 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contour Proposal Networks for Biomedical Instance Segmentation
Apr 07, 2021

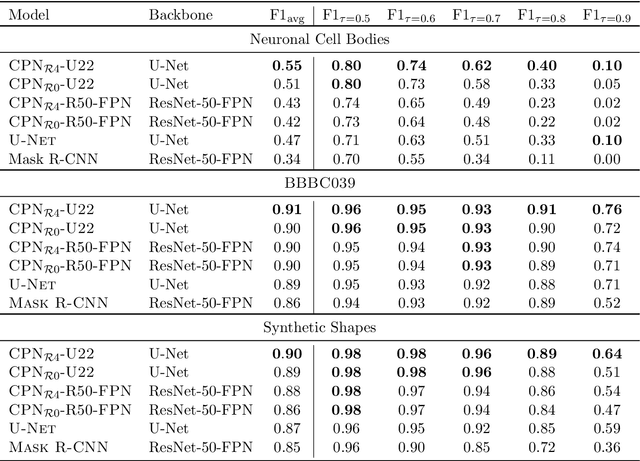


We present a conceptually simple framework for object instance segmentation called Contour Proposal Network (CPN), which detects possibly overlapping objects in an image while simultaneously fitting closed object contours using an interpretable, fixed-sized representation based on Fourier Descriptors. The CPN can incorporate state of the art object detection architectures as backbone networks into a single-stage instance segmentation model that can be trained end-to-end. We construct CPN models with different backbone networks, and apply them to instance segmentation of cells in datasets from different modalities. In our experiments, we show CPNs that outperform U-Nets and Mask R-CNNs in instance segmentation accuracy, and present variants with execution times suitable for real-time applications. The trained models generalize well across different domains of cell types. Since the main assumption of the framework are closed object contours, it is applicable to a wide range of detection problems also outside the biomedical domain. An implementation of the model architecture in PyTorch is freely available.
Optimal Transport as a Defense Against Adversarial Attacks
Feb 05, 2021
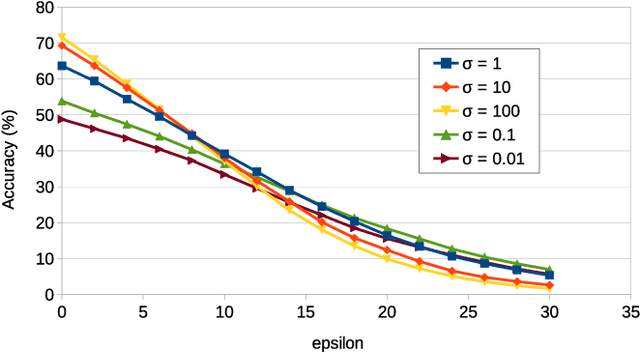
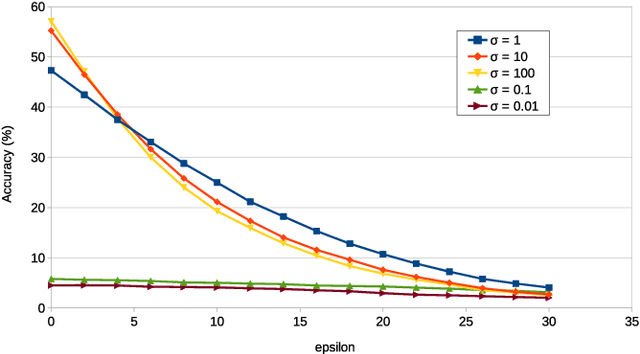
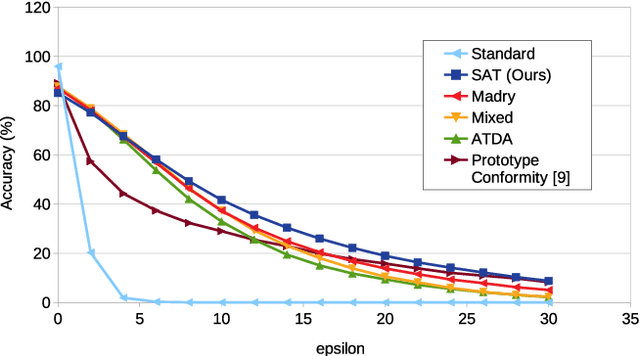
Deep learning classifiers are now known to have flaws in the representations of their class. Adversarial attacks can find a human-imperceptible perturbation for a given image that will mislead a trained model. The most effective methods to defend against such attacks trains on generated adversarial examples to learn their distribution. Previous work aimed to align original and adversarial image representations in the