 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Network Signatures from Image Representation of Adjacency Matrices: Deep/Transfer Learning for Subgraph Classification
Apr 17, 2018
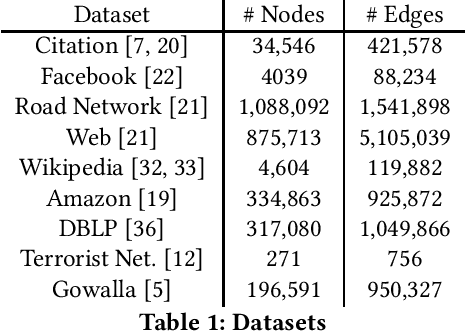

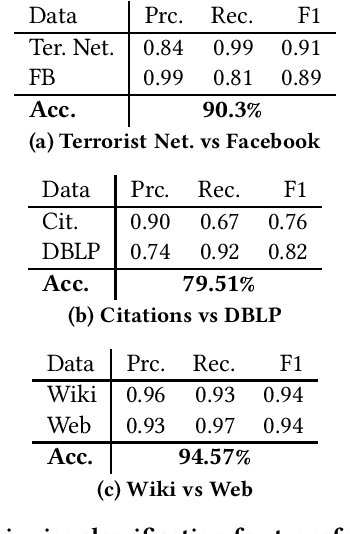
We propose a novel subgraph image representation for classification of network fragments with the targets being their parent networks. The graph image representation is based on 2D image embeddings of adjacency matrices. We use this image representation in two modes. First, as the input to a machine learning algorithm. Second, as the input to a pure transfer learner. Our conclusions from several datasets are that (a) deep learning using our structured image features performs the best compared to benchmark graph kernel and classical features based methods; and, (b) pure transfer learning works effectively with minimum interference from the user and is robust against small data.
Geospatial Transformations for Ground-Based Sky Imaging Systems
Mar 02, 2021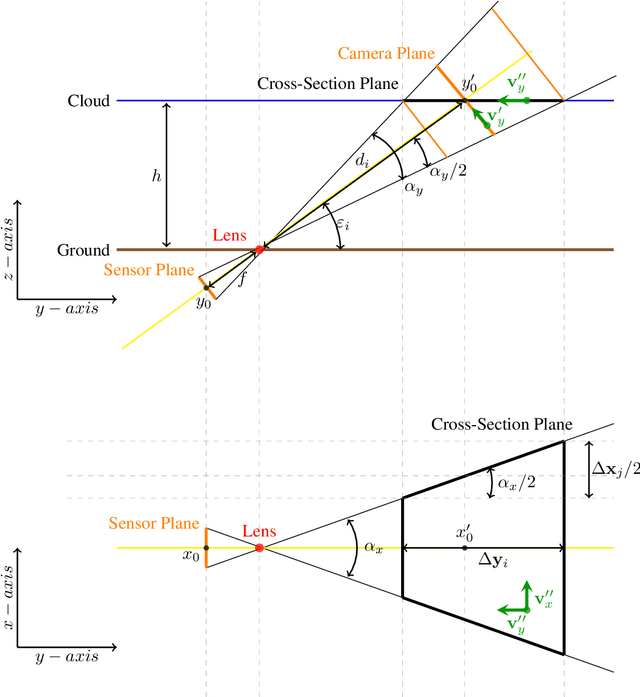
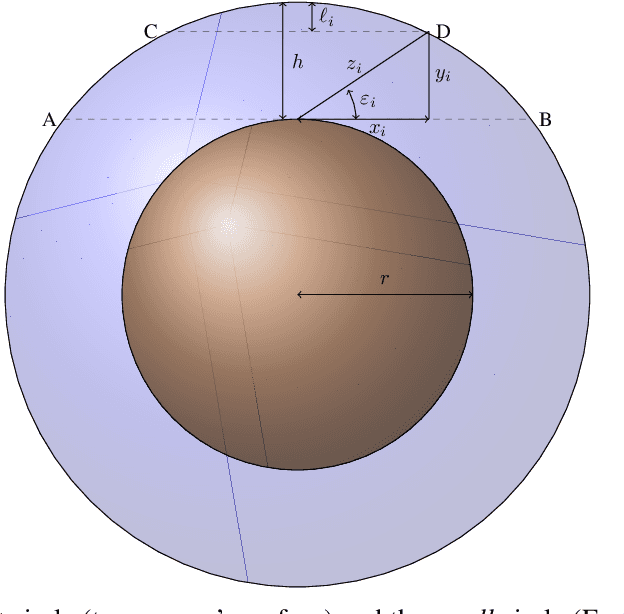
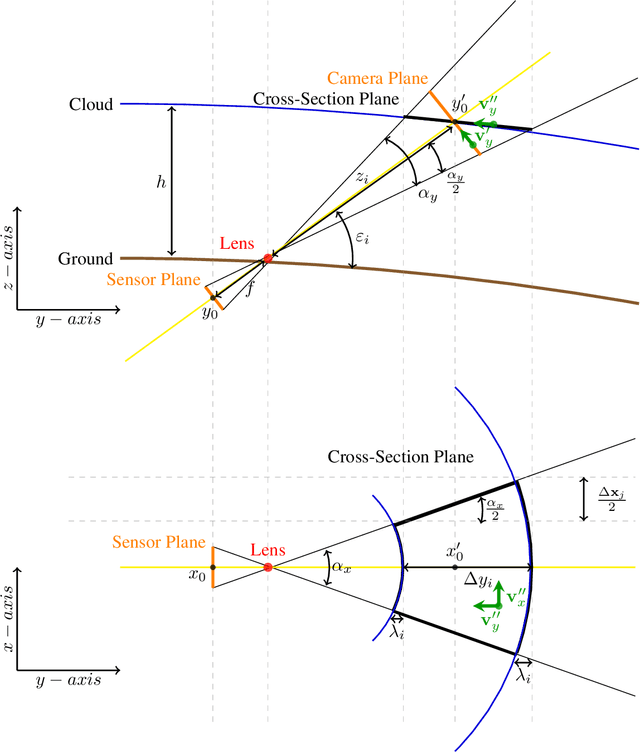

Sky imaging systems use lenses to acquire images concentrating light beams in an imager. The light beams received by the imager have an elevation angle with respect to the normal of the device. This produces that the pixels in an image contain information from different areas of the sky within imaging