 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual Directed Capsule Network for Very Low Resolution Image Recognition
Aug 27, 2019
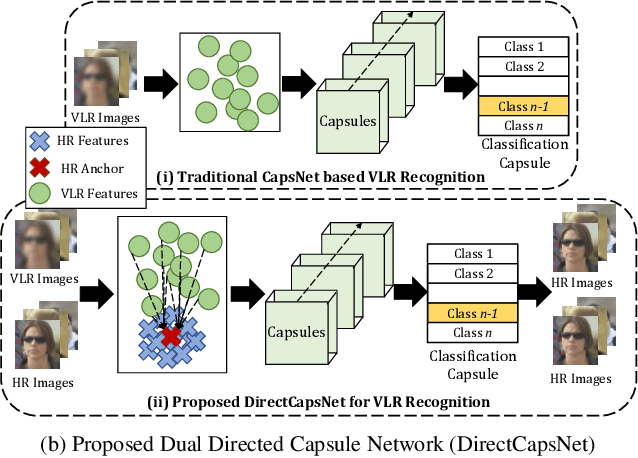
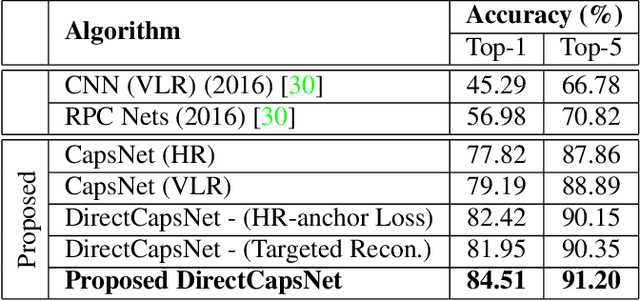

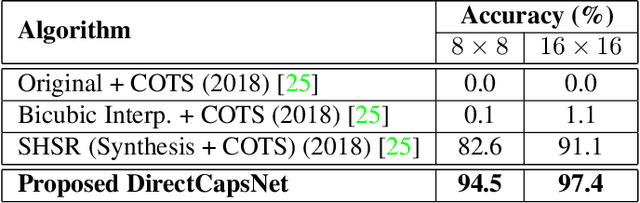
Very low resolution (VLR) image recognition corresponds to classifying images with resolution 16x16 or less. Though it has widespread applicability when objects are captured at a very large stand-off distance (e.g. surveillance scenario) or from wide angle mobile cameras, it has received limited attention. This research presents a novel Dual Directed Capsule Network model, termed as DirectCapsNet, for addressing VLR digit and face recognition. The proposed architecture utilizes a combination of capsule and convolutional layers for learning an effective VLR recognition model. The architecture also incorporates two novel loss functions: (i) the proposed HR-anchor loss and (ii) the proposed targeted reconstruction loss, in order to overcome the challenges of limited information content in VLR images. The proposed losses use high resolution images as auxiliary data during training to "direct" discriminative feature learning. Multiple experiments for VLR digit classification and VLR face recognition are performed along with comparisons with state-of-the-art algorithms. The proposed DirectCapsNet consistently showcases state-of-the-art results; for example, on the UCCS face database, it shows over 95\% face recognition accuracy when 16x16 images are matched with 80x80 images.
