 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Artificial intelligence for detection and quantification of rust and leaf miner in coffee crop
Apr 01, 2021




Pest and disease control plays a key role in agriculture since the damage caused by these agents are responsible for a huge economic loss every year. Based on this assumption, we create an algorithm capable of detecting rust (Hemileia vastatrix) and leaf miner (Leucoptera coffeella) in coffee leaves (Coffea arabica) and quantify disease severity using a mobile application as a high-level interface for the model inferences. We used different convolutional neural network architectures to create the object detector, besides the OpenCV library, k-means, and three treatments: the RGB and value to quantification, and the AFSoft software, in addition to the analysis of variance, where we compare the three methods. The results show an average precision of 81,5% in the detection and that there was no significant statistical difference between treatments to quantify the severity of coffee leaves, proposing a computationally less costly method. The application, together with the trained model, can detect the pest and disease over different image conditions and infection stages and also estimate the disease infection stage.
Classifying Breast Histopathology Images with a Ductal Instance-Oriented Pipeline
Dec 11, 2020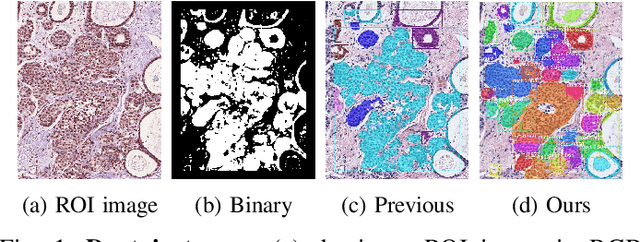
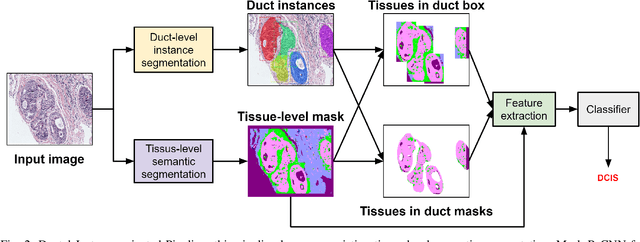
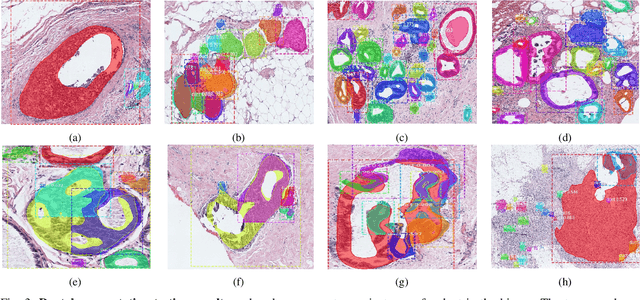
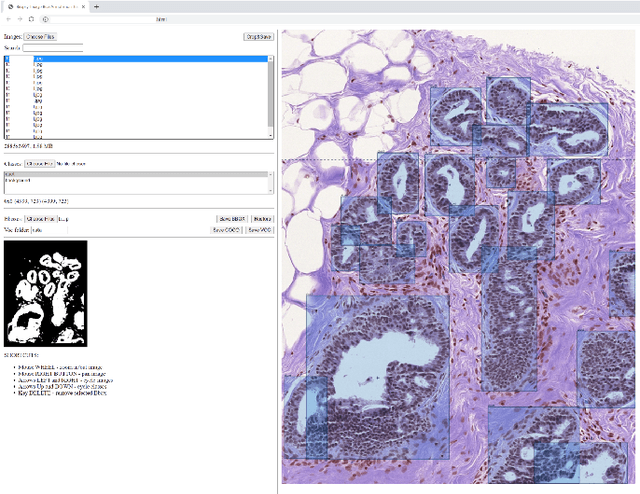
In this study, we propose the Ductal Instance-Oriented Pipeline (DIOP) that contains a duct-level instance segmentation model, a tissue-level semantic segmentation model, and three-levels of features for diagnostic classification. Based on recent advancements in instance segmentation and the Mask R-CNN model, our duct-level segmenter tries to identify each ductal individual inside a microscopic image; then, it extracts tissue-level information from the identified ductal instances. Leveraging three levels of information obtained from these ductal instances and also the histopathology image, the proposed DIOP outperforms previous approaches (both feature-based and CNN-based) in all diagnostic tasks; for the four-way classification task, the DIOP achieves comparable performance to general pathologists in this unique dataset. The proposed DIOP only takes a few seconds to run in the inference time, which could be used interactively on most modern computers. More clinical explorations are needed to study the robustness and generalizability of this system in the future.
