 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Anti-Adversarially Manipulated Attributions for Weakly and Semi-Supervised Semantic Segmentation
Mar 16, 2021
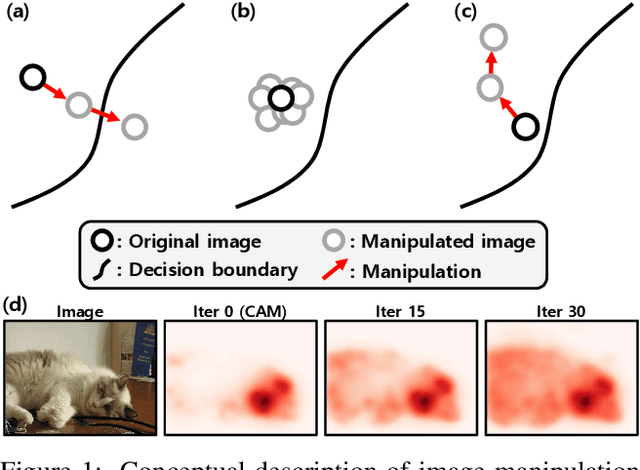
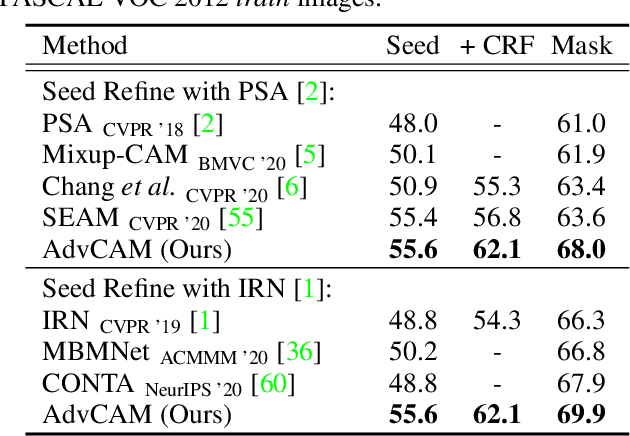
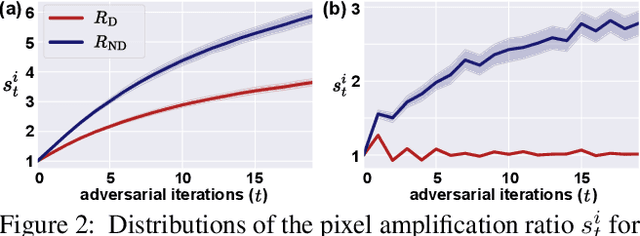
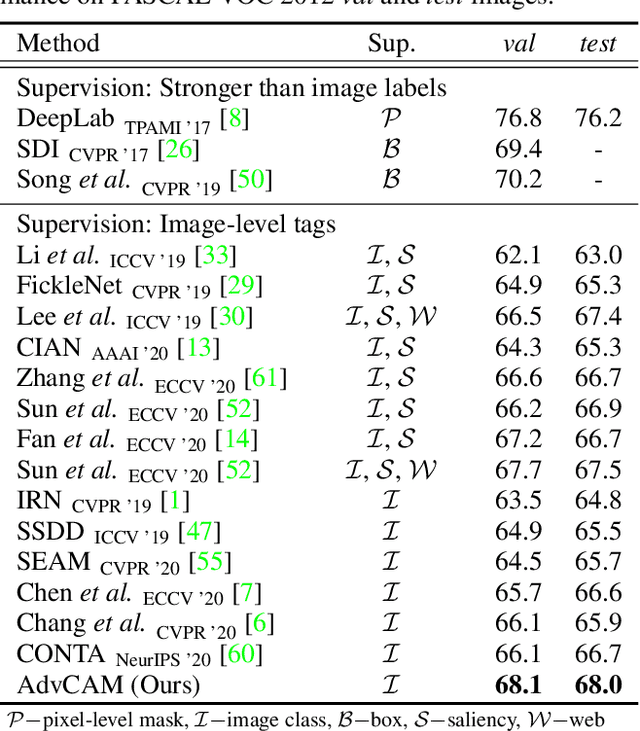
Weakly supervised semantic segmentation produces a pixel-level localization from a classifier, but it is likely to restrict its focus to a small discriminative region of the target object. AdvCAM is an attribution map of an image that is manipulated to increase the classification score. This manipulation is realized in an anti-adversarial manner, which perturbs the images along pixel gradients in the opposite direction from those used in an adversarial attack. It forces regions initially considered not to be discriminative to become involved in subsequent classifications, and produces attribution maps that successively identify more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and limits the attributions of the regions that already have high scores. On PASCAL VOC 2012 test images, we achieve mIoUs of 68.0 and 76.9 for weakly and semi-supervised semantic segmentation respectively, which represent a new state-of-the-art.
