 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image based Eye Gaze Tracking and its Applications
Jul 09, 2019
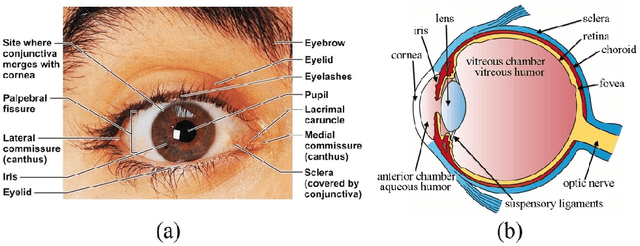
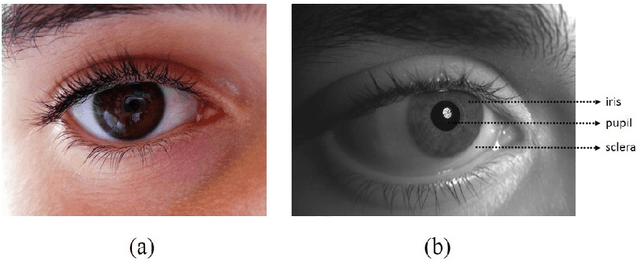

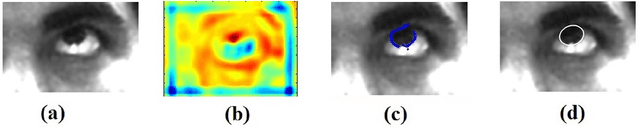
Eye movements play a vital role in perceiving the world. Eye gaze can give a direct indication of the users point of attention, which can be useful in improving human-computer interaction. Gaze estimation in a non-intrusive manner can make human-computer interaction more natural. Eye tracking can be used for several applications such as fatigue detection, biometric authentication, disease diagnosis, activity recognition, alertness level estimation, gaze-contingent display, human-computer interaction, etc. Even though eye-tracking technology has been around for many decades, it has not found much use in consumer applications. The main reasons are the high cost of eye tracking hardware and lack of consumer level applications. In this work, we attempt to address these two issues. In the first part of this work, image-based algorithms are developed for gaze tracking which includes a new two-stage iris center localization algorithm. We have developed a new algorithm which works in challenging conditions such as motion blur, glint, and varying illumination levels. A person independent gaze direction classification framework using a convolutional neural network is also developed which eliminates the requirement of user-specific calibration. In the second part of this work, we have developed two applications which can benefit from eye tracking data. A new framework for biometric identification based on eye movement parameters is developed. A framework for activity recognition, using gaze data from a head-mounted eye tracker is also developed. The information from gaze data, ego-motion, and visual features are integrated to classify the activities.
Domain-robust VQA with diverse datasets and methods but no target labels
Mar 29, 2021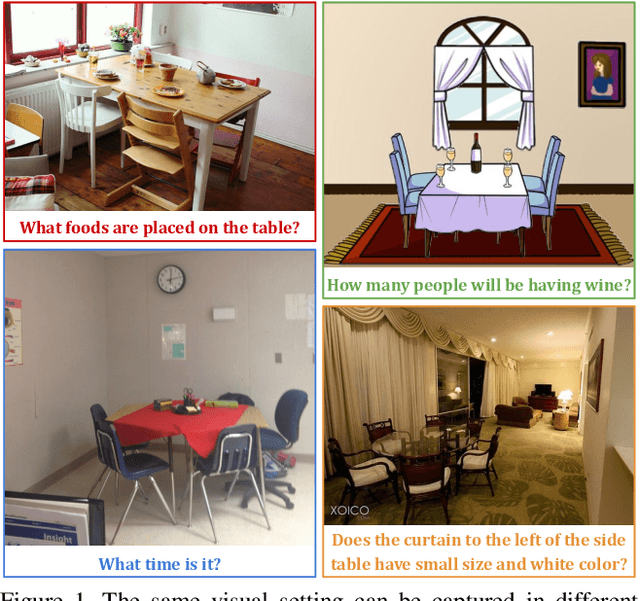

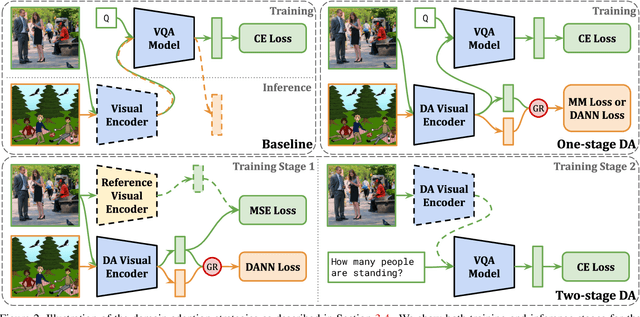
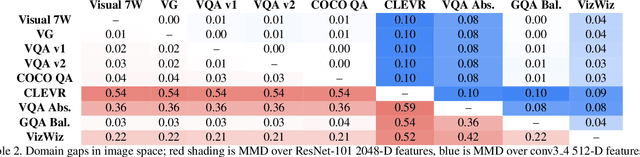
