 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Artificial intelligence for detection and quantification of rust and leaf miner in coffee crop
Apr 01, 2021




Pest and disease control plays a key role in agriculture since the damage caused by these agents are responsible for a huge economic loss every year. Based on this assumption, we create an algorithm capable of detecting rust (Hemileia vastatrix) and leaf miner (Leucoptera coffeella) in coffee leaves (Coffea arabica) and quantify disease severity using a mobile application as a high-level interface for the model inferences. We used different convolutional neural network architectures to create the object detector, besides the OpenCV library, k-means, and three treatments: the RGB and value to quantification, and the AFSoft software, in addition to the analysis of variance, where we compare the three methods. The results show an average precision of 81,5% in the detection and that there was no significant statistical difference between treatments to quantify the severity of coffee leaves, proposing a computationally less costly method. The application, together with the trained model, can detect the pest and disease over different image conditions and infection stages and also estimate the disease infection stage.
AdaBins: Depth Estimation using Adaptive Bins
Nov 28, 2020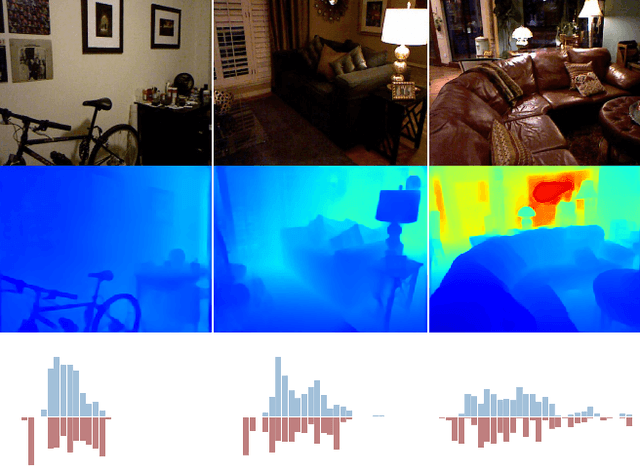

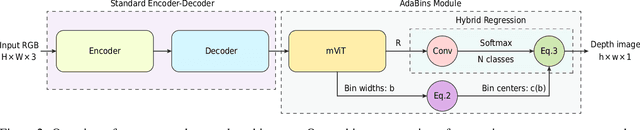
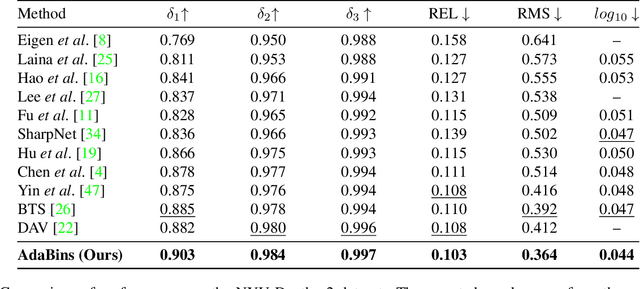
We address the problem of estimating a high quality dense depth map from a single RGB input image. We start out with a baseline encoder-decoder convolutional neural network architecture and pose the question of how the global processing of information can help improve overall depth estimation. To this end, we propose a transformer-based architecture block that divides the depth range into bins whose center value is estimated adaptively per image. The final depth values are estimated as linear combinations of the bin centers. We call our new building block AdaBins. Our results show a decisive improvement over the state-of-the-art on several popular depth datasets across all metrics. We also validate the effectiveness of the proposed block with an ablation study and provide the code and corresponding pre-trained weights of the new state-of-the-art model.