same way as domain adaptation to improve robustness. Yet, they partially align the representations using approaches that do not reflect the geometry of space and distribution. In addition, it is difficult to accurately compare robustness between defended models. Until now, they have been evaluated using a fixed perturbation size. However, defended models may react differently to variations of this perturbation size. In this paper, the analogy of domain adaptation is taken a step further by exploiting optimal transport theory. We propose to use a loss between distributions that faithfully reflect the ground distance. This leads to SAT (Sinkhorn Adversarial Training), a more robust defense against adversarial attacks. Then, we propose to quantify more precisely the robustness of a model to adversarial attacks over a wide range of perturbation sizes using a different metric, the Area Under the Accuracy Curve (AUAC). We perform extensive experiments on both CIFAR-10 and CIFAR-100 datasets and show that our defense is globally more robust than the state-of-the-art.
Visual-Semantic Embedding Model Informed by Structured Knowledge
Sep 21, 2020
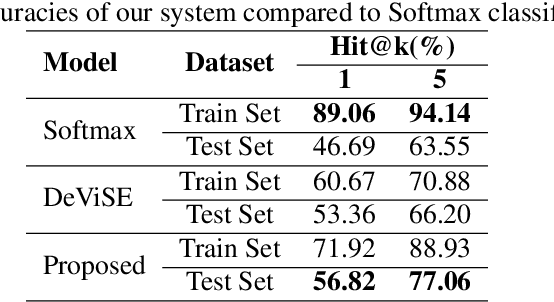
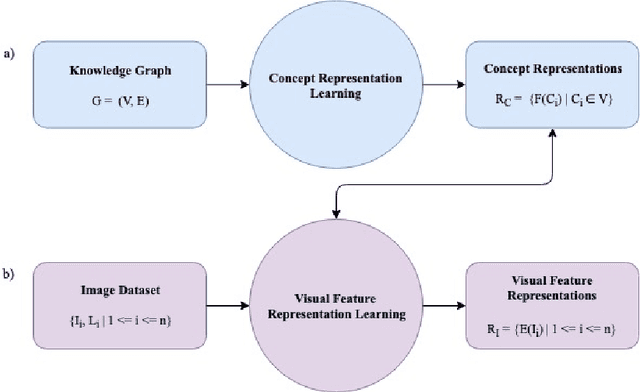

We propose a novel approach to improve a visual-semantic embedding model by incorporating concept representations captured from an external structured knowledge base. We investigate its performance on image classification under both standard and zero-shot settings. We propose two novel evaluation frameworks to analyse classification errors with respect to the class hierarchy indicated by the knowledge base. The approach is tested using the ILSVRC 2012 image dataset and a WordNet knowledge base. With respect to both standard and zero-shot image classification, our approach shows superior performance compared with the original approach, which uses word embeddings.