Unpaired Multi-Domain Image Generation via Regularized Conditional GANs
May 07, 2018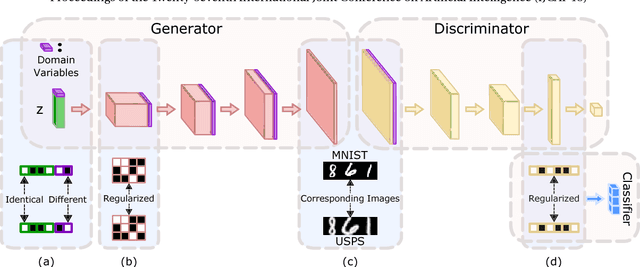
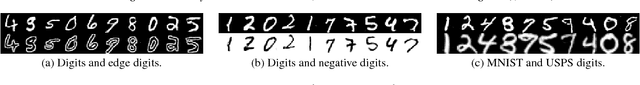
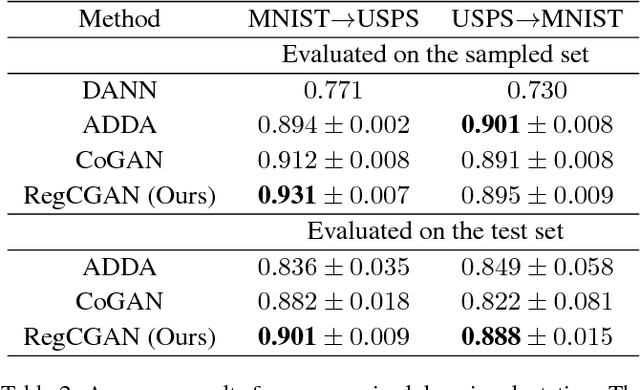

In this paper, we study the problem of multi-domain image generation, the goal of which is to generate pairs of corresponding images from different domains. With the recent development in generative models, image generation has achieved great progress and has been applied to various computer vision tasks. However, multi-domain image generation may not achieve the desired performance due to the difficulty of learning the correspondence of different domain images, especially when the information of paired samples is not given. To tackle this problem, we propose Regularized Conditional GAN (RegCGAN) which is capable of learning to generate corresponding images in the absence of paired training data. RegCGAN is based on the conditional GAN, and we introduce two regularizers to guide the model to learn the corresponding semantics of different domains. We evaluate the proposed model on several tasks for which paired training data is not given, including the generation of edges and photos, the generation of faces with different attributes, etc. The experimental results show that our model can successfully generate corresponding images for all these tasks, while outperforms the baseline methods. We also introduce an approach of applying RegCGAN to unsupervised domain adaptation.
