 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Color Quantization Optimization Approach for Image Representation Learning
Nov 23, 2017
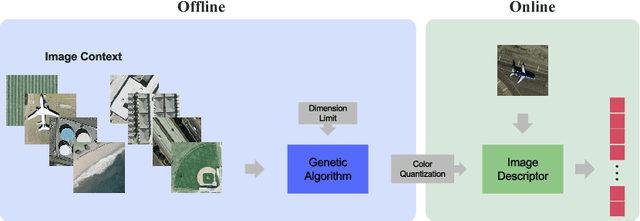
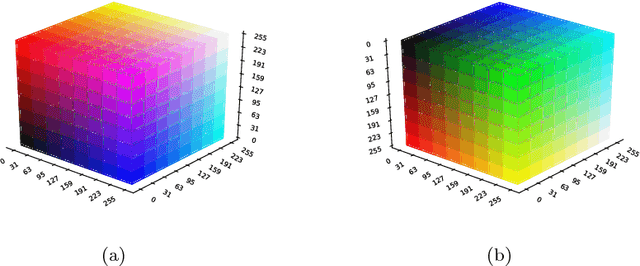

Over the last two decades, hand-crafted feature extractors have been used in order to compose image representations. Recently, data-driven feature learning have been explored as a way of producing more representative visual features. In this work, we proposed two approaches to learn image visual representations which aims at providing more effective and compact image representations. Our strategy employs Genetic Algorithms to improve hand-crafted feature extraction algorithms by optimizing colour quantization for the image domain. Our hypothesis is that changes in the quantization affect the description quality of the features enabling representation improvements. We conducted a series of experiments in order to evaluate the robustness of the proposed approaches in the task of content-based image retrieval in eight well-known datasets from different visual properties. Experimental results indicated that the approach focused on representation effectiveness outperformed the baselines in all the tested scenarios. The other approach, more focused on compactness, was able to produce competitive results by keeping or even reducing the final feature dimensionality until 25% smaller with statistically equivalent performance.
Single Stage Class Agnostic Common Object Detection: A Simple Baseline
Apr 25, 2021

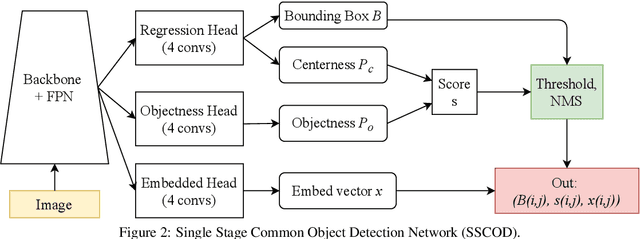
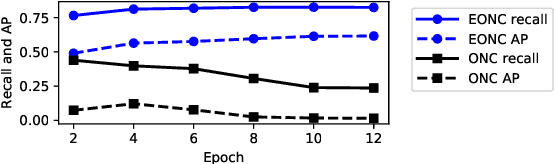
This paper addresses the problem of common object detection, which aims to detect objects of similar categories from a set of images. Although it shares some similarities with the standard object detection and co-segmentation, common object detection, recently promoted by \cite{Jiang2019a}, has some unique advantages and challenges. First, it is designed to work on both closed-set and open-set conditions, a.k.a. known and unknown objects. Second, it must be able to match objects of the same category but not restricted to the same instance, texture, or posture. Third, it can distinguish multiple objects. In this work, we introduce the Single Stage Common Object Detection (SSCOD) to detect class-agnostic common objects from an image set. The proposed method is built upon the standard single-stage object detector. Furthermore, an embedded branch is introduced to generate the object's representation feature, and their similarity is measured by cosine distance. Experiments are conducted on PASCAL VOC 2007 and COCO 2014 datasets. While being simple and flexible, our proposed SSCOD built upon ATSSNet performs significantly better than the baseline of the standard object detection, while still be able to match objects of unknown categories. Our source code can be found at \href{https://github.com/cybercore-co-ltd/Single-Stage-Common-Object-Detection}{(URL)}
