 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepFacePencil: Creating Face Images from Freehand Sketches
Aug 31, 2020
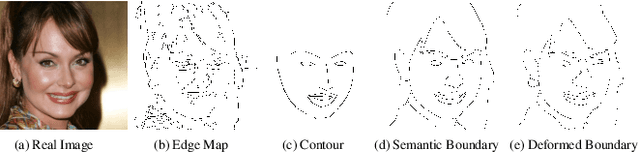

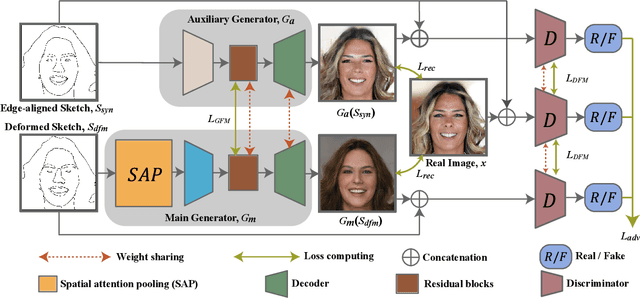
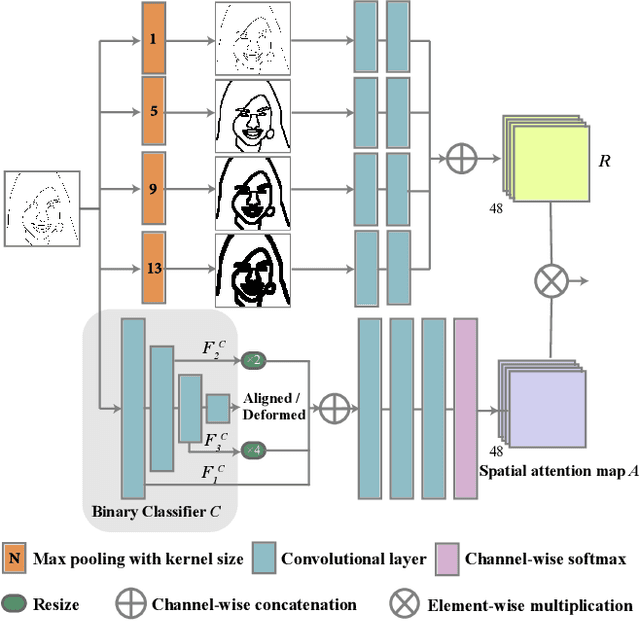
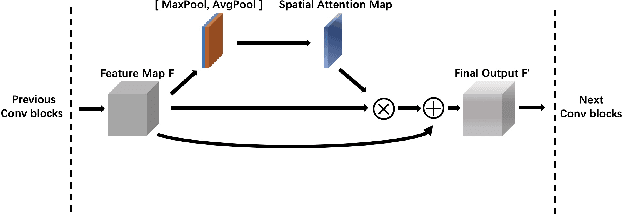
In this paper, we explore the task of generating photo-realistic face images from hand-drawn sketches. Existing image-to-image translation methods require a large-scale dataset of paired sketches and images for supervision. They typically utilize synthesized edge maps of face images as training data. However, these synthesized edge maps strictly align with the edges of the corresponding face images, which limit their generalization ability to real hand-drawn sketches with vast stroke diversity. To address this problem, we propose DeepFacePencil, an effective tool that is able to generate photo-realistic face images from hand-drawn sketches, based on a novel dual generator image translation network during training. A novel spatial attention pooling (SAP) is designed to adaptively handle stroke distortions which are spatially varying to support various stroke styles and different levels of details. We conduct extensive experiments and the results demonstrate the superiority of our model over existing methods on both image quality and model generalization to hand-drawn sketches.
