 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Photo Scan: Semi-supervised learning for dealing with the real-world degradation in smartphone photo scanning
Feb 11, 2021
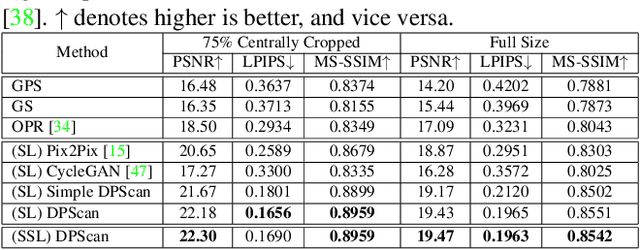
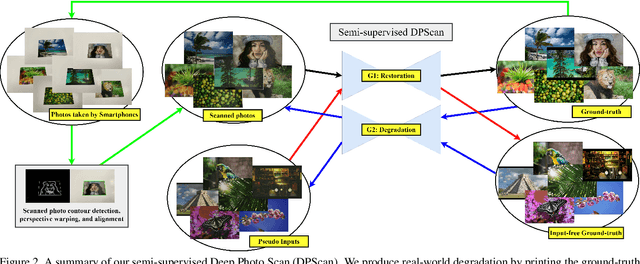
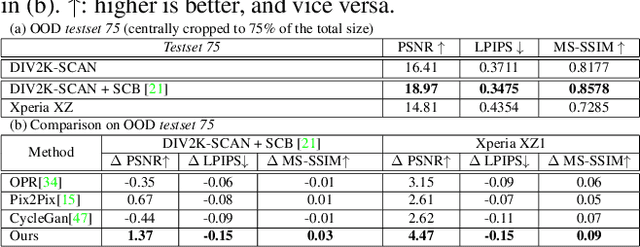
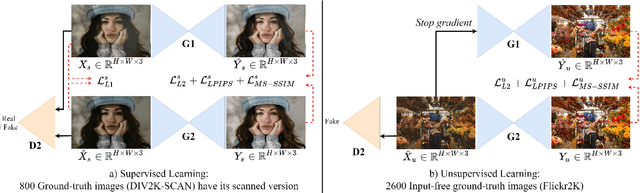
Physical photographs now can be conveniently scanned by smartphones and stored forever as a digital version, but the scanned photos are not restored well. One solution is to train a supervised deep neural network on many digital photos and the corresponding scanned photos. However, human annotation costs a huge resource leading to limited training data. Previous works create training pairs by simulating degradation using image processing techniques. Their synthetic images are formed with perfectly scanned photos in latent space. Even so, the real-world degradation in smartphone photo scanning remains unsolved since it is more complicated due to real lens defocus, lighting conditions, losing details via printing, various photo materials, and more. To solve these problems, we propose a Deep Photo Scan (DPScan) based on semi-supervised learning. First, we present the way to produce real-world degradation and provide the DIV2K-SCAN dataset for smartphone-scanned photo restoration. Second, by using DIV2K-SCAN, we adopt the concept of Generative Adversarial Networks to learn how to degrade a high-quality image as if it were scanned by a real smartphone, then generate pseudo-scanned photos for unscanned photos. Finally, we propose to train on the scanned and pseudo-scanned photos representing a semi-supervised approach with a cycle process as: high-quality images --> real-/pseudo-scanned photos --> reconstructed images. The proposed semi-supervised scheme can balance between supervised and unsupervised errors while optimizing to limit imperfect pseudo inputs but still enhance restoration. As a result, the proposed DPScan quantitatively and qualitatively outperforms its baseline architecture, state-of-the-art academic research, and industrial products in smartphone photo scanning.
