 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Very Lightweight Photo Retouching Network with Conditional Sequential Modulation
Apr 13, 2021

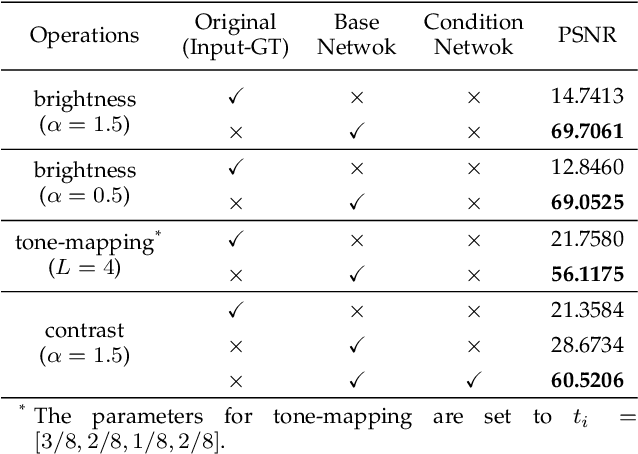
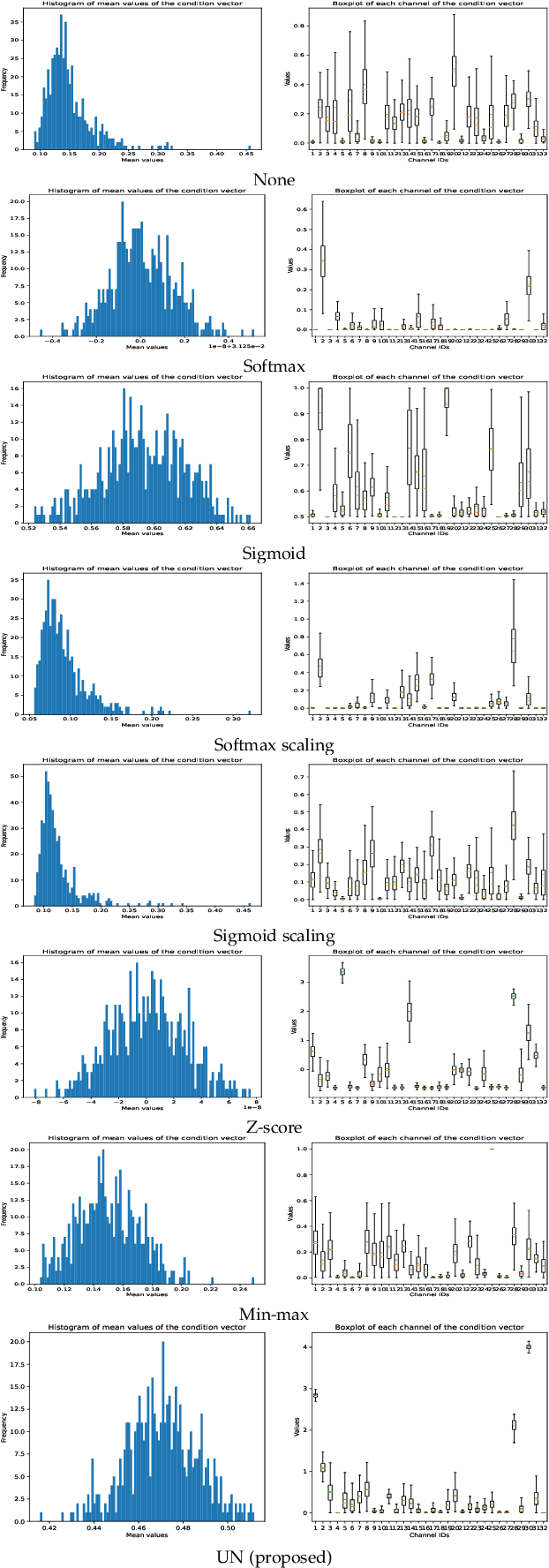
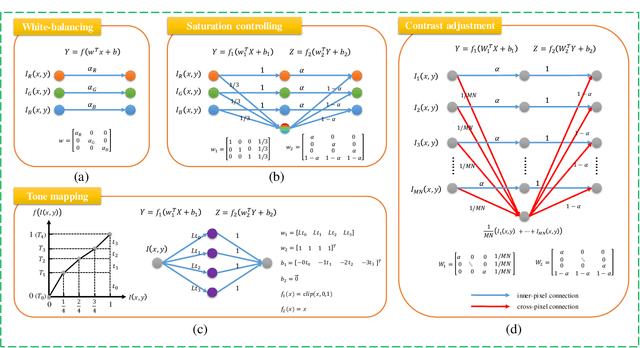
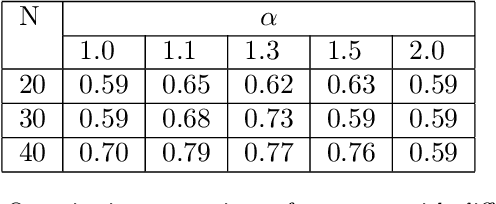
Photo retouching aims at improving the aesthetic visual quality of images that suffer from photographic defects such as poor contrast, over/under exposure, and inharmonious saturation. In practice, photo retouching can be accomplished by a series of image processing operations. As most commonly-used retouching operations are pixel-independent, i.e., the manipulation on one pixel is uncorrelated with its neighboring pixels, we can take advantage of this property and design a specialized algorithm for efficient global photo retouching. We analyze these global operations and find that they can be mathematically formulated by a Multi-Layer Perceptron (MLP). Based on this observation, we propose an extremely lightweight framework -- Conditional Sequential Retouching Network (CSRNet). Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37K trainable parameters, which are orders of magnitude smaller than existing learning-based methods. Experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. In addition to achieve global photo retouching, the proposed framework can be easily extended to learn local enhancement effects. The extended model, namly CSRNet-L, also achieves competitive results in various local enhancement tasks. Codes will be available.
