 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Super-Resolution with Deep Adaptive Image Resampling
Dec 18, 2017
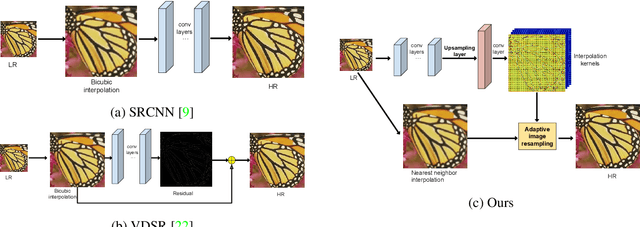

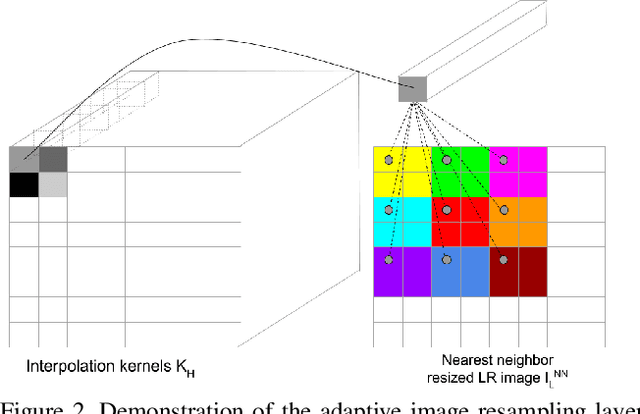
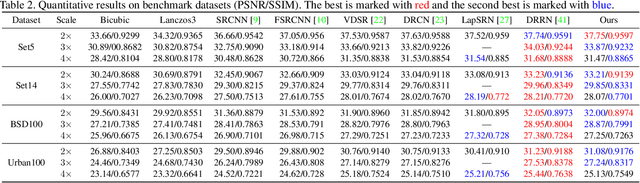
Deep learning based methods have recently pushed the state-of-the-art on the problem of Single Image Super-Resolution (SISR). In this work, we revisit the more traditional interpolation-based methods, that were popular before, now with the help of deep learning. In particular, we propose to use a Convolutional Neural Network (CNN) to estimate spatially variant interpolation kernels and apply the estimated kernels adaptively to each position in the image. The whole model is trained in an end-to-end manner. We explore two ways to improve the results for the case of large upscaling factors, and propose a recursive extension of our basic model. This achieves results that are on par with state-of-the-art methods. We visualize the estimated adaptive interpolation kernels to gain more insight on the effectiveness of the proposed method. We also extend the method to the task of joint image filtering and again achieve state-of-the-art performance.
Modeling Graph Node Correlations with Neighbor Mixture Models
Apr 18, 2021
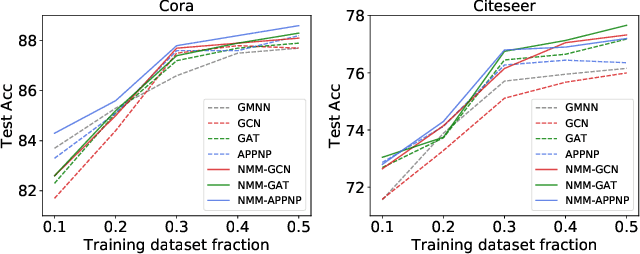
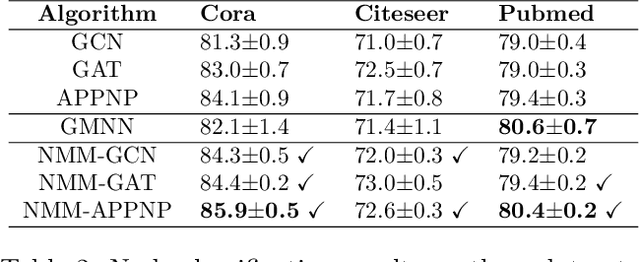
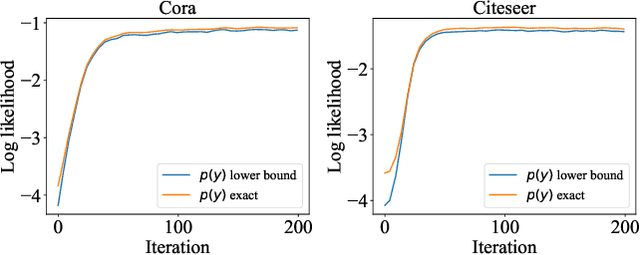
We propose a new model, the Neighbor Mixture Model (NMM), for modeling node labels in a graph. This model aims to capture correlations between the labels of nodes in a local neighborhood. We carefully design the model so it could be an alternative to a Markov Random Field but with more affordable computations. In particular, drawing samples and evaluating marginal probabilities of single labels can be done in linear time. To scale computations to large graphs, we devise a variational approximation without introducing extra parameters. We further use graph neural networks (GNNs) to parameterize the NMM, which reduces the number of learnable parameters while allowing expressive representation learning. The proposed model can be either fit directly to large observed graphs or used to enable scalable inference that preserves correlations for other distributions such as deep generative graph models. Across a diverse set of node classification, image denoising, and link prediction tasks, we show our proposed NMM advances the state-of-the-art in modeling real-world labeled graphs.
