 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021
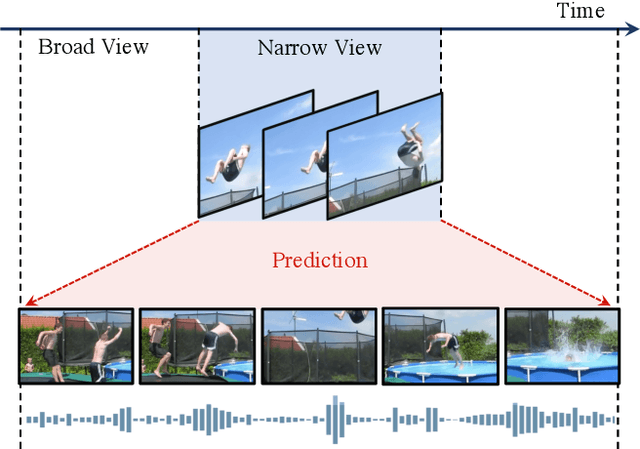
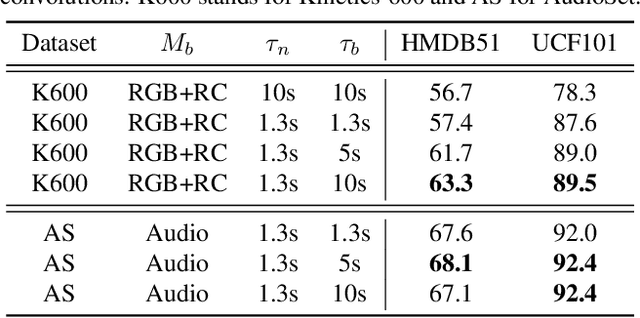
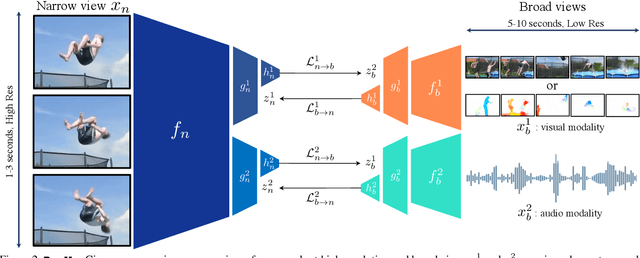
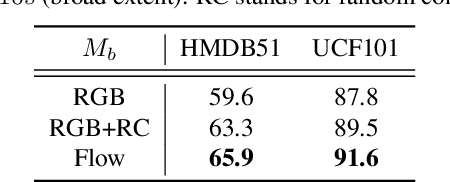
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Quality Classified Image Analysis with Application to Face Detection and Recognition
Jan 19, 2018
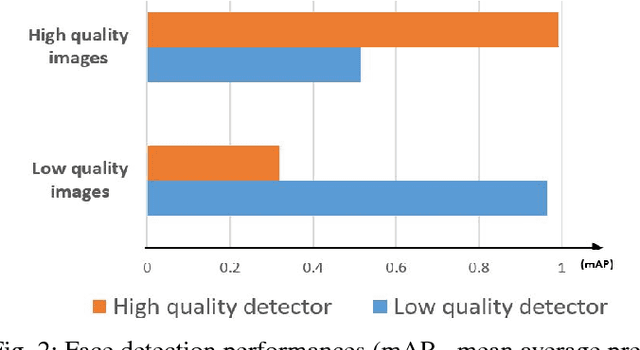
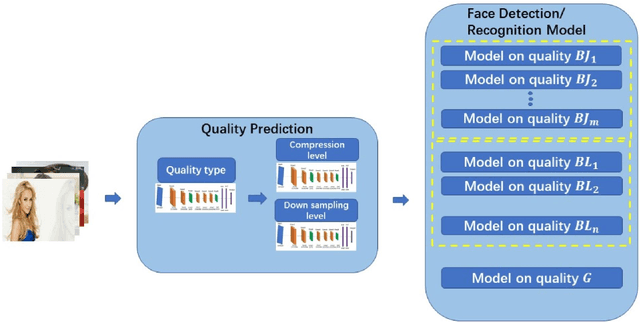
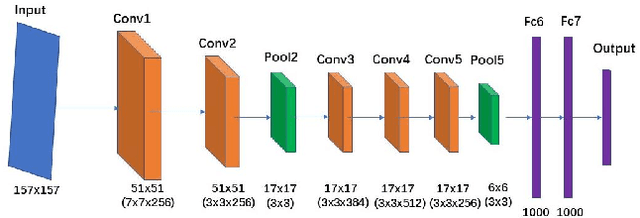
Motion blur, out of focus, insufficient spatial resolution, lossy compression and many other factors can all cause an image to have poor quality. However, image quality is a largely ignored issue in traditional pattern recognition literature. In this paper, we use face detection and recognition as case studies to show that image quality is an essential factor which will affect the performances of traditional algorithms. We demonstrated that it is not the image quality itself that is the most important, but rather the quality of the images in the training set should have similar quality as those in the testing set. To handle real-world application scenarios where images with different kinds and severities of degradation can be presented to the system, we have developed a quality classified image analysis framework to deal with images of mixed qualities adaptively. We use deep neural networks first to classify images based on their quality classes and then design a separate face detector and recognizer for images in each quality class. We will present experimental results to show that our quality classified framework can accurately classify images based on the type and severity of image degradations and can significantly boost the performances of state-of-the-art face detector and recognizer in dealing with image datasets containing mixed quality images.
