 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
Mar 29, 2021
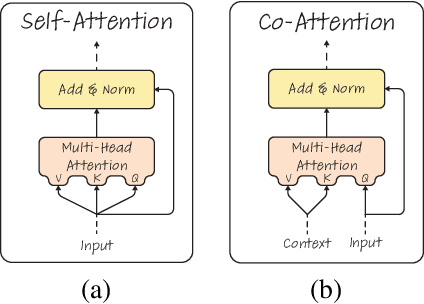
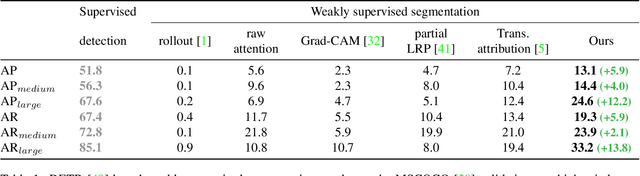
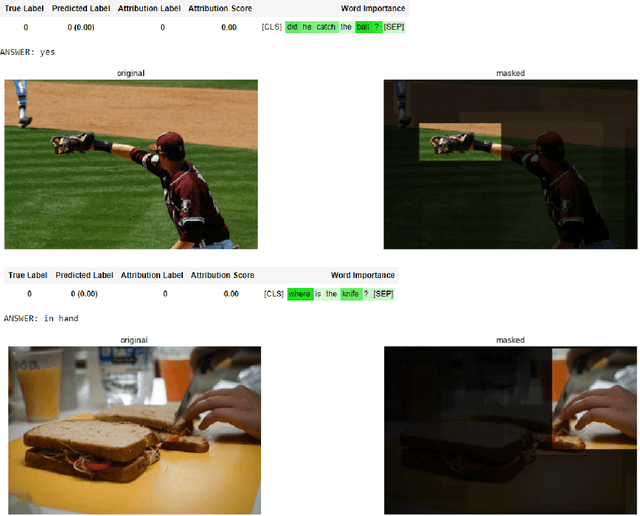
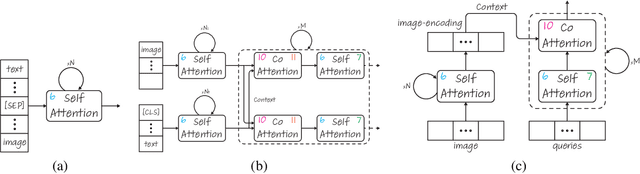
Transformers are increasingly dominating multi-modal reasoning tasks, such as visual question answering, achieving state-of-the-art results thanks to their ability to contextualize information using the self-attention and co-attention mechanisms. These attention modules also play a role in other computer vision tasks including object detection and image segmentation. Unlike Transformers that only use self-attention, Transformers with co-attention require to consider multiple attention maps in parallel in order to highlight the information that is relevant to the prediction in the model's input. In this work, we propose the first method to explain prediction by any Transformer-based architecture, including bi-modal Transformers and Transformers with co-attentions. We provide generic solutions and apply these to the three most commonly used of these architectures: (i) pure self-attention, (ii) self-attention combined with co-attention, and (iii) encoder-decoder attention. We show that our method is superior to all existing methods which are adapted from single modality explainability.