H-Net: Unsupervised Attention-based Stereo Depth Estimation Leveraging Epipolar Geometry
Apr 22, 2021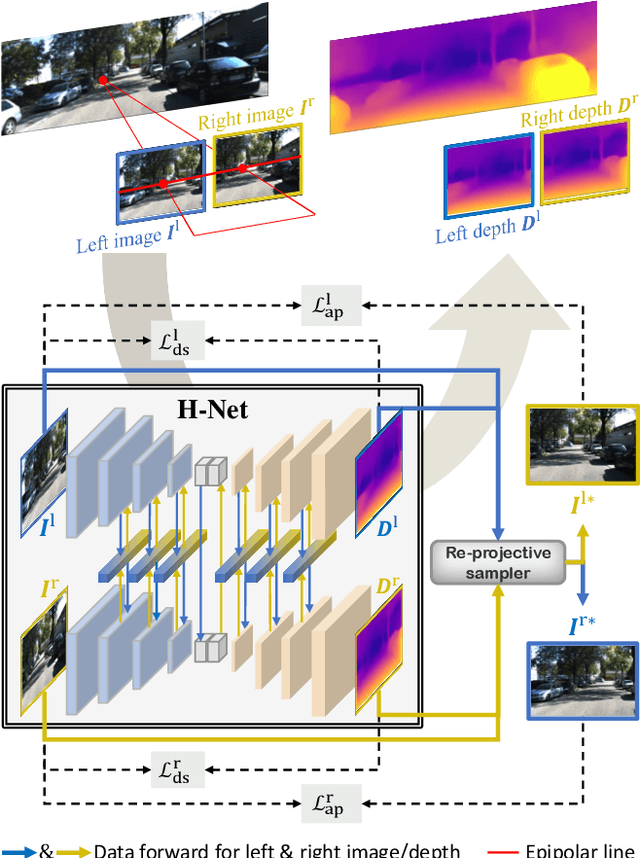
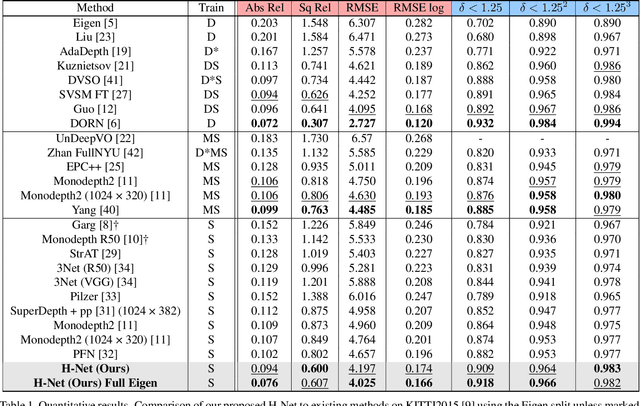
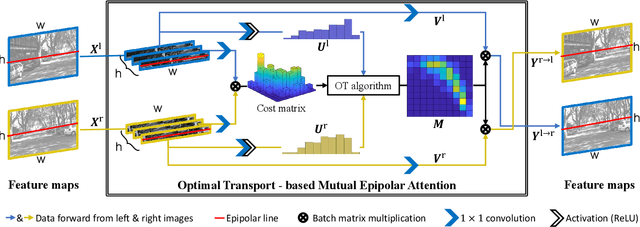
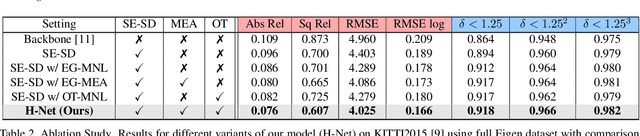
Depth estimation from a stereo image pair has become one of the most explored applications in computer vision, with most of the previous methods relying on fully supervised learning settings. However, due to the difficulty in acquiring accurate and scalable ground truth data, the training of fully supervised methods is challenging. As an alternative, self-supervised methods are becoming more popular to mitigate this challenge. In this paper, we introduce the H-Net, a deep-learning framework for unsupervised stereo depth estimation that leverages epipolar geometry to refine stereo matching. For the first time, a Siamese autoencoder architecture is used for depth estimation which allows mutual information between the rectified stereo images to be extracted. To enforce the epipolar constraint, the mutual epipolar attention mechanism has been designed which gives more emphasis to correspondences of features which lie on the same epipolar line while learning mutual information between the input stereo pair. Stereo correspondences are further enhanced by incorporating semantic information to the proposed attention mechanism. More specifically, the optimal transport algorithm is used to suppress attention and eliminate outliers in areas not visible in both cameras. Extensive experiments on KITTI2015 and Cityscapes show that our method outperforms the state-ofthe-art unsupervised stereo depth estimation methods while closing the gap with the fully supervised approaches.
