 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improve Vision Transformers Training by Suppressing Over-smoothing
Apr 26, 2021
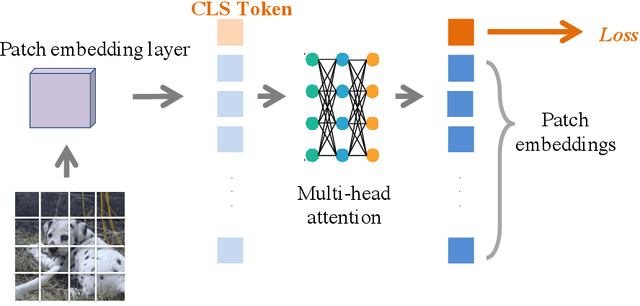

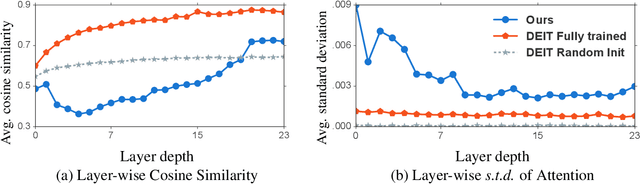
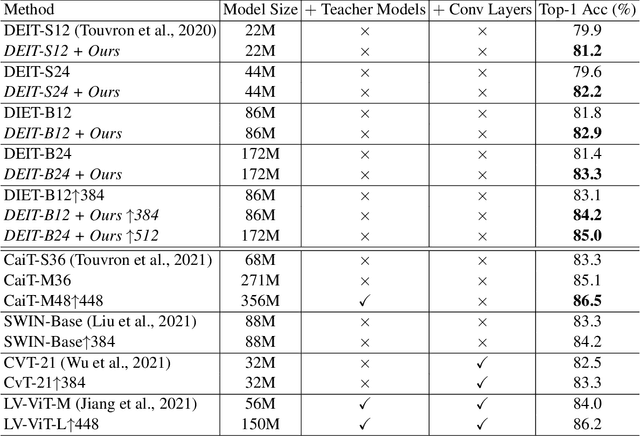
Introducing the transformer structure into computer vision tasks holds the promise of yielding a better speed-accuracy trade-off than traditional convolution networks. However, directly training vanilla transformers on vision tasks has been shown to yield unstable and sub-optimal results. As a result, recent works propose to modify transformer structures by incorporating convolutional layers to improve the performance on vision tasks. This work investigates how to stabilize the training of vision transformers \emph{without} special structure modification. We observe that the instability of transformer training on vision tasks can be attributed to the over-smoothing problem, that the self-attention layers tend to map the different patches from the input image into a similar latent representation, hence yielding the loss of information and degeneration of performance, especially when the number of layers is large. We then propose a number of techniques to alleviate this problem, including introducing additional loss functions to encourage diversity, prevent loss of information, and discriminate different patches by additional patch classification loss for Cutmix. We show that our proposed techniques stabilize the training and allow us to train wider and deeper vision transformers, achieving 85.0\% top-1 accuracy on ImageNet validation set without introducing extra teachers or additional convolution layers. Our code will be made publicly available at https://github.com/ChengyueGongR/PatchVisionTransformer .
