 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditional Variational Capsule Network for Open Set Recognition
Apr 19, 2021
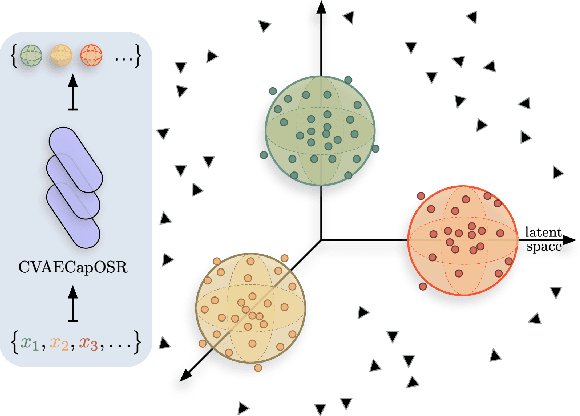
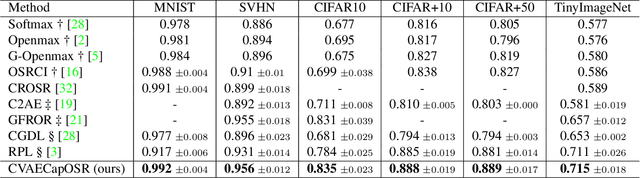
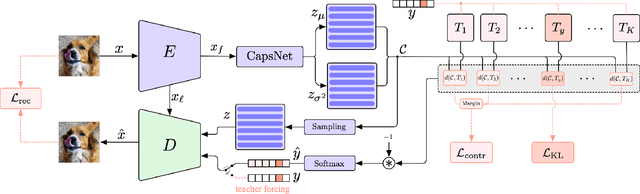

In open set recognition, a classifier has to detect unknown classes that are not known at training time. In order to recognize new classes, the classifier has to project the input samples of known classes in very compact and separated regions of the features space in order to discriminate outlier samples of unknown classes. Recently proposed Capsule Networks have shown to outperform alternatives in many fields, particularly in image recognition, however they have not been fully applied yet to open-set recognition. In capsule networks, scalar neurons are replaced by capsule vectors or matrices, whose entries represent different properties of objects. In our proposal, during training, capsules features of the same known class are encouraged to match a pre-defined gaussian, one for each class. To this end, we use the variational autoencoder framework, with a set of gaussian prior as the approximation for the posterior distribution. In this way, we are able to control the compactness of the features of the same class around the center of the gaussians, thus controlling the ability of the classifier in detecting samples from unknown classes. We conducted several experiments and ablation of our model, obtaining state of the art results on different datasets in the open set recognition and unknown detection tasks.
Prototype Mixture Models for Few-shot Semantic Segmentation
Sep 01, 2020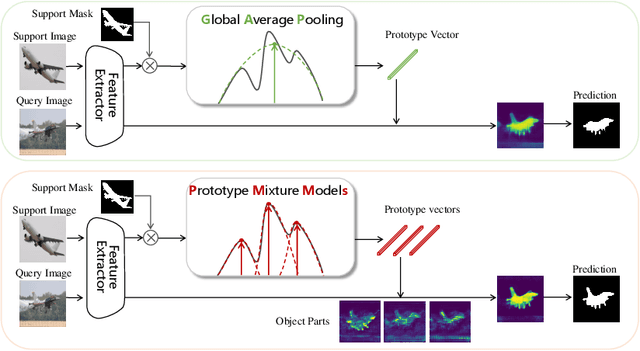

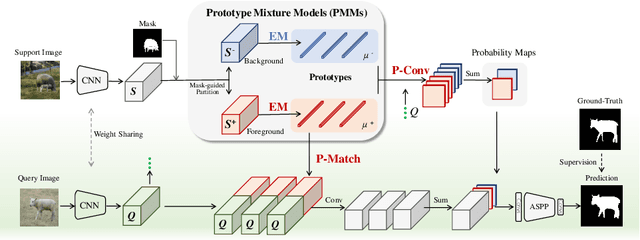
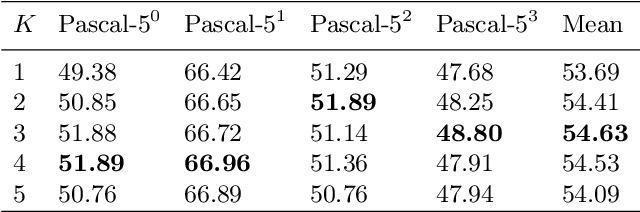
Few-shot segmentation is challenging because objects within the support and query images could significantly differ in appearance and pose. Using a single prototype acquired directly from the support image to segment the query image causes semantic ambiguity. In this paper, we propose prototype mixture models (PMMs), which correlate diverse image regions with multiple prototypes to enforce the prototype-based semantic representation. Estimated by an Expectation-Maximization algorithm, PMMs incorporate rich channel-wised and spatial semantics from limited support images. Utilized as representations as well as classifiers, PMMs fully leverage the semantics to activate objects in the query image while depressing background regions in a duplex manner. Extensive experiments on Pascal VOC and MS-COCO datasets show that PMMs significantly improve upon state-of-the-arts. Particularly, PMMs improve 5-shot segmentation performance on MS-COCO by up to 5.82\% with only a moderate cost for model size and inference speed.