The observation that computer vision methods overfit to dataset specifics has inspired diverse attempts to make object recognition models robust to domain shifts. However, similar work on domain-robust visual question answering methods is very limited. Domain adaptation for VQA differs from adaptation for object recognition due to additional complexity: VQA models handle multimodal inputs, methods contain multiple steps with diverse modules resulting in complex optimization, and answer spaces in different datasets are vastly different. To tackle these challenges, we first quantify domain shifts between popular VQA datasets, in both visual and textual space. To disentangle shifts between datasets arising from different modalities, we also construct synthetic shifts in the image and question domains separately. Second, we test the robustness of different families of VQA methods (classic two-stream, transformer, and neuro-symbolic methods) to these shifts. Third, we test the applicability of existing domain adaptation methods and devise a new one to bridge VQA domain gaps, adjusted to specific VQA models. To emulate the setting of real-world generalization, we focus on unsupervised domain adaptation and the open-ended classification task formulation.
A New Variational Model for Joint Image Reconstruction and Motion Estimation in Spatiotemporal Imaging
Dec 09, 2018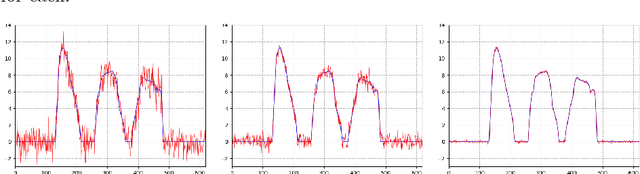



We propose a new variational model for joint image reconstruction and motion estimation in spatiotemporal imaging, which is investigated along a general framework that we present with shape theory. This model consists of two components, one for conducting modified static image reconstruction, and the other performs sequentially indirect image registration. For the latter, we generalize the large deformation diffeomorphic metric mapping framework into the sequentially indirect registration setting. The proposed model is compared theoretically against alternative approaches (optical flow based model and diffeomorphic motion models), and we demonstrate that the proposed model has desirable properties in terms of the optimal solution. The theoretical derivations and efficient algorithms are also presented for a time-discretized scenario of the proposed model, which show that the optimal solution of the time-discretized version is consistent with that of the time-continuous one, and most of the computational components is the easy-implemented linearized deformation. The complexity of the algorithm is analyzed as well. This work is concluded by some numerical examples in 2D space + time tomography with very sparse and/or highly noisy data.