AdaBins: Depth Estimation using Adaptive Bins
Nov 28, 2020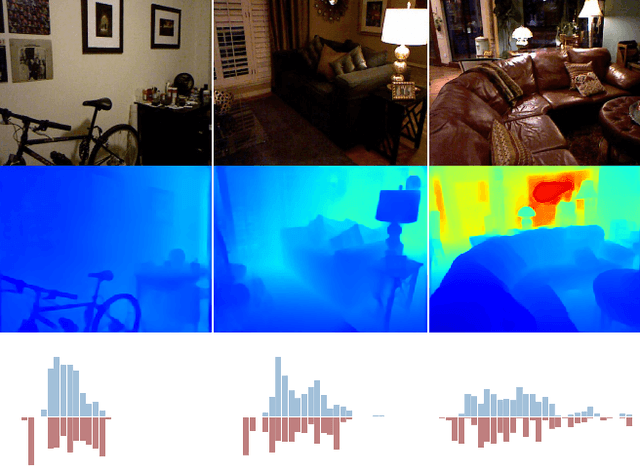

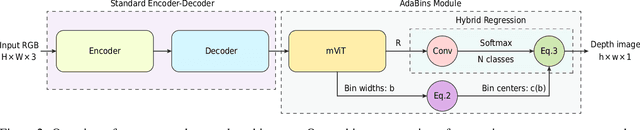
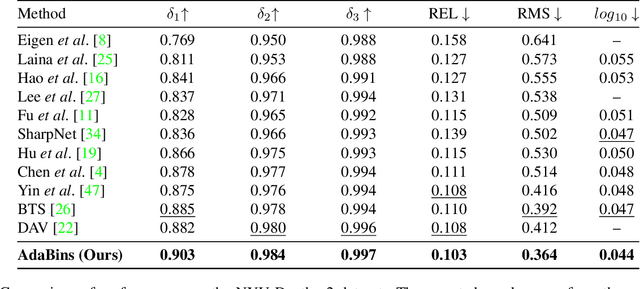
We address the problem of estimating a high quality dense depth map from a single RGB input image. We start out with a baseline encoder-decoder convolutional neural network architecture and pose the question of how the global processing of information can help improve overall depth estimation. To this end, we propose a transformer-based architecture block that divides the depth range into bins whose center value is estimated adaptively per image. The final depth values are estimated as linear combinations of the bin centers. We call our new building block AdaBins. Our results show a decisive improvement over the state-of-the-art on several popular depth datasets across all metrics. We also validate the effectiveness of the proposed block with an ablation study and provide the code and corresponding pre-trained weights of the new state-of-the-art model.
Object Priors for Classifying and Localizing Unseen Actions
Apr 10, 2021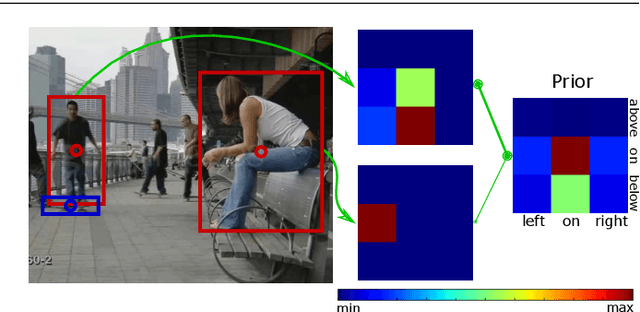

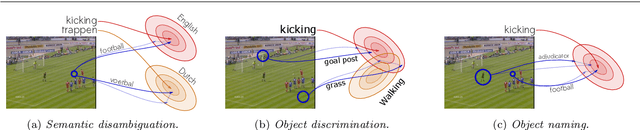
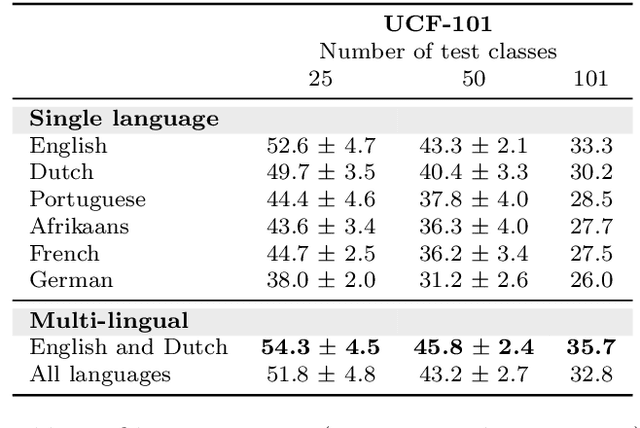
This work strives for the classification and localization of human actions in videos, without the need for any labeled video training examples. Where existing work relies on transferring global attribute or object information from seen to unseen action videos, we seek to classify and spatio-temporally localize unseen actions in videos from image-based object information only. We propose three spatial object priors, which encode local person and object detectors along with their spatial relations. On top we introduce three semantic object priors, which extend semantic matching through word embeddings with three simple functions that tackle semantic ambiguity, object discrimination, and object naming. A video embedding combines the spatial and semantic object priors. It enables us to introduce a new video retrieval task that retrieves action tubes in video collections based on user-specified objects, spatial relations, and object size. Experimental evaluation on five action datasets shows the importance of spatial and semantic object priors for unseen actions. We find that persons and objects have preferred spatial relations that benefit unseen action localization, while using multiple languages and simple object filtering directly improves semantic matching, leading to state-of-the-art results for both unseen action classification and localization.