system Field Of View (FOV). The area of the field of view contained in the pixels increases as the elevation angle of the incident light beams decreases. When the sky imaging system are mounted on a solar tracker the angle of incidence of the light beams varies along time. This investigation introduces a transformation that projects the original euclidean frame of the plane of the imager to the geospatial frame of the sky imaging system field of view.
Image Compression Based on Compressive Sensing: End-to-End Comparison with JPEG
Jul 28, 2018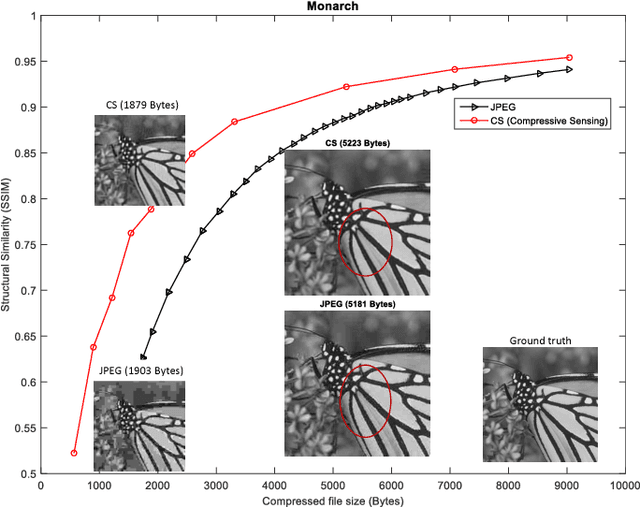
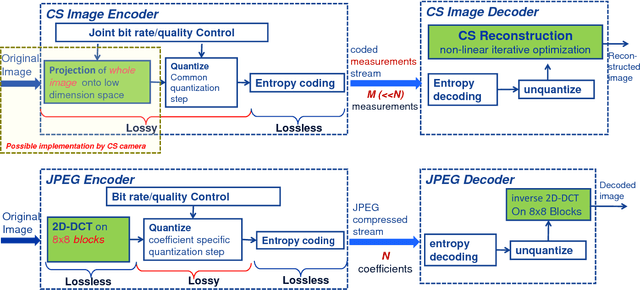
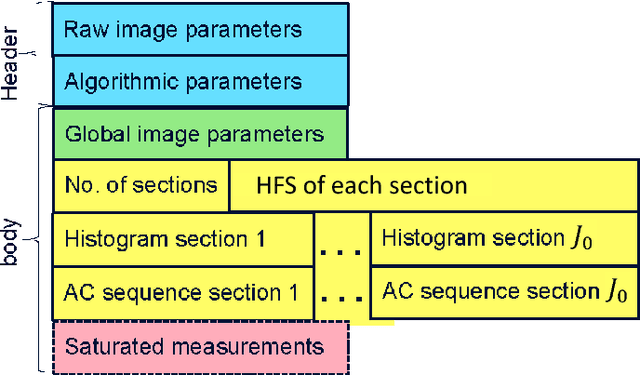
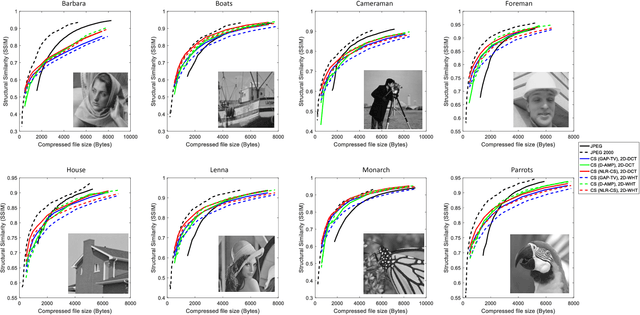
We present an end-to-end image compression system based on compressive sensing. The presented system integrates the conventional scheme of compressive sampling and reconstruction with quantization and entropy coding. The compression performance, in terms of decoded image quality versus data rate, is shown to be comparable with JPEG and significantly better at the low rate range. We study the parameters that influence the system performance, including (i) the choice of sensing matrix, (ii) the trade-off between quantization and compression ratio, and (iii) the reconstruction algorithms. We propose an effective method to jointly control the quantization step and compression ratio in order to achieve near optimal quality at any given bit rate. Furthermore, our proposed image compression system can be directly used in the compressive sensing camera, e.g. the single pixel camera, to construct a hardware compressive sampling system.
