 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Conglomerate of Multiple OCR Table Detection and Extraction
Oct 16, 2020
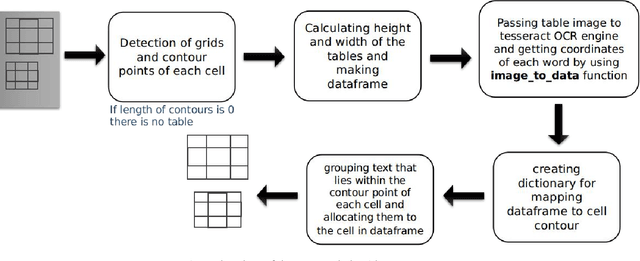
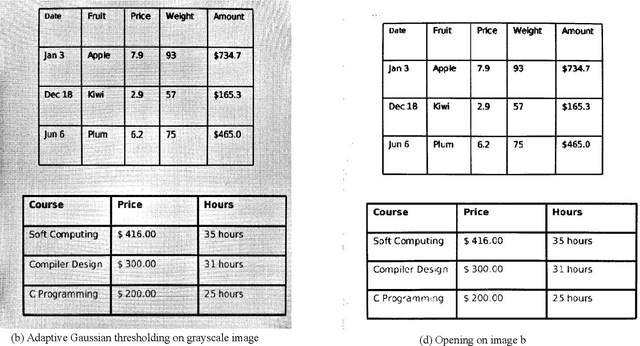
Information representation as tables are compact and concise method that eases searching, indexing, and storage requirements. Extracting and cloning tables from parsable documents is easier and widely used, however industry still faces challenge in detecting and extracting tables from OCR documents or images. This paper proposes an algorithm that detects and extracts multiple tables from OCR document. The algorithm uses a combination of image processing techniques, text recognition and procedural coding to identify distinct tables in same image and map the text to appropriate corresponding cell in dataframe which can be stored as Comma-separated values, Database, Excel and multiple other usable formats.
Automating Visual Blockage Classification of Culverts with Deep Learning
Apr 21, 2021
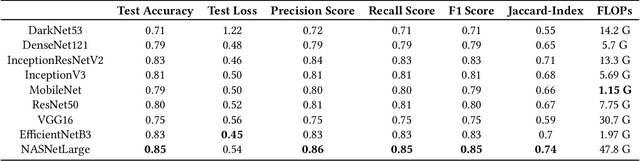
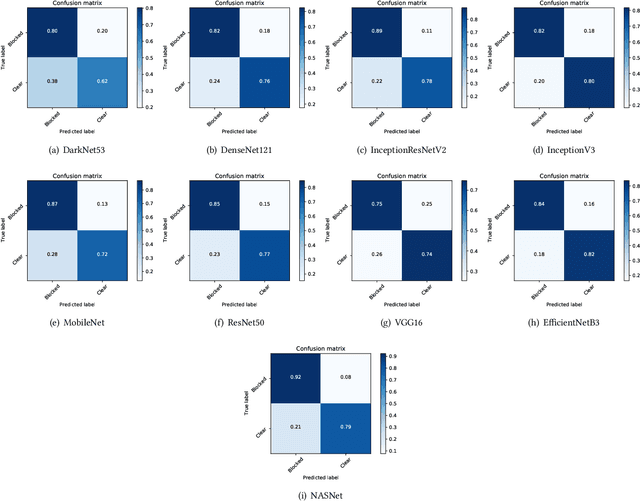
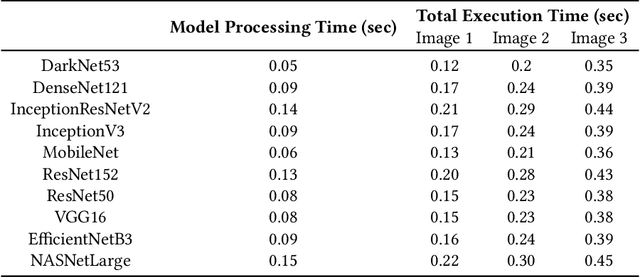
Blockage of culverts by transported debris materials is reported as main contributor in originating urban flash floods. Conventional modelling approaches had no success in addressing the problem largely because of unavailability of peak floods hydraulic data and highly non-linear behaviour of debris at culvert. This article explores a new dimension to investigate the issue by proposing the use of Intelligent Video Analytic (IVA) algorithms for extracting blockage related information. Potential of using existing Convolutional Neural Network (CNN) algorithms (i.e., DarkNet53, DenseNet121, InceptionResNetV2, InceptionV3, MobileNet, ResNet50, VGG16, EfficientNetB3, NASNet) is investigated over a custom collected blockage dataset (i.e., Images of Culvert Openings and Blockage (ICOB)) to predict the blockage in a given image. Models were evaluated based on their performance on test dataset (i.e., accuracy, loss, precision, recall, F1-score, Jaccard-Index), Floating Point Operations Per Second (FLOPs) and response times to process a single test instance. From the results, NASNet was reported most efficient in classifying the blockage with the accuracy of 85\%; however, EfficientNetB3 was recommended for the hardware implementation because of its improved response time with accuracy comparable to NASNet (i.e., 83\%). False Negative (FN) instances, False Positive (FP) instances and CNN layers activation suggested that background noise and oversimplified labelling criteria were two contributing factors in degraded performance of existing CNN algorithms.
