 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spherical Transformer: Adapting Spherical Signal to CNNs
Jan 24, 2021
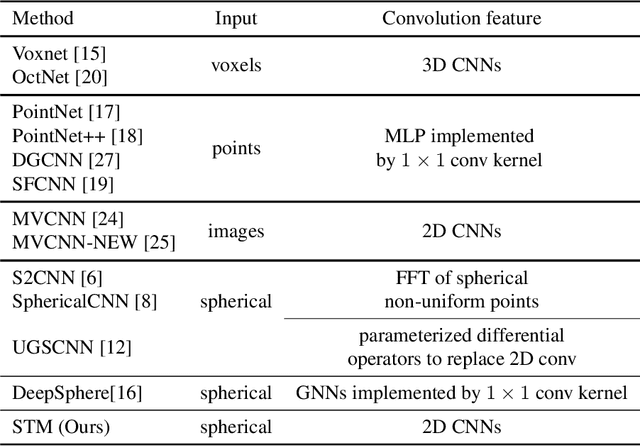
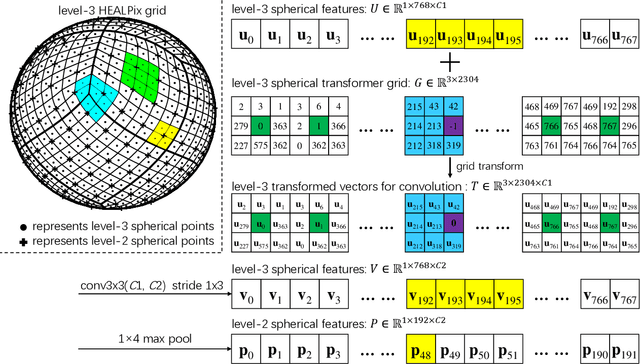
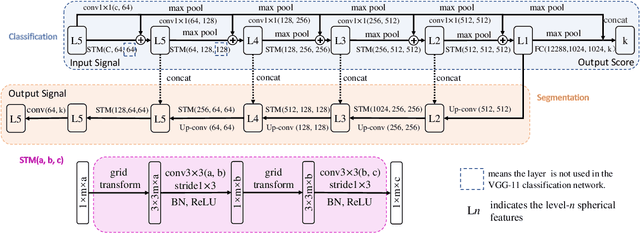
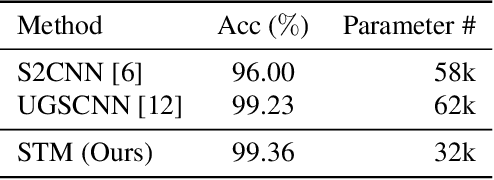
Convolutional neural networks (CNNs) have been widely used in various vision tasks, e.g. image classification, semantic segmentation, etc. Unfortunately, standard 2D CNNs are not well suited for spherical signals such as panorama images or spherical projections, as the sphere is an unstructured grid. In this paper, we present Spherical Transformer which can transform spherical signals into vectors that can be directly processed by standard CNNs such that many well-designed CNNs architectures can be reused across tasks and datasets by pretraining. To this end, the proposed method first uses locally structured sampling methods such as HEALPix to construct a transformer grid by using the information of spherical points and its adjacent points, and then transforms the spherical signals to the vectors through the grid. By building the Spherical Transformer module, we can use multiple CNN architectures directly. We evaluate our approach on the tasks of spherical MNIST recognition, 3D object classification and omnidirectional image semantic segmentation. For 3D object classification, we further propose a rendering-based projection method to improve the performance and a rotational-equivariant model to improve the anti-rotation ability. Experimental results on three tasks show that our approach achieves superior performance over state-of-the-art methods.
