 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vessel-CAPTCHA: an efficient learning framework for vessel annotation and segmentation
Jan 29, 2021
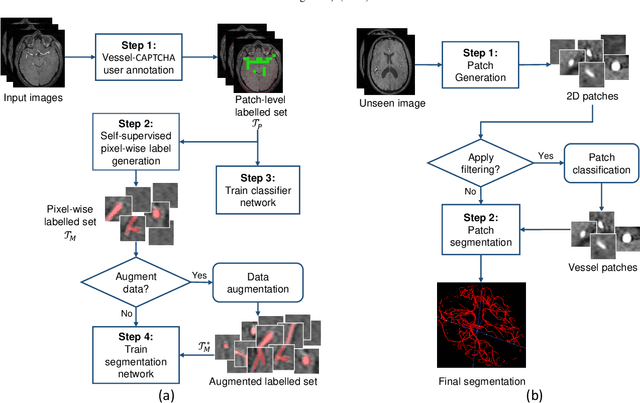
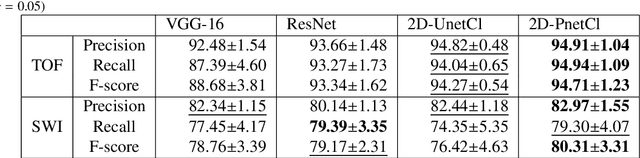
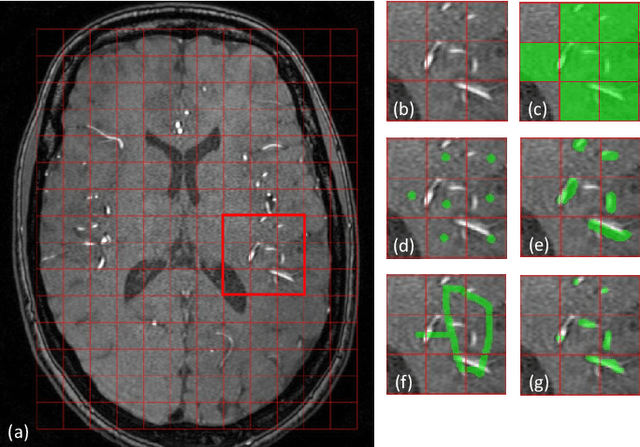

The use of deep learning techniques for 3D brain vessel image segmentation has not been as widespread as for the segmentation of other organs and tissues. This can be explained by two factors. First, deep learning techniques tend to show poor performances at the segmentation of relatively small objects compared to the size of the full image. Second, due to the complexity of vascular trees and the small size of vessels, it is challenging to obtain the amount of annotated training data typically needed by deep learning methods. To address these problems, we propose a novel annotation-efficient deep learning vessel segmentation framework. The framework avoids pixel-wise annotations, only requiring patch-level labels to discriminate between vessel and non-vessel 2D patches in the training set, in a setup similar to the CAPTCHAs used to differentiate humans from bots in web applications. The user-provided annotations are used for two tasks: 1) to automatically generate pixel-wise labels for vessels and background in each patch, which are used to train a segmentation network, and 2) to train a classifier network. The classifier network allows to generate additional weak patch labels, further reducing the annotation burden, and it acts as a noise filter for poor quality images. We use this framework for the segmentation of the cerebrovascular tree in Time-of-Flight angiography (TOF) and Susceptibility-Weighted Images (SWI). The results show that the framework achieves state-of-the-art accuracy, while reducing the annotation time by up to 80% with respect to learning-based segmentation methods using pixel-wise labels for training
Reconstruction of Undersampled 3D Non-Cartesian Image-Based Navigators for Coronary MRA Using an Unrolled Deep Learning Model