Multimodal Learning for Hateful Memes Detection
Dec 06, 2020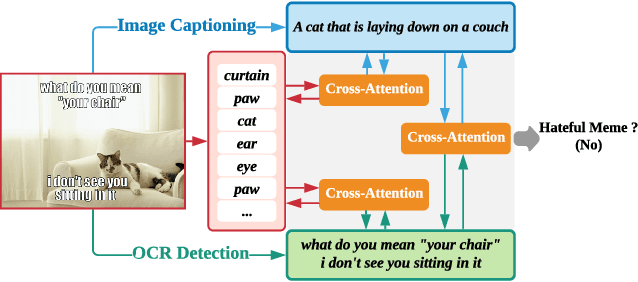
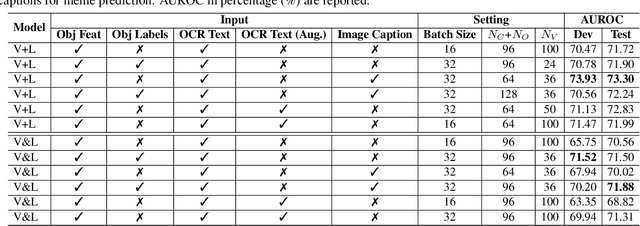
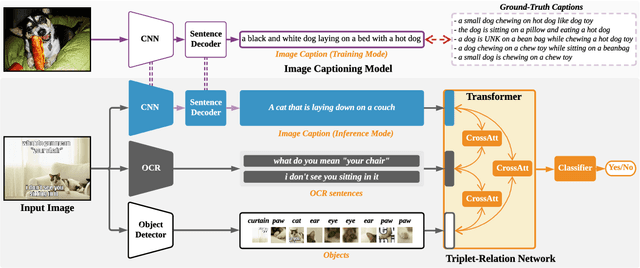

Memes are used for spreading ideas through social networks. Although most memes are created for humor, some memes become hateful under the combination of pictures and text. Automatically detecting the hateful memes can help reduce their harmful social impact. Unlike the conventional multimodal tasks, where the visual and textual information is semantically aligned, the challenge of hateful memes detection lies in its unique multimodal information. The image and text in memes are weakly aligned or even irrelevant, which requires the model to understand the content and perform reasoning over multiple modalities. In this paper, we focus on multimodal hateful memes detection and propose a novel method that incorporates the image captioning process into the memes detection process. We conduct extensive experiments on multimodal meme datasets and illustrated the effectiveness of our approach. Our model achieves promising results on the Hateful Memes Detection Challenge.
NVAE-GAN Based Approach for Unsupervised Time Series Anomaly Detection
Jan 08, 2021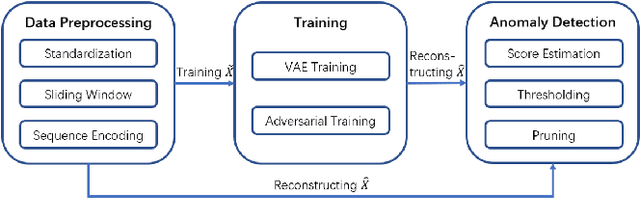

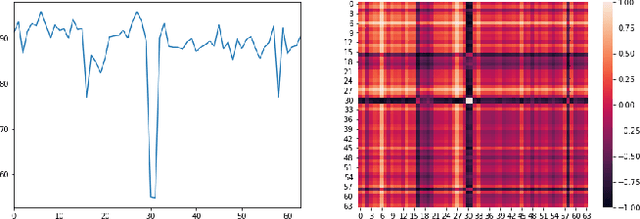

In recent studies, Lots of work has been done to solve time series anomaly detection by applying Variational Auto-Encoders (VAEs). Time series anomaly detection is a very common but challenging task in many industries, which plays an important role in network monitoring, facility maintenance, information security, and so on. However, it is very difficult to detect anomalies in time series with high accuracy, due to noisy data collected from real world, and complicated abnormal patterns. From recent studies, we are inspired by Nouveau VAE (NVAE) and propose our anomaly detection model: Time series to Image VAE (T2IVAE), an unsupervised model based on NVAE for univariate series, transforming 1D time series to 2D image as input, and adopting the reconstruction error to detect anomalies. Besides, we also apply the Generative Adversarial Networks based techniques to T2IVAE training strategy, aiming to reduce the overfitting. We evaluate our model performance on three datasets, and compare it with other several popular models using F1 score. T2IVAE achieves 0.639 on Numenta Anomaly Benchmark, 0.651 on public dataset from NASA, and 0.504 on our dataset collected from real-world scenario, outperforms other comparison models.