Block-wise Image Transformation with Secret Key for Adversarially Robust Defense
Oct 02, 2020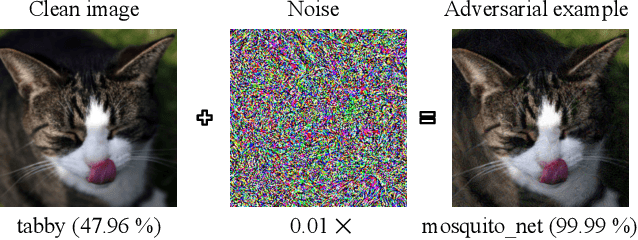
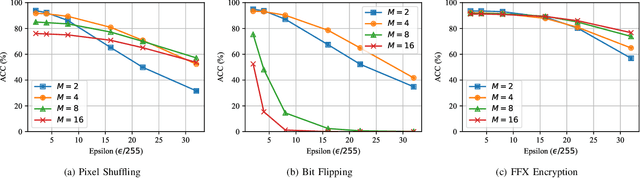
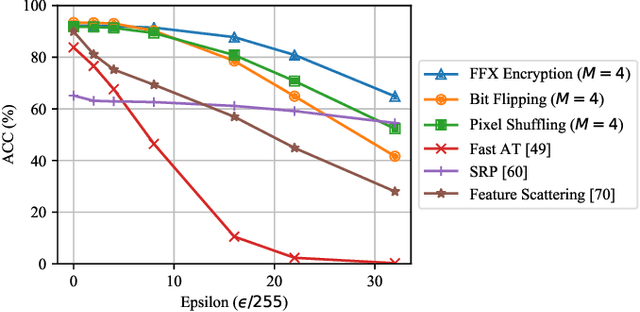
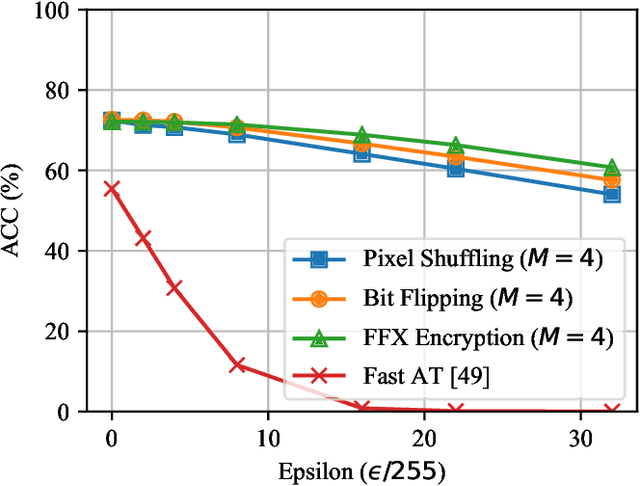
In this paper, we propose a novel defensive transformation that enables us to maintain a high classification accuracy under the use of both clean images and adversarial examples for adversarially robust defense. The proposed transformation is a block-wise preprocessing technique with a secret key to input images. We developed three algorithms to realize the proposed transformation: Pixel Shuffling, Bit Flipping, and FFX Encryption. Experiments were carried out on the CIFAR-10 and ImageNet datasets by using both black-box and white-box attacks with various metrics including adaptive ones. The results show that the proposed defense achieves high accuracy close to that of using clean images even under adaptive attacks for the first time. In the best-case scenario, a model trained by using images transformed by FFX Encryption (block size of 4) yielded an accuracy of 92.30% on clean images and 91.48% under PGD attack with a noise distance of 8/255, which is close to the non-robust accuracy (95.45%) for the CIFAR-10 dataset, and it yielded an accuracy of 72.18% on clean images and 71.43% under the same attack, which is also close to the standard accuracy (73.70%) for the ImageNet dataset. Overall, all three proposed algorithms are demonstrated to outperform state-of-the-art defenses including adversarial training whether or not a model is under attack.