Segmentation overlapping wear particles with few labelled data and imbalance sample
Nov 20, 2020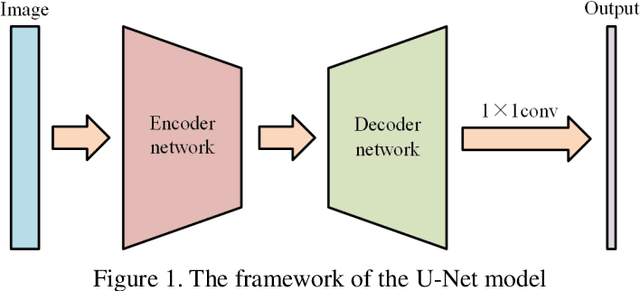
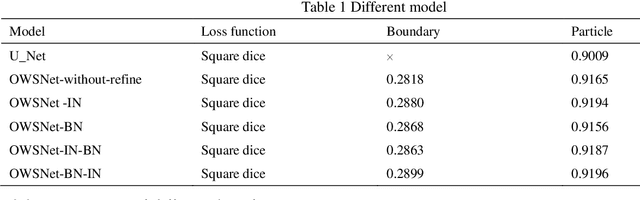
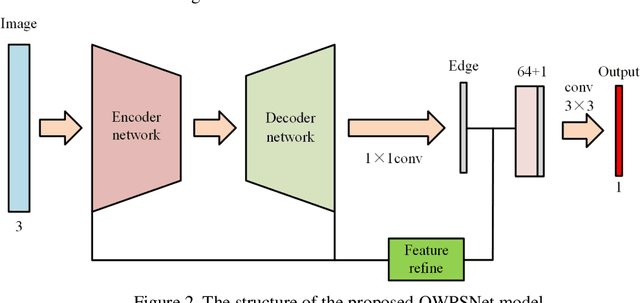

Ferrograph image segmentation is of significance for obtaining features of wear particles. However, wear particles are usually overlapped in the form of debris chains, which makes challenges to segment wear debris. An overlapping wear particle segmentation network (OWPSNet) is proposed in this study to segment the overlapped debris chains. The proposed deep learning model includes three parts: a region segmentation network, an edge detection network and a feature refine module. The region segmentation network is an improved U shape network, and it is applied to separate the wear debris form background of ferrograph image. The edge detection network is used to detect the edges of wear particles. Then, the feature refine module combines low-level features and high-level semantic features to obtain the final results. In order to solve the problem of sample imbalance, we proposed a square dice loss function to optimize the model. Finally, extensive experiments have been carried out on a ferrograph image dataset. Results show that the proposed model is capable of separating overlapping wear particles. Moreover, the proposed square dice loss function can improve the segmentation results, especially for the segmentation results of wear particle edge.
Detecting Adversarial Examples by Input Transformations, Defense Perturbations, and Voting
Jan 27, 2021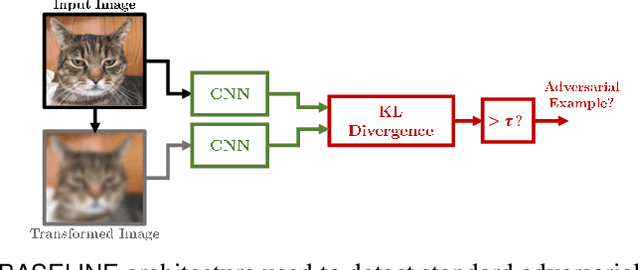

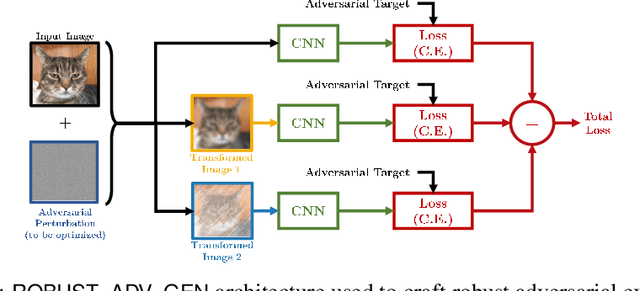
Over the last few years, convolutional neural networks (CNNs) have proved to reach super-human performance in visual recognition tasks. However, CNNs can easily be fooled by adversarial examples, i.e., maliciously-crafted images that force the networks to predict an incorrect output while being extremely similar to those for which a correct output is predicted. Regular adversarial examples are not robust to input image transformations, which can then be used to detect whether an adversarial example is presented to the network. Nevertheless, it is still possible to generate adversarial examples that are robust to such transformations. This paper extensively explores the detection of adversarial examples via image transformations and proposes a novel methodology, called \textit{defense perturbation}, to detect robust adversarial examples with the same input transformations the adversarial examples are robust to. Such a \textit{defense perturbation} is shown to be an effective counter-measure to robust adversarial examples. Furthermore, multi-network adversarial examples are introduced. This kind of adversarial examples can be used to simultaneously fool multiple networks, which is critical in systems that use network redundancy, such as those based on architectures with majority voting over multiple CNNs. An extensive set of experiments based on state-of-the-art CNNs trained on the Imagenet dataset is finally reported.