Investigating Human Factors in Image Forgery Detection
Apr 05, 2017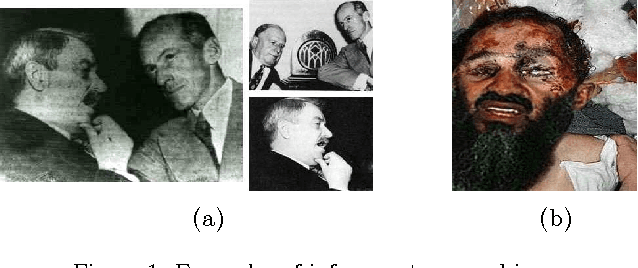
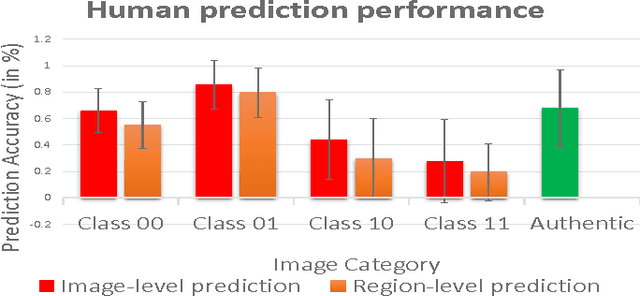
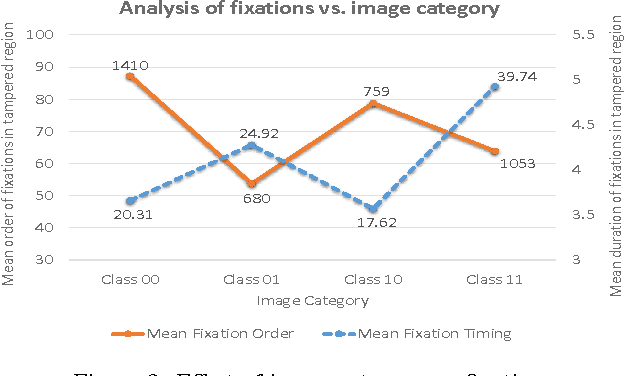
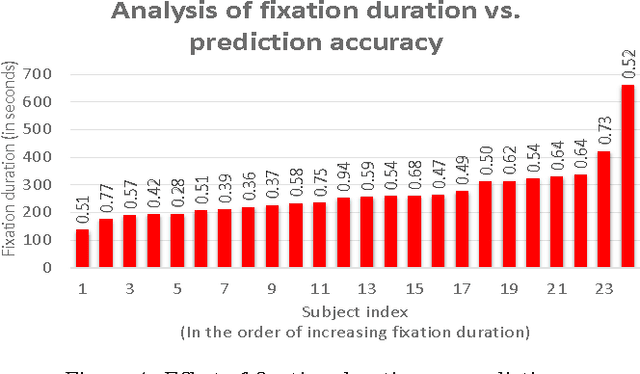
In today's age of internet and social media, one can find an enormous volume of forged images on-line. These images have been used in the past to convey falsified information and achieve harmful intentions. The spread and the effect of the social media only makes this problem more severe. While creating forged images has become easier due to software advancements, there is no automated algorithm which can reliably detect forgery. Image forgery detection can be seen as a subset of image understanding problem. Human performance is still the gold-standard for these type of problems when compared to existing state-of-art automated algorithms. We conduct a subjective evaluation test with the aid of eye-tracker to investigate into human factors associated with this problem. We compare the performance of an automated algorithm and humans for forgery detection problem. We also develop an algorithm which uses the data from the evaluation test to predict the difficulty-level of an image (the difficulty-level of an image here denotes how difficult it is for humans to detect forgery in an image. Terms such as "Easy/difficult image" will be used in the same context). The experimental results presented in this paper should facilitate development of better algorithms in the future.
Unsupervised Classification for Polarimetric SAR Data Using Variational Bayesian Wishart Mixture Model with Inverse Gamma-Gamma Prior
Apr 04, 2021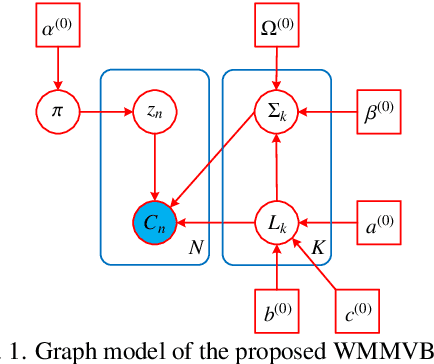
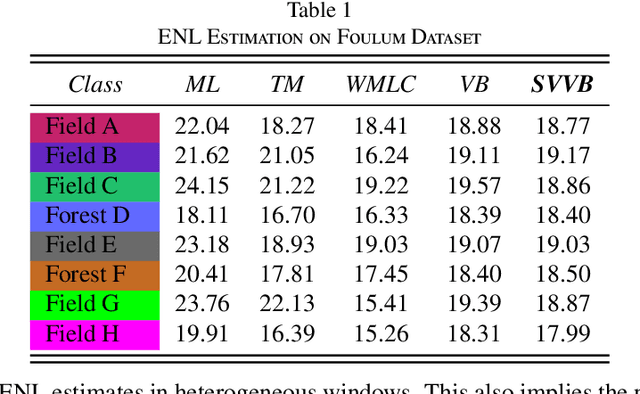
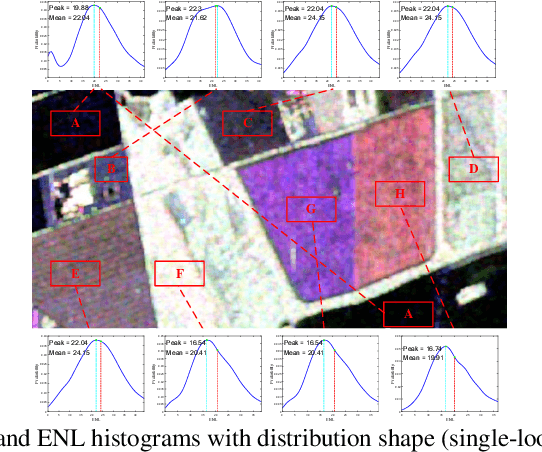
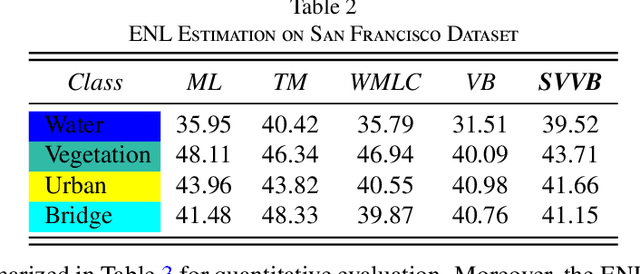