Oct 24, 2019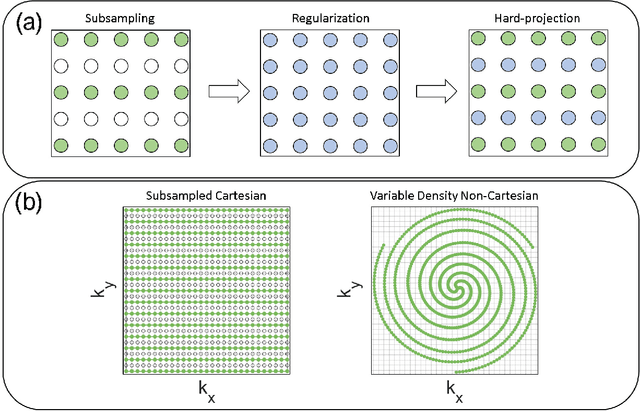

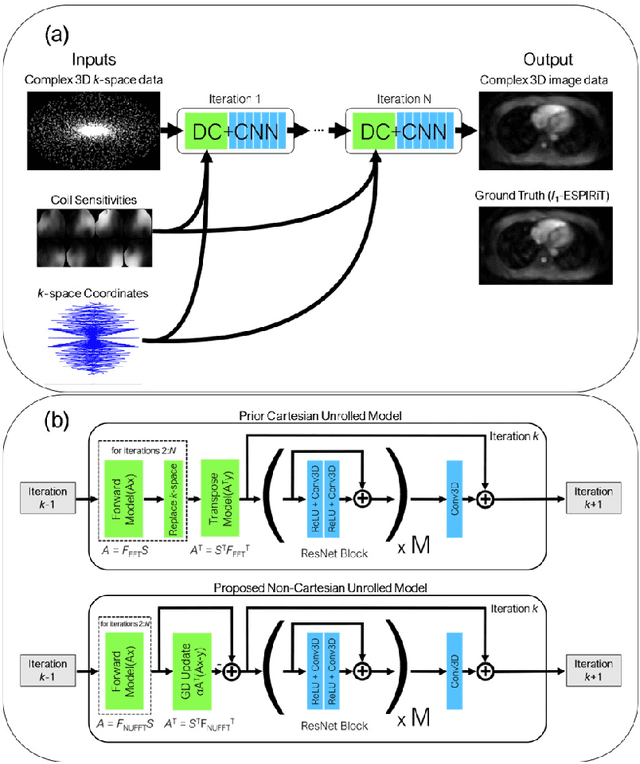
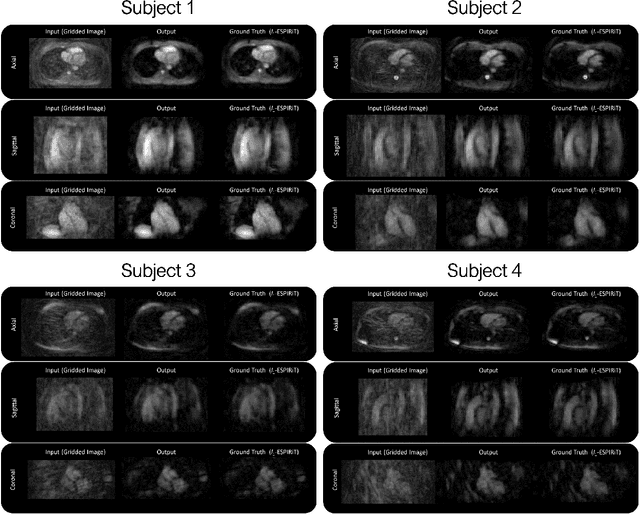
Purpose: To rapidly reconstruct undersampled 3D non-Cartesian image-based navigators (iNAVs) using an unrolled deep learning (DL) model for non-rigid motion correction in coronary magnetic resonance angiography (CMRA). Methods: An unrolled network is trained to reconstruct beat-to-beat 3D iNAVs acquired as part of a CMRA sequence. The unrolled model incorporates a non-uniform FFT operator to perform the data consistency operation, and the regularization term is learned by a convolutional neural network (CNN) based on the proximal gradient descent algorithm. The training set includes 6,000 3D iNAVs acquired from 7 different subjects and 11 scans using a variable-density (VD) cones trajectory. For testing, 3D iNAVs from 4 additional subjects are reconstructed using the unrolled model. To validate reconstruction accuracy, global and localized motion estimates from DL model-based 3D iNAVs are compared with those extracted from 3D iNAVs reconstructed with $\textit{l}_{1}$-ESPIRiT. Then, the high-resolution coronary MRA images motion corrected with autofocusing using the $\textit{l}_{1}$-ESPIRiT and DL model-based 3D iNAVs are assessed for differences. Results: 3D iNAVs reconstructed using the DL model-based approach and conventional $\textit{l}_{1}$-ESPIRiT generate similar global and localized motion estimates and provide equivalent coronary image quality. Reconstruction with the unrolled network completes in a fraction of the time compared to CPU and GPU implementations of $\textit{l}_{1}$-ESPIRiT (20x and 3x speed increases, respectively). Conclusion: We have developed a deep neural network architecture to reconstruct undersampled 3D non-Cartesian VD cones iNAVs. Our approach decreases reconstruction time for 3D iNAVs, while preserving the accuracy of non-rigid motion information offered by them for correction.
Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data
Nov 01, 2018Image translation is a computer vision task that involves translating one representation of the scene into another. Various approaches have been proposed and achieved highly desirable results. Nevertheless, its accomplishment requires abundant paired training data which are expensive to acquire. Therefore, models for translation are usually trained on a set of paired training data which are carefully and laboriously designed. Our work is focused on learning through automatically generated paired data. We propose a method to generate fake sketches from images using an adversarial network and then pair the images with corresponding fake sketches to form large-scale multi-class paired training data for training a sketch-to-image translation model. Our model is an encoder-decoder architecture where the encoder generates fake sketches from images and the decoder performs sketch-to-image translation. Qualitative results show that the encoder can be used for generating large-scale multi-class paired data under low supervision. Our current dataset now contains 61255 image and (fake) sketch pairs from 256 different categories. These figures can be greatly increased in the future thanks to our weak reliance on manually labeled data.
Learning Deep Context-Network Architectures for Image Annotation
Mar 23, 2018

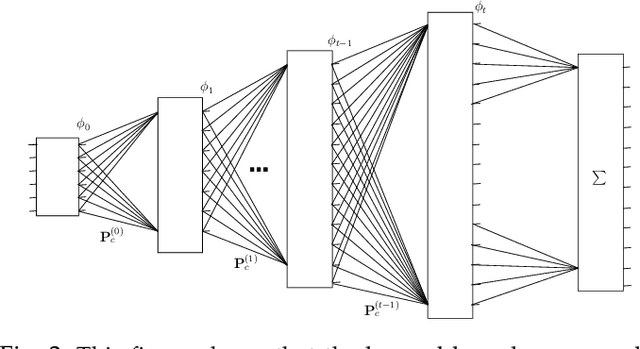

Context plays an important role in visual pattern recognition as it provides complementary clues for different learning tasks including image classification and annotation. In the particular scenario of kernel learning, the general recipe of context-based kernel design consists in learning positive semi-definite similarity functions that return high values not only when data share similar content but also similar context. However, in spite of having a positive impact on performance, the use of context in these kernel design methods has not been fully explored; indeed, context has been handcrafted instead of being learned. In this paper, we introduce a novel context-aware kernel design framework based on deep learning. Our method discriminatively learns spatial geometric context as the weights of a deep network (DN). The architecture of this network is fully determined by the solution of an objective function that mixes content, context and regularization, while the parameters of this network determine the most relevant (discriminant) parts of the learned context. We apply this context and kernel learning framework to image classification using the challenging ImageCLEF Photo Annotation benchmark; the latter shows that our deep context learning provides highly effective kernels for image classification as corroborated through extensive experiments.
