 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
Jun 03, 2017

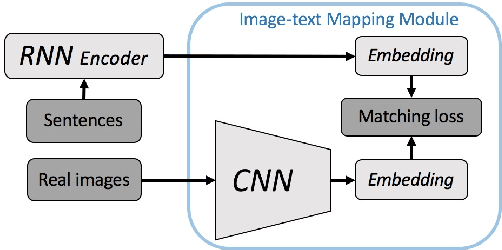
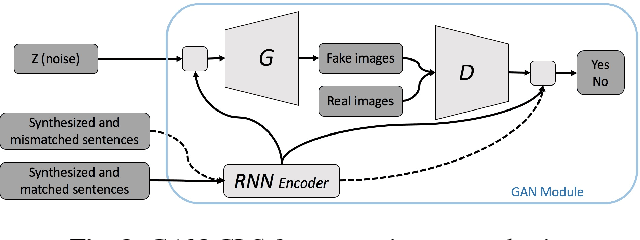
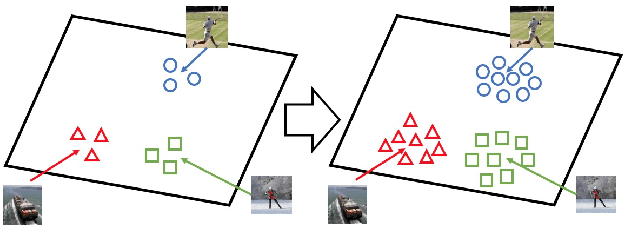
Translating information between text and image is a fundamental problem in artificial intelligence that connects natural language processing and computer vision. In the past few years, performance in image caption generation has seen significant improvement through the adoption of recurrent neural networks (RNN). Meanwhile, text-to-image generation begun to generate plausible images using datasets of specific categories like birds and flowers. We've even seen image generation from multi-category datasets such as the Microsoft Common Objects in Context (MSCOCO) through the use of generative adversarial networks (GANs). Synthesizing objects with a complex shape, however, is still challenging. For example, animals and humans have many degrees of freedom, which means that they can take on many complex shapes. We propose a new training method called Image-Text-Image (I2T2I) which integrates text-to-image and image-to-text (image captioning) synthesis to improve the performance of text-to-image synthesis. We demonstrate that %the capability of our method to understand the sentence descriptions, so as to I2T2I can generate better multi-categories images using MSCOCO than the state-of-the-art. We also demonstrate that I2T2I can achieve transfer learning by using a pre-trained image captioning module to generate human images on the MPII Human Pose
Fast digital refocusing and depth of field extended Fourier ptychography microscopy
May 06, 2021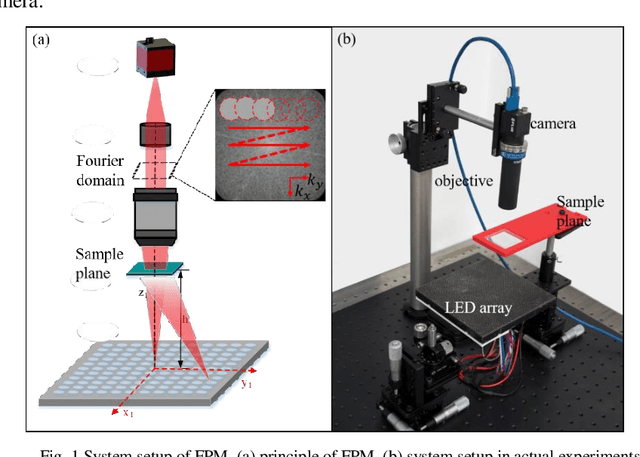
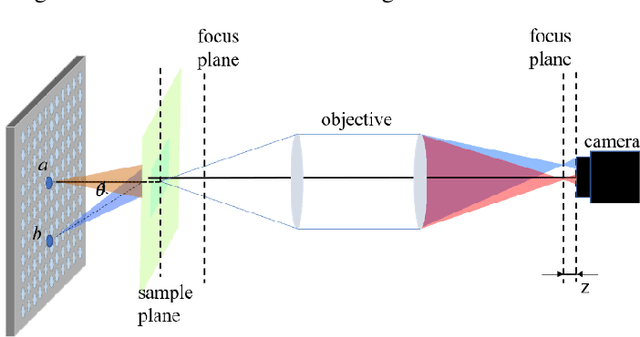
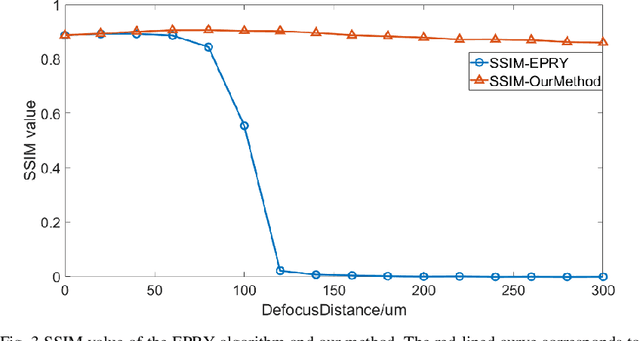

Fourier ptychography microscopy (FPM), sharing its roots with synthetic aperture technique and phase retrieval method, is a recently developed computational microscopic super-resolution technique. By turning on the light-emitting diode (LED) elements sequentially and acquiring the corresponding images that contain different spatial frequencies, FPM can achieve a wide field-of-view (FOV), high-spatial-resolution imaging, and phase recovery simultaneously. Conventional FPM assumes that the sample is sufficiently thin and strictly in focus. Nevertheless, even for a relatively thin sample, the non-planar distribution