Detecting Adversarial Examples by Input Transformations, Defense Perturbations, and Voting
Jan 27, 2021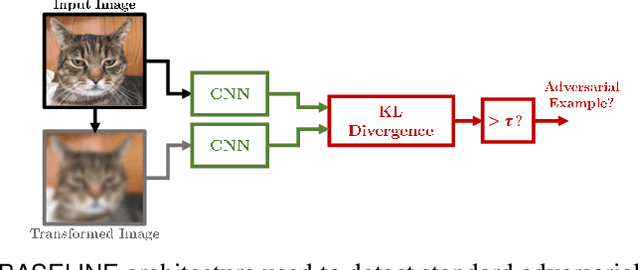

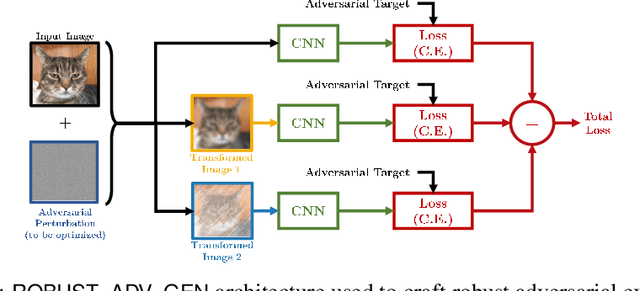
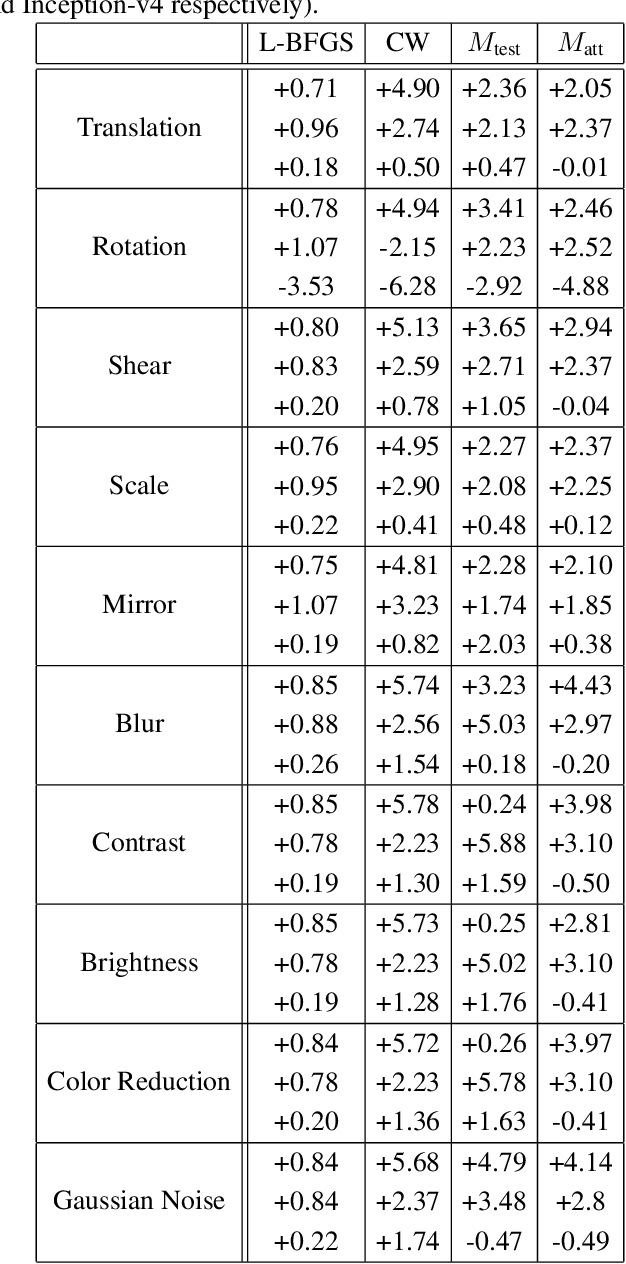
Over the last few years, convolutional neural networks (CNNs) have proved to reach super-human performance in visual recognition tasks. However, CNNs can easily be fooled by adversarial examples, i.e., maliciously-crafted images that force the networks to predict an incorrect output while being extremely similar to those for which a correct output is predicted. Regular adversarial examples are not robust to input image transformations, which can then be used to detect whether an adversarial example is presented to the network. Nevertheless, it is still possible to generate adversarial examples that are robust to such transformations. This paper extensively explores the detection of adversarial examples via image transformations and proposes a novel methodology, called \textit{defense perturbation}, to detect robust adversarial examples with the same input transformations the adversarial examples are robust to. Such a \textit{defense perturbation} is shown to be an effective counter-measure to robust adversarial examples. Furthermore, multi-network adversarial examples are introduced. This kind of adversarial examples can be used to simultaneously fool multiple networks, which is critical in systems that use network redundancy, such as those based on architectures with majority voting over multiple CNNs. An extensive set of experiments based on state-of-the-art CNNs trained on the Imagenet dataset is finally reported.