Deep learning using Havrda-Charvat entropy for classification of pulmonary endomicroscopy
Apr 13, 2021
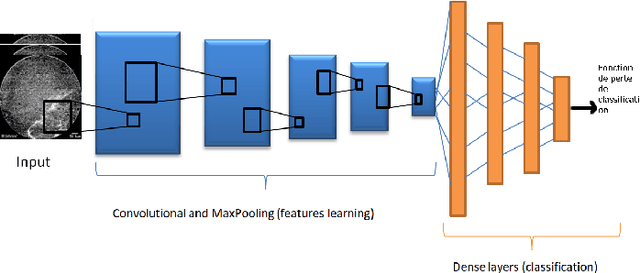
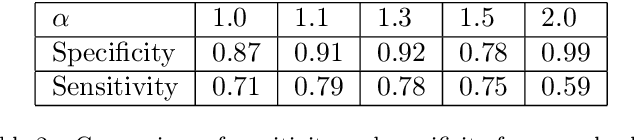
Pulmonary optical endomicroscopy (POE) is an imaging technology in real time. It allows to examine pulmonary alveoli at a microscopic level. Acquired in clinical settings, a POE image sequence can have as much as 25% of the sequence being uninformative frames (i.e. pure-noise and motion artefacts). For future data analysis, these uninformative frames must be first removed from the sequence. Therefore, the objective of our work is to develop an automatic detection method of uninformative images in endomicroscopy images. We propose to take the detection problem as a classification one. Considering advantages of deep learning methods, a classifier based on CNN (Convolutional Neural Network) is designed with a new loss function based on Havrda-Charvat entropy which is a parametrical generalization of the Shannon entropy. We propose to use this formula to get a better hold on all sorts of data since it provides a model more stable than the Shannon entropy. Our method is tested on one POE dataset including 2947 distinct images, is showing better results than using Shannon entropy and behaves better with regard to the problem of overfitting. Keywords: Deep Learning, CNN, Shannon entropy, Havrda-Charvat entropy, Pulmonary optical endomicroscopy.