characteristics and the non-ideal position/posture of the sample will cause all or part of FOV to be defocused. In this paper, we proposed a fast digital refocusing and depth-of-field (DOF) extended FPM strategy by taking the advantages of image lateral shift caused by sample defocusing and varied-angle illuminations. The lateral shift amount is proportional to the defocus distance and the tangent of the illumination angle. Instead of searching the optimal defocus distance in optimization strategy, which is time-consuming, the defocus distance of each subregion of the sample can be precisely and quickly obtained by calculating the relative lateral shift amounts corresponding to different oblique illuminations. And then, the digital refocusing strategy rooting in the Fresnel propagator is integrated into the FPM framework to achieve the high-resolution and phase information reconstruction for each part of the sample, which means the DOF the FPM is effectively extended. The feasibility of the proposed method in fast digital refocusing and FOV extending is verified in the actual experiments with the USAF chart and biological samples.
MVPNet: Multi-View Point Regression Networks for 3D Object Reconstruction from A Single Image
Nov 23, 2018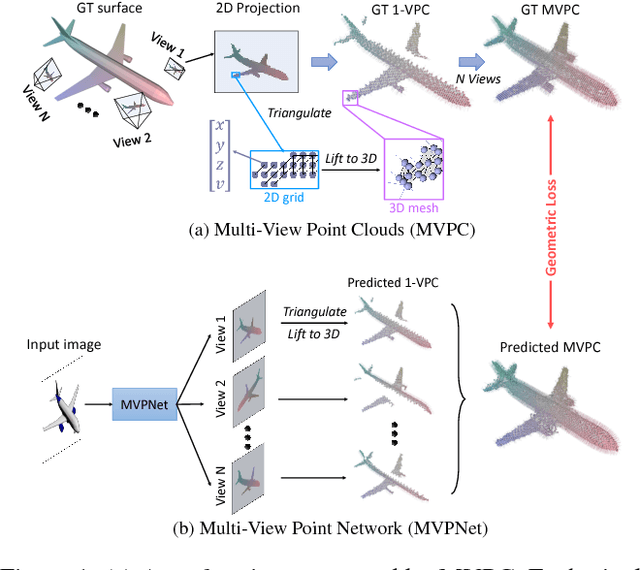
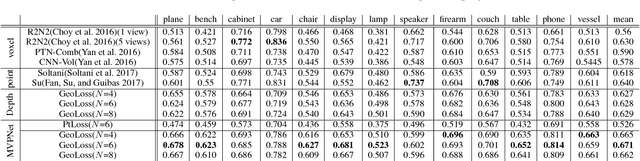

In this paper, we address the problem of reconstructing an object's surface from a single image using generative networks. First, we represent a 3D surface with an aggregation of dense point clouds from multiple views. Each point cloud is embedded in a regular 2D grid aligned on an image plane of a viewpoint, making the point cloud convolution-favored and ordered so as to fit into deep network architectures. The point clouds can be easily triangulated by exploiting connectivities of the 2D grids to form mesh-based surfaces. Second, we propose an encoder-decoder network that generates such kind of multiple view-dependent point clouds from a single image by regressing their 3D coordinates and visibilities. We also introduce a novel geometric loss that is able to interpret discrepancy over 3D surfaces as opposed to 2D projective planes, resorting to the surface discretization on the constructed meshes. We demonstrate that the multi-view point regression network outperforms state-of-the-art methods with a significant improvement on challenging datasets.