Optimized CNN for PolSAR Image Classification via Differentiable Neural Architecture Search
Nov 16, 2019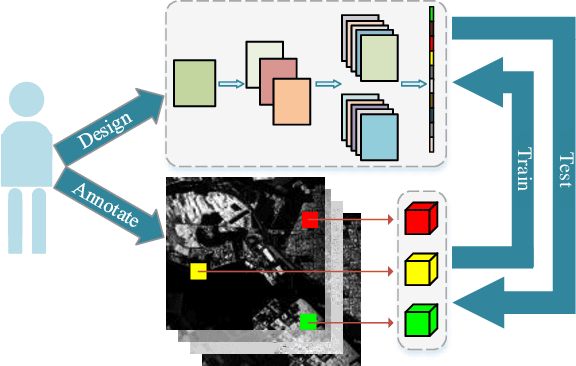
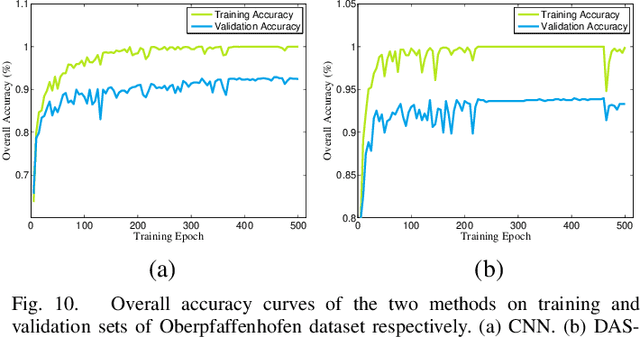
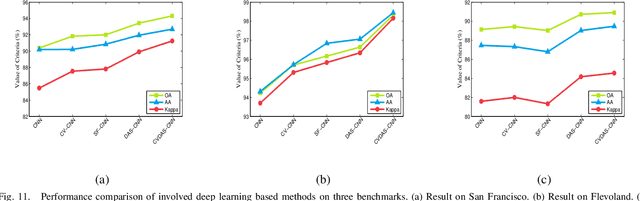
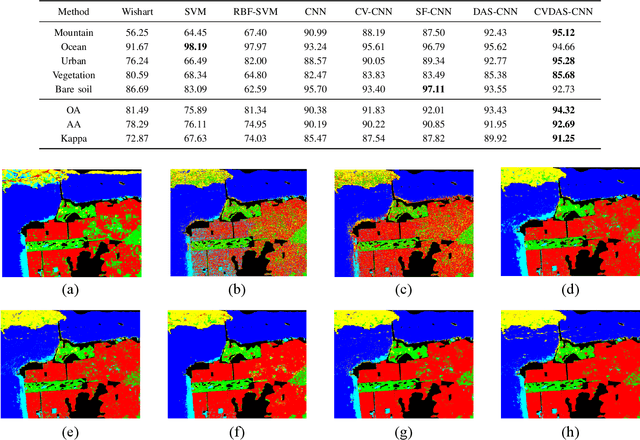
Convolutional neural networks (CNNs) realize the automation of feature engineering and their applications have shown good performance in polarimetric synthetic aperture radar (PolSAR) image classification. Excellent hand-crafted architectures of CNNs incorporated the wisdom of human experts, which is an important reason for CNN's success. However, the design of the architectures is a difficult problem, which needs a lot of professional knowledge as well as computational resources. Moreover, the architecture designed by hand must be suboptimal, because it is only one of thousands of unobserved but objective existed paths. Considering that the success of deep learning is largely due to its automation of the feature engineering process, how to design automatic architecture searching methods to replace the hand-crafted ones is an interesting topic. In this paper, we explore the application of neural architecture search (NAS) in PolSAR area for the first time. Different from the utilization of existing NAS methods, we propose a differentiable architecture search (DAS) method which is customized for PolSAR classification. The proposed DAS is equipped with a PolSAR tailored search space and an improved one-shot search strategy. By DAS, the weights parameters and architecture parameters (corresponds to the hyperparameters but not the topologies) can be optimized by stochastic gradient descent method during the training. The optimized architecture parameters should be transformed into corresponding CNN architecture and re-train to achieve high-precision PolSAR classification. In addition, complex-valued DAS is developed to take into account the characteristics of PolSAR images so as to further improve the performance. Experiments on three PolSAR benchmark datasets show that the CNNs obtained by searching have better classification performance than the hand-crafted ones.