Semantic Comparison of State-of-the-Art Deep Learning Methods for Image Multi-Label Classification
Apr 05, 2019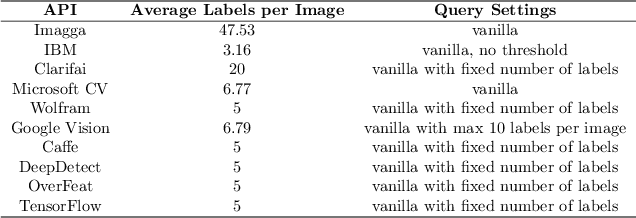
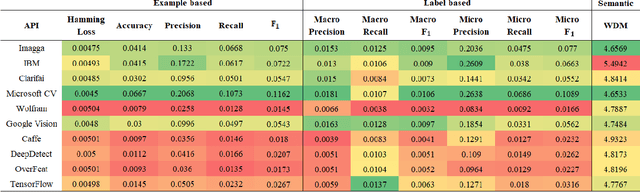
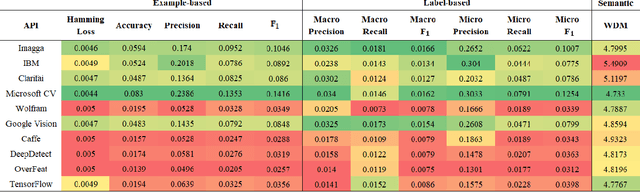
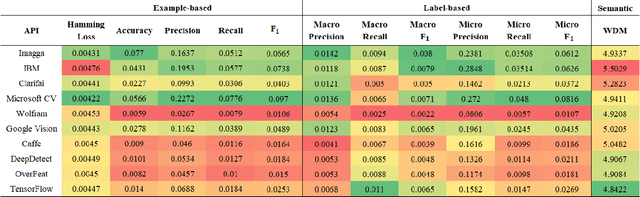
Image understanding relies heavily on accurate multi-label classification. In recent years deep learning (DL) algorithms have become very successful tools for multi-label classification of image objects. With these set of tools, various implementations of DL algorithms have been released for the public use in the form of application programming interfaces (API). In this study, we evaluate and compare 10 of the most prominent publicly available APIs in a best-of-breed challenge. The evaluation is performed on the Visual Genome labeling benchmark dataset using 12 well-recognized similarity metrics. In addition, for the first time in this kind of comparison, we use a semantic similarity metric to evaluate the semantic similarity performance of these APIs. In this evaluation, Microsoft's Computer Vision, TensorFlow, Imagga, and IBM's Visual Recognition showed better performance than the other APIs. Furthermore, the new semantic similarity metric allowed deeper insights for comparison.
