipeline, separating aspects such as head pose, facial expression, hair style, illumination, and many others which are very hard to annotate in real data. The real images, which are presented to the network without labels, extend the variety of the generated images and encourage realism. Finally, we propose an evaluation criterion using an attribute detection network combined with a user study and demonstrate state-of-the-art individual control over attributes in the output images.
Learning Discriminative Multilevel Structured Dictionaries for Supervised Image Classification
Feb 28, 2018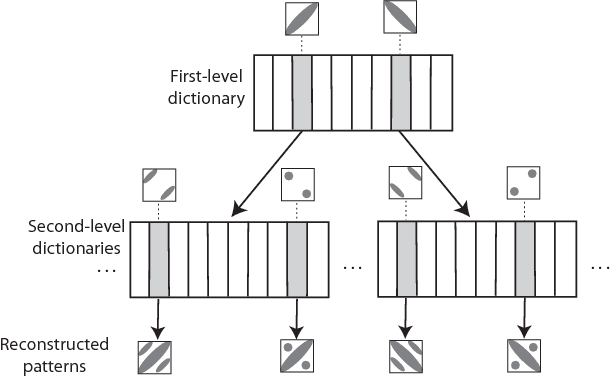


Sparse representations using overcomplete dictionaries have proved to be a powerful tool in many signal processing applications such as denoising, super-resolution, inpainting, compression or classification. The sparsity of the representation very much depends on how well the dictionary is adapted to the data at hand. In this paper, we propose a method for learning structured multilevel dictionaries with discriminative constraints to make them well suited for the supervised pixelwise classification of images. A multilevel tree-structured discriminative dictionary is learnt for each class, with a learning objective concerning the reconstruction errors of the image patches around the pixels over each class-representative dictionary. After the initial assignment of the class labels to image pixels based on their sparse representations over the learnt dictionaries, the final classification is achieved by smoothing the label image with a graph cut method and an erosion method. Applied to a common set of texture images, our supervised classification method shows competitive results with the state of the art.
Continuous control of an underground loader using deep reinforcement learning
Mar 01, 2021
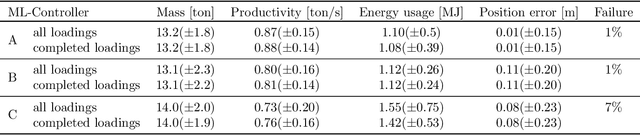

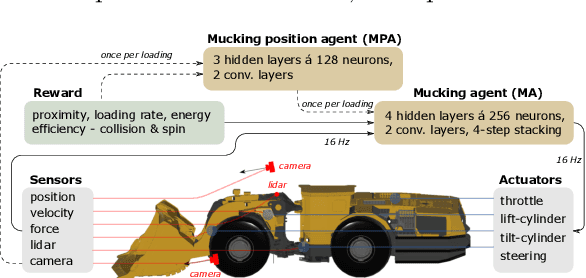
Reinforcement learning control of an underground loader is investigated in simulated environment, using a multi-agent deep neural network approach. At the start of each loading cycle, one agent selects the dig position from a depth camera image of the pile of fragmented rock. A second agent is responsible for continuous control of the vehicle, with the goal of filling the bucket at the selected loading point, while avoiding collisions, getting stuck, or losing ground traction. It relies on motion and force sensors, as well as on camera and lidar. Using a soft actor-critic algorithm the agents learn policies for efficient bucket filling over many subsequent loading cycles, with clear ability to adapt to the changing environment. The best results, on average 75% of the max capacity, are obtained when including a penalty for energy usage in the reward.