Deep Retinal Image Understanding
Sep 05, 2016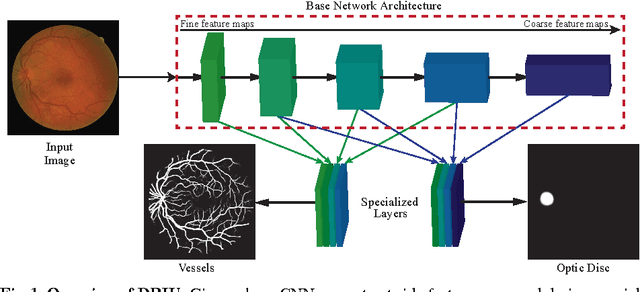
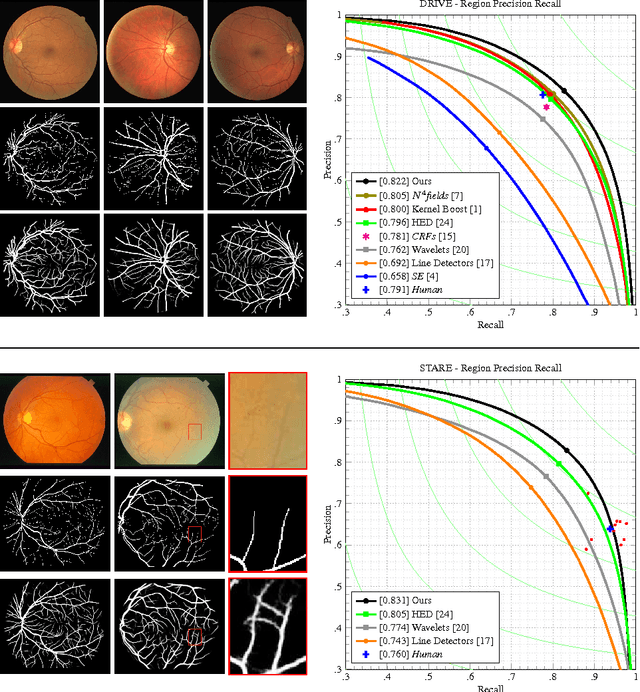
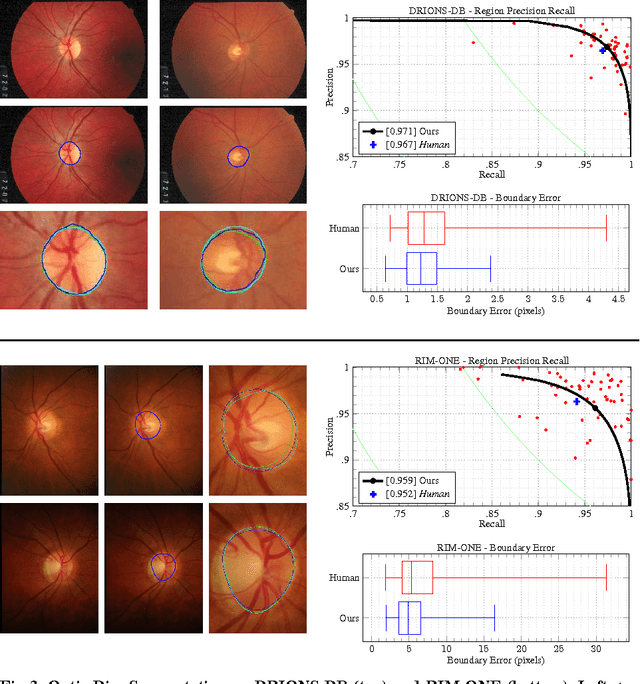
This paper presents Deep Retinal Image Understanding (DRIU), a unified framework of retinal image analysis that provides both retinal vessel and optic disc segmentation. We make use of deep Convolutional Neural Networks (CNNs), which have proven revolutionary in other fields of computer vision such as object detection and image classification, and we bring their power to the study of eye fundus images. DRIU uses a base network architecture on which two set of specialized layers are trained to solve both the retinal vessel and optic disc segmentation. We present experimental validation, both qualitative and quantitative, in four public datasets for these tasks. In all of them, DRIU presents super-human performance, that is, it shows results more consistent with a gold standard than a second human annotator used as control.
