 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Energy-Efficient AI over a Virtualized Cloud Fog Network
May 07, 2021
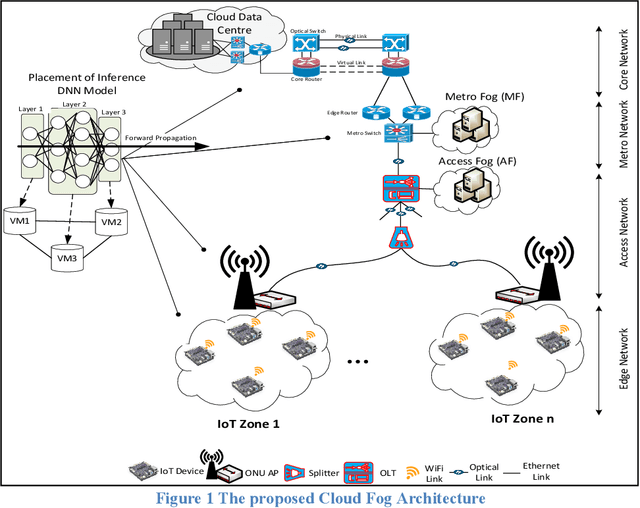
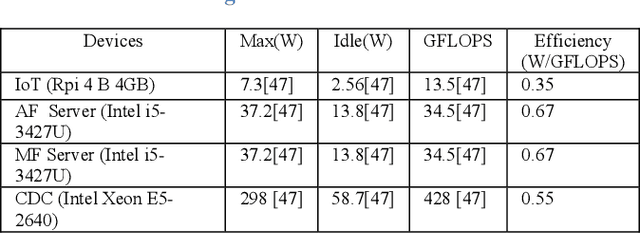
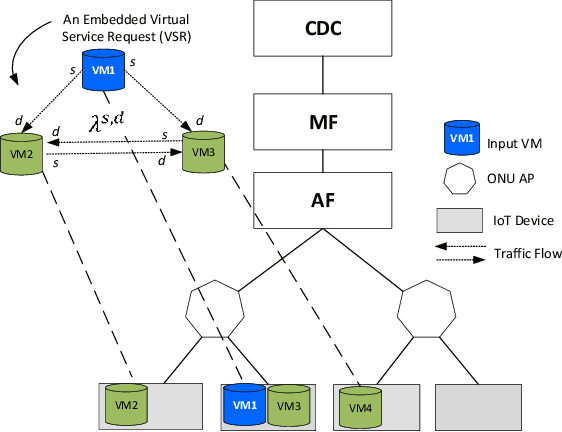
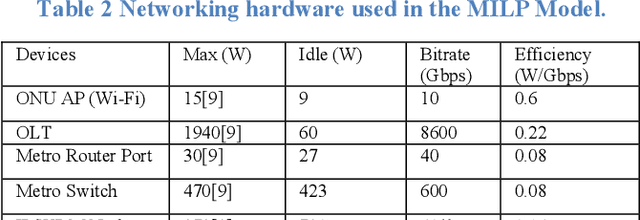
Deep Neural Networks (DNNs) have served as a catalyst in introducing a plethora of next-generation services in the era of Internet of Things (IoT), thanks to the availability of massive amounts of data collected by the objects on the edge. Currently, DNN models are used to deliver many Artificial Intelligence (AI) services that include image and natural language processing, speech recognition, and robotics. Accordingly, such services utilize various DNN models that make it computationally intensive for deployment on the edge devices alone. Thus, most AI models are offloaded to distant cloud data centers (CDCs), which tend to consolidate large amounts of computing and storage resources into one or more CDCs. Deploying services in the CDC will inevitably lead to excessive latencies and overall increase in power consumption. Instead, fog computing allows for cloud services to be extended to the edge of the network, which allows for data processing to be performed closer to the end-user device. However, different from cloud data centers, fog nodes have limited computational power and are highly distributed in the network. In this paper, using Mixed Integer Linear Programming (MILP), we formulate the placement of DNN inference models, which is abstracted as a network embedding problem in a Cloud Fog Network (CFN) architecture, where power savings are introduced through trade-offs between processing and networking. We study the performance of the CFN architecture by comparing the energy savings when compared to the baseline approach which is the CDC.