Intrinsic Temporal Regularization for High-resolution Human Video Synthesis
Dec 11, 2020


Temporal consistency is crucial for extending image processing pipelines to the video domain, which is often enforced with flow-based warping error over adjacent frames. Yet for human video synthesis, such scheme is less reliable due to the misalignment between source and target video as well as the difficulty in accurate flow estimation. In this paper, we propose an effective intrinsic temporal regularization scheme to mitigate these issues, where an intrinsic confidence map is estimated via the frame generator to regulate motion estimation via temporal loss modulation. This creates a shortcut for back-propagating temporal loss gradients directly to the front-end motion estimator, thus improving training stability and temporal coherence in output videos. We apply our intrinsic temporal regulation to single-image generator, leading to a powerful "INTERnet" capable of generating $512\times512$ resolution human action videos with temporal-coherent, realistic visual details. Extensive experiments demonstrate the superiority of proposed INTERnet over several competitive baselines.
Single-view robot pose and joint angle estimation via render & compare
Apr 19, 2021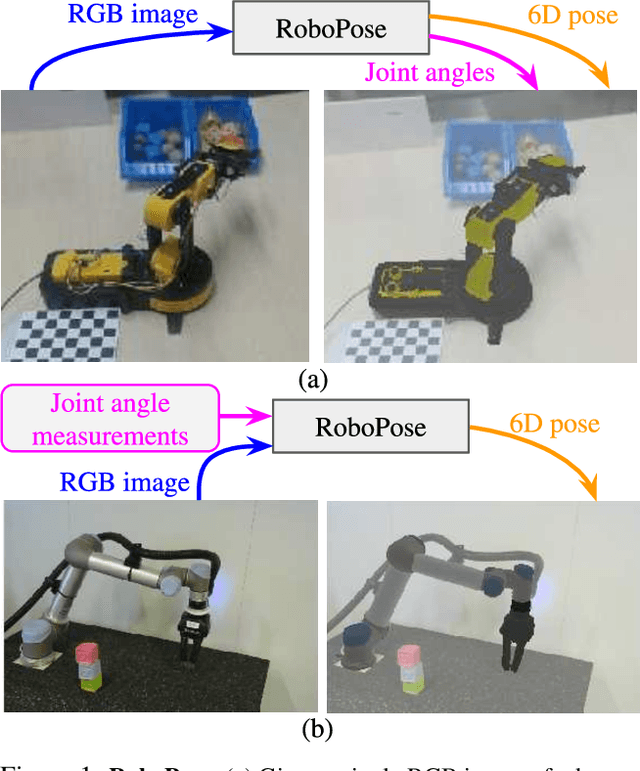
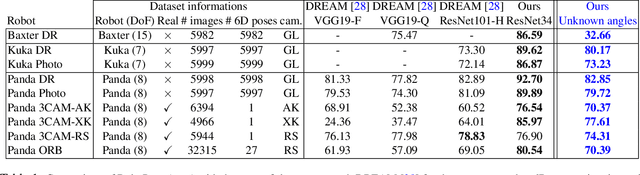
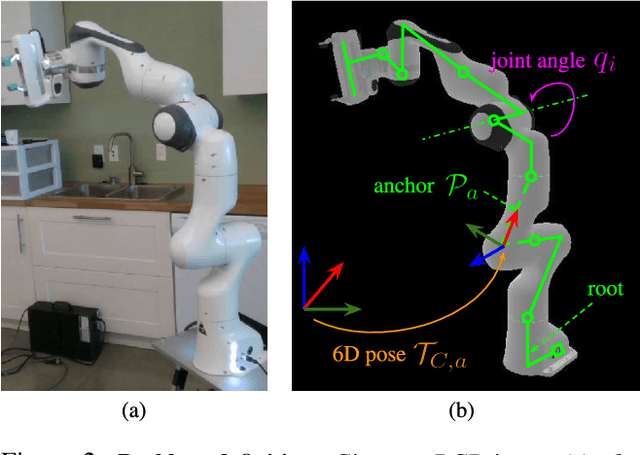
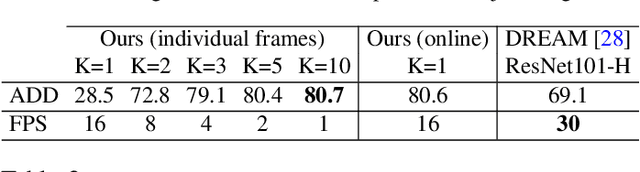
We introduce RoboPose, a method to estimate the joint angles and the 6D camera-to-robot pose of a known articulated robot from a single RGB image. This is an important problem to grant mobile and itinerant autonomous systems the ability to interact with other robots using only visual information in non-instrumented environments, especially in the context of collaborative robotics. It is also challenging because robots have many degrees of freedom and an infinite space of possible configurations that often result in self-occlusions and depth ambiguities when imaged by a single camera. The contributions of this work are three-fold. First, we introduce a new render & compare