 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DICODerma: A practical approach for metadata management of images in dermatology
Feb 17, 2021

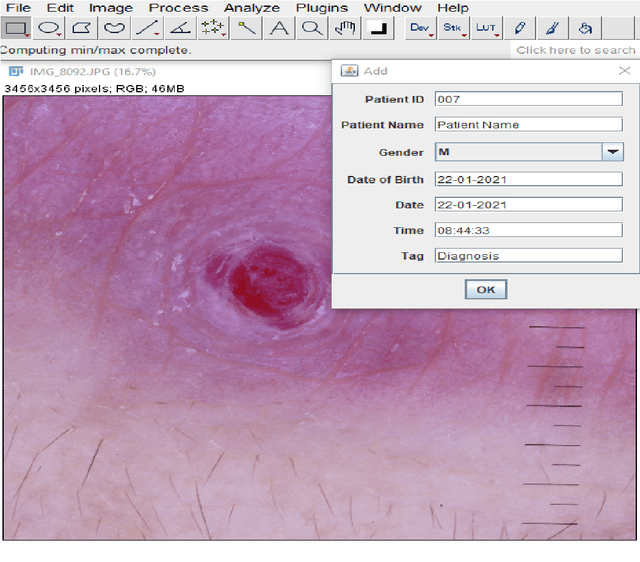
Clinical images are vital for diagnosing and monitoring skin diseases, and their importance has increased with the growing popularity of machine learning. Lack of standards has stifled innovation in dermatological imaging, unlike other image-intensive specialties such as radiology. We investigate the meta-requirements for utilizing the popular DICOM standard for metadata management of images in dermatology. We propose practical design solutions and provide open-source tools to integrate dermatologists' workflow with enterprise imaging systems. Using the tool, dermatologists can tag, search, organize and convert clinical images to the DICOM format. We believe that our less disruptive approach will improve the adoption of standards in the specialty.
What makes fake images detectable? Understanding properties that generalize
Aug 24, 2020
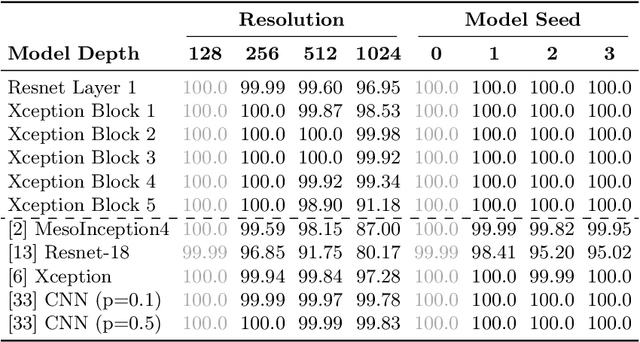
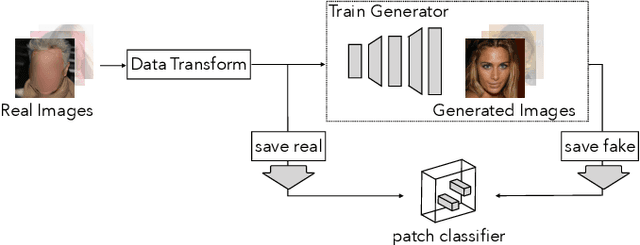
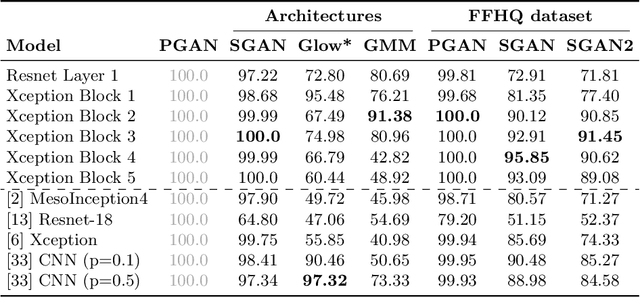
The quality of image generation and manipulation is reaching impressive levels, making it increasingly difficult for a human to distinguish between what is real and what is fake. However, deep networks can still pick up on the subtle artifacts in these doctored images. We seek to understand what properties of fake images make them detectable and identify what generalizes across different model architectures, datasets, and variations in training. We use a patch-based classifier with limited receptive fields to visualize which regions of fake images are more easily detectable. We further show a technique to exaggerate these detectable properties and demonstrate that, even when the image generator is adversarially finetuned against a fake image classifier, it is still imperfect and leaves detectable artifacts in certain image patches. Code is available at https://chail.github.io/patch-forensics/.