Restoring Spatially-Heterogeneous Distortions using Mixture of Experts Network
Sep 30, 2020
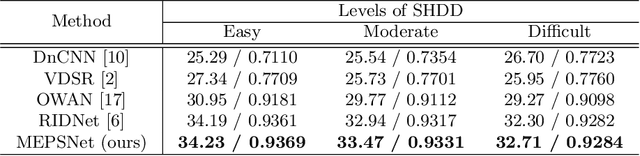
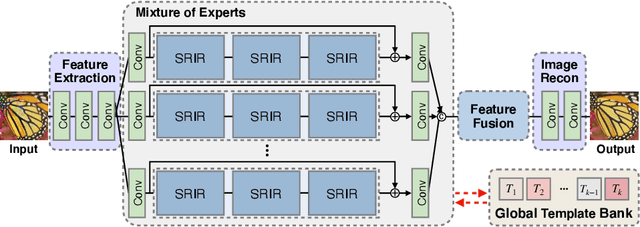

In recent years, deep learning-based methods have been successfully applied to the image distortion restoration tasks. However, scenarios that assume a single distortion only may not be suitable for many real-world applications. To deal with such cases, some studies have proposed sequentially combined distortions datasets. Viewing in a different point of combining, we introduce a spatially-heterogeneous distortion dataset in which multiple corruptions are applied to the different locations of each image. In addition, we also propose a mixture of experts network to effectively restore a multi-distortion image. Motivated by the multi-task learning, we design our network to have multiple paths that learn both common and distortion-specific representations. Our model is effective for restoring real-world distortions and we experimentally verify that our method outperforms other models designed to manage both single distortion and multiple distortions.
EigenRank by Committee: A Data Subset Selection and Failure Prediction paradigm for Robust Deep Learning based Medical Image Segmentation
Aug 17, 2019
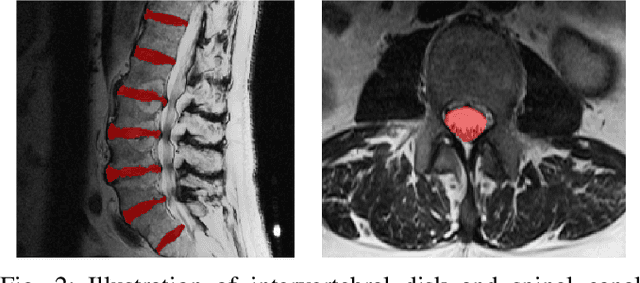
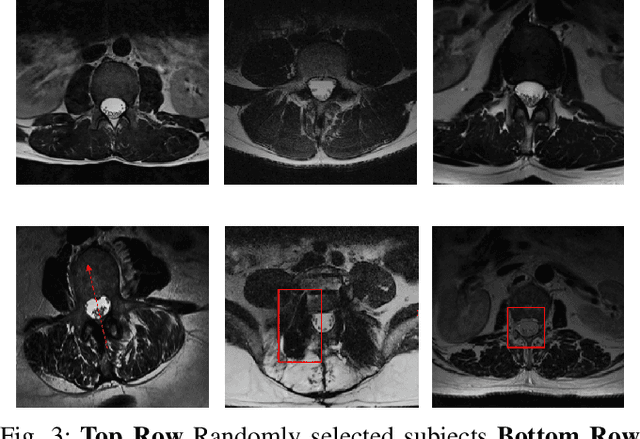
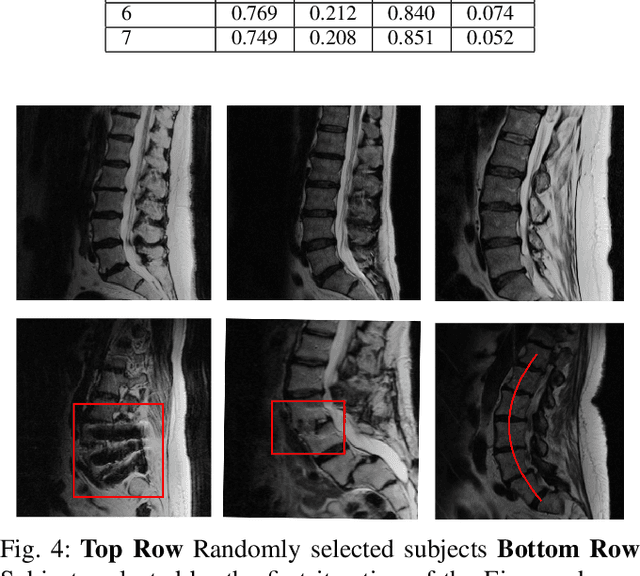
Translation of fully automated deep learning based medical image segmentation technologies to clinical workflows face two main algorithmic challenges. The first, is the collection and archival of large quantities of manually annotated ground truth data for both training and validation. The second is the relative inability of the majority of deep learning based segmentation techniques to alert physicians to a likely segmentation failure. Here we propose a novel algorithm, named `Eigenrank' which addresses both of these challenges. Eigenrank can select for manual labeling, a subset of medical images from a large database, such that a U-Net trained on this subset is superior to one trained on a randomly selected subset of the same size. Eigenrank can also be used to pick out, cases in a large database, where deep learning segmentation will fail. We present our algorithm, followed by results and a discussion of how Eigenrank exploits the Von Neumann information to perform both data subset selection and failure prediction for medical image segmentation using deep learning.
