 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Autonomous Robotic Mapping of Fragile Geologic Features
May 04, 2021

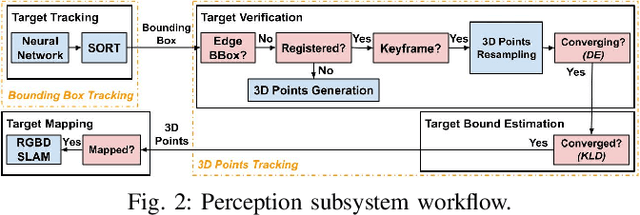
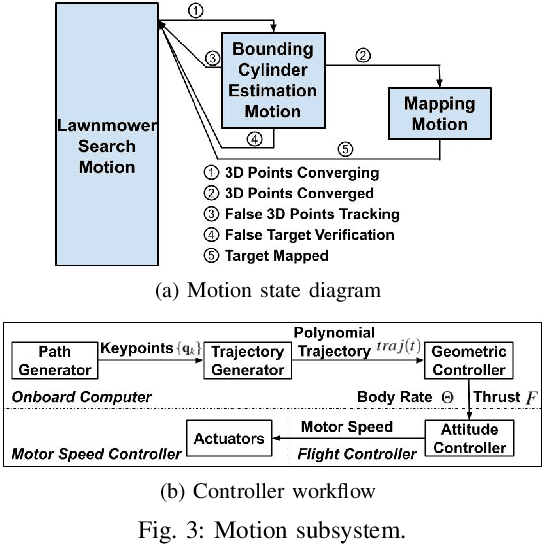
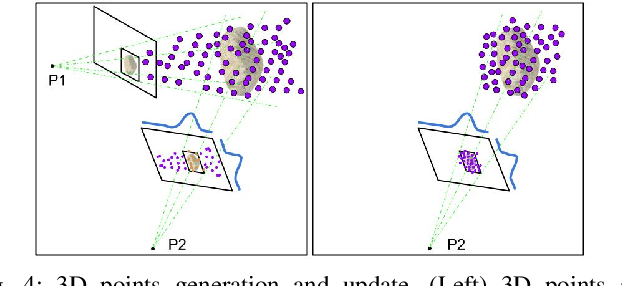
Robotic mapping is useful in scientific applications that involve surveying unstructured environments. This paper presents a target-oriented mapping system for sparsely distributed geologic surface features, such as precariously balanced rocks (PBRs), whose geometric fragility parameters can provide valuable information on earthquake shaking history and landscape development for a region. With this geomorphology problem as the test domain, we demonstrate a pipeline for detecting, localizing, and precisely mapping fragile geologic features distributed on a landscape. To do so, we first carry out a lawn-mower search pattern in the survey region from a high elevation using an Unpiloted Aerial Vehicle (UAV). Once a potential PBR target is detected by a deep neural network, we track the bounding box in the image frames using a real-time tracking algorithm. The location and occupancy of the target in world coordinates are estimated using a sampling-based filtering algorithm, where a set of 3D points are re-sampled after weighting by the tracked bounding boxes from different camera perspectives. The converged 3D points provide a prior on 3D bounding shape of a target, which is used for UAV path planning to closely and completely map the target with Simultaneous Localization and Mapping (SLAM). After target mapping, the UAV resumes the lawn-mower search pattern to find the next target. We introduce techniques to make the target mapping robust to false positive and missing detection from the neural network. Our target-oriented mapping system has the advantages of reducing map storage and emphasizing complete visible surface features on specified targets.