Surveilling Surveillance: Estimating the Prevalence of Surveillance Cameras with Street View Data
May 04, 2021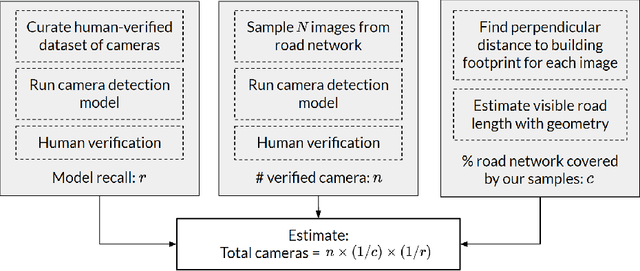
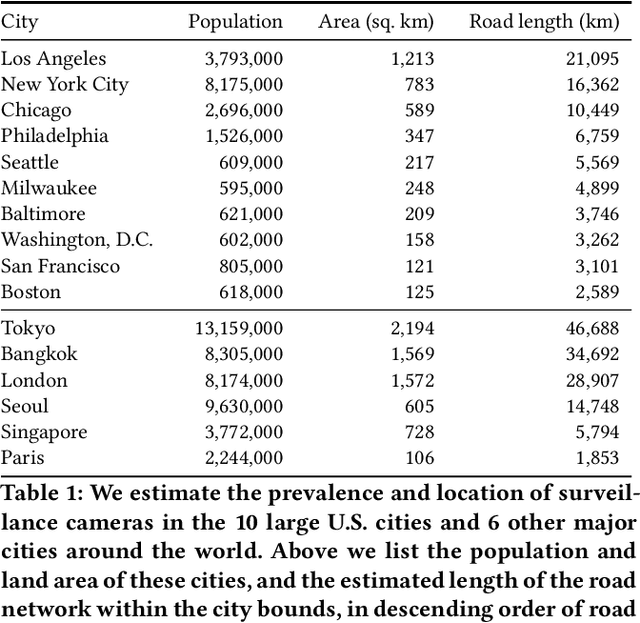


The use of video surveillance in public spaces -- both by government agencies and by private citizens -- has attracted considerable attention in recent years, particularly in light of rapid advances in face-recognition technology. But it has been difficult to systematically measure the prevalence and placement of cameras, hampering efforts to assess the implications of surveillance on privacy and public safety. Here we present a novel approach for estimating the spatial distribution of surveillance cameras: applying computer vision algorithms to large-scale street view image data. Specifically, we build a camera detection model and apply it to 1.6 million street view images sampled from 10 large U.S. cities and 6 other major cities around the world, with positive model detections verified by human experts. After adjusting for the estimated recall of our model, and accounting for the spatial coverage of our sampled images, we are able to estimate the density of surveillance cameras visible from the road. Across the 16 cities we consider, the estimated number of surveillance cameras per linear kilometer ranges from 0.1 (in Seattle) to 0.9 (in Seoul). In a detailed analysis of the 10 U.S. cities, we find that cameras are concentrated in commercial, industrial, and mixed zones, and in neighborhoods with higher shares of non-white residents -- a pattern that persists even after adjusting for land use. These results help inform ongoing discussions on the use of surveillance technology, including its potential disparate impacts on communities of color.