Improved Algorithms for Agnostic Pool-based Active Classification
May 13, 2021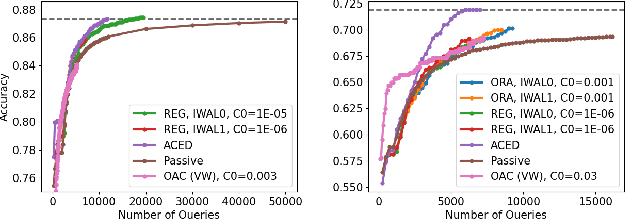

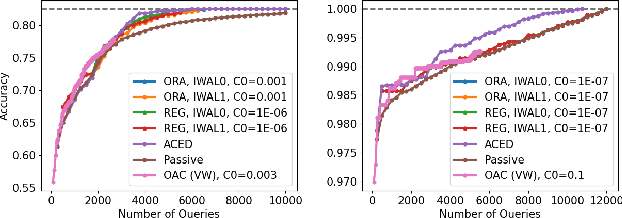
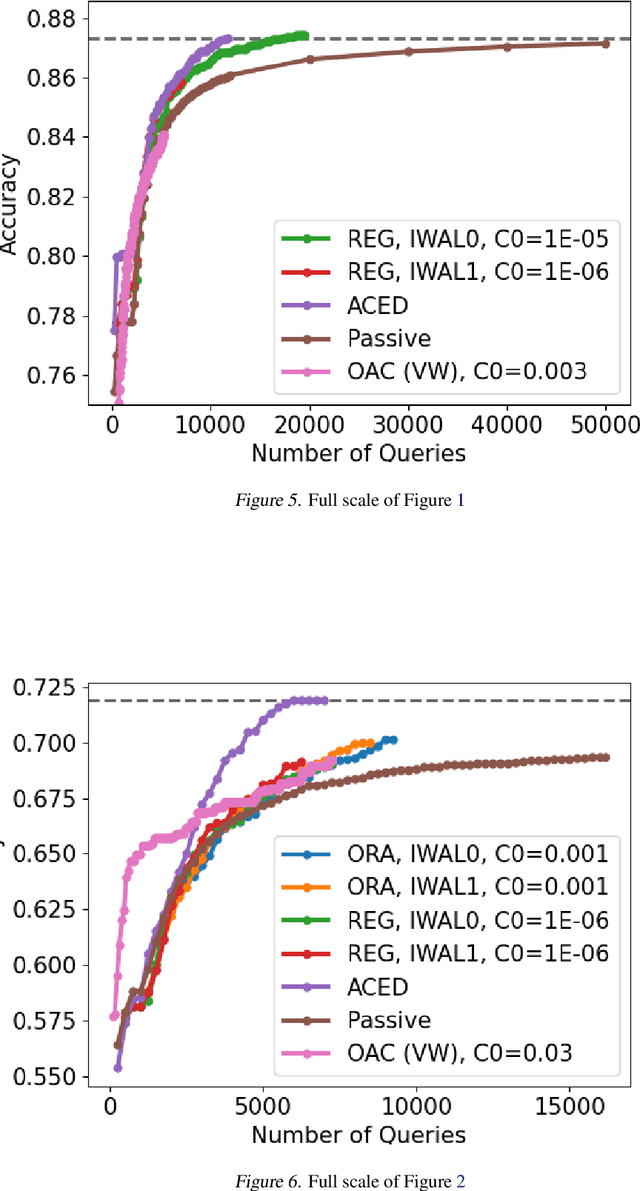
We consider active learning for binary classification in the agnostic pool-based setting. The vast majority of works in active learning in the agnostic setting are inspired by the CAL algorithm where each query is uniformly sampled from the disagreement region of the current version space. The sample complexity of such algorithms is described by a quantity known as the disagreement coefficient which captures both the geometry of the hypothesis space as well as the underlying probability space. To date, the disagreement coefficient has been justified by minimax lower bounds only, leaving the door open for superior instance dependent sample complexities. In this work we propose an algorithm that, in contrast to uniform sampling over the disagreement region, solves an experimental design problem to determine a distribution over examples from which to request labels. We show that the new approach achieves sample complexity bounds that are never worse than the best disagreement coefficient-based bounds, but in specific cases can be dramatically smaller. From a practical perspective, the proposed algorithm requires no hyperparameters to tune (e.g., to control the aggressiveness of sampling), and is computationally efficient by means of assuming access to an empirical risk minimization oracle (without any constraints). Empirically, we demonstrate that our algorithm is superior to state of the art agnostic active learning algorithms on image classification datasets.