Image Anomalies: a Review and Synthesis of Detection Methods
Aug 07, 2018
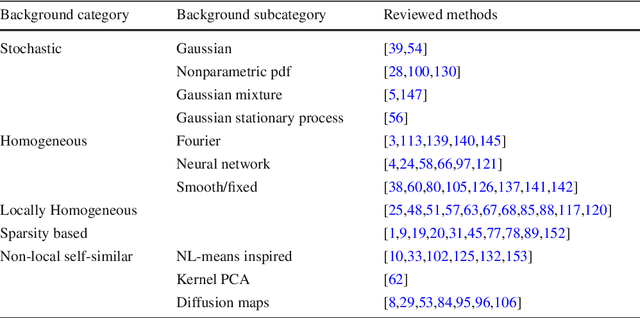

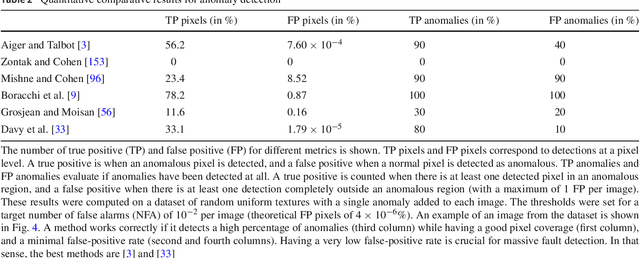
We review the broad variety of methods that have been proposed for anomaly detection in images. Most methods found in the literature have in mind a particular application. Yet we show that the methods can be classified mainly by the structural assumption they make on the "normal" image. Five different structural assumptions emerge. Our analysis leads us to reformulate the best representative algorithms by attaching to them an a contrario detection that controls the number of false positives and thus derive universal detection thresholds. By combining the most general structural assumptions expressing the background's normality with the best proposed statistical detection tools, we end up proposing generic algorithms that seem to generalize or reconcile most methods. We compare the six best representatives of our proposed classes of algorithms on anomalous images taken from classic papers on the subject, and on a synthetic database. Our conclusion is that it is possible to perform automatic anomaly detection on a single image.
Comparative Evaluation of 3D and 2D Deep Learning Techniques for Semantic Segmentation in CT Scans
Jan 19, 2021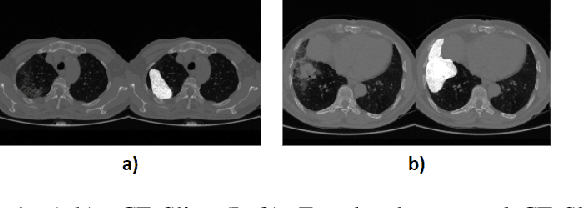

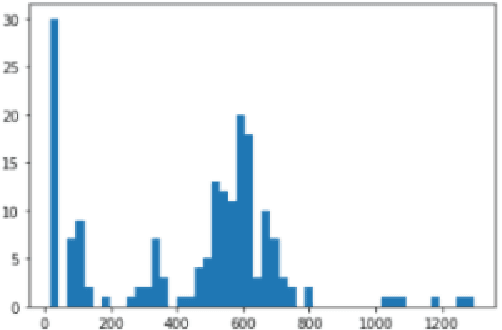
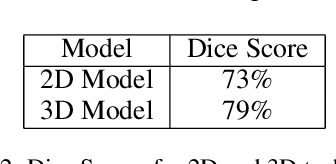
Image segmentation plays a pivotal role in several medical-imaging applications by assisting the segmentation of the regions of interest. Deep learning-based approaches have been widely adopted for semantic segmentation of medical data. In recent years, in addition to 2D deep learning architectures, 3D architectures have been employed as the predictive algorithms for 3D medical image data. In this paper, we propose a 3D stack-based deep learning technique for segmenting manifestations of consolidation and ground-glass opacities in 3D Computed Tomography (CT) scans. We also present a comparison based on the segmentation results, the contextual information retained, and the inference time between this 3D technique and a traditional 2D deep learning technique. We also define the area-plot, which represents the peculiar pattern observed in the slice-wise areas of the pathology regions predicted by these deep learning models. In our exhaustive evaluation, 3D technique performs better than the 2D technique for the segmentation of CT scans. We get dice scores of 79% and 73% for the 3D and the 2D techniques respectively. The 3D technique results in a 5X reduction in the inference time compared to the 2D technique. Results also show that the area-plots predicted by the 3D model are more similar to the ground truth than those predicted by the 2D model. We also show how increasing the amount of contextual information retained during the training can improve the 3D model's performance.