Deep-neural-network based sinogram synthesis for sparse-view CT image reconstruction
Mar 06, 2018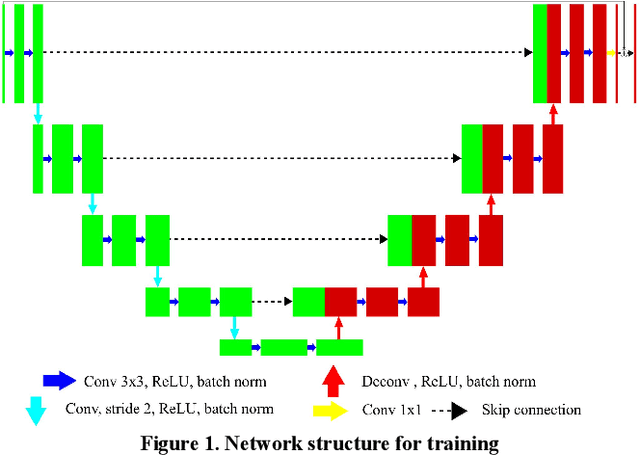
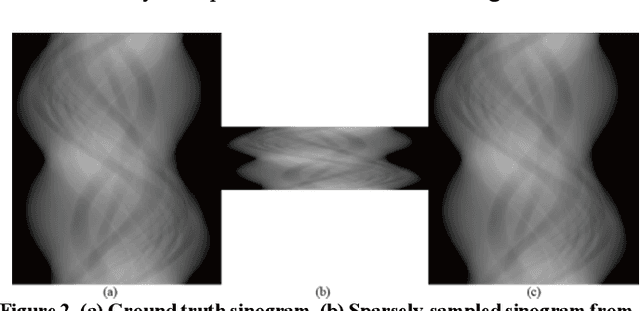

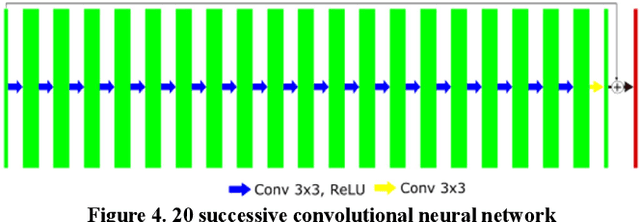
Recently, a number of approaches to low-dose computed tomography (CT) have been developed and deployed in commercialized CT scanners. Tube current reduction is perhaps the most actively explored technology with advanced image reconstruction algorithms. Sparse data sampling is another viable option to the low-dose CT, and sparse-view CT has been particularly of interest among the researchers in CT community. Since analytic image reconstruction algorithms would lead to severe image artifacts, various iterative algorithms have been developed for reconstructing images from sparsely view-sampled projection data. However, iterative algorithms take much longer computation time than the analytic algorithms, and images are usually prone to different types of image artifacts that heavily depend on the reconstruction parameters. Interpolation methods have also been utilized to fill the missing data in the sinogram of sparse-view CT thus providing synthetically full data for analytic image reconstruction. In this work, we introduce a deep-neural-network-enabled sinogram synthesis method for sparse-view CT, and show its outperformance to the existing interpolation methods and also to the iterative image reconstruction approach.
Learning low bending and low distortion manifold embeddings
Apr 27, 2021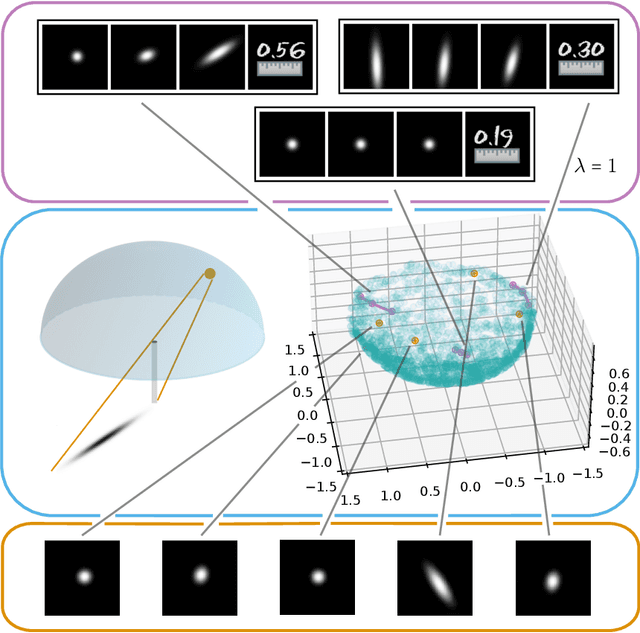
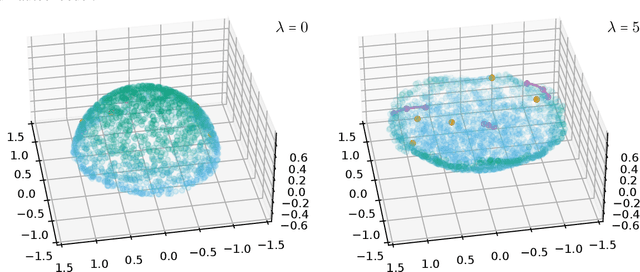
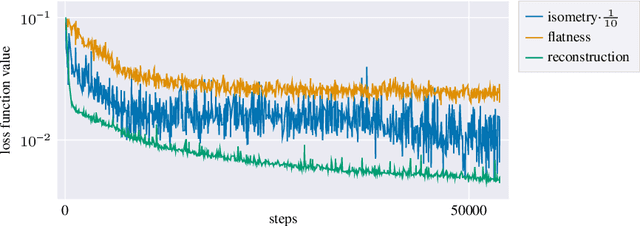
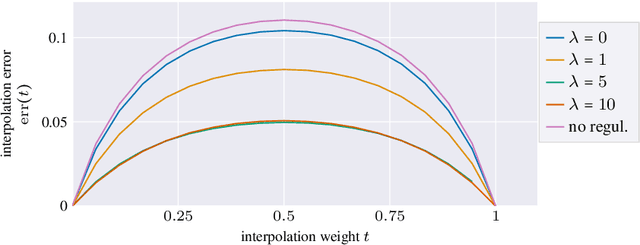
Autoencoders are a widespread tool in machine learning to transform high-dimensional data into a lowerdimensional representation which still exhibits the essential characteristics of the input. The encoder provides an embedding from the input data manifold into a latent space which may then be used for further processing. For instance, learning interpolation