Deep Photo Scan: Semi-supervised learning for dealing with the real-world degradation in smartphone photo scanning
Feb 11, 2021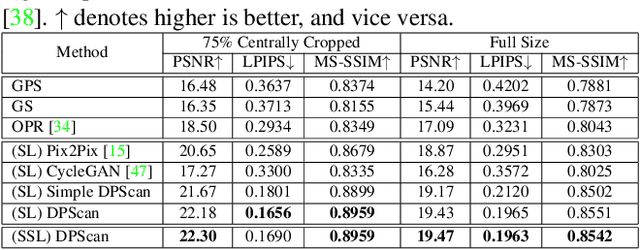
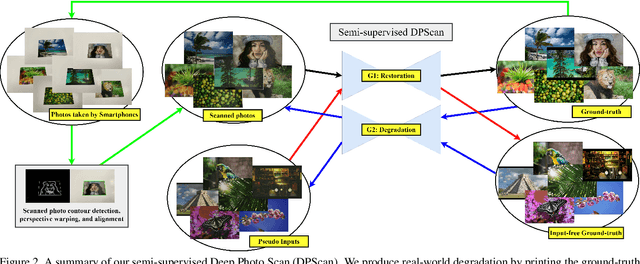
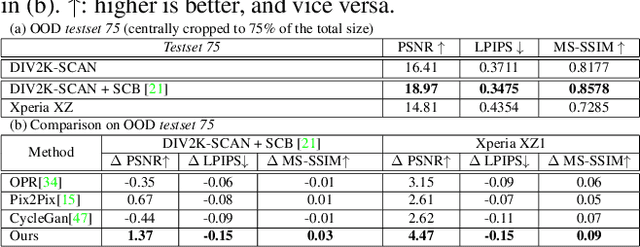
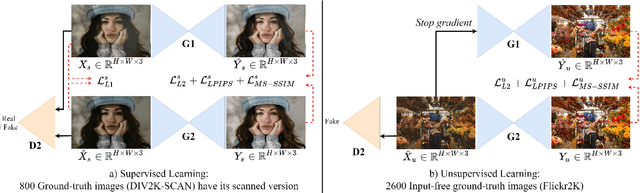
Physical photographs now can be conveniently scanned by smartphones and stored forever as a digital version, but the scanned photos are not restored well. One solution is to train a supervised deep neural network on many digital photos and the corresponding scanned photos. However, human annotation costs a huge resource leading to limited training data. Previous works create training pairs by simulating degradation using image processing techniques. Their synthetic images are formed with perfectly scanned photos in latent space. Even so, the real-world degradation in smartphone photo scanning remains unsolved since it is more complicated due to real lens defocus, lighting conditions, losing details via printing, various photo materials, and more. To solve these problems, we propose a Deep Photo Scan (DPScan) based on semi-supervised learning. First, we present the way to produce real-world degradation and provide the DIV2K-SCAN dataset for smartphone-scanned photo restoration. Second, by using DIV2K-SCAN, we adopt the concept of Generative Adversarial Networks to learn how to degrade a high-quality image as if it were scanned by a real smartphone, then generate pseudo-scanned photos for unscanned photos. Finally, we propose to train on the scanned and pseudo-scanned photos representing a semi-supervised approach with a cycle process as: high-quality images --> real-/pseudo-scanned photos --> reconstructed images. The proposed semi-supervised scheme can balance between supervised and unsupervised errors while optimizing to limit imperfect pseudo inputs but still enhance restoration. As a result, the proposed DPScan quantitatively and qualitatively outperforms its baseline architecture, state-of-the-art academic research, and industrial products in smartphone photo scanning.