Vessel-CAPTCHA: an efficient learning framework for vessel annotation and segmentation
Jan 27, 2021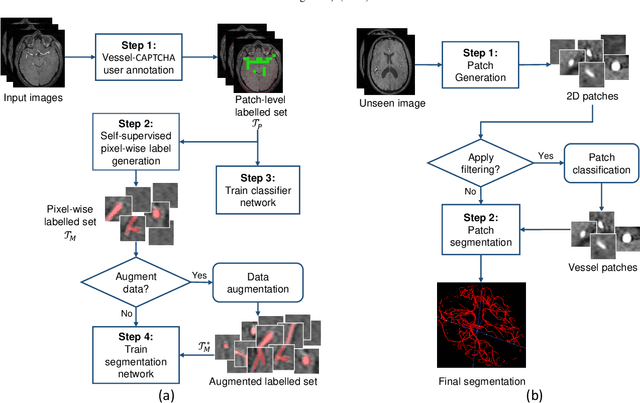
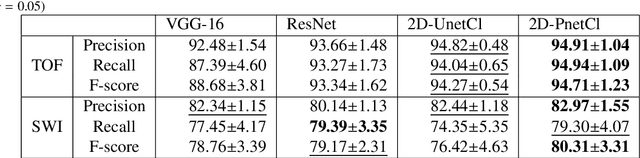
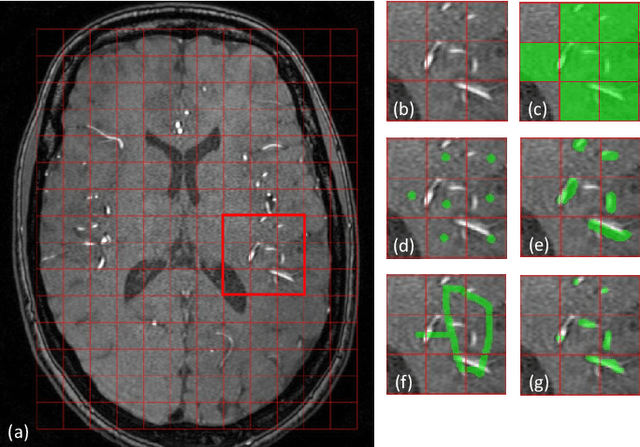

The use of deep learning techniques for 3D brain vessel image segmentation has not been as widespread as for the segmentation of other organs and tissues. This can be explained by two factors. First, deep learning techniques tend to show poor performances at the segmentation of relatively small objects compared to the size of the full image. Second, due to the complexity of vascular trees and the small size of vessels, it is challenging to obtain the amount of annotated training data typically needed by deep learning methods. To address these problems, we propose a novel annotation-efficient deep learning vessel segmentation framework. The framework avoids pixel-wise annotations, only requiring patch-level labels to discriminate between vessel and non-vessel 2D patches in the training set, in a setup similar to the CAPTCHAs used to differentiate humans from bots in web applications. The user-provided annotations are used for two tasks: 1) to automatically generate pixel-wise labels for vessels and background in each patch, which are used to train a segmentation network, and 2) to train a classifier network. The classifier network allows to generate additional weak patch labels, further reducing the annotation burden, and it acts as a noise filter for poor quality images. We use this framework for the segmentation of the cerebrovascular tree in Time-of-Flight angiography (TOF) and Susceptibility-Weighted Images (SWI). The results show that the framework achieves state-of-the-art accuracy, while reducing the annotation time by up to 80% with respect to learning-based segmentation methods using pixel-wise labels for training
Approximating Instance-Dependent Noise via Instance-Confidence Embedding
Mar 25, 2021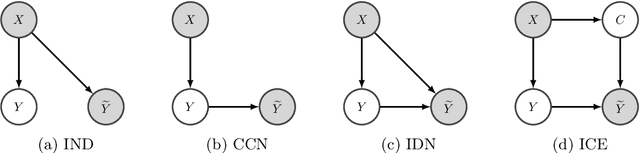


Label noise in multiclass classification is a major obstacle to the deployment of learning systems. However, unlike the widely used class-conditional noise (CCN) assumption that the noisy label is independent of the input feature given the true label, label noise in real-world datasets can be aleatory and heavily dependent on individual instances. In this work, we investigate the instance-dependent noise (IDN) model and propose an efficient approximation of IDN to capture the instance-specific label corruption. Concretely, noting the fact that most columns of the IDN transition matrix have only limited influence on the class-posterior estimation, we propose a variational approximation that uses a single-scalar confidence parameter. To cope with the situation where the mapping from the instance to its confidence value could vary significantly for two adjacent instances, we suggest using instance embedding that assigns a trainable parameter to each instance. The resulting instance-confidence embedding (ICE) method not only performs well under label noise but also can effectively detect ambiguous or mislabeled instances. We validate its utility on various image and text classification tasks.