Although various clustering methods have been successfully applied to polarimetric synthetic aperture radar (PolSAR) image clustering tasks, most of the available approaches fail to realize automatic determination of cluster number, nor have they derived an exact distribution for the number of looks. To overcome these limitations and achieve robust unsupervised classification of PolSAR images, this paper proposes the variational Bayesian Wishart mixture model (VBWMM), where variational Bayesian expectation maximization (VBEM) technique is applied to estimate the variational posterior distribution of model parameters iteratively. Besides, covariance matrix similarity and geometric similarity are combined to incorporate spatial information of PolSAR images. Furthermore, we derive a new distribution named inverse gamma-gamma (IGG) prior that originates from the log-likelihood function of proposed model to enable efficient handling of number of looks. As a result, we obtain a closed-form variational lower bound, which can be used to evaluate the convergence of proposed model. We validate the superiority of proposed method in clustering performance on four real-measured datasets and demonstrate significant improvements towards conventional methods. As a by-product, the experiments show that our proposed IGG prior is effective in estimating the number of looks.
Quicksilver: Fast Predictive Image Registration - a Deep Learning Approach
Jul 19, 2017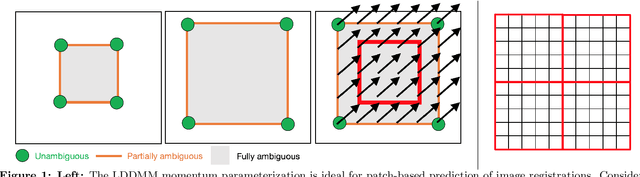
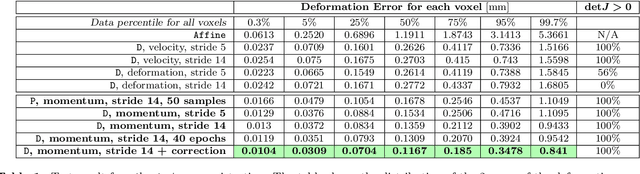
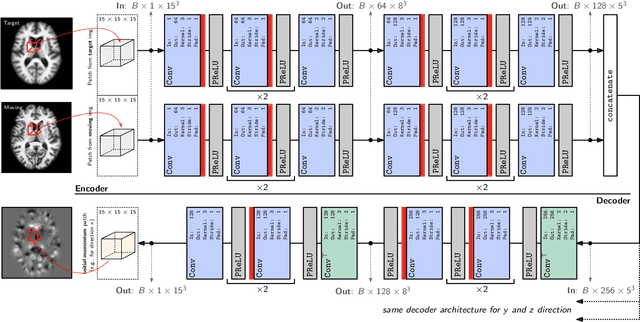
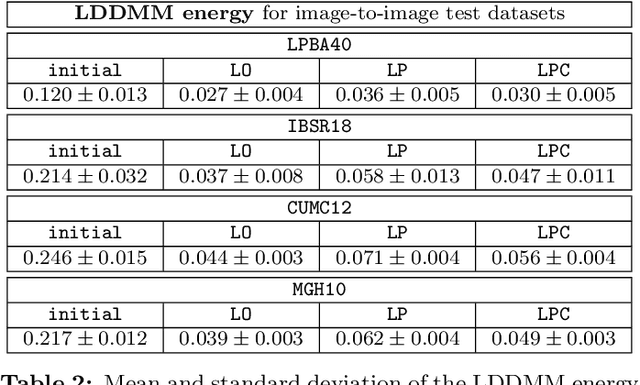
This paper introduces Quicksilver, a fast deformable image registration method. Quicksilver registration for image-pairs works by patch-wise prediction of a deformation model based directly on image appearance. A deep encoder-decoder network is used as the prediction model. While the prediction strategy is general, we focus on