 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-View Food Portion Estimation: Learning Image-to-Energy Mappings Using Generative Adversarial Networks
May 23, 2018

Due to the growing concern of chronic diseases and other health problems related to diet, there is a need to develop accurate methods to estimate an individual's food and energy intake. Measuring accurate dietary intake is an open research problem. In particular, accurate food portion estimation is challenging since the process of food preparation and consumption impose large variations on food shapes and appearances. In this paper, we present a food portion estimation method to estimate food energy (kilocalories) from food images using Generative Adversarial Networks (GAN). We introduce the concept of an "energy distribution" for each food image. To train the GAN, we design a food image dataset based on ground truth food labels and segmentation masks for each food image as well as energy information associated with the food image. Our goal is to learn the mapping of the food image to the food energy. We can then estimate food energy based on the energy distribution. We show that an average energy estimation error rate of 10.89% can be obtained by learning the image-to-energy mapping.
Image Segmentation and Processing for Efficient Parking Space Analysis
Mar 13, 2018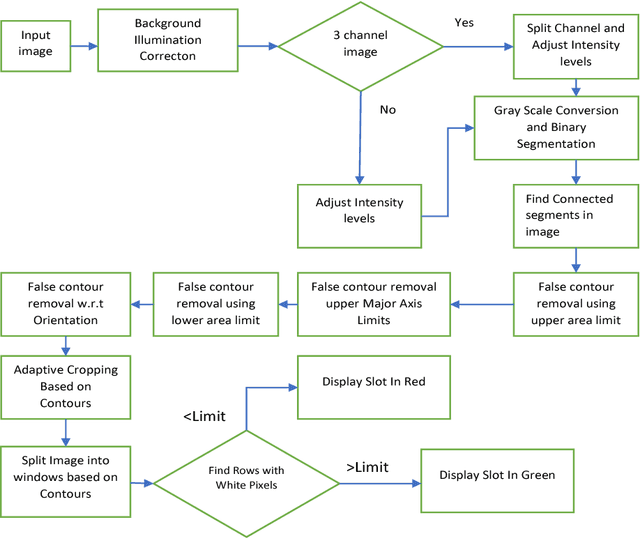

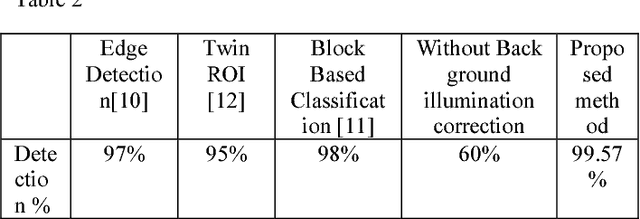
In this paper, we develop a method to detect vacant parking spaces in an environment with unclear segments and contours with the help of MATLAB image processing capabilities. Due to the anomalies present in the parking spaces, such as uneven illumination, distorted slot lines and overlapping of cars. The present-day conventional algorithms have difficulties processing the image for accurate results. The algorithm proposed uses a combination of image pre-processing and false contour detection techniques to improve the detection efficiency. The proposed method also eliminates the need to employ individual sensors to detect a car, instead uses real-time static images to consider a group of slots together, instead of the usual single slot method. This greatly decreases the expenses required to design an efficient parking system. We compare the performance of our algorithm to that of other techniques. These comparisons show that the proposed algorithm can detect the vacancies in the parking spots while ignoring the false data and other distortions.