Segmentation overlapping wear particles with few labelled data and imbalance sample
Nov 20, 2020
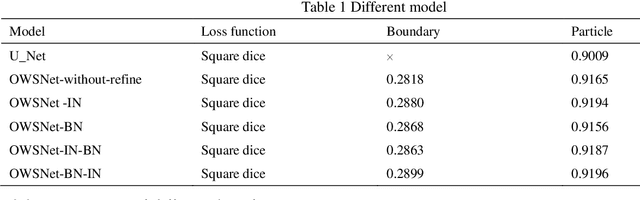
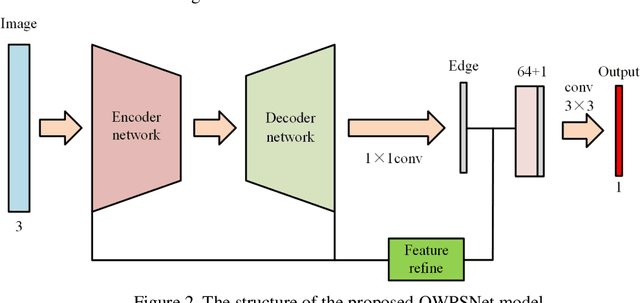

Ferrograph image segmentation is of significance for obtaining features of wear particles. However, wear particles are usually overlapped in the form of debris chains, which makes challenges to segment wear debris. An overlapping wear particle segmentation network (OWPSNet) is proposed in this study to segment the overlapped debris chains. The proposed deep learning model includes three parts: a region segmentation network, an edge detection network and a feature refine module. The region segmentation network is an improved U shape network, and it is applied to separate the wear debris form background of ferrograph image. The edge detection network is used to detect the edges of wear particles. Then, the feature refine module combines low-level features and high-level semantic features to obtain the final results. In order to solve the problem of sample imbalance, we proposed a square dice loss function to optimize the model. Finally, extensive experiments have been carried out on a ferrograph image dataset. Results show that the proposed model is capable of separating overlapping wear particles. Moreover, the proposed square dice loss function can improve the segmentation results, especially for the segmentation results of wear particle edge.
Super-Resolution with Deep Adaptive Image Resampling
Dec 18, 2017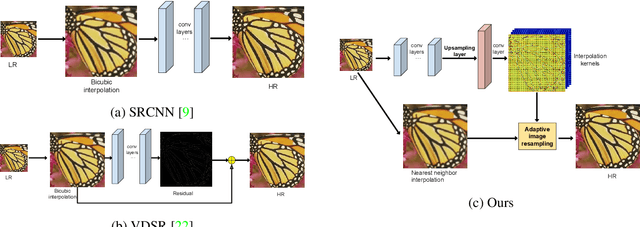

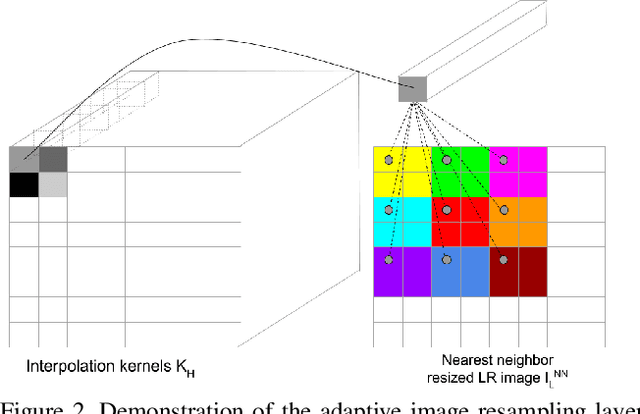
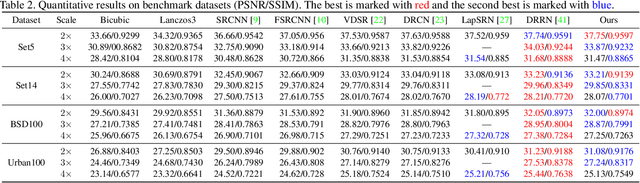
Deep learning based methods have recently pushed the state-of-the-art on the problem of Single Image Super-Resolution (SISR). In this work, we revisit the more traditional interpolation-based methods, that were popular before, now with the help of deep learning. In particular, we propose to use a Convolutional Neural Network (CNN) to estimate spatially variant interpolation kernels and apply the estimated kernels adaptively to each position in the image. The whole model is trained in an end-to-end manner. We explore two ways to improve the results for the case of large upscaling factors, and propose a recursive extension of our basic model. This achieves results that are on par with state-of-the-art methods. We visualize the estimated adaptive interpolation kernels to gain more insight on the effectiveness of the proposed method. We also extend the method to the task of joint image filtering and again achieve state-of-the-art performance.