Memory Efficient Class-Incremental Learning for Image Classification
Aug 04, 2020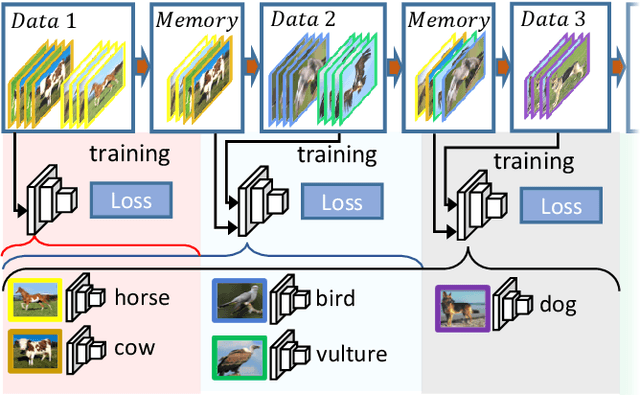
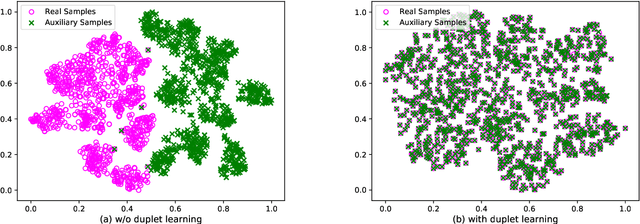
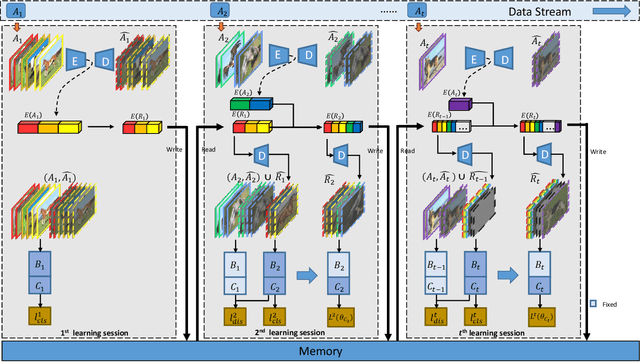

With the memory-resource-limited constraints, class-incremental learning (CIL) usually suffers from the "catastrophic forgetting" problem when updating the joint classification model on the arrival of newly added classes. To cope with the forgetting problem, many CIL methods transfer the knowledge of old classes by preserving some exemplar samples into the size-constrained memory buffer. To utilize the memory buffer more efficiently, we propose to keep more auxiliary low-fidelity exemplar samples rather than the original real high-fidelity exemplar samples. Such memory-efficient exemplar preserving scheme make the old-class knowledge transfer more effective. However, the low-fidelity exemplar samples are often distributed in a different domain away from that of the original exemplar samples, that is, a domain shift. To alleviate this problem, we propose a duplet learning scheme that seeks to construct domain-compatible feature extractors and classifiers, which greatly narrows down the above domain gap. As a result, these low-fidelity auxiliary exemplar samples have the ability to moderately replace the original exemplar samples with a lower memory cost. In addition, we present a robust classifier adaptation scheme, which further refines the biased classifier (learned with the samples containing distillation label knowledge about old classes) with the help of the samples of pure true class labels. Experimental results demonstrate the effectiveness of this work against the state-of-the-art approaches. We will release the code, baselines, and training statistics for all models to facilitate future research.