Query-adaptive Image Retrieval by Deep Weighted Hashing
May 09, 2017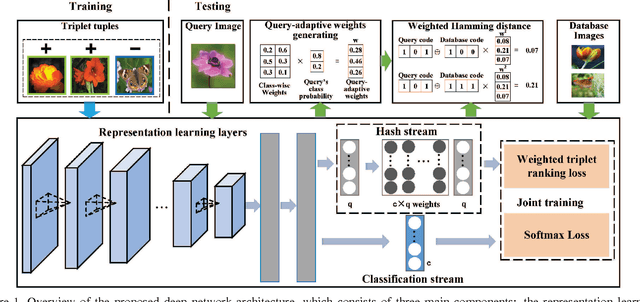
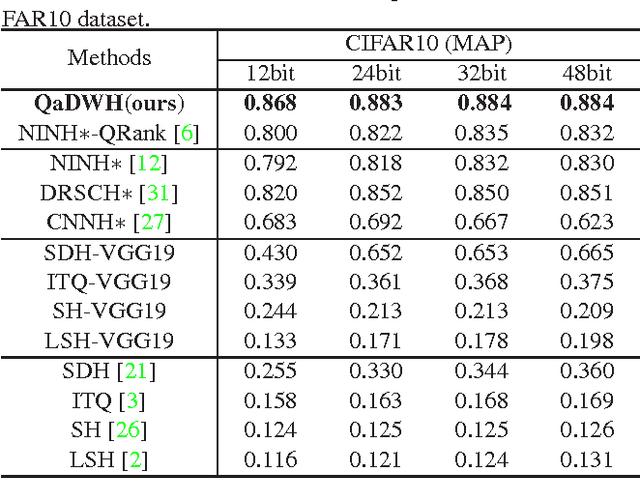
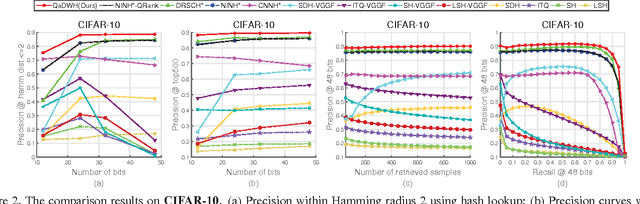
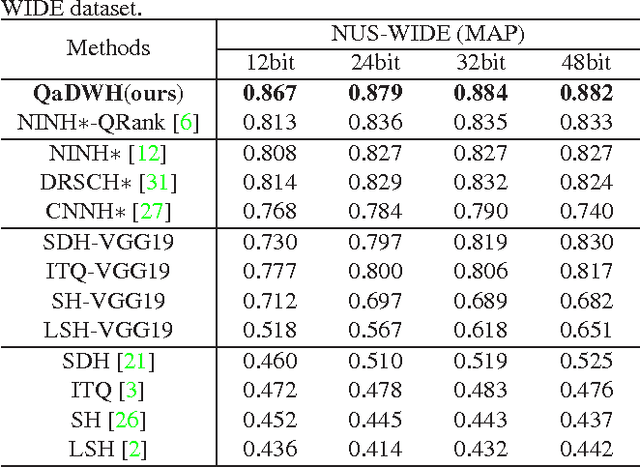
Hashing methods have attracted much attention for large scale image retrieval. Some deep hashing methods have achieved promising results by taking advantage of the strong representation power of deep networks recently. However, existing deep hashing methods treat all hash bits equally. On one hand, a large number of images share the same distance to a query image due to the discrete Hamming distance, which raises a critical issue of image retrieval where fine-grained rankings are very important. On the other hand, different hash bits actually contribute to the image retrieval differently, and treating them equally greatly affects the retrieval accuracy of image. To address the above two problems, we propose the query-adaptive deep weighted hashing (QaDWH) approach, which can perform fine-grained ranking for different queries by weighted Hamming distance. First, a novel deep hashing network is proposed to learn the hash codes and corresponding class-wise weights jointly, so that the learned weights can reflect the importance of different hash bits for different image classes. Second, a query-adaptive image retrieval method is proposed, which rapidly generates hash bit weights for different query images by fusing its semantic probability and the learned class-wise weights. Fine-grained image retrieval is then performed by the weighted Hamming distance, which can provide more accurate ranking than the traditional Hamming distance. Experiments on four widely used datasets show that the proposed approach outperforms eight state-of-the-art hashing methods.