Overcoming Catastrophic Forgetting with Gaussian Mixture Replay
Apr 19, 2021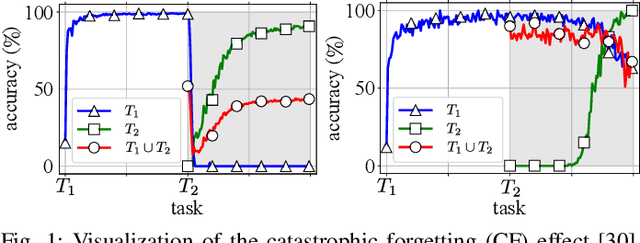

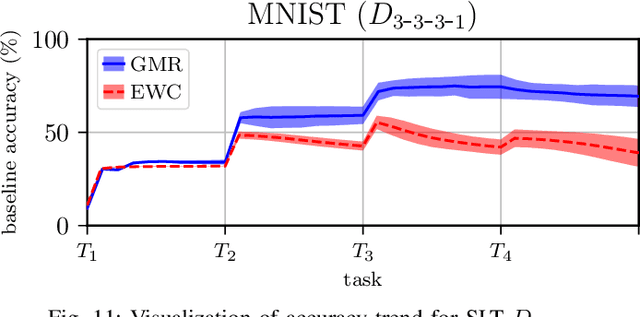
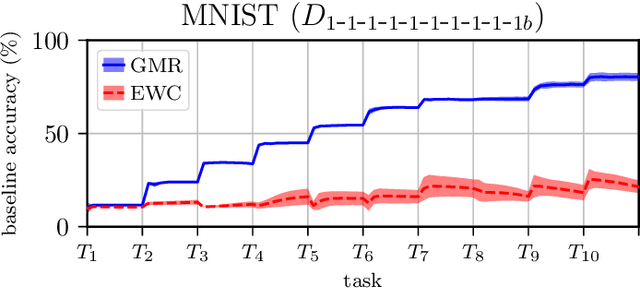
We present Gaussian Mixture Replay (GMR), a rehearsal-based approach for continual learning (CL) based on Gaussian Mixture Models (GMM). CL approaches are intended to tackle the problem of catastrophic forgetting (CF), which occurs for Deep Neural Networks (DNNs) when sequentially training them on successive sub-tasks. GMR mitigates CF by generating samples from previous tasks and merging them with current training data. GMMs serve several purposes here: sample generation, density estimation (e.g., for detecting outliers or recognizing task boundaries) and providing a high-level feature representation for classification. GMR has several conceptual advantages over existing replay-based CL approaches. First of all, GMR achieves sample generation, classification and density estimation in a single network structure with strongly reduced memory requirements. Secondly, it can be trained at constant time complexity w.r.t. the number of sub-tasks, making it particularly suitable for life-long learning. Furthermore, GMR minimizes a differentiable loss function and seems to avoid mode collapse. In addition, task boundaries can be detected by applying GMM density estimation. Lastly, GMR does not require access to sub-tasks lying in the future for hyper-parameter tuning, allowing CL under real-world constraints. We evaluate GMR on multiple image datasets, which are divided into class-disjoint sub-tasks.
Structure-From-Motion and RGBD Depth Fusion
Mar 10, 2021
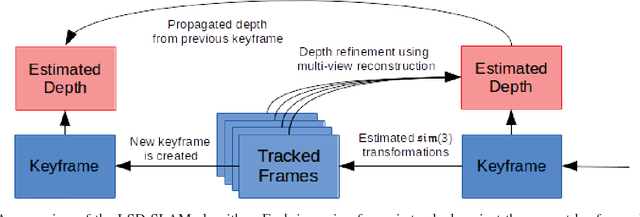
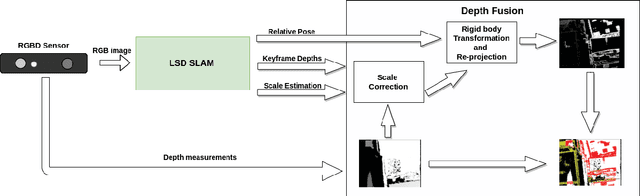

This article describes a technique to augment a typical RGBD sensor by integrating depth estimates obtained via Structure-from-Motion (SfM) with sensor depth measurements. Limitations in the RGBD depth sensing technology prevent capturing depth measurements in four important contexts: (1) distant surfaces (>5m), (2) dark surfaces, (3) brightly lit indoor scenes and (4) sunlit outdoor scenes. SfM technology computes depth via multi-view reconstruction from the RGB image sequence alone. As such, SfM depth estimates do not suffer the same limitations and may be computed in all four of the previously listed circumstances. This work describes a novel fusion of RGBD depth data and SfM-estimated depths to generate an improved depth stream that may be processed by one of many important downstream applications such as robotic localization and mapping, as well as object recognition and tracking.