Identifying Melanoma Images using EfficientNet Ensemble: Winning Solution to the SIIM-ISIC Melanoma Classification Challenge
Oct 11, 2020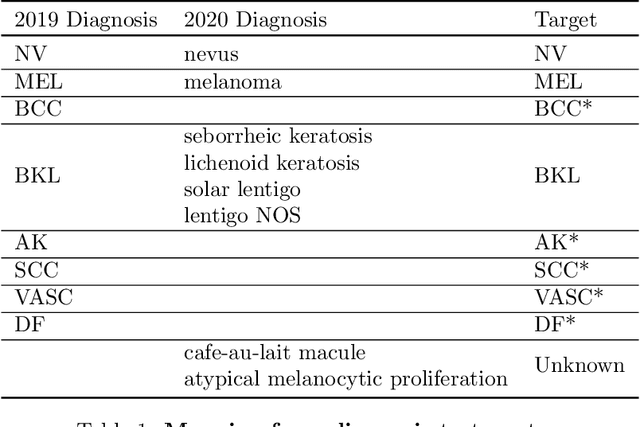
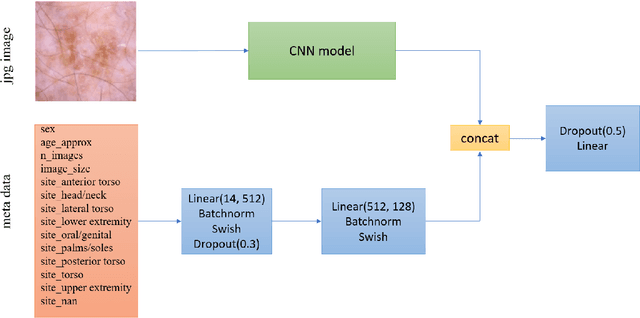
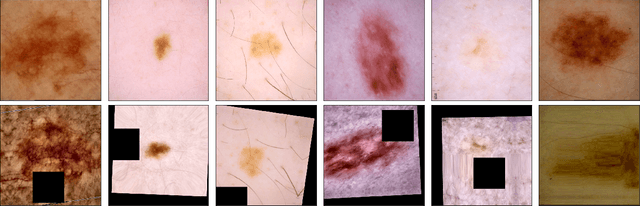
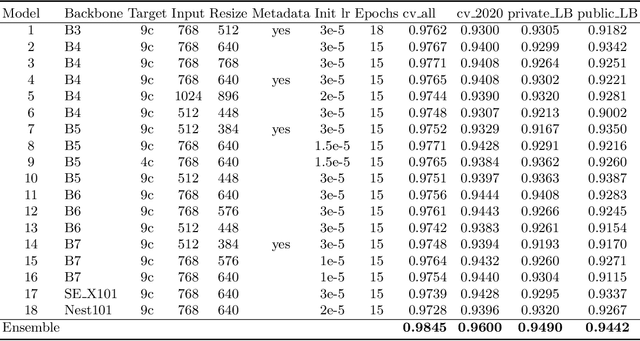
We present our winning solution to the SIIM-ISIC Melanoma Classification Challenge. It is an ensemble of convolutions neural network (CNN) models with different backbones and input sizes, most of which are image-only models while a few of them used image-level and patient-level metadata. The keys to our winning are: (1) stable validation scheme (2) good choice of model target (3) carefully tuned pipeline and (4) ensembling with very diverse models. The winning submission scored 0.9600 AUC on cross validation and 0.9490 AUC on private leaderboard.