* 8 pages, 7 figures
A Benchmark for Inpainting of Clothing Images with Irregular Holes
Jul 09, 2020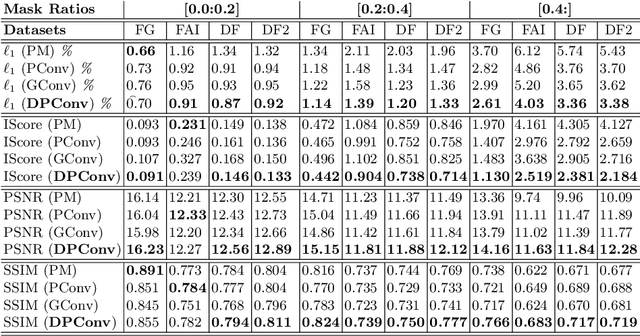

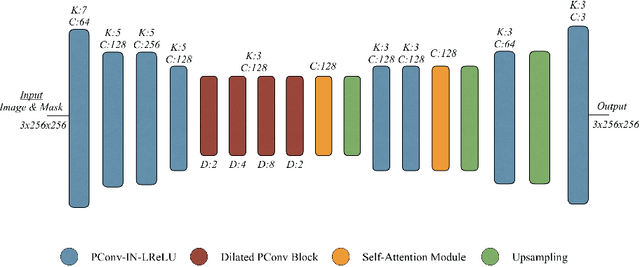

Fashion image understanding is an active research field with a large number of practical applications for the industry. Despite its practical impacts on intelligent fashion analysis systems, clothing image inpainting has not been extensively examined yet. For that matter, we present an extensive benchmark of clothing image inpainting on well-known fashion datasets. Furthermore, we introduce the use of a dilated version of partial convolutions, which efficiently derive the mask update step, and empirically show that the proposed method reduces the required number of layers to form fully-transparent masks. Experiments show that dilated partial convolutions (DPConv) improve the quantitative inpainting performance when compared to the other inpainting strategies, especially it performs better when the mask size is 20% or more of the image. \keywords{image inpainting, fashion image understanding, dilated convolutions, partial convolutions
Hierarchical Proxy-based Loss for Deep Metric Learning
Mar 25, 2021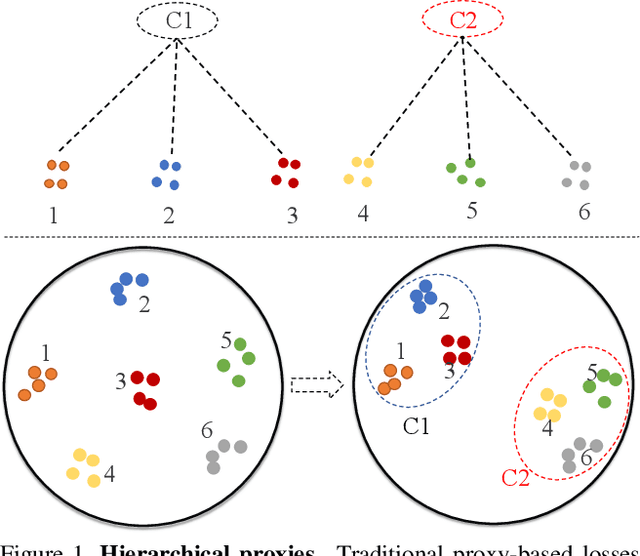
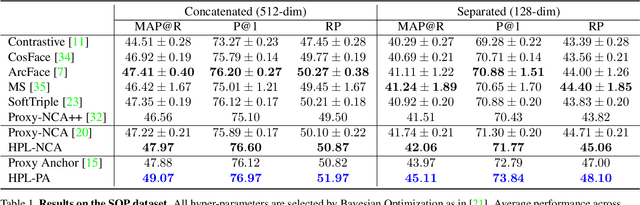
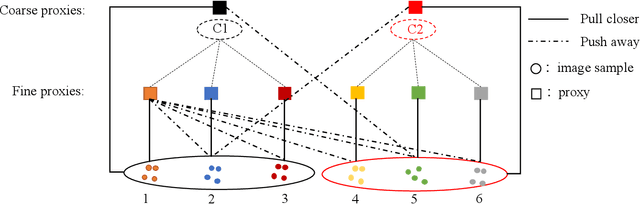
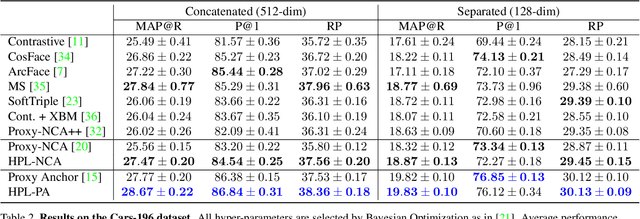
Proxy-based metric learning losses are superior to pair-based losses due to their fast convergence and low training complexity. However, existing proxy-based losses focus on learning class-discriminative features while overlooking the commonalities shared across classes which are potentially useful in describing and matching samples. Moreover, they ignore the implicit hierarchy of categories in real-world datasets, where similar subordinate classes can be grouped together. In this paper, we present a framework that leverages this implicit hierarchy by imposing a hierarchical structure on the proxies and can be used with any existing proxy-based loss. This allows our model to capture both class-discriminative features and class-shared characteristics without breaking the implicit data hierarchy. We evaluate our method on five established image retrieval datasets such as In-Shop and SOP. Results demonstrate that our hierarchical proxy-based loss framework improves the performance of existing proxy-based losses, especially on large datasets which exhibit strong hierarchical structure.