FKIMNet: A Finger Dorsal Image Matching Network Comparing Component (Major, Minor and Nail) Matching with Holistic (Finger Dorsal) Matching
Apr 02, 2019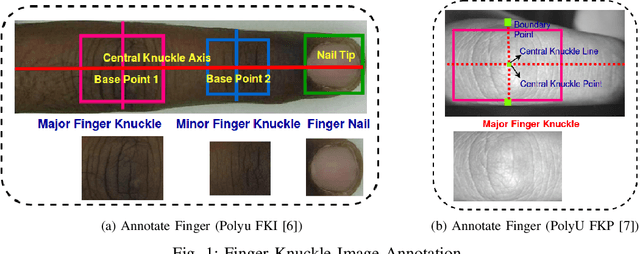
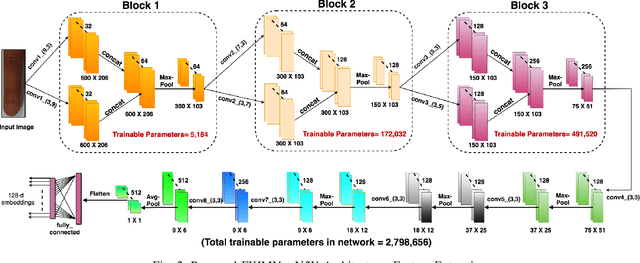
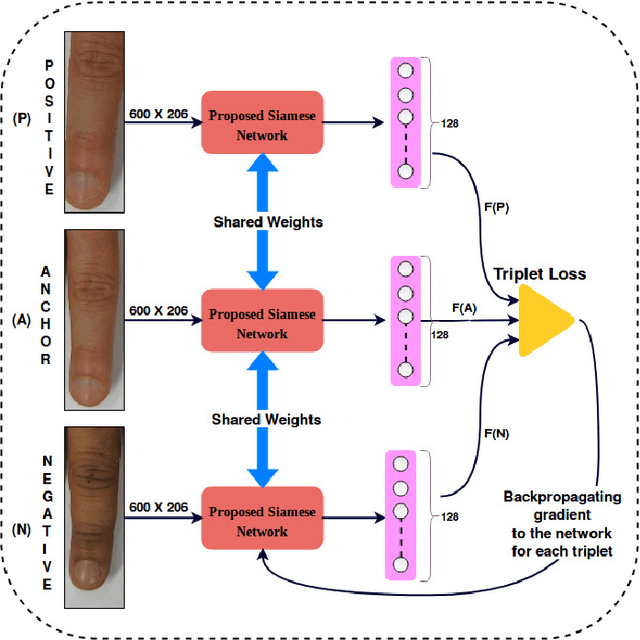
Current finger knuckle image recognition systems, often require users to place fingers' major or minor joints flatly towards the capturing sensor. To extend these systems for user non-intrusive application scenarios, such as consumer electronics, forensic, defence etc, we suggest matching the full dorsal fingers, rather than the major/ minor region of interest (ROI) alone. In particular, this paper makes a comprehensive study on the comparisons between full finger and fusion of finger ROI's for finger knuckle image recognition. These experiments suggest that using full-finger, provides a more elegant solution. Addressing the finger matching problem, we propose a CNN (convolutional neural network) which creates a $128$-D feature embedding of an image. It is trained via. triplet loss function, which enforces the L2 distance between the embeddings of the same subject to be approaching zero, whereas the distance between any 2 embeddings of different subjects to be at least a margin. For precise training of the network, we use dynamic adaptive margin, data augmentation, and hard negative mining. In distinguished experiments, the individual performance of finger, as well as weighted sum score level fusion of major knuckle, minor knuckle, and nail modalities have been computed, justifying our assumption to consider full finger as biometrics instead of its counterparts. The proposed method is evaluated using two publicly available finger knuckle image datasets i.e., PolyU FKP dataset and PolyU Contactless FKI Datasets.