Multiple Manifolds Metric Learning with Application to Image Set Classification
May 30, 2018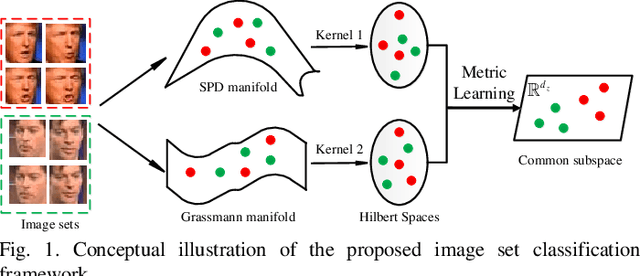
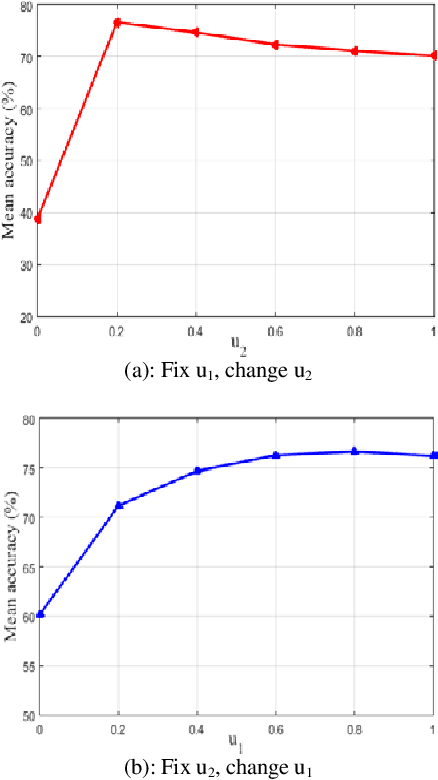
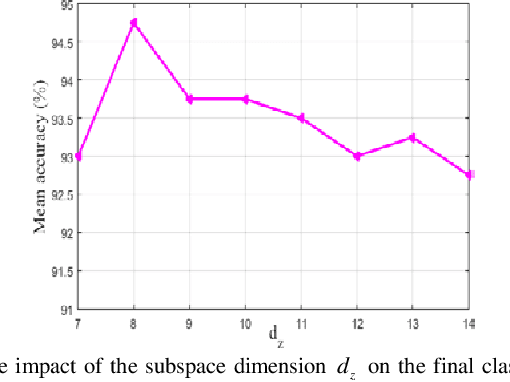
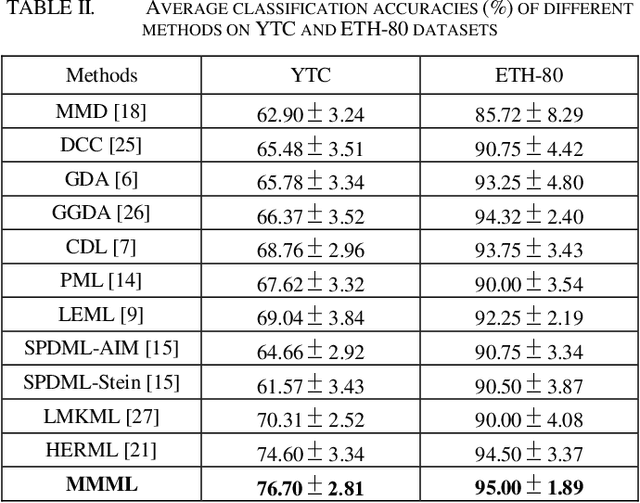
In image set classification, a considerable advance has been made by modeling the original image sets by second order statistics or linear subspace, which typically lie on the Riemannian manifold. Specifically, they are Symmetric Positive Definite (SPD) manifold and Grassmann manifold respectively, and some algorithms have been developed on them for classification tasks. Motivated by the inability of existing methods to extract discriminatory features for data on Riemannian manifolds, we propose a novel algorithm which combines multiple manifolds as the features of the original image sets. In order to fuse these manifolds, the well-studied Riemannian kernels have been utilized to map the original Riemannian spaces into high dimensional Hilbert spaces. A metric Learning method has been devised to embed these kernel spaces into a lower dimensional common subspace for classification. The state-of-the-art results achieved on three datasets corresponding to two different classification tasks, namely face recognition and object categorization, demonstrate the effectiveness of the proposed method.
