 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Local Structure Consistency based Heterogeneous Remote Sensing Change Detection
Aug 29, 2020
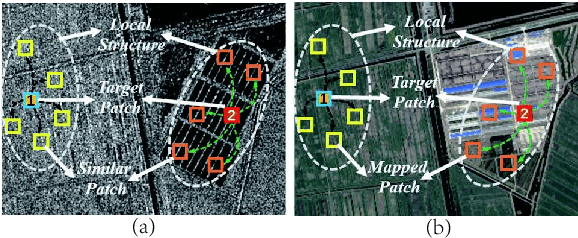

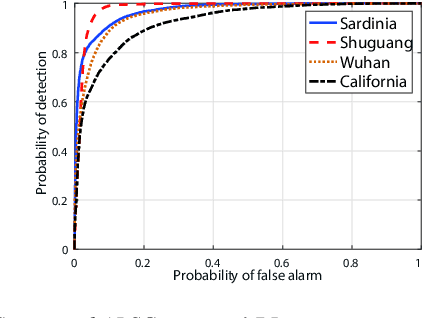

Change detection of heterogeneous remote sensing images is an important and challenging topic in remote sensing for emergency situation resulting from nature disaster. Due to the different imaging mechanisms of heterogeneous sensors, it is difficult to directly compare the images. To address this challenge, we explore an unsupervised change detection method based on adaptive local structure consistency (ALSC) between heterogeneous images in this letter, which constructs an adaptive graph representing the local structure for each patch in one image domain and then projects this graph to the other image domain to measure the change level. This local structure consistency exploits the fact that the heterogeneous images share the same structure information for the same ground object, which is imaging modality-invariant. To avoid the leakage of heterogeneous data, the pixelwise change image is calculated in the same image domain by graph projection. Experiment results demonstrate the effectiveness of the proposed ALSC based change detection method by comparing with some state-of-the-art methods.
FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
Jan 11, 2019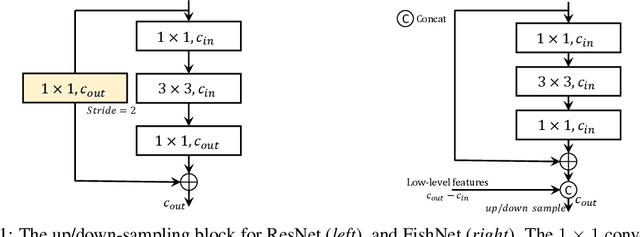
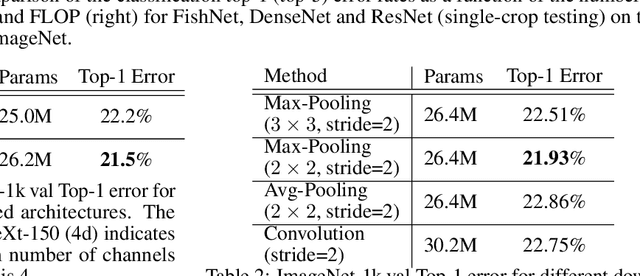
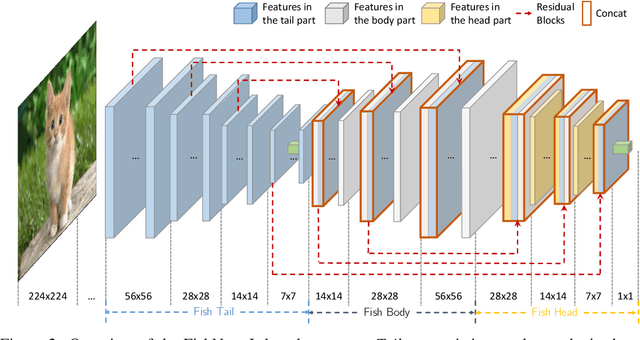
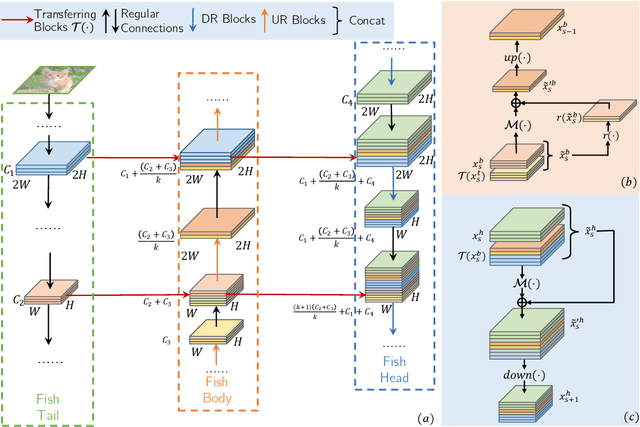
The basic principles in designing convolutional neural network (CNN) structures for predicting objects on different levels, e.g., image-level, region-level, and pixel-level are diverging. Generally, network structures designed specifically for image classification are directly used as default backbone structure for other tasks including detection and segmentation, but there is seldom backbone structure designed under the consideration of unifying the advantages of networks designed for pixel-level or region-level predicting tasks, which may require very deep features with high resolution. Towards this goal, we design a fish-like network, called FishNet. In FishNet, the information of all resolutions is preserved