Depth Structure Preserving Scene Image Generation
Nov 22, 2017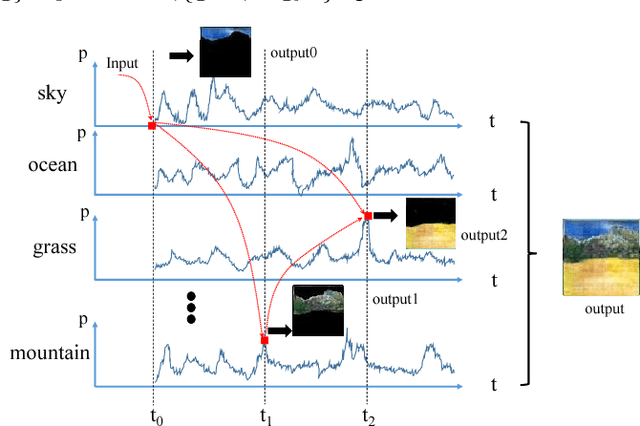
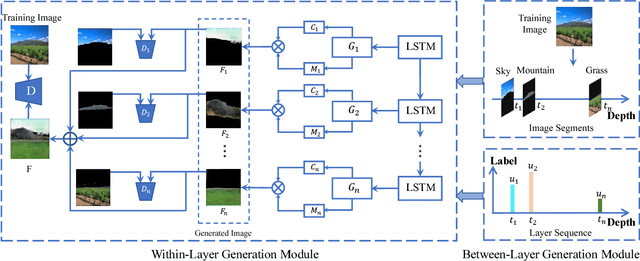

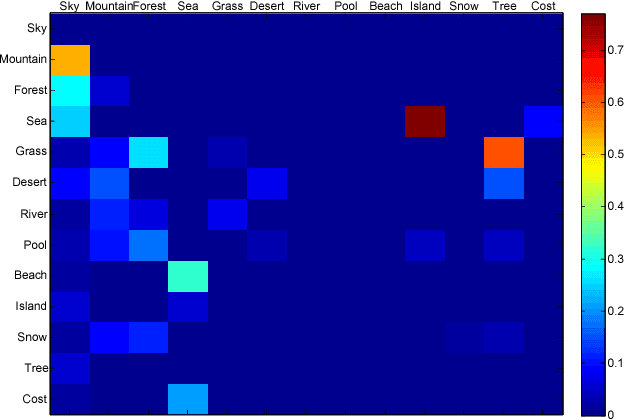
Key to automatically generate natural scene images is to properly arrange among various spatial elements, especially in the depth direction. To this end, we introduce a novel depth structure preserving scene image generation network (DSP-GAN), which favors a hierarchical and heterogeneous architecture, for the purpose of depth structure preserving scene generation. The main trunk of the proposed infrastructure is built on a Hawkes point process that models the spatial dependency between different depth layers. Within each layer generative adversarial sub-networks are trained collaboratively to generate realistic scene components, conditioned on the layer information produced by the point process. We experiment our model on a sub-set of SUNdataset with annotated scene images and demonstrate that our models are capable of generating depth-realistic natural scene image.