CompressAI: a PyTorch library and evaluation platform for end-to-end compression research
Nov 05, 2020
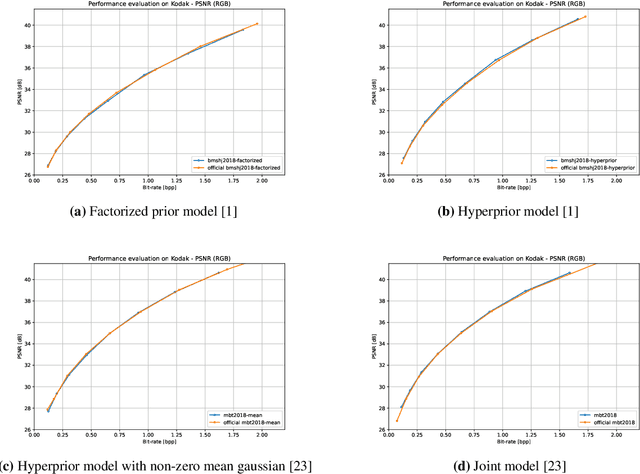

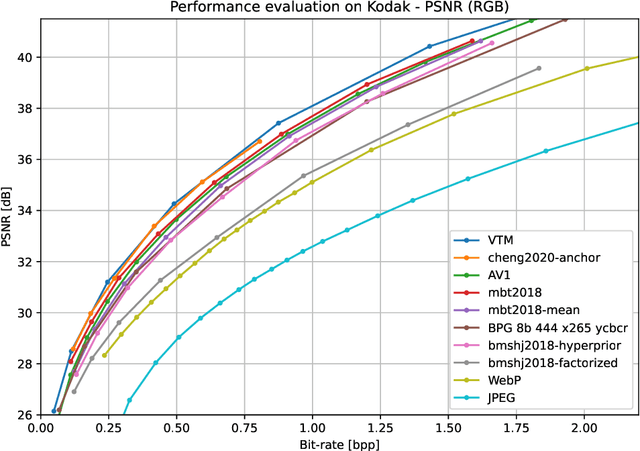
This paper presents CompressAI, a platform that provides custom operations, layers, models and tools to research, develop and evaluate end-to-end image and video compression codecs. In particular, CompressAI includes pre-trained models and evaluation tools to compare learned methods with traditional codecs. Multiple models from the state-of-the-art on learned end-to-end compression have thus been reimplemented in PyTorch and trained from scratch. We also report objective comparison results using PSNR and MS-SSIM metrics vs. bit-rate, using the Kodak image dataset as test set. Although this framework currently implements models for still-picture compression, it is intended to be soon extended to the video compression domain.
FKIMNet: A Finger Dorsal Image Matching Network Comparing Component (Major, Minor and Nail) Matching with Holistic (Finger Dorsal) Matching
Apr 02, 2019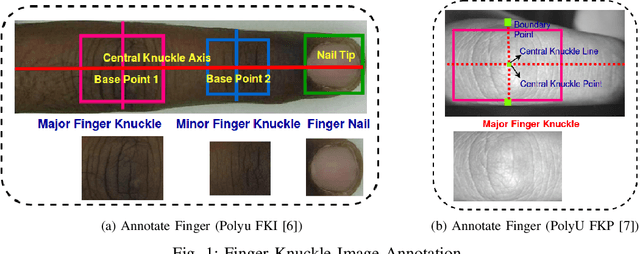
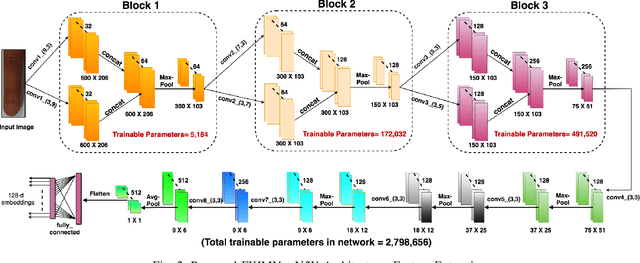
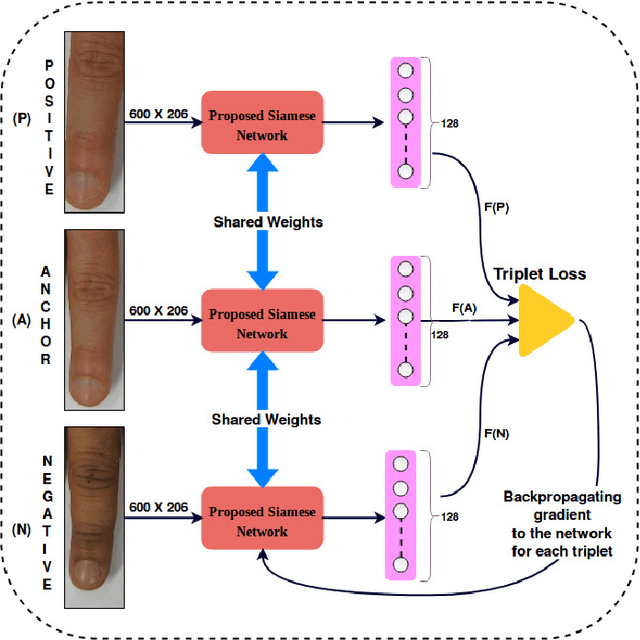
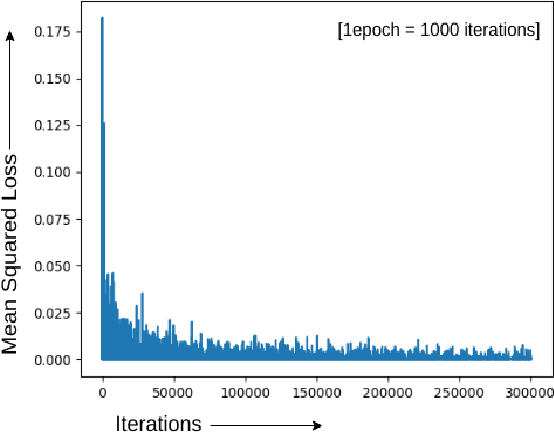
Current finger knuckle image recognition systems, often require users to place fingers' major or minor joints flatly towards the capturing sensor. To extend these systems for user non-intrusive application scenarios, such as consumer electronics, forensic, defence etc, we suggest matching the full dorsal fingers, rather than the major/ minor region of interest (ROI) alone. In particular, this paper makes a comprehensive study on the comparisons between full finger and fusion of finger ROI's for finger knuckle image recognition. These experiments suggest that using full-finger, provides a more elegant solution. Addressing the finger matching problem, we propose a CNN (convolutional neural network) which creates a $128$-D feature embedding of an image. It is trained via. triplet loss function, which enforces the L2 distance between the embeddings of the same subject to be approaching zero, whereas the distance between any 2 embeddings of different subjects to be at least a margin. For precise training of the network, we use dynamic adaptive margin, data augmentation, and hard negative mining. In distinguished experiments, the individual performance of finger, as well as weighted sum score level fusion of major knuckle, minor knuckle, and nail modalities have been computed, justifying our assumption to consider full finger as biometrics instead of its counterparts. The proposed method is evaluated using two publicly available finger knuckle image datasets i.e., PolyU FKP dataset and PolyU Contactless FKI Datasets.