Reconstruction of Undersampled 3D Non-Cartesian Image-Based Navigators for Coronary MRA Using an Unrolled Deep Learning Model
Oct 24, 2019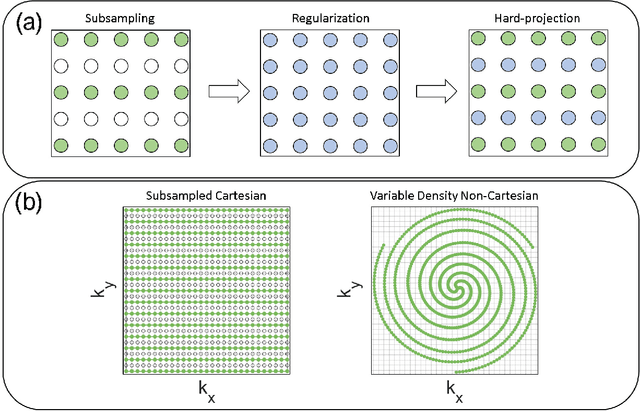

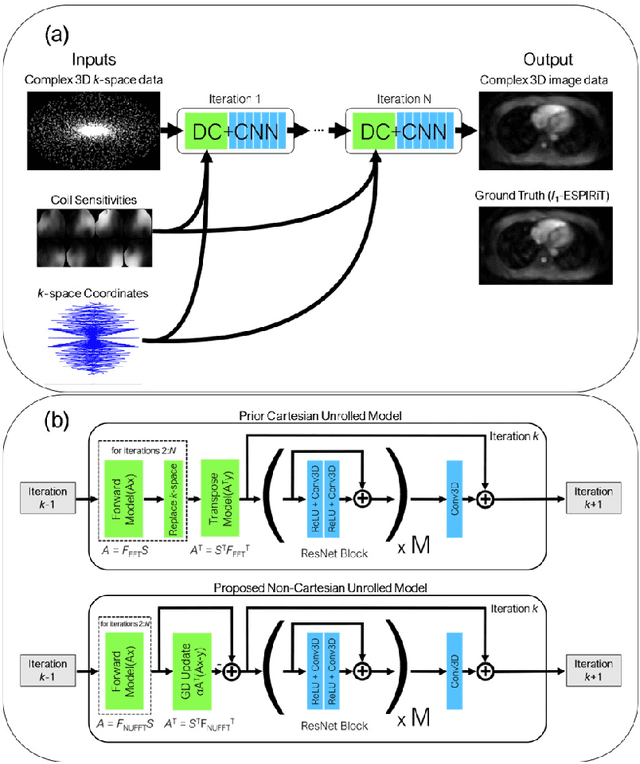
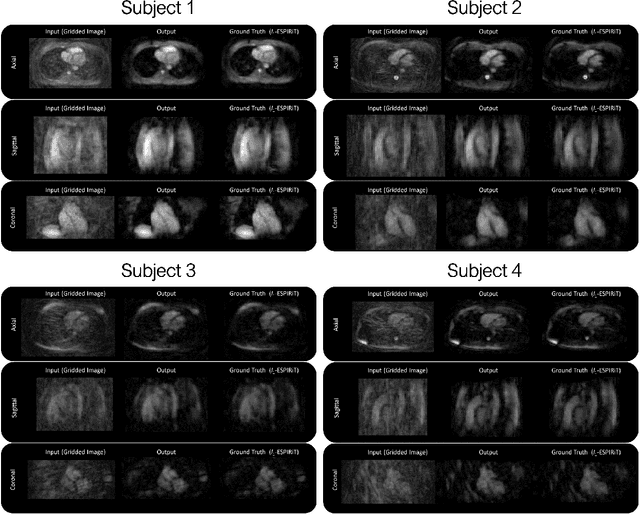
Purpose: To rapidly reconstruct undersampled 3D non-Cartesian image-based navigators (iNAVs) using an unrolled deep learning (DL) model for non-rigid motion correction in coronary magnetic resonance angiography (CMRA). Methods: An unrolled network is trained to reconstruct beat-to-beat 3D iNAVs acquired as part of a CMRA sequence. The unrolled model incorporates a non-uniform FFT operator to perform the data consistency operation, and the regularization term is learned by a convolutional neural network (CNN) based on the proximal gradient descent algorithm. The training set includes 6,000 3D iNAVs acquired from 7 different subjects and 11 scans using a variable-density (VD) cones trajectory. For testing, 3D iNAVs from 4 additional subjects are reconstructed using the unrolled model. To validate reconstruction accuracy, global and localized motion estimates from DL model-based 3D iNAVs are compared with those extracted from 3D iNAVs reconstructed with $\textit{l}_{1}$-ESPIRiT. Then, the high-resolution coronary MRA images motion corrected with autofocusing using the $\textit{l}_{1}$-ESPIRiT and DL model-based 3D iNAVs are assessed for differences. Results: 3D iNAVs reconstructed using the DL model-based approach and conventional $\textit{l}_{1}$-ESPIRiT generate similar global and localized motion estimates and provide equivalent coronary image quality. Reconstruction with the unrolled network completes in a fraction of the time compared to CPU and GPU implementations of $\textit{l}_{1}$-ESPIRiT (20x and 3x speed increases, respectively). Conclusion: We have developed a deep neural network architecture to reconstruct undersampled 3D non-Cartesian VD cones iNAVs. Our approach decreases reconstruction time for 3D iNAVs, while preserving the accuracy of non-rigid motion information offered by them for correction.