Multimodal Learning for Hateful Memes Detection
Dec 06, 2020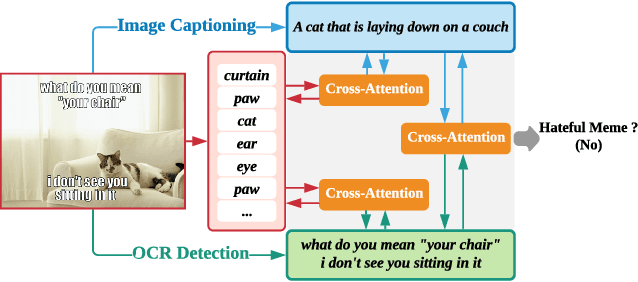
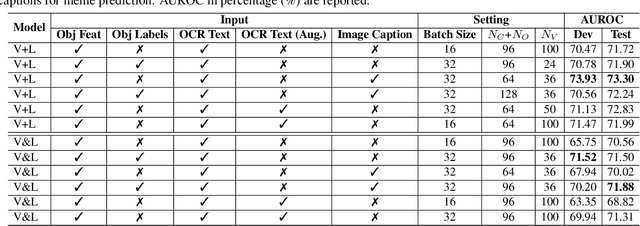
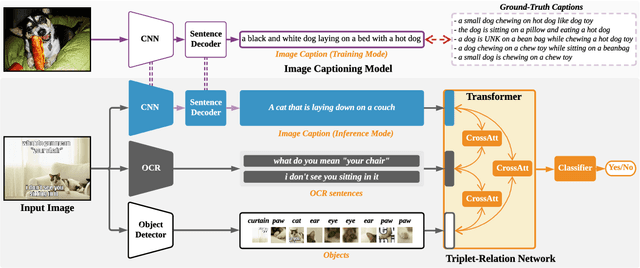

Memes are used for spreading ideas through social networks. Although most memes are created for humor, some memes become hateful under the combination of pictures and text. Automatically detecting the hateful memes can help reduce their harmful social impact. Unlike the conventional multimodal tasks, where the visual and textual information is semantically aligned, the challenge of hateful memes detection lies in its unique multimodal information. The image and text in memes are weakly aligned or even irrelevant, which requires the model to understand the content and perform reasoning over multiple modalities. In this paper, we focus on multimodal hateful memes detection and propose a novel method that incorporates the image captioning process into the memes detection process. We conduct extensive experiments on multimodal meme datasets and illustrated the effectiveness of our approach. Our model achieves promising results on the Hateful Memes Detection Challenge.
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Sep 28, 2018
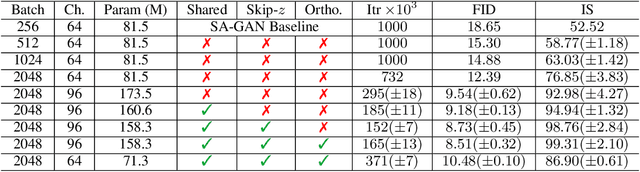


Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale. We find that applying orthogonal regularization to the generator renders it amenable to a simple "truncation trick", allowing fine control over the trade-off between sample fidelity and variety by truncating the latent space. Our modifications lead to models which set the new state of the art in class-conditional image synthesis. When trained on ImageNet at 128x128 resolution, our models (BigGANs) achieve an Inception Score (IS) of 166.3 and Frechet Inception Distance (FID) of 9.6, improving over the previous best IS of 52.52 and FID of 18.65.
SMD-Nets: Stereo Mixture Density Networks
Apr 08, 2021
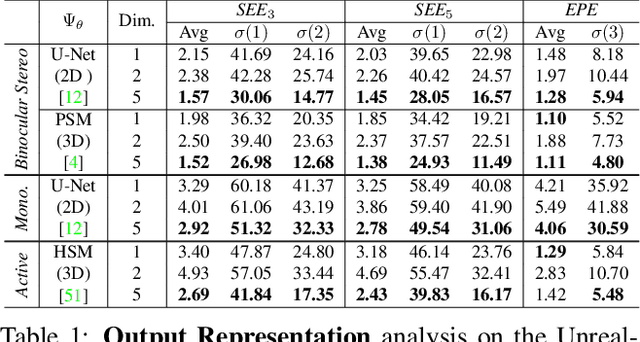
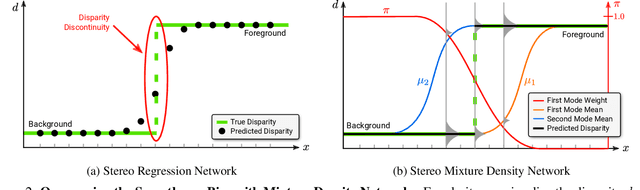
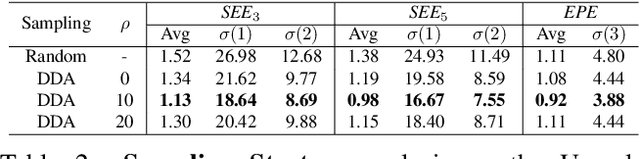
Despite stereo matching accuracy has greatly improved by deep learning in the last few years, recovering sharp boundaries and high-resolution outputs efficiently remains challenging. In this paper, we propose Stereo Mixture Density Networks (SMD-Nets), a simple yet effective learning framework compatible with a wide class of 2D and 3D architectures which ameliorates both issues. Specifically, we exploit bimodal mixture densities as output representation and show that this allows for sharp and precise disparity estimates near discontinuities while explicitly modeling the aleatoric uncertainty inherent in the observations. Moreover, we formulate disparity estimation as a continuous problem in the image domain, allowing our model to query disparities at arbitrary spatial precision. We carry out comprehensive experiments on a new high-resolution and highly realistic synthetic stereo dataset, consisting of stereo pairs at 8Mpx resolution, as well as on real-world stereo datasets. Our experiments demonstrate increased depth accuracy near object boundaries and prediction of ultra high-resolution disparity maps on standard GPUs. We demonstrate the flexibility of our technique by improving the performance of a variety of stereo backbones.