A new solution to the curved Ewald sphere problem for 3D image reconstruction in electron microscopy
Jan 04, 2021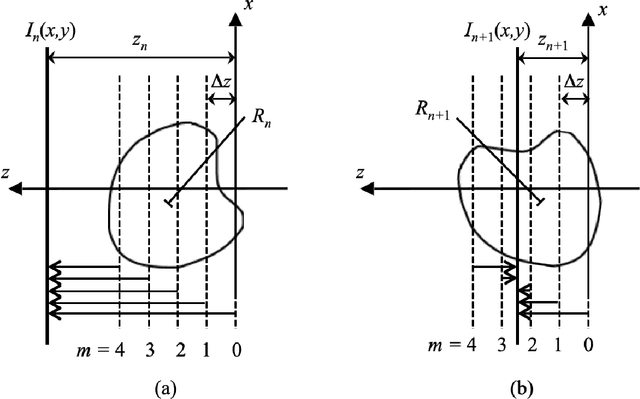
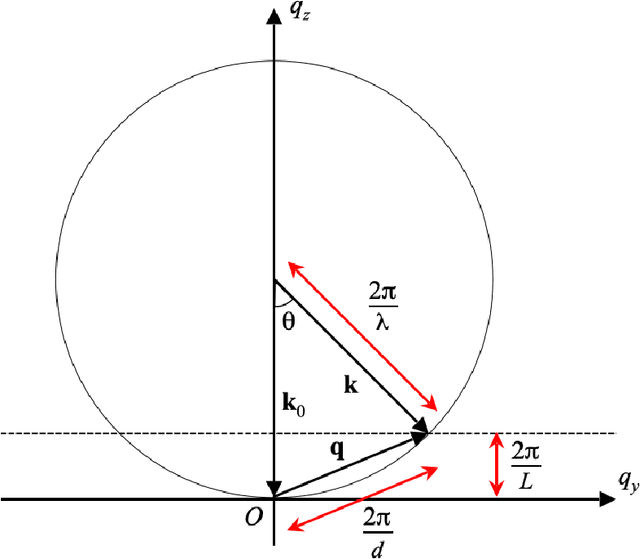
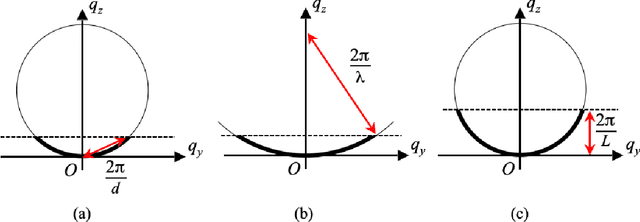
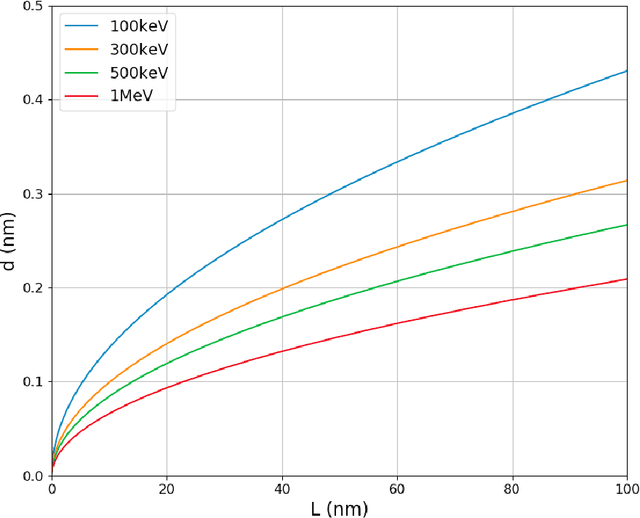
We develop an algorithm capable of reconstructing 3D images of an object given a collection of two-dimensional images that are significantly influenced by the curvature of the Ewald sphere. These 2D images are not projections. Such an algorithm is useful in cryo-electron microscopy where larger samples, higher resolution, or lower energy electron beams are desired.
