 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distilling Vision-Language Models on Millions of Videos
Jan 11, 2024
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video-language model is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%.
Textual Prompt Guided Image Restoration
Dec 11, 2023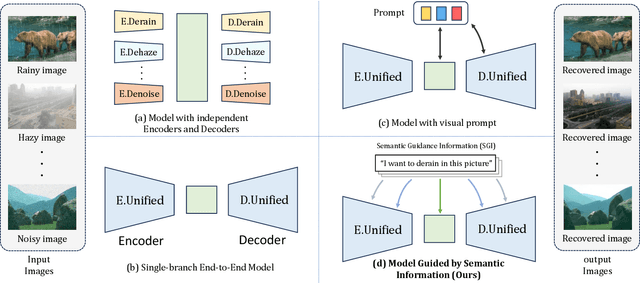
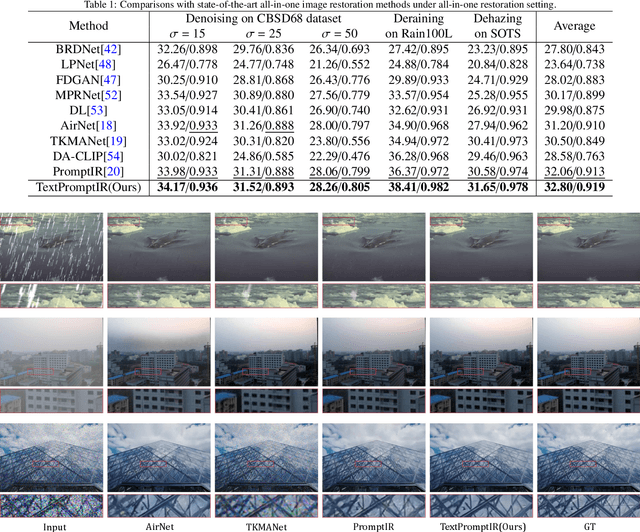
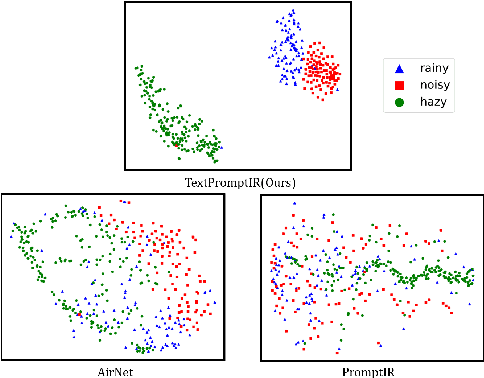
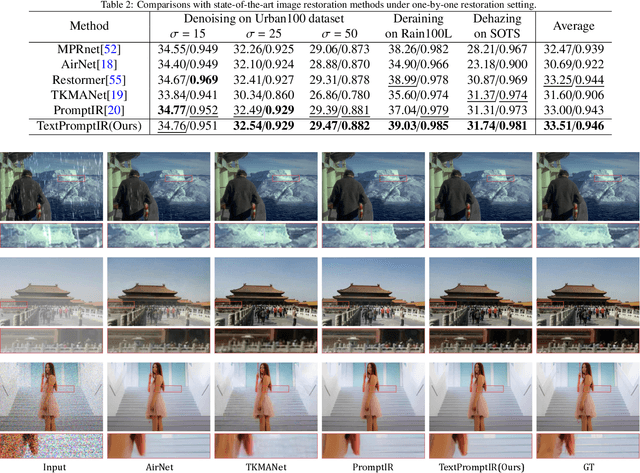
Image restoration has always been a cutting-edge topic in the academic and industrial fields of computer vision. Since degradation signals are often random and diverse, "all-in-one" models that can do blind image restoration have been concerned in recent years. Early works require training specialized headers and tails to handle each degradation of concern, which are manually cumbersome. Recent works focus on learning visual prompts from data distribution to identify degradation type. However, the prompts employed in most of models are non-text, lacking sufficient emphasis on the importance of human-in-the-loop. In this paper, an effective textual prompt guided image restoration model has been proposed. In this model, task-specific BERT is fine-tuned to accurately understand user's instructions and generating textual prompt guidance. Depth-wise multi-head transposed attentions and gated convolution modules are designed to bridge the gap between textual prompts and visual features. The proposed model has innovatively introduced semantic prompts into low-level visual domain. It highlights the potential to provide a natural, precise, and controllable way to perform image restoration tasks. Extensive experiments have been done on public denoising, dehazing and deraining datasets. The experiment results demonstrate that, compared with popular state-of-the-art methods, the proposed model can obtain much more superior performance, achieving accurate recognition and removal of degradation without increasing model's complexity. Related source codes and data will be publicly available on github site https://github.com/MoTong-AI-studio/TextPromptIR.