Learning Hybrid Sparsity Prior for Image Restoration: Where Deep Learning Meets Sparse Coding
Jul 18, 2018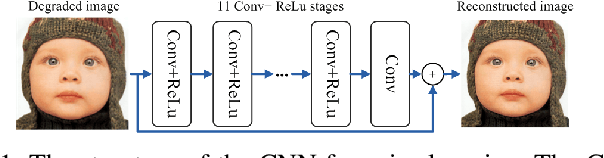


State-of-the-art approaches toward image restoration can be classified into model-based and learning-based. The former - best represented by sparse coding techniques - strive to exploit intrinsic prior knowledge about the unknown high-resolution images; while the latter - popularized by recently developed deep learning techniques - leverage external image prior from some training dataset. It is natural to explore their middle ground and pursue a hybrid image prior capable of achieving the best in both worlds. In this paper, we propose a systematic approach of achieving this goal called Structured Analysis Sparse Coding (SASC). Specifically, a structured sparse prior is learned from extrinsic training data via a deep convolutional neural network (in a similar way to previous learning-based approaches); meantime another structured sparse prior is internally estimated from the input observation image (similar to previous model-based approaches). Two structured sparse priors will then be combined to produce a hybrid prior incorporating the knowledge from both domains. To manage the computational complexity, we have developed a novel framework of implementing hybrid structured sparse coding processes by deep convolutional neural networks. Experimental results show that the proposed hybrid image restoration method performs comparably with and often better than the current state-of-the-art techniques.
Deep HVS-IQA Net: Human Visual System Inspired Deep Image Quality Assessment Networks
Feb 14, 2019
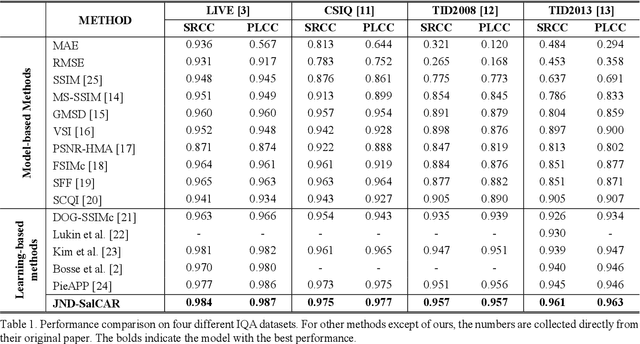
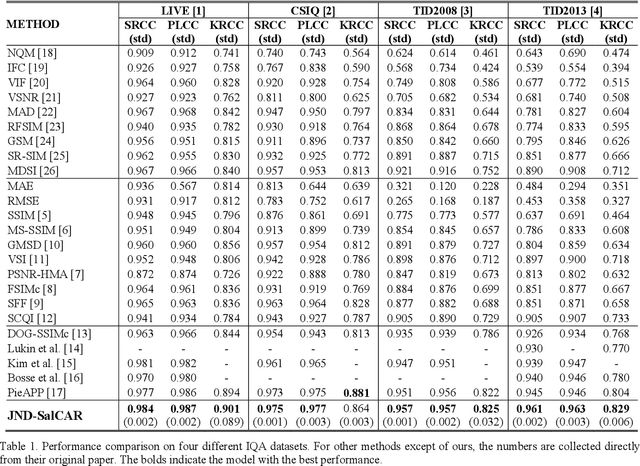
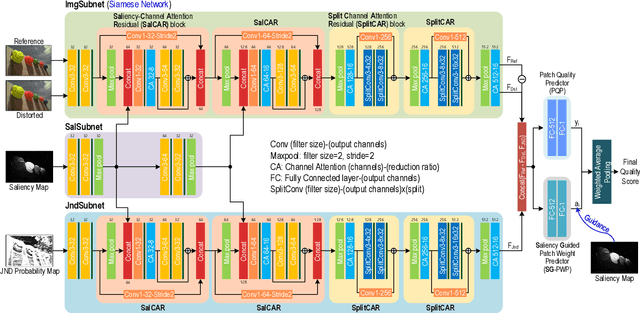
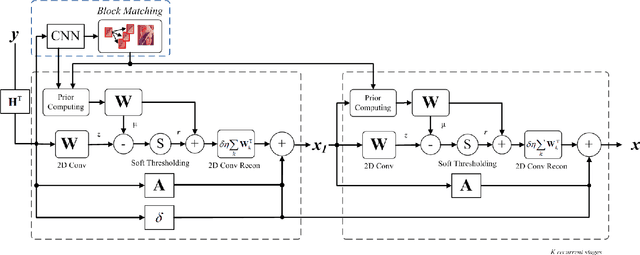
In image quality enhancement processing, it is the most important to predict how humans perceive processed images since human observers are the ultimate receivers of the images. Thus, objective image quality assessment (IQA) methods based on human visual sensitivity from psychophysical experiments have been extensively studied. Thanks to the powerfulness of deep convolutional neural networks (CNN), many CNN based IQA models have been studied. However, previous CNN-based IQA models have not fully utilized the characteristics of human visual systems (HVS) for IQA problems by simply entrusting everything to CNN where the CNN-based models are often trained as a regressor