Spatio-Contextual Deep Network Based Multimodal Pedestrian Detection For Autonomous Driving
May 26, 2021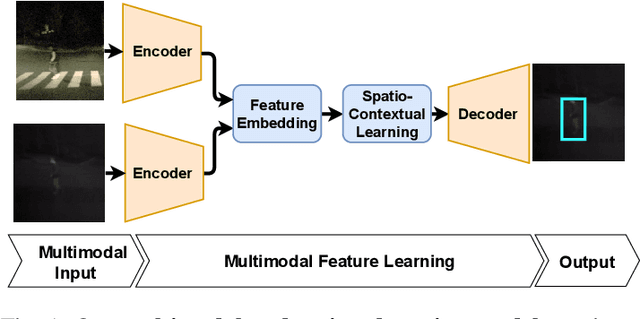
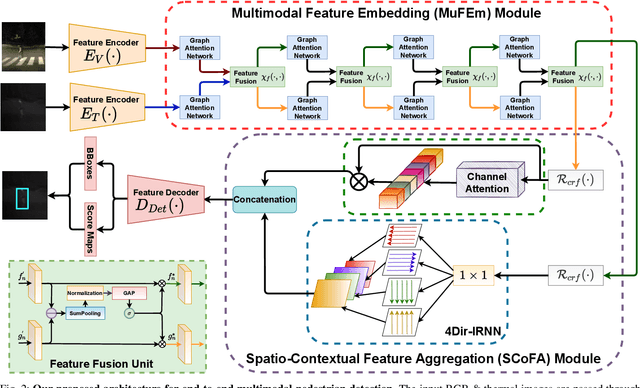


Pedestrian Detection is the most critical module of an Autonomous Driving system. Although a camera is commonly used for this purpose, its quality degrades severely in low-light night time driving scenarios. On the other hand, the quality of a thermal camera image remains unaffected in similar conditions. This paper proposes an end-to-end multimodal fusion model for pedestrian detection using RGB and thermal images. Its novel spatio-contextual deep network architecture is capable of exploiting the multimodal input efficiently. It consists of two distinct deformable ResNeXt-50 encoders for feature extraction from the two modalities. Fusion of these two encoded features takes place inside a multimodal feature embedding module (MuFEm) consisting of several groups of a pair of Graph Attention Network and a feature fusion unit. The output of the last feature fusion unit of MuFEm is subsequently passed to two CRFs for their spatial refinement. Further enhancement of the features is achieved by applying channel-wise attention and extraction of contextual information with the help of four RNNs traversing in four different directions. Finally, these feature maps are used by a single-stage decoder to generate the bounding box of each pedestrian and the score map. We have performed extensive experiments of the proposed framework on three publicly available multimodal pedestrian detection benchmark datasets, namely KAIST, CVC-14, and UTokyo. The results on each of them improved the respective state-of-the-art performance. A short video giving an overview of this work along with its qualitative results can be seen at https://youtu.be/FDJdSifuuCs.