Image analysis for Alzheimer's disease prediction: Embracing pathological hallmarks for model architecture design
Nov 13, 2020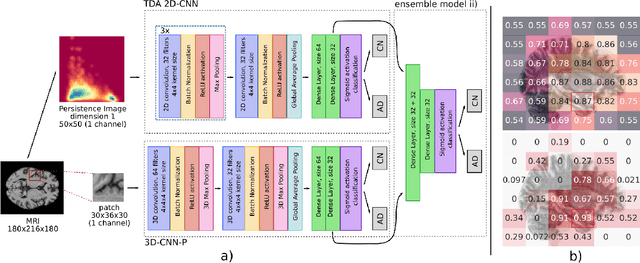
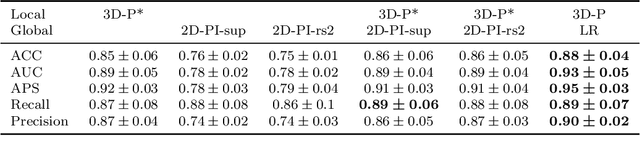
Alzheimer's disease (AD) is associated with local (e.g. brain tissue atrophy) and global brain changes (loss of cerebral connectivity), which can be detected by high-resolution structural magnetic resonance imaging. Conventionally, these changes and their relation to AD are investigated independently. Here, we introduce a novel, highly-scalable approach that simultaneously captures $\textit{local}$ and $\textit{global}$ changes in the diseased brain. It is based on a neural network architecture that combines patch-based, high-resolution 3D-CNNs with global topological features, evaluating multi-scale brain tissue connectivity. Our local-global approach reached competitive results with an average precision score of $0.95\pm0.03$ for the classification of cognitively normal subjects and AD patients (prevalence $\approx 55\%$).