Offline Reinforcement Learning from Images with Latent Space Models
Dec 21, 2020
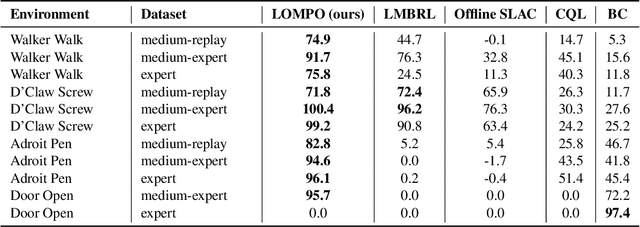
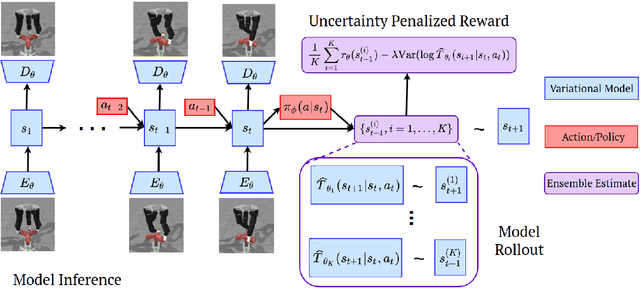
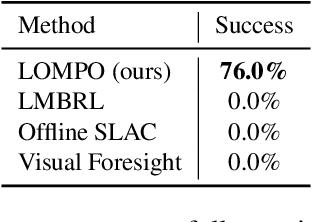
Offline reinforcement learning (RL) refers to the problem of learning policies from a static dataset of environment interactions. Offline RL enables extensive use and re-use of historical datasets, while also alleviating safety concerns associated with online exploration, thereby expanding the real-world applicability of RL. Most prior work in offline RL has focused on tasks with compact state representations. However, the ability to learn directly from rich observation spaces like images is critical for real-world applications such as robotics. In this work, we build on recent advances in model-based algorithms for offline RL, and extend them to high-dimensional visual observation spaces. Model-based offline RL algorithms have achieved state of the art results in state based tasks and have strong theoretical guarantees. However, they rely crucially on the ability to quantify uncertainty in the model predictions, which is particularly challenging with image observations. To overcome this challenge, we propose to learn a latent-state dynamics model, and represent the uncertainty in the latent space. Our approach is both tractable in practice and corresponds to maximizing a lower bound of the ELBO in the unknown POMDP. In experiments on a range of challenging image-based locomotion and manipulation tasks, we find that our algorithm significantly outperforms previous offline model-free RL methods as well as state-of-the-art online visual model-based RL methods. Moreover, we also find that our approach excels on an image-based drawer closing task on a real robot using a pre-existing dataset. All results including videos can be found online at https://sites.google.com/view/lompo/ .