Adaptive Quantile Sparse Image (AQuaSI) Prior for Inverse Imaging Problems
Apr 06, 2018



Inverse problems play a central role for many classical computer vision and image processing tasks. A key challenge in solving an inverse problem is to find an appropriate prior to convert an ill-posed problem into a well-posed task. Many of the existing priors, like total variation, are based on ad-hoc assumptions that have difficulties to represent the actual distribution of natural images. In this work, we propose the Adaptive Quantile Sparse Image (AQuaSI) prior. It is based on a quantile filter, can be used as a joint filter on guidance data, and be readily plugged into a wide range of numerical optimization algorithms. We demonstrate the efficacy of the proposed prior in joint RGB/depth upsampling, on RGB/NIR image restoration, and in a comparison with related regularization by denoising approaches.
Brain Tumors Classification for MR images based on Attention Guided Deep Learning Model
Apr 06, 2021
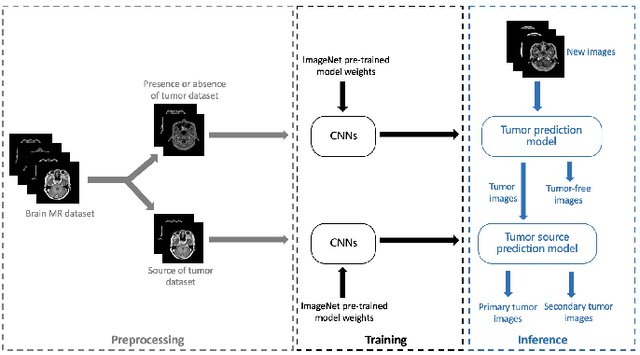
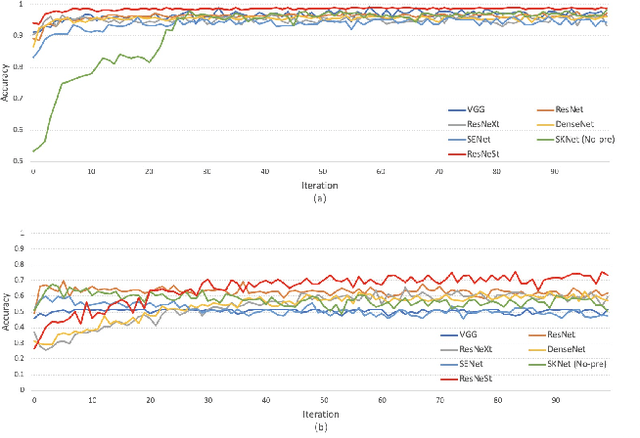
In the clinical diagnosis and treatment of brain tumors, manual image reading consumes a lot of energy and time. In recent years, the automatic tumor classification technology based on deep learning has entered people's field of vision. Brain tumors can be divided into primary and secondary intracranial tumors according to their source. However, to our best knowledge, most existing research on brain tumors are limited to primary intracranial tumor images and cannot classify the source of the tumor. In order to solve the task of tumor source type classification, we analyze the existing technology and propose an attention guided deep convolution neural network (CNN) model. Meanwhile, the method proposed in this paper also effectively improves the accuracy of classifying the presence or absence of tumor. For the brain MR dataset, our method can achieve the average accuracy of 99.18% under ten-fold cross-validation for identifying the presence or absence of tumor, and 83.38% for classifying the source of tumor. Experimental results show that our method is consistent with the method of medical experts. It can assist doctors in achieving efficient clinical diagnosis of brain tumors.