A deep learning based interactive sketching system for fashion images design
Oct 09, 2020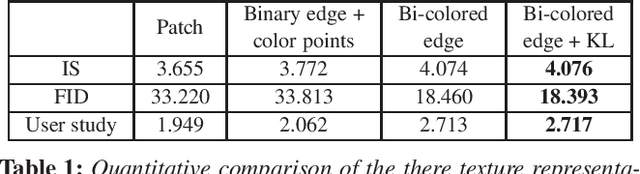
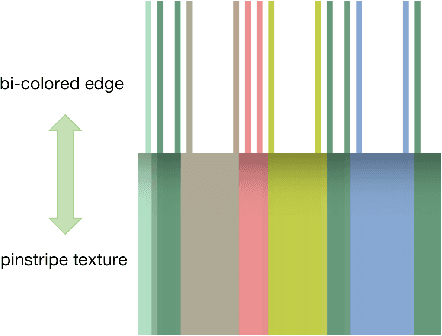
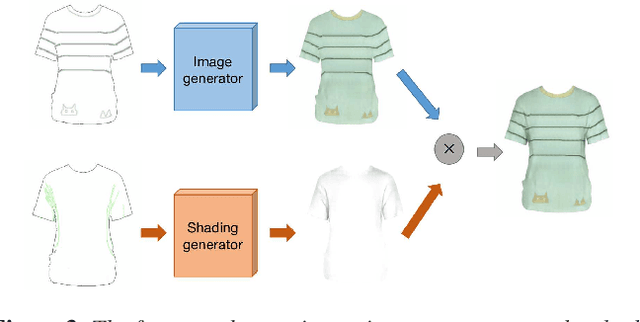

In this work, we propose an interactive system to design diverse high-quality garment images from fashion sketches and the texture information. The major challenge behind this system is to generate high-quality and detailed texture according to the user-provided texture information. Prior works mainly use the texture patch representation and try to map a small texture patch to a whole garment image, hence unable to generate high-quality details. In contrast, inspired by intrinsic image decomposition, we decompose this task into texture synthesis and shading enhancement. In particular, we propose a novel bi-colored edge texture representation to synthesize textured garment images and a shading enhancer to render shading based on the grayscale edges. The bi-colored edge representation provides simple but effective texture cues and color constraints, so that the details can be better reconstructed. Moreover, with the rendered shading, the synthesized garment image becomes more vivid.
ConvMath: A Convolutional Sequence Network for Mathematical Expression Recognition
Dec 23, 2020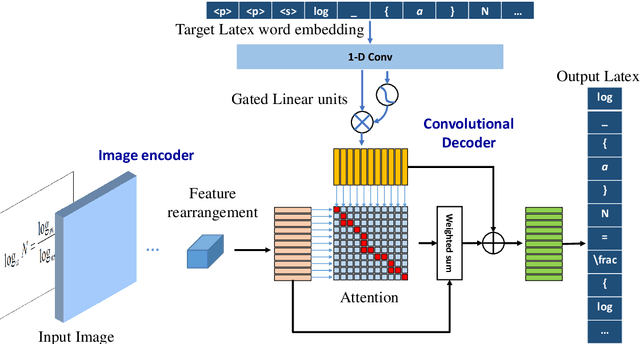
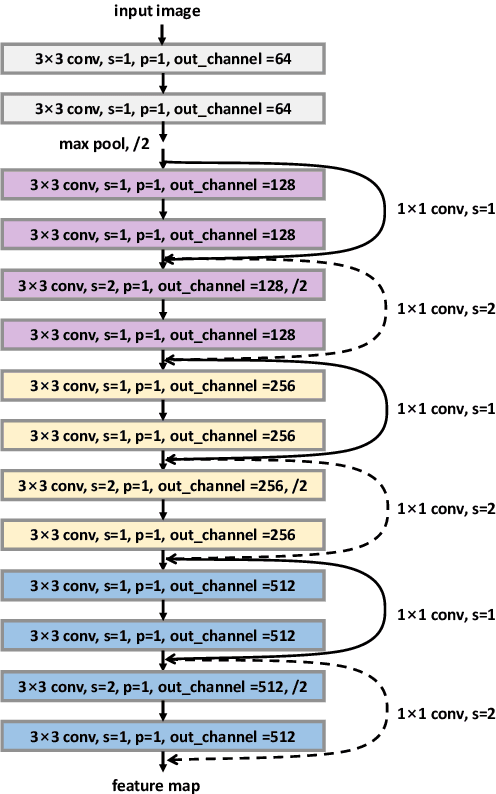

Despite the recent advances in optical character recognition (OCR), mathematical expressions still face a great challenge to recognize due to their two-dimensional graphical layout. In this paper, we propose a convolutional sequence modeling network, ConvMath, which converts the mathematical expression description in an image into a LaTeX sequence in an end-to-end way. The network combines an image encoder for feature extraction and a convolutional decoder for sequence generation. Compared with other Long Short Term Memory(LSTM) based encoder-decoder models, ConvMath is entirely based on convolution, thus it is easy to perform parallel computation. Besides, the network adopts multi-layer attention mechanism in the decoder, which allows the model to align output symbols with source feature vectors automatically, and alleviates the problem of lacking coverage while training the model. The performance of ConvMath is evaluated on an open dataset named IM2LATEX-100K, including 103556 samples. The experimental results demonstrate that the proposed network achieves state-of-the-art accuracy and much better efficiency than previous methods.