Modeling Graph Node Correlations with Neighbor Mixture Models
Mar 29, 2021
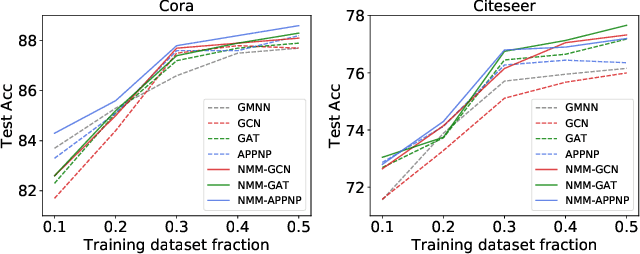
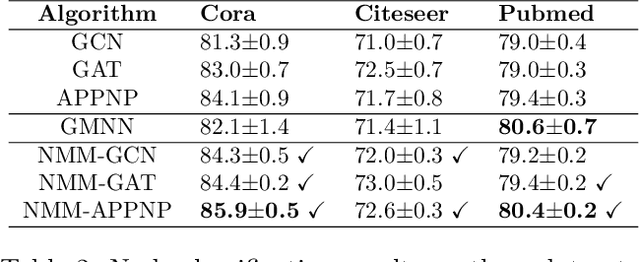
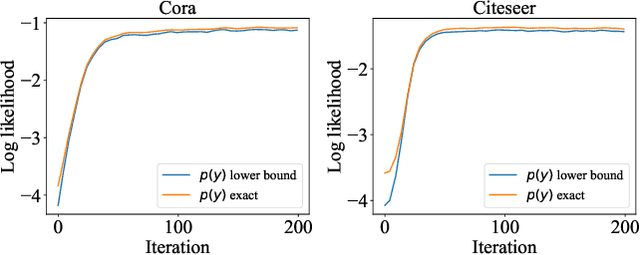
We propose a new model, the Neighbor Mixture Model (NMM), for modeling node labels in a graph. This model aims to capture correlations between the labels of nodes in a local neighborhood. We carefully design the model so it could be an alternative to a Markov Random Field but with more affordable computations. In particular, drawing samples and evaluating marginal probabilities of single labels can be done in linear time. To scale computations to large graphs, we devise a variational approximation without introducing extra parameters. We further use graph neural networks (GNNs) to parameterize the NMM, which reduces the number of learnable parameters while allowing expressive representation learning. The proposed model can be either fit directly to large observed graphs or used to enable scalable inference that preserves correlations for other distributions such as deep generative graph models. Across a diverse set of node classification, image denoising, and link prediction tasks, we show our proposed NMM advances the state-of-the-art in modeling real-world labeled graphs.
Where are the Masks: Instance Segmentation with Image-level Supervision
Jul 02, 2019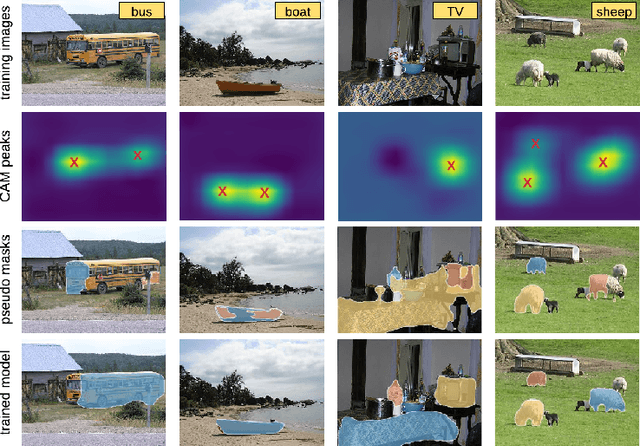
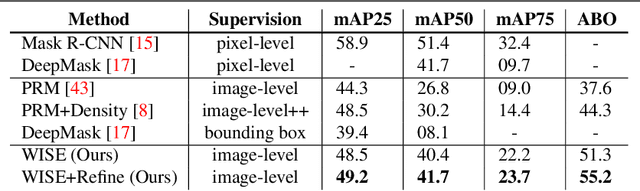
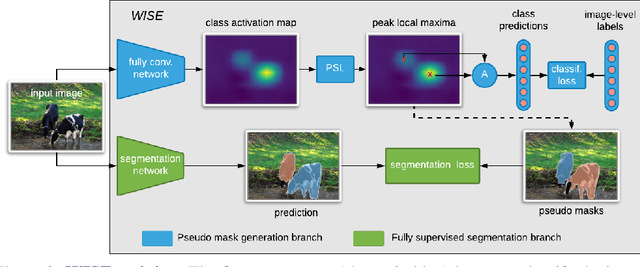