approach for estimating the 6D pose and joint angles of an articulated robot that can be trained from synthetic data, generalizes to new unseen robot configurations at test time, and can be applied to a variety of robots. Second, we experimentally demonstrate the importance of the robot parametrization for the iterative pose updates and design a parametrization strategy that is independent of the robot structure. Finally, we show experimental results on existing benchmark datasets for four different robots and demonstrate that our method significantly outperforms the state of the art. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/robopose/.
A Review of Artificial Intelligence Technologies for Early Prediction of Alzheimer's Disease
Dec 22, 2020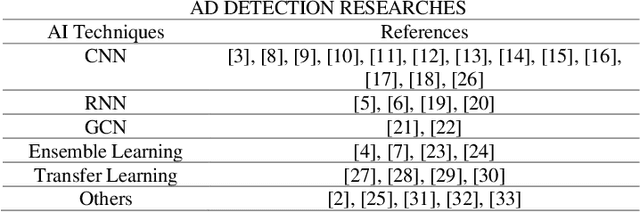
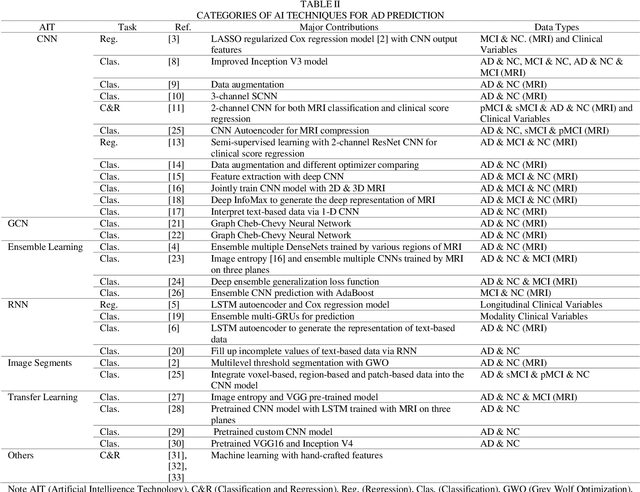

Alzheimer's Disease (AD) is a severe brain disorder, destroying memories and brain functions. AD causes chronically, progressively, and irreversibly cognitive declination and brain damages. The reliable and effective evaluation of early dementia has become essential research with medical imaging technologies and computer-aided algorithms. This trend has moved to modern Artificial Intelligence (AI) technologies motivated by deeplearning success in image classification and natural language processing. The purpose of this review is to provide an overview of the latest research involving deep-learning algorithms in evaluating the process of dementia, diagnosing the early stage of AD, and discussing an outlook for this research. This review introduces various applications of modern AI algorithms in AD diagnosis, including Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), Automatic Image Segmentation, Autoencoder, Graph CNN (GCN), Ensemble Learning, and Transfer Learning. The advantages and disadvantages of the proposed methods and their performance are discussed. The conclusion section summarizes the primary contributions and medical imaging preprocessing techniques applied in the reviewed research. Finally, we discuss the limitations and future outlooks.