Systematic Analysis and Removal of Circular Artifacts for StyleGAN
Mar 04, 2021
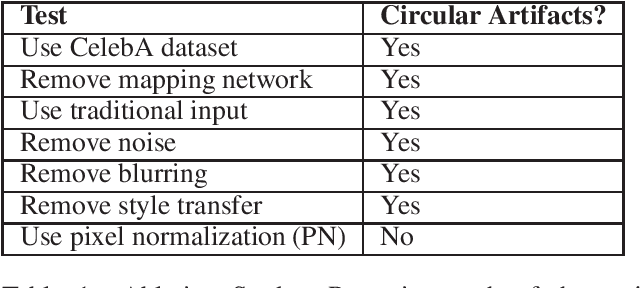
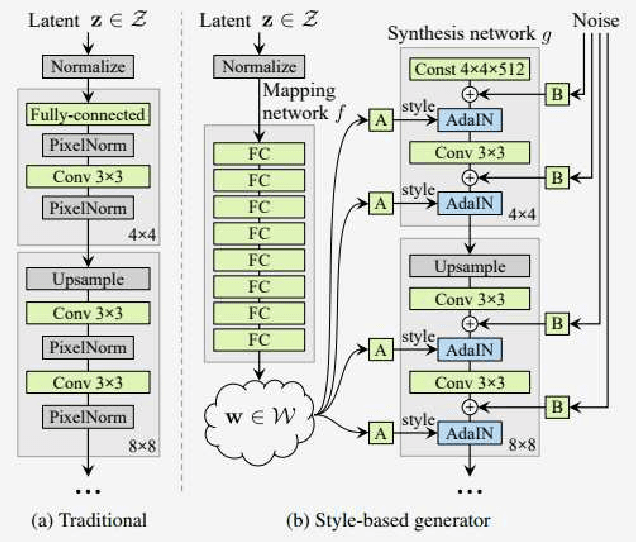

StyleGAN is one of the state-of-the-art image generators which is well-known for synthesizing high-resolution and hyper-realistic face images. Though images generated by vanilla StyleGAN model are visually appealing, they sometimes contain prominent circular artifacts which severely degrade the quality of generated images. In this work, we provide a systematic investigation on how those circular artifacts are formed by studying the functionalities of different stages of vanilla StyleGAN architecture, with both mechanism analysis and extensive experiments. The key modules of vanilla StyleGAN that promote such undesired artifacts are highlighted. Our investigation also explains why the artifacts are usually circular, relatively small and rarely split into 2 or more parts. Besides, we propose a simple yet effective solution to remove the prominent circular artifacts for vanilla StyleGAN, by applying a novel pixel-instance normalization (PIN) layer.