CANDY: Conditional Adversarial Networks based Fully End-to-End System for Single Image Haze Removal
May 02, 2018
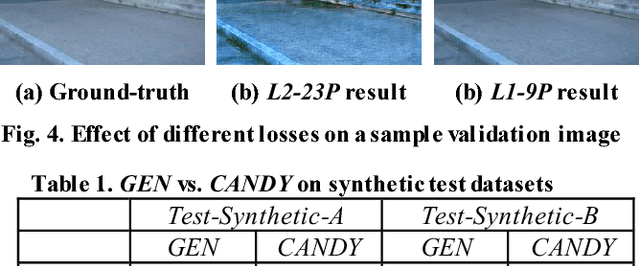
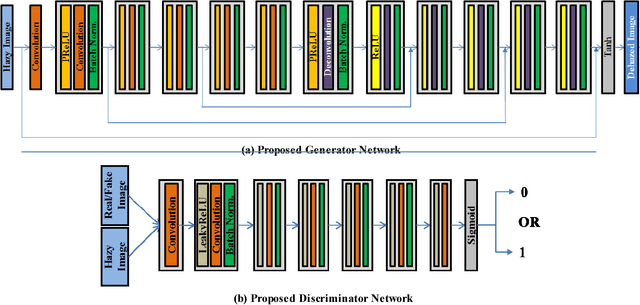
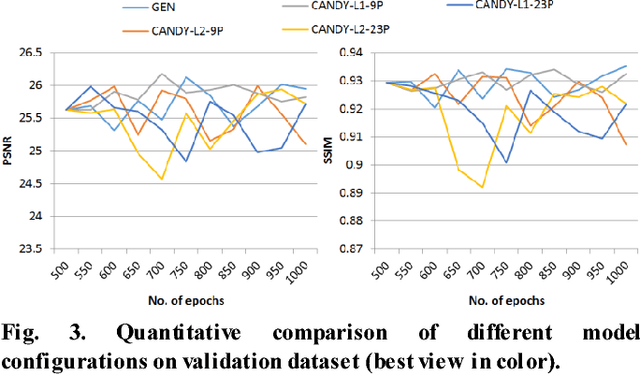
Single image haze removal is a very challenging and ill-posed problem. The existing haze removal methods in literature, including the recently introduced deep learning methods, model the problem of haze removal as that of estimating intermediate parameters, viz., scene transmission map and atmospheric light. These are used to compute the haze-free image from the hazy input image. Such an approach only focuses on accurate estimation of intermediate parameters, while the aesthetic quality of the haze-free image is unaccounted for in the optimization framework. Thus, errors in the estimation of intermediate parameters often lead to generation of inferior quality haze-free images. In this paper, we present CANDY (Conditional Adversarial Networks based Dehazing of hazY images), a fully end-to-end model which directly generates a clean haze-free image from a hazy input image. CANDY also incorporates the visual quality of haze-free image into the optimization function; thus, generating a superior quality haze-free image. To the best of our knowledge, this is the first work in literature to propose a fully end-to-end model for single image haze removal. Also, this is the first work to explore the newly introduced concept of generative adversarial networks for the problem of single image haze removal. The proposed model CANDY was trained on a synthetically created haze image dataset, while evaluation was performed on challenging synthetic as well as real haze image datasets. The extensive evaluation and comparison results of CANDY reveal that it significantly outperforms existing state-of-the-art haze removal methods in literature, both quantitatively as well as qualitatively.