and refined for the final task. Besides, we observe that existing works still cannot \emph{directly} propagate the gradient information from deep layers to shallow layers. Our design can better handle this problem. Extensive experiments have been conducted to demonstrate the remarkable performance of the FishNet. In particular, on ImageNet-1k, the accuracy of FishNet is able to surpass the performance of DenseNet and ResNet with fewer parameters. FishNet was applied as one of the modules in the winning entry of the COCO Detection 2018 challenge. The code is available at https://github.com/kevin-ssy/FishNet.
Evolving Deep Convolutional Neural Networks for Hyperspectral Image Denoising
Aug 15, 2020Hyperspectral images (HSIs) are susceptible to various noise factors leading to the loss of information, and the noise restricts the subsequent HSIs object detection and classification tasks. In recent years, learning-based methods have demonstrated their superior strengths in denoising the HSIs. Unfortunately, most of the methods are manually designed based on the extensive expertise that is not necessarily available to the users interested. In this paper, we propose a novel algorithm to automatically build an optimal Convolutional Neural Network (CNN) to effectively denoise HSIs. Particularly, the proposed algorithm focuses on the architectures and the initialization of the connection weights of the CNN. The experiments of the proposed algorithm have been well-designed and compared against the state-of-the-art peer competitors, and the experimental results demonstrate the competitive performance of the proposed algorithm in terms of the different evaluation metrics, visual assessments, and the computational complexity.
Ordinal Neural Network Transformation Models: Deep and interpretable regression models for ordinal outcomes
Oct 26, 2020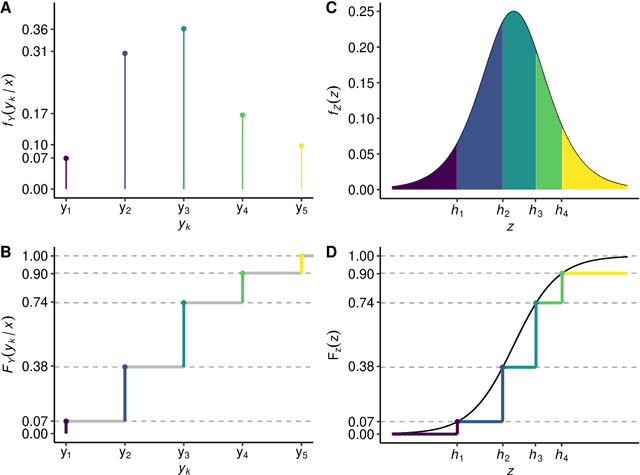
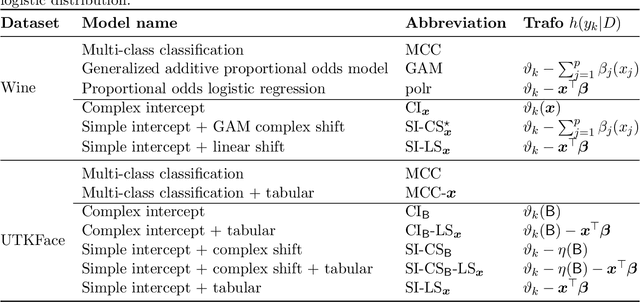
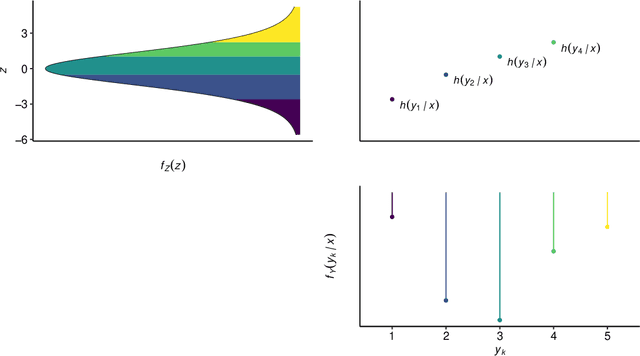
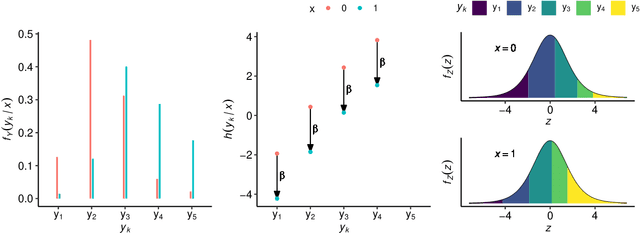