UPANets: Learning from the Universal Pixel Attention Networks
Mar 15, 2021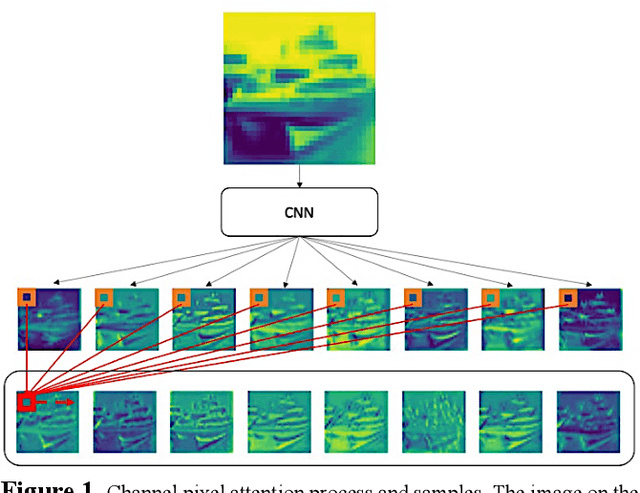
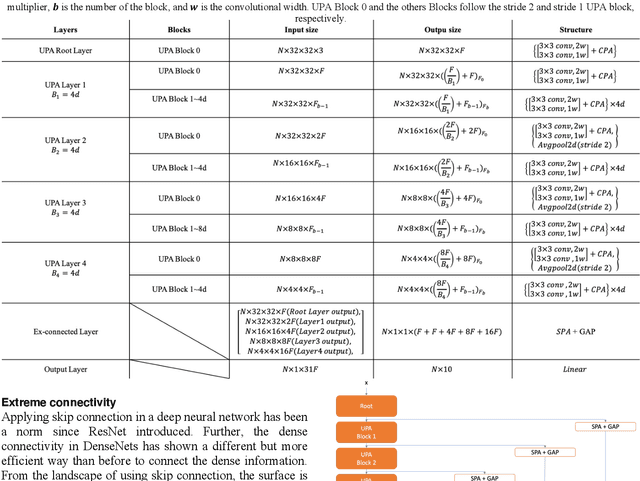
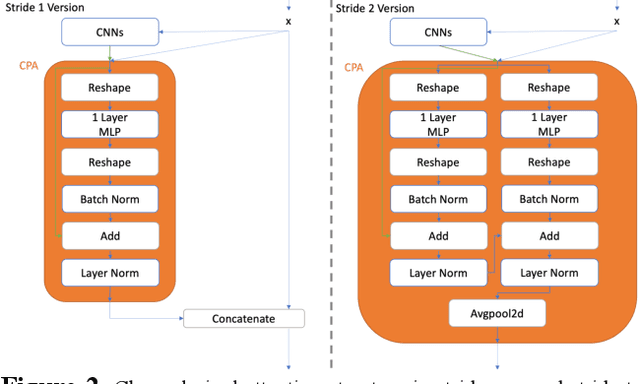
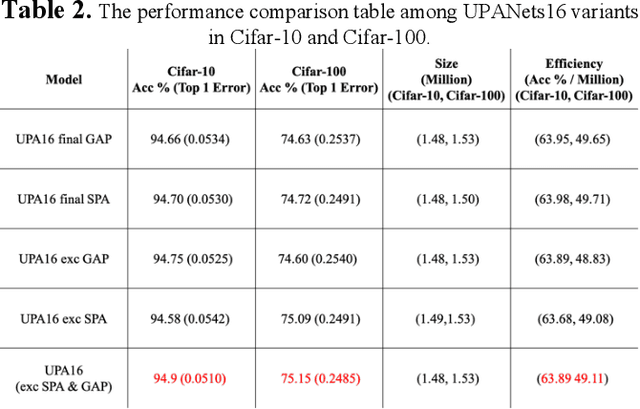
Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.