Learning Deep Similarity Models with Focus Ranking for Fabric Image Retrieval
Dec 29, 2017

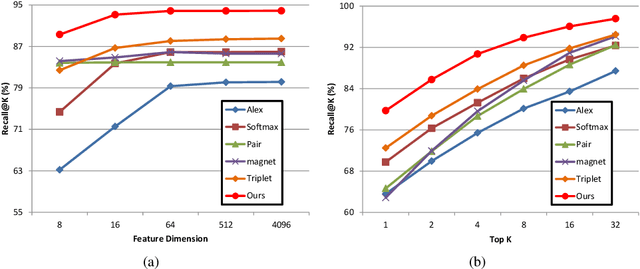
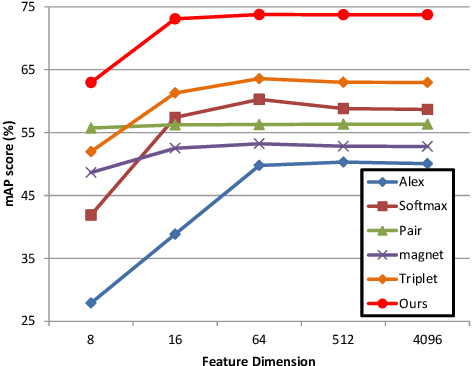
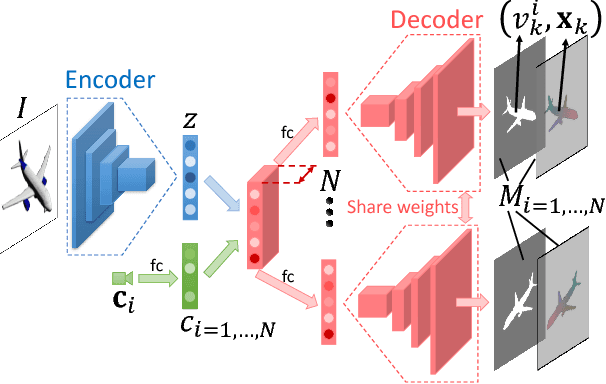
Fabric image retrieval is beneficial to many applications including clothing searching, online shopping and cloth modeling. Learning pairwise image similarity is of great importance to an image retrieval task. With the resurgence of Convolutional Neural Networks (CNNs), recent works have achieved significant progresses via deep representation learning with metric embedding, which drives similar examples close to each other in a feature space, and dissimilar ones apart from each other. In this paper, we propose a novel embedding method termed focus ranking that can be easily unified into a CNN for jointly learning image representations and metrics in the context of fine-grained fabric image retrieval. Focus ranking aims to rank similar examples higher than all dissimilar ones by penalizing ranking disorders via the minimization of the overall cost attributed to similar samples being ranked below dissimilar ones. At the training stage, training samples are organized into focus ranking units for efficient optimization. We build a large-scale fabric image retrieval dataset (FIRD) with about 25,000 images of 4,300 fabrics, and test the proposed model on the FIRD dataset. Experimental results show the superiority of the proposed model over existing metric embedding models.