From Design Draft to Real Attire: Unaligned Fashion Image Translation
Sep 16, 2020

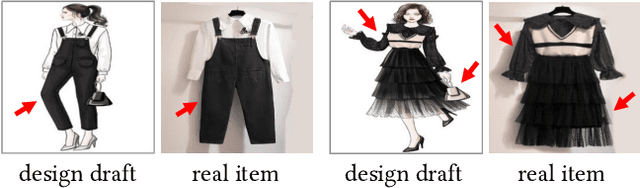
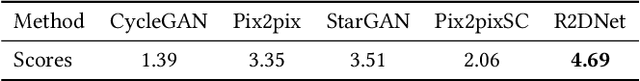
Fashion manipulation has attracted growing interest due to its great application value, which inspires many researches towards fashion images. However, little attention has been paid to fashion design draft. In this paper, we study a new unaligned translation problem between design drafts and real fashion items, whose main challenge lies in the huge misalignment between the two modalities. We first collect paired design drafts and real fashion item images without pixel-wise alignment. To solve the misalignment problem, our main idea is to train a sampling network to adaptively adjust the input to an intermediate state with structure alignment to the output. Moreover, built upon the sampling network, we present design draft to real fashion item translation network (D2RNet), where two separate translation streams that focus on texture and shape, respectively, are combined tactfully to get both benefits. D2RNet is able to generate realistic garments with both texture and shape consistency to their design drafts. We show that this idea can be effectively applied to the reverse translation problem and present R2DNet accordingly. Extensive experiments on unaligned fashion design translation demonstrate the superiority of our method over state-of-the-art methods. Our project website is available at: https://victoriahy.github.io/MM2020/ .
Prototype Mixture Models for Few-shot Semantic Segmentation
Sep 01, 2020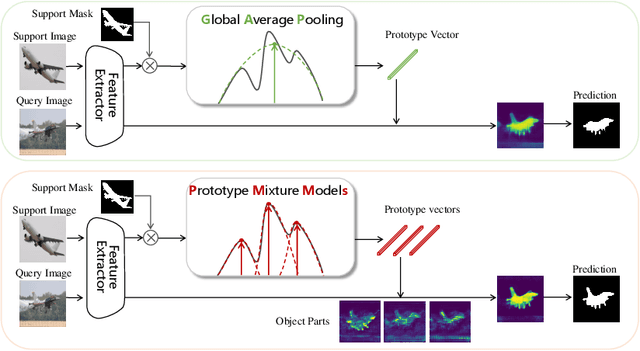

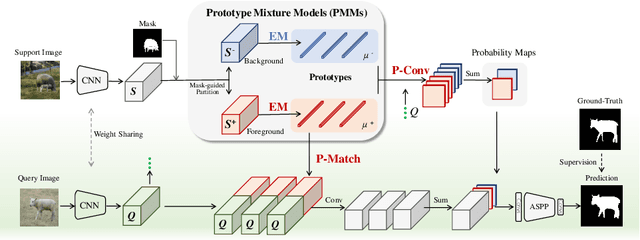
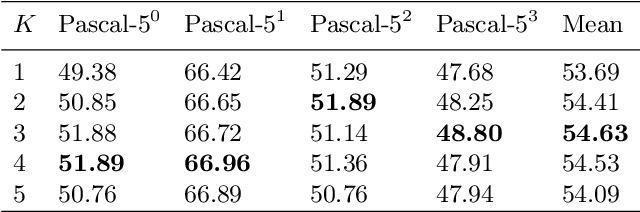
Few-shot segmentation is challenging because objects within the support and query images could significantly differ in appearance and pose. Using a single prototype acquired directly from the support image to segment the query image causes semantic ambiguity. In this paper, we propose prototype mixture models (PMMs), which correlate diverse image regions with multiple prototypes to enforce the prototype-based semantic representation. Estimated by an Expectation-Maximization algorithm, PMMs incorporate rich channel-wised and spatial semantics from limited support images. Utilized as representations as well as classifiers, PMMs fully leverage the semantics to activate objects in the query image while depressing background regions in a duplex manner. Extensive experiments on Pascal VOC and MS-COCO datasets show that PMMs significantly improve upon state-of-the-arts. Particularly, PMMs improve 5-shot segmentation performance on MS-COCO by up to 5.82\% with only a moderate cost for model size and inference speed.