Outcomes with a natural order commonly occur in prediction tasks and oftentimes the available input data are a mixture of complex data, like images, and tabular predictors. Although deep Learning (DL) methods have shown outstanding performance on image classification, most models treat ordered outcomes as unordered and lack interpretability. In contrast, classical ordinal regression models yield interpretable predictor effects but are limited to tabular input data. Here, we present the highly modular class of ordinal neural network transformation models (ONTRAMs). Transformation models use a parametric transformation function and a simple distribution to trade off flexibility and interpretability of individual model components. In ONTRAMs, this trade-off is achieved by additively decomposing the transformation function into terms for the tabular and image data using a set of jointly trained neural networks. We show that the most flexible ONTRAMs achieve on-par performance with DL classifiers while outperforming them in training speed. We discuss how to interpret components of ONTRAMs in general and in the case of correlated tabular and image data. Taken together, ONTRAMs join benefits of DL and distributional regression to create interpretable prediction models for ordinal outcomes.
A Review on Near Duplicate Detection of Images using Computer Vision Techniques
Sep 07, 2020



Nowadays, digital content is widespread and simply redistributable, either lawfully or unlawfully. For example, after images are posted on the internet, other web users can modify them and then repost their versions, thereby generating near-duplicate images. The presence of near-duplicates affects the performance of the search engines critically. Computer vision is concerned with the automatic extraction, analysis and understanding of useful information from digital images. The main application of computer vision is image understanding. There are several tasks in image understanding such as feature extraction, object detection, object recognition, image cleaning, image transformation, etc. There is no proper survey in literature related to near duplicate detection of images. In this paper, we review the state-of-the-art computer vision-based approaches and feature extraction methods for the detection of near duplicate images. We also discuss the main challenges in this field and how other researchers addressed those challenges. This review provides research directions to the fellow researchers who are interested to work in this field.