to predict the scores of subjective quality assessment obtained from IQA datasets. In this paper, we propose a novel HVS-inspired deep IQA network, called Deep HVS-IQA Net, where the human psychophysical characteristics such as visual saliency and just noticeable difference (JND) are incorporated at the front-end of the Deep HVS-IQA Net. To our best knowledge, our work is the first HVS-inspired trainable IQA network that considers both the visual saliency and JND characteristics of HVS. Furthermore, we propose a rank loss to train our Deep HVS-IQA Net effectively so that perceptually important features can be extracted for image quality prediction. The rank loss can penalize the Deep HVS-IQA Net when the order of its predicted quality scores is different from that of the ground truth scores. We evaluate the proposed Deep HVS-IQA Net on large IQA datasets where it outperforms all the recent state-of-the-art IQA methods.
Beyond Pixels: Image Provenance Analysis Leveraging Metadata
Jul 15, 2018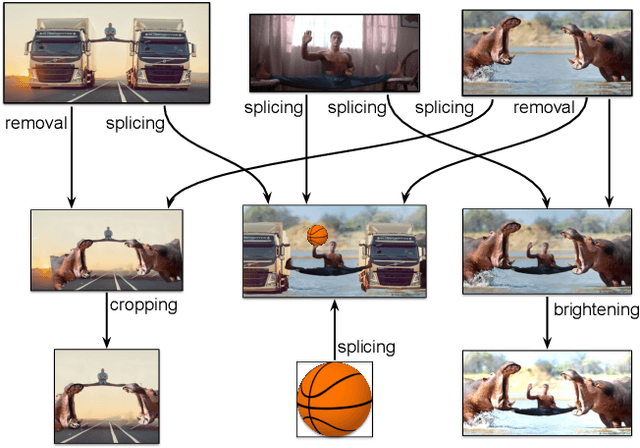
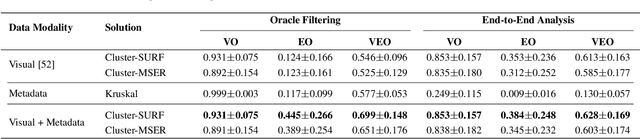
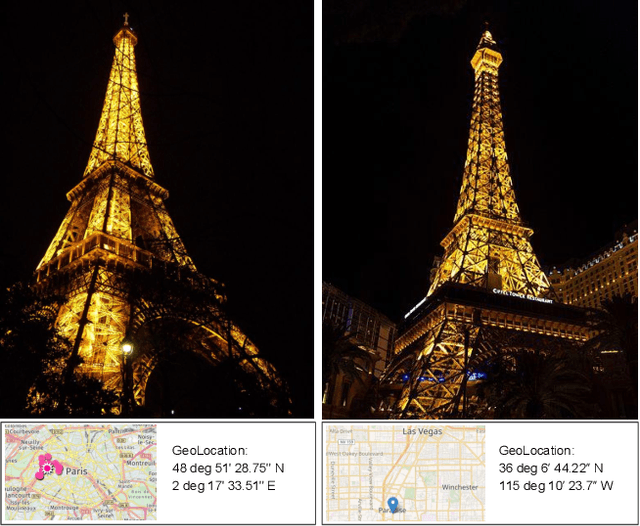
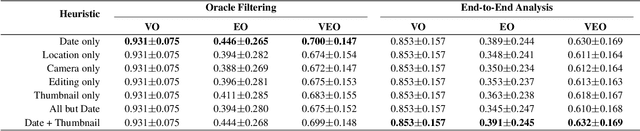
Creative works, whether paintings or memes, follow unique journeys that result in their final form. Understanding these journeys, a process known as "provenance analysis", provides rich insights into the use, motivation, and authenticity underlying any given work. The application of this type of study to the expanse of unregulated content on the Internet is what we consider in this paper. Provenance analysis provides a snapshot of the chronology and validity of content as it is uploaded, re-uploaded, and modified over time. Although still in its infancy, automated provenance analysis for online multimedia is already being applied to different types of content. Most current works seek to build provenance graphs based on the shared content between images or videos. This can be a computationally expensive task, especially when considering the vast influx of content that the Internet sees every day. Utilizing non-content-based information, such as timestamps, geotags, and camera IDs can help provide important insights into the path a particular image or video has traveled during its time on the Internet without large computational overhead. This paper tests the scope and applicability of metadata-based inferences for provenance graph construction in two different scenarios: digital image forensics and cultural analytics.