Learning to Guide Local Feature Matches
Oct 21, 2020
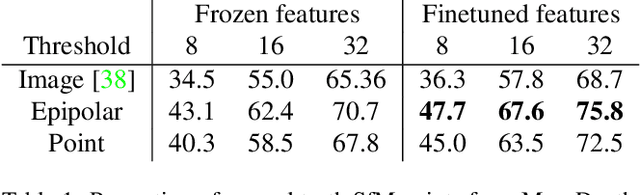
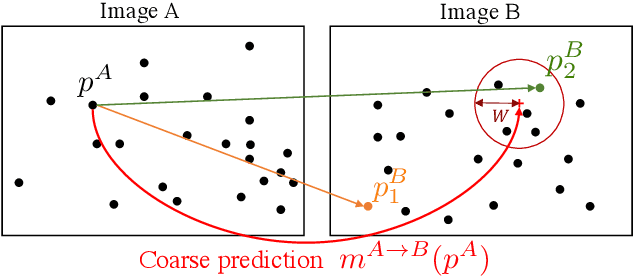
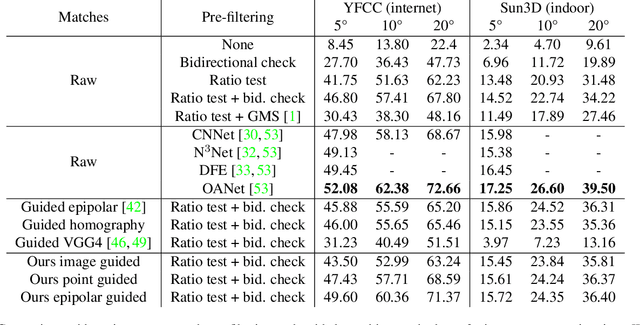
We tackle the problem of finding accurate and robust keypoint correspondences between images. We propose a learning-based approach to guide local feature matches via a learned approximate image matching. Our approach can boost the results of SIFT to a level similar to state-of-the-art deep descriptors, such as Superpoint, ContextDesc, or D2-Net and can improve performance for these descriptors. We introduce and study different levels of supervision to learn coarse correspondences. In particular, we show that weak supervision from epipolar geometry leads to performances higher than the stronger but more biased point level supervision and is a clear improvement over weak image level supervision. We demonstrate the benefits of our approach in a variety of conditions by evaluating our guided keypoint correspondences for localization of internet images on the YFCC100M dataset and indoor images on theSUN3D dataset, for robust localization on the Aachen day-night benchmark and for 3D reconstruction in challenging conditions using the LTLL historical image data.
A Color Quantization Optimization Approach for Image Representation Learning
Nov 23, 2017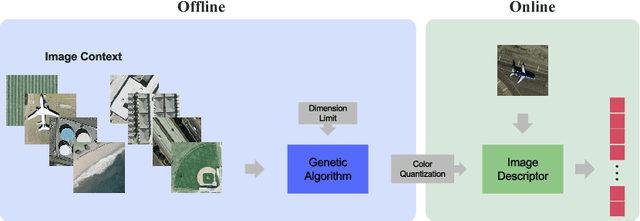
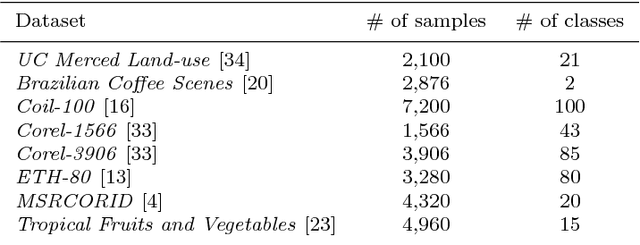

Over the last two decades, hand-crafted feature extractors have been used in order to compose image representations. Recently, data-driven feature learning have been explored as a way of producing more representative visual features. In this work, we proposed two approaches to learn image visual representations which aims at providing more effective and compact image representations. Our strategy employs Genetic Algorithms to improve hand-crafted feature extraction algorithms by optimizing colour quantization for the image domain. Our hypothesis is that changes in the quantization affect the description quality of the features enabling representation improvements. We conducted a series of experiments in order to evaluate the robustness of the proposed approaches in the task of content-based image retrieval in eight well-known datasets from different visual properties. Experimental results indicated that the approach focused on representation effectiveness outperformed the baselines in all the tested scenarios. The other approach, more focused on compactness, was able to produce competitive results by keeping or even reducing the final feature dimensionality until 25% smaller with statistically equivalent performance.