Few-Shot Image Classification via Contrastive Self-Supervised Learning
Aug 23, 2020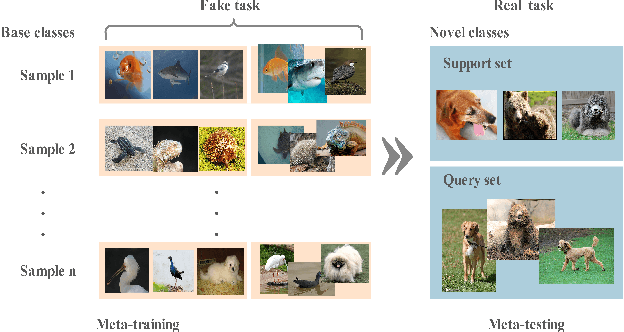
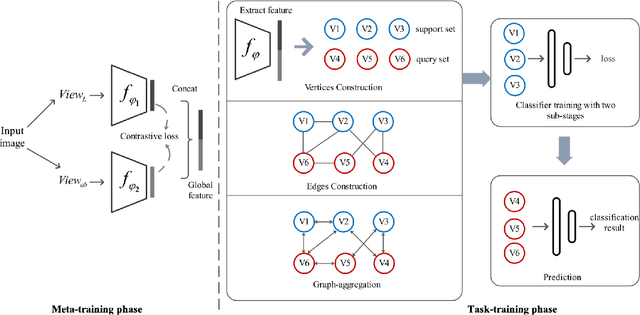
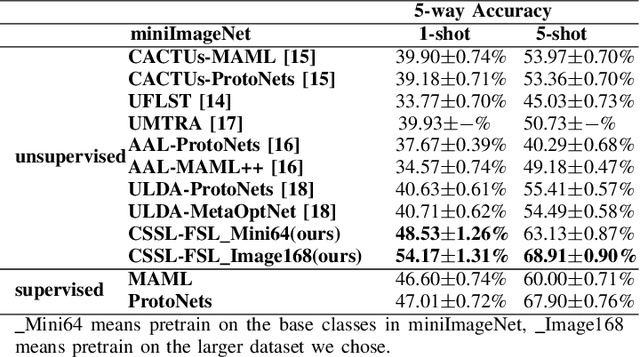
Most previous few-shot learning algorithms are based on meta-training with fake few-shot tasks as training samples, where large labeled base classes are required. The trained model is also limited by the type of tasks. In this paper we propose a new paradigm of unsupervised few-shot learning to repair the deficiencies. We solve the few-shot tasks in two phases: meta-training a transferable feature extractor via contrastive self-supervised learning and training a classifier using graph aggregation, self-distillation and manifold augmentation. Once meta-trained, the model can be used in any type of tasks with a task-dependent classifier training. Our method achieves state of-the-art performance in a variety of established few-shot tasks on the standard few-shot visual classification datasets, with an 8- 28% increase compared to the available unsupervised few-shot learning methods.