Deep-neural-network based sinogram synthesis for sparse-view CT image reconstruction
Mar 06, 2018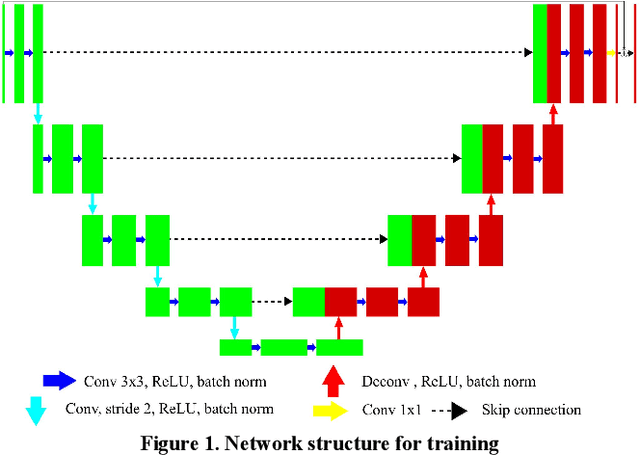
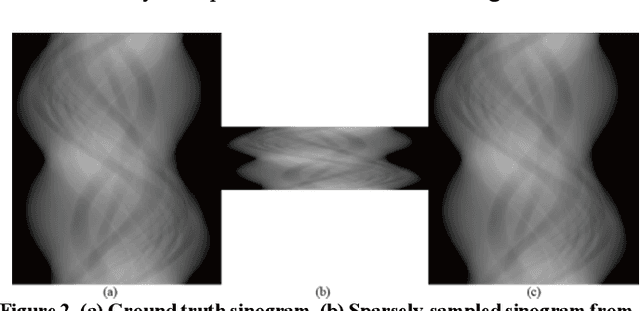

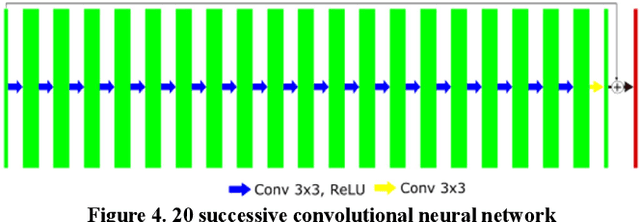
Recently, a number of approaches to low-dose computed tomography (CT) have been developed and deployed in commercialized CT scanners. Tube current reduction is perhaps the most actively explored technology with advanced image reconstruction algorithms. Sparse data sampling is another viable option to the low-dose CT, and sparse-view CT has been particularly of interest among the researchers in CT community. Since analytic image reconstruction algorithms would lead to severe image artifacts, various iterative algorithms have been developed for reconstructing images from sparsely view-sampled projection data. However, iterative algorithms take much longer computation time than the analytic algorithms, and images are usually prone to different types of image artifacts that heavily depend on the reconstruction parameters. Interpolation methods have also been utilized to fill the missing data in the sinogram of sparse-view CT thus providing synthetically full data for analytic image reconstruction. In this work, we introduce a deep-neural-network-enabled sinogram synthesis method for sparse-view CT, and show its outperformance to the existing interpolation methods and also to the iterative image reconstruction approach.