3D-GMNet: Learning to Estimate 3D Shape from A Single Image As A Gaussian Mixture
Dec 10, 2019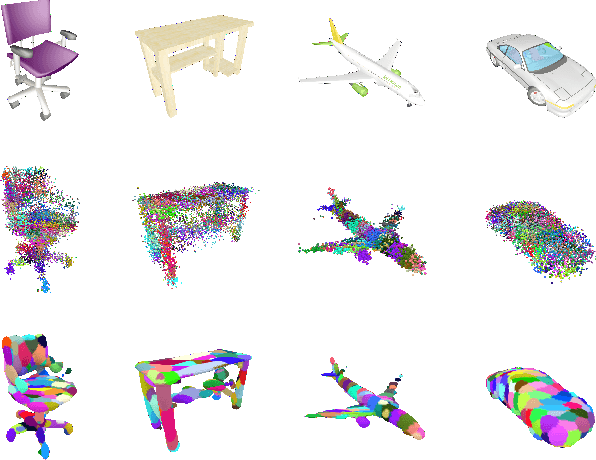

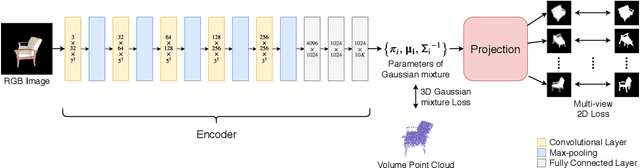

In this paper, we introduce 3D-GMNet, a deep neural network for single-image 3D shape recovery. As the name suggests, 3D-GMNet recovers 3D shape as a Gaussian mixture model. In contrast to voxels, point clouds, or meshes, a Gaussian mixture representation requires a much smaller footprint for representing 3D shapes and, at the same time, offers a number of additional advantages including instant pose estimation, automatic level-of-detail computation, and a distance measure. The proposed 3D-GMNet is trained end-to-end with single input images and corresponding 3D models by using two novel loss functions: a 3D Gaussian mixture loss and a multi-view 2D loss. The first maximizes the likelihood of the Gaussian mixture shape representation by considering the target point cloud as samples from the true distribution, and the latter improves the consistency between the input silhouette and the projection of the Gaussian mixture shape model. Extensive quantitative evaluations with synthesized and real images demonstrate the effectiveness of the proposed method.