on the manifold may be simplified via the new manifold representation in latent space. The efficiency of such further processing heavily depends on the regularity and structure of the embedding. In this article, the embedding into latent space is regularized via a loss function that promotes an as isometric and as flat embedding as possible. The required training data comprises pairs of nearby points on the input manifold together with their local distance and their local Frechet average. This regularity loss functional even allows to train the encoder on its own. The loss functional is computed via a Monte Carlo integration which is shown to be consistent with a geometric loss functional defined directly on the embedding map. Numerical tests are performed using image data that encodes different data manifolds. The results show that smooth manifold embeddings in latent space are obtained. These embeddings are regular enough such that interpolation between not too distant points on the manifold is well approximated by linear interpolation in latent space.
AMPA-Net: Optimization-Inspired Attention Neural Network for Deep Compressed Sensing
Nov 09, 2020
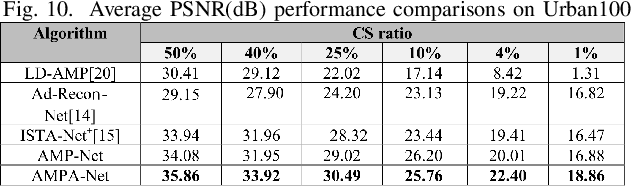
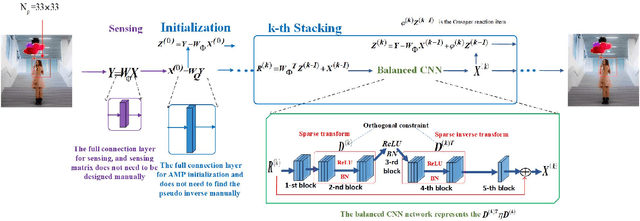
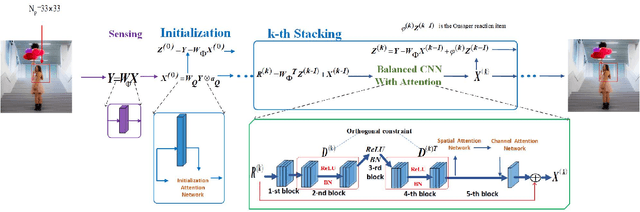
Compressed sensing (CS) is a challenging problem in image processing due to reconstructing an almost complete image from a limited measurement. To achieve fast and accurate CS reconstruction, we synthesize the advantages of two well-known methods (neural network and optimization algorithm) to propose a novel optimization inspired neural network which dubbed AMP-Net. AMP-Net realizes the fusion of the Approximate Message Passing (AMP) algorithm and neural network. All of its parameters are learned automatically. Furthermore, we propose an AMPA-Net which uses three attention networks to improve the representation ability of AMP-Net. Finally, We demonstrate the effectiveness of AMP-Net and AMPA-Net on four standard CS reconstruction benchmark data sets.