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020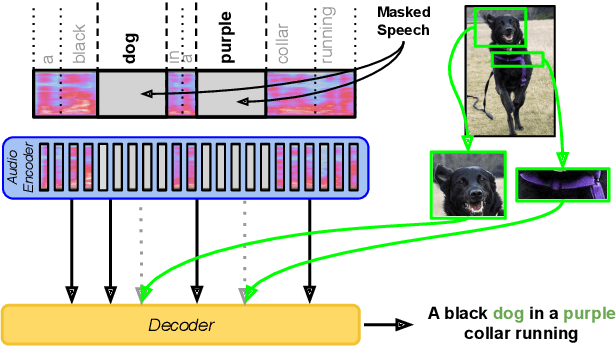
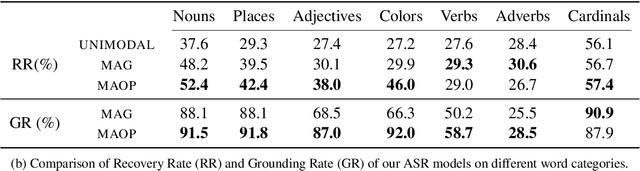
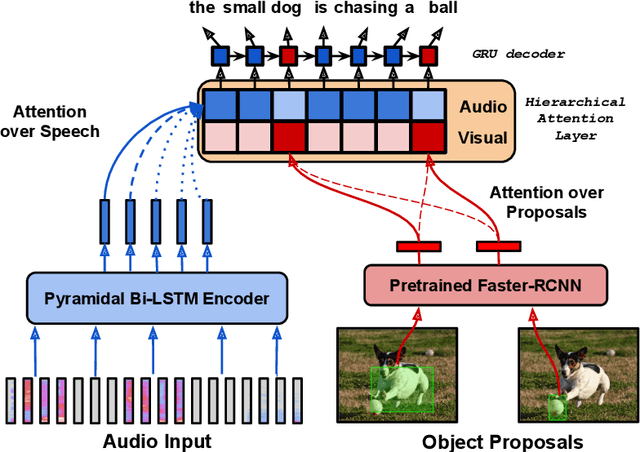
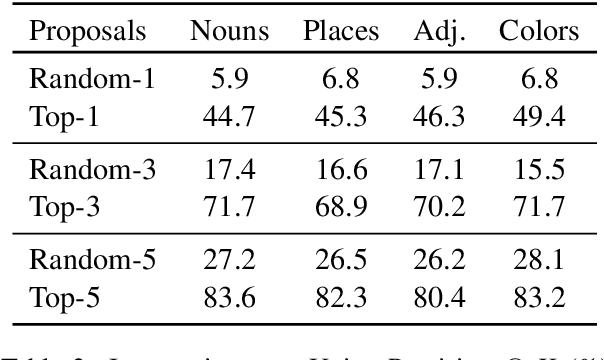
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
Towards Fast and Accurate Real-World Depth Super-Resolution: Benchmark Dataset and Baseline
Apr 13, 2021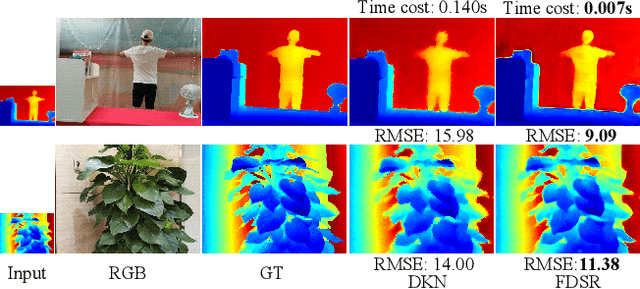


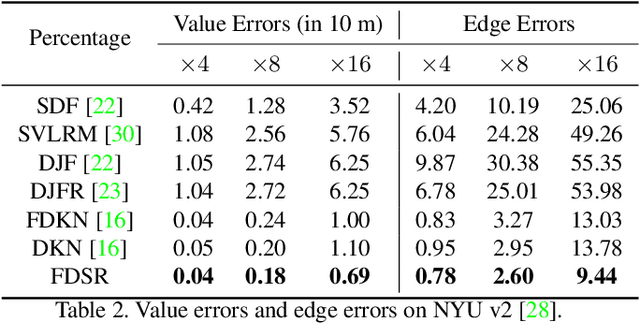
Depth maps obtained by commercial depth sensors are always in low-resolution, making it difficult to be used in various computer vision tasks. Thus, depth map super-resolution (SR) is a practical and valuable task, which upscales the depth map into high-resolution (HR) space. However, limited by the lack of real-world paired low-resolution (LR) and HR depth maps, most existing methods use downsampling to obtain paired training samples. To this end, we first construct a large-scale dataset named "RGB-D-D", which can greatly promote the study of depth map SR and even more depth-related real-world tasks. The "D-D" in our dataset represents the paired LR and HR depth maps captured from mobile phone and Lucid Helios respectively ranging from indoor scenes to challenging outdoor scenes. Besides, we provide a fast depth map super-resolution (FDSR) baseline, in which the high-frequency component adaptively decomposed from RGB image to guide the depth map SR. Extensive experiments on existing public datasets demonstrate the effectiveness and efficiency of our network compared with the state-of-the-art methods. Moreover, for the real-world LR depth maps, our algorithm can produce more accurate HR depth maps with clearer boundaries and to some extent correct the depth value errors.