A Cascaded Convolutional Neural Network for Single Image Dehazing
Mar 21, 2018
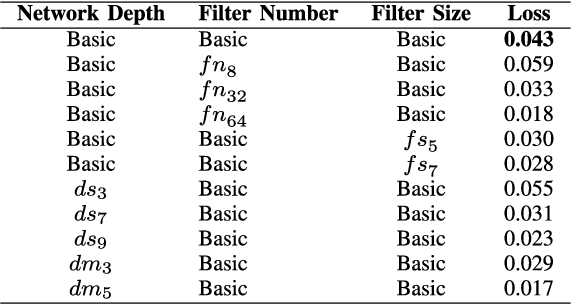
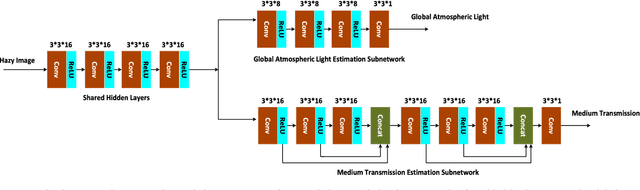
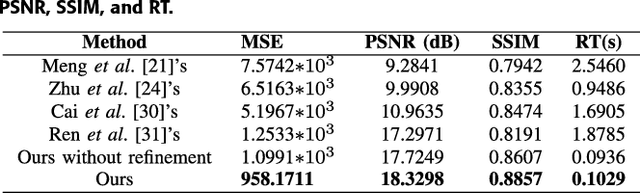
Images captured under outdoor scenes usually suffer from low contrast and limited visibility due to suspended atmospheric particles, which directly affects the quality of photos. Despite numerous image dehazing methods have been proposed, effective hazy image restoration remains a challenging problem. Existing learning-based methods usually predict the medium transmission by Convolutional Neural Networks (CNNs), but ignore the key global atmospheric light. Different from previous learning-based methods, we propose a flexible cascaded CNN for single hazy image restoration, which considers the medium transmission and global atmospheric light jointly by two task-driven subnetworks. Specifically, the medium transmission estimation subnetwork is inspired by the densely connected CNN while the global atmospheric light estimation subnetwork is a light-weight CNN. Besides, these two subnetworks are cascaded by sharing the common features. Finally, with the estimated model parameters, the haze-free image is obtained by the atmospheric scattering model inversion, which achieves more accurate and effective restoration performance. Qualitatively and quantitatively experimental results on the synthetic and real-world hazy images demonstrate that the proposed method effectively removes haze from such images, and outperforms several state-of-the-art dehazing methods.
Image Representations and New Domains in Neural Image Captioning
Aug 09, 2015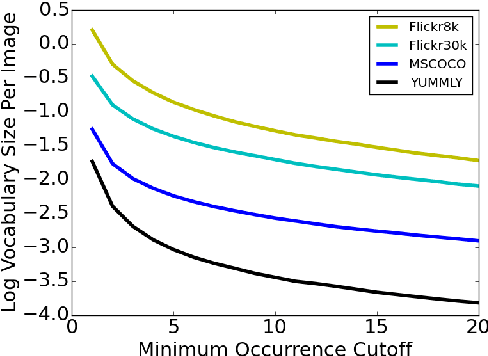
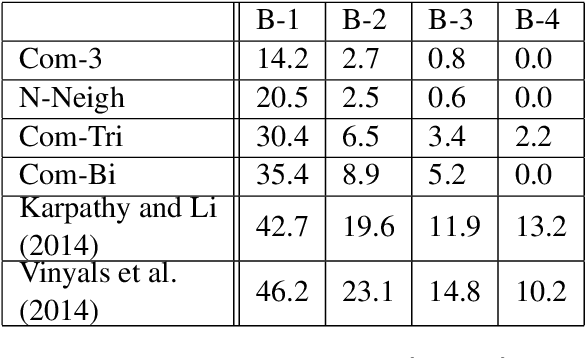
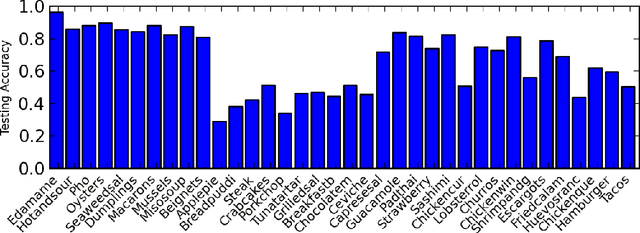