What's in my closet?: Image classification using fuzzy logic
Dec 05, 2017

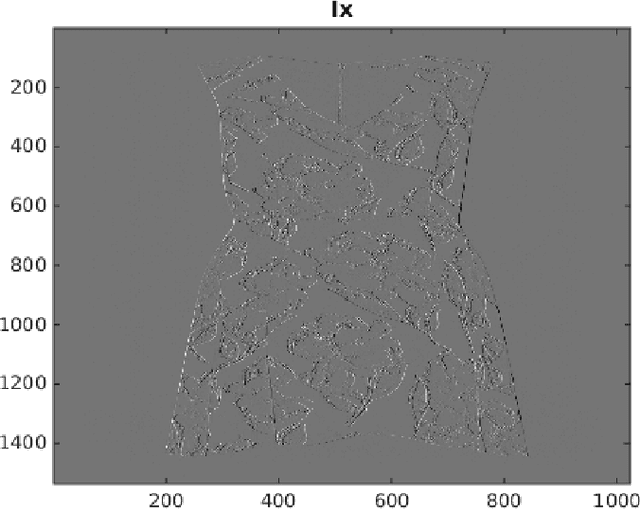
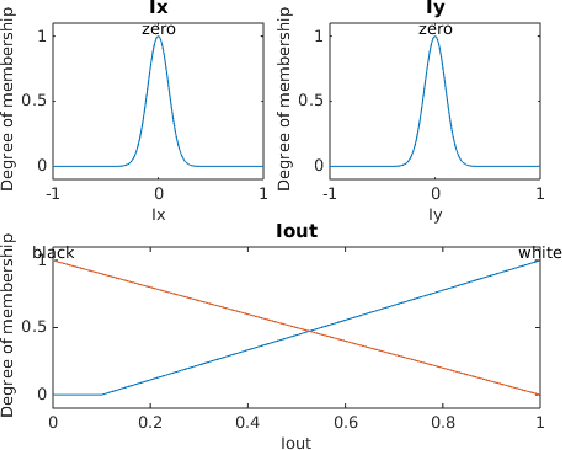
A fuzzy system was created in MATLAB to identify an item of clothing as a dress, shirt, or pair of pants from a series of input images. The system was initialized using a high-contrast vector-image of each item of clothing as the state closest to a direct solution. Nine other user-input images (three of each item) were also used to determine the characteristic function of each item and recognize each pattern. Mamdani inference systems were used for edge location and identification of characteristic regions of interest for each item of clothing. Based on these non-dimensional trends, a second Mamdani fuzzy inference system was used to characterize each image as containing a shirt, a dress, or a pair of pants. An outline of the fuzzy inference system and image processing techniques used for creating an image pattern recognition system are discussed.
SAFFIRE: System for Autonomous Feature Filtering and Intelligent ROI Estimation
Dec 04, 2020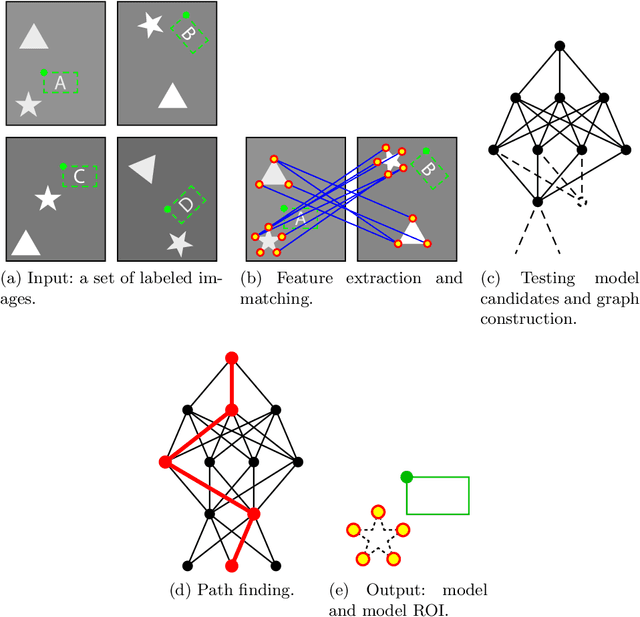

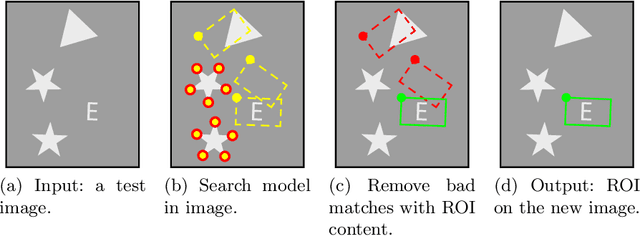
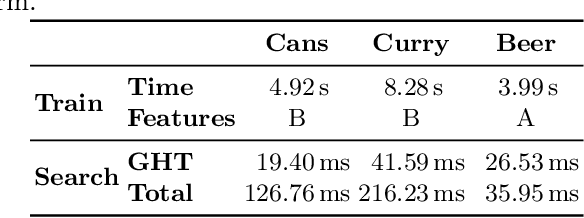
This work introduces a new framework, named SAFFIRE, to automatically extract a dominant recurrent image pattern from a set of image samples. Such a pattern shall be used to eliminate pose variations between samples, which is a common requirement in many computer vision and machine learning tasks. The framework is specialized here in the context of a machine vision system for automated product inspection. Here, it is customary to ask the user for the identification of an anchor pattern, to be used by the automated system to normalize data before further processing. Yet, this is a very sensitive operation which is intrinsically subjective and requires high expertise. Hereto, SAFFIRE provides a unique and disruptive framework for unsupervised identification of an optimal anchor pattern in a way which is fully transparent to the user. SAFFIRE is thoroughly validated on several realistic case studies for a machine vision inspection pipeline.