Binary Constrained Deep Hashing Network for Image Retrieval without Manual Annotation
Aug 02, 2018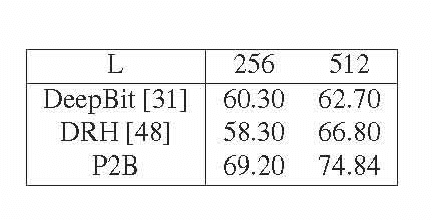
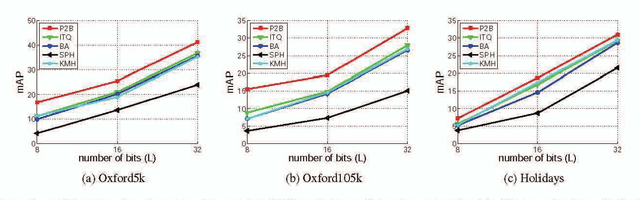
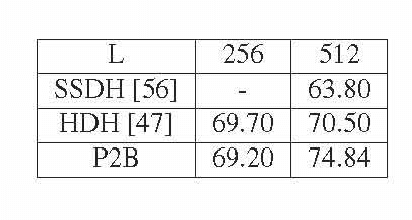
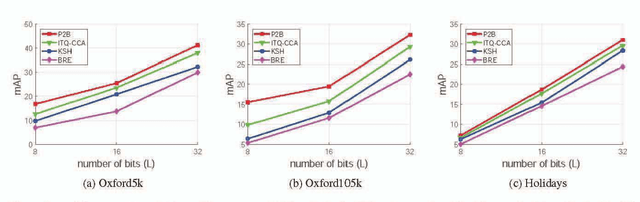
Learning compact binary codes for image retrieval problem using deep neural networks has attracted increasing attention recently. However, training deep hashing networks is challenging due to the binary constraints on the hash codes, the similarity preserving property, and the requirement for a vast amount of labelled images. To the best of our knowledge, none of the existing methods has tackled all of these challenges completely in a unified framework. In this work, we propose a novel end-to-end deep hashing approach, which is trained to produce binary codes directly from image pixels without the need of manual annotation. In particular, we propose a novel pairwise binary constrained loss function, which simultaneously encodes the distances between pairs of hash codes, and the binary quantization error. In order to train the network with the proposed loss function, we also propose an efficient parameter learning algorithm. In addition, to provide similar/dissimilar training images to train the network, we exploit 3D models reconstructed from unlabelled images for automatic generation of enormous similar/dissimilar pairs. Extensive experiments on three image retrieval benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art hashing methods on the image retrieval problem.
Automated Prostate Cancer Diagnosis Based on Gleason Grading Using Convolutional Neural Network
Nov 29, 2020
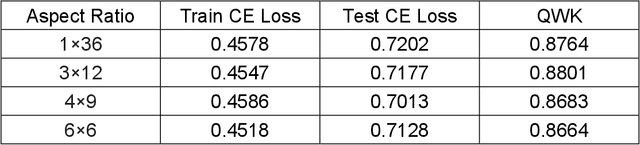
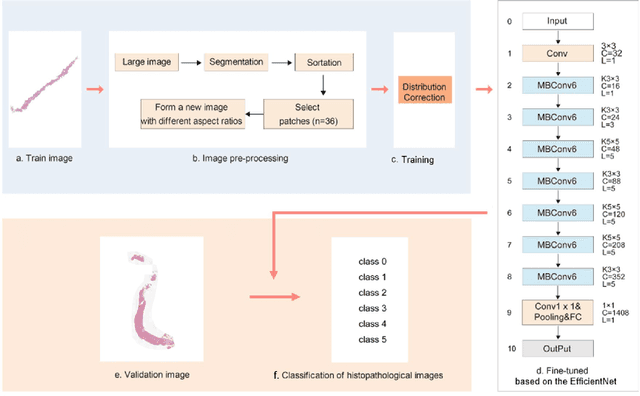
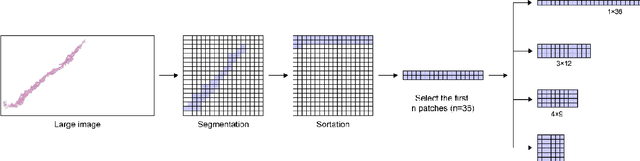
The Gleason grading system using histological images is the most powerful diagnostic and prognostic predictor of prostate cancer. The current standard inspection is evaluating Gleason H&E-stained histopathology images by pathologists. However, it is complicated, time-consuming, and subject to observers. Deep learning (DL) based-methods that automatically learn image features and achieve higher generalization ability have attracted significant attention. However, challenges remain especially using DL to train the whole slide image (WSI), a predominant clinical source in the current diagnostic setting, containing billions of pixels, morphological heterogeneity, and artifacts. Hence, we proposed a convolutional neural network (CNN)-based automatic classification method for accurate grading of PCa using whole slide histopathology images. In this paper, a data augmentation method named Patch-Based Image Reconstruction (PBIR) was proposed to reduce the high resolution and increase the diversity of WSIs. In addition, a distribution correction (DC) module was developed to enhance the adaption of pretrained model to the target dataset by adjusting the data distribution. Besides, a Quadratic Weighted Mean Square Error (QWMSE) function was presented to reduce the misdiagnosis caused by equal Euclidean distances. Our experiments indicated the combination of PBIR, DC, and QWMSE function was necessary for achieving superior expert-level performance, leading to the best results (0.8885 quadratic-weighted kappa coefficient).