predictions for the Large Deformation Diffeomorphic Metric Mapping (LDDMM) model. Specifically, we predict the momentum-parameterization of LDDMM, which facilitates a patch-wise prediction strategy while maintaining the theoretical properties of LDDMM, such as guaranteed diffeomorphic mappings for sufficiently strong regularization. We also provide a probabilistic version of our prediction network which can be sampled during the testing time to calculate uncertainties in the predicted deformations. Finally, we introduce a new correction network which greatly increases the prediction accuracy of an already existing prediction network. We show experimental results for uni-modal atlas-to-image as well as uni- / multi- modal image-to-image registrations. These experiments demonstrate that our method accurately predicts registrations obtained by numerical optimization, is very fast, achieves state-of-the-art registration results on four standard validation datasets, and can jointly learn an image similarity measure. Quicksilver is freely available as an open-source software.
Identifying Melanoma Images using EfficientNet Ensemble: Winning Solution to the SIIM-ISIC Melanoma Classification Challenge
Oct 11, 2020
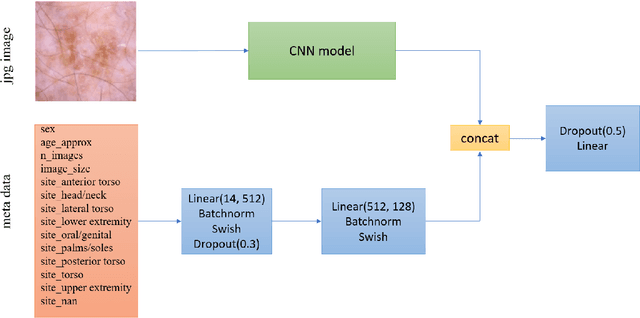
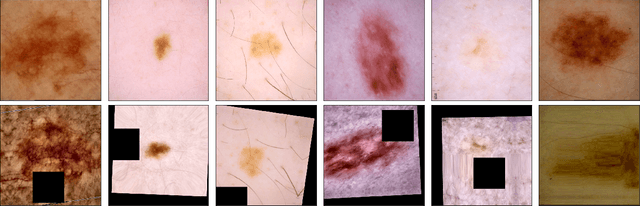
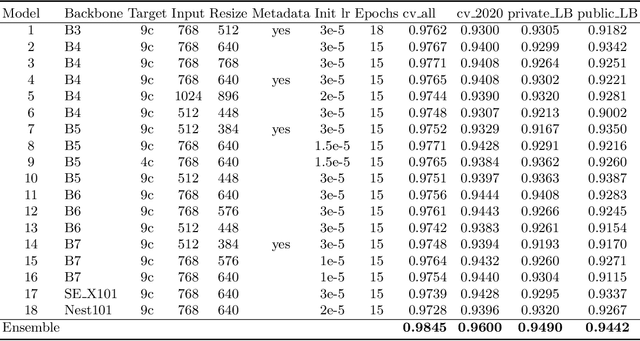
We present our winning solution to the SIIM-ISIC Melanoma Classification Challenge. It is an ensemble of convolutions neural network (CNN) models with different backbones and input sizes, most of which are image-only models while a few of them used image-level and patient-level metadata. The keys to our winning are: (1) stable validation scheme (2) good choice of model target (3) carefully tuned pipeline and (4) ensembling with very diverse models. The winning submission scored 0.9600 AUC on cross validation and 0.9490 AUC on private leaderboard.