Generative View Synthesis: From Single-view Semantics to Novel-view Images
Aug 20, 2020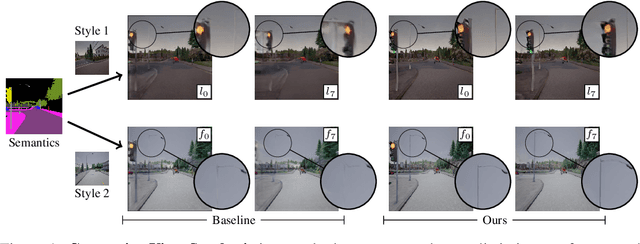
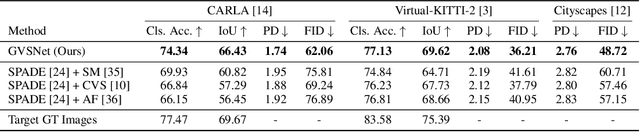
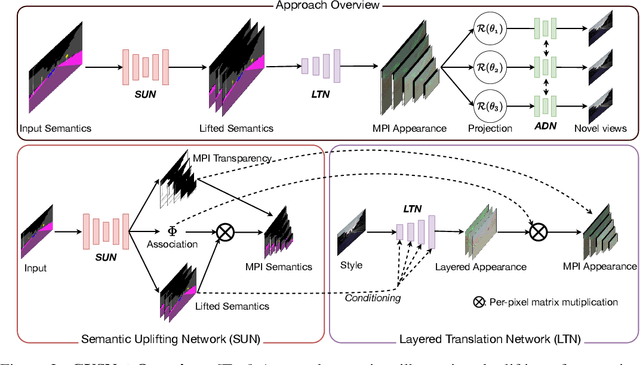
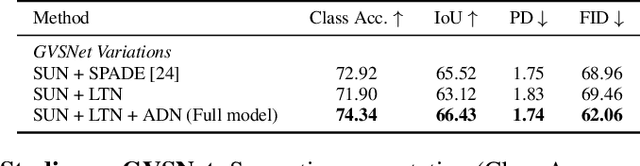
Content creation, central to applications such as virtual reality, can be a tedious and time-consuming. Recent image synthesis methods simplify this task by offering tools to generate new views from as little as a single input image, or by converting a semantic map into a photorealistic image. We propose to push the envelope further, and introduce \emph{Generative View Synthesis} (GVS), which can synthesize multiple photorealistic views of a scene given a single semantic map. We show that the sequential application of existing techniques, e.g., semantics-to-image translation followed by monocular view synthesis, fail at capturing the scene's structure. In contrast, we solve the semantics-to-image translation in concert with the estimation of the 3D layout of the scene, thus producing geometrically consistent novel views that preserve semantic structures. We first lift the input 2D semantic map onto a 3D layered representation of the scene in feature space, thereby preserving the semantic labels of 3D geometric structures. We then project the layered features onto the target views to generate the final novel-view images. We verify the strengths of our method and compare it with several advanced baselines on three different datasets. Our approach also allows for style manipulation and image editing operations, such as the addition or removal of objects, with simple manipulations of the input style images and semantic maps respectively. Visit the project page at https://gvsnet.github.io.
Making Images Undiscoverable from Co-Saliency Detection
Sep 19, 2020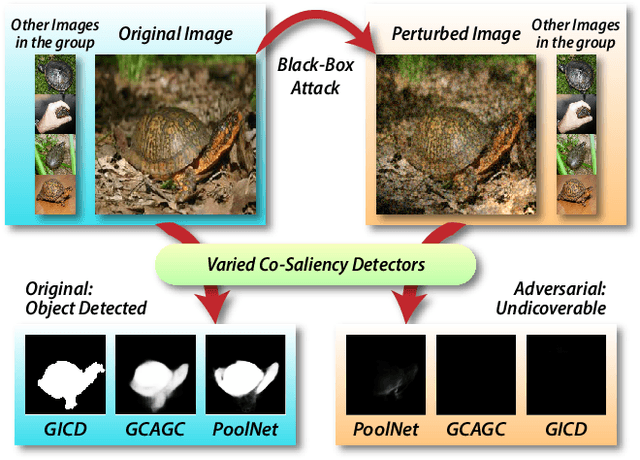
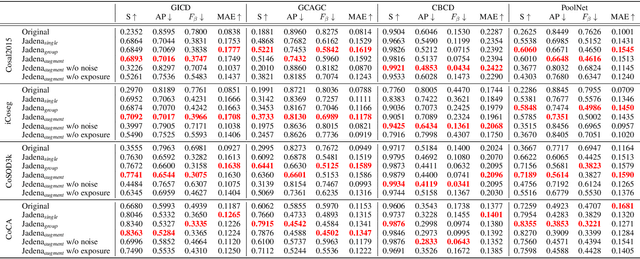
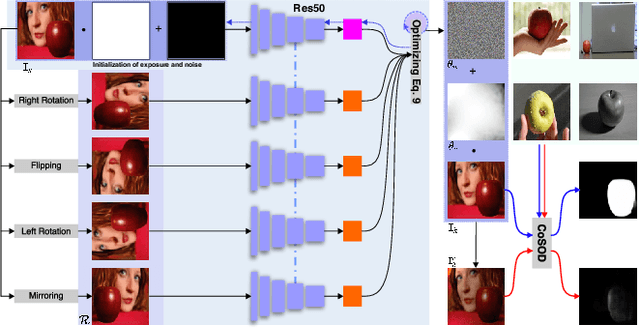
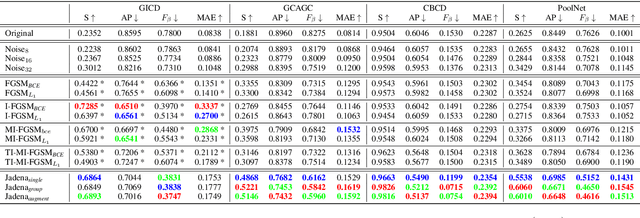
In recent years, co-saliency object detection (CoSOD) has achieved significant progress and played a key role in the retrieval-related tasks, e.g., image retrieval and video foreground detection. Nevertheless, it also inevitably posts a totally new safety and security problem, i.e., how to prevent high-profile and personal-sensitive contents from being extracted by the powerful CoSOD methods. In this paper, we address this problem from the perspective of adversarial attack and identify a novel task, i.e., adversarial