Anti-Adversarially Manipulated Attributions for Weakly and Semi-Supervised Semantic Segmentation
Mar 16, 2021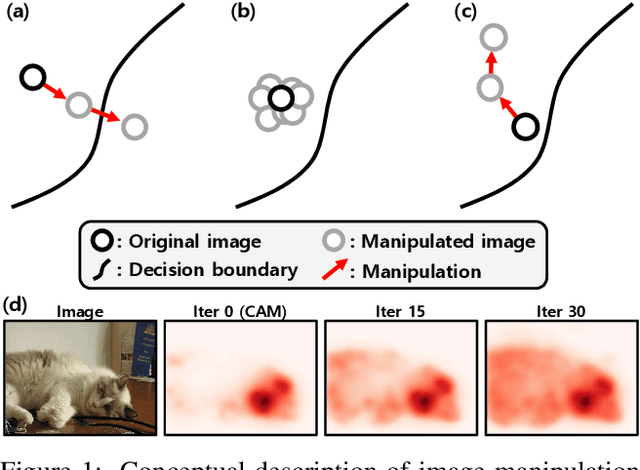
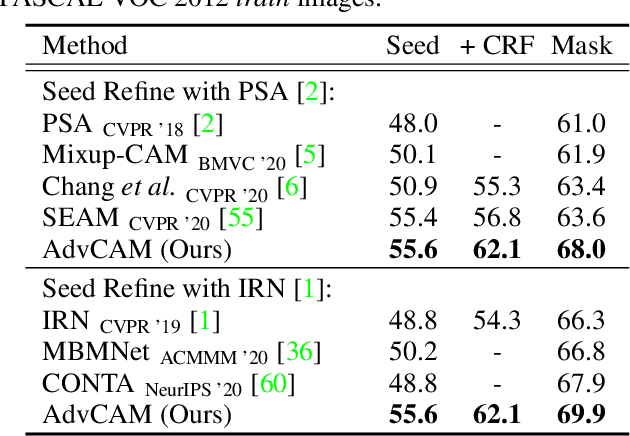
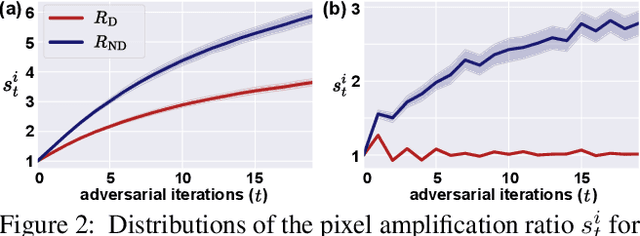
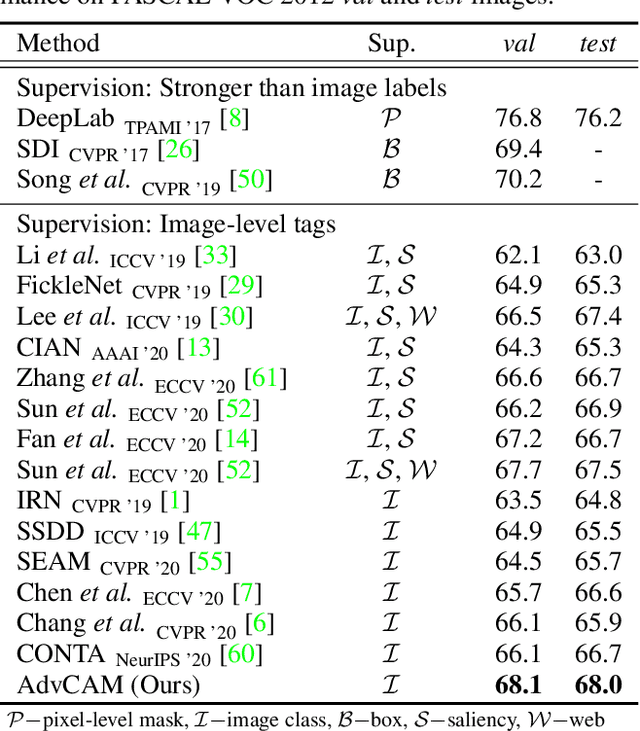
Weakly supervised semantic segmentation produces a pixel-level localization from a classifier, but it is likely to restrict its focus to a small discriminative region of the target object. AdvCAM is an attribution map of an image that is manipulated to increase the classification score. This manipulation is realized in an anti-adversarial manner, which perturbs the images along pixel gradients in the opposite direction from those used in an adversarial attack. It forces regions initially considered not to be discriminative to become involved in subsequent classifications, and produces attribution maps that successively identify more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and limits the attributions of the regions that already have high scores. On PASCAL VOC 2012 test images, we achieve mIoUs of 68.0 and 76.9 for weakly and semi-supervised semantic segmentation respectively, which represent a new state-of-the-art.
nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation
Sep 27, 2018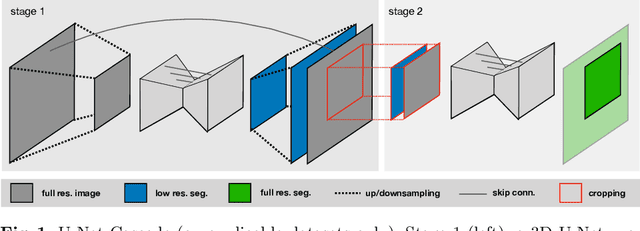
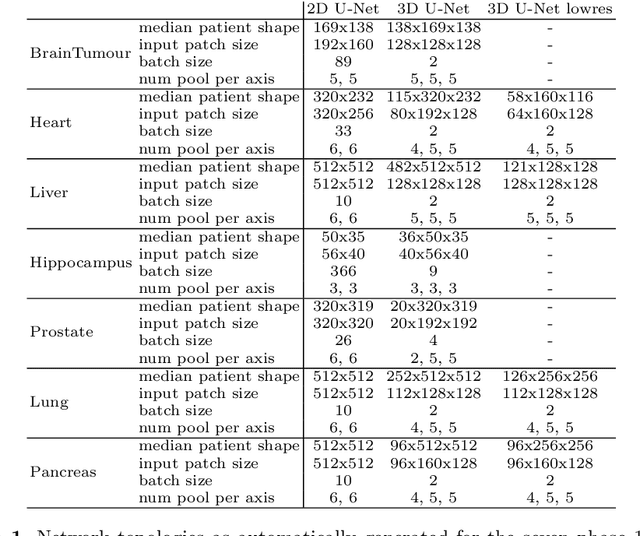
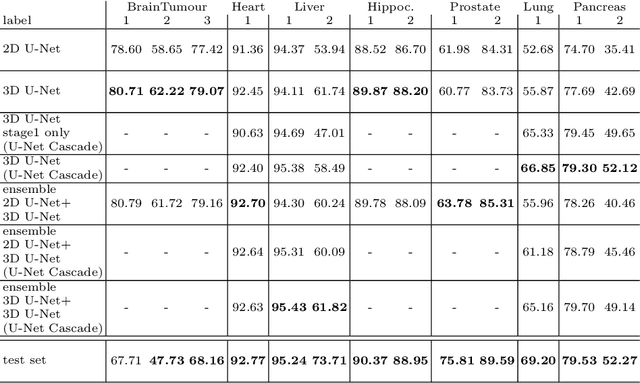
The U-Net was presented in 2015. With its straight-forward and successful architecture it quickly evolved to a commonly used benchmark in medical image segmentation. The adaptation of the U-Net to novel problems, however, comprises several degrees of freedom regarding the exact architecture, preprocessing, training and inference. These choices are not independent of each other and substantially impact the overall performance. The present paper introduces the nnU-Net ('no-new-Net'), which refers to a robust and self-adapting framework on the basis of 2D and 3D vanilla U-Nets. We argue the strong case for taking away superfluous bells and whistles of many proposed network designs and instead focus on the remaining aspects that make out the performance and generalizability of a method. We evaluate the nnU-Net in the context of the Medical Segmentation Decathlon challenge, which measures segmentation performance in ten disciplines comprising distinct entities, image modalities, image geometries and dataset sizes, with no manual adjustments between datasets allowed. At the time of manuscript submission, nnU-Net achieves the highest mean dice scores across all classes and seven phase 1 tasks (except class 1 in BrainTumour) in the online leaderboard of the challenge.