Visual-Semantic Embedding Model Informed by Structured Knowledge
Sep 21, 2020
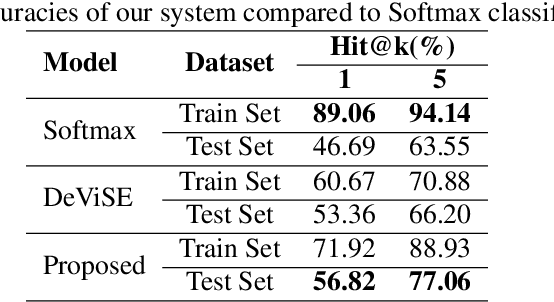
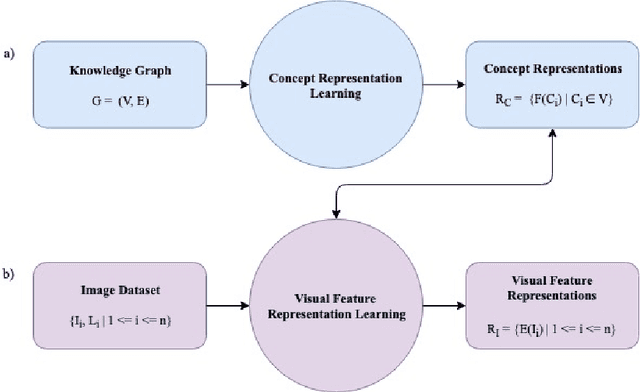

We propose a novel approach to improve a visual-semantic embedding model by incorporating concept representations captured from an external structured knowledge base. We investigate its performance on image classification under both standard and zero-shot settings. We propose two novel evaluation frameworks to analyse classification errors with respect to the class hierarchy indicated by the knowledge base. The approach is tested using the ILSVRC 2012 image dataset and a WordNet knowledge base. With respect to both standard and zero-shot image classification, our approach shows superior performance compared with the original approach, which uses word embeddings.
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021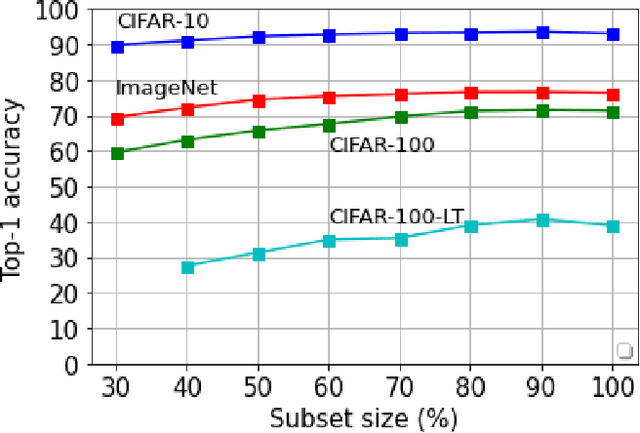
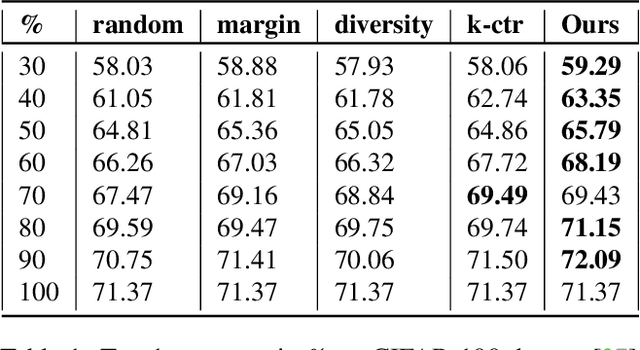
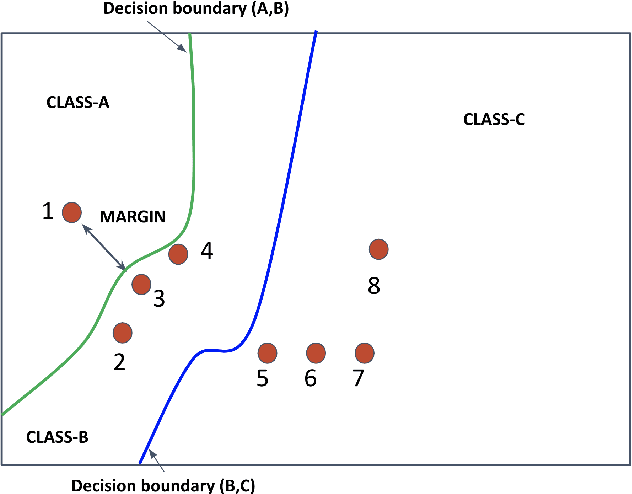
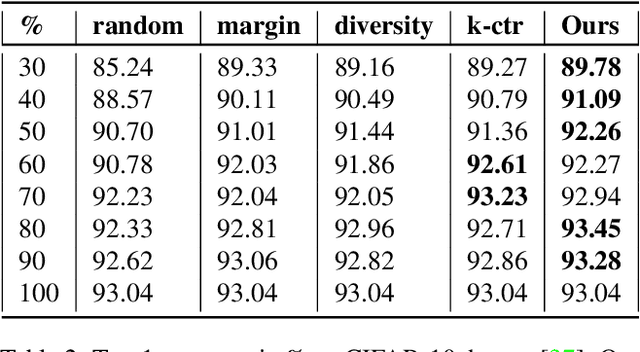
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
A Cascaded Convolutional Neural Network for Single Image Dehazing
Mar 21, 2018
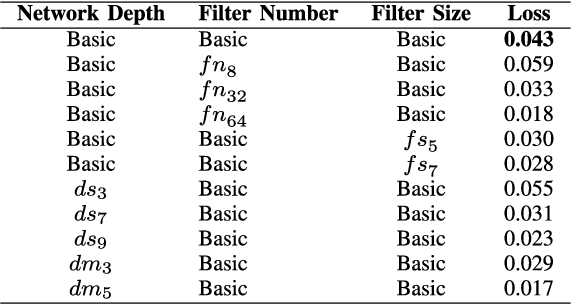
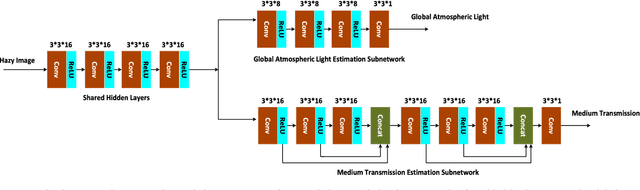
Images captured under outdoor scenes usually suffer from low contrast and limited visibility due to suspended atmospheric particles, which directly affects the quality of photos. Despite numerous image dehazing methods have been proposed, effective hazy image restoration remains