Image Compression Based on Compressive Sensing: End-to-End Comparison with JPEG
Jul 28, 2018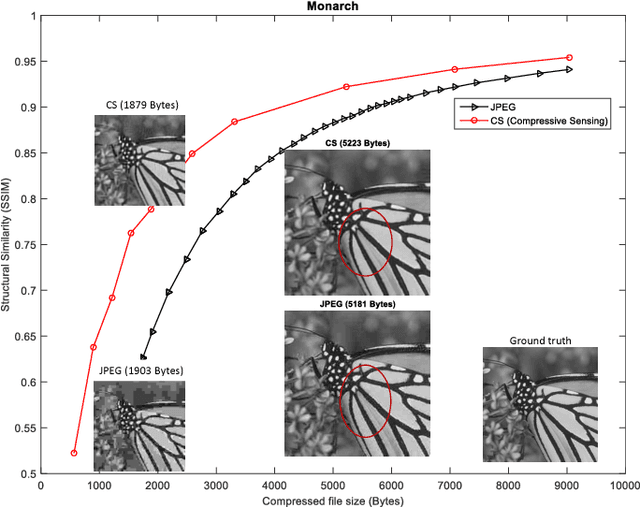
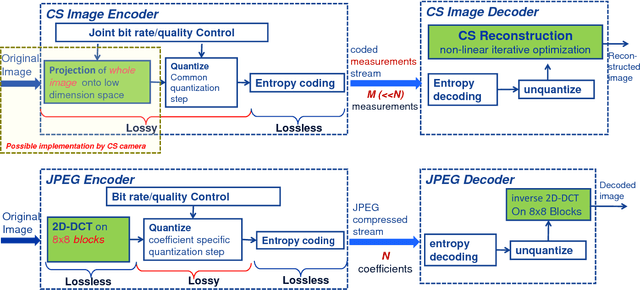
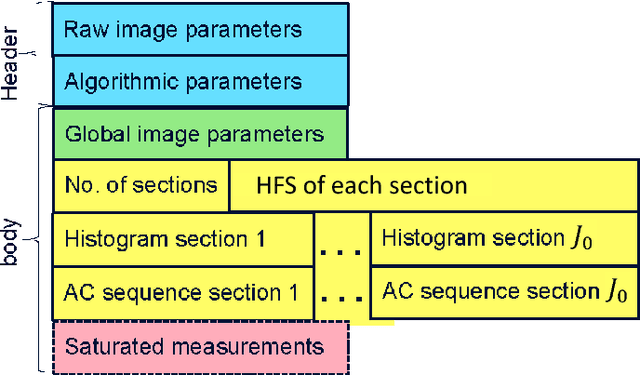
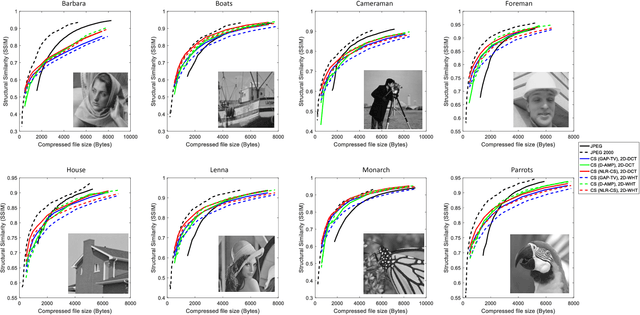
We present an end-to-end image compression system based on compressive sensing. The presented system integrates the conventional scheme of compressive sampling and reconstruction with quantization and entropy coding. The compression performance, in terms of decoded image quality versus data rate, is shown to be comparable with JPEG and significantly better at the low rate range. We study the parameters that influence the system performance, including (i) the choice of sensing matrix, (ii) the trade-off between quantization and compression ratio, and (iii) the reconstruction algorithms. We propose an effective method to jointly control the quantization step and compression ratio in order to achieve near optimal quality at any given bit rate. Furthermore, our proposed image compression system can be directly used in the compressive sensing camera, e.g. the single pixel camera, to construct a hardware compressive sampling system.