Hyperspectral Anomaly Change Detection Based on Auto-encoder
Oct 27, 2020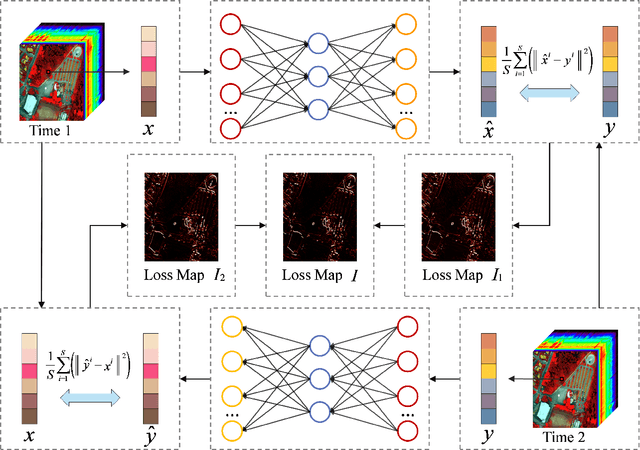



With the hyperspectral imaging technology, hyperspectral data provides abundant spectral information and plays a more important role in geological survey, vegetation analysis and military reconnaissance. Different from normal change detection, hyperspectral anomaly change detection (HACD) helps to find those small but important anomaly changes between multi-temporal hyperspectral images (HSI). In previous works, most classical methods use linear regression to establish the mapping relationship between two HSIs and then detect the anomalies from the residual image. However, the real spectral differences between multi-temporal HSIs are likely to be quite complex and of nonlinearity, leading to the limited performance of these linear predictors. In this paper, we propose an original HACD algorithm based on auto-encoder (ACDA) to give a nonlinear solution. The proposed ACDA can construct an effective predictor model when facing complex imaging conditions. In the ACDA model, two systematic auto-encoder (AE) networks are deployed to construct two predictors from two directions. The predictor is used to model the spectral variation of the background to obtain the predicted image under another imaging condition. Then mean square error (MSE) between the predictive image and corresponding expected image is computed to obtain the loss map, where the spectral differences of the unchanged pixels are highly suppressed and anomaly changes are highlighted. Ultimately, we take the minimum of the two loss maps of two directions as the final anomaly change intensity map. The experiments results on public "Viareggio 2013" datasets demonstrate the efficiency and superiority over traditional methods.
Patch Shortcuts: Interpretable Proxy Models Efficiently Find Black-Box Vulnerabilities
Apr 22, 2021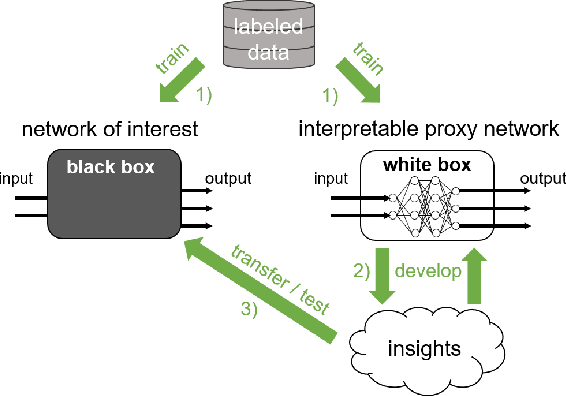
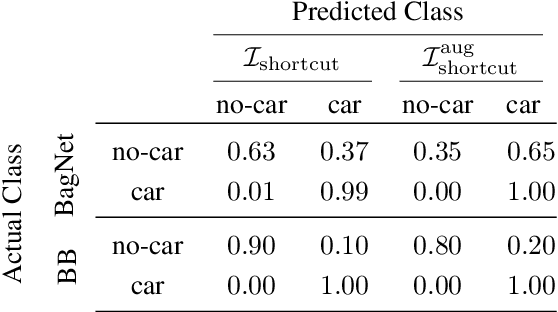

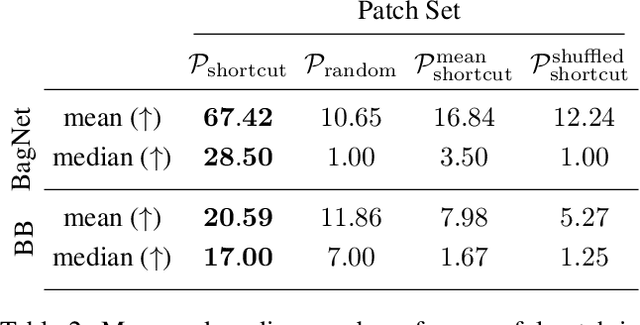