Thickened 2D Networks for 3D Medical Image Segmentation
Apr 02, 2019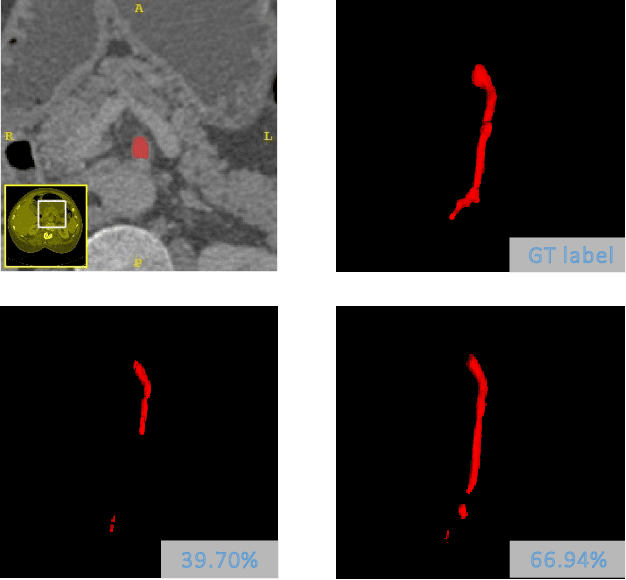
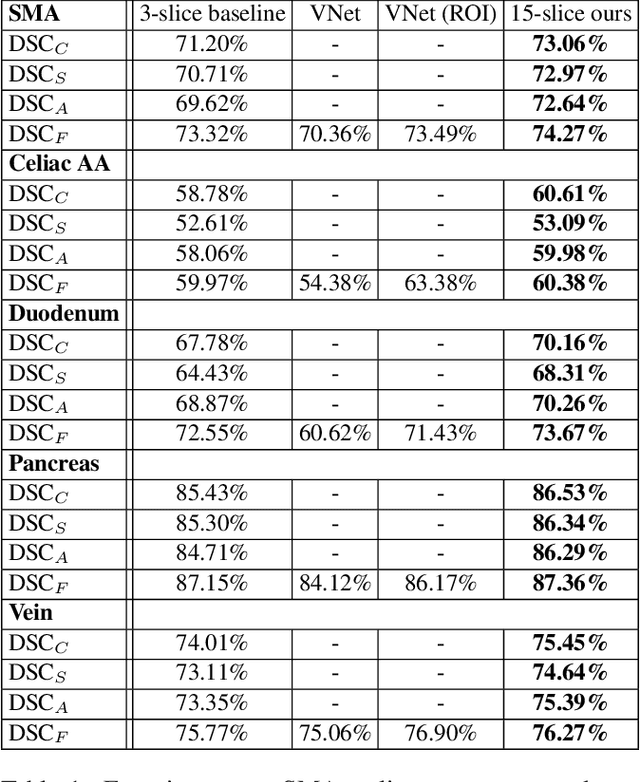
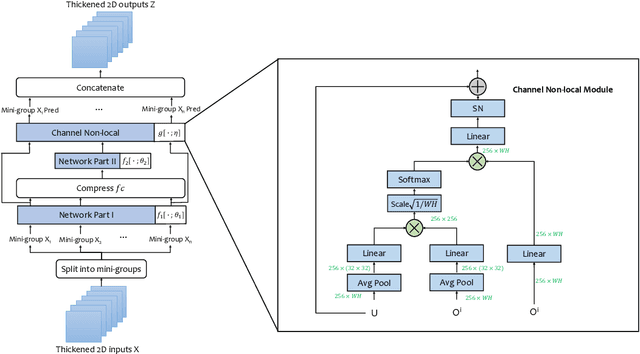
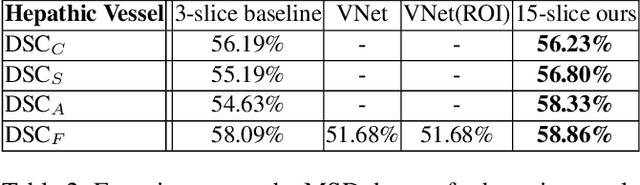
There has been a debate in medical image segmentation on whether to use 2D or 3D networks, where both pipelines have advantages and disadvantages. This paper presents a novel approach which thickens the input of a 2D network, so that the model is expected to enjoy both the stability and efficiency of 2D networks as well as the ability of 3D networks in modeling volumetric contexts. A major information loss happens when a large number of 2D slices are fused at the first convolutional layer, resulting in a relatively weak ability of the network in distinguishing the difference among slices. To alleviate this drawback, we propose an effective framework which (i) postpones slice fusion and (ii) adds highway connections from the pre-fusion layer so that the prediction layer receives slice-sensitive auxiliary cues. Experiments on segmenting a few abdominal targets in particular blood vessels which require strong 3D contexts demonstrate the effectiveness of our approach.