Dynamic Fusion based Federated Learning for COVID-19 Detection
Sep 26, 2020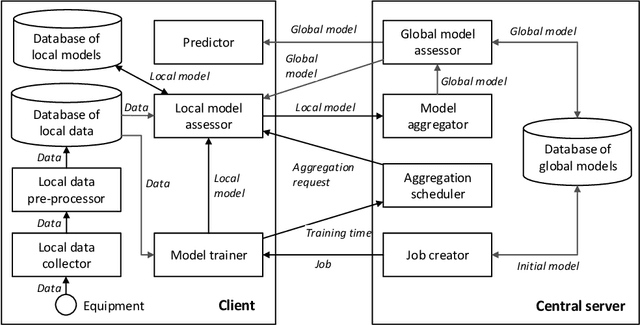
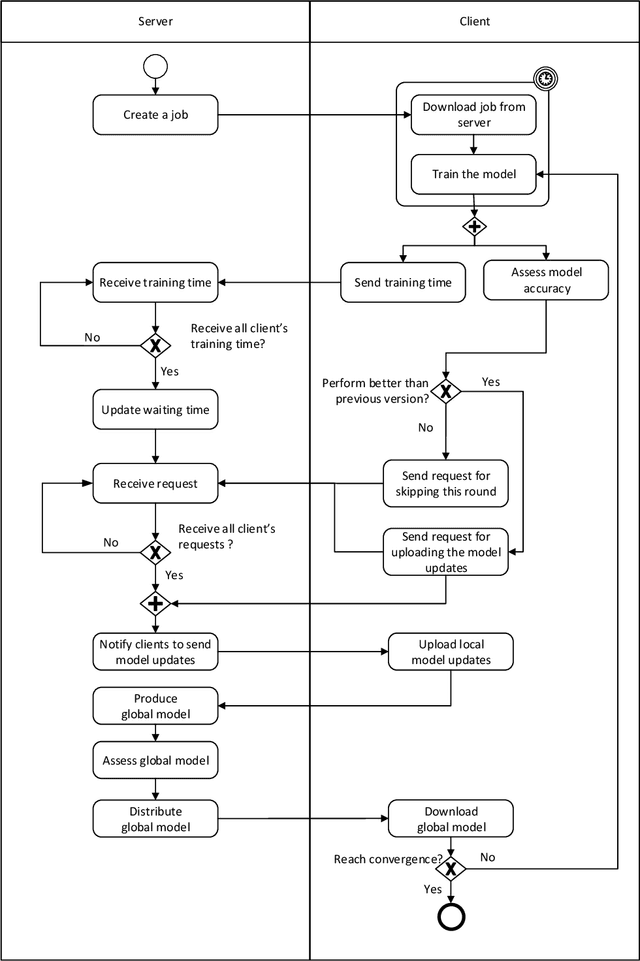
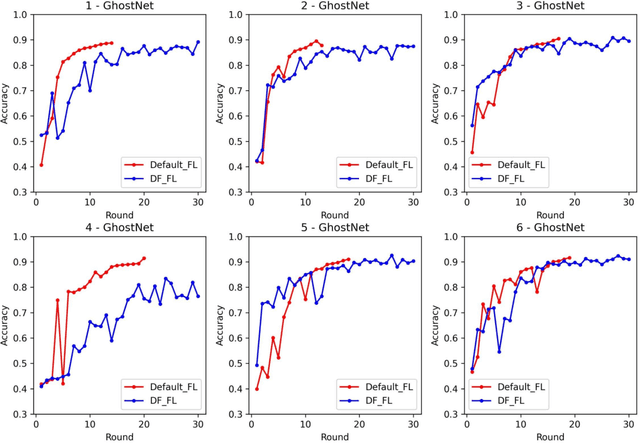
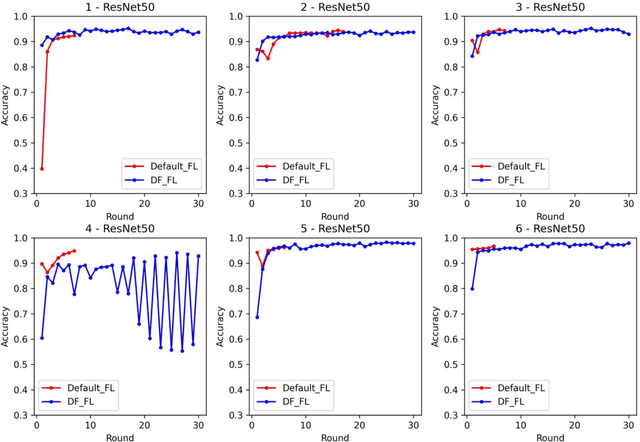
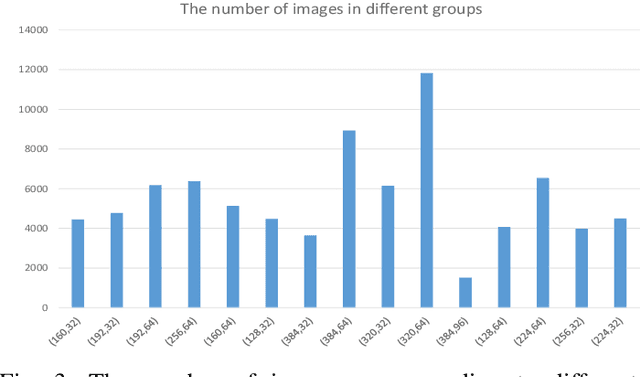
Medical diagnostic image analysis (e.g., CT scan or X-Ray) using machine learning is an efficient and accurate way to detect COVID-19 infections. However, sharing diagnostic images across medical institutions is usually not allowed due to the concern of patients' privacy. This causes the issue of insufficient datasets for training the image classification model. Federated learning is an emerging privacy-preserving machine learning paradigm that produces an unbiased global model based on the received updates of local models trained by clients without exchanging clients' local data. Nevertheless, the default setting of federated learning introduces huge communication cost of transferring model updates and can hardly ensure model performance when data heterogeneity of clients heavily exists. To improve communication efficiency and model performance, in this paper, we propose a novel dynamic fusion-based federated learning approach for medical diagnostic image analysis to detect COVID-19 infections. First, we design an architecture for dynamic fusion-based federated learning systems to analyse medical diagnostic images. Further, we present a dynamic fusion method to dynamically decide the participating clients according to their local model performance and schedule the model fusion-based on participating clients' training time. In addition, we summarise a category of medical diagnostic image datasets for COVID-19 detection, which can be used by the machine learning community for image analysis. The evaluation results show that the proposed approach is feasible and performs better than the default setting of federated learning in terms of model performance, communication efficiency and fault tolerance.