Poisoning MorphNet for Clean-Label Backdoor Attack to Point Clouds
May 11, 2021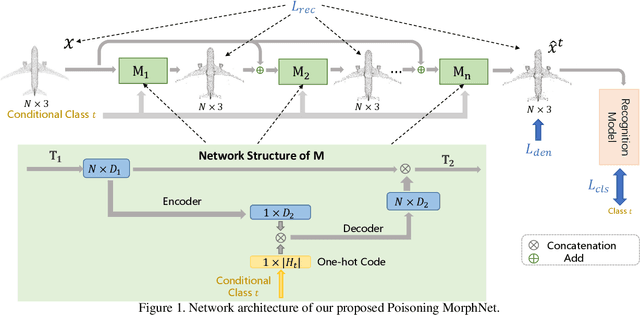

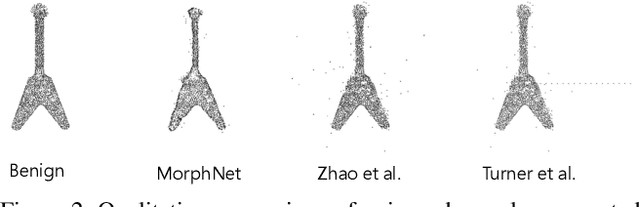

This paper presents Poisoning MorphNet, the first backdoor attack method on point clouds. Conventional adversarial attack takes place in the inference stage, often fooling a model by perturbing samples. In contrast, backdoor attack aims to implant triggers into a model during the training stage, such that the victim model acts normally on the clean data unless a trigger is present in a sample. This work follows a typical setting of clean-label backdoor attack, where a few poisoned samples (with their content tampered yet labels unchanged) are injected into the training set. The unique contributions of MorphNet are two-fold. First, it is key to ensure the implanted triggers both visually imperceptible to humans and lead to high attack success rate on the point clouds. To this end, MorphNet jointly optimizes two objectives for sample-adaptive poisoning: a reconstruction loss that preserves the visual similarity between benign / poisoned point clouds, and a classification loss that enforces a modern recognition model of point clouds tends to mis-classify the poisoned sample to a pre-specified target category. This implicitly conducts spectral separation over point clouds, hiding sample-adaptive triggers in fine-grained high-frequency details. Secondly, existing backdoor attack methods are mainly designed for image data, easily defended by some point cloud specific operations (such as denoising). We propose a third loss in MorphNet for suppressing isolated points, leading to improved resistance to denoising-based defense. Comprehensive evaluations are conducted on ModelNet40 and ShapeNetcorev2. Our proposed Poisoning MorphNet outstrips all previous methods with clear margins.
Conditional Variational Capsule Network for Open Set Recognition
Apr 19, 2021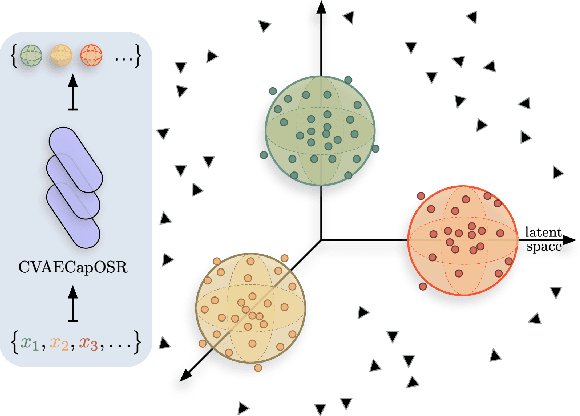
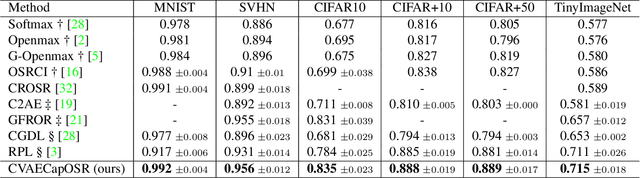
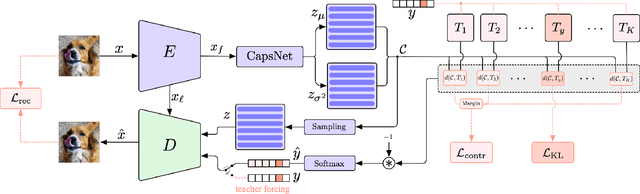

In open set recognition, a classifier has to detect unknown classes that are not known at training time. In order to recognize new classes, the classifier has to project the input samples of known classes in very compact and separated regions of the features space in order to discriminate outlier samples of unknown classes. Recently proposed Capsule Networks have shown to outperform alternatives in many fields, particularly in image recognition, however they have not been fully applied yet to open-set recognition. In capsule networks, scalar neurons are replaced by capsule vectors or matrices, whose entries represent different properties of objects. In our proposal, during training, capsules features of the same known class are encouraged to match a pre-defined gaussian, one for each class. To this end, we use the variational autoencoder framework, with a set of gaussian prior as the approximation for the posterior distribution. In this way, we are able to control the compactness of the features of the same class around the center of the gaussians, thus controlling the ability of the classifier in detecting samples from unknown classes. We conducted several experiments and ablation of our model, obtaining state of the art results on different datasets in the open set recognition and unknown detection tasks.