Continual Learning From Unlabeled Data Via Deep Clustering
Apr 14, 2021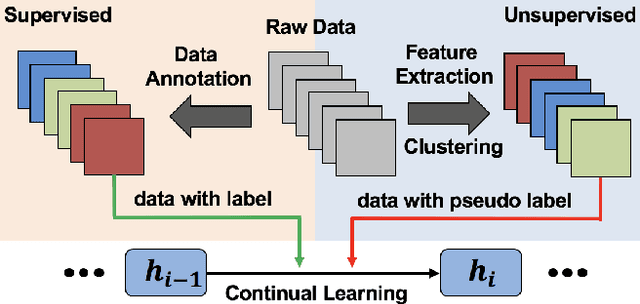
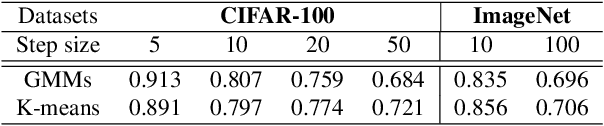
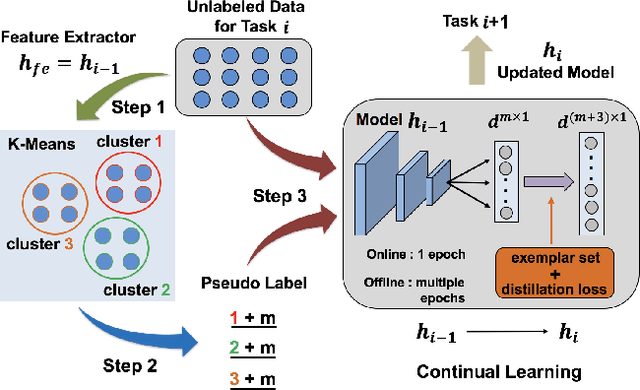
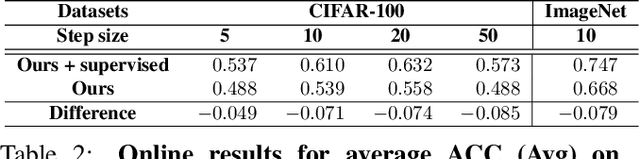
Continual learning, a promising future learning strategy, aims to learn new tasks incrementally using less computation and memory resources instead of retraining the model from scratch whenever new task arrives. However, existing approaches are designed in supervised fashion assuming all data from new tasks have been annotated, which are not practical for many real-life applications. In this work, we introduce a new framework to make continual learning feasible in unsupervised mode by using pseudo label obtained from cluster assignments to update model. We focus on image classification task under class-incremental setting and assume no class label is provided for training in each incremental learning step. For illustration purpose, we apply k-means clustering, knowledge distillation loss and exemplar set as our baseline solution, which achieves competitive results even compared with supervised approaches on both challenging CIFAR-100 and ImageNet (ILSVRC) datasets. We also demonstrate that the performance of our baseline solution can be further improved by incorporating recently developed supervised continual learning techniques, showing great potential for our framework to minimize the gap between supervised and unsupervised continual learning.
SE-Harris and eSUSAN: Asynchronous Event-Based Corner Detection Using Megapixel Resolution CeleX-V Camera
May 02, 2021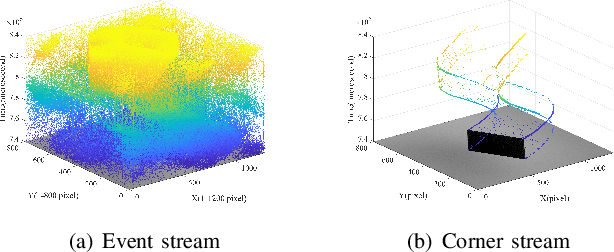
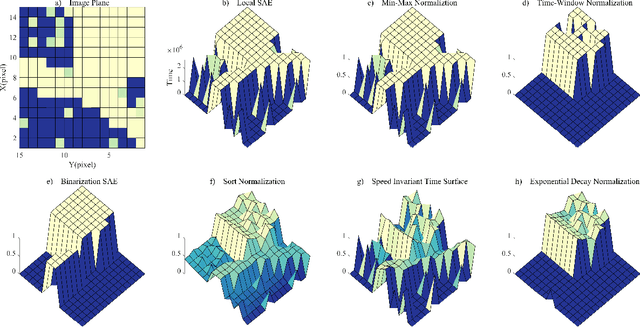
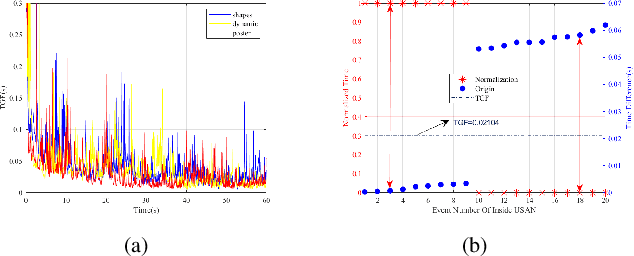
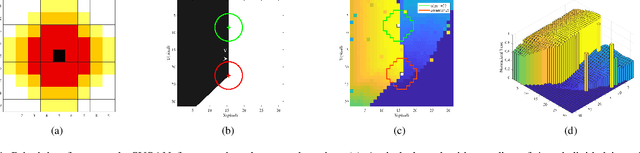