Learning When to Quit: Meta-Reasoning for Motion Planning
Mar 07, 2021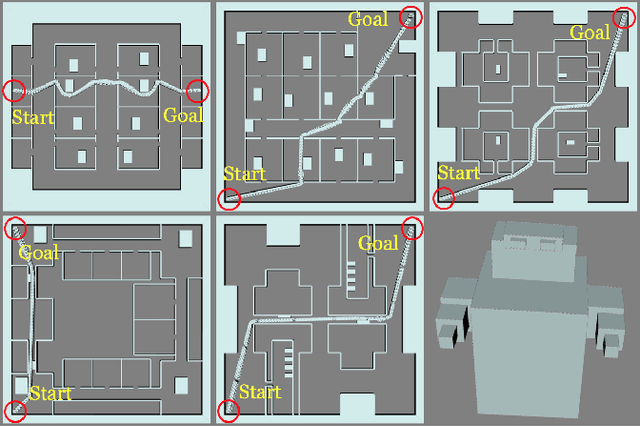
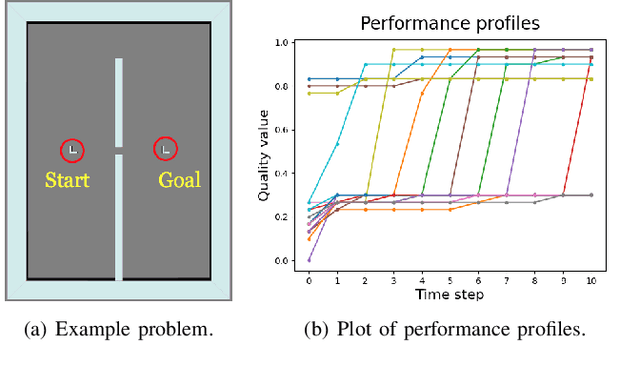
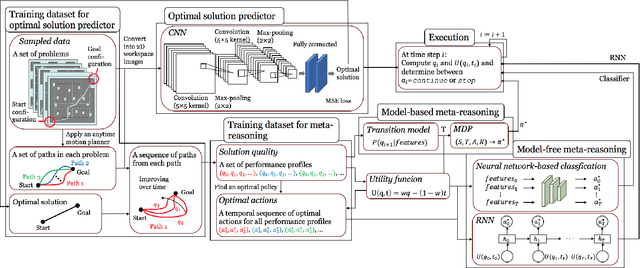
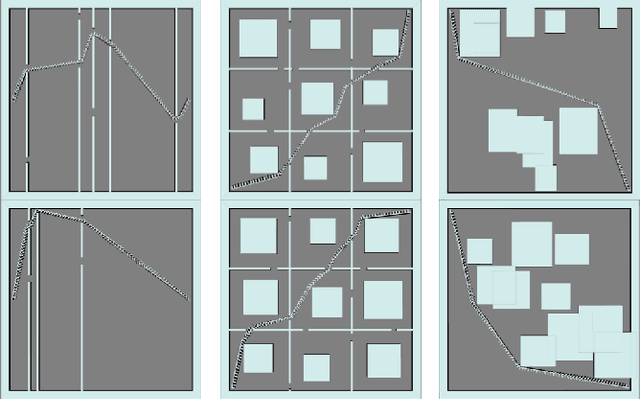
Anytime motion planners are widely used in robotics. However, the relationship between their solution quality and computation time is not well understood, and thus, determining when to quit planning and start execution is unclear. In this paper, we address the problem of deciding when to stop deliberation under bounded computational capacity, so called meta-reasoning, for anytime motion planning. We propose data-driven learning methods, model-based and model-free meta-reasoning, that are applicable to different environment distributions and agnostic to the choice of anytime motion planners. As a part of the framework, we design a convolutional neural network-based optimal solution predictor that predicts the optimal path length from a given 2D workspace image. We empirically evaluate the performance of the proposed methods in simulation in comparison with baselines.
Uncalibrated Neural Inverse Rendering for Photometric Stereo of General Surfaces
Dec 12, 2020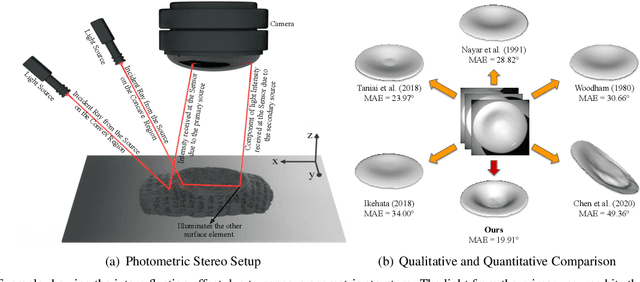
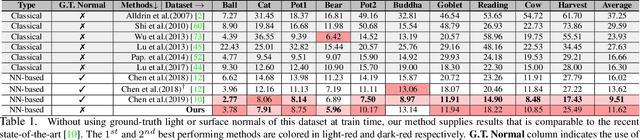
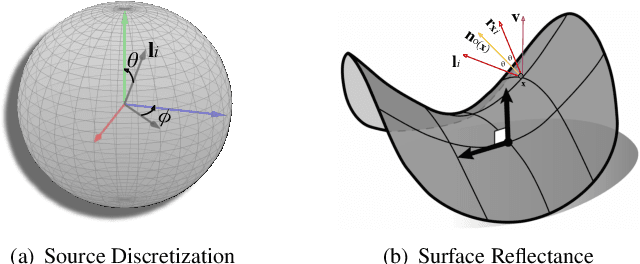

This paper presents an uncalibrated deep neural network framework for the photometric stereo problem. For training models to solve the problem, existing neural network-based methods either require exact light directions or ground-truth surface normals of the object or both. However, in practice, it is challenging to procure both of this information precisely, which restricts the broader adoption of photometric stereo algorithms for vision application. To bypass this difficulty, we propose an uncalibrated neural inverse rendering approach to this problem. Our method first estimates the light directions from the input images and then optimizes an image reconstruction loss to calculate the surface normals, bidirectional reflectance distribution function value, and depth. Additionally, our formulation explicitly models the concave and convex parts of a complex surface to consider the effects of interreflections in the image formation process. Extensive evaluation of the proposed method on the challenging subjects generally shows comparable or better results than the supervised and classical approaches.