Artist, Style And Year Classification Using Face Recognition And Clustering With Convolutional Neural Networks
Dec 02, 2020
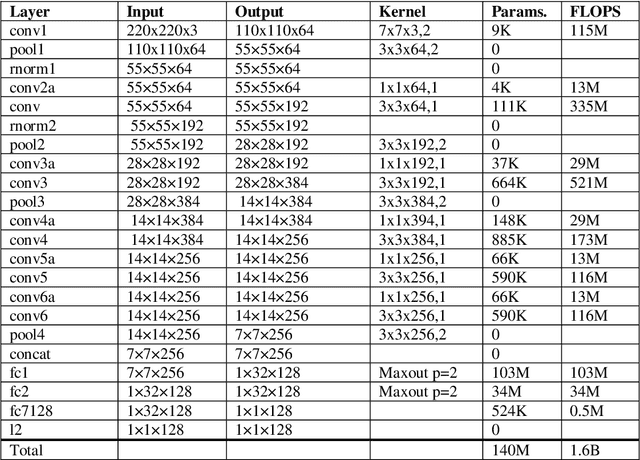
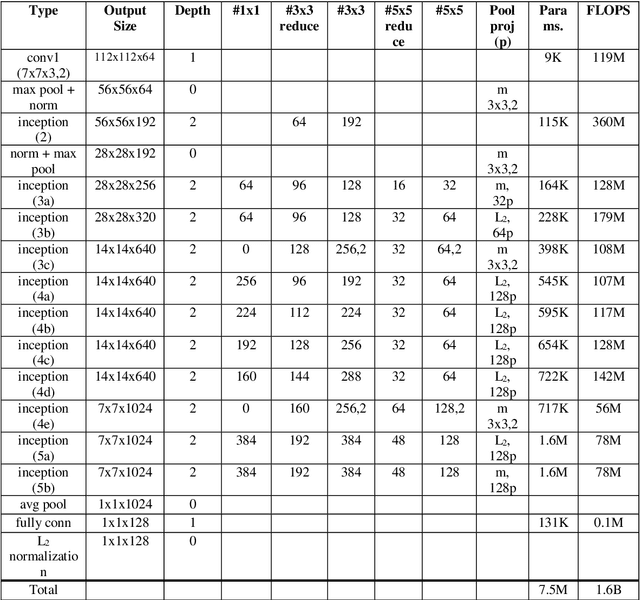

Artist, year and style classification of fine-art paintings are generally achieved using standard image classification methods, image segmentation, or more recently, convolutional neural networks (CNNs). This works aims to use newly developed face recognition methods such as FaceNet that use CNNs to cluster fine-art paintings using the extracted faces in the paintings, which are found abundantly. A dataset consisting of over 80,000 paintings from over 1000 artists is chosen, and three separate face recognition and clustering tasks are performed. The produced clusters are analyzed by the file names of the paintings and the clusters are named by their majority artist, year range, and style. The clusters are further analyzed and their performance metrics are calculated. The study shows promising results as the artist, year, and styles are clustered with an accuracy of 58.8, 63.7, and 81.3 percent, while the clusters have an average purity of 63.1, 72.4, and 85.9 percent.