Systematic Analysis and Removal of Circular Artifacts for StyleGAN
Mar 04, 2021
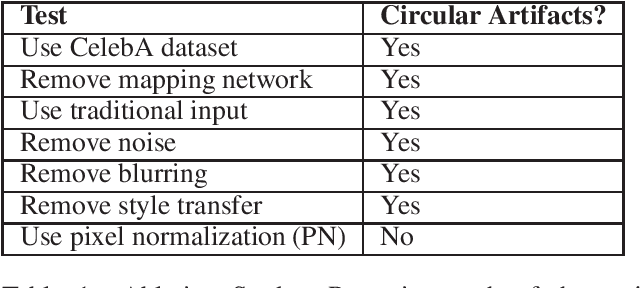
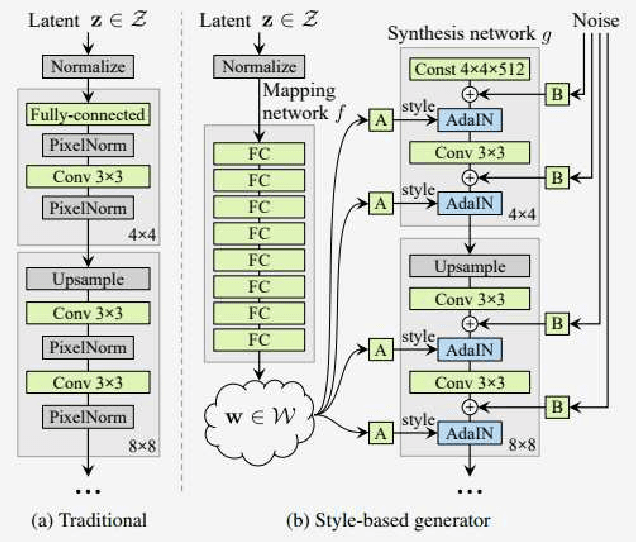

StyleGAN is one of the state-of-the-art image generators which is well-known for synthesizing high-resolution and hyper-realistic face images. Though images generated by vanilla StyleGAN model are visually appealing, they sometimes contain prominent circular artifacts which severely degrade the quality of generated images. In this work, we provide a systematic investigation on how those circular artifacts are formed by studying the functionalities of different stages of vanilla StyleGAN architecture, with both mechanism analysis and extensive experiments. The key modules of vanilla StyleGAN that promote such undesired artifacts are highlighted. Our investigation also explains why the artifacts are usually circular, relatively small and rarely split into 2 or more parts. Besides, we propose a simple yet effective solution to remove the prominent circular artifacts for vanilla StyleGAN, by applying a novel pixel-instance normalization (PIN) layer.
Network Signatures from Image Representation of Adjacency Matrices: Deep/Transfer Learning for Subgraph Classification
Apr 17, 2018
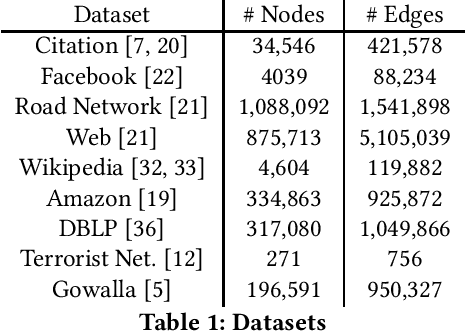

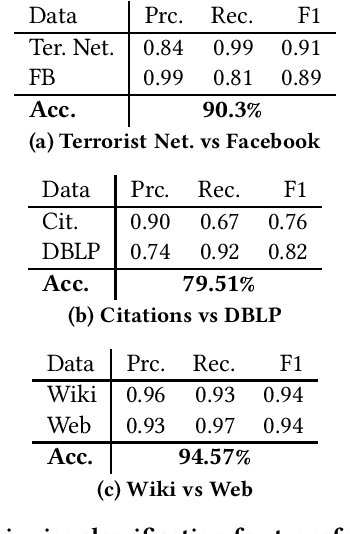
We propose a novel subgraph image representation for classification of network fragments with the targets being their parent networks. The graph image representation is based on 2D image embeddings of adjacency matrices. We use this image representation in two modes. First, as the input to a machine learning algorithm. Second, as the input to a pure transfer learner. Our conclusions from several datasets are that (a) deep learning using our structured image features performs the best compared to benchmark graph kernel and classical features based methods; and, (b) pure transfer learning works effectively with minimum interference from the user and is robust against small data.