A New Variational Model for Joint Image Reconstruction and Motion Estimation in Spatiotemporal Imaging
Dec 18, 2018



We propose a new variational model for joint image reconstruction and motion estimation in spatiotemporal imaging, which is investigated along a general framework that we present with shape theory. This model consists of two components, one for conducting modified static image reconstruction, and the other performs sequentially indirect image registration. For the latter, we generalize the large deformation diffeomorphic metric mapping framework into the sequentially indirect registration setting. The proposed model is compared theoretically against alternative approaches (optical flow based model and diffeomorphic motion models), and we demonstrate that the proposed model has desirable properties in terms of the optimal solution. The theoretical derivations and efficient algorithms are also presented for a time-discretized scenario of the proposed model, which show that the optimal solution of the time-discretized version is consistent with that of the time-continuous one, and most of the computational components is the easy-implemented linearized deformation. The complexity of the algorithm is analyzed as well. This work is concluded by some numerical examples in 2D space + time tomography with very sparse and/or highly noisy data.
High Fidelity Interactive Video Segmentation Using Tensor Decomposition Boundary Loss Convolutional Tessellations and Context Aware Skip Connections
Nov 23, 2020



We provide a high fidelity deep learning algorithm (HyperSeg) for interactive video segmentation tasks using a convolutional network with context-aware skip connections, and compressed, hypercolumn image features combined with a convolutional tessellation procedure. In order to maintain high output fidelity, our model crucially processes and renders all image features in high resolution, without utilizing downsampling or pooling procedures. We maintain this consistent, high grade fidelity efficiently in our model chiefly through two means: (1) We use a statistically-principled tensor decomposition procedure to modulate the number of hypercolumn features and (2) We render these features in their native resolution using a convolutional tessellation technique. For improved pixel level segmentation results, we introduce a boundary loss function; for improved temporal coherence in video data, we include temporal image information in our model. Through experiments, we demonstrate the improved accuracy of our model against baseline models for interactive segmentation tasks using high resolution video data. We also introduce a benchmark video segmentation dataset, the VFX Segmentation Dataset, which contains over 27,046 high resolution video frames, including greenscreen and various composited scenes with corresponding, hand crafted, pixel level segmentations. Our work presents an extension to improvement to state of the art segmentation fidelity with high resolution data and can be used across a broad range of application domains, including VFX pipelines and medical imaging disciplines.
Audio Transformers:Transformer Architectures For Large Scale Audio Understanding. Adieu Convolutions
May 01, 2021
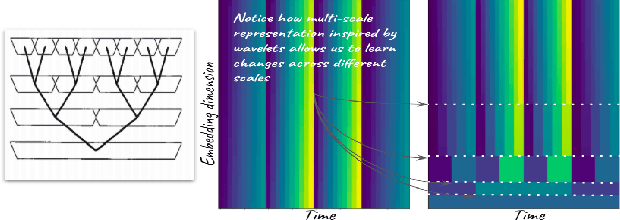
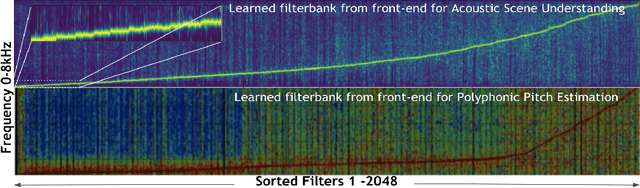
Over the past two decades, CNN architectures have produced compelling models of sound perception and cognition, learning hierarchical organizations of features. Analogous to successes in computer vision, audio feature classification can be optimized for a particular task of interest, over a wide variety of datasets and labels. In fact similar architectures designed for image understanding have proven effective for acoustic scene analysis. Here we propose applying Transformer based architectures without convolutional layers to raw audio signals. On a standard dataset of Free Sound 50K,comprising of 200 categories, our model outperforms convolutional models to produce state of the art results. This is significant as unlike in natural language processing and computer vision, we do not perform unsupervised pre-training for outperforming convolutional architectures. On the same training set, with respect mean aver-age precision benchmarks, we show a significant improvement. We further improve the performance of Transformer architectures by using techniques such as pooling inspired from convolutional net-work designed in the past few years. In addition, we also show how multi-rate signal processing ideas inspired from wavelets, can be applied to the Transformer embeddings to improve the results. We also show how our models learns a non-linear non constant band-width filter-bank, which shows an adaptable time frequency front end representation for the task of audio understanding, different from other tasks e.g. pitch estimation.