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
Jan 11, 2019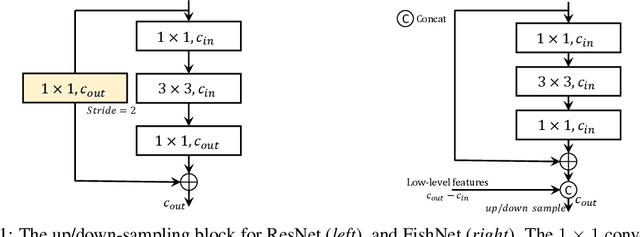
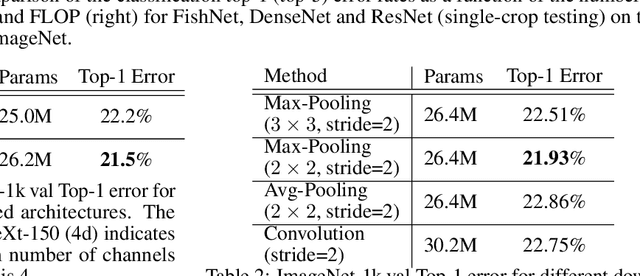
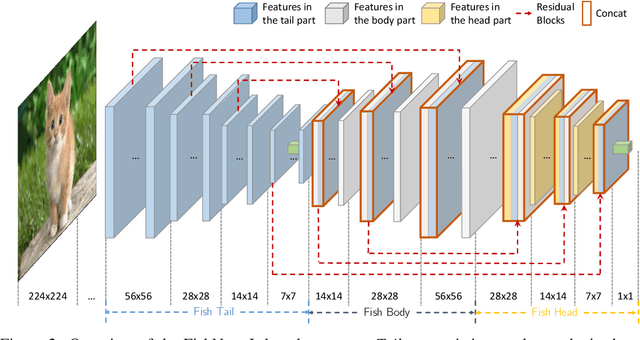
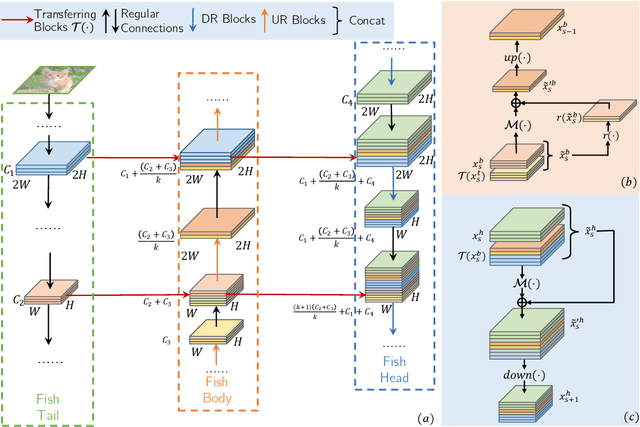
The basic principles in designing convolutional neural network (CNN) structures for predicting objects on different levels, e.g., image-level, region-level, and pixel-level are diverging. Generally, network structures designed specifically for image classification are directly used as default backbone structure for other tasks including detection and segmentation, but there is seldom backbone structure designed under the consideration of unifying the advantages of networks designed for pixel-level or region-level predicting tasks, which may require very deep features with high resolution. Towards this goal, we design a fish-like network, called FishNet. In FishNet, the information of all resolutions is preserved and refined for the final task. Besides, we observe that existing works still cannot \emph{directly} propagate the gradient information from deep layers to shallow layers. Our design can better handle this problem. Extensive experiments have been conducted to demonstrate the remarkable performance of the FishNet. In particular, on ImageNet-1k, the accuracy of FishNet is able to surpass the performance of DenseNet and ResNet with fewer parameters. FishNet was applied as one of the modules in the winning entry of the COCO Detection 2018 challenge. The code is available at https://github.com/kevin-ssy/FishNet.