* 7 pages,7 figures
UPANets: Learning from the Universal Pixel Attention Networks
Mar 22, 2021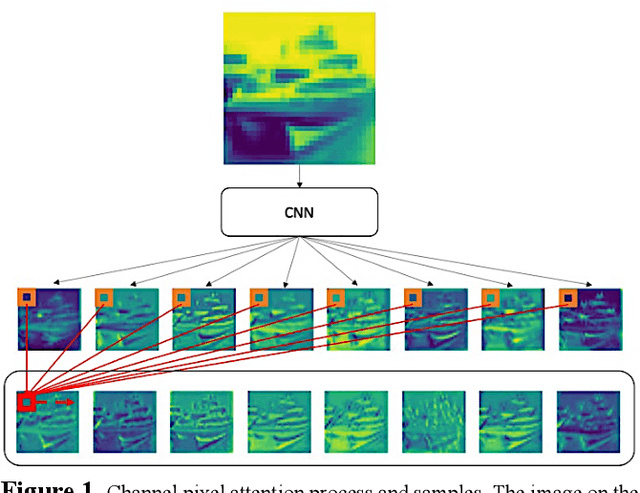
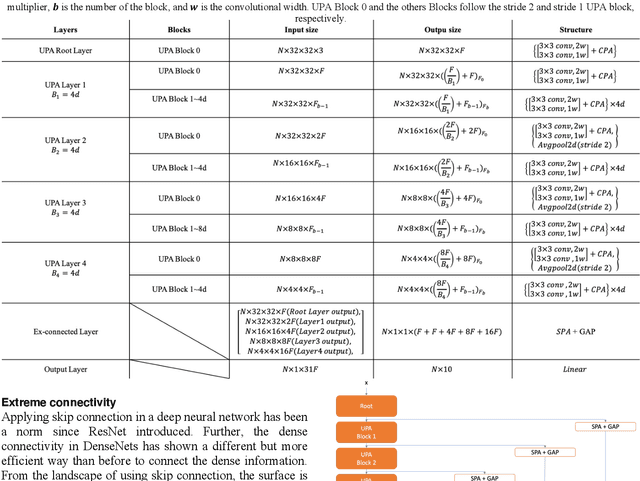
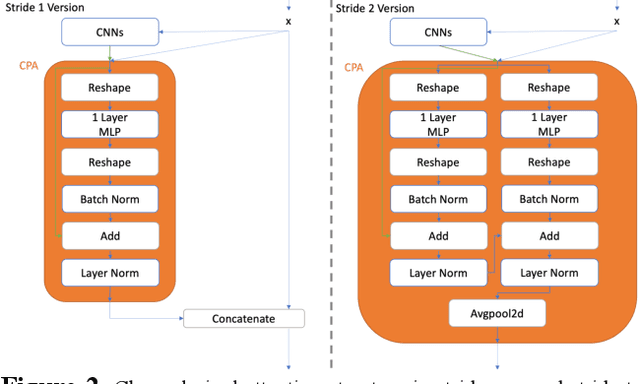
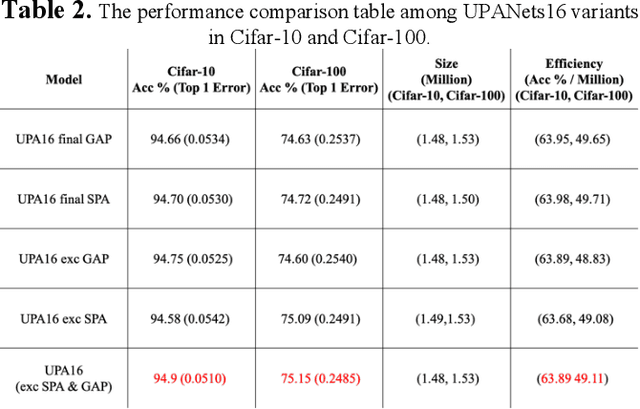
Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.