The Cube++ Illumination Estimation Dataset
Nov 19, 2020
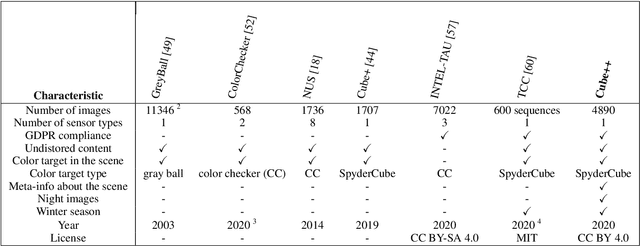

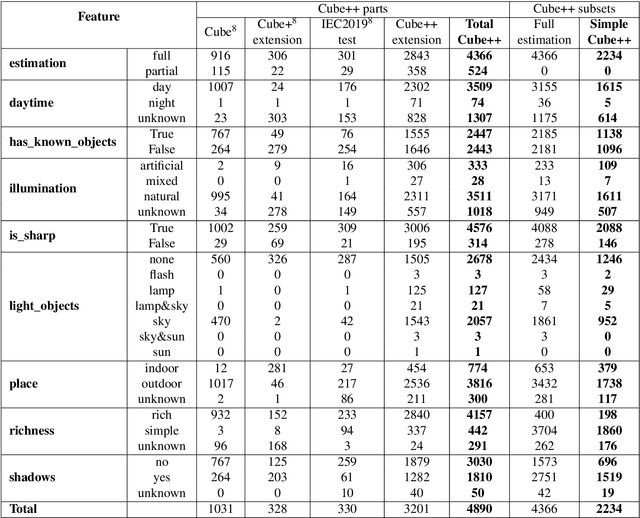
Computational color constancy has the important task of reducing the influence of the scene illumination on the object colors. As such, it is an essential part of the image processing pipelines of most digital cameras. One of the important parts of the computational color constancy is illumination estimation, i.e. estimating the illumination color. When an illumination estimation method is proposed, its accuracy is usually reported by providing the values of error metrics obtained on the images of publicly available datasets. However, over time it has been shown that many of these datasets have problems such as too few images, inappropriate image quality, lack of scene diversity, absence of version tracking, violation of various assumptions, GDPR regulation violation, lack of additional shooting procedure info, etc. In this paper, a new illumination estimation dataset is proposed that aims to alleviate many of the mentioned problems and to help the illumination estimation research. It consists of 4890 images with known illumination colors as well as with additional semantic data that can further make the learning process more accurate. Due to the usage of the SpyderCube color target, for every image there are two ground-truth illumination records covering different directions. Because of that, the dataset can be used for training and testing of methods that perform single or two-illuminant estimation. This makes it superior to many similar existing datasets. The datasets, it's smaller version SimpleCube++, and the accompanying code are available at https://github.com/Visillect/CubePlusPlus/.
A Closer Look at Self-training for Zero-Label Semantic Segmentation
Apr 21, 2021
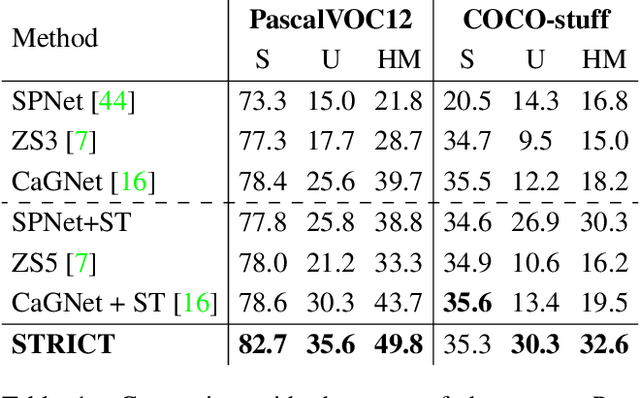
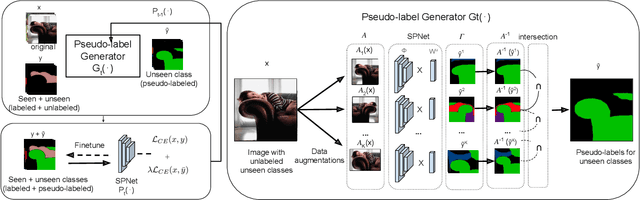
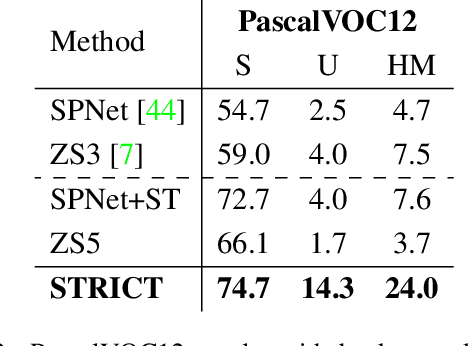
Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.