Verisimilar Image Synthesis for Accurate Detection and Recognition of Texts in Scenes
Sep 26, 2018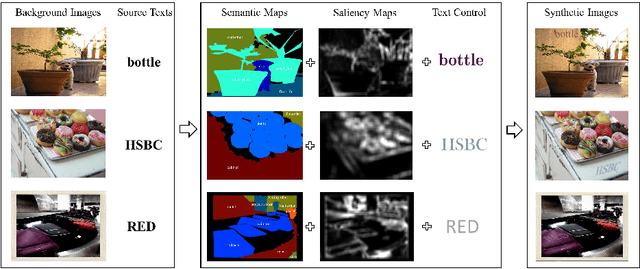
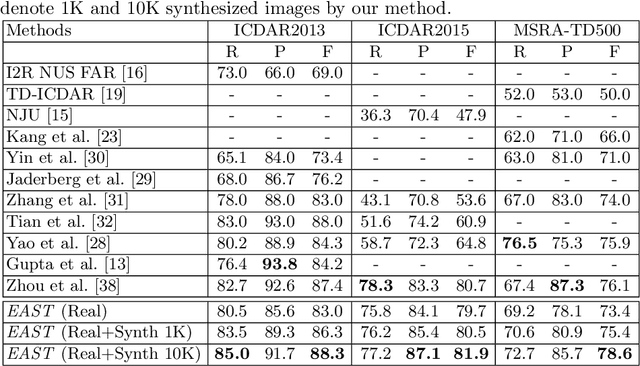

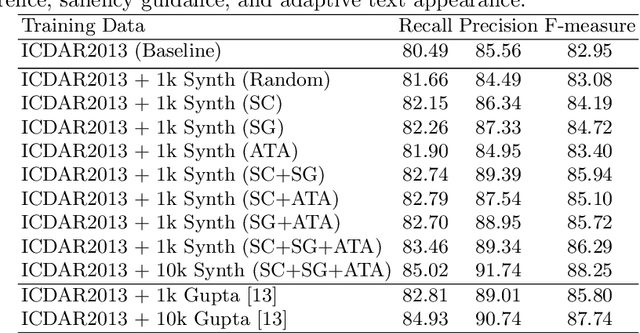
The requirement of large amounts of annotated images has become one grand challenge while training deep neural network models for various visual detection and recognition tasks. This paper presents a novel image synthesis technique that aims to generate a large amount of annotated scene text images for training accurate and robust scene text detection and recognition models. The proposed technique consists of three innovative designs. First, it realizes "semantic coherent" synthesis by embedding texts at semantically sensible regions within the background image, where the semantic coherence is achieved by leveraging the semantic annotations of objects and image regions that have been created in the prior semantic segmentation research. Second, it exploits visual saliency to determine the embedding locations within each semantic sensible region, which coincides with the fact that texts are often placed around homogeneous regions for better visibility in scenes. Third, it designs an adaptive text appearance model that determines the color and brightness of embedded texts by learning from the feature of real scene text images adaptively. The proposed technique has been evaluated over five public datasets and the experiments show its superior performance in training accurate and robust scene text detection and recognition models.
Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks
Apr 18, 2021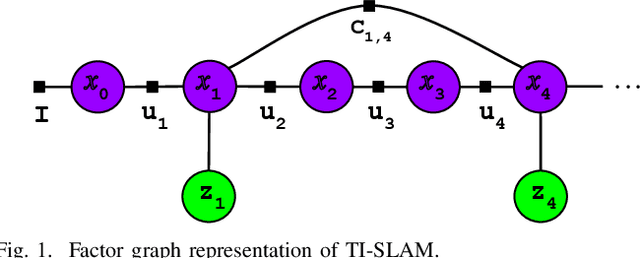
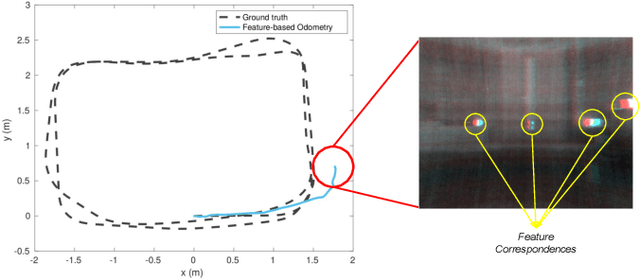
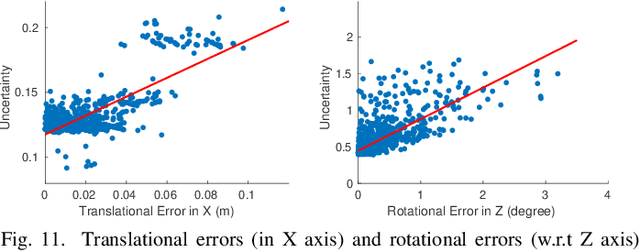
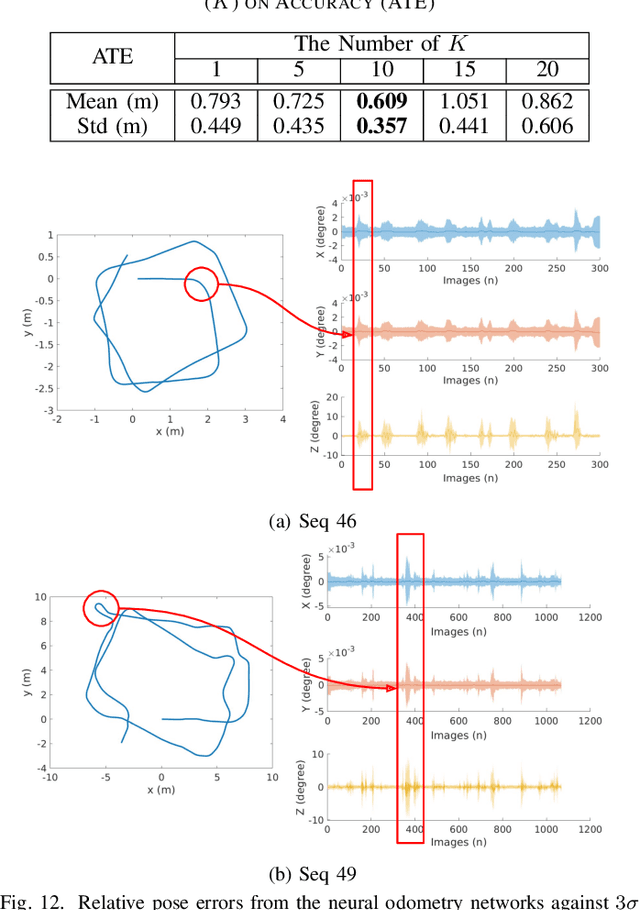
Simultaneous Localization and Mapping (SLAM) system typically employ vision-based sensors to observe the surrounding environment. However, the performance of such systems highly depends on the ambient illumination conditions. In scenarios with adverse visibility or in the presence of airborne particulates (e.g. smoke, dust, etc.), alternative modalities such as those based on thermal imaging and inertial sensors are more promising. In this paper, we propose the first complete thermal-inertial SLAM system which combines neural abstraction in the SLAM front end with robust pose graph optimization in the SLAM back end. We model the sensor abstraction in the front end by employing probabilistic deep learning parameterized by Mixture Density Networks (MDN). Our key strategies to successfully model this encoding from thermal imagery are the usage of normalized 14-bit radiometric data, the incorporation of hallucinated visual (RGB) features, and the inclusion of feature selection to estimate the MDN parameters. To enable a full SLAM system, we also design an efficient global image descriptor which is able to detect loop closures from thermal embedding vectors. We performed extensive experiments and analysis using three datasets, namely self-collected ground robot and handheld data taken in indoor environment, and one public dataset (SubT-tunnel) collected in underground tunnel. Finally, we demonstrate that an accurate thermal-inertial SLAM system can be realized in conditions of both benign and adverse visibility.
Deep image mining for diabetic retinopathy screening
Apr 28, 2017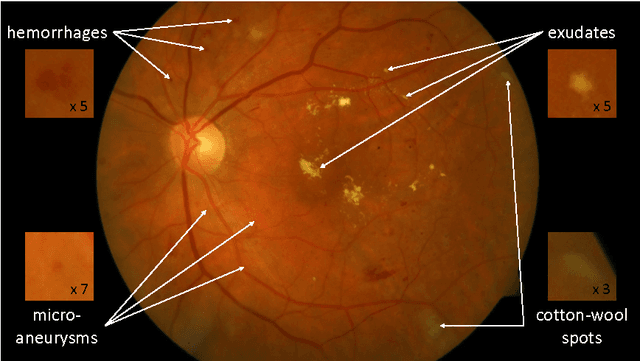
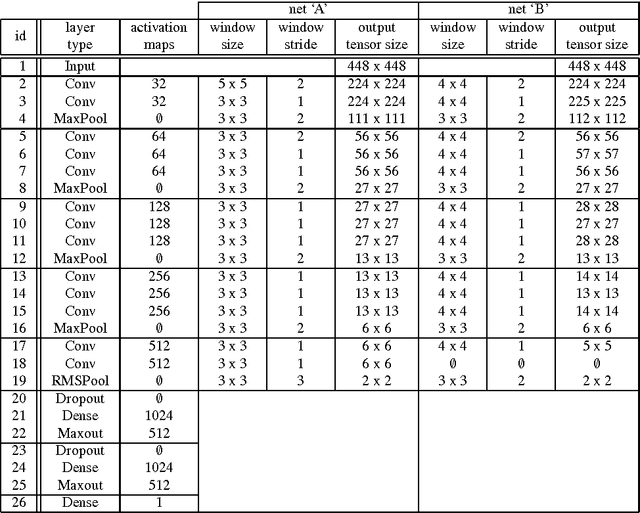
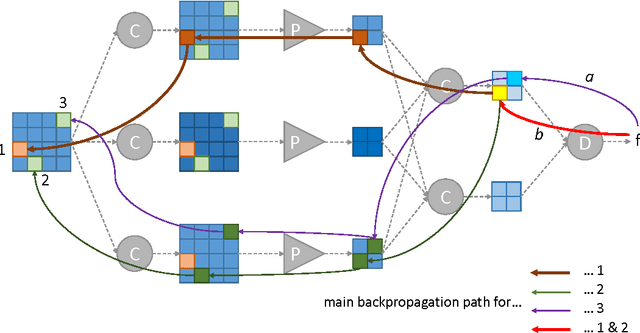
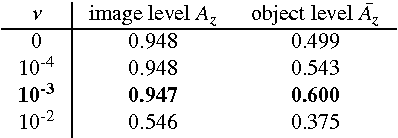
Deep learning is quickly becoming the leading methodology for medical image analysis. Given a large medical archive, where each image is associated with a diagnosis, efficient pathology detectors or classifiers can be trained with virtually no expert knowledge about the target pathologies. However, deep learning algorithms, including the popular ConvNets, are black boxes: little is known about the local patterns analyzed by ConvNets to make a decision at the image level. A solution is proposed in this paper to create heatmaps showing which pixels in images play a role in the image-level predictions. In other words, a ConvNet trained for image-level classification can be