SAFFIRE: System for Autonomous Feature Filtering and Intelligent ROI Estimation
Dec 04, 2020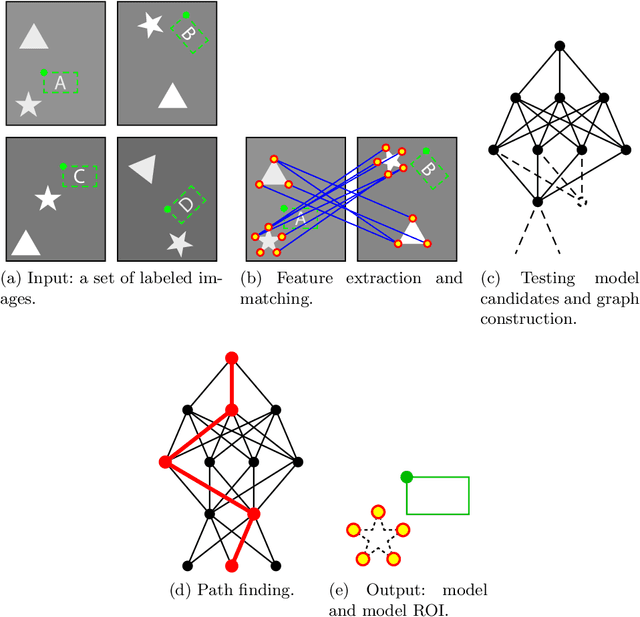

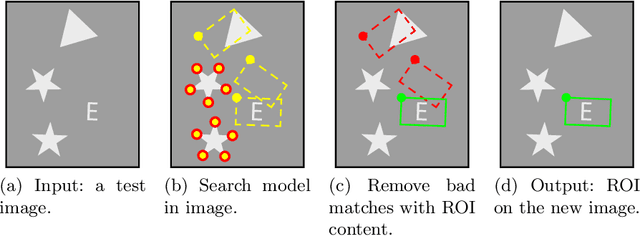
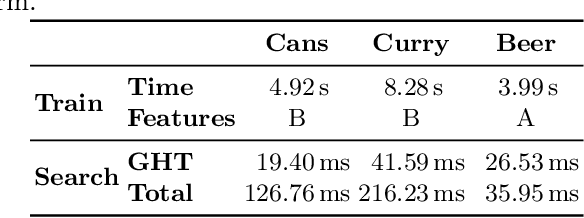
This work introduces a new framework, named SAFFIRE, to automatically extract a dominant recurrent image pattern from a set of image samples. Such a pattern shall be used to eliminate pose variations between samples, which is a common requirement in many computer vision and machine learning tasks. The framework is specialized here in the context of a machine vision system for automated product inspection. Here, it is customary to ask the user for the identification of an anchor pattern, to be used by the automated system to normalize data before further processing. Yet, this is a very sensitive operation which is intrinsically subjective and requires high expertise. Hereto, SAFFIRE provides a unique and disruptive framework for unsupervised identification of an optimal anchor pattern in a way which is fully transparent to the user. SAFFIRE is thoroughly validated on several realistic case studies for a machine vision inspection pipeline.