Image Labeling by Assignment
Mar 16, 2016



We introduce a novel geometric approach to the image labeling problem. Abstracting from specific labeling applications, a general objective function is defined on a manifold of stochastic matrices, whose elements assign prior data that are given in any metric space, to observed image measurements. The corresponding Riemannian gradient flow entails a set of replicator equations, one for each data point, that are spatially coupled by geometric averaging on the manifold. Starting from uniform assignments at the barycenter as natural initialization, the flow terminates at some global maximum, each of which corresponds to an image labeling that uniquely assigns the prior data. Our geometric variational approach constitutes a smooth non-convex inner approximation of the general image labeling problem, implemented with sparse interior-point numerics in terms of parallel multiplicative updates that converge efficiently.
Mutual Graph Learning for Camouflaged Object Detection
Apr 03, 2021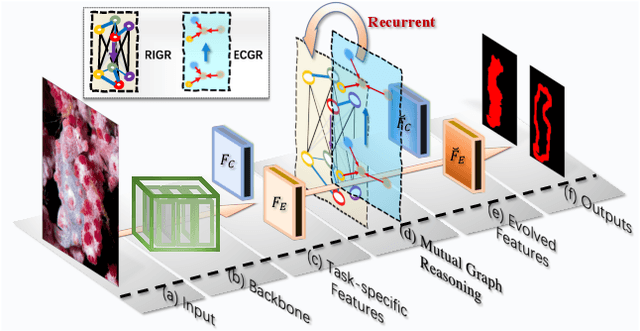
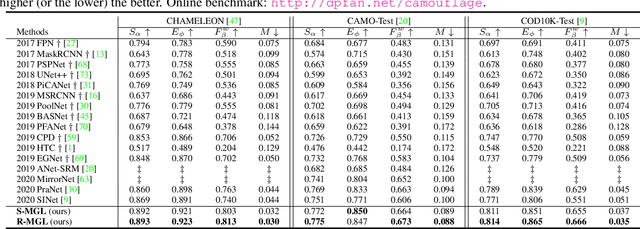
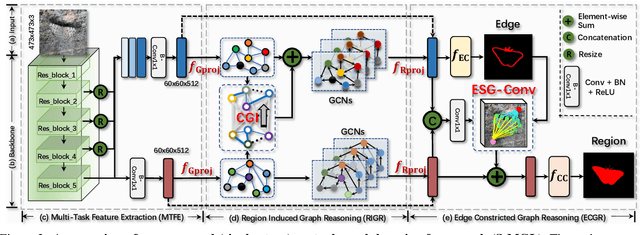

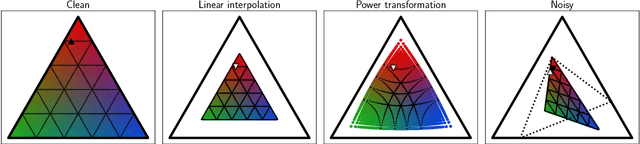
Automatically detecting/segmenting object(s) that blend in with their surroundings is difficult for current models. A major challenge is that the intrinsic similarities between such foreground objects and background surroundings make the features extracted by deep model indistinguishable. To overcome this challenge, an ideal model should be able to seek valuable, extra clues from the given scene and incorporate them into a joint learning framework for representation co-enhancement. With this inspiration, we design a novel Mutual Graph Learning (MGL) model, which generalizes the idea of conventional mutual learning from regular grids to the graph domain. Specifically, MGL decouples an image into two task-specific feature maps -- one for roughly locating the target and the other for accurately capturing its boundary details -- and fully exploits the mutual benefits by recurrently reasoning their high-order relations through graphs. Importantly, in contrast to most mutual learning approaches that use a shared function to model all between-task interactions, MGL is equipped with typed functions for handling different complementary relations to maximize information interactions. Experiments on challenging datasets, including CHAMELEON, CAMO and COD10K, demonstrate the effectiveness of our MGL with superior performance to existing state-of-the-art methods.