Using Deep Cross Modal Hashing and Error Correcting Codes for Improving the Efficiency of Attribute Guided Facial Image Retrieval
Feb 11, 2019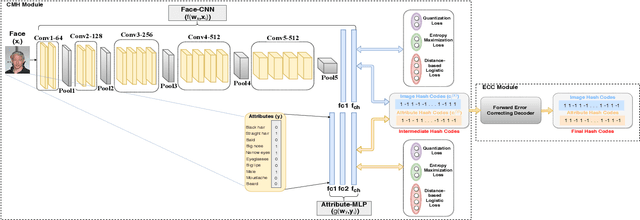

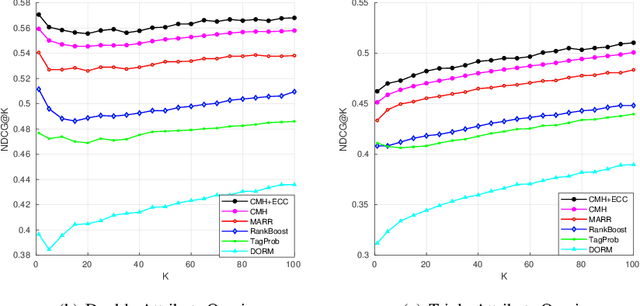
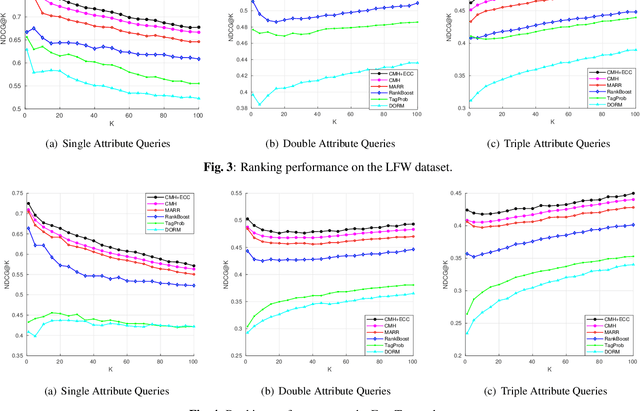
With benefits of fast query speed and low storage cost, hashing-based image retrieval approaches have garnered considerable attention from the research community. In this paper, we propose a novel Error-Corrected Deep Cross Modal Hashing (CMH-ECC) method which uses a bitmap specifying the presence of certain facial attributes as an input query to retrieve relevant face images from the database. In this architecture, we generate compact hash codes using an end-to-end deep learning module, which effectively captures the inherent relationships between the face and attribute modality. We also integrate our deep learning module with forward error correction codes to further reduce the distance between different modalities of the same subject. Specifically, the properties of deep hashing and forward error correction codes are exploited to design a cross modal hashing framework with high retrieval performance. Experimental results using two standard datasets with facial attributes-image modalities indicate that our CMH-ECC face image retrieval model outperforms most of the current attribute-based face image retrieval approaches.