Single-view robot pose and joint angle estimation via render & compare
Apr 19, 2021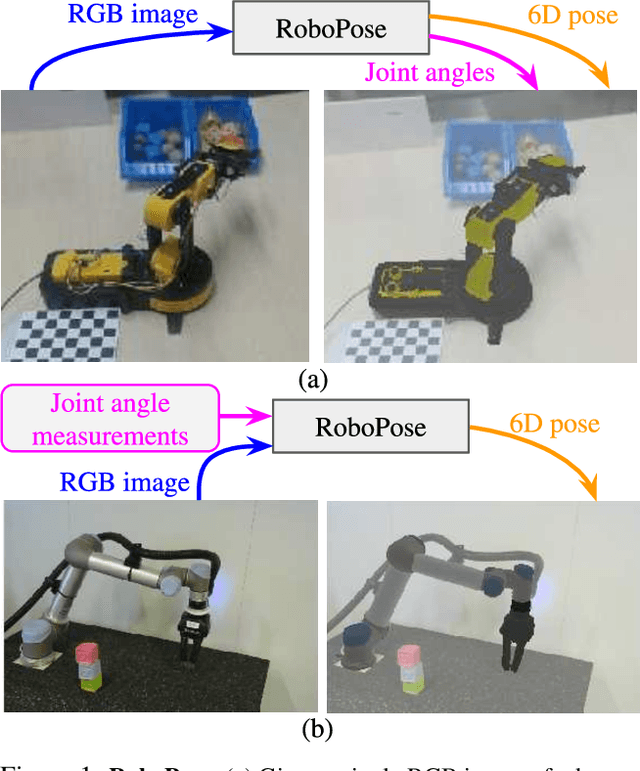
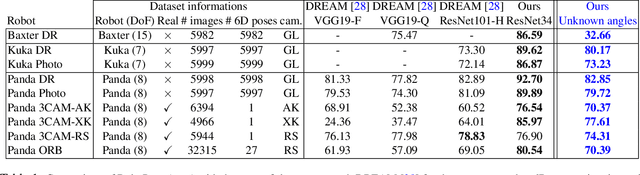
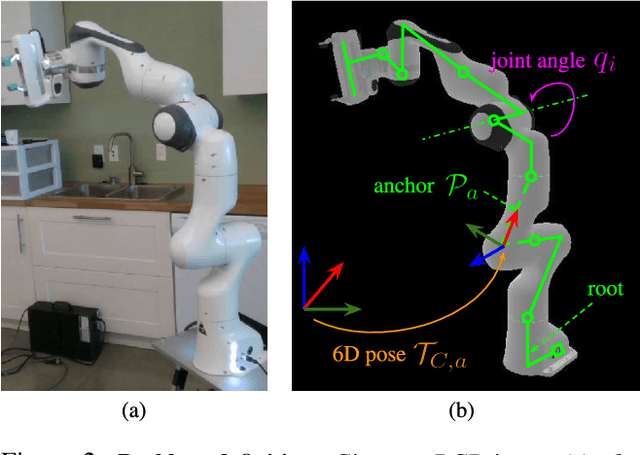
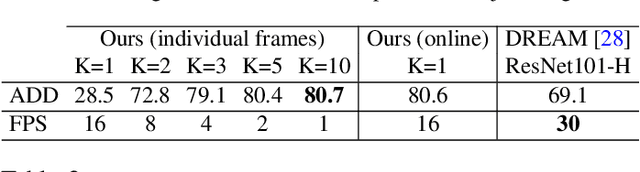
We introduce RoboPose, a method to estimate the joint angles and the 6D camera-to-robot pose of a known articulated robot from a single RGB image. This is an important problem to grant mobile and itinerant autonomous systems the ability to interact with other robots using only visual information in non-instrumented environments, especially in the context of collaborative robotics. It is also challenging because robots have many degrees of freedom and an infinite space of possible configurations that often result in self-occlusions and depth ambiguities when imaged by a single camera. The contributions of this work are three-fold. First, we introduce a new render & compare approach for estimating the 6D pose and joint angles of an articulated robot that can be trained from synthetic data, generalizes to new unseen robot configurations at test time, and can be applied to a variety of robots. Second, we experimentally demonstrate the importance of the robot parametrization for the iterative pose updates and design a parametrization strategy that is independent of the robot structure. Finally, we show experimental results on existing benchmark datasets for four different robots and demonstrate that our method significantly outperforms the state of the art. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/robopose/.