Astronomical image reconstruction with convolutional neural networks
Jun 07, 2017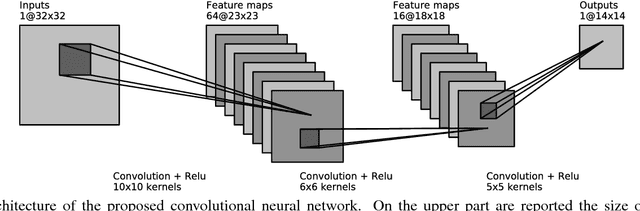
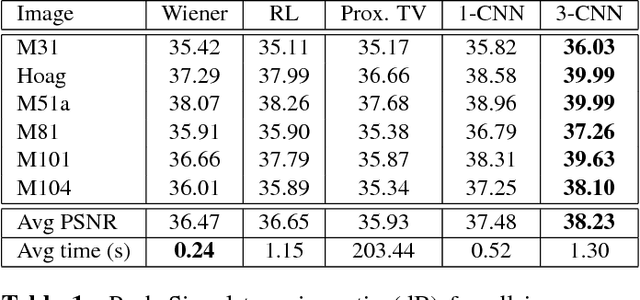


State of the art methods in astronomical image reconstruction rely on the resolution of a regularized or constrained optimization problem. Solving this problem can be computationally intensive and usually leads to a quadratic or at least superlinear complexity w.r.t. the number of pixels in the image. We investigate in this work the use of convolutional neural networks for image reconstruction in astronomy. With neural networks, the computationally intensive tasks is the training step, but the prediction step has a fixed complexity per pixel, i.e. a linear complexity. Numerical experiments show that our approach is both computationally efficient and competitive with other state of the art methods in addition to being interpretable.
OR-Net: Pointwise Relational Inference for Data Completion under Partial Observation
May 05, 2021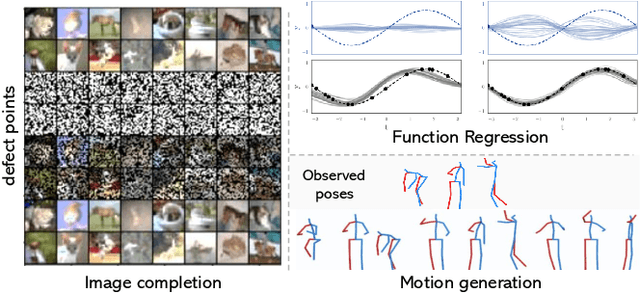
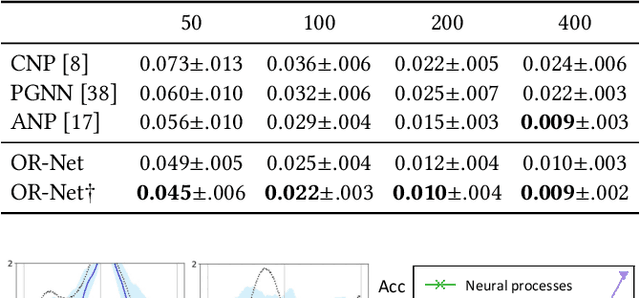
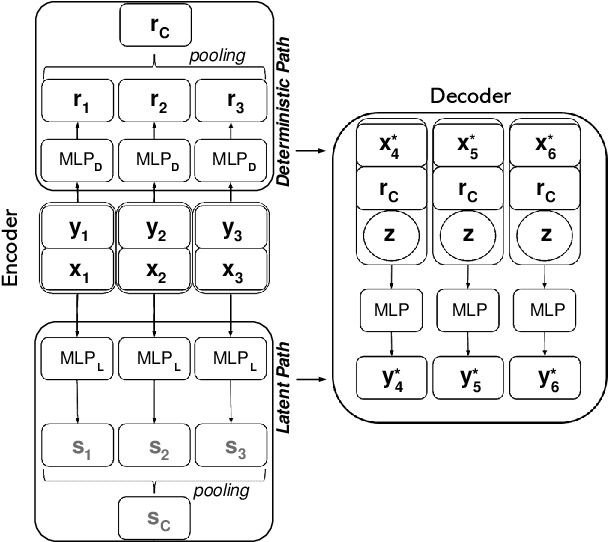
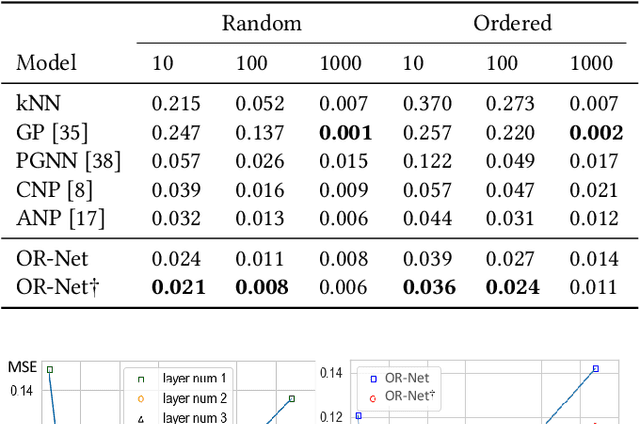
Contemporary data-driven methods are typically fed with full supervision on large-scale datasets which limits their applicability. However, in the actual systems with limitations such as measurement error and data acquisition problems, people usually obtain incomplete data. Although data completion has attracted wide attention, the underlying data pattern and relativity are still