Deep Tiling: Texture Tile Synthesis Using a Deep Learning Approach
Mar 14, 2021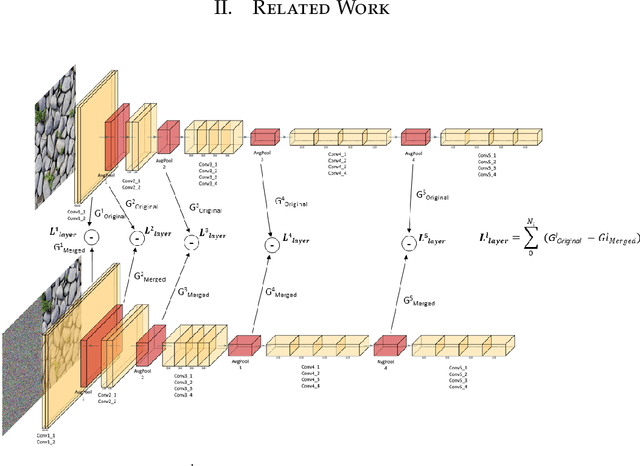



Texturing is a fundamental process in computer graphics. Texture is leveraged to enhance the visualization outcome for a 3D scene. In many cases a texture image cannot cover a large 3D model surface because of its small resolution. Conventional techniques like repeating, mirror repeating or clamp to edge do not yield visually acceptable results. Deep learning based texture synthesis has proven to be very effective in such cases. All deep texture synthesis methods trying to create larger resolution textures are limited in terms of GPU memory resources. In this paper, we propose a novel approach to example-based texture synthesis by using a robust deep learning process for creating tiles of arbitrary resolutions that resemble the structural components of an input texture. In this manner, our method is firstly much less memory limited owing to the fact that a new texture tile of small size is synthesized and merged with the original texture and secondly can easily produce missing parts of a large texture.
Discriminative Pattern Mining for Breast Cancer Histopathology Image Classification via Fully Convolutional Autoencoder
Feb 27, 2019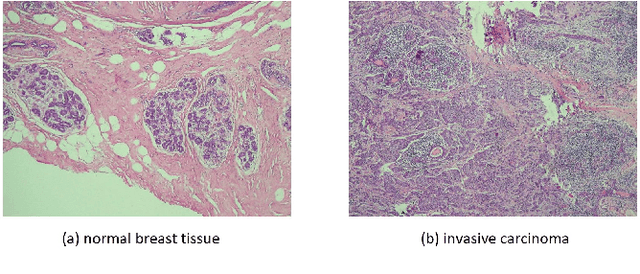

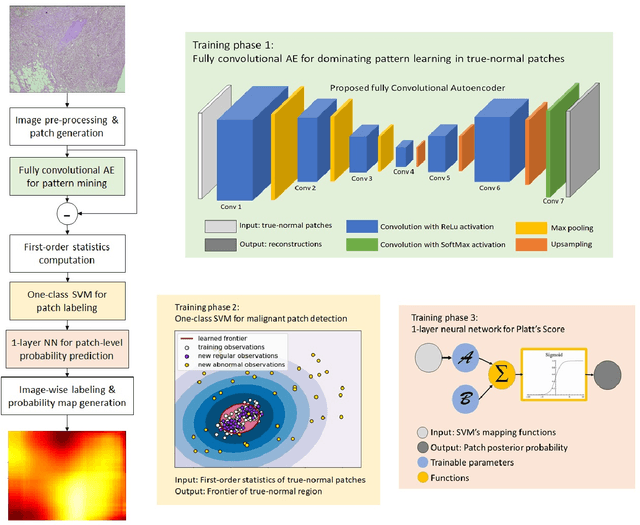
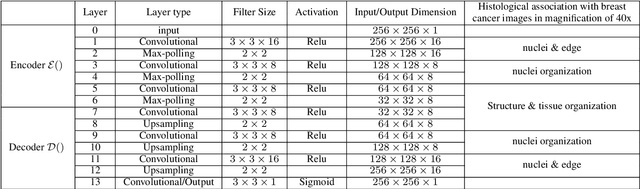
Accurate diagnosis of breast cancer in histopathology images is challenging due to the heterogeneity of cancer cell growth as well as of a variety of benign breast tissue proliferative lesions. In this paper, we propose a practical and self-interpretable invasive cancer diagnosis solution. With minimum annotation information, the proposed method mines contrast patterns between normal and malignant images in unsupervised manner and generates a probability map of abnormalities to verify its reasoning. Particularly, a fully convolutional autoencoder is used to learn the