OR-Net: Pointwise Relational Inference for Data Completion under Partial Observation
May 05, 2021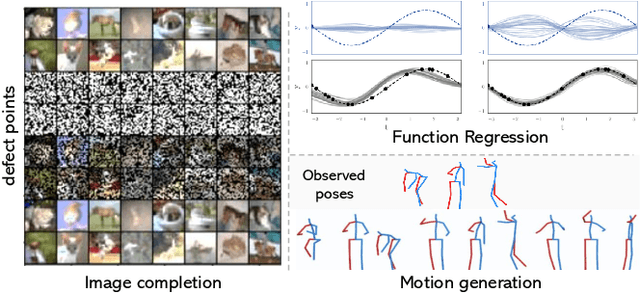
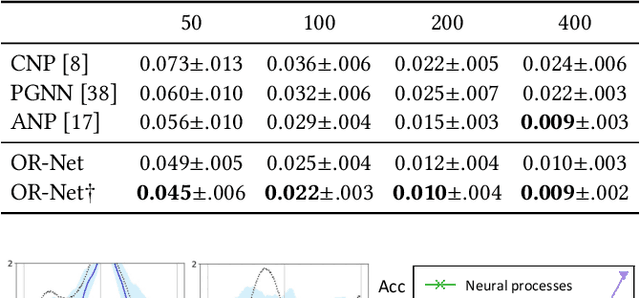
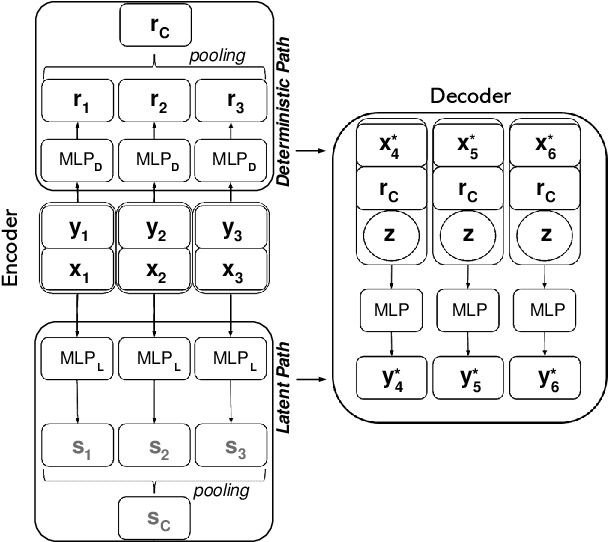
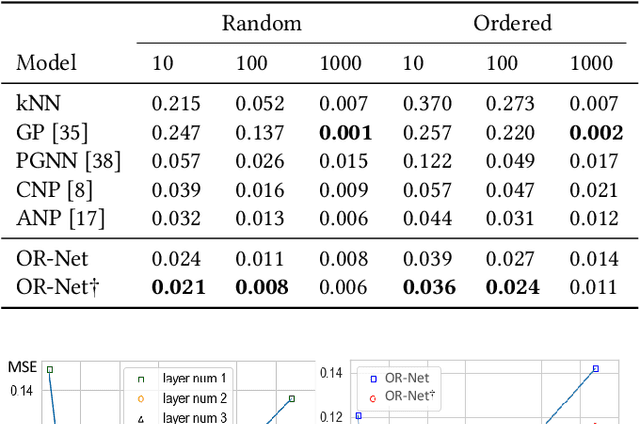
Contemporary data-driven methods are typically fed with full supervision on large-scale datasets which limits their applicability. However, in the actual systems with limitations such as measurement error and data acquisition problems, people usually obtain incomplete data. Although data completion has attracted wide attention, the underlying data pattern and relativity are still under-developed. Currently, the family of latent variable models allows learning deep latent variables over observed variables by fitting the marginal distribution. As far as we know, current methods fail to perceive the data relativity under partial observation. Aiming at modeling incomplete data, this work uses relational inference to fill in the incomplete data. Specifically, we expect to approximate the real joint distribution over the partial observation and latent variables, thus infer the unseen targets respectively. To this end, we propose Omni-Relational Network (OR-Net) to model the pointwise relativity in two aspects: (i) On one hand, the inner relationship is built among the context points in the partial observation; (ii) On the other hand, the unseen targets are inferred by learning the cross-relationship with the observed data points. It is further discovered that the proposed method can be generalized to different scenarios regardless of whether the physical structure can be observed or not. It is demonstrated that the proposed OR-Net can be well generalized for data completion tasks of various modalities, including function regression, image completion on MNIST and CelebA datasets, and also sequential motion generation conditioned on the observed poses.