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021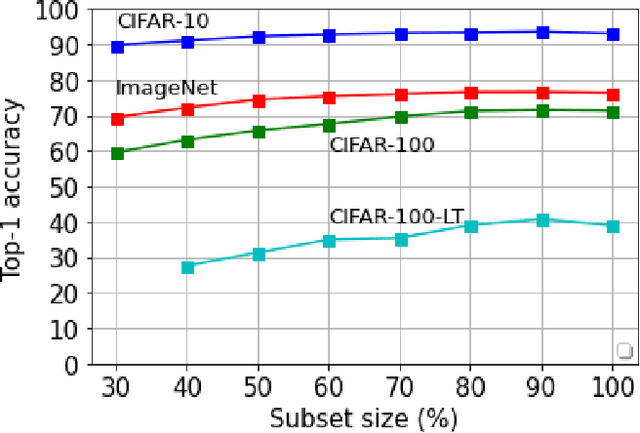
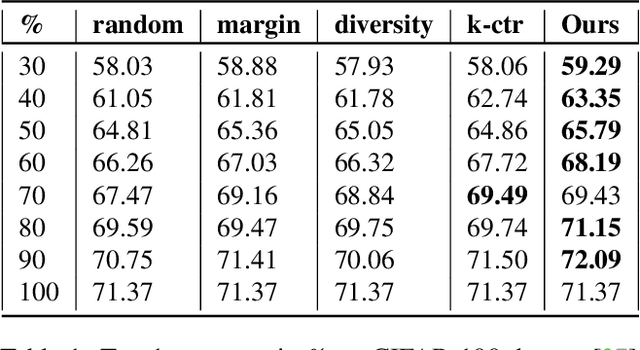
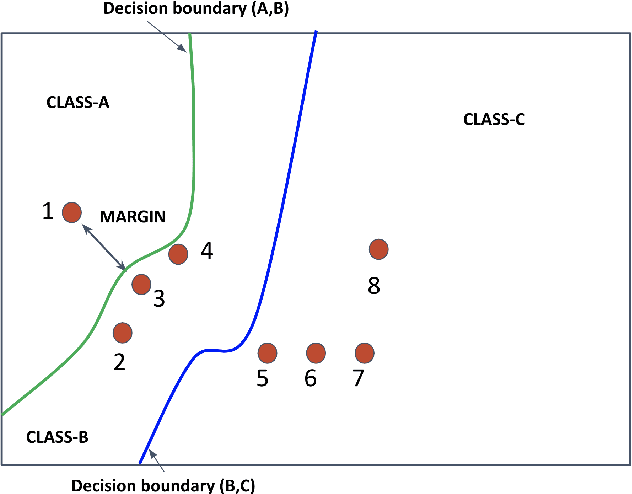
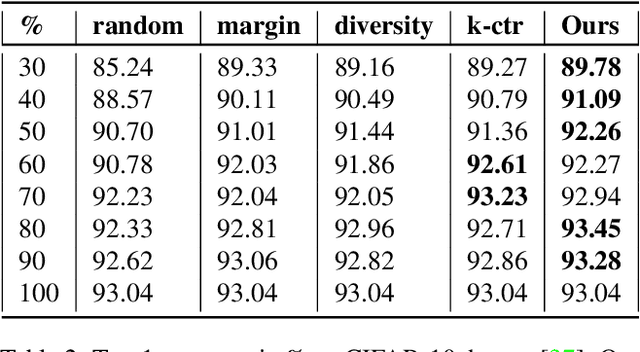
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
Learning Guided Electron Microscopy with Active Acquisition
Jan 07, 2021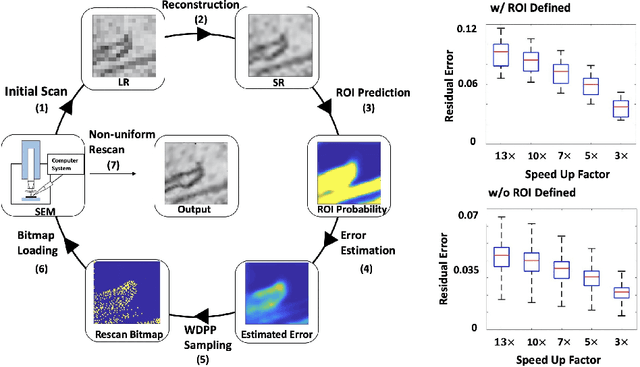
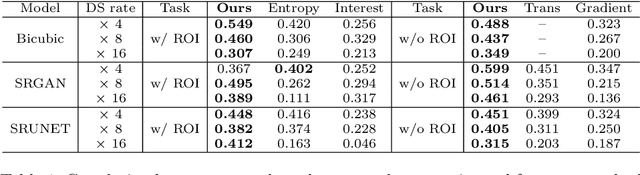
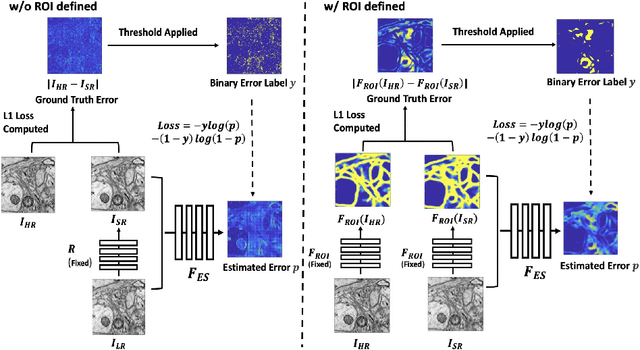
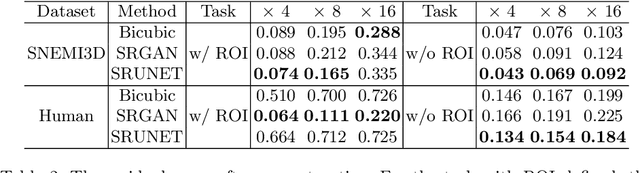
Single-beam scanning electron microscopes (SEM) are widely used to acquire massive data sets for biomedical study, material analysis, and fabrication inspection. Datasets are typically acquired with uniform acquisition: applying the electron beam with the same power and duration to all image pixels, even if there is great variety in the pixels' importance for eventual use. Many SEMs are now able to move the beam to any pixel in the field of view without delay, enabling them, in principle, to invest their time budget more effectively with non-uniform imaging. In this paper, we show how to use deep learning to accelerate and optimize single-beam SEM acquisition of images. Our algorithm rapidly collects an information-lossy image (e.g. low resolution) and then applies a novel learning method to identify a small subset of pixels to be collected at higher resolution based on a trade-off between the saliency and spatial diversity. We demonstrate the efficacy of this novel technique for active acquisition by speeding up the task of collecting connectomic datasets for neurobiology by up to an order of magnitude.