Event cameras are novel neuromorphic vision sensors with ultrahigh temporal resolution and low latency, both in the order of microseconds. Instead of image frames, event cameras generate an asynchronous event stream of per-pixel intensity changes with precise timestamps. The resulting sparse data structure impedes applying many conventional computer vision techniques to event streams, and specific algorithms should be designed to leverage the information provided by event cameras. We propose a corner detection algorithm, eSUSAN, inspired by the conventional SUSAN (smallest univalue segment assimilating nucleus) algorithm for corner detection. The proposed eSUSAN extracts the univalue segment assimilating nucleus from the circle kernel based on the similarity across timestamps and distinguishes corner events by the number of pixels in the nucleus area. Moreover, eSUSAN is fast enough to be applied to CeleX-V, the event camera with the highest resolution available. Based on eSUSAN, we also propose the SE-Harris corner detector, which uses adaptive normalization based on exponential decay to quickly construct a local surface of active events and the event-based Harris detector to refine the corners identified by eSUSAN. We evaluated the proposed algorithms on a public dataset and CeleX-V data. Both eSUSAN and SE-Harris exhibit higher real-time performance than existing algorithms while maintaining high accuracy and tracking performance.
Improving axial resolution in SIM using deep learning
Sep 04, 2020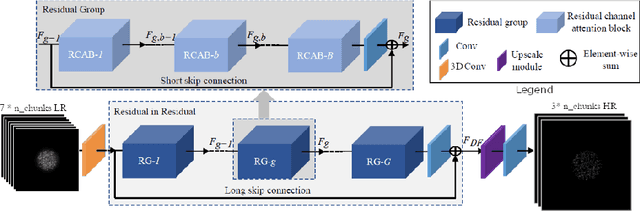

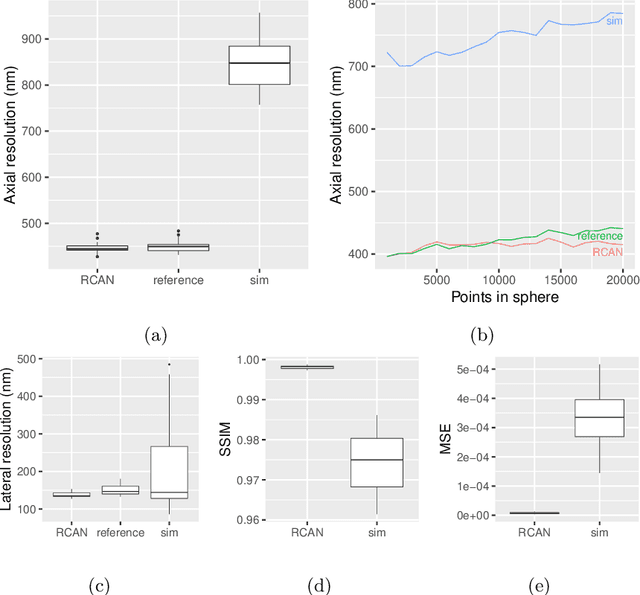
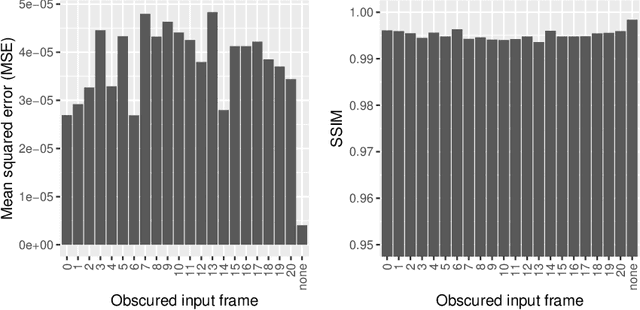
Structured Illumination Microscopy is a widespread methodology to image live and fixed biological structures smaller than the diffraction limits of conventional optical microscopy. Using recent advances in image up-scaling through deep learning models, we demonstrate a method to reconstruct 3D SIM image stacks with twice the axial resolution attainable through conventional SIM reconstructions. We further evaluate our method for robustness to noise & generalisability to varying observed specimens, and discuss potential adaptions of the method to further improvements in resolution.