City-Scale Visual Place Recognition with Deep Local Features Based on Multi-Scale Ordered VLAD Pooling
Sep 19, 2020

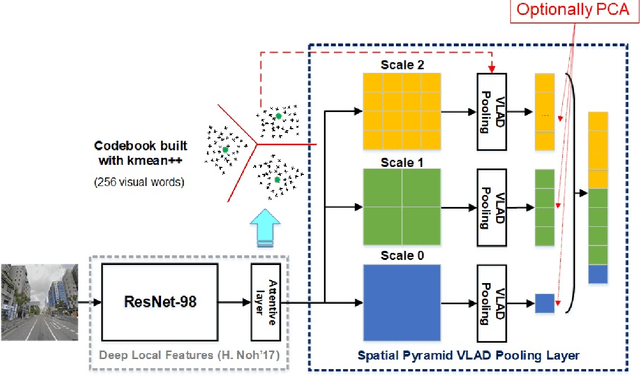
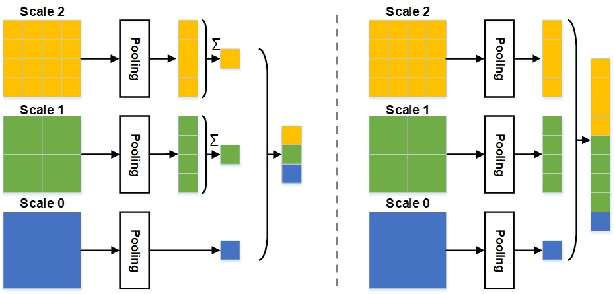
Visual place recognition is the task of recognizing a place depicted in an image based on its pure visual appearance without metadata. In visual place recognition, the challenges lie upon not only the changes in lighting conditions, camera viewpoint, and scale, but also the characteristic of scene level images and the distinct features of the area. To resolve these challenges, one must consider both the local discriminativeness and the global semantic context of images. On the other hand, the diversity of the datasets is also particularly important to develop more general models and advance the progress of the field. In this paper, we present a fully-automated system for place recognition at a city-scale based on content-based image retrieval. Our main contributions to the community lie in three aspects. Firstly, we take a comprehensive analysis of visual place recognition and sketch out the unique challenges of the task compared to general image retrieval tasks. Next, we propose yet a simple pooling approach on top of convolutional neural network activations to embed the spatial information into the image representation vector. Finally, we introduce new datasets for place recognition, which are particularly essential for application-based research. Furthermore, throughout extensive experiments, various issues in both image retrieval and place recognition are analyzed and discussed to give some insights for improving the performance of retrieval models in reality.
Leveraging Local and Global Descriptors in Parallel to Search Correspondences for Visual Localization
Sep 23, 2020
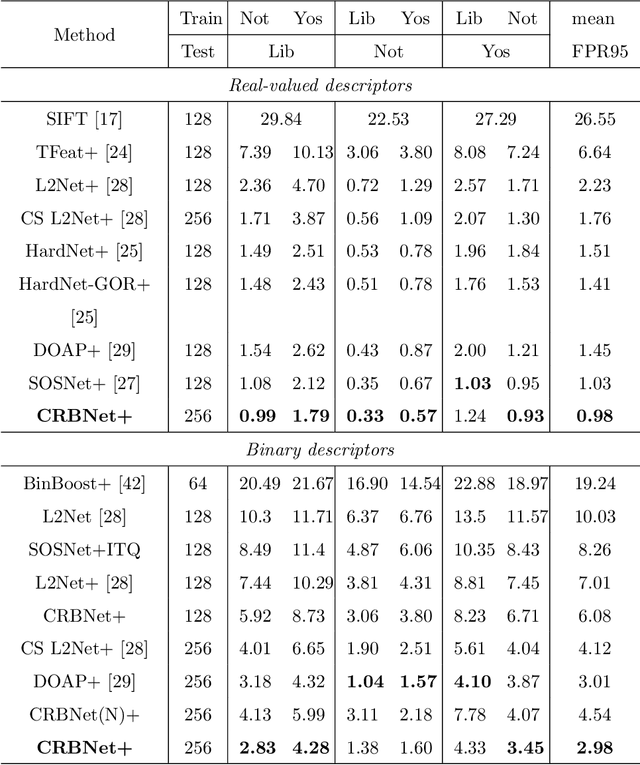
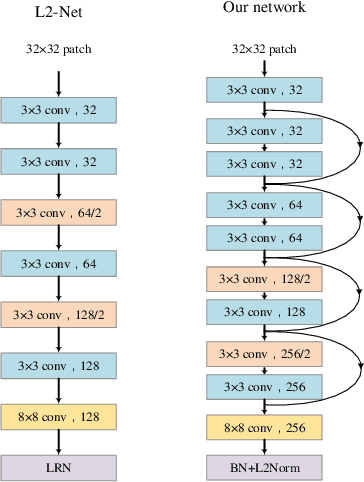
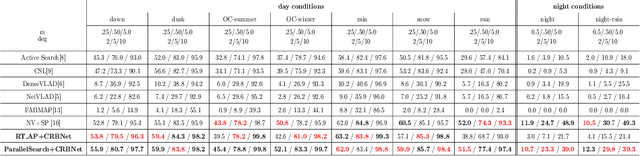
Visual localization to compute 6DoF camera pose from a given image has wide applications such as in robotics, virtual reality, augmented reality, etc. Two kinds of descriptors are important for the visual localization. One is global descriptors that extract the whole feature from each image. The other is local descriptors that extract the local feature from each image patch usually enclosing a key point. More and more methods of the visual localization have two stages: at first to perform image retrieval by global descriptors and then from the