Design of a vision based range bearing and heading system for robot swarms
Mar 14, 2021An essential problem of swarm robotics is how members of the swarm knows the positions of other robots. The main aim of this research is to develop a cost-effective and simple vision-based system to detect the range, bearing, and heading of the robots inside a swarm using a multi-purpose passive landmark. A small Zumo robot equipped with Raspberry Pi, PiCamera is utilized for the implementation of the algorithm, and different kinds of multipurpose passive landmarks with nonsymmetrical patterns, which give reliable information about the range, bearing and heading in a single unit, are designed. By comparing the recorded features obtained from image analysis of the landmark through systematical experimentation and the actual measurements, correlations are obtained, and algorithms converting those features into range, bearing and heading are designed. The reliability and accuracy of algorithms are tested and errors are found within an acceptable range.
Selfie Periocular Verification using an Efficient Super-Resolution Approach
Feb 16, 2021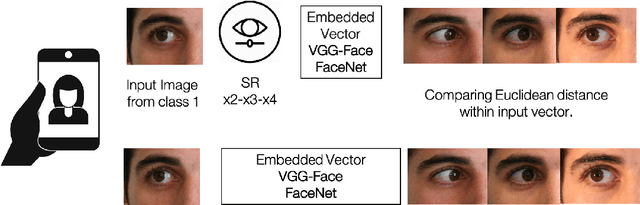
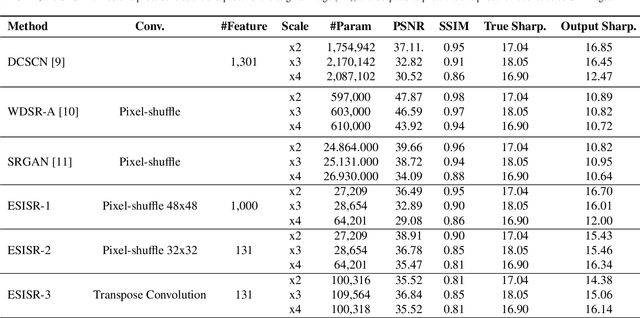
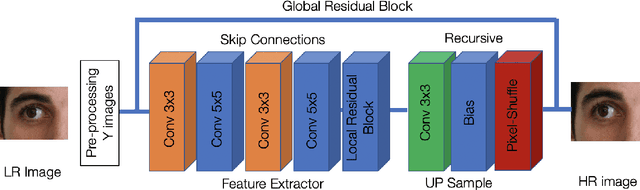
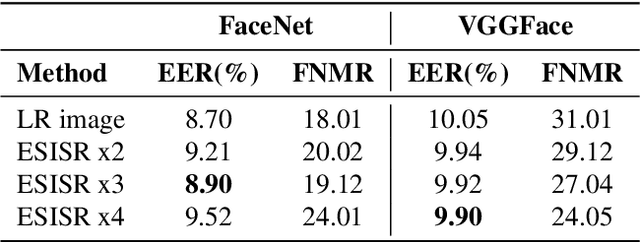
Selfie-based biometrics has great potential for a wide range of applications from marketing to higher security environments like online banking. This is now especially relevant since e.g. periocular verification is contactless, and thereby safe to use in pandemics such as COVID-19. However, selfie-based biometrics faces some challenges since there is limited control over the data acquisition conditions. Therefore, super-resolution has to be used to increase the quality of the captured images. Most of the state of the art super-resolution methods use deep networks with large filters, thereby needing to train and store a correspondingly large number of parameters, and making their use difficult for mobile devices commonly used for selfie-based. In order to achieve an efficient super-resolution method, we propose an Efficient Single Image Super-Resolution (ESISR) algorithm, which takes into account a trade-off between the efficiency of the deep neural network and the size of its filters. To that end, the method implements a novel loss function based on the Sharpness metric. This metric turns out to be more suitable for increasing the quality of the eye images. Our method drastically reduces the number of parameters when compared with Deep CNNs with Skip Connection and Network (DCSCN): from 2,170,142 to 28,654 parameters when the image size is increased by a factor of x3. Furthermore, the proposed method keeps the sharp quality of the images, which is highly relevant for biometric recognition purposes. The results on remote verification systems with raw images reached an Equal Error Rate (EER) of 8.7% for FaceNet and 10.05% for VGGFace. Where embedding vectors were used from periocular images the best results reached an EER of 8.9% (x3) for FaceNet and 9.90% (x4) for VGGFace.