a challenging problem. Existing learning-based methods usually predict the medium transmission by Convolutional Neural Networks (CNNs), but ignore the key global atmospheric light. Different from previous learning-based methods, we propose a flexible cascaded CNN for single hazy image restoration, which considers the medium transmission and global atmospheric light jointly by two task-driven subnetworks. Specifically, the medium transmission estimation subnetwork is inspired by the densely connected CNN while the global atmospheric light estimation subnetwork is a light-weight CNN. Besides, these two subnetworks are cascaded by sharing the common features. Finally, with the estimated model parameters, the haze-free image is obtained by the atmospheric scattering model inversion, which achieves more accurate and effective restoration performance. Qualitatively and quantitatively experimental results on the synthetic and real-world hazy images demonstrate that the proposed method effectively removes haze from such images, and outperforms several state-of-the-art dehazing methods.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021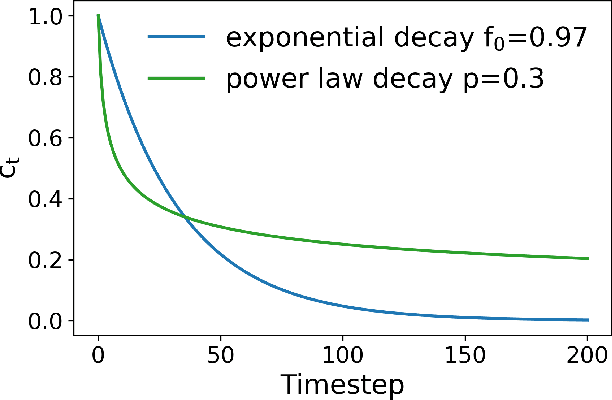
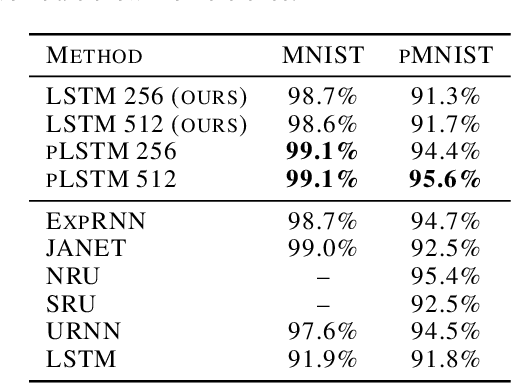
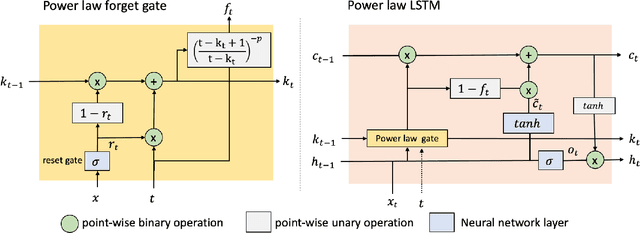
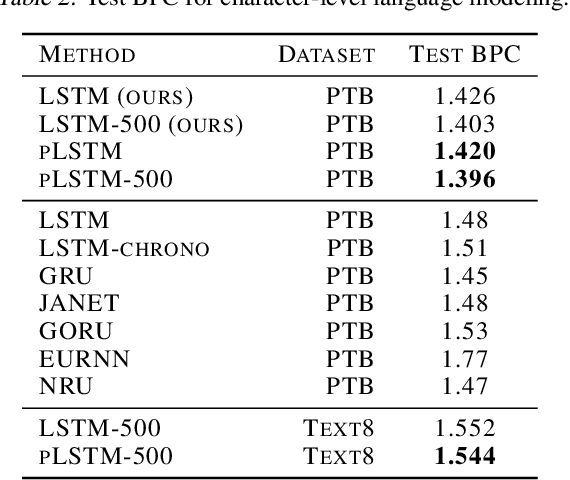
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Automated Prostate Cancer Diagnosis Based on Gleason Grading Using Convolutional Neural Network
Nov 29, 2020
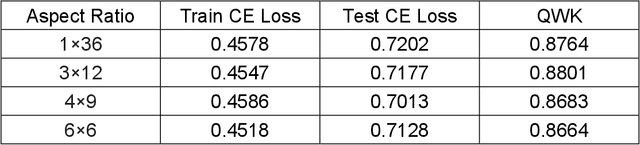
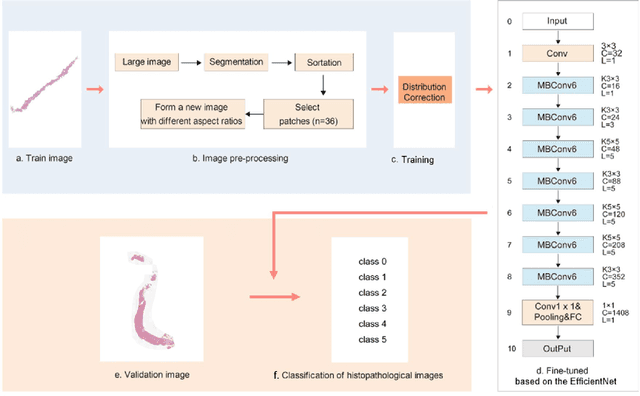
The Gleason grading system using histological images is the most powerful diagnostic and prognostic predictor of prostate cancer. The current standard inspection is evaluating Gleason H&E-stained histopathology images by pathologists. However, it is complicated, time-consuming, and subject to observers. Deep learning (DL) based-methods that automatically learn image features and achieve higher generalization ability have attracted significant attention. However, challenges remain especially using DL to train the whole slide image (WSI), a predominant clinical source in the current diagnostic setting, containing billions of pixels, morphological heterogeneity, and artifacts. Hence, we proposed a convolutional neural network (CNN)-based automatic classification method for accurate grading of PCa using whole slide histopathology images. In this paper, a data augmentation method named Patch-Based Image Reconstruction (PBIR) was proposed to reduce the high resolution and increase the diversity of WSIs. In addition, a distribution correction (DC) module was developed to enhance the adaption of pretrained model to the target dataset by adjusting the data distribution. Besides, a Quadratic Weighted Mean Square Error (QWMSE) function was presented to reduce the misdiagnosis caused by equal Euclidean distances. Our experiments indicated the combination of PBIR, DC, and QWMSE function was necessary for achieving superior expert-level performance, leading to the best results (0.8885 quadratic-weighted kappa coefficient).