Fixes That Fail: Self-Defeating Improvements in Machine-Learning Systems
Mar 22, 2021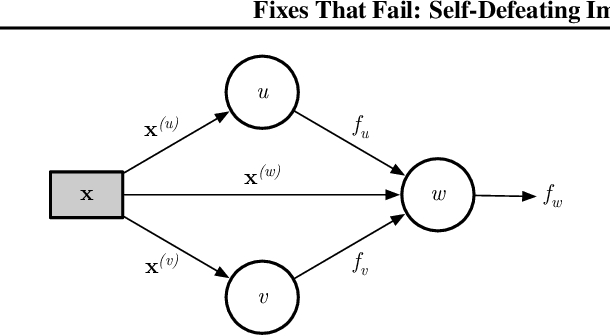
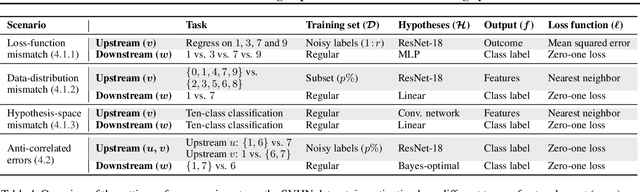
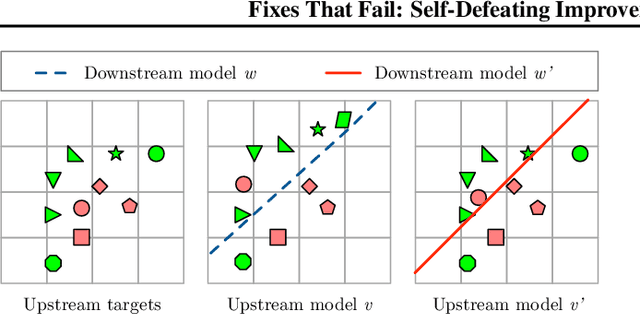
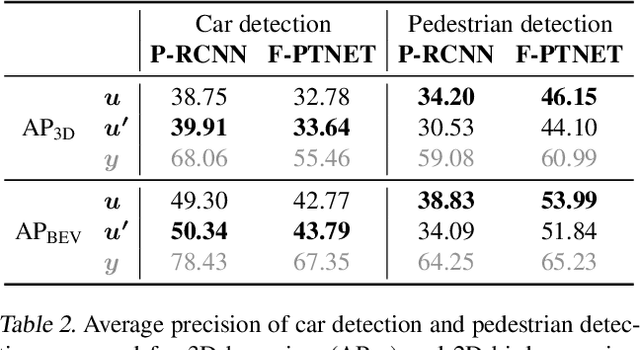
Machine-learning systems such as self-driving cars or virtual assistants are composed of a large number of machine-learning models that recognize image content, transcribe speech, analyze natural language, infer preferences, rank options, etc. These systems can be represented as directed acyclic graphs in which each vertex is a model, and models feed each other information over the edges. Oftentimes, the models are developed and trained independently, which raises an obvious concern: Can improving a machine-learning model make the overall system worse? We answer this question affirmatively by showing that improving a model can deteriorate the performance of downstream models, even after those downstream models are retrained. Such self-defeating improvements are the result of entanglement between the models. We identify different types of entanglement and demonstrate via simple experiments how they can produce self-defeating improvements. We also show that self-defeating improvements emerge in a realistic stereo-based object detection system.