co-saliency attack: given an image selected from an image group containing some common and salient objects, how to generate an adversarial version that can mislead CoSOD methods to predict incorrect co-salient regions. Note that, compared with general adversarial attacks for classification, this new task introduces two extra challenges for existing whitebox adversarial noise attacks: (1) low success rate due to the diverse appearance of images in the image group; (2) low transferability across CoSOD methods due to the considerable difference between CoSOD pipelines. To address these challenges, we propose the very first blackbox joint adversarial exposure & noise attack (Jadena) where we jointly and locally tune the exposure and additive perturbations of the image according to a newly designed high-feature-level contrast-sensitive loss function. Our method, without any information of the state-of-the-art CoSOD methods, leads to significant performance degradation on various co-saliency detection datasets and make the co-salient objects undetectable, which can be strongly practical in nowadays where large-scale personal photos are shared on the internet and should be properly and securely preserved.
Ratio-Preserving Half-Cylindrical Warps for Natural Image Stitching
Mar 18, 2018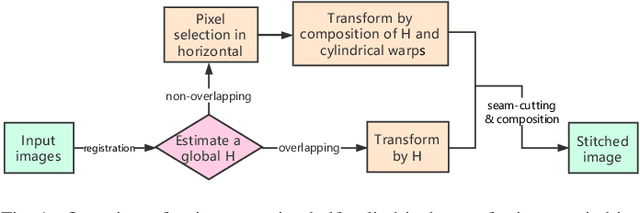
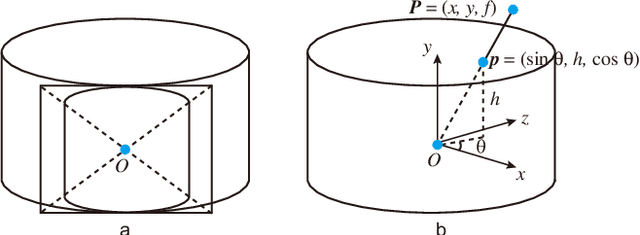

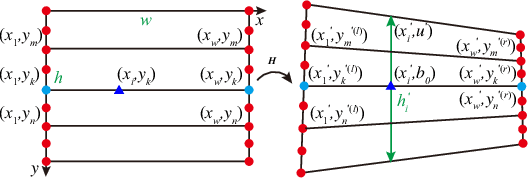
A novel warp for natural image stitching is proposed that utilizes the property of cylindrical warp and a horizontal pixel selection strategy. The proposed ratio-preserving half-cylindrical warp is a combination of homography and cylindrical warps which guarantees alignment by homography and possesses less projective distortion by cylindrical warp. Unlike previous approaches applying cylindrical warp before homography, we use partition lines to divide the image into different parts and apply homography in the overlapping region while a composition of homography and cylindrical warps in the non-overlapping region. The pixel selection strategy then samples the points in horizontal and reconstructs the image via interpolation to further reduce horizontal distortion by maintaining the ratio as similarity. With applying half-cylindrical warp and horizontal pixel selection, the projective distortion in vertical and horizontal is mitigated simultaneously. Experiments show that our warp is efficient and produces a more natural-looking stitched result than previous methods.