Fully-deformable 3D image registration in two seconds
Dec 17, 2018
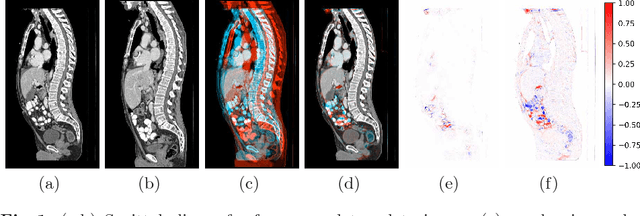
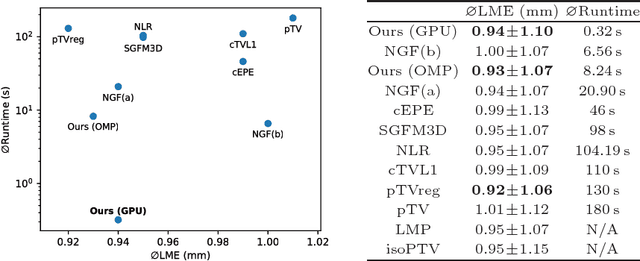
We present a highly parallel method for accurate and efficient variational deformable 3D image registration on a consumer-grade graphics processing unit (GPU). We build on recent matrix-free variational approaches and specialize the concepts to the massively-parallel manycore architecture provided by the GPU. Compared to a parallel and optimized CPU implementation, this allows us to achieve an average speedup of 32.53 on 986 real-world CT thorax-abdomen follow-up scans. At a resolution of approximately $256^3$ voxels, the average runtime is 1.99 seconds for the full registration. On the publicly available DIR-lab benchmark, our method ranks third with respect to average landmark error at an average runtime of 0.32 seconds.
Meticulous Object Segmentation
Dec 13, 2020Compared with common image segmentation tasks targeted at low-resolution images, higher resolution detailed image segmentation receives much less attention. In this paper, we propose and study a task named Meticulous Object Segmentation (MOS), which is focused on segmenting well-defined foreground objects with elaborate shapes in high resolution images (e.g. 2k - 4k). To this end, we propose the MeticulousNet which leverages a dedicated decoder to capture the object boundary details. Specifically, we design a Hierarchical Point-wise Refining (HierPR) block to better delineate object boundaries, and reformulate the decoding process as a recursive coarse to fine refinement of the object mask. To evaluate segmentation quality near object boundaries, we propose the Meticulosity Quality (MQ) score considering both the mask coverage and boundary precision. In addition, we collect a MOS benchmark dataset including 600 high quality images with complex objects. We provide comprehensive empirical evidence showing that MeticulousNet can reveal pixel-accurate segmentation boundaries and is superior to state-of-the-art methods for high resolution object segmentation tasks.
Self-Supervised Training Enhances Online Continual Learning
Mar 25, 2021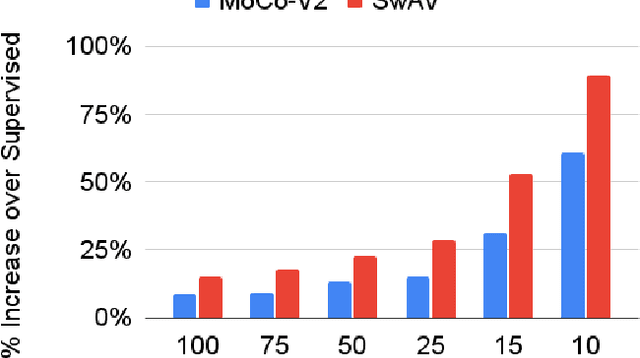
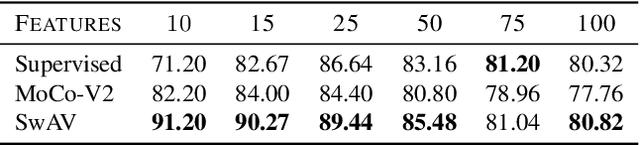
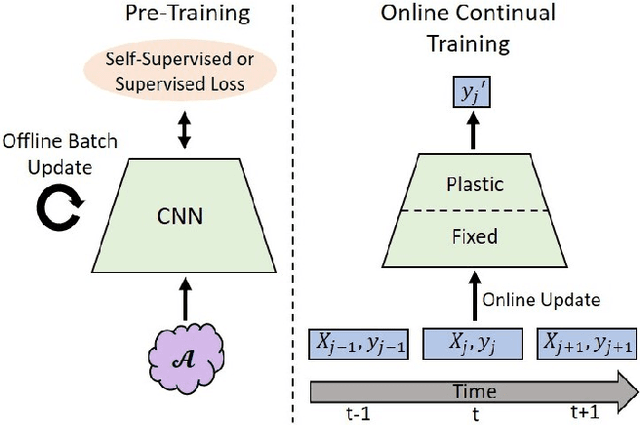
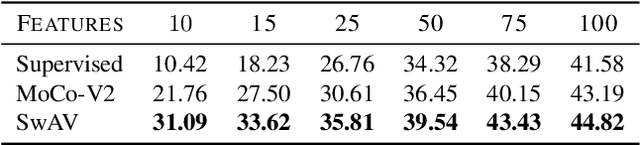