used to detect lesions as well. A generalization of the backpropagation method is proposed in order to train ConvNets that produce high-quality heatmaps. The proposed solution is applied to diabetic retinopathy (DR) screening in a dataset of almost 90,000 fundus photographs from the 2015 Kaggle Diabetic Retinopathy competition and a private dataset of almost 110,000 photographs (e-ophtha). For the task of detecting referable DR, very good detection performance was achieved: $A_z = 0.954$ in Kaggle's dataset and $A_z = 0.949$ in e-ophtha. Performance was also evaluated at the image level and at the lesion level in the DiaretDB1 dataset, where four types of lesions are manually segmented: microaneurysms, hemorrhages, exudates and cotton-wool spots. The proposed detector outperforms recent algorithms trained to detect those lesions specifically, as well as competing heatmap generation algorithms for ConvNets. This detector is part of the Messidor system for mobile eye pathology screening. Because it does not rely on expert knowledge or manual segmentation for detecting relevant patterns, the proposed solution is a promising image mining tool, which has the potential to discover new biomarkers in images.
* Accepted for publication in Medical Image Analysis
Few Shot Learning Framework to Reduce Inter-observer Variability in Medical Images
Aug 07, 2020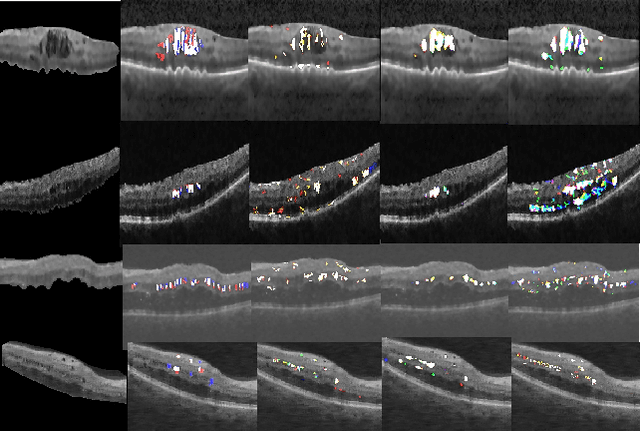
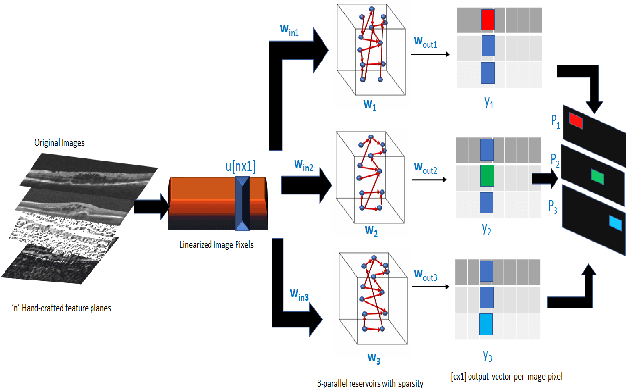
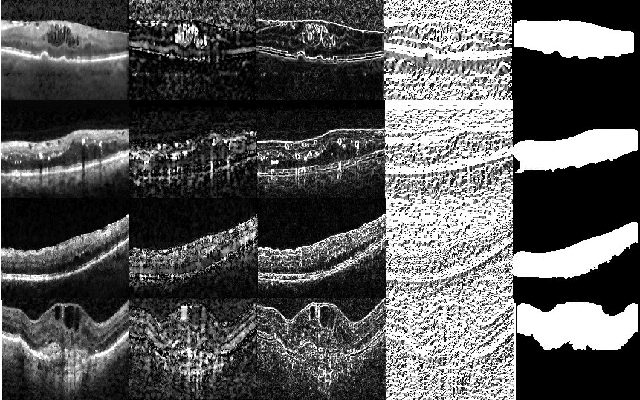
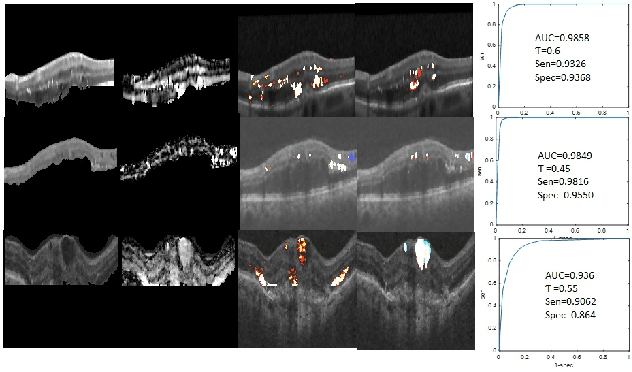
Most computer aided pathology detection systems rely on large volumes of quality annotated data to aid diagnostics and follow up procedures. However, quality assuring large volumes of annotated medical image data can be subjective and expensive. In this work we present a novel standardization framework that implements three few-shot learning (FSL) models that can be iteratively trained by atmost 5 images per 3D stack to generate multiple regional proposals (RPs) per test image. These FSL models include a novel parallel echo state network (ParESN) framework and an augmented U-net