Single-View Food Portion Estimation: Learning Image-to-Energy Mappings Using Generative Adversarial Networks
May 23, 2018
Due to the growing concern of chronic diseases and other health problems related to diet, there is a need to develop accurate methods to estimate an individual's food and energy intake. Measuring accurate dietary intake is an open research problem. In particular, accurate food portion estimation is challenging since the process of food preparation and consumption impose large variations on food shapes and appearances. In this paper, we present a food portion estimation method to estimate food energy (kilocalories) from food images using Generative Adversarial Networks (GAN). We introduce the concept of an "energy distribution" for each food image. To train the GAN, we design a food image dataset based on ground truth food labels and segmentation masks for each food image as well as energy information associated with the food image. Our goal is to learn the mapping of the food image to the food energy. We can then estimate food energy based on the energy distribution. We show that an average energy estimation error rate of 10.89% can be obtained by learning the image-to-energy mapping.
Multiple Instance Captioning: Learning Representations from Histopathology Textbooks and Articles
Mar 08, 2021
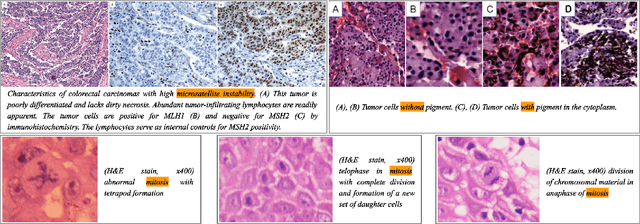
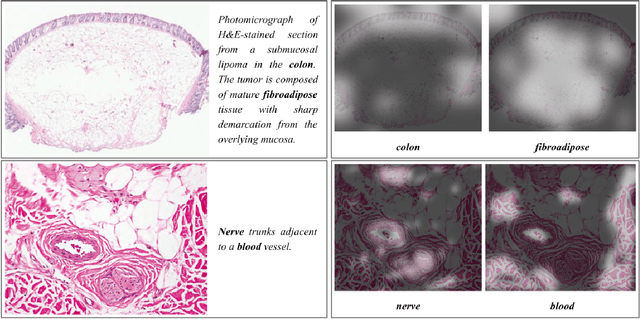
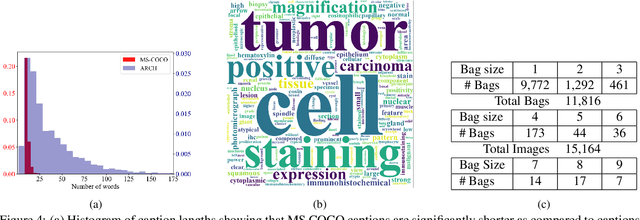
We present ARCH, a computational pathology (CP) multiple instance captioning dataset to facilitate dense supervision of CP tasks. Existing CP datasets focus on narrow tasks; ARCH on the other hand contains dense diagnostic and morphological descriptions for a range of stains, tissue types and pathologies. Using intrinsic dimensionality estimation, we show that ARCH is the only CP dataset to (ARCH-)rival its computer vision analog MS-COCO Captions. We conjecture that an encoder pre-trained on dense image captions learns transferable representations for most CP tasks. We support the conjecture with evidence that ARCH representation transfers to a variety of pathology sub-tasks better than ImageNet features or representations obtained via self-supervised or multi-task learning on pathology images alone. We release our best model and invite other researchers to test it on their CP tasks.