An important pillar for safe machine learning (ML) is the systematic mitigation of weaknesses in neural networks to afford their deployment in critical applications. An ubiquitous class of safety risks are learned shortcuts, i.e. spurious correlations a network exploits for its decisions that have no semantic connection to the actual task. Networks relying on such shortcuts bear the risk of not generalizing well to unseen inputs. Explainability methods help to uncover such network vulnerabilities. However, many of these techniques are not directly applicable if access to the network is constrained, in so-called black-box setups. These setups are prevalent when using third-party ML components. To address this constraint, we present an approach to detect learned shortcuts using an interpretable-by-design network as a proxy to the black-box model of interest. Leveraging the proxy's guarantees on introspection we automatically extract candidates for learned shortcuts. Their transferability to the black box is validated in a systematic fashion. Concretely, as proxy model we choose a BagNet, which bases its decisions purely on local image patches. We demonstrate on the autonomous driving dataset A2D2 that extracted patch shortcuts significantly influence the black box model. By efficiently identifying such patch-based vulnerabilities, we contribute to safer ML models.
SSLM: Self-Supervised Learning for Medical Diagnosis from MR Video
Apr 22, 2021
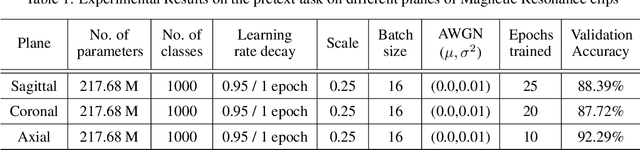
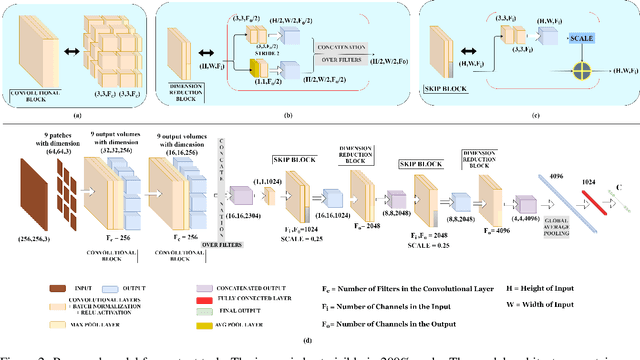
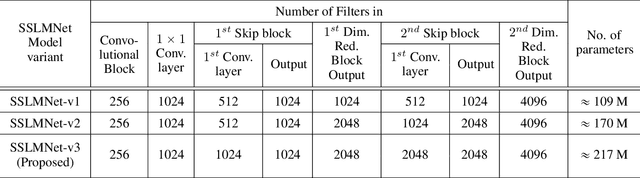
In medical image analysis, the cost of acquiring high-quality data and their annotation by experts is a barrier in many medical applications. Most of the techniques used are based on supervised learning framework and need a large amount of annotated data to achieve satisfactory performance. As an alternative, in this paper, we propose a self-supervised learning approach to learn the spatial anatomical representations from the frames of magnetic resonance (MR) video clips for the diagnosis of knee medical conditions. The pretext model learns meaningful spatial context-invariant representations. The downstream task in our paper is a class imbalanced multi-label classification. Different experiments show that the features learnt by the pretext model provide explainable performance in the downstream task. Moreover, the efficiency and reliability of the proposed pretext model in learning representations of minority classes without applying