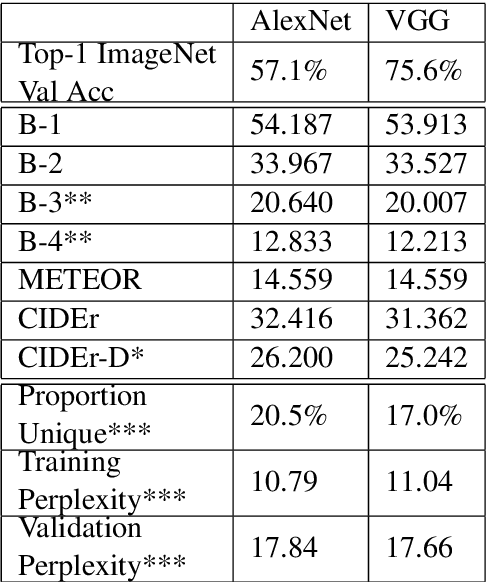
We examine the possibility that recent promising results in automatic caption generation are due primarily to language models. By varying image representation quality produced by a convolutional neural network, we find that a state-of-the-art neural captioning algorithm is able to produce quality captions even when provided with surprisingly poor image representations. We replicate this result in a new, fine-grained, transfer learned captioning domain, consisting of 66K recipe image/title pairs. We also provide some experiments regarding the appropriateness of datasets for automatic captioning, and find that having multiple captions per image is beneficial, but not an absolute requirement.
Invariant Deep Compressible Covariance Pooling for Aerial Scene Categorization
Nov 11, 2020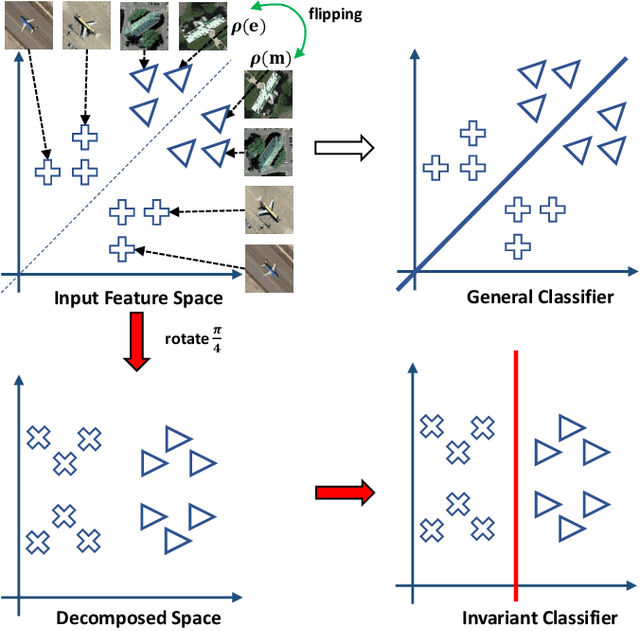
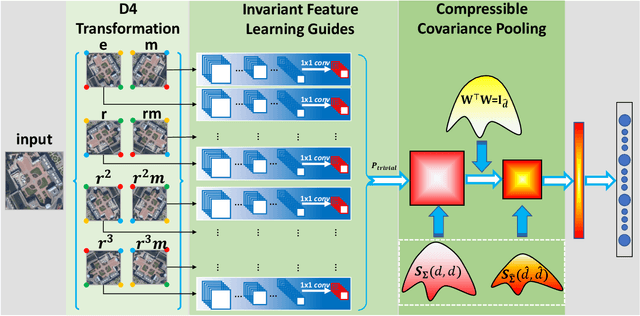
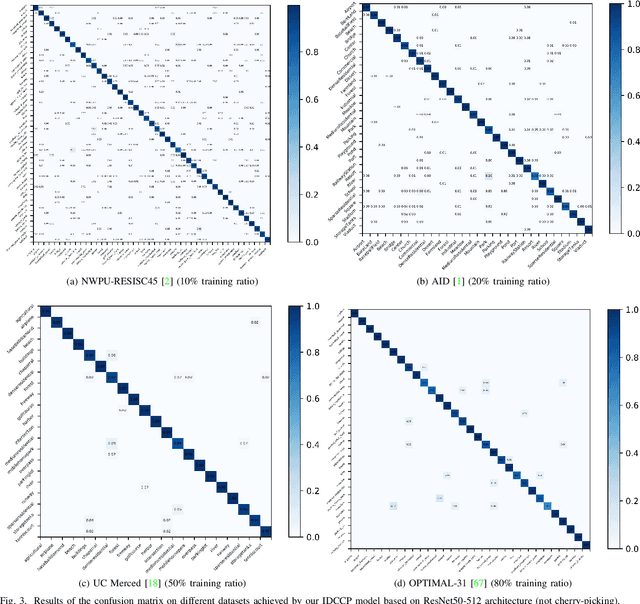
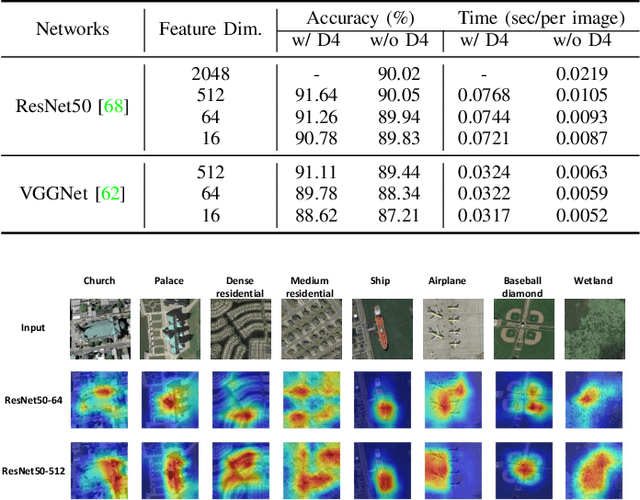
Learning discriminative and invariant feature representation is the key to visual image categorization. In this article, we propose a novel invariant deep compressible covariance pooling (IDCCP) to solve nuisance variations in aerial scene categorization. We consider transforming the input image according to a finite transformation group that consists of multiple confounding orthogonal matrices, such as the D4 group. Then, we adopt a Siamese-style network to transfer the group structure to the representation space, where we can derive a trivial representation that is invariant under the group action. The linear classifier trained with trivial representation will also be possessed with invariance. To further improve the discriminative power of representation, we extend the representation