Sparse-Shot Learning for Extremely Many Localisations
Apr 21, 2021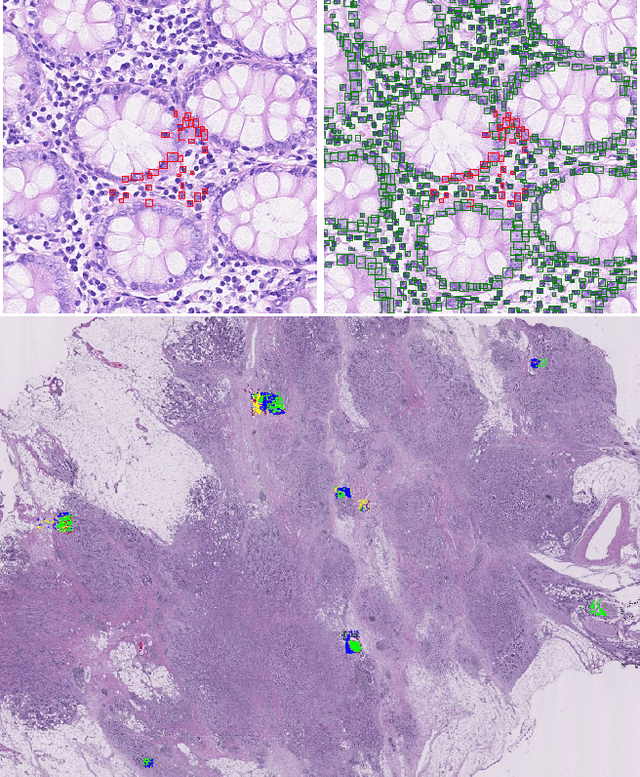

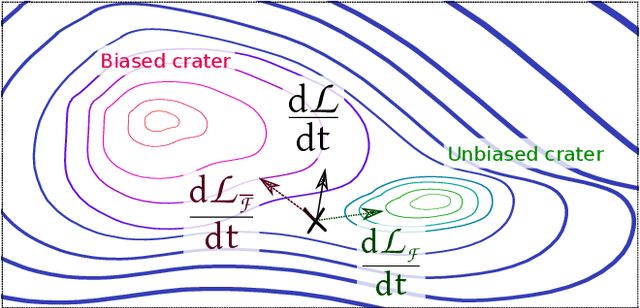
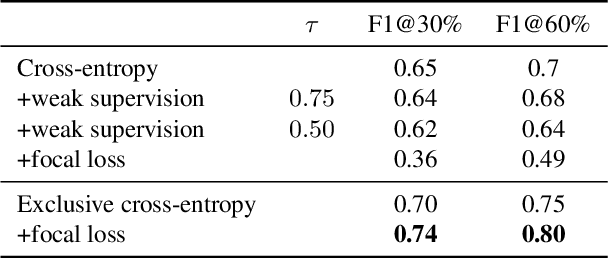
Object localisation is typically considered in the context of regular images, for instance depicting objects like people or cars. In these images there is typically a relatively small number of instances per image per class, which usually is manageable to annotate. However, outside the realm of regular images we are often confronted with a different situation. In computational pathology digitised tissue sections are extremely large images, whose dimensions quickly exceed 250'000x250'000 pixels, where relevant objects, such as tumour cells or lymphocytes can quickly number in the millions. Annotating them all is practically impossible and annotating sparsely a few, out of many more, is the only possibility. Unfortunately, learning from sparse annotations, or sparse-shot learning, clashes with standard supervised learning because what is not annotated is treated as a negative. However, assigning negative labels to what are true positives leads to confusion in the gradients and biased learning. To this end, we present exclusive cross entropy, which slows down the biased learning by examining the second-order loss derivatives in order to drop the loss terms corresponding to likely biased terms. Experiments on nine datasets and two different localisation tasks, detection with YOLLO and segmentation with Unet, show that we obtain considerable improvements compared to cross entropy or focal loss, while often reaching the best possible performance for the model with only 10-40 of annotations.