Fixes That Fail: Self-Defeating Improvements in Machine-Learning Systems
Mar 22, 2021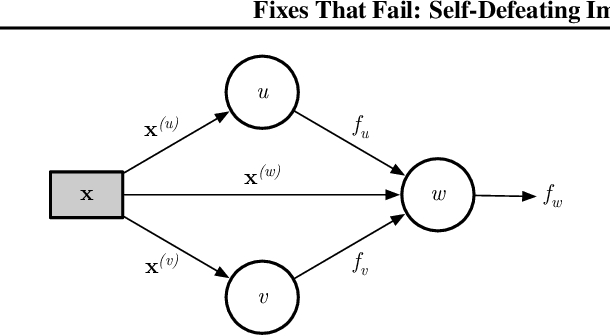
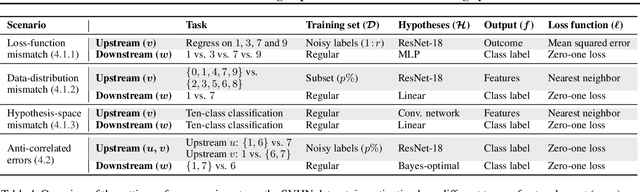
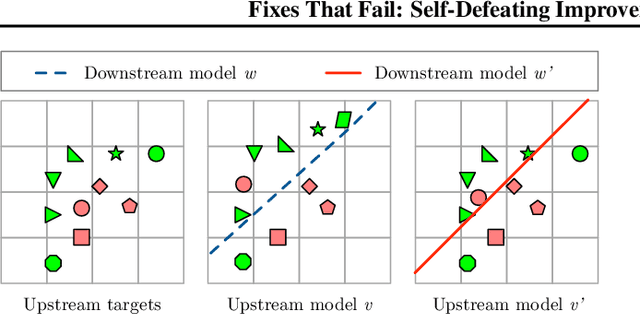
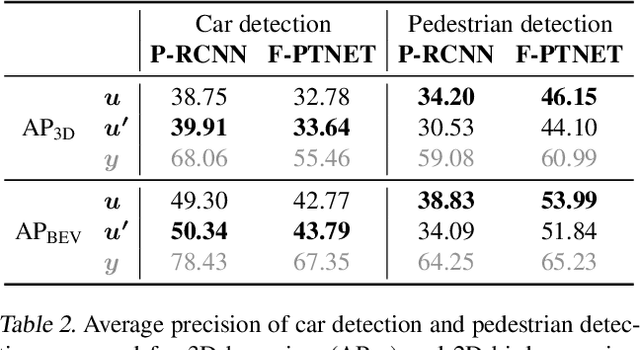
Machine-learning systems such as self-driving cars or virtual assistants are composed of a large number of machine-learning models that recognize image content, transcribe speech, analyze natural language, infer preferences, rank options, etc. These systems can be represented as directed acyclic graphs in which each vertex is a model, and models feed each other information over the edges. Oftentimes, the models are developed and trained independently, which raises an obvious concern: Can improving a machine-learning model make the overall system worse? We answer this question affirmatively by showing that improving a model can deteriorate the performance of downstream models, even after those downstream models are retrained. Such self-defeating improvements are the result of entanglement between the models. We identify different types of entanglement and demonstrate via simple experiments how they can produce self-defeating improvements. We also show that self-defeating improvements emerge in a realistic stereo-based object detection system.
Deep Two-View Structure-from-Motion Revisited
Apr 01, 2021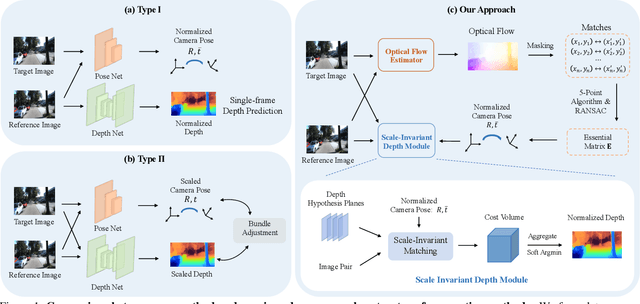
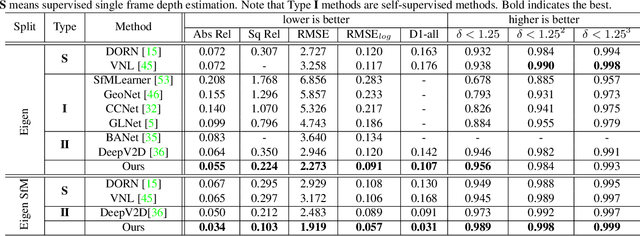


Two-view structure-from-motion (SfM) is the cornerstone of 3D reconstruction and visual SLAM. Existing deep learning-based approaches formulate the problem by either recovering absolute pose scales from two consecutive frames or predicting a depth map from a single image, both of which are ill-posed problems. In contrast, we propose to revisit the problem of deep two-view SfM by leveraging the well-posedness of the classic pipeline. Our method consists of 1) an optical flow estimation network that predicts dense correspondences between two frames; 2) a normalized pose estimation module that computes relative camera poses from the 2D optical flow correspondences, and 3) a scale-invariant depth estimation network that leverages epipolar geometry to reduce the search space, refine the dense correspondences, and estimate relative depth maps. Extensive experiments show that our method outperforms all state-of-the-art two-view SfM methods by a clear margin on KITTI depth, KITTI VO, MVS, Scenes11, and SUN3D datasets in both relative pose and depth estimation.