Fractional Calculus In Image Processing: A Review
Aug 10, 2016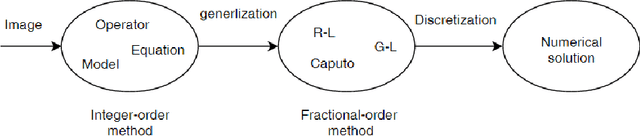
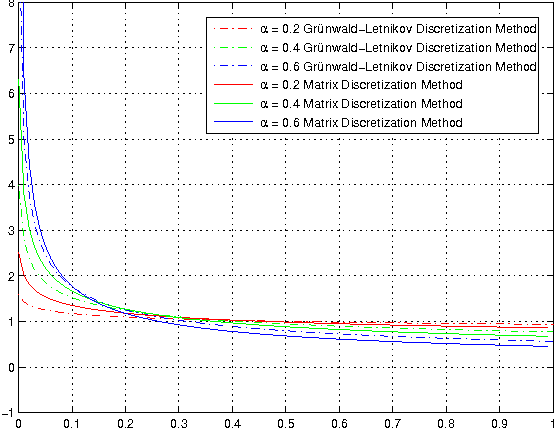

Over the last decade, it has been demonstrated that many systems in science and engineering can be modeled more accurately by fractional-order than integer-order derivatives, and many methods are developed to solve the problem of fractional systems. Due to the extra free parameter order, fractional-order based methods provide additional degree of freedom in optimization performance. Not surprisingly, many fractional-order based methods have been used in image processing field. Herein recent studies are reviewed in ten sub-fields, which include image enhancement, image denoising, image edge detection, image segmentation, image registration, image recognition, image fusion, image encryption, image compression and image restoration. In sum, it is well proved that as a fundamental mathematic tool, fractional-order derivative shows great success in image processing.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
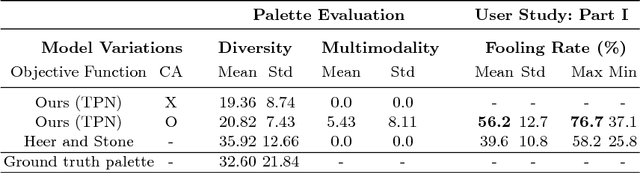


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures
A Straightforward Framework For Video Retrieval Using CLIP
Feb 26, 2021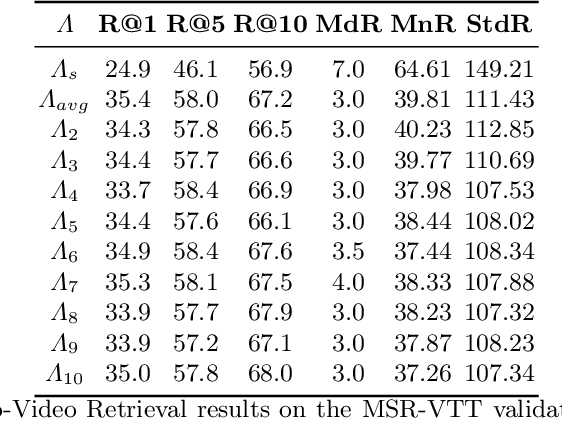