Efficient and Differentiable Shadow Computation for Inverse Problems
Apr 01, 2021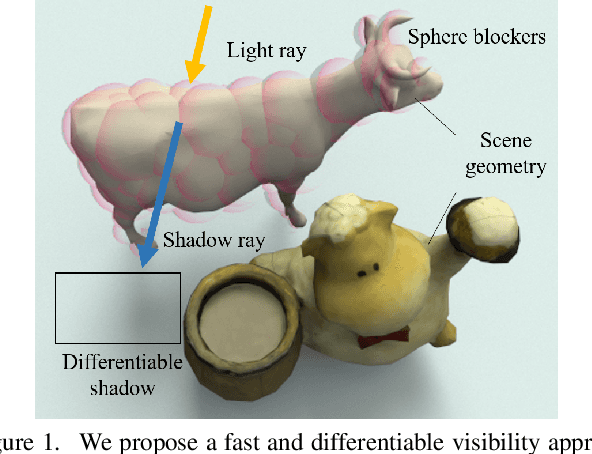
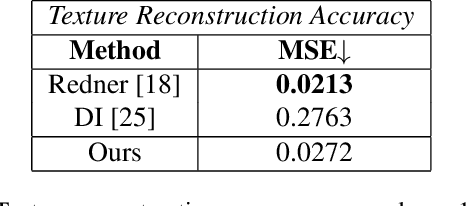
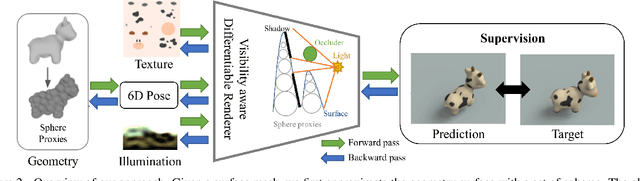
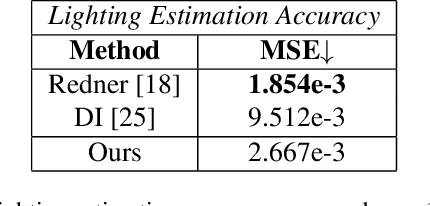
Differentiable rendering has received increasing interest for image-based inverse problems. It can benefit traditional optimization-based solutions to inverse problems, but also allows for self-supervision of learning-based approaches for which training data with ground truth annotation is hard to obtain. However, existing differentiable renderers either do not model visibility of the light sources from the different points in the scene, responsible for shadows in the images, or are too slow for being used to train deep architectures over thousands of iterations. To this end, we propose an accurate yet efficient approach for differentiable visibility and soft shadow computation. Our approach is based on the spherical harmonics approximations of the scene illumination and visibility, where the occluding surface is approximated with spheres. This allows for a significantly more efficient shadow computation compared to methods based on ray tracing. As our formulation is differentiable, it can be used to solve inverse problems such as texture, illumination, rigid pose, and geometric deformation recovery from images using analysis-by-synthesis optimization.