to the tensor space while imposing orthogonal constraints on the transformation matrix to effectively reduce feature dimensions. We conduct extensive experiments on the publicly released aerial scene image data sets and demonstrate the superiority of this method compared with state-of-the-art methods. In particular, with using ResNet architecture, our IDCCP model can reduce the dimension of the tensor representation by about 98% without sacrificing accuracy (i.e., <0.5%).
Spatial Context-Aware Self-Attention Model For Multi-Organ Segmentation
Dec 16, 2020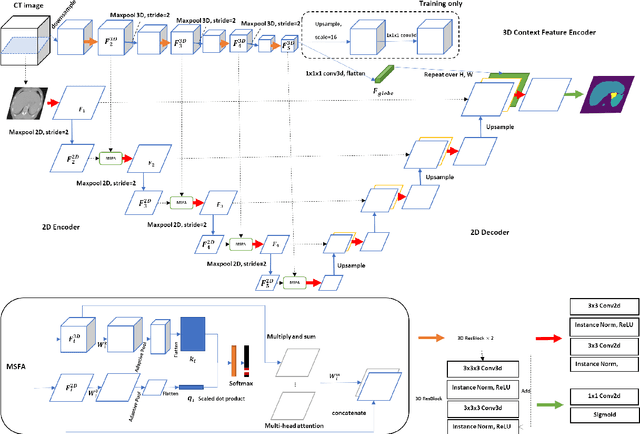

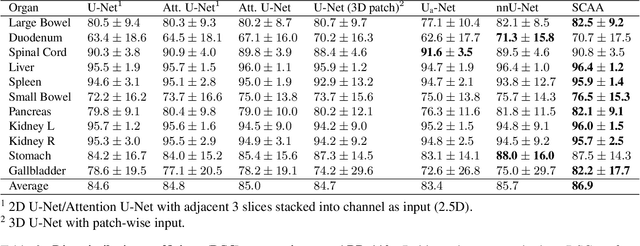
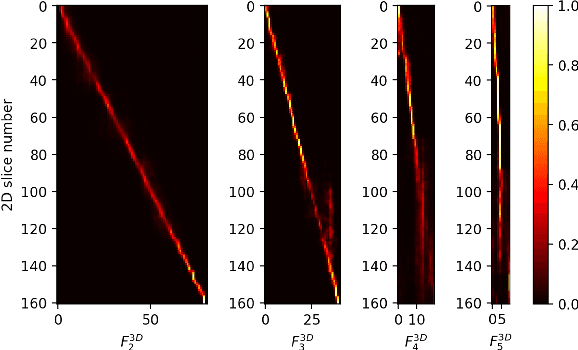
Multi-organ segmentation is one of most successful applications of deep learning in medical image analysis. Deep convolutional neural nets (CNNs) have shown great promise in achieving clinically applicable image segmentation performance on CT or MRI images. State-of-the-art CNN segmentation models apply either 2D or 3D convolutions on input images, with pros and cons associated with each method: 2D convolution is fast, less memory-intensive but inadequate for extracting 3D contextual information from volumetric images, while the opposite is true for 3D convolution. To fit a 3D CNN model on CT or MRI images on commodity GPUs, one usually has to either downsample input images or use cropped local regions as inputs, which limits the utility of 3D models for multi-organ segmentation. In this work, we propose a new framework for combining 3D and 2D models, in which the segmentation is realized through high-resolution 2D convolutions, but guided by spatial contextual information extracted from a low-resolution 3D model. We implement a self-attention mechanism to control which 3D features