Denoising Score-Matching for Uncertainty Quantification in Inverse Problems
Nov 16, 2020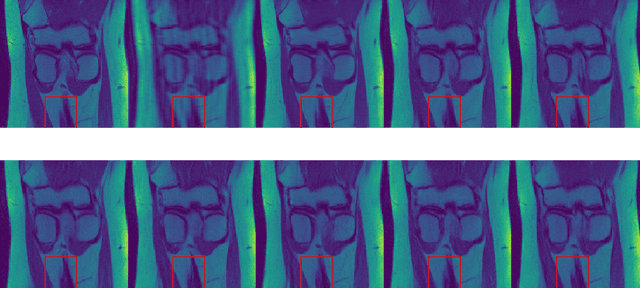

Deep neural networks have proven extremely efficient at solving a wide rangeof inverse problems, but most often the uncertainty on the solution they provideis hard to quantify. In this work, we propose a generic Bayesian framework forsolving inverse problems, in which we limit the use of deep neural networks tolearning a prior distribution on the signals to recover. We adopt recent denoisingscore matching techniques to learn this prior from data, and subsequently use it aspart of an annealed Hamiltonian Monte-Carlo scheme to sample the full posteriorof image inverse problems. We apply this framework to Magnetic ResonanceImage (MRI) reconstruction and illustrate how this approach not only yields highquality reconstructions but can also be used to assess the uncertainty on particularfeatures of a reconstructed image.
CNN with large memory layers
Jan 27, 2021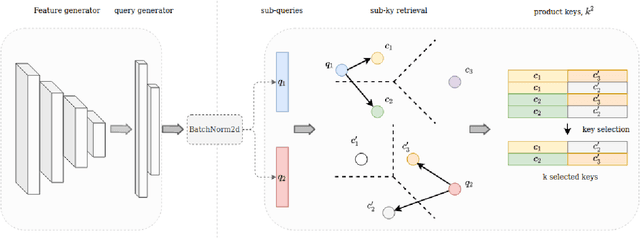
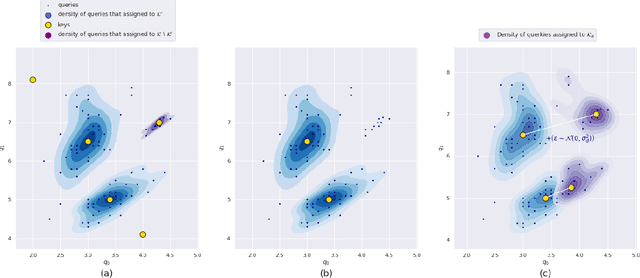
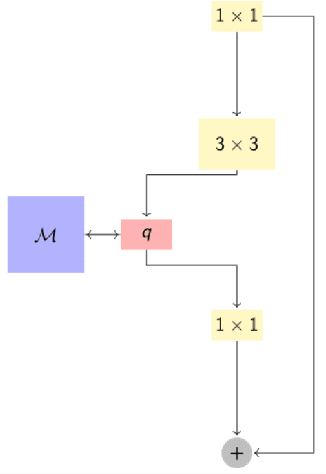
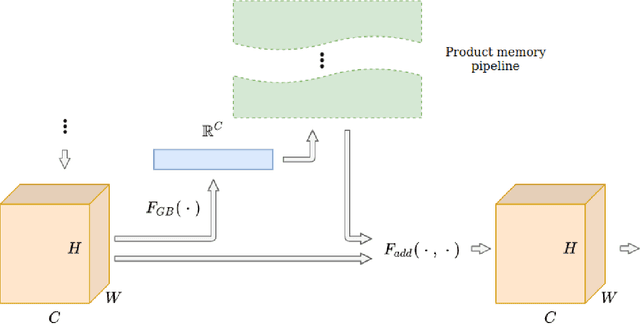
This work is centred around the recently proposed product key memory structure \cite{large_memory}, implemented for a number of computer vision applications. The memory structure can be regarded as a simple computation primitive suitable to be augmented to nearly all neural network architectures. The memory block allows implementing sparse access to