Three Dimensional Fluorescence Microscopy Image Synthesis and Segmentation
Apr 21, 2018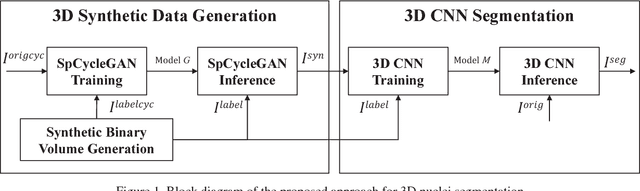
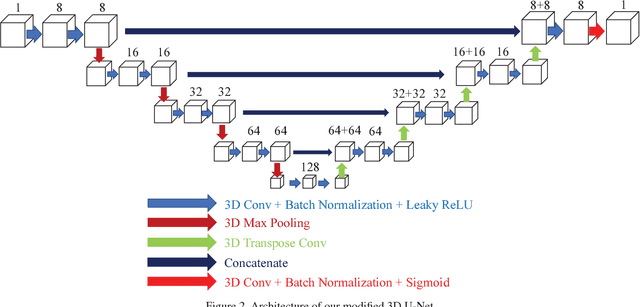
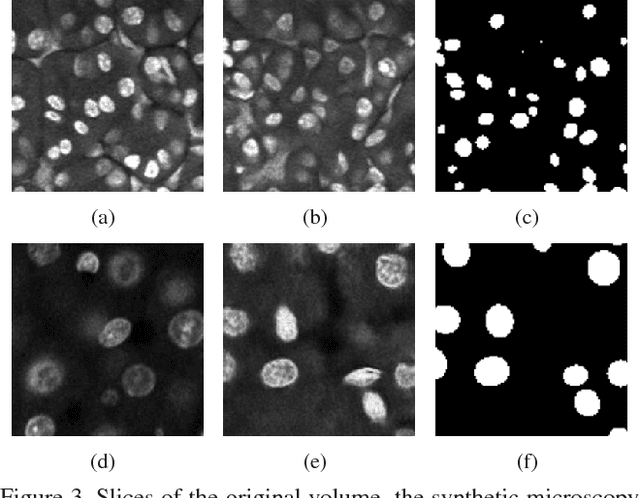
Advances in fluorescence microscopy enable acquisition of 3D image volumes with better image quality and deeper penetration into tissue. Segmentation is a required step to characterize and analyze biological structures in the images and recent 3D segmentation using deep learning has achieved promising results. One issue is that deep learning techniques require a large set of groundtruth data which is impractical to annotate manually for large 3D microscopy volumes. This paper describes a 3D deep learning nuclei segmentation method using synthetic 3D volumes for training. A set of synthetic volumes and the corresponding groundtruth are generated using spatially constrained cycle-consistent adversarial networks. Segmentation results demonstrate that our proposed method is capable of segmenting nuclei successfully for various data sets.