should be used to guide 2D segmentation. Our model is light on memory usage but fully equipped to take 3D contextual information into account. Experiments on multiple organ segmentation datasets demonstrate that by taking advantage of both 2D and 3D models, our method is consistently outperforms existing 2D and 3D models in organ segmentation accuracy, while being able to directly take raw whole-volume image data as inputs.
Improved Image Segmentation via Cost Minimization of Multiple Hypotheses
Jan 31, 2018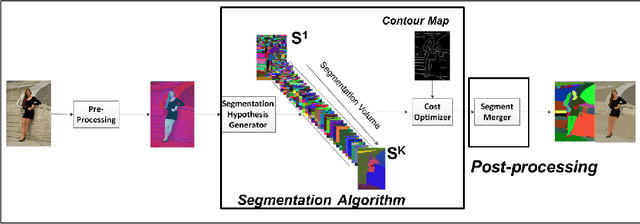
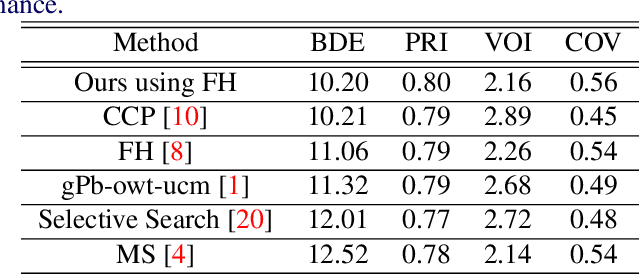
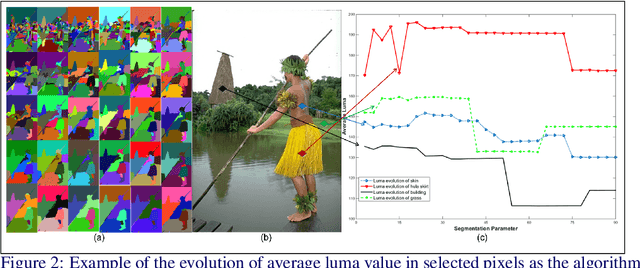
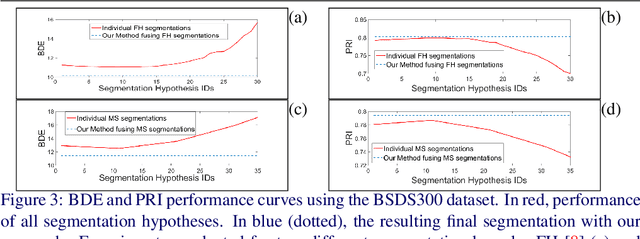
Image segmentation is an important component of many image understanding systems. It aims to group pixels in a spatially and perceptually coherent manner. Typically, these algorithms have a collection of parameters that control the degree of over-segmentation produced. It still remains a challenge to properly select such parameters for human-like perceptual grouping. In this work, we exploit the diversity of segments produced by different choices of parameters. We scan the segmentation parameter space and generate a collection of image segmentation hypotheses (from highly over-segmented to under-segmented). These are fed into a cost minimization framework that produces the final segmentation by selecting segments that: (1) better describe the natural contours of the image, and (2) are more stable and persistent among all the segmentation hypotheses. We compare our algorithm's performance with state-of-the-art algorithms, showing that we can achieve improved results. We also show that our framework is robust to the choice of segmentation kernel that produces the initial set of hypotheses.