Matthews Correlation Coefficient Loss for Deep Convolutional Networks: Application to Skin Lesion Segmentation
Oct 26, 2020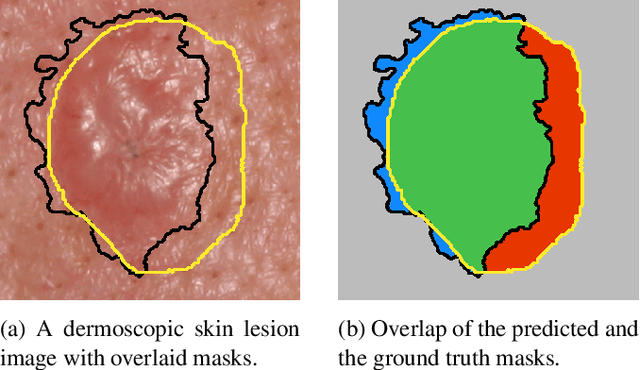
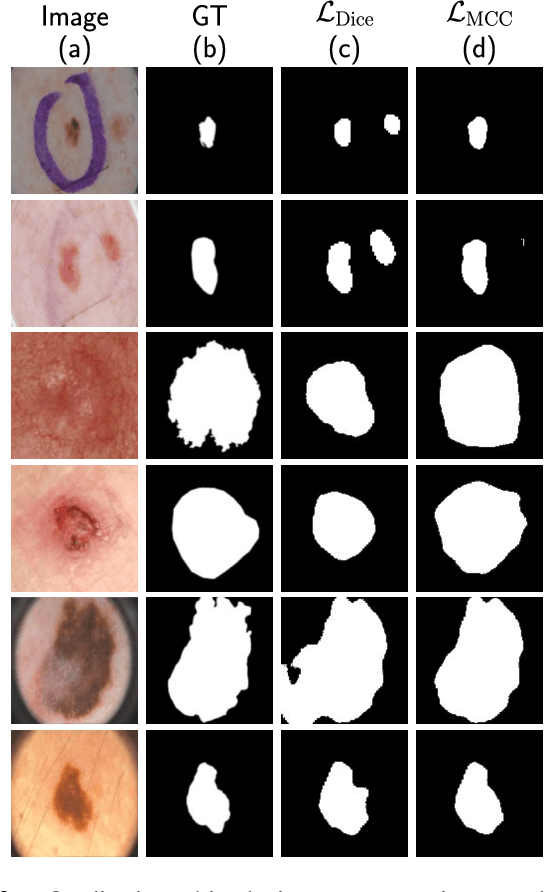
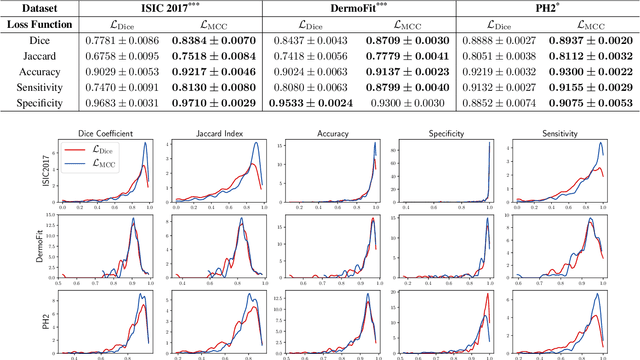
The segmentation of skin lesions is a crucial task in clinical decision support systems for the computer aided diagnosis of skin lesions. Although deep learning based approaches have improved segmentation performance, these models are often susceptible to class imbalance in the data, particularly, the fraction of the image occupied by the background healthy skin. Despite variations of the popular Dice loss function being proposed to tackle the class imbalance problem, the Dice loss formulation does not penalize misclassifications of the background pixels. We propose a novel metric-based loss function using the Matthews correlation coefficient, a metric that has been shown to be efficient in scenarios with skewed class distributions, and use it to optimize deep segmentation models. Evaluations on three dermoscopic image datasets: the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset, the DermoFit Image Library, and the PH2 dataset show that models trained using the proposed loss function outperform those trained using Dice loss by 11.25%, 4.87%, and 0.76% respectively in the mean Jaccard index. We plan to release the code on GitHub at https://github.com/kakumarabhishek/MCC-Loss upon publication of this paper.