Sparse-GAN: Sparsity-constrained Generative Adversarial Network for Anomaly Detection in Retinal OCT Image
Nov 28, 2019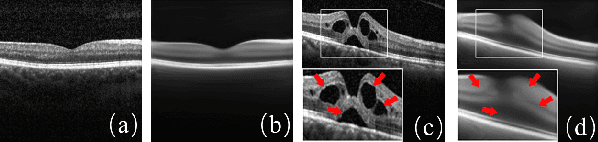
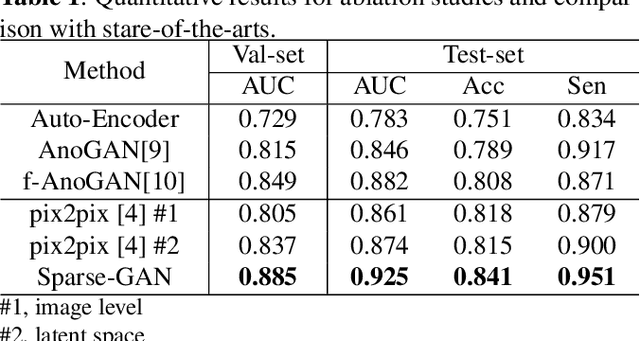
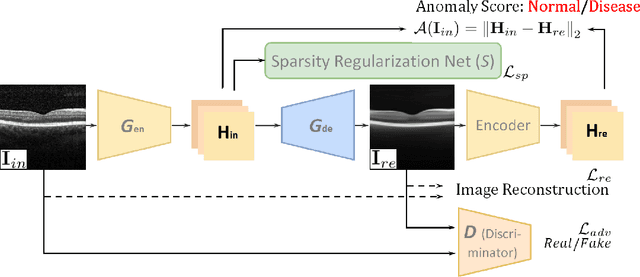
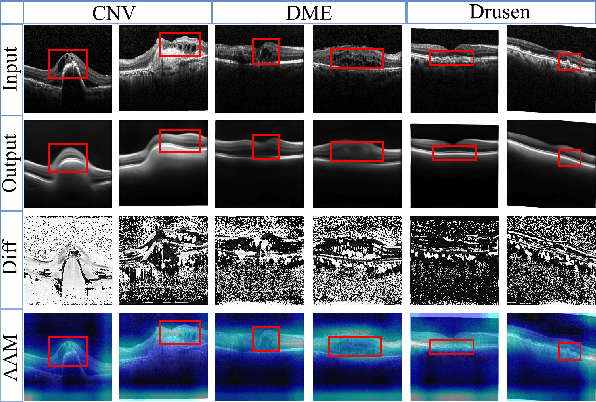
With the development of convolutional neural network, deep learning has shown its success for retinal disease detection from optical coherence tomography (OCT) images. However, deep learning often relies on large scale labelled data for training, which is oftentimes challenging especially for disease with low occurrence. Moreover, a deep learning system trained from data-set with one or a few diseases is unable to detect other unseen diseases, which limits the practical usage of the system in disease screening. To address the limitation, we propose a novel anomaly detection framework termed Sparsity-constrained Generative Adversarial Network (Sparse-GAN) for disease screening where only healthy data are available in the training set. The contributions of Sparse-GAN are two-folds: 1) The proposed Sparse-GAN predicts the anomalies in latent space rather than image-level; 2) Sparse-GAN is constrained by a novel Sparsity Regularization Net. Furthermore, in light of the role of lesions for disease screening, we present to leverage on an anomaly activation map to show the heatmap of lesions. We evaluate our proposed Sparse-GAN on a publicly available dataset, and the results show that the proposed method outperforms the state-of-the-art methods.