A major obstacle in instance segmentation is that existing methods often need many per-pixel labels in order to be effective. These labels require large human effort and for certain applications, such labels are not readily available. To address this limitation, we propose a novel framework that can effectively train with image-level labels, which are significantly cheaper to acquire. For instance, one can do an internet search for the term "car" and obtain many images where a car is present with minimal effort. Our framework consists of two stages: (1) train a classifier to generate pseudo masks for the objects of interest; (2) train a fully supervised Mask R-CNN on these pseudo masks. Our two main contribution are proposing a pipeline that is simple to implement and is amenable to different segmentation methods; and achieves new state-of-the-art results for this problem setup. Our results are based on evaluating our method on PASCAL VOC 2012, a standard dataset for weakly supervised methods, where we demonstrate major performance gains compared to existing methods with respect to mean average precision.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021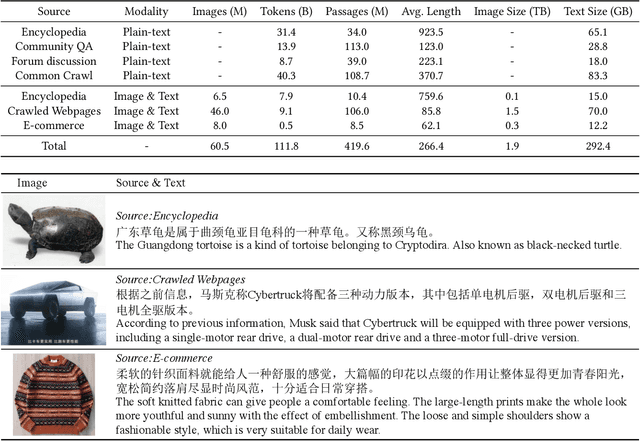
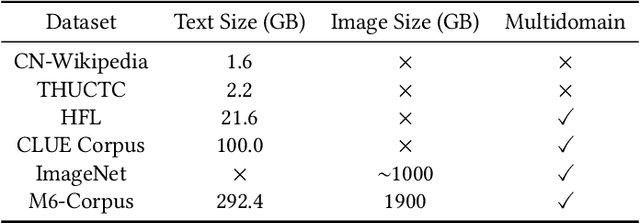

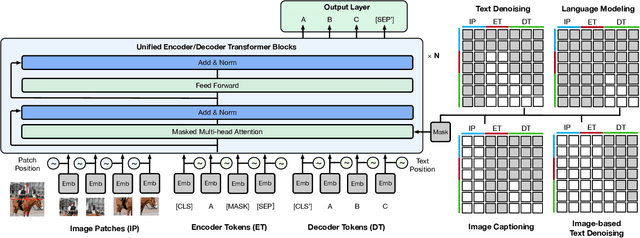
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.
Real-Time COVID-19 Diagnosis from X-Ray Images Using Deep CNN and Extreme Learning Machines Stabilized by Chimp Optimization Algorithm
May 14, 2021
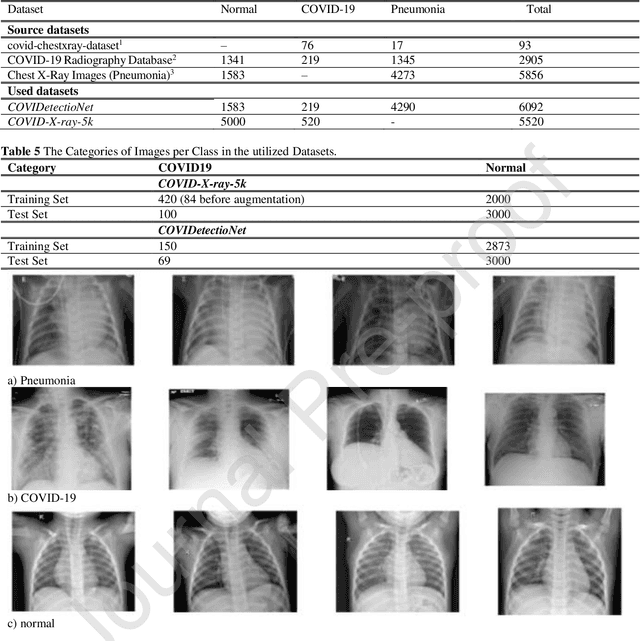
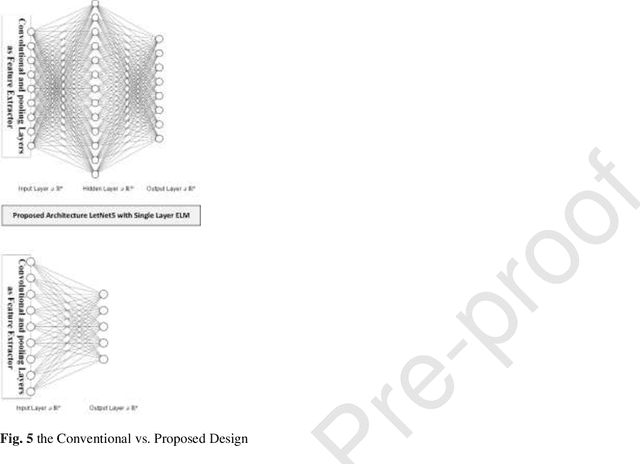
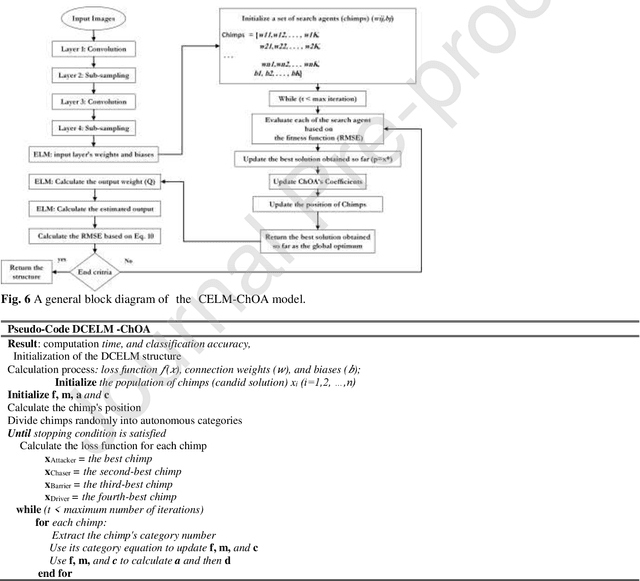