retrieval feedback to make 2D-3D point correspondences by local descriptors. The two stages are in serial for most of the methods. This simple combination has not achieved superiority of fusing local and global descriptors. The 3D points obtained from the retrieval feedback are as the nearest neighbor candidates of the 2D image points only by global descriptors. Each of the 2D image points is also called a query local feature when performing the 2D-3D point correspondences. In this paper, we propose a novel parallel search framework, which leverages advantages of both local and global descriptors to get nearest neighbor candidates of a query local feature. Specifically, besides using deep learning based global descriptors, we also utilize local descriptors to construct random tree structures for obtaining nearest neighbor candidates of the query local feature. We propose a new probabilistic model and a new deep learning based local descriptor when constructing the random trees. A weighted Hamming regularization term to keep discriminativeness after binarization is given in the loss function for the proposed local descriptor. The loss function co-trains both real and binary descriptors of which the results are integrated into the random trees.
Multimodal Personal Ear Authentication Using Smartphones
Mar 23, 2021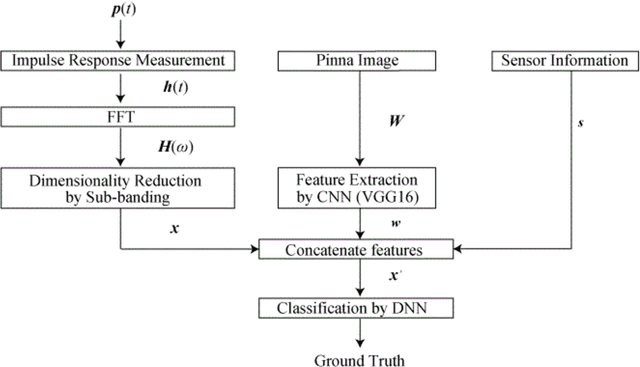


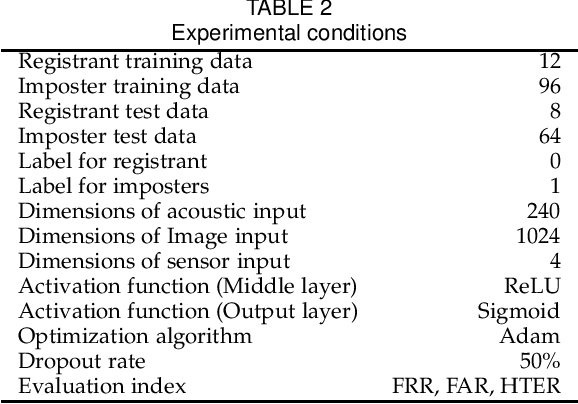
In recent years, biometric authentication technology for smartphones has become widespread, with the mainstream methods being fingerprint authentication and face recognition. However, fingerprint authentication cannot be used when hands are wet, and face recognition cannot be used when a person is wearing a mask. Therefore, we examine a personal authentication system using the pinna as a new approach for biometric authentication on smartphones. Authentication systems based on the acoustic transfer function of the pinna (PRTF: Pinna Related Transfer Function) have been investigated. However, the authentication accuracy decreases due to the positional fluctuation across each measurement. In this paper, we propose multimodal personal authentication on smartphones using PRTF. The pinna image and positional sensor information are used with the PRTF, and the effectiveness of the authentication method is examined. We demonstrate that the proposed authentication system can compensate for the positional changes in each measurement and improve robustness.