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020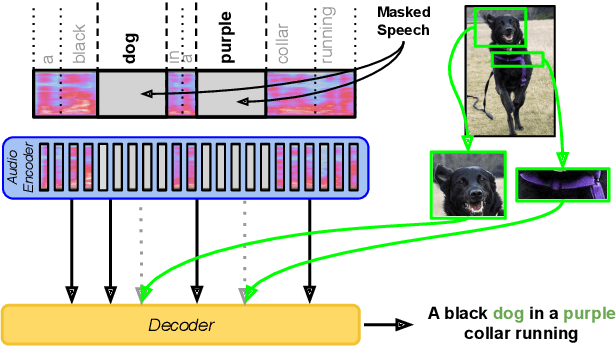
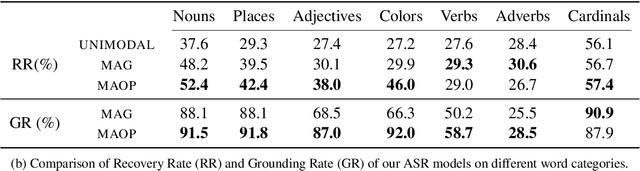
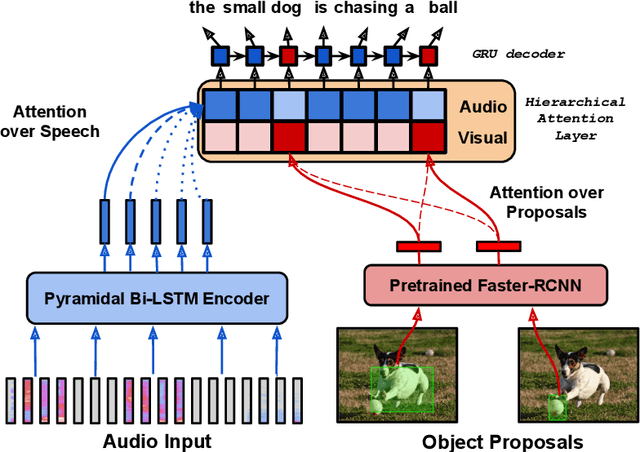
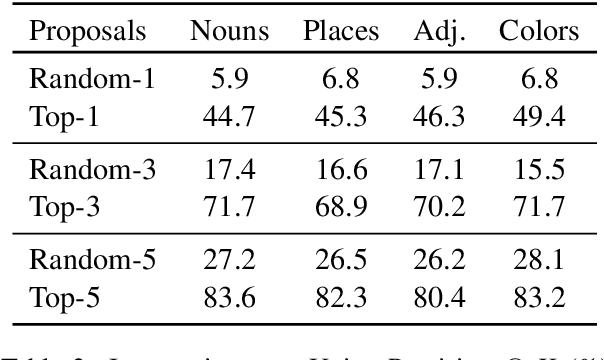
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
Nonparametric Trace Regression in High Dimensions via Sign Series Representation
May 04, 2021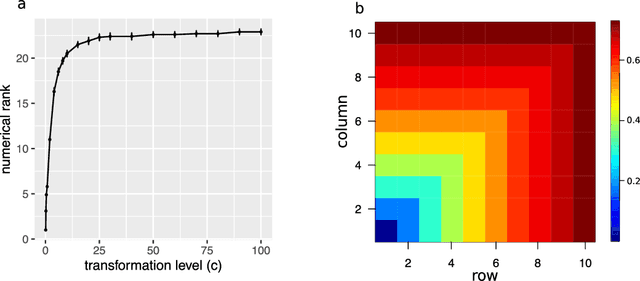

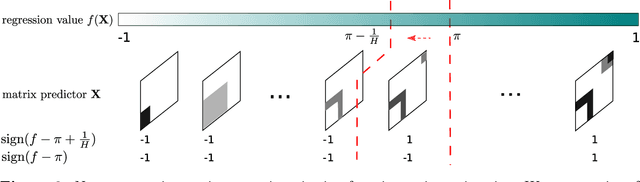

Learning of matrix-valued data has recently surged in a range of scientific and business applications. Trace regression is a widely used method to model effects of matrix predictors and has shown great success in matrix learning. However, nearly all existing trace regression solutions rely on two assumptions: (i) a known functional form of the conditional mean, and (ii) a global low-rank structure in the entire range of the regression function, both of which may be violated in practice. In this article, we relax these assumptions by developing a general framework for nonparametric trace regression models via structured sign series representations of high dimensional functions. The new model embraces both linear and nonlinear trace effects, and enjoys rank invariance to order-preserving transformations of the response. In the context of matrix completion, our framework leads to a substantially richer model based on what we coin as the "sign rank" of a matrix. We show that the sign series can be statistically characterized by weighted classification tasks. Based on this connection, we propose a learning reduction approach to learn the regression model via a series of classifiers, and develop a parallelable computation algorithm to implement sign series aggregations. We establish the excess risk bounds, estimation error rates, and sample complexities. Our proposal provides a broad nonparametric paradigm to many important matrix learning problems, including matrix regression, matrix completion, multi-task learning, and compressed sensing. We demonstrate the advantages of our method through simulations and two applications, one on brain connectivity study and the other on high-rank image completion.