Impact of Facial Tattoos and Paintings on Face Recognition Systems
Mar 27, 2021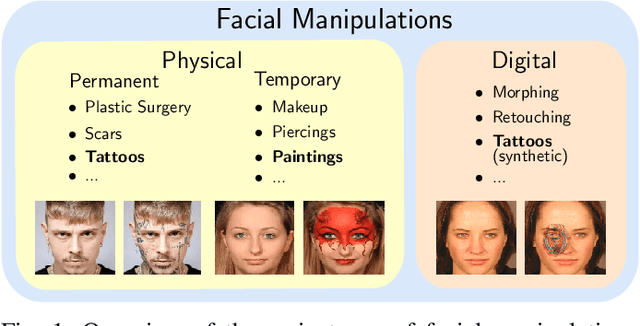
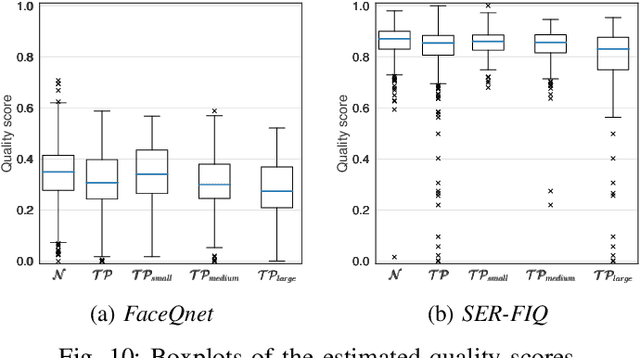
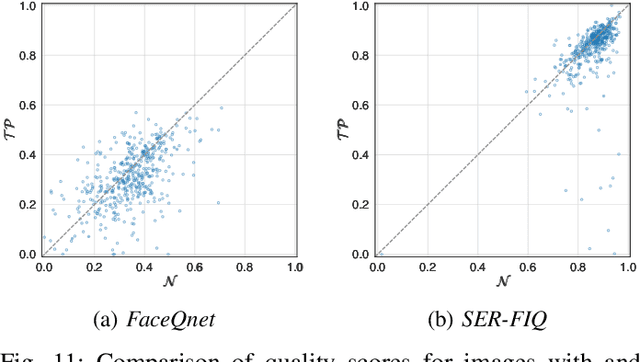

In the past years, face recognition technologies have shown impressive recognition performance, mainly due to recent developments in deep convolutional neural networks. Notwithstanding those improvements, several challenges which affect the performance of face recognition systems remain. In this work, we investigate the impact that facial tattoos and paintings have on current face recognition systems. To this end, we first collected an appropriate database containing image-pairs of individuals with and without facial tattoos or paintings. The assembled database was used to evaluate how facial tattoos and paintings affect the detection, quality estimation, as well as the feature extraction and comparison modules of a face recognition system. The impact on these modules was evaluated using state-of-the-art open-source and commercial systems. The obtained results show that facial tattoos and paintings affect all the tested modules, especially for images where a large area of the face is covered with tattoos or paintings. Our work is an initial case-study and indicates a need to design algorithms which are robust to the visual changes caused by facial tattoos and paintings.