Conditional Image Generation for Learning the Structure of Visual Objects
Jun 20, 2018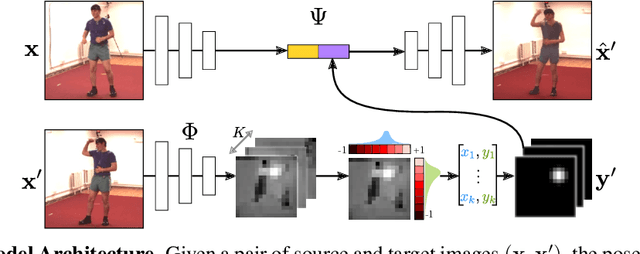
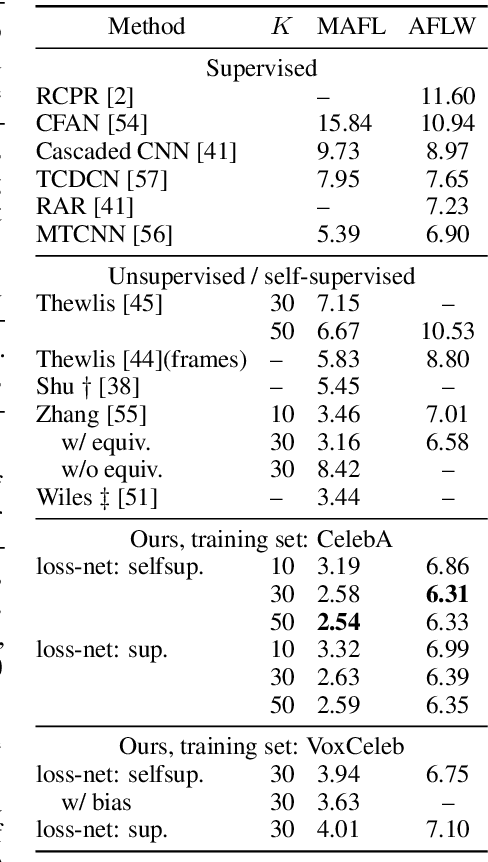

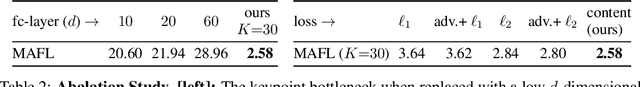
In this paper, we consider the problem of learning landmarks for object categories without any manual annotations. We cast this as the problem of conditionally generating an image of an object from another one, where the images differ by acquisition time and/or viewpoint. The process is aided by providing the generator with a keypoint-like representation extracted from the target image through a tight bottleneck. This encourages the representation to distil information about the object geometry, which changes from source to target, while the appearance, which is shared between the source and target, is read off from the source alone. Conditioning simplifies the generation task significantly, to the point that adopting a simple perceptual loss instead of more sophisticated approaches such as adversarial training is sufficient to learn landmarks. We show that our method is applicable to a large variety of datasets - faces, people, 3D objects, and digits - without any modifications. We further demonstrate that we can learn landmarks from synthetic image deformations or videos, all without manual supervision, while outperforming state-of-the-art unsupervised landmark detectors.
ChatPainter: Improving Text to Image Generation using Dialogue
Feb 22, 2018

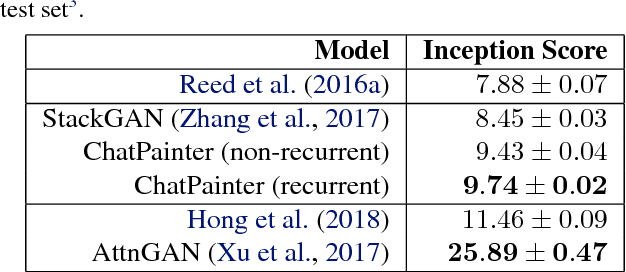
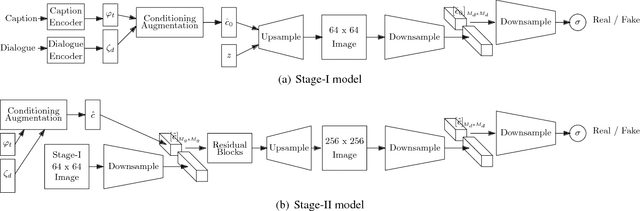
Synthesizing realistic images from text descriptions on a dataset like Microsoft Common Objects in Context (MS COCO), where each image can contain several objects, is a challenging task. Prior work has used text captions to generate images. However, captions might not be informative enough to capture the entire image and insufficient for the model to be able to understand which objects in the images correspond to which words in the captions. We show that adding a dialogue that further describes the scene leads to significant improvement in the inception score and in the quality of generated images on the MS COCO dataset.