Deep learning to estimate the physical proportion of infected region of lung for COVID-19 pneumonia with CT image set
Jun 09, 2020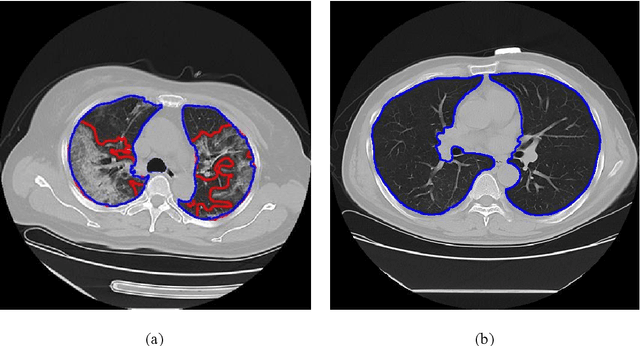
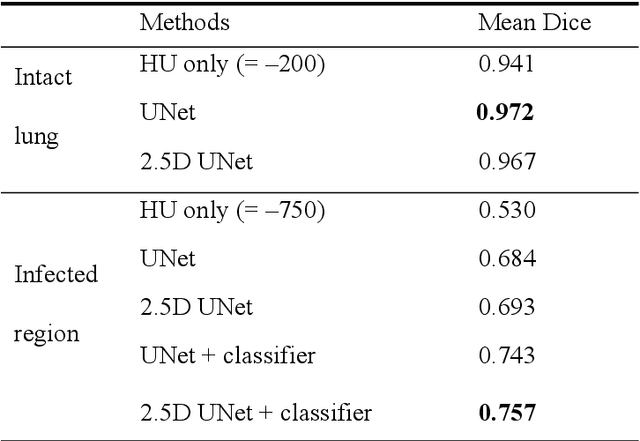
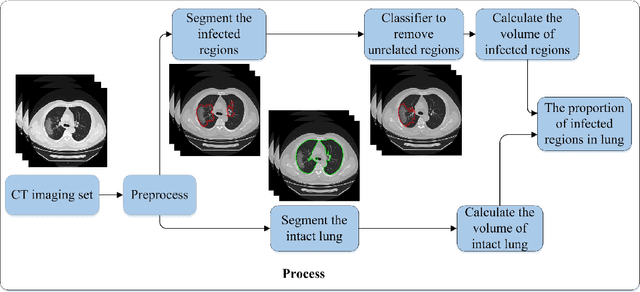
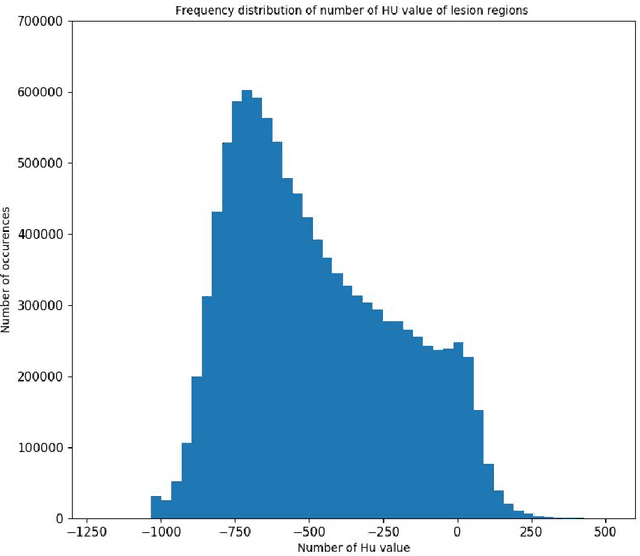
Utilizing computed tomography (CT) images to quickly estimate the severity of cases with COVID-19 is one of the most straightforward and efficacious methods. Two tasks were studied in this present paper. One was to segment the mask of intact lung in case of pneumonia. Another was to generate the masks of regions infected by COVID-19. The masks of these two parts of images then were converted to corresponding volumes to calculate the physical proportion of infected region of lung. A total of 129 CT image set were herein collected and studied. The intrinsic Hounsfiled value of CT images was firstly utilized to generate the initial dirty version of labeled masks both for intact lung and infected regions. Then, the samples were carefully adjusted and improved by two professional radiologists to generate the final training set and test benchmark. Two deep learning models were evaluated: UNet and 2.5D UNet. For the segment of infected regions, a deep learning based classifier was followed to remove unrelated blur-edged regions that were wrongly segmented out such as air tube and blood vessel tissue etc. For the segmented masks of intact lung and infected regions, the best method could achieve 0.972 and 0.757 measure in mean Dice similarity coefficient on our test benchmark. As the overall proportion of infected region of lung, the final result showed 0.961 (Pearson's correlation coefficient) and 11.7% (mean absolute percent error). The instant proportion of infected regions of lung could be used as a visual evidence to assist clinical physician to determine the severity of the case. Furthermore, a quantified report of infected regions can help predict the prognosis for COVID-19 cases which were scanned periodically within the treatment cycle.