In continual learning, a system must incrementally learn from a non-stationary data stream without catastrophic forgetting. Recently, multiple methods have been devised for incrementally learning classes on large-scale image classification tasks, such as ImageNet. State-of-the-art continual learning methods use an initial supervised pre-training phase, in which the first 10% - 50% of the classes in a dataset are used to learn representations in an offline manner before continual learning of new classes begins. We hypothesize that self-supervised pre-training could yield features that generalize better than supervised learning, especially when the number of samples used for pre-training is small. We test this hypothesis using the self-supervised MoCo-V2 and SwAV algorithms. On ImageNet, we find that both outperform supervised pre-training considerably for online continual learning, and the gains are larger when fewer samples are available. Our findings are consistent across three continual learning algorithms. Our best system achieves a 14.95% relative increase in top-1 accuracy on class incremental ImageNet over the prior state of the art for online continual learning.
HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
Oct 15, 2020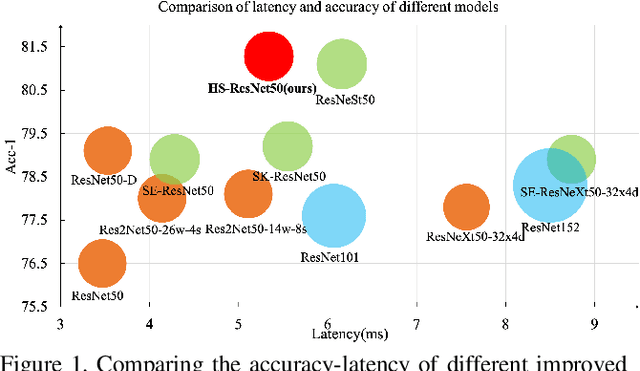
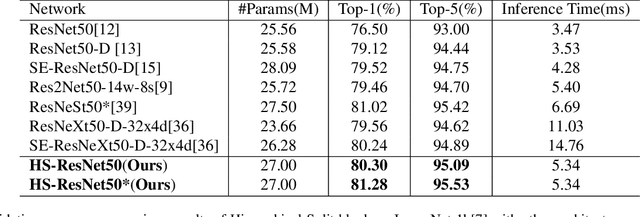
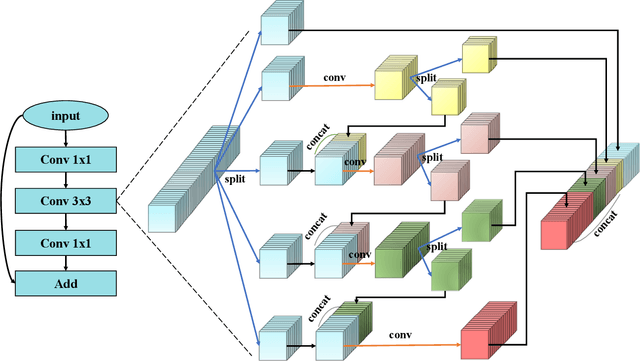

This paper addresses representational block named Hierarchical-Split Block, which can be taken as a plug-and-play block to upgrade existing convolutional neural networks, improves model performance significantly in a network. Hierarchical-Split Block contains many hierarchical split and concatenate connections within one single residual block. We find multi-scale features is of great importance for numerous vision tasks. Moreover, Hierarchical-Split block is very flexible and efficient, which provides a large space of potential network architectures for different applications. In this work, we present a common backbone based on Hierarchical-Split block for tasks: image classification, object detection, instance segmentation and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baseline. As shown in Figure1, for image classification, our 50-layers network(HS-ResNet50) achieves 81.28% top-1 accuracy with competitive latency on ImageNet-1k dataset. It also outperforms most state-of-the-art models. The source code and models will be available on: https://github.com/PaddlePaddle/PaddleClas