RSUD20K: A Dataset for Road Scene Understanding In Autonomous Driving
Jan 14, 2024Road scene understanding is crucial in autonomous driving, enabling machines to perceive the visual environment. However, recent object detectors tailored for learning on datasets collected from certain geographical locations struggle to generalize across different locations. In this paper, we present RSUD20K, a new dataset for road scene understanding, comprised of over 20K high-resolution images from the driving perspective on Bangladesh roads, and includes 130K bounding box annotations for 13 objects. This challenging dataset encompasses diverse road scenes, narrow streets and highways, featuring objects from different viewpoints and scenes from crowded environments with densely cluttered objects and various weather conditions. Our work significantly improves upon previous efforts, providing detailed annotations and increased object complexity. We thoroughly examine the dataset, benchmarking various state-of-the-art object detectors and exploring large vision models as image annotators.
Masked Contrastive Reconstruction for Cross-modal Medical Image-Report Retrieval
Dec 27, 2023Cross-modal medical image-report retrieval task plays a significant role in clinical diagnosis and various medical generative tasks. Eliminating heterogeneity between different modalities to enhance semantic consistency is the key challenge of this task. The current Vision-Language Pretraining (VLP) models, with cross-modal contrastive learning and masked reconstruction as joint training tasks, can effectively enhance the performance of cross-modal retrieval. This framework typically employs dual-stream inputs, using unmasked data for cross-modal contrastive learning and masked data for reconstruction. However, due to task competition and information interference caused by significant differences between the inputs of the two proxy tasks, the effectiveness of representation learning for intra-modal and cross-modal features is limited. In this paper, we propose an efficient VLP framework named Masked Contrastive and Reconstruction (MCR), which takes masked data as the sole input for both tasks. This enhances task connections, reducing information interference and competition between them, while also substantially decreasing the required GPU memory and training time. Moreover, we introduce a new modality alignment strategy named Mapping before Aggregation (MbA). Unlike previous methods, MbA maps different modalities to a common feature space before conducting local feature aggregation, thereby reducing the loss of fine-grained semantic information necessary for improved modality alignment. Qualitative and quantitative experiments conducted on the MIMIC-CXR dataset validate the effectiveness of our approach, demonstrating state-of-the-art performance in medical cross-modal retrieval tasks.
Masked Attribute Description Embedding for Cloth-Changing Person Re-identification
Jan 12, 2024Cloth-changing person re-identification (CC-ReID) aims to match persons who change clothes over long periods. The key challenge in CC-ReID is to extract clothing-independent features, such as face, hairstyle, body shape, and gait. Current research mainly focuses on modeling body shape using multi-modal biological features (such as silhouettes and sketches). However, it does not fully leverage the personal description information hidden in the original RGB image. Considering that there are certain attribute descriptions which remain unchanged after the changing of cloth, we propose a Masked Attribute Description Embedding (MADE) method that unifies personal visual appearance and attribute description for CC-ReID. Specifically, handling variable clothing-sensitive information, such as color and type, is challenging for effective modeling. To address this, we mask the clothing and color information in the personal attribute description extracted through an attribute detection model. The masked attribute description is then connected and embedded into Transformer blocks at various levels, fusing it with the low-level to high-level features of the image. This approach compels the model to discard clothing information. Experiments are conducted on several CC-ReID benchmarks, including PRCC, LTCC, Celeb-reID-light, and LaST. Results demonstrate that MADE effectively utilizes attribute description, enhancing cloth-changing person re-identification performance, and compares favorably with state-of-the-art methods. The code is available at https://github.com/moon-wh/MADE.
Superpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering
Dec 24, 2023Hyperspectral images (HSIs) provide exceptional spatial and spectral resolution of a scene, crucial for various remote sensing applications. However, the high dimensionality, presence of noise and outliers, and the need for precise labels of HSIs present significant challenges to HSIs analysis, motivating the development of performant HSI clustering algorithms. This paper introduces a novel unsupervised HSI clustering algorithm, Superpixel-based and Spatially-regularized Diffusion Learning (S2DL), which addresses these challenges by incorporating rich spatial information encoded in HSIs into diffusion geometry-based clustering. S2DL employs the Entropy Rate Superpixel (ERS) segmentation technique to partition an image into superpixels, then constructs a spatially-regularized diffusion graph using the most representative high-density pixels. This approach reduces computational burden while preserving accuracy. Cluster modes, serving as exemplars for underlying cluster structure, are identified as the highest-density pixels farthest in diffusion distance from other highest-density pixels. These modes guide the labeling of the remaining representative pixels from ERS superpixels. Finally, majority voting is applied to the labels assigned within each superpixel to propagate labels to the rest of the image. This spatial-spectral approach simultaneously simplifies graph construction, reduces computational cost, and improves clustering performance. S2DL's performance is illustrated with extensive experiments on three publicly available, real-world HSIs: Indian Pines, Salinas, and Salinas A. Additionally, we apply S2DL to landscape-scale, unsupervised mangrove species mapping in the Mai Po Nature Reserve, Hong Kong, using a Gaofen-5 HSI. The success of S2DL in these diverse numerical experiments indicates its efficacy on a wide range of important unsupervised remote sensing analysis tasks.