A Closer Look at Self-training for Zero-Label Semantic Segmentation
Apr 21, 2021
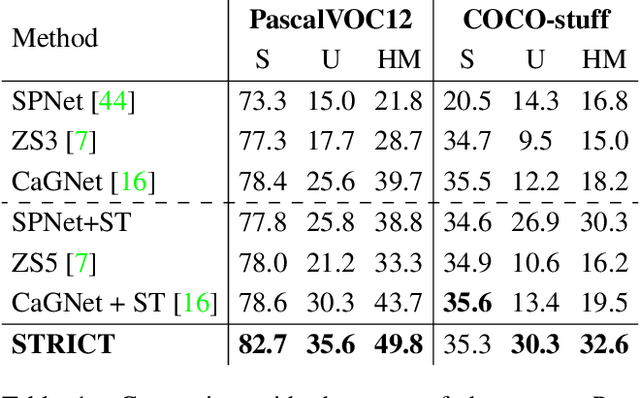
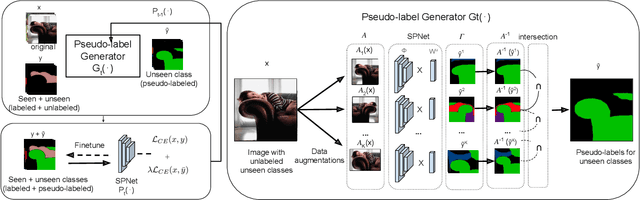
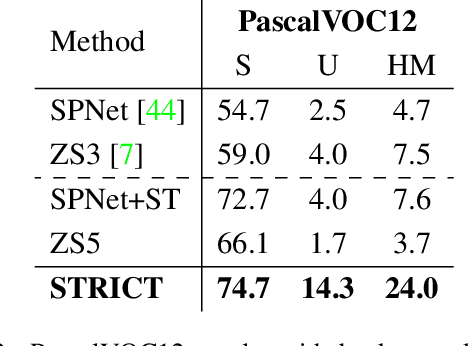
Being able to segment unseen classes not observed during training is an important technical challenge in deep learning, because of its potential to reduce the expensive annotation required for semantic segmentation. Prior zero-label semantic segmentation works approach this task by learning visual-semantic embeddings or generative models. However, they are prone to overfitting on the seen classes because there is no training signal for them. In this paper, we study the challenging generalized zero-label semantic segmentation task where the model has to segment both seen and unseen classes at test time. We assume that pixels of unseen classes could be present in the training images but without being annotated. Our idea is to capture the latent information on unseen classes by supervising the model with self-produced pseudo-labels for unlabeled pixels. We propose a consistency regularizer to filter out noisy pseudo-labels by taking the intersections of the pseudo-labels generated from different augmentations of the same image. Our framework generates pseudo-labels and then retrain the model with human-annotated and pseudo-labelled data. This procedure is repeated for several iterations. As a result, our approach achieves the new state-of-the-art on PascalVOC12 and COCO-stuff datasets in the challenging generalized zero-label semantic segmentation setting, surpassing other existing methods addressing this task with more complex strategies.