Histogram Specification by Assignment of Optimal Unique Values
Feb 04, 2021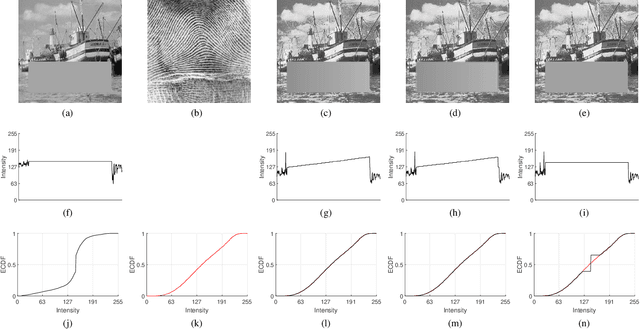
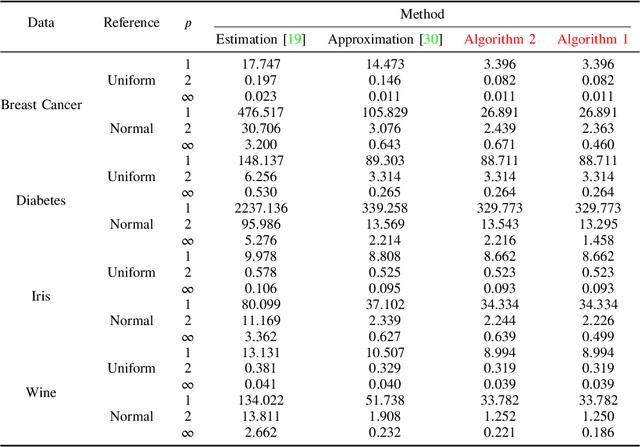
In this paper, we propose two novel algorithms for histogram specification and quantile transformation of data without local information. These are core techniques that can serve as building blocks for applications that require specifying the sample distribution of a given set of data. Histogram specification is best known for its image enhancement applications, whereas quantile transformation is typically employed in data preprocessing for data normalization. In signal processing, methods often require temporal or spatial information; in data preprocessing, methods work by interpolation or by approximation, drawing from results in computational statistics, and have a trade-off between speed and quality. It is nontrivial to accommodate for cases that do not have local information (e.g., tabular data) while also providing a fast, exact solution. For that, we take up a concept in image processing called group mapping law and propose an extension. The proposed extension allows us to formulate a convex functional where we look for the best approximation between the output unique values and the reference histogram. Then, we apply the ordered assignment solution, a result in optimal transport, to reconstruct the output from the optimal unique values. Two sets of results show the effectiveness of the proposed algorithms when compared to traditional and state-of-the-art methods. The proposed algorithms are fast, exact, and least $p$-norm optimal. Further, we define the algorithms as generic data processing methods. Thus, contributions from this paper can be easily incorporated in applications spanning many disciplines, especially in applied data science.