Rethinking Spatial Dimensions of Vision Transformers
Mar 30, 2021
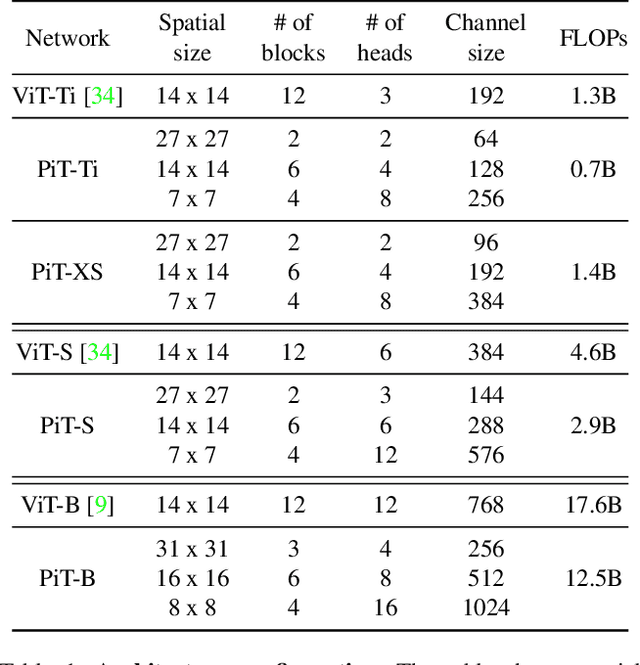
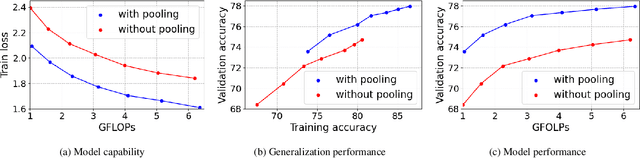
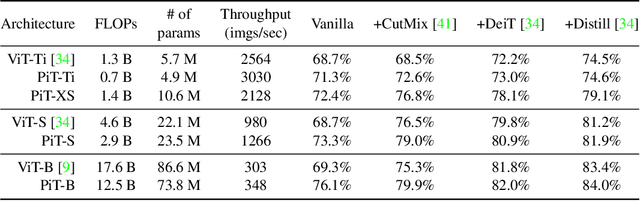
Vision Transformer (ViT) extends the application range of transformers from language processing to computer vision tasks as being an alternative architecture against the existing convolutional neural networks (CNN). Since the transformer-based architecture has been innovative for computer vision modeling, the design convention towards an effective architecture has been less studied yet. From the successful design principles of CNN, we investigate the role of the spatial dimension conversion and its effectiveness on the transformer-based architecture. We particularly attend the dimension reduction principle of CNNs; as the depth increases, a conventional CNN increases channel dimension and decreases spatial dimensions. We empirically show that such a spatial dimension reduction is beneficial to a transformer architecture as well, and propose a novel Pooling-based Vision Transformer (PiT) upon the original ViT model. We show that PiT achieves the improved model capability and generalization performance against ViT. Throughout the extensive experiments, we further show PiT outperforms the baseline on several tasks such as image classification, object detection and robustness evaluation. Source codes and ImageNet models are available at https://github.com/naver-ai/pit
Anchor Distance for 3D Multi-Object Distance Estimation from 2D Single Shot
Feb 16, 2021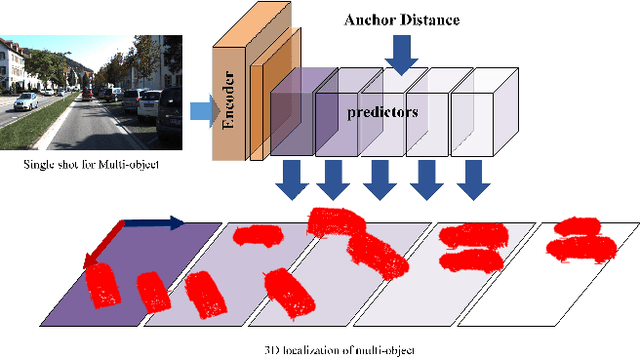
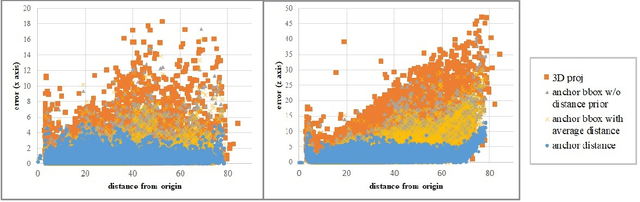
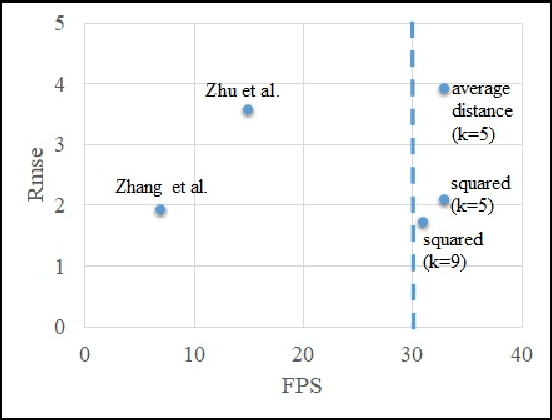
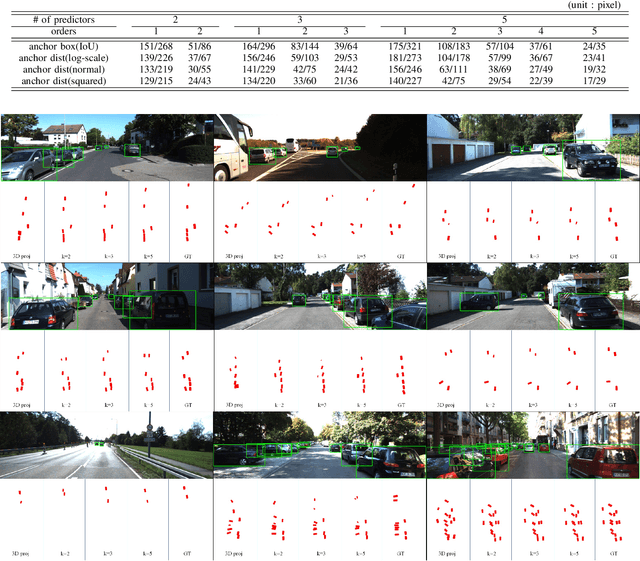