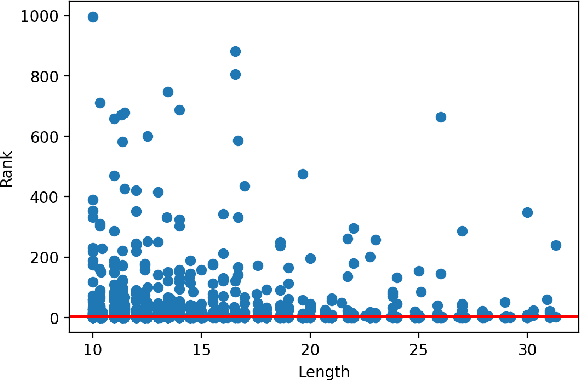
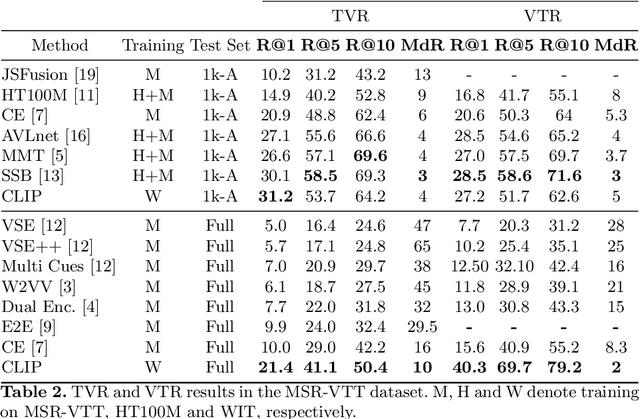
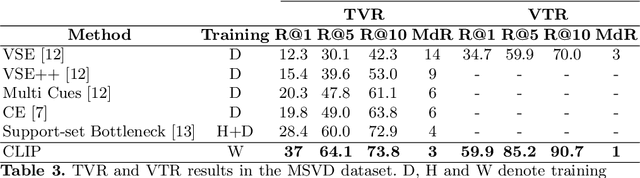
Video Retrieval is a challenging task where a text query is matched to a video or vice versa. Most of the existing approaches for addressing such a problem rely on annotations made by the users. Although simple, this approach is not always feasible in practice. In this work, we explore the application of the language-image model, CLIP, to obtain video representations without the need for said annotations. This model was explicitly trained to learn a common space where images and text can be compared. Using various techniques described in this document, we extended its application to videos, obtaining state-of-the-art results on the MSR-VTT and MSVD benchmarks.
Adversarial Learning for Image Forensics Deep Matching with Atrous Convolution
Sep 08, 2018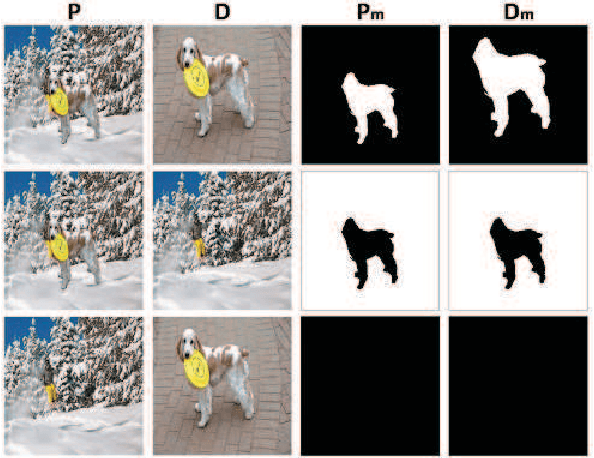
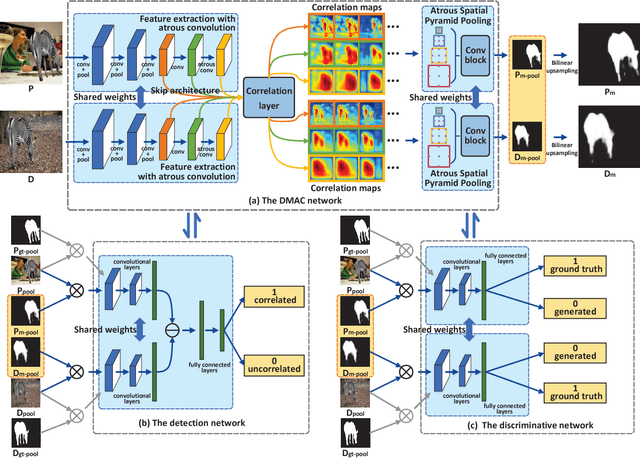
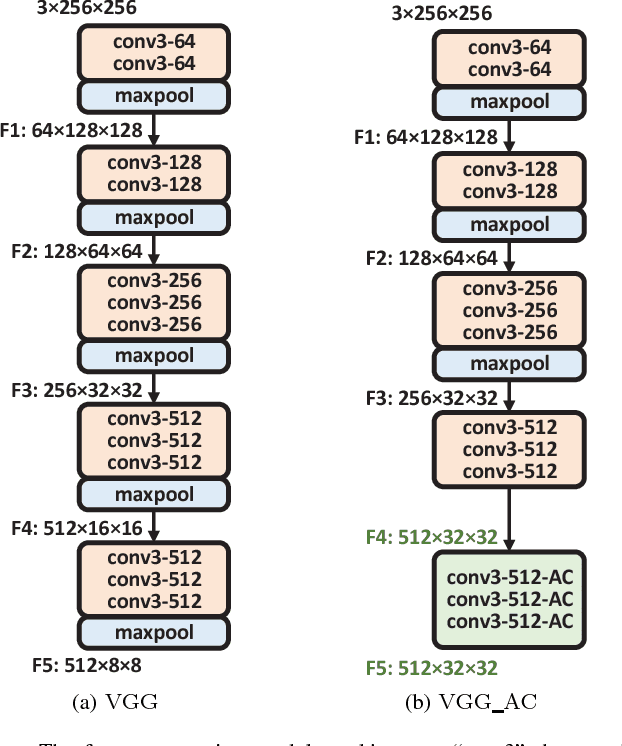
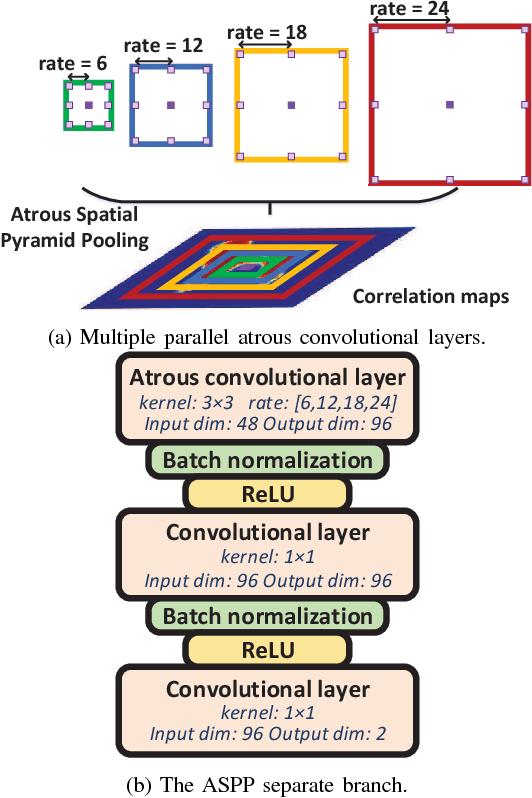
Constrained image splicing detection and localization (CISDL) is a newly proposed challenging task for image forensics, which investigates two input suspected images and identifies whether one image has suspected regions pasted from the other. In this paper, we propose a novel adversarial learning framework to train the deep matching network for CISDL. Our framework mainly consists of three building blocks: 1) the deep matching network based on atrous convolution (DMAC) aims to generate two high-quality candidate masks which indicate the suspected regions of the two input images, 2) the detection network is designed to rectify inconsistencies between the two corresponding candidate masks, 3) the discriminative network drives the DMAC network to produce masks that are hard to distinguish from ground-truth ones. In DMAC, atrous convolution is adopted to extract features with rich spatial information, the correlation layer based on the skip architecture is proposed to capture hierarchical features, and atrous spatial pyramid pooling is constructed to localize tampered regions at multiple scales. The detection network and the discriminative network act as the losses with auxiliary parameters to supervise the training of DMAC in an adversarial way. Extensive experiments, conducted on 21 generated testing sets and two public datasets, demonstrate the effectiveness of the proposed framework and the superior performance of DMAC.