any strategy towards imbalance in the dataset can be seen from the results. To the best of our knowledge, this work is the first work of its kind in showing the effectiveness and reliability of self-supervised learning algorithms in class imbalanced multi-label classification tasks on MR video. The code for evaluation of the proposed work is available at https://github.com/sadimanna/sslm
The Federated Tumor Segmentation (FeTS) Challenge
May 14, 2021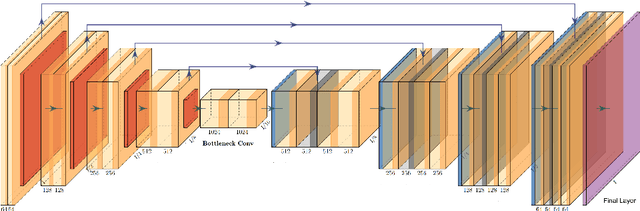
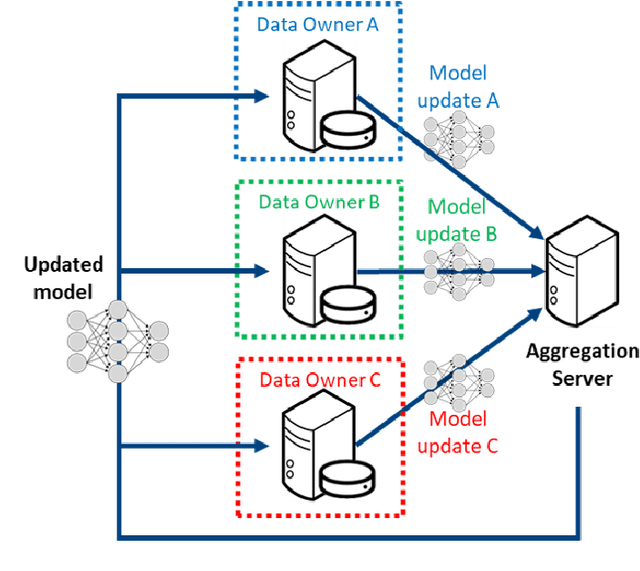
This manuscript describes the first challenge on Federated Learning, namely the Federated Tumor Segmentation (FeTS) challenge 2021. International challenges have become the standard for validation of biomedical image analysis methods. However, the actual performance of participating (even the winning) algorithms on "real-world" clinical data often remains unclear, as the data included in challenges are usually acquired in very controlled settings at few institutions. The seemingly obvious solution of just collecting increasingly more data from more institutions in such challenges does not scale well due to privacy and ownership hurdles. Towards alleviating these concerns, we are proposing the FeTS challenge 2021 to cater towards both the development and the evaluation of models for the segmentation of intrinsically heterogeneous (in appearance, shape, and histology) brain tumors, namely gliomas. Specifically, the FeTS 2021 challenge uses clinically acquired, multi-institutional magnetic resonance imaging (MRI) scans from the BraTS 2020 challenge, as well as from various remote independent institutions included in the collaborative network of a real-world federation (https://www.fets.ai/). The goals of the FeTS challenge are directly represented by the two included tasks: 1) the identification of the optimal weight aggregation approach towards the training of a consensus model that has gained knowledge via federated learning from multiple geographically distinct institutions, while their data are always retained within each institution, and 2) the federated evaluation of the generalizability of brain tumor segmentation models "in the wild", i.e. on data from institutional distributions that were not part of the training datasets.