under-developed. Currently, the family of latent variable models allows learning deep latent variables over observed variables by fitting the marginal distribution. As far as we know, current methods fail to perceive the data relativity under partial observation. Aiming at modeling incomplete data, this work uses relational inference to fill in the incomplete data. Specifically, we expect to approximate the real joint distribution over the partial observation and latent variables, thus infer the unseen targets respectively. To this end, we propose Omni-Relational Network (OR-Net) to model the pointwise relativity in two aspects: (i) On one hand, the inner relationship is built among the context points in the partial observation; (ii) On the other hand, the unseen targets are inferred by learning the cross-relationship with the observed data points. It is further discovered that the proposed method can be generalized to different scenarios regardless of whether the physical structure can be observed or not. It is demonstrated that the proposed OR-Net can be well generalized for data completion tasks of various modalities, including function regression, image completion on MNIST and CelebA datasets, and also sequential motion generation conditioned on the observed poses.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018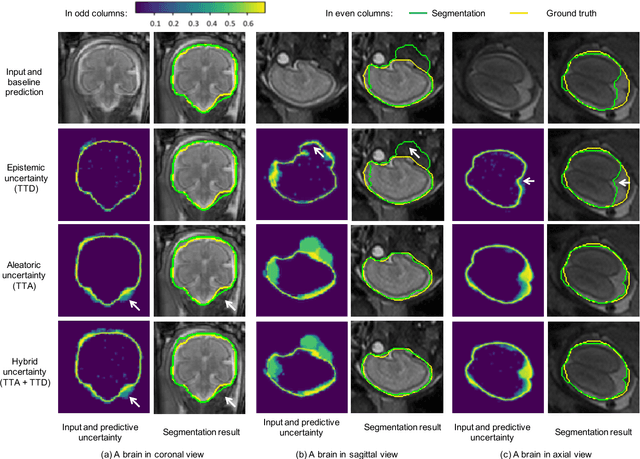
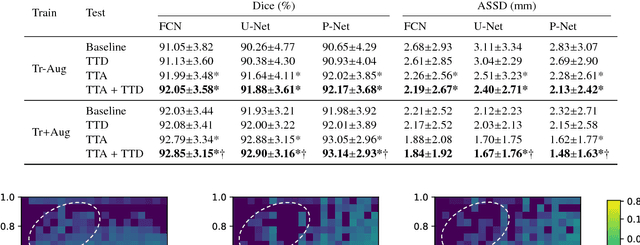
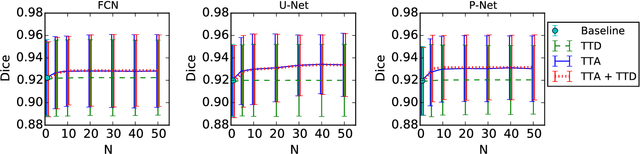
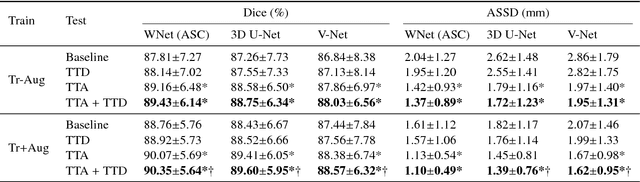
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.