Real-time detection of COVID-19 using radiological images has gained priority due to the increasing demand for fast diagnosis of COVID-19 cases. This paper introduces a novel two-phase approach for classifying chest X-ray images. Deep Learning (DL) methods fail to cover these aspects since training and fine-tuning the model's parameters consume much time. In this approach, the first phase comes to train a deep CNN working as a feature extractor, and the second phase comes to use Extreme Learning Machines (ELMs) for real-time detection. The main drawback of ELMs is to meet the need of a large number of hidden-layer nodes to gain a reliable and accurate detector in applying image processing since the detective performance remarkably depends on the setting of initial weights and biases. Therefore, this paper uses Chimp Optimization Algorithm (ChOA) to improve results and increase the reliability of the network while maintaining real-time capability. The designed detector is to be benchmarked on the COVID-Xray-5k and COVIDetectioNet datasets, and the results are verified by comparing it with the classic DCNN, Genetic Algorithm optimized ELM (GA-ELM), Cuckoo Search optimized ELM (CS-ELM), and Whale Optimization Algorithm optimized ELM (WOA-ELM). The proposed approach outperforms other comparative benchmarks with 98.25% and 99.11% as ultimate accuracy on the COVID-Xray-5k and COVIDetectioNet datasets, respectively, and it led relative error to reduce as the amount of 1.75% and 1.01% as compared to a convolutional CNN. More importantly, the time needed for training deep ChOA-ELM is only 0.9474 milliseconds, and the overall testing time for 3100 images is 2.937 seconds.
* 17 pages. arXiv admin note: text overlap with arXiv:2105.14192