Few-Shot Image Classification via Contrastive Self-Supervised Learning
Aug 23, 2020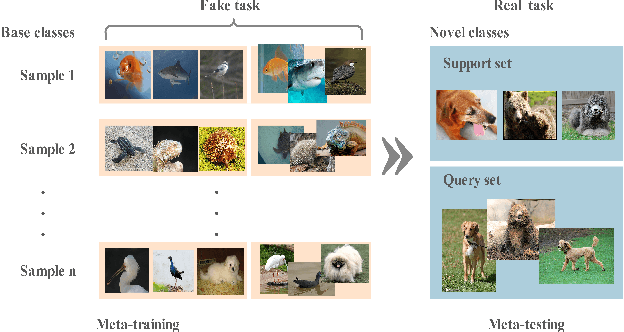
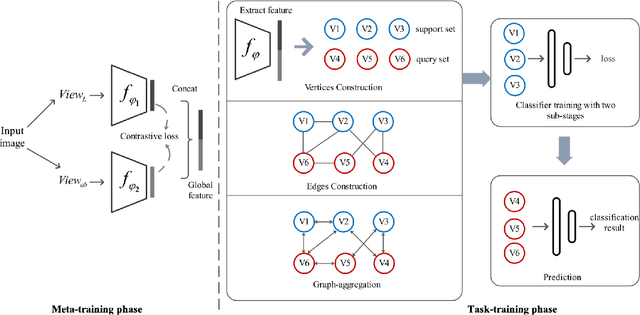
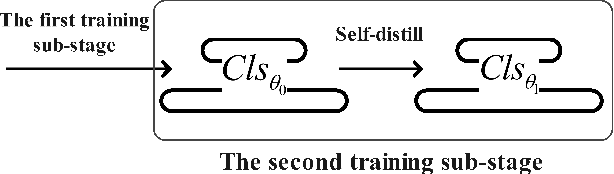
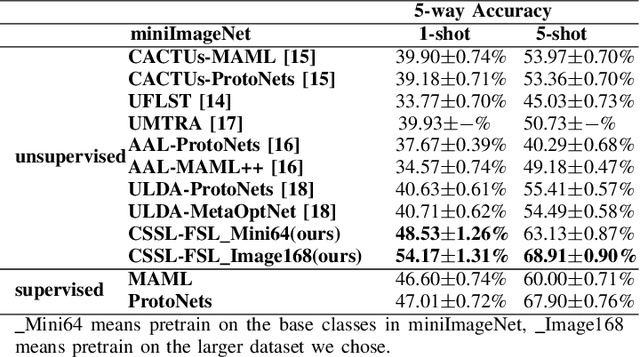
Most previous few-shot learning algorithms are based on meta-training with fake few-shot tasks as training samples, where large labeled base classes are required. The trained model is also limited by the type of tasks. In this paper we propose a new paradigm of unsupervised few-shot learning to repair the deficiencies. We solve the few-shot tasks in two phases: meta-training a transferable feature extractor via contrastive self-supervised learning and training a classifier using graph aggregation, self-distillation and manifold augmentation. Once meta-trained, the model can be used in any type of tasks with a task-dependent classifier training. Our method achieves state of-the-art performance in a variety of established few-shot tasks on the standard few-shot visual classification datasets, with an 8- 28% increase compared to the available unsupervised few-shot learning methods.
Overcoming Catastrophic Forgetting with Gaussian Mixture Replay
Apr 19, 2021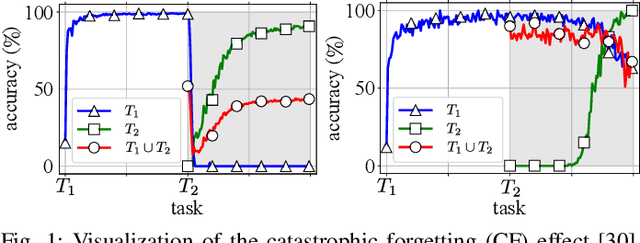

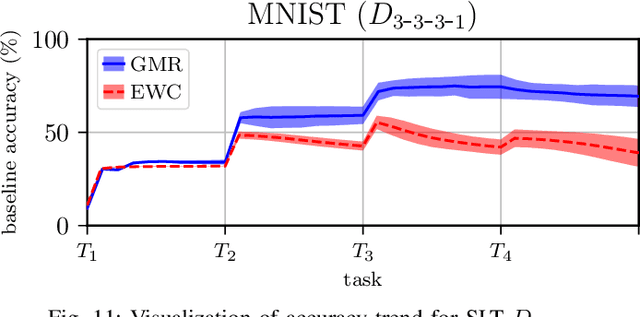
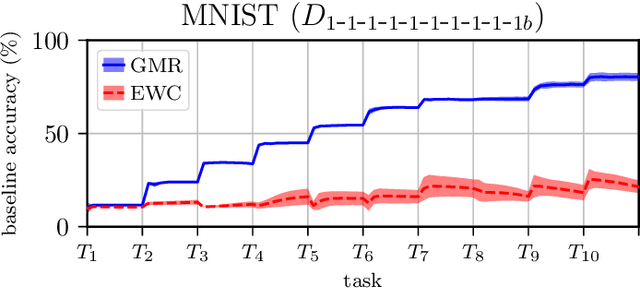
We present Gaussian Mixture Replay (GMR), a rehearsal-based approach for continual learning (CL) based on Gaussian Mixture Models (GMM). CL approaches are intended to tackle the problem of catastrophic forgetting (CF), which occurs for Deep Neural Networks (DNNs) when sequentially training them on successive sub-tasks. GMR mitigates CF by generating samples from previous tasks and merging them with current training data. GMMs serve several purposes here: sample generation, density estimation (e.g., for detecting outliers or recognizing task boundaries) and