dominant structural patterns among normal image patches. Patches that do not share the characteristics of this normal population are detected and analyzed by one-class support vector machine and 1-layer neural network. We apply the proposed method to a public breast cancer image set. Our results, in consultation with a senior pathologist, demonstrate that the proposed method outperforms existing methods. The obtained probability map could benefit the pathology practice by providing visualized verification data and potentially leads to a better understanding of data-driven diagnosis solutions.
Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data
Jul 23, 2018
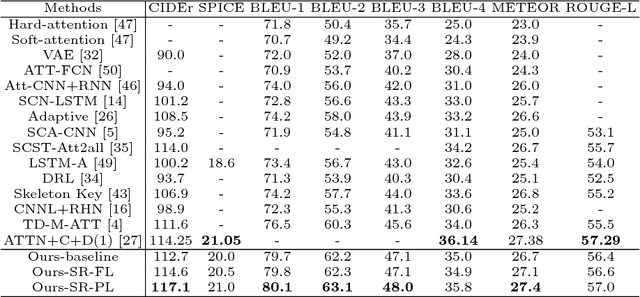
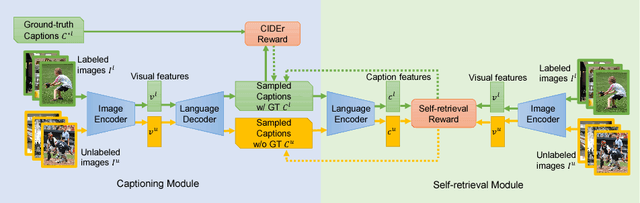
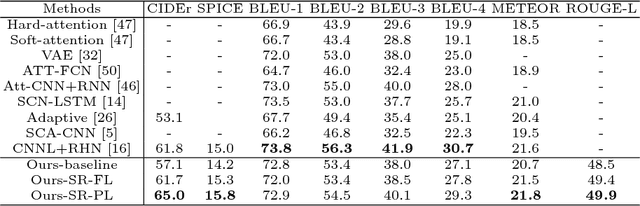
The aim of image captioning is to generate captions by machine to describe image contents. Despite many efforts, generating discriminative captions for images remains non-trivial. Most traditional approaches imitate the language structure patterns, thus tend to fall into a stereotype of replicating frequent phrases or sentences and neglect unique aspects of each image. In this work, we propose an image captioning framework with a self-retrieval module as training guidance, which encourages generating discriminative captions. It brings unique advantages: (1) the self-retrieval guidance can act as a metric and an evaluator of caption discriminativeness to assure the quality of generated captions. (2) The correspondence between generated captions and images are naturally incorporated in the generation process without human annotations, and hence our approach could utilize a large amount of unlabeled images to boost captioning performance with no additional laborious annotations. We demonstrate the effectiveness of the proposed retrieval-guided method on COCO and Flickr30k captioning datasets, and show its superior captioning performance with more discriminative captions.