CNN+CNN: Convolutional Decoders for Image Captioning
May 23, 2018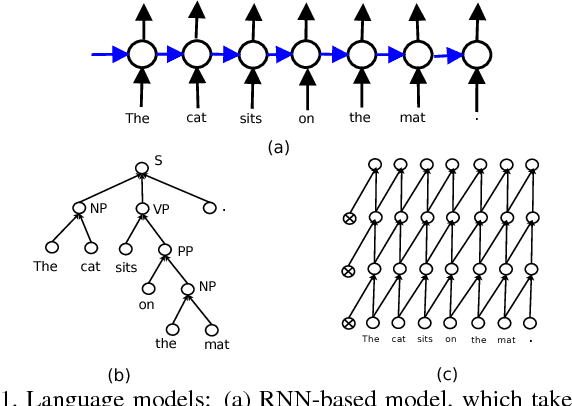
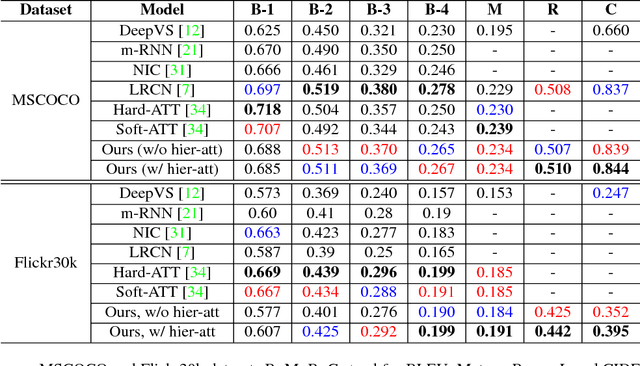
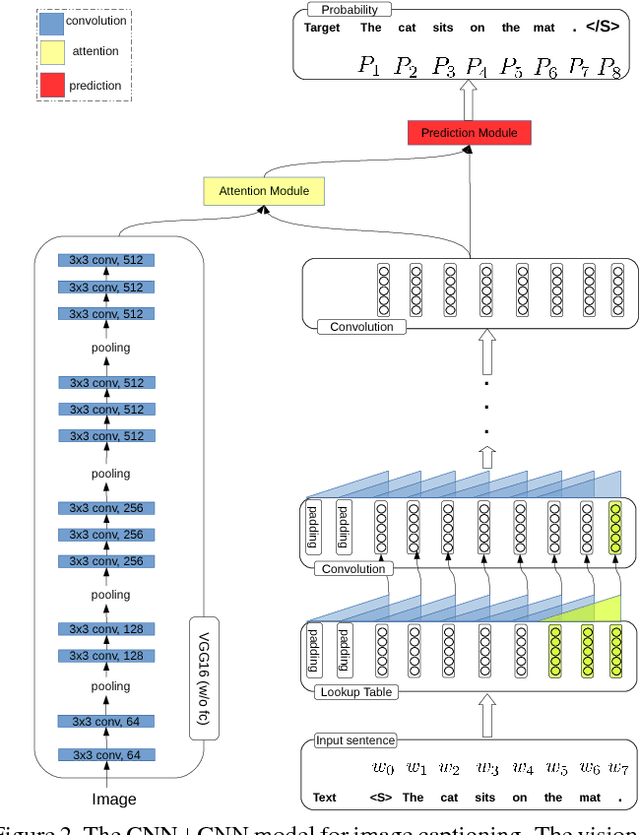
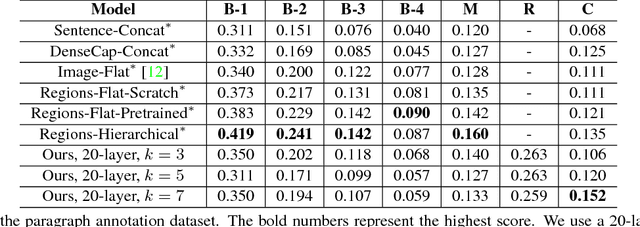
Image captioning is a challenging task that combines the field of computer vision and natural language processing. A variety of approaches have been proposed to achieve the goal of automatically describing an image, and recurrent neural network (RNN) or long-short term memory (LSTM) based models dominate this field. However, RNNs or LSTMs cannot be calculated in parallel and ignore the underlying hierarchical structure of a sentence. In this paper, we propose a framework that only employs convolutional neural networks (CNNs) to generate captions. Owing to parallel computing, our basic model is around 3 times faster than NIC (an LSTM-based model) during training time, while also providing better results. We conduct extensive experiments on MSCOCO and investigate the influence of the model width and depth. Compared with LSTM-based models that apply similar attention mechanisms, our proposed models achieves comparable scores of BLEU-1,2,3,4 and METEOR, and higher scores of CIDEr. We also test our model on the paragraph annotation dataset, and get higher CIDEr score compared with hierarchical LSTMs
Sparse Range-constrained Learning and Its Application for Medical Image Grading
Jul 11, 2018
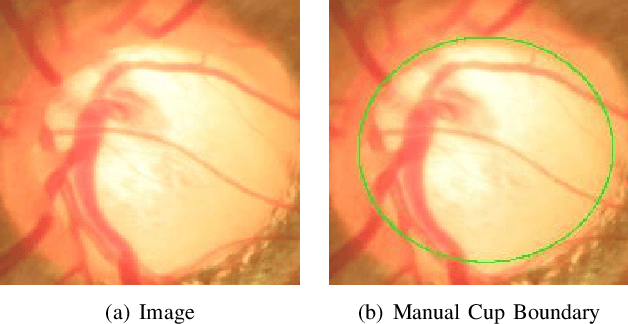
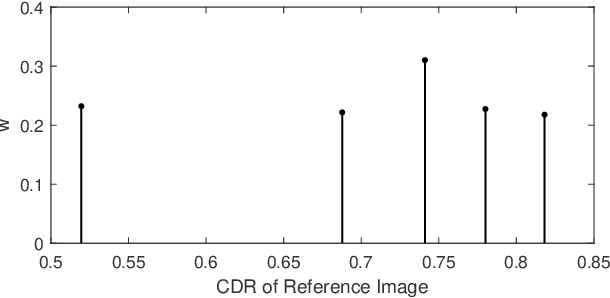
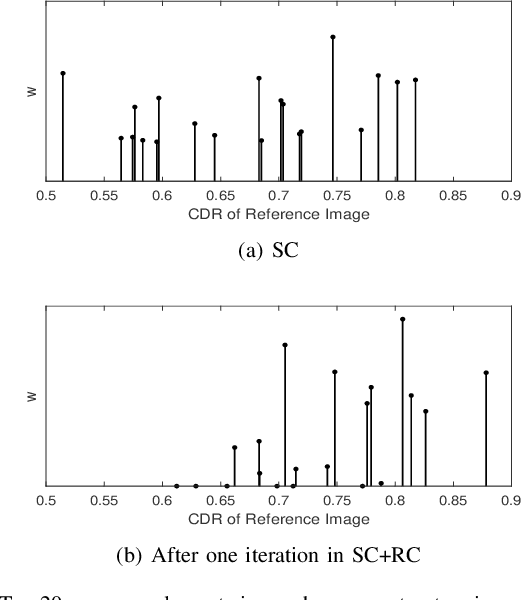