providing a high-level feature representation for classification. GMR has several conceptual advantages over existing replay-based CL approaches. First of all, GMR achieves sample generation, classification and density estimation in a single network structure with strongly reduced memory requirements. Secondly, it can be trained at constant time complexity w.r.t. the number of sub-tasks, making it particularly suitable for life-long learning. Furthermore, GMR minimizes a differentiable loss function and seems to avoid mode collapse. In addition, task boundaries can be detected by applying GMM density estimation. Lastly, GMR does not require access to sub-tasks lying in the future for hyper-parameter tuning, allowing CL under real-world constraints. We evaluate GMR on multiple image datasets, which are divided into class-disjoint sub-tasks.
Use of Transfer Learning and Wavelet Transform for Breast Cancer Detection
Mar 05, 2021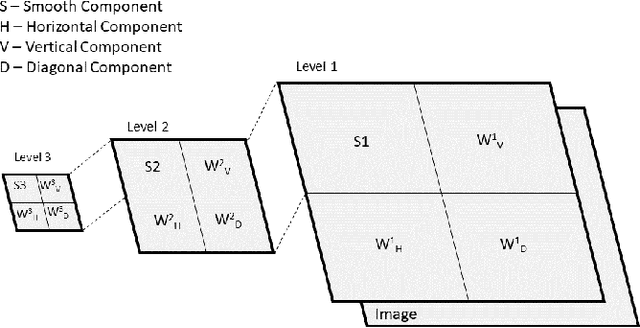
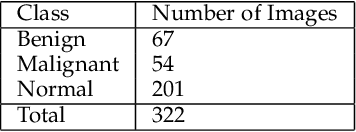
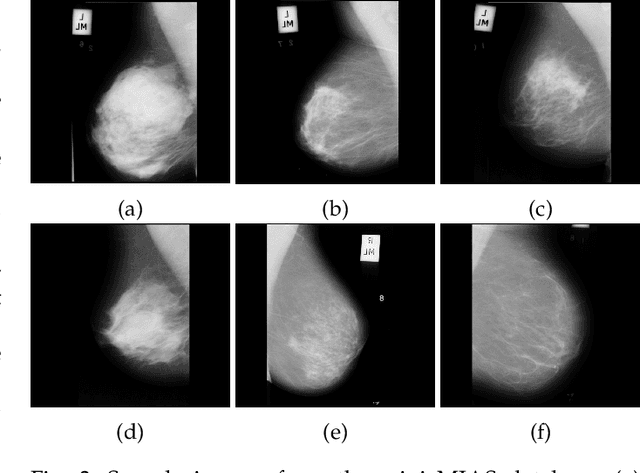
Breast cancer is one of the most common cause of deaths among women. Mammography is a widely used imaging modality that can be used for cancer detection in its early stages. Deep learning is widely used for the detection of cancerous masses in the images obtained via mammography. The need to improve accuracy remains constant due to the sensitive nature of the datasets so we introduce segmentation and wavelet transform to enhance the important features in the image scans. Our proposed system aids the radiologist in the screening phase of cancer detection by using a combination of segmentation and wavelet transforms as pre-processing augmentation that leads to transfer learning in neural networks. The proposed system with these pre-processing techniques significantly increases the accuracy of detection on Mini-MIAS.