Efficient Visual Pretraining with Contrastive Detection
Mar 19, 2021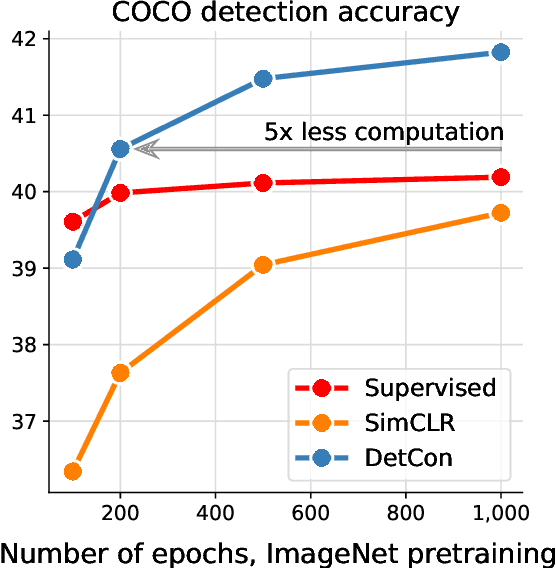
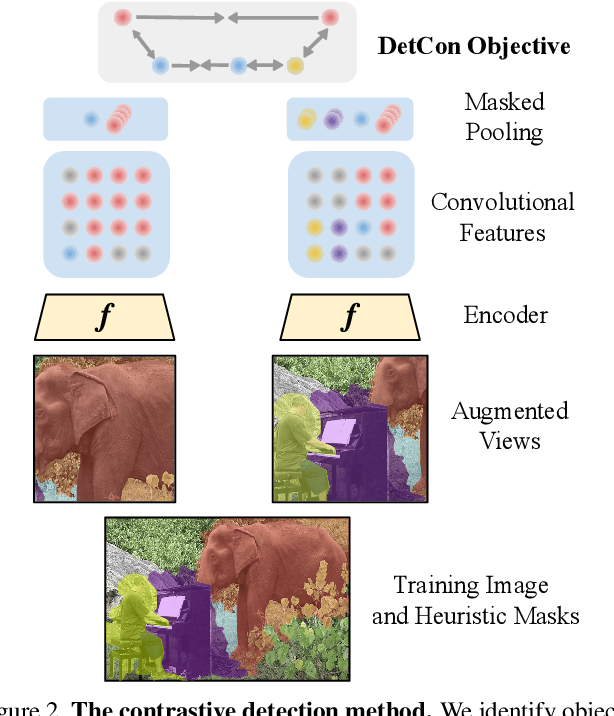
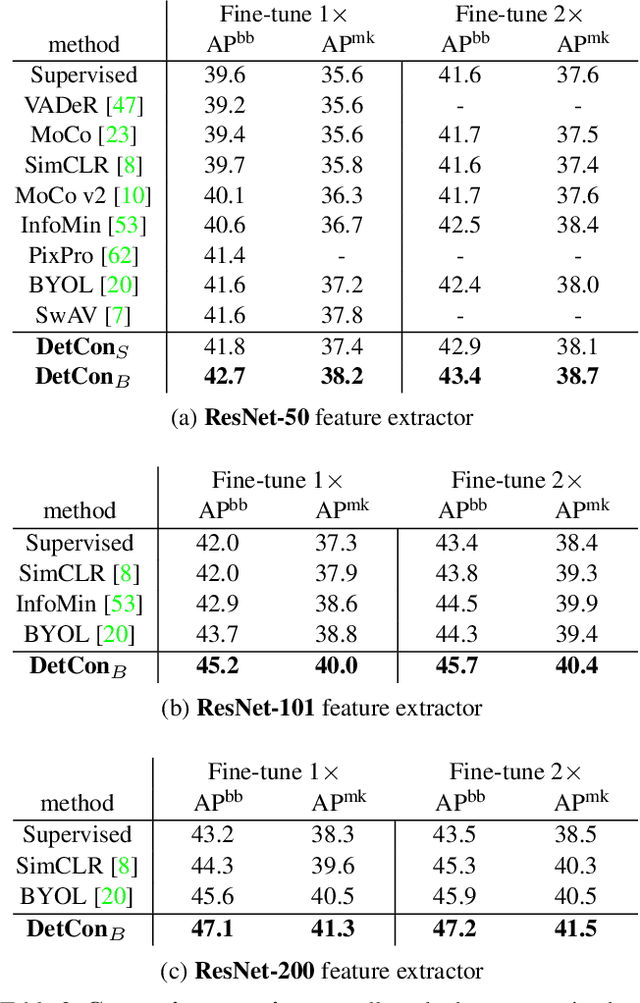

Self-supervised pretraining has been shown to yield powerful representations for transfer learning. These performance gains come at a large computational cost however, with state-of-the-art methods requiring an order of magnitude more computation than supervised pretraining. We tackle this computational bottleneck by introducing a new self-supervised objective, contrastive detection, which tasks representations with identifying object-level features across augmentations. This objective extracts a rich learning signal per image, leading to state-of-the-art transfer performance from ImageNet to COCO, while requiring up to 5x less pretraining. In particular, our strongest ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pretraining data. Finally, our objective seamlessly handles pretraining on more complex images such as those in COCO, closing the gap with supervised transfer learning from COCO to PASCAL.