Convolutional Neural Network for Blur Images Detection as an Alternative for Laplacian Method
Oct 15, 2020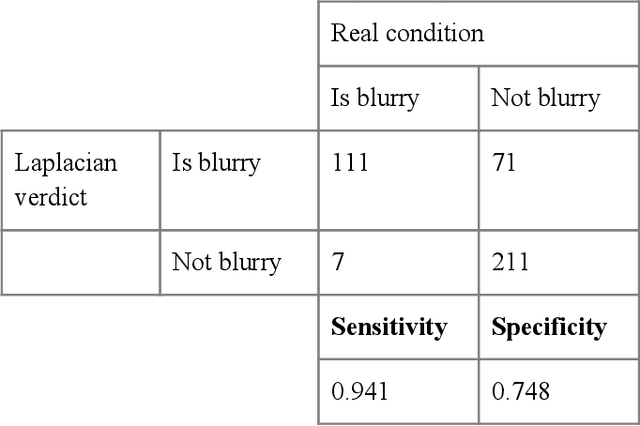
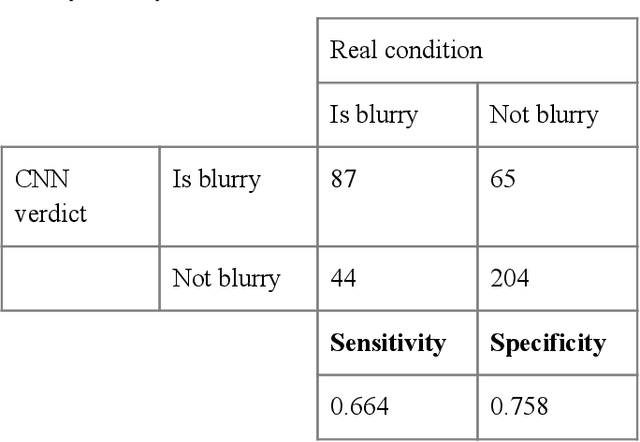

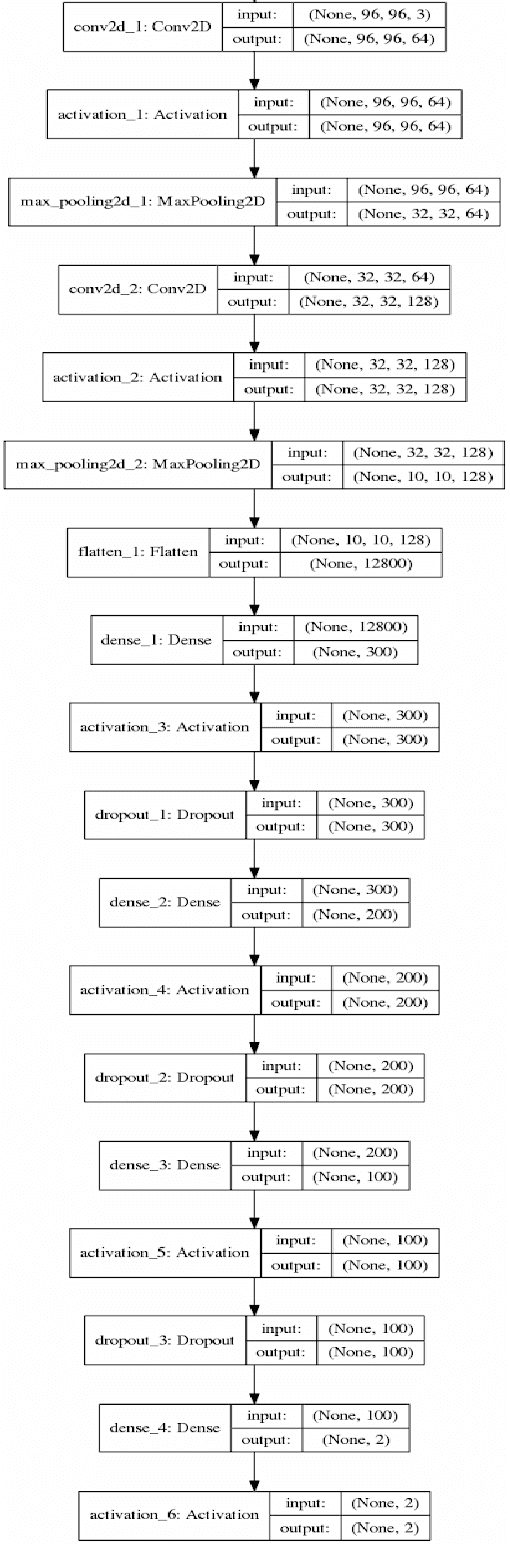
With the prevalence of digital cameras, the number of digital images increases quickly, which raises the demand for non-manual image quality assessment. While there are many methods considered useful for detecting blurriness, in this paper we propose and evaluate a new method that uses a deep convolutional neural network, which can determine whether an image is blurry or not. Experimental results demonstrate the effectiveness of the proposed scheme and are compared to deterministic methods using the confusion matrix.
Memory-efficient Learning for High-Dimensional MRI Reconstruction
Mar 06, 2021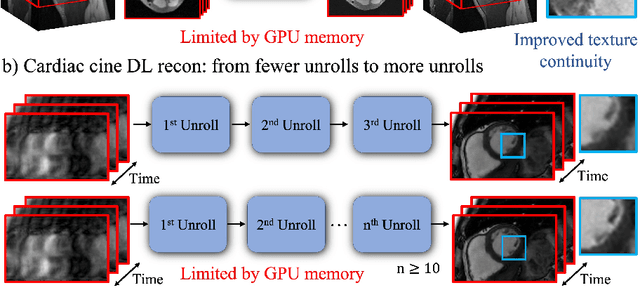