A Parameterised Quantum Circuit Approach to Point Set Matching
Feb 12, 2021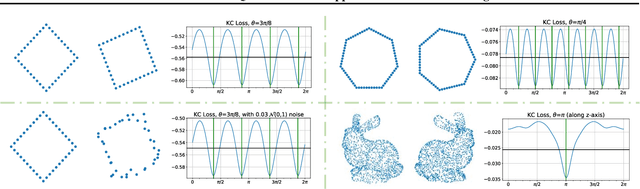
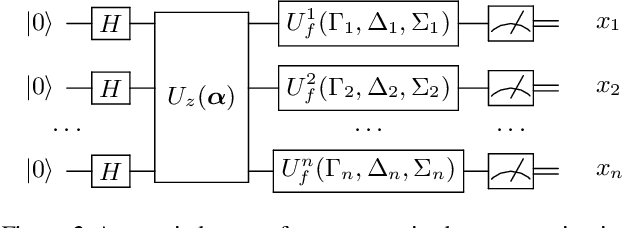
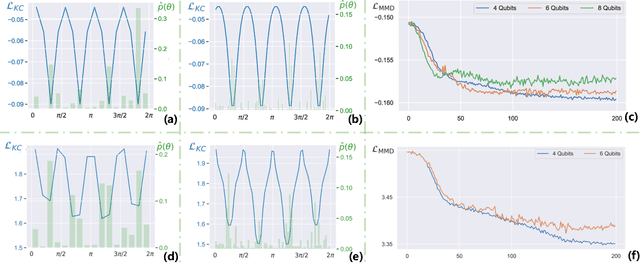
Point set registration is one of the challenging tasks in areas such as pattern recognition, computer vision and image processing. Efficient performance of this task has been a hot topic of research due to its widespread applications. We propose a parameterised quantum circuit learning approach to point set matching problem. The proposed method benefits from a kernel-based quantum generative model that: 1) is able to find all possible optimal matching solution angles, 2) is potentially able to show quantum learning supremacy, and 3) benefits from kernel-embedding techniques and integral probability metrics for the definition of a powerful loss function. Moreover, the theoretical framework has been backed up by satisfactory preliminary and proof of concept experimental results.
Scientific image rendering for space scenes with the SurRender software
Oct 02, 2018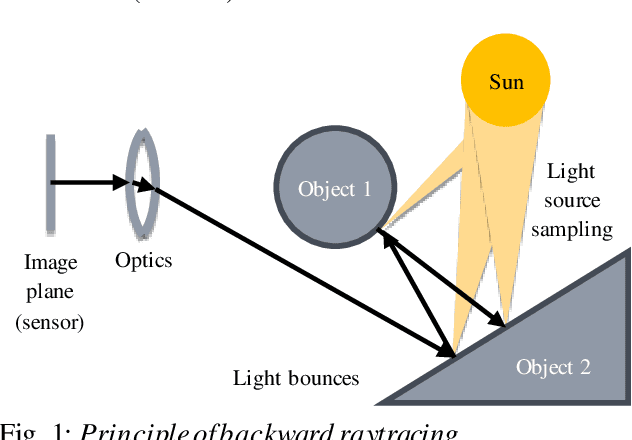



Spacecraft autonomy can be enhanced by vision-based navigation (VBN) techniques. Applications range from manoeuvers around Solar System objects and landing on planetary surfaces, to in-orbit servicing or space debris removal. The development and validation of VBN algorithms relies on the availability of physically accurate relevant images. Yet archival data from past missions can rarely serve this purpose and acquiring new data is often costly. The SurRender software is an image simulator that addresses the challenges of realistic image rendering, with high representativeness for space scenes. Images are rendered by raytracing, which implements the physical principles of geometrical light propagation, in physical units. A macroscopic instrument model and scene objects reflectance functions are used. SurRender is specially optimized for space scenes, with huge distances between objects and scenes up to Solar System size. Raytracing conveniently tackles some important effects for VBN algorithms: image quality, eclipses, secondary illumination, subpixel limb imaging, etc. A simulation is easily setup (in MATLAB, Python, and more) by specifying the position of the bodies (camera, Sun, planets, satellites) over time, 3D shapes and material surface properties. SurRender comes with its own modelling tool enabling to go beyond existing models for shapes, materials and sensors (projection, temporal sampling, electronics, etc.). It is natively designed to simulate different kinds of sensors (visible, LIDAR, etc.). Tools are available for manipulating huge datasets to store albedo maps and digital elevation models, or for procedural (fractal) texturing that generates high-quality images for a large range of observing distances (from millions of km to touchdown). We illustrate SurRender performances with a selection of case studies, placing particular emphasis on a 900-km Moon flyby simulation.