model. Additionally, we propose a novel target label selection algorithm (TLSA) that measures relative agreeability between RPs and the manually annotated target labels to detect the "best" quality annotation per image. Using the FSL models, our system achieves 0.28-0.64 Dice coefficient across vendor image stacks for intra-retinal cyst segmentation. Additionally, the TLSA is capable of automatically classifying high quality target labels from their noisy counterparts for 60-97% of the images while ensuring manual supervision on remaining images. Also, the proposed framework with ParESN model minimizes manual annotation checking to 12-28% of the total number of images. The TLSA metrics further provide confidence scores for the automated annotation quality assurance. Thus, the proposed framework is flexible to extensions for quality image annotation curation of other image stacks as well.
* 8 pages, 8 figures, 4 tables
Convolutional neural network stacking for medical image segmentation in CT scans
Jul 23, 2019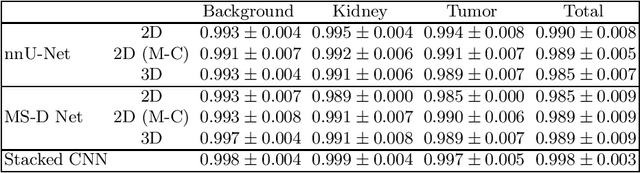
Computed tomography (CT) data poses many challenges to medical image segmentation based on convolutional neural networks(CNNs). The main challenges in handling CT scans with CNN are the scale of data (large range of Hounsfield Units) and the processing of the slices. In this paper, we consider a framework, which addresses these demands regarding the data pre-processing, the data augmentation, and the CNN architecture itself. For this purpose, we present a data preprocessing and an augmentation method tailored to CT data. We evaluate and compare different input dimensionalities and two different CNN architectures. One of the architectures is a modified U-Net and the other a modified Mixed-Scale Dense Network (MS-D Net). Thus, we compare dilated convolutions for parallel multi-scale processing to the U-Net approach with traditional scaling operations based on the different input dimensionalities. Finally, we merge a set of 3D modified MS-D Nets and a set of 2D modified U-Nets as a stacked CNN-model to combine the different strengths of both model.