Spatial-Semantic Collaborative Cropping for User Generated Content
Jan 16, 2024A large amount of User Generated Content (UGC) is uploaded to the Internet daily and displayed to people world-widely through the client side (e.g., mobile and PC). This requires the cropping algorithms to produce the aesthetic thumbnail within a specific aspect ratio on different devices. However, existing image cropping works mainly focus on landmark or landscape images, which fail to model the relations among the multi-objects with the complex background in UGC. Besides, previous methods merely consider the aesthetics of the cropped images while ignoring the content integrity, which is crucial for UGC cropping. In this paper, we propose a Spatial-Semantic Collaborative cropping network (S2CNet) for arbitrary user generated content accompanied by a new cropping benchmark. Specifically, we first mine the visual genes of the potential objects. Then, the suggested adaptive attention graph recasts this task as a procedure of information association over visual nodes. The underlying spatial and semantic relations are ultimately centralized to the crop candidate through differentiable message passing, which helps our network efficiently to preserve both the aesthetics and the content integrity. Extensive experiments on the proposed UGCrop5K and other public datasets demonstrate the superiority of our approach over state-of-the-art counterparts. Our project is available at https://github.com/suyukun666/S2CNet.
EPNet: An Efficient Pyramid Network for Enhanced Single-Image Super-Resolution with Reduced Computational Requirements
Dec 20, 2023Single-image super-resolution (SISR) has seen significant advancements through the integration of deep learning. However, the substantial computational and memory requirements of existing methods often limit their practical application. This paper introduces a new Efficient Pyramid Network (EPNet) that harmoniously merges an Edge Split Pyramid Module (ESPM) with a Panoramic Feature Extraction Module (PFEM) to overcome the limitations of existing methods, particularly in terms of computational efficiency. The ESPM applies a pyramid-based channel separation strategy, boosting feature extraction while maintaining computational efficiency. The PFEM, a novel fusion of CNN and Transformer structures, enables the concurrent extraction of local and global features, thereby providing a panoramic view of the image landscape. Our architecture integrates the PFEM in a manner that facilitates the streamlined exchange of feature information and allows for the further refinement of image texture details. Experimental results indicate that our model outperforms existing state-of-the-art methods in image resolution quality, while considerably decreasing computational and memory costs. This research contributes to the ongoing evolution of efficient and practical SISR methodologies, bearing broader implications for the field of computer vision.
Automatic 3D Multi-modal Ultrasound Segmentation of Human Placenta using Fusion Strategies and Deep Learning
Jan 17, 2024Purpose: Ultrasound is the most commonly used medical imaging modality for diagnosis and screening in clinical practice. Due to its safety profile, noninvasive nature and portability, ultrasound is the primary imaging modality for fetal assessment in pregnancy. Current ultrasound processing methods are either manual or semi-automatic and are therefore laborious, time-consuming and prone to errors, and automation would go a long way in addressing these challenges. Automated identification of placental changes at earlier gestation could facilitate potential therapies for conditions such as fetal growth restriction and pre-eclampsia that are currently detected only at late gestational age, potentially preventing perinatal morbidity and mortality. Methods: We propose an automatic three-dimensional multi-modal (B-mode and power Doppler) ultrasound segmentation of the human placenta using deep learning combined with different fusion strategies.We collected data containing Bmode and power Doppler ultrasound scans for 400 studies. Results: We evaluated different fusion strategies and state-of-the-art image segmentation networks for placenta segmentation based on standard overlap- and boundary-based metrics. We found that multimodal information in the form of B-mode and power Doppler scans outperform any single modality. Furthermore, we found that B-mode and power Doppler input scans fused at the data level provide the best results with a mean Dice Similarity Coefficient (DSC) of 0.849. Conclusion: We conclude that the multi-modal approach of combining B-mode and power Doppler scans is effective in segmenting the placenta from 3D ultrasound scans in a fully automated manner and is robust to quality variation of the datasets.
A gradient-based approach to fast and accurate head motion compensation in cone-beam CT
Jan 17, 2024Cone-beam computed tomography (CBCT) systems, with their portability, present a promising avenue for direct point-of-care medical imaging, particularly in critical scenarios such as acute stroke assessment. However, the integration of CBCT into clinical workflows faces challenges, primarily linked to long scan duration resulting in patient motion during scanning and leading to image quality degradation in the reconstructed volumes. This paper introduces a novel approach to CBCT motion estimation using a gradient-based optimization algorithm, which leverages generalized derivatives of the backprojection operator for cone-beam CT geometries. Building on that, a fully differentiable target function is formulated which grades the quality of the current motion estimate in reconstruction space. We drastically accelerate motion estimation yielding a 19-fold speed-up compared to existing methods. Additionally, we investigate the architecture of networks used for quality metric regression and propose predicting voxel-wise quality maps, favoring autoencoder-like architectures over contracting ones. This modification improves gradient flow, leading to more accurate motion estimation. The presented method is evaluated through realistic experiments on head anatomy. It achieves a reduction in reprojection error from an initial average of 3mm to 0.61mm after motion compensation and consistently demonstrates superior performance compared to existing approaches. The analytic Jacobian for the backprojection operation, which is at the core of the proposed method, is made publicly available. In summary, this paper contributes to the advancement of CBCT integration into clinical workflows by proposing a robust motion estimation approach that enhances efficiency and accuracy, addressing critical challenges in time-sensitive scenarios.