Contrastive Representation Learning for Whole Brain Cytoarchitectonic Mapping in Histological Human Brain Sections
Nov 25, 2020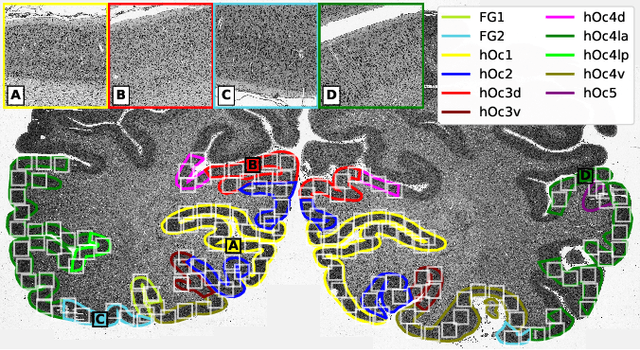
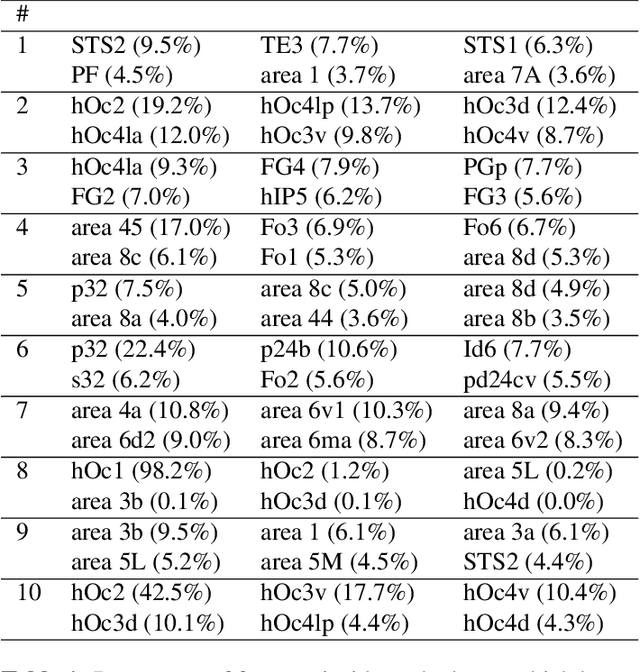
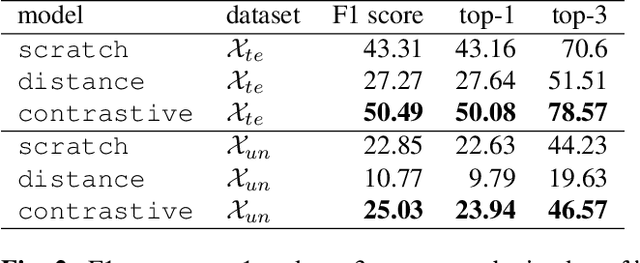
Cytoarchitectonic maps provide microstructural reference parcellations of the brain, describing its organization in terms of the spatial arrangement of neuronal cell bodies as measured from histological tissue sections. Recent work provided the first automatic segmentations of cytoarchitectonic areas in the visual system using Convolutional Neural Networks. We aim to extend this approach to become applicable to a wider range of brain areas, envisioning a solution for mapping the complete human brain. Inspired by recent success in image classification, we propose a contrastive learning objective for encoding microscopic image patches into robust microstructural features, which are efficient for cytoarchitectonic area classification. We show that a model pre-trained using this learning task outperforms a model trained from scratch, as well as a model pre-trained on a recently proposed auxiliary task. We perform cluster analysis in the feature space to show that the learned representations form anatomically meaningful groups.