Classifying a specific image region using convolutional nets with an ROI mask as input
Dec 05, 2018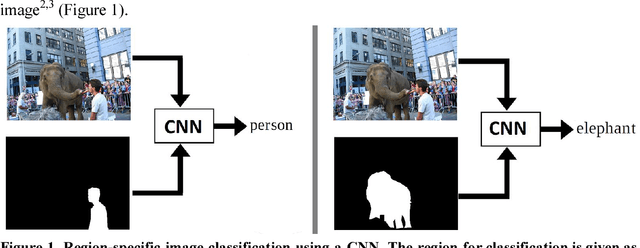
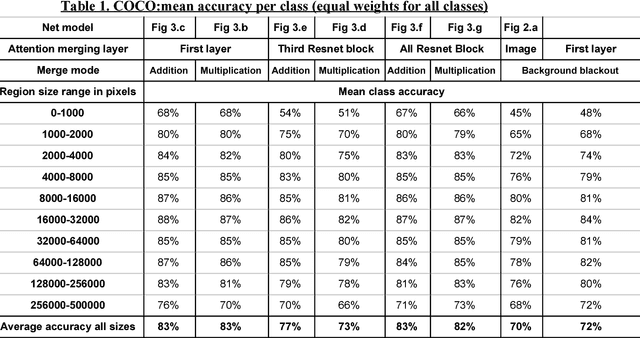
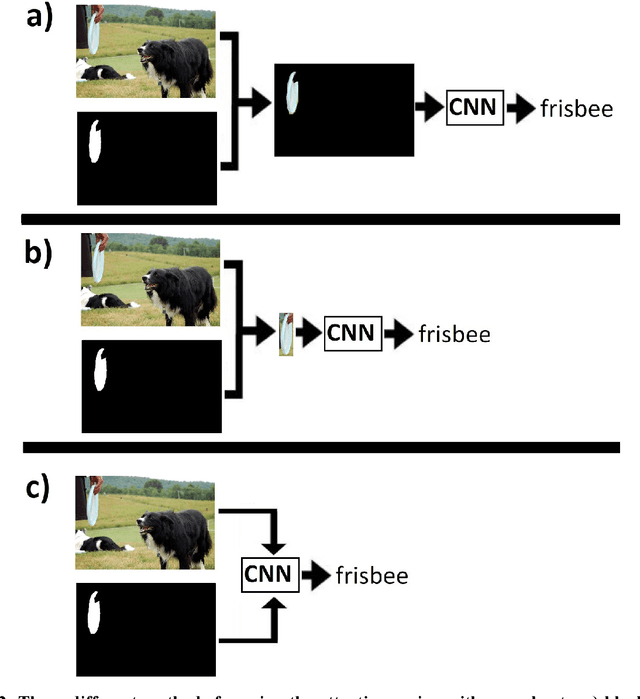
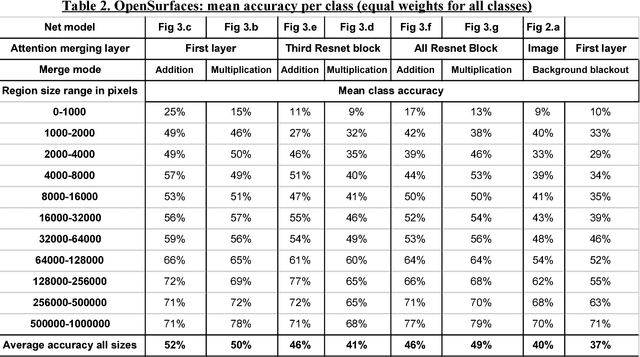
Convolutional neural nets (CNN) are the leading computer vision method for classifying images. In some cases, it is desirable to classify only a specific region of the image that corresponds to a certain object. Hence, assuming that the region of the object in the image is known in advance and is given as a binary region of interest (ROI) mask, the goal is to classify the object in this region using a convolutional neural net. This goal is achieved using a standard image classification net with the addition of a side branch, which converts the ROI mask into an attention map. This map is then combined with the image classification net. This allows the net to focus the attention on the object region while still extracting contextual cues from the background. This approach was evaluated using the COCO object dataset and the OpenSurfaces materials dataset. In both cases, it gave superior results to methods that completely ignore the background region. In addition, it was found that combining the attention map at the first layer of the net gave better results than combining it at higher layers of the net. The advantages of this method are most apparent in the classification of small regions which demands a great deal of contextual information from the background.