DeepViT: Towards Deeper Vision Transformer
Apr 19, 2021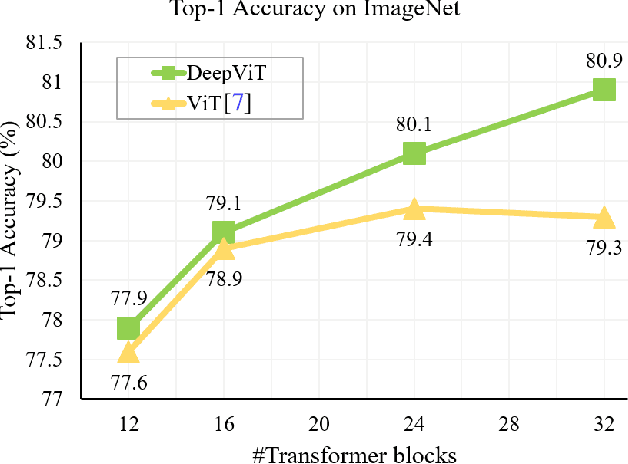
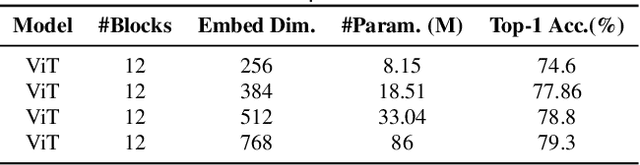
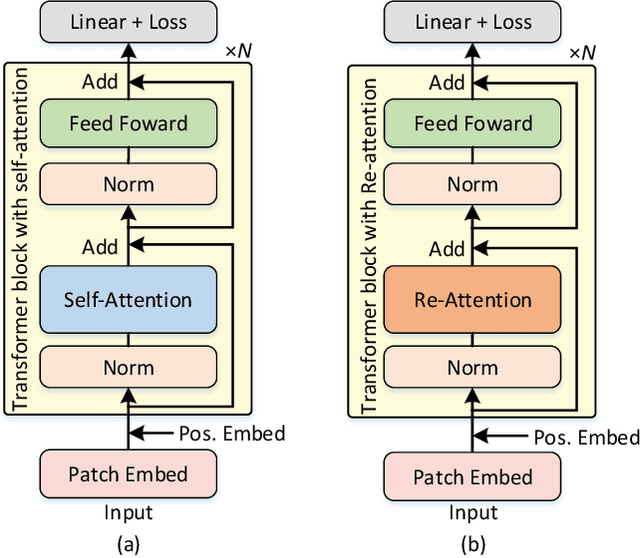

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.
Image based Eye Gaze Tracking and its Applications
Jul 09, 2019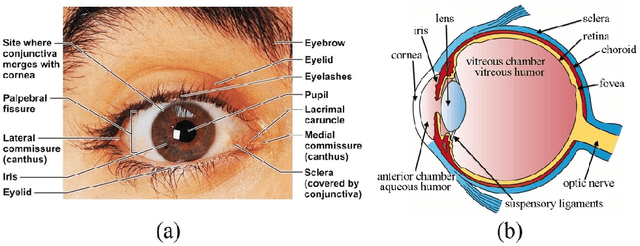
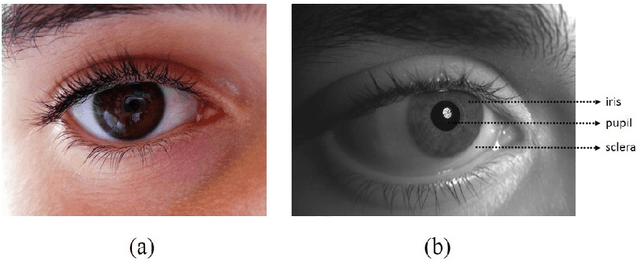

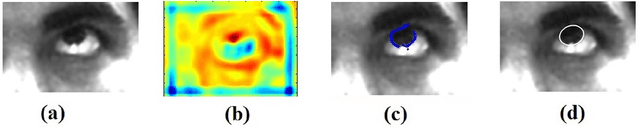
Eye movements play a vital role in perceiving the world. Eye gaze can give a direct indication of the users point of attention, which can be useful in improving human-computer interaction. Gaze estimation in a non-intrusive manner can make human-computer interaction more natural. Eye tracking can be used for several applications such as fatigue detection, biometric authentication, disease diagnosis, activity recognition, alertness level estimation, gaze-contingent display, human-computer interaction, etc. Even though eye-tracking technology has been around for many decades, it has not found much use in consumer applications. The main reasons are the high cost of eye tracking hardware and lack of consumer level applications. In this work, we attempt to address these two issues. In the first part of this work, image-based algorithms are developed for gaze tracking which includes a new two-stage iris center localization algorithm. We have developed a new algorithm which works in challenging conditions such as motion blur, glint, and varying illumination levels. A person independent gaze direction classification framework using a convolutional neural network is also developed which eliminates the requirement of user-specific calibration. In the second part of this work, we have developed two applications which can benefit from eye tracking data. A new framework for biometric identification based on eye movement parameters is developed. A framework for activity recognition, using gaze data from a head-mounted eye tracker is also developed. The information from gaze data, ego-motion, and visual features are integrated to classify the activities.