Is it Enough to Optimize CNN Architectures on ImageNet?
Mar 16, 2021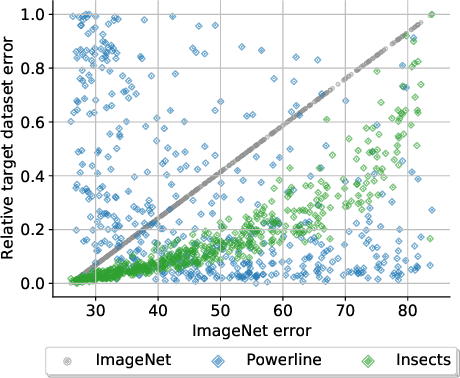
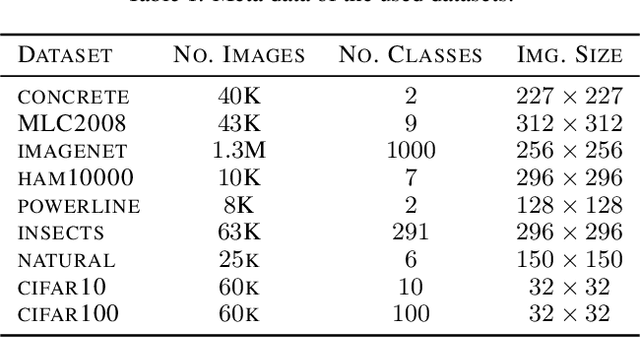
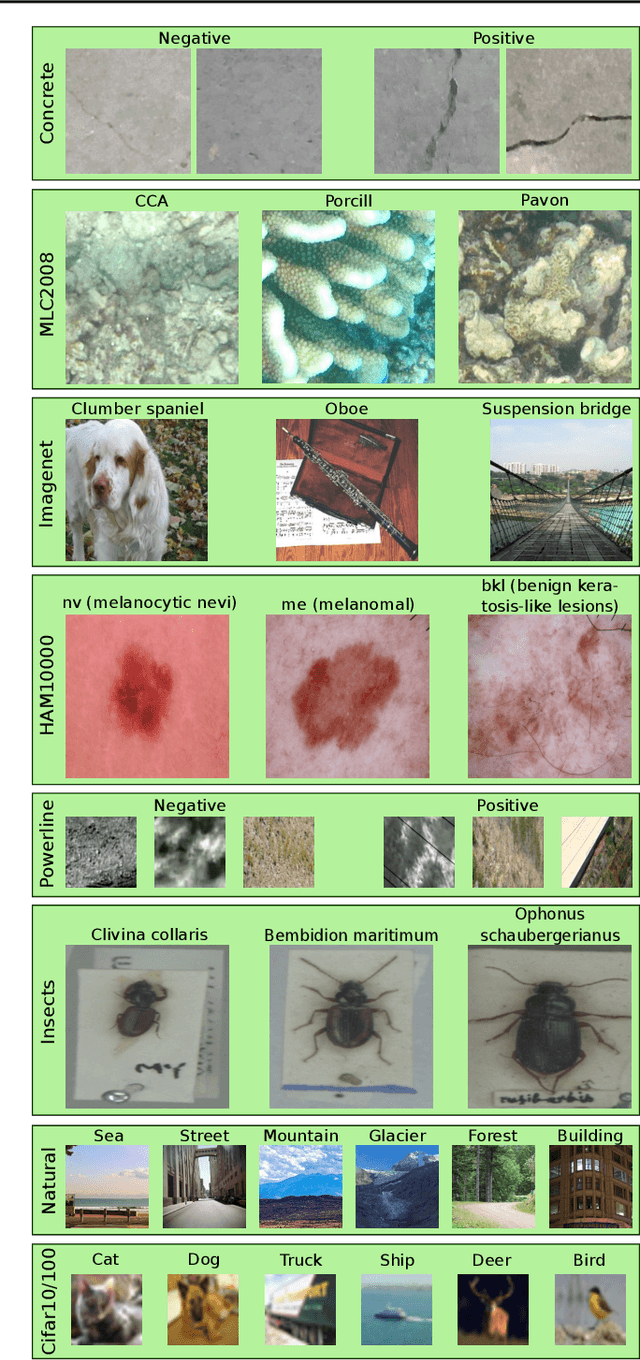
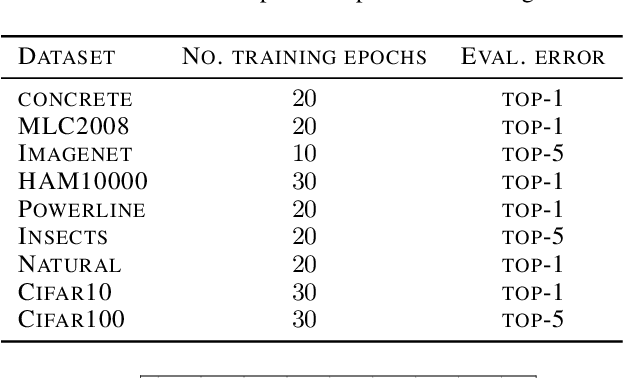
An implicit but pervasive hypothesis of modern computer vision research is that convolutional neural network (CNN) architectures that perform better on ImageNet will also perform better on other vision datasets. We challenge this hypothesis through an extensive empirical study for which we train 500 sampled CNN architectures on ImageNet as well as 8 other image classification datasets from a wide array of application domains. The relationship between architecture and performance varies wildly, depending on the datasets. For some of them, the performance correlation with ImageNet is even negative. Clearly, it is not enough to optimize architectures solely for ImageNet when aiming for progress that is relevant for all applications. Therefore, we identify two dataset-specific performance indicators: the cumulative width across layers as well as the total depth of the network. Lastly, we show that the range of dataset variability covered by ImageNet can be significantly extended by adding ImageNet subsets restricted to few classes.