memory with square root complexity scaling with respect to the memory capacity. The latter scaling is possible due to the incorporation of Cartesian product space decomposition of the key space for the nearest neighbour search. We have tested the memory layer on the classification, image reconstruction and relocalization problems and found that for some of those, the memory layers can provide significant speed/accuracy improvement with the high utilization of the key-value elements, while others require more careful fine-tuning and suffer from dying keys. To tackle the later problem we have introduced a simple technique of memory re-initialization which helps us to eliminate unused key-value pairs from the memory and engage them in training again. We have conducted various experiments and got improvements in speed and accuracy for classification and PoseNet relocalization models. We showed that the re-initialization has a huge impact on a toy example of randomly labeled data and observed some gains in performance on the image classification task. We have also demonstrated the generalization property perseverance of the large memory layers on the relocalization problem, while observing the spatial correlations between the images and the selected memory cells.
DeepViT: Towards Deeper Vision Transformer
Apr 19, 2021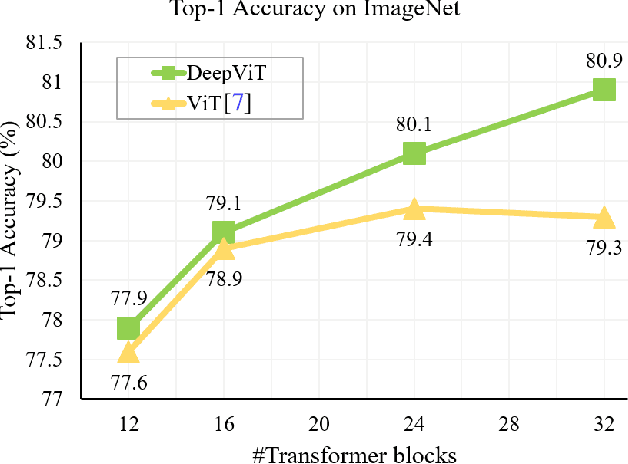
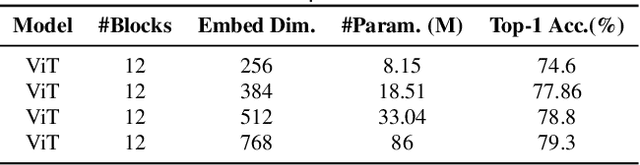
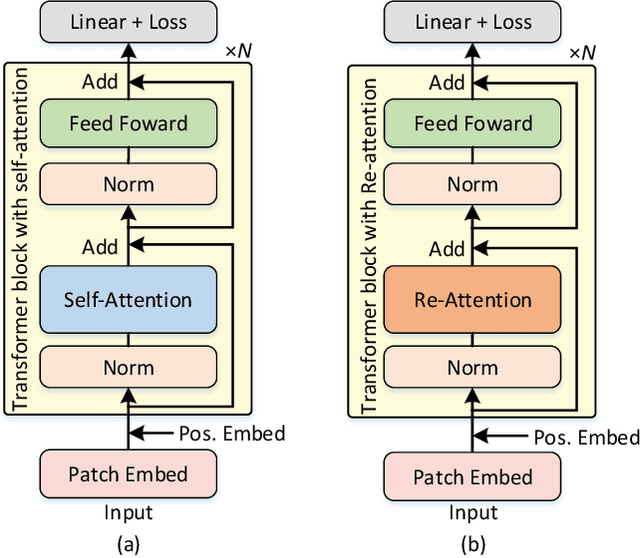

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.