Answer-checking in Context: A Multi-modal FullyAttention Network for Visual Question Answering
Oct 17, 2020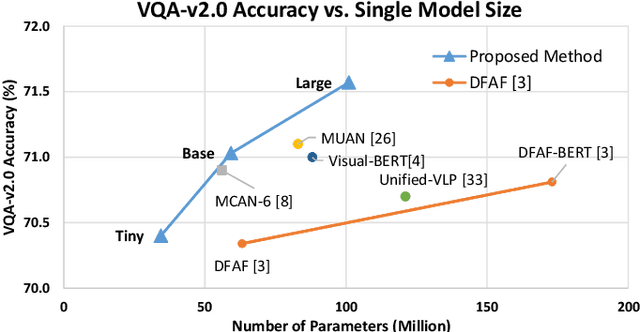
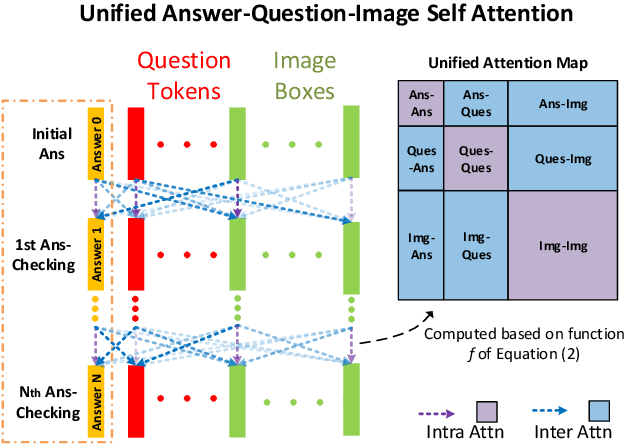
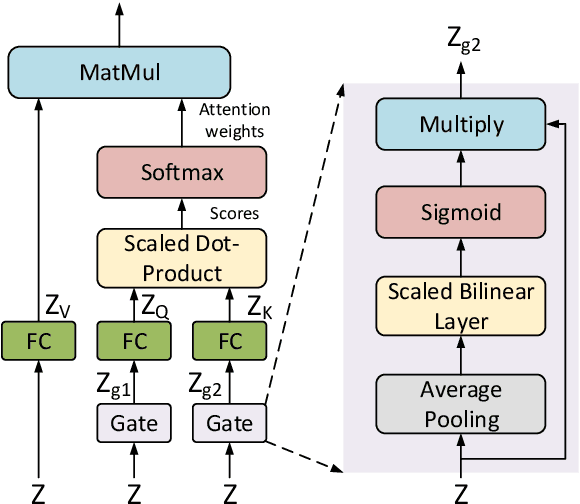
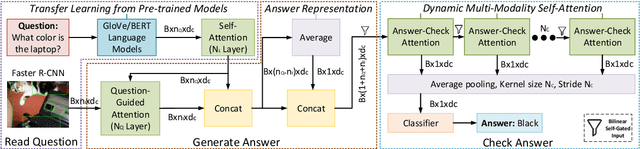
Visual Question Answering (VQA) is challenging due to the complex cross-modal relations. It has received extensive attention from the research community. From the human perspective, to answer a visual question, one needs to read the question and then refer to the image to generate an answer. This answer will then be checked against the question and image again for the final confirmation. In this paper, we mimic this process and propose a fully attention based VQA architecture. Moreover, an answer-checking module is proposed to perform a unified attention on the jointly answer, question and image representation to update the answer. This mimics the human answer checking process to consider the answer in the context. With answer-checking modules and transferred BERT layers, our model achieves the state-of-the-art accuracy 71.57\% using fewer parameters on VQA-v2.0 test-standard split.
Deep Image-to-Video Adaptation and Fusion Networks for Action Recognition
Nov 25, 2019
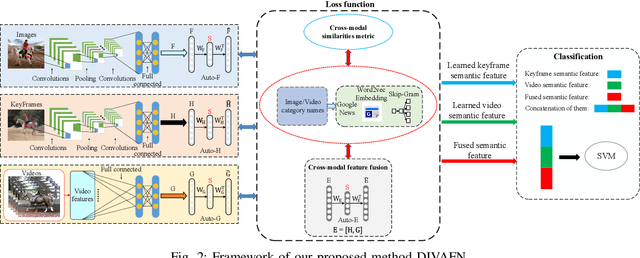


Existing deep learning methods for action recognition in videos require a large number of labeled videos for training, which is labor-intensive and time-consuming. For the same action, the knowledge learned from different media types, e.g., videos and images, may be related and complementary. However, due to the domain shifts and heterogeneous feature representations between videos and images, the performance of classifiers trained on images may be dramatically degraded when directly deployed to videos. In this paper, we propose a novel method, named Deep Image-to-Video Adaptation and Fusion Networks (DIVAFN), to enhance action recognition in videos by transferring knowledge from images using video keyframes as a bridge. The DIVAFN is a unified deep learning model, which integrates domain-invariant representations learning and cross-modal feature fusion into a unified optimization framework. Specifically, we design an efficient cross-modal similarities metric to reduce the modality shift among images, keyframes and videos. Then, we adopt an autoencoder architecture, whose hidden layer is constrained to be the semantic representations of the action class names. In this way, when the autoencoder is adopted to project the learned features from different domains to the same space, more compact, informative and discriminative representations can be obtained. Finally, the concatenation of the learned semantic feature representations from these three autoencoders are used to train the classifier for action recognition in videos. Comprehensive experiments on four real-world datasets show that our method outperforms some state-of-the-art domain adaptation and action recognition methods.