Embedded Computer Vision System Applied to a Four-Legged Line Follower Robot
Jan 12, 2021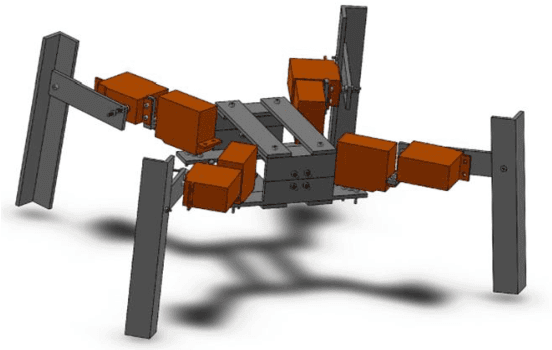
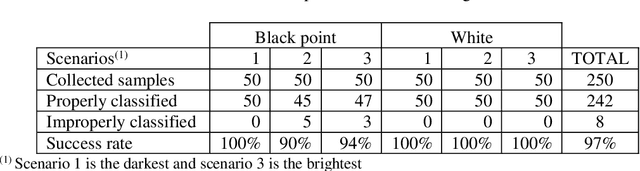
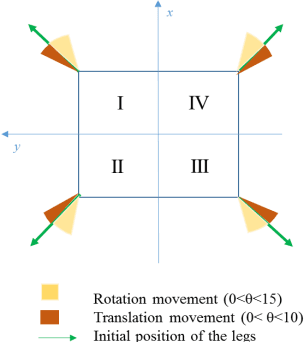

Robotics can be defined as the connection of perception to action. Taking this further, this project aims to drive a robot using an automated computer vision embedded system, connecting the robot's vision to its behavior. In order to implement a color recognition system on the robot, open source tools are chosen, such as Processing language, Android system, Arduino platform and Pixy camera. The constraints are clear: simplicity, replicability and financial viability. In order to integrate Robotics, Computer Vision and Image Processing, the robot is applied on a typical mobile robot's issue: line following. The problem of distinguishing the path from the background is analyzed through different approaches: the popular Otsu's Method, thresholding based on color combinations through experimentation and color tracking via hue and saturation. Decision making of where to move next is based on the line center of the path and is fully automated. Using a four-legged robot as platform and a camera as its only sensor, the robot is capable of successfully follow a line. From capturing the image to moving the robot, it's evident how integrative Robotics can be. The issue of this paper alone involves knowledge of Mechanical Engineering, Electronics, Control Systems and Programming. Everything related to this work was documented and made available on an open source online page, so it can be useful in learning and experimenting with robotics.
Processing of incomplete images by (graph) convolutional neural networks
Oct 26, 2020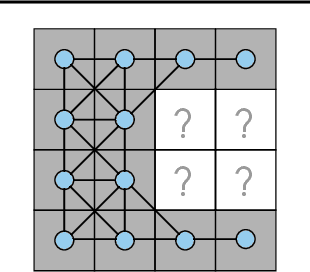

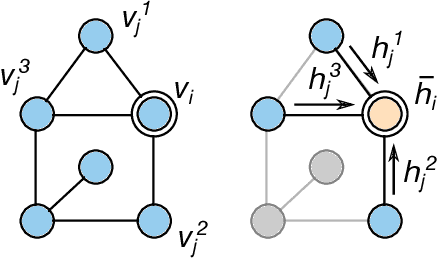
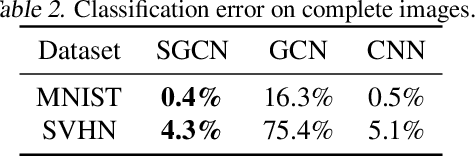
We investigate the problem of training neural networks from incomplete images without replacing missing values. For this purpose, we first represent an image as a graph, in which missing pixels are entirely ignored. The graph image representation is processed using a spatial graph convolutional network (SGCN) -- a type of graph convolutional networks, which is a proper generalization of classical CNNs operating on images. On one hand, our approach avoids the problem of missing data imputation while, on the other hand, there is a natural correspondence between CNNs and SGCN. Experiments confirm that our approach performs better than analogical CNNs with the imputation of missing values on typical classification and reconstruction tasks.