Weather and Light Level Classification for Autonomous Driving: Dataset, Baseline and Active Learning
Apr 28, 2021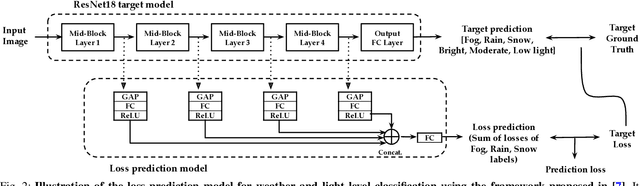
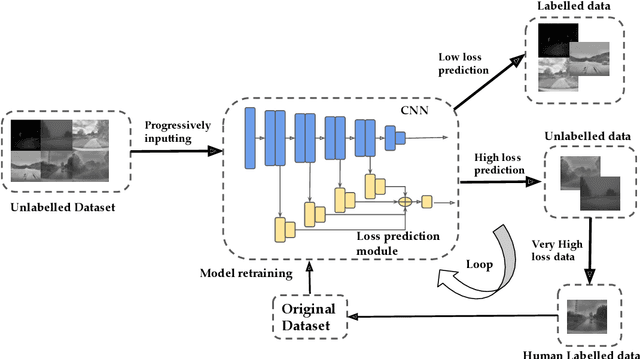
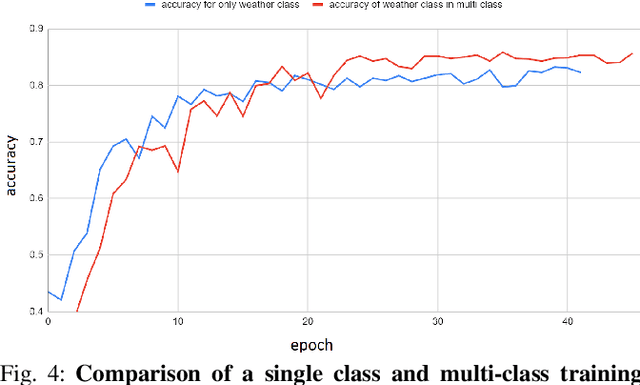
Autonomous driving is rapidly advancing, and Level 2 functions are becoming a standard feature. One of the foremost outstanding hurdles is to obtain robust visual perception in harsh weather and low light conditions where accuracy degradation is severe. It is critical to have a weather classification model to decrease visual perception confidence during these scenarios. Thus, we have built a new dataset for weather (fog, rain, and snow) classification and light level (bright, moderate, and low) classification. Furthermore, we provide street type (asphalt, grass, and cobblestone) classification, leading to 9 labels. Each image has three labels corresponding to weather, light level, and street type. We recorded the data utilizing an industrial front camera of RCCC (red/clear) format with a resolution of $1024\times1084$. We collected 15k video sequences and sampled 60k images. We implement an active learning framework to reduce the dataset's redundancy and find the optimal set of frames for training a model. We distilled the 60k images further to 1.1k images, which will be shared publicly after privacy anonymization. There is no public dataset for weather and light level classification focused on autonomous driving to the best of our knowledge. The baseline ResNet18 network used for weather classification achieves state-of-the-art results in two non-automotive weather classification public datasets but significantly lower accuracy on our proposed dataset, demonstrating it is not saturated and needs further research.