Visual perception of the objects in a 3D environment is a key to successful performance in autonomous driving and simultaneous localization and mapping (SLAM). In this paper, we present a real time approach for estimating the distances to multiple objects in a scene using only a single-shot image. Given a 2D Bounding Box (BBox) and object parameters, a 3D distance to the object can be calculated directly using 3D reprojection; however, such methods are prone to significant errors because an error from the 2D detection can be amplified in 3D. In addition, it is also challenging to apply such methods to a real-time system due to the computational burden. In the case of the traditional multi-object detection methods, %they mostly pay attention to existing works have been developed for specific tasks such as object segmentation or 2D BBox regression. These methods introduce the concept of anchor BBox for elaborate 2D BBox estimation, and predictors are specialized and trained for specific 2D BBoxes. In order to estimate the distances to the 3D objects from a single 2D image, we introduce the notion of \textit{anchor distance} based on an object's location and propose a method that applies the anchor distance to the multi-object detector structure. We let the predictors catch the distance prior using anchor distance and train the network based on the distance. The predictors can be characterized to the objects located in a specific distance range. By propagating the distance prior using a distance anchor to the predictors, it is feasible to perform the precise distance estimation and real-time execution simultaneously. The proposed method achieves about 30 FPS speed, and shows the lowest RMSE compared to the existing methods.