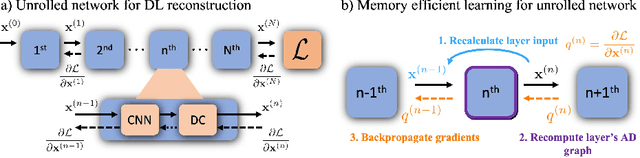
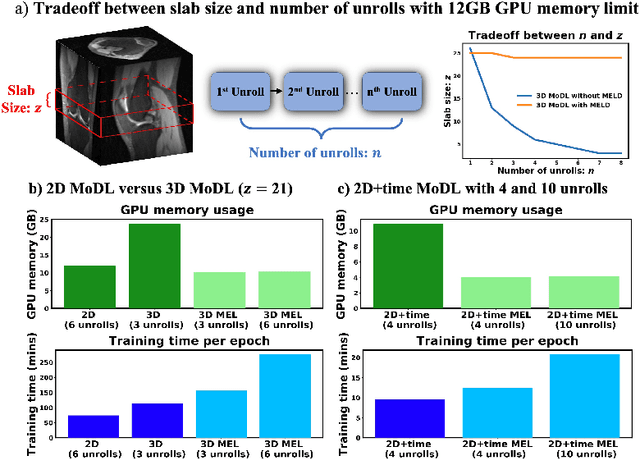
Deep learning (DL) based unrolled reconstructions have shown state-of-the-art performance for under-sampled magnetic resonance imaging (MRI). Similar to compressed sensing, DL can leverage high-dimensional data (e.g. 3D, 2D+time, 3D+time) to further improve performance. However, network size and depth are currently limited by the GPU memory required for backpropagation. Here we use a memory-efficient learning (MEL) framework which favorably trades off storage with a manageable increase in computation during training. Using MEL with multi-dimensional data, we demonstrate improved image reconstruction performance for in-vivo 3D MRI and 2D+time cardiac cine MRI. MEL uses far less GPU memory while marginally increasing the training time, which enables new applications of DL to high-dimensional MRI.