Dual Directed Capsule Network for Very Low Resolution Image Recognition
Aug 27, 2019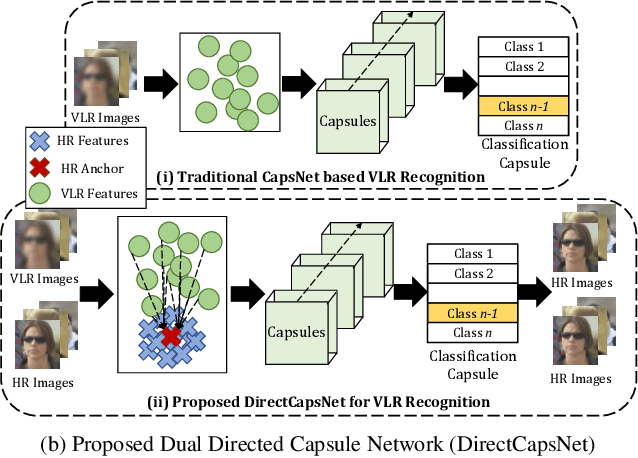
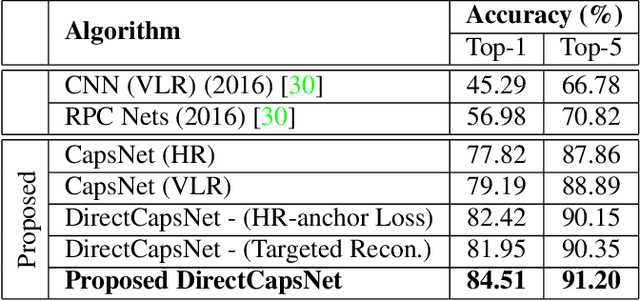

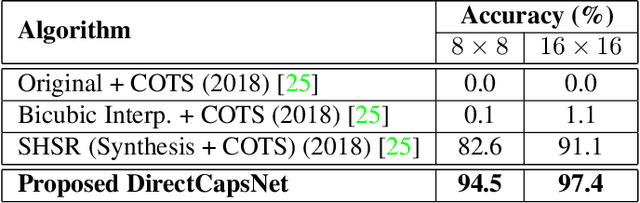
Very low resolution (VLR) image recognition corresponds to classifying images with resolution 16x16 or less. Though it has widespread applicability when objects are captured at a very large stand-off distance (e.g. surveillance scenario) or from wide angle mobile cameras, it has received limited attention. This research presents a novel Dual Directed Capsule Network model, termed as DirectCapsNet, for addressing VLR digit and face recognition. The proposed architecture utilizes a combination of capsule and convolutional layers for learning an effective VLR recognition model. The architecture also incorporates two novel loss functions: (i) the proposed HR-anchor loss and (ii) the proposed targeted reconstruction loss, in order to overcome the challenges of limited information content in VLR images. The proposed losses use high resolution images as auxiliary data during training to "direct" discriminative feature learning. Multiple experiments for VLR digit classification and VLR face recognition are performed along with comparisons with state-of-the-art algorithms. The proposed DirectCapsNet consistently showcases state-of-the-art results; for example, on the UCCS face database, it shows over 95\% face recognition accuracy when 16x16 images are matched with 80x80 images.