Automating Visual Blockage Classification of Culverts with Deep Learning
Apr 21, 2021
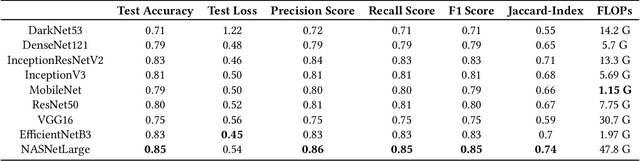
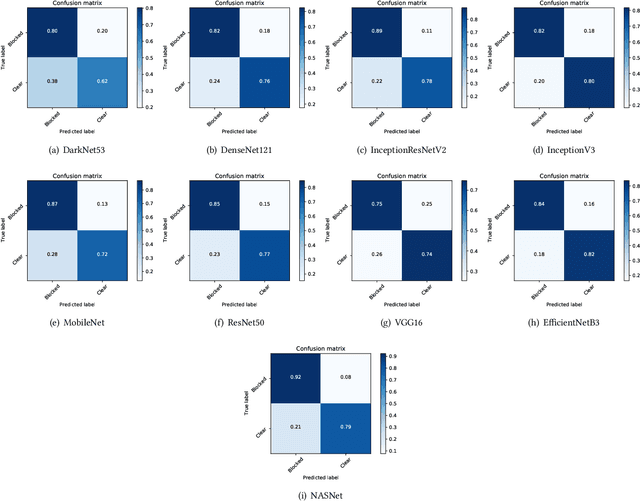
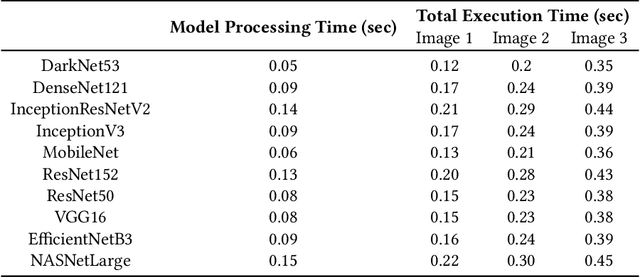
Blockage of culverts by transported debris materials is reported as main contributor in originating urban flash floods. Conventional modelling approaches had no success in addressing the problem largely because of unavailability of peak floods hydraulic data and highly non-linear behaviour of debris at culvert. This article explores a new dimension to investigate the issue by proposing the use of Intelligent Video Analytic (IVA) algorithms for extracting blockage related information. Potential of using existing Convolutional Neural Network (CNN) algorithms (i.e., DarkNet53, DenseNet121, InceptionResNetV2, InceptionV3, MobileNet, ResNet50, VGG16, EfficientNetB3, NASNet) is investigated over a custom collected blockage dataset (i.e., Images of Culvert Openings and Blockage (ICOB)) to predict the blockage in a given image. Models were evaluated based on their performance on test dataset (i.e., accuracy, loss, precision, recall, F1-score, Jaccard-Index), Floating Point Operations Per Second (FLOPs) and response times to process a single test instance. From the results, NASNet was reported most efficient in classifying the blockage with the accuracy of 85\%; however, EfficientNetB3 was recommended for the hardware implementation because of its improved response time with accuracy comparable to NASNet (i.e., 83\%). False Negative (FN) instances, False Positive (FP) instances and CNN layers activation suggested that background noise and oversimplified labelling criteria were two contributing factors in degraded performance of existing CNN algorithms.