Sparse learning has been shown to be effective in solving many real-world problems. Finding sparse representations is a fundamentally important topic in many fields of science including signal processing, computer vision, genome study and medical imaging. One important issue in applying sparse representation is to find the basis to represent the data,especially in computer vision and medical imaging where the data is not necessary incoherent. In medical imaging, clinicians often grade the severity or measure the risk score of a disease based on images. This process is referred to as medical image grading. Manual grading of the disease severity or risk score is often used. However, it is tedious, subjective and expensive. Sparse learning has been used for automatic grading of medical images for different diseases. In the grading, we usually begin with one step to find a sparse representation of the testing image using a set of reference images or atoms from the dictionary. Then in the second step, the selected atoms are used as references to compute the grades of the testing images. Since the two steps are conducted sequentially, the objective function in the first step is not necessarily optimized for the second step. In this paper, we propose a novel sparse range-constrained learning(SRCL)algorithm for medical image grading.Different from most of existing sparse learning algorithms, SRCL integrates the objective of finding a sparse representation and that of grading the image into one function. It aims to find a sparse representation of the testing image based on atoms that are most similar in both the data or feature representation and the medical grading scores. We apply the new proposed SRCL to CDR computation and cataract grading. Experimental results show that the proposed method is able to improve the accuracy in cup-to-disc ratio computation and cataract grading.