Deep Tiered Image Segmentation forDetecting Internal Ice Layers in Radar Imagery
Oct 08, 2020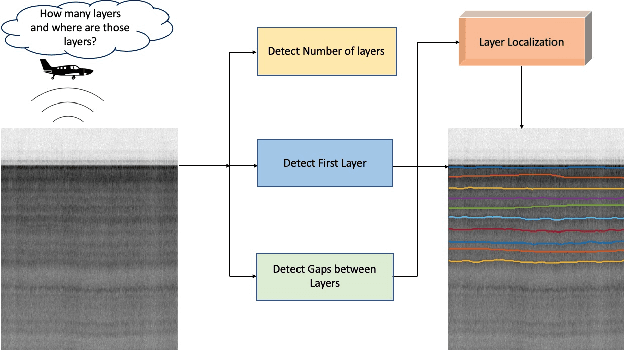

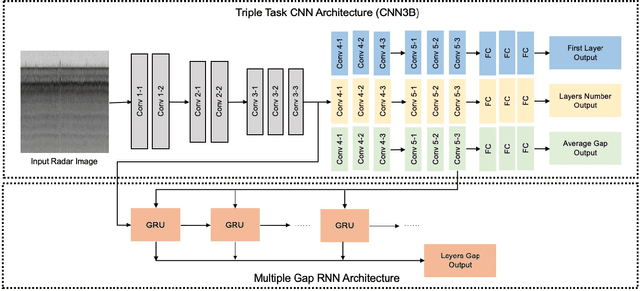
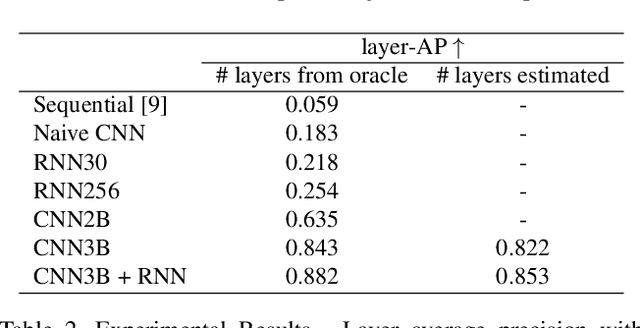
Understanding the structure of the ice at the Earth's poles is important for modeling how global warming will impact polar ice and, in turn, the Earth's climate. Ground-penetrating radar is able to collect observations of the internal structure of snow and ice, but the process of manually labeling these observations with layer boundaries is slow and laborious. Recent work has developed automatic techniques for finding ice-bed boundaries, but finding internal boundaries is much more challenging because the number of layers is unknown and the layers can disappear, reappear, merge, and split. In this paper, we propose a novel deep neural network-based model for solving a general class of tiered segmentation problems. We then apply it to detecting internal layers in polar ice, and evaluate on a large-scale dataset of polar ice radar data with human-labeled annotations as ground truth.
ExplAIn: Explanatory Artificial Intelligence for Diabetic Retinopathy Diagnosis
Aug 13, 2020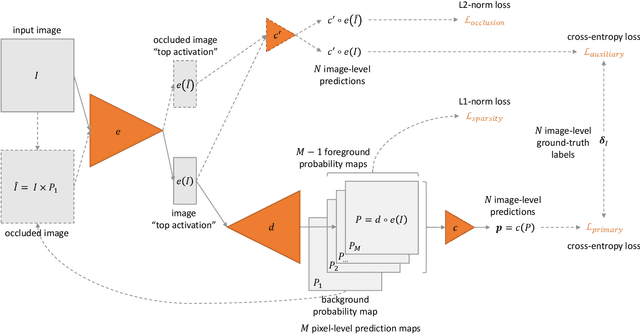
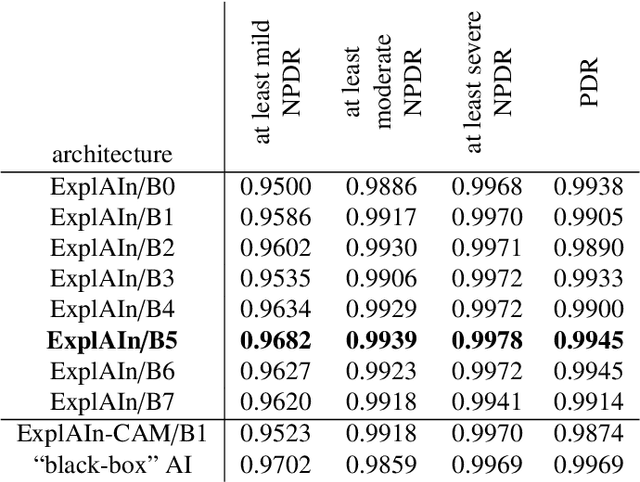
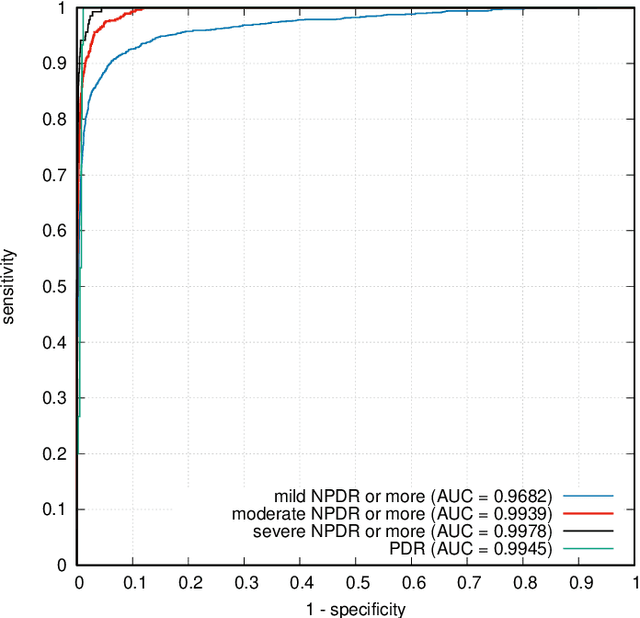
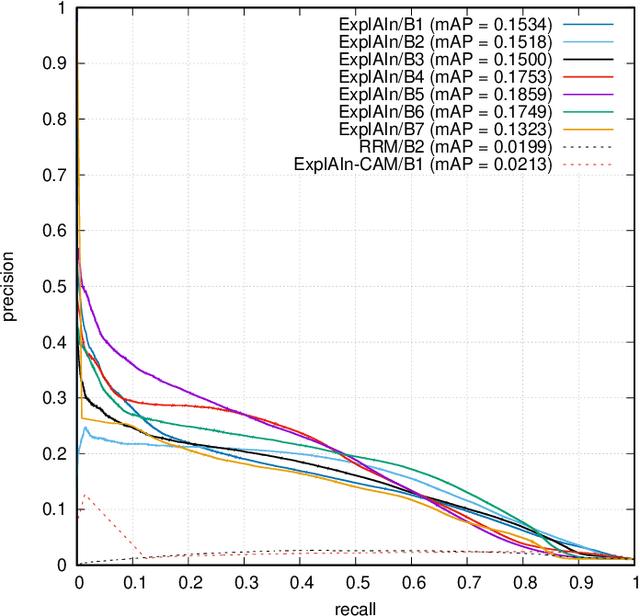
In recent years, Artificial Intelligence (AI) has proven its relevance for medical decision support. However, the "black-box" nature of successful AI algorithms still holds back their wide-spread deployment. In this paper, we describe an eXplanatory Artificial Intelligence (XAI) that reaches the same level of performance as black-box AI, for the task of Diabetic Retinopathy (DR) diagnosis using Color Fundus Photography (CFP). This algorithm, called ExplAIn, learns to segment and categorize lesions in images; the final diagnosis is directly derived from these multivariate lesion segmentations. The novelty of this explanatory framework is that it is trained from end to end, with image supervision only, just like black-box AI algorithms: the concepts of lesions and lesion categories emerge by themselves. For improved lesion localization, foreground/background separation is trained through self-supervision, in such a way that occluding foreground pixels transforms the input image into a healthy-looking image. The advantage of such an architecture is that automatic diagnoses can be explained simply by an image and/or a few sentences. ExplAIn is evaluated at the image level and at the pixel level on various CFP image datasets. We expect this new framework, which jointly offers high classification performance and explainability, to facilitate AI deployment.