E-LPIPS: Robust Perceptual Image Similarity via Random Transformation Ensembles
Jun 11, 2019


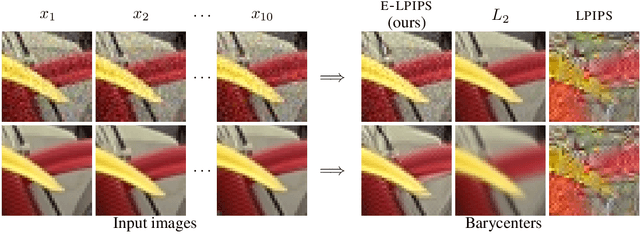
It has been recently shown that the hidden variables of convolutional neural networks make for an efficient perceptual similarity metric that accurately predicts human judgment on relative image similarity assessment. First, we show that such learned perceptual similarity metrics (LPIPS) are susceptible to adversarial attacks that dramatically contradict human visual similarity judgment. While this is not surprising in light of neural networks' well-known weakness to adversarial perturbations, we proceed to show that self-ensembling with an infinite family of random transformations of the input --- a technique known not to render classification networks robust --- is enough to turn the metric robust against attack, while retaining predictive power on human judgments. Finally, we study the geometry imposed by our our novel self-ensembled metric (E-LPIPS) on the space of natural images. We find evidence of "perceptual convexity" by showing that convex combinations of similar-looking images retain appearance, and that discrete geodesics yield meaningful frame interpolation and texture morphing, all without explicit correspondences.
Rethinking Spatial Dimensions of Vision Transformers
Mar 30, 2021
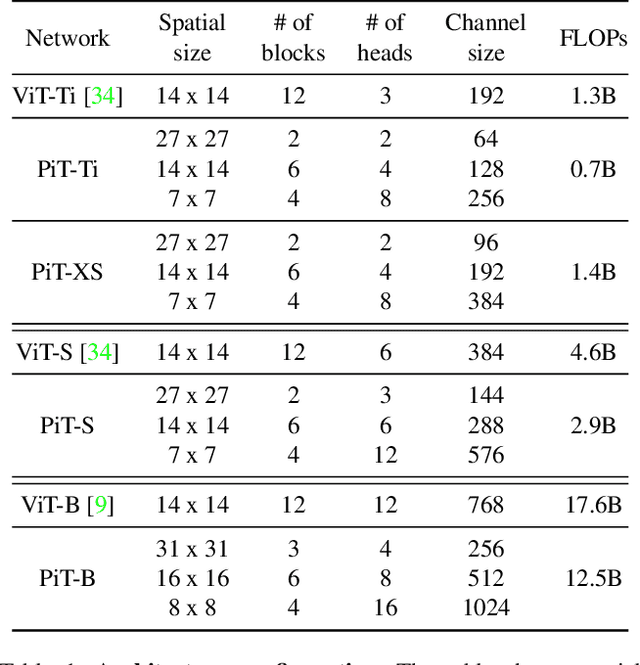
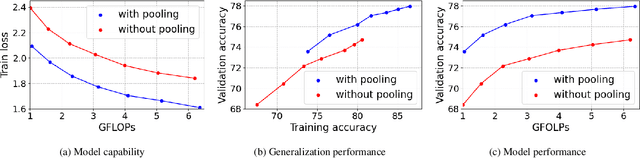
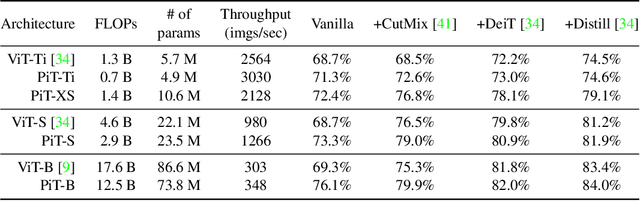
Vision Transformer (ViT) extends the application range of transformers from language processing to computer vision tasks as being an alternative architecture against the existing convolutional neural networks (CNN). Since the transformer-based architecture has been innovative for computer vision modeling, the design convention towards an effective architecture has been less studied yet. From the successful design principles of CNN, we investigate the role of the spatial dimension conversion and its effectiveness on the transformer-based architecture. We particularly attend the dimension reduction principle of CNNs; as the depth increases, a conventional CNN increases channel dimension and decreases spatial dimensions. We empirically show that such a spatial dimension reduction is beneficial to a transformer architecture as well, and propose a novel Pooling-based Vision Transformer (PiT) upon the original ViT model. We show that PiT achieves the improved model capability and generalization performance against ViT. Throughout the extensive experiments, we further show PiT outperforms the baseline on several tasks such as image classification, object detection and robustness evaluation. Source codes and ImageNet models are available at https://github.com/naver-ai/pit