Image reconstruction by domain transform manifold learning
Apr 28, 2017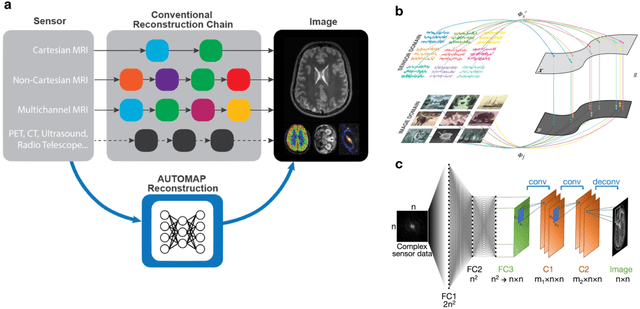
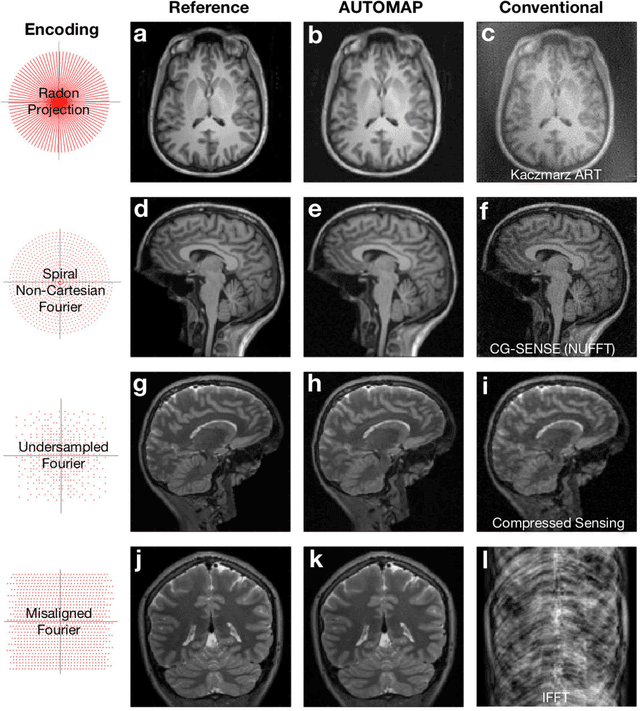
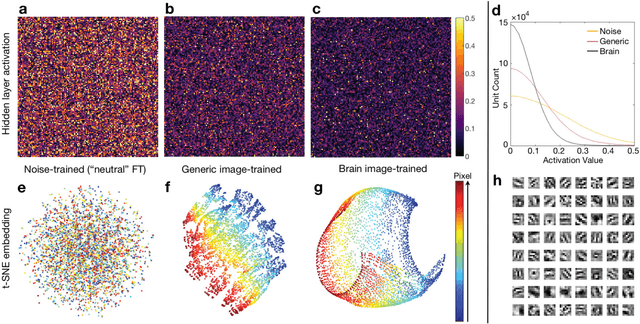
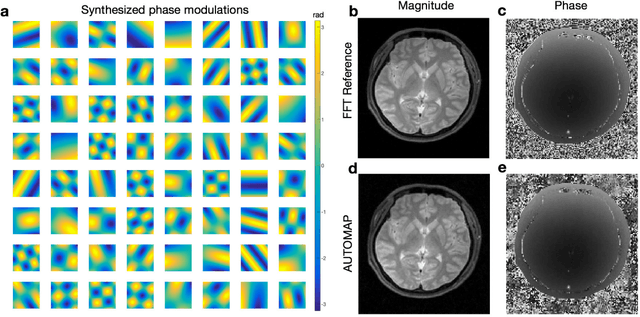
Image reconstruction plays a critical role in the implementation of all contemporary imaging modalities across the physical and life sciences including optical, MRI, CT, PET, and radio astronomy. During an image acquisition, the sensor encodes an intermediate representation of an object in the sensor domain, which is subsequently reconstructed into an image by an inversion of the encoding function. Image reconstruction is challenging because analytic knowledge of the inverse transform may not exist a priori, especially in the presence of sensor non-idealities and noise. Thus, the standard reconstruction approach involves approximating the inverse function with multiple ad hoc stages in a signal processing chain whose composition depends on the details of each acquisition strategy, and often requires expert parameter tuning to optimize reconstruction performance. We present here a unified framework for image reconstruction, AUtomated TransfOrm by Manifold APproximation (AUTOMAP), which recasts image reconstruction as a data-driven, supervised learning task that allows a mapping between sensor and image domain to emerge from an appropriate corpus of training data. We implement AUTOMAP with a deep neural network and exhibit its flexibility in learning reconstruction transforms for a variety of MRI acquisition strategies, using the same network architecture and hyperparameters. We further demonstrate its efficiency in sparsely representing transforms along low-dimensional manifolds, resulting in superior immunity to noise and reconstruction artifacts compared with conventional handcrafted reconstruction methods. In addition to improving the reconstruction performance of existing acquisition methodologies, we anticipate accelerating the discovery of new acquisition strategies across modalities as the burden of reconstruction becomes lifted by AUTOMAP and learned-reconstruction approaches.
Attacking Visual Language Grounding with Adversarial Examples: A Case Study on Neural Image Captioning
May 22, 2018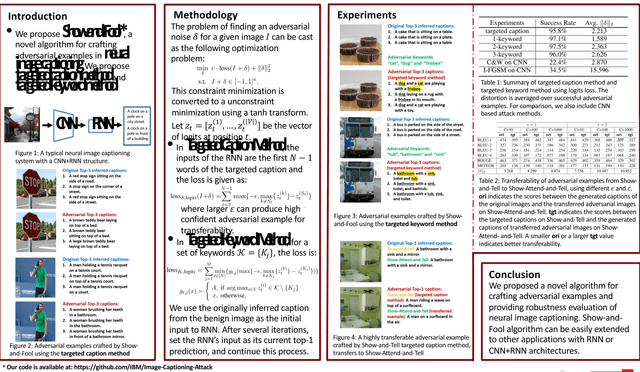
Visual language grounding is widely studied in modern neural image captioning systems, which typically adopts an encoder-decoder framework consisting of two principal components: a convolutional neural network (CNN) for image feature extraction and a recurrent neural network (RNN) for language caption generation. To study the robustness of language grounding to adversarial perturbations in machine vision and perception, we propose Show-and-Fool, a novel algorithm for crafting adversarial examples in neural image captioning. The proposed algorithm provides two evaluation approaches, which check whether neural image captioning systems can be mislead to output some randomly chosen captions or keywords. Our extensive experiments show that our algorithm can successfully craft visually-similar adversarial examples with randomly targeted captions or keywords, and the adversarial examples can be made highly transferable to other image captioning systems. Consequently, our approach leads to new robustness implications of neural image captioning and novel insights in visual language grounding.
Study of Residual Networks for Image Recognition
Apr 21, 2018
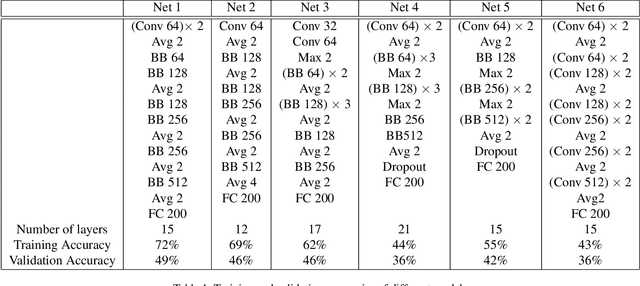

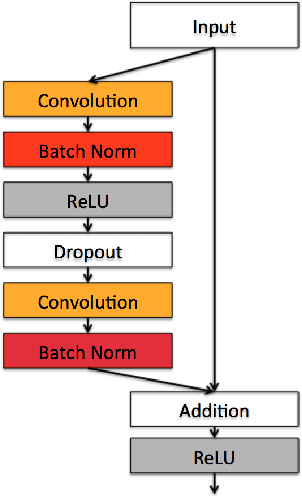
Deep neural networks demonstrate to have a high performance on image classification tasks while being more difficult to train. Due to the complexity and vanishing gradient problem, it normally takes a lot of time and more computational power to train deeper neural networks. Deep residual networks (ResNets) can make the training process faster and attain more accuracy compared to their equivalent neural networks. ResNets achieve this improvement by adding a simple skip connection parallel to the layers of convolutional neural networks. In this project we first design a ResNet model that can perform the image classification task on the Tiny ImageNet dataset with a high accuracy, then we compare the performance of this ResNet model with its equivalent Convolutional Network (ConvNet). Our findings illustrate that ResNets are more prone to overfitting despite their higher accuracy. Several